

Последние пару лет я пишу под ядро Linux и часто вижу, как люди страдают от незнания давнишних, общепринятых и (почти) удобных инструментов. Например,
printk, собрать логи, обработать их В ядре Linux таких механизмов 3:
- tracepoints
- kprobes
- perf events
На основе этих 3 фич ядра строятся абсолютно все профилировщики и трассировщики, которые доступны для Linux, в том числе
ftrace, perf, SystemTap, ktap и другие. В этой статье я расскажу, что они (механизмы) дают, как работают, а в следующие разы мы посмотрим уже на конкретные тулзы.Kernel tracepoints
Kernel tracepoints — это фреймворк для трассировки ядра, сделанный через статическое инструментирование кода. Да, вы правильно поняли, большинство важных функций ядра (сеть, управление памятью, планировщик) статически инструментировано. На моём ядре количество tracepoint’ов такое:
[etn]$ perf list tracepointt | wc -l 1271
Среди них есть kmalloc:
[etn]$ perf list tracepoint | grep "kmalloc " kmem:kmalloc [Tracepoint event]
А вот так оно выглядит на самом деле в ядерной функции
__do_kmalloc:/**
* __do_kmalloc - allocate memory
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate (see kmalloc).
* @caller: function caller for debug tracking of the caller
*/
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,
unsigned long caller)
{
struct kmem_cache *cachep;
void *ret;
cachep = kmalloc_slab(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
ret = slab_alloc(cachep, flags, caller);
trace_kmalloc(caller, ret,
size, cachep->size, flags);
return ret;
}
trace_kmalloc — это и есть tracepoint.Такие tracepoint’ы пишут вывод в отладочный кольцевой буфер, который можно посмотреть в /sys/kernel/debug/tracing/trace:
[~]# mount -t debugfs none /sys/kernel/debug [~]# cd /sys/kernel/debug/tracing/ [tracing]# echo 1 > events/kmem/kmalloc/enable [tracing]# tail trace bash-10921 [000] .... 1127940.937139: kmalloc: call_site=ffffffff8122f0f5 ptr=ffff8800aaecb900 bytes_req=48 bytes_alloc=64 gfp_flags=GFP_KERNEL bash-10921 [000] .... 1127940.937139: kmalloc: call_site=ffffffff8122f084 ptr=ffff8800ca008800 bytes_req=2048 bytes_alloc=2048 gfp_flags=GFP_KERNEL|GFP_NOWARN|GFP_NORETRY bash-10921 [000] .... 1127940.937139: kmalloc: call_site=ffffffff8122f084 ptr=ffff8800aaecbd80 bytes_req=64 bytes_alloc=64 gfp_flags=GFP_KERNEL|GFP_NOWARN|GFP_NORETRY tail-11005 [001] .... 1127940.937451: kmalloc: call_site=ffffffff81219297 ptr=ffff8800aecf5f00 bytes_req=240 bytes_alloc=256 gfp_flags=GFP_KERNEL|GFP_ZERO tail-11005 [000] .... 1127940.937518: kmalloc: call_site=ffffffff81267801 ptr=ffff880123e8bd80 bytes_req=128 bytes_alloc=128 gfp_flags=GFP_KERNEL tail-11005 [000] .... 1127940.937519: kmalloc: call_site=ffffffff81267786 ptr=ffff880077faca00 bytes_req=504 bytes_alloc=512 gfp_flags=GFP_KERNEL
Заметьте, что traсepoint «kmem:kmalloc», как и все остальные, по умолчанию выключен, так что его надо включить, сказав 1 в его
enable файл.Вы можете сами написать tracepoint для своего модуля ядра. Но,
CONFIG_MODULE_SIG (почти всегда да) и нет закрытого ключа для подписи (он у вендора ядра вашего дистрибутива). Смотри душераздирающие подробности в lkml [1], [2].Короче говоря, tracepoint’ы простая и легковесная вещь, но пользоваться ей руками неудобно и не рекомендуется — используйте
ftrace или perf.kprobes
Если tracepoint’ы — это метки статического инструментирования, то
kprobes — это механизм динамического инструментирования кода. С помощью kprobes вы можете прервать выполнение ядерного кода в любом месте, вызвать свой обработчик, сделать в нём что хотите и вернуться обратно как ни в чём ни бывало.Как это делается: вы пишете свой модуль ядра, в котором регистрируете обработчик на определённый символ ядра (читай, функцию) или вообще любой адрес.
Работает это всё следующим образом:
- Мы делаем свой модуль ядра, в котором пишем наш обработчик.
- Мы регистрируем наш обработчик на некий адрес A, будь то просто адрес или
какая-нибудь функция. - Подсистема kprobe копирует инструкции по адресу, А и заменяет их на CPU trap (
int 3для x86). - Теперь, когда выполнение кода доходит до адреса A, генерируется исключение, по которому сохраняются регистры, а управление передаётся обработчику исключительной ситуации, коим в конце концов становится kprobes.
- Подсистема kprobes смотрит на адрес исключения, находит, кто был зарегистрирован по адресу, А и вызывает наш обработчик.
- Когда наш обработчик заканчивается, регистры восстанавливаются, выполняются сохранённые инструкции, и выполнение продолжается дальше.
В ядре есть 3 вида kprobes:
- kprobes — «базовая» проба, которая позволяет прервать любое место ядра.
- jprobes — jump probe, вставляется только в начало функции, но зато даёт удобный механизм доступа к аргументам прерываемой функции для нашего обработчика. Также работает не за счёт trap’ов, а через
setjmp/longjmp(отсюда и название), то есть более легковесна. - kretprobes — return probe, вставляется перед выходом из функции и даёт удобный доступ к результату функции.
С помощью kprobes мы можем трассировать всё что угодно, включая код сторонних модулей. Давайте сделаем это для нашего miscdevice драйвера. Я хочу знать, что
В моём miscdevice драйвере функция выглядит так:
ssize_t etn_write(struct file *filp, const char __user *buf,
size_t count, loff_t *f_pos)Я написал простой jprobe модуль, который пишет в ядерный лог количество байт и смещение.
root@etn:~# tail -F /var/log/kern.log Jan 1 00:00:42 etn kernel: [ 42.923717] ETN JPROBE: jprobe_init:46: Planted jprobe at bf00f7a8, handler addr bf071000 Jan 1 00:00:43 etn kernel: [ 43.194840] ETN JPROBE: trace_etn_write:23: Writing 2 bytes at offset 4 Jan 1 00:00:43 etn kernel: [ 43.201827] ETN JPROBE: trace_etn_write:23: Writing 2 bytes at offset 4
Короче, вещь мощная, однако пользоваться не шибко удобно: доступа к локальным переменным нет (только через отступ от
ebp), нужно писать модуль ядра, отлаживать, загружать Perf events
Сразу скажу, что не надо путать «perf events» и программу
perf — про программу будет сказано отдельно.«Perf events» — это интерфейс доступа к счётчикам в PMU (Performance Monitoring Unit), который является частью CPU. Благодаря этим метрикам, вы можете с легкостью попросить ядро показать вам сколько было промахов в L1 кеше, независимо от того, какая у вас архитектура, будь то ARM или amd64. Правда, для вашего процессора должна быть поддержка в ядре:-) Относительно актуальную информацию по этому поводу можно найти здесь.
Для доступа к этим счётчикам, а также к огромной куче другого добра, была написана программа
perf. С её помощью можно посмотреть, какие железные события нам доступны. $ perf list pmu hw sw cache branch-instructions OR cpu/branch-instructions/ [Kernel PMU event] branch-misses OR cpu/branch-misses/ [Kernel PMU event] bus-cycles OR cpu/bus-cycles/ [Kernel PMU event] cache-misses OR cpu/cache-misses/ [Kernel PMU event] cache-references OR cpu/cache-references/ [Kernel PMU event] cpu-cycles OR cpu/cpu-cycles/ [Kernel PMU event] instructions OR cpu/instructions/ [Kernel PMU event] cpu-cycles OR cycles [Hardware event] instructions [Hardware event] cache-references [Hardware event] cache-misses [Hardware event] branch-instructions OR branches [Hardware event] branch-misses [Hardware event] bus-cycles [Hardware event] ref-cycles [Hardware event] cpu-clock [Software event] task-clock [Software event] page-faults OR faults [Software event] context-switches OR cs [Software event] cpu-migrations OR migrations [Software event] minor-faults [Software event] major-faults [Software event] alignment-faults [Software event] emulation-faults [Software event] dummy [Software event] L1-dcache-loads [Hardware cache event] L1-dcache-load-misses [Hardware cache event] L1-dcache-stores [Hardware cache event] L1-dcache-store-misses [Hardware cache event] L1-dcache-prefetches [Hardware cache event] L1-icache-loads [Hardware cache event] L1-icache-load-misses [Hardware cache event] LLC-loads [Hardware cache event] LLC-load-misses [Hardware cache event] LLC-stores [Hardware cache event] LLC-store-misses [Hardware cache event] dTLB-loads [Hardware cache event] dTLB-load-misses [Hardware cache event] dTLB-stores [Hardware cache event] dTLB-store-misses [Hardware cache event] iTLB-loads [Hardware cache event] iTLB-load-misses [Hardware cache event] branch-loads [Hardware cache event] branch-load-misses [Hardware cache event]
root@etn:~# perf list pmu hw sw cache cpu-cycles OR cycles [Hardware event] instructions [Hardware event] cache-references [Hardware event] cache-misses [Hardware event] branch-instructions OR branches [Hardware event] branch-misses [Hardware event] stalled-cycles-frontend OR idle-cycles-frontend [Hardware event] stalled-cycles-backend OR idle-cycles-backend [Hardware event] ref-cycles [Hardware event] cpu-clock [Software event] task-clock [Software event] page-faults OR faults [Software event] context-switches OR cs [Software event] cpu-migrations OR migrations [Software event] minor-faults [Software event] major-faults [Software event] alignment-faults [Software event] emulation-faults [Software event] dummy [Software event] L1-dcache-loads [Hardware cache event] L1-dcache-load-misses [Hardware cache event] L1-dcache-stores [Hardware cache event] L1-dcache-store-misses [Hardware cache event] L1-icache-load-misses [Hardware cache event] dTLB-load-misses [Hardware cache event] dTLB-store-misses [Hardware cache event] iTLB-load-misses [Hardware cache event] branch-loads [Hardware cache event] branch-load-misses [Hardware cache event]
Видно, что x86 побогаче будет на такие вещи.
Для доступа к «perf events» был сделан специальный системный вызов
perf_event_open, которому вы передаёте сам event и конфиг, в котором описываете, что вы хотите с этим событием делать. В ответ вы получаете файловый дескриптор, из которого можно читать данные, собранные perf’ом по событию.Поверх этого,
perf предоставляет множество разных фич, вроде группировки событий, фильтрации, вывода в разные форматы, анализа собранных профилей и пр. Поэтому в perf сейчас пихают всё, что можно: от tracepoint’ов до eBPF и вплоть до того, что весь ftrace хотят сделать частью perf [3] [4].Короче говоря, «perf_events» сами по себе мало интересны, а сам
perf заслуживает отдельной статьи, поэтому для затравки покажу простой пример.Говорим:
root@etn:~# perf timechart record apt-get update ... root@etn:~# perf timechart -i perf.data -o timechart.svg
И получаем вот такое чудо:
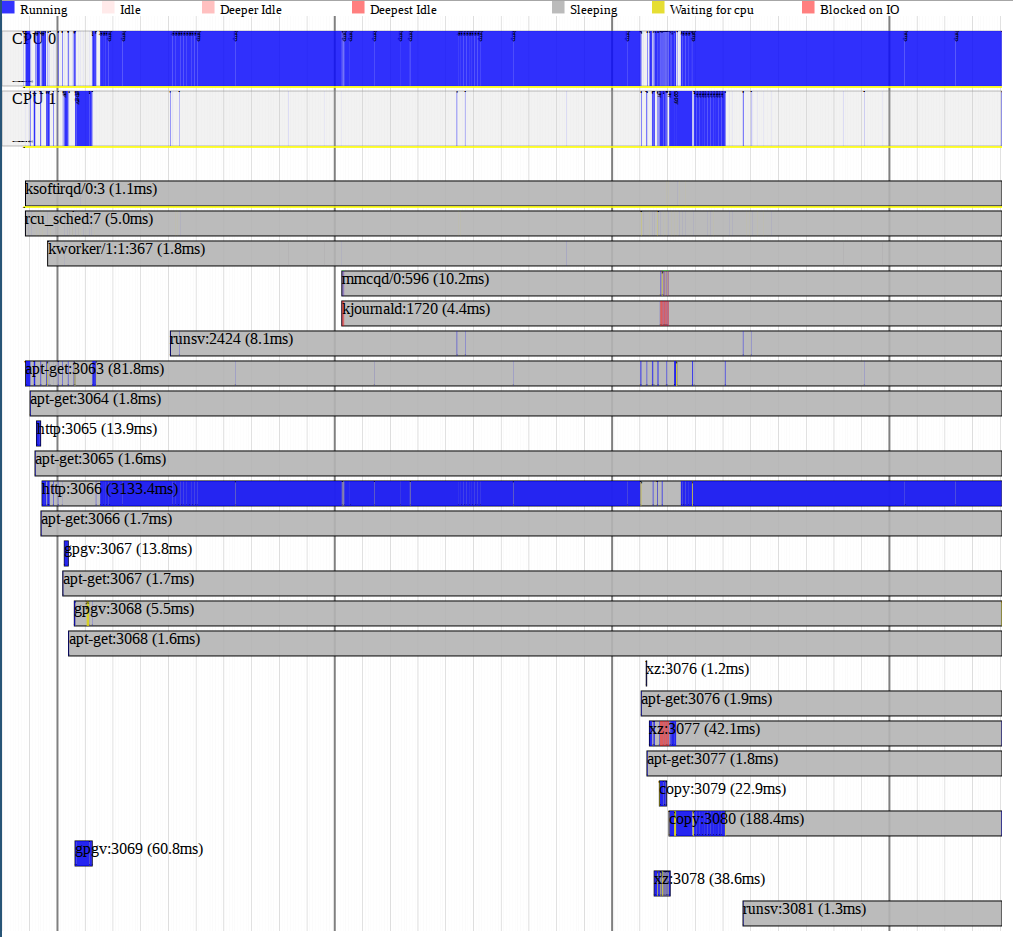 Perf timechart
Perf timechartВывод
Таким образом, зная чуть больше про трассировку и профилирование в ядре, вы можете сильно облегчить жизнь себе и товарищам, особенно если научиться пользоваться настоящими инструментами как
ftrace, perf и SystemTap, но об этом в другой раз.Почитать
Комментарии (11)

jcmvbkbc
25.06.2015 00:45программа perf. С её помощью можно посмотреть, какие железные события нам доступны.
perf list hw cache работает с фиксированным набором типов событий и выводит только подмножество событий, для которых архитектура предоставляет мэппинг. Но делать по этому списку вывод о богатстве возможностей аппаратных перфкаунтеров архитектуры неправильно. Полный доступ к аппаратной функциональности можно получить через raw события.
kay
25.06.2015 10:06+1perf сложновато запустить на системах виртуализации типа xen, т.к. хостовая система может иметь кустомное ядро.

grafmishurov
25.06.2015 02:34+1Не удивительно, что есть трассировщики, для kernel thread ведь создается task_struct, где есть состояние TASK_TRACED. А так да, принтами трейсить — не очень изящное решение.
jcmvbkbc
25.06.2015 02:53+1TASK_TRACED — это для отладчиков, см. lwn.net/Articles/100092
Ни один из перечисленных в статье механизмов не использует ptrace.

vtsymbal
25.06.2015 14:17+1Прошу прощения за такой рекламный коментарий, но чтобы было удобнее пользоваться результатами собранными perf, можно использовать VTune, который отобразит ивенты не только относительно всей системы, но и относительно вашего модуля, функции, строчки кода или ассемблерных интрукций, по выбору. Плюс куча инструментария для анализа производительности приложения применима и к perf-трассам.
Кроме того, можно импортировать результаты коллекции ивентов собранных с perf, например:
>perf record -o< trace_file_name>.perf -e cpu-cycles,instructions <application_to_launch>
Импортируем в VTune GUI или command line:
>amplxe-cl -import my_profile.perf -source-search-dir <PATH>
Так же можно и прямо запустить профилировку в VTune с использованием perf в качестве коллектора. В общем инструменты интегрированы.

ignat99
25.06.2015 19:31+1Хотелось бы услышать больше деталей про SWAP-Samsung, NOP — Apple, Valgrind — GNU
И их особенности ;-)
dzeban Автор
25.06.2015 19:40Valgrind — это динамический отладчик для пользовательских приложений, про него информации уйма, в том числе на хабре. Про остальное я впервые слышу и не могу ничего нагуглить. Можно поподробнее, что такое NOP и SWAP?
ignat99
25.06.2015 19:50NOP и SWAP это внутренние фирменные профилировщики двух известных корпораций. С полностью инструментированными функциями ядра OS. Различаются подходами. Не уверен, что можно
о них говорить вслухрассказать принцип их действия до открытия этих инструментов широкой общественности.

SaveTheRbtz
30.06.2015 12:10Начиная с 3.5 в ядре Linux появились uprobe'ы, то есть фактически аналог kprobe для userspace'а. Они тоже местами весьма полезны:
Пример использования uprobe с perf# perf probe -x /bin/bash 'readline%return +0($retval):string' Added new event: probe_bash:readline (on readline%return in /bin/bash with +0($retval):string) You can now use it in all perf tools, such as: perf record -e probe_bash:readline -aR sleep 1 # perf record -e probe_bash:readline -a ^C[ perf record: Woken up 1 times to write data ] [ perf record: Captured and wrote 0.259 MB perf.data (2 samples) ] # perf script bash 26239 [003] 283194.152199: probe_bash:readline: (48db60 <- 41e876) arg1="ls -l" bash 26239 [003] 283195.016155: probe_bash:readline: (48db60 <- 41e876) arg1="date" # perf probe --del probe_bash:readline Removed event: probe_bash:readline
degs
Спасибо, можно еще?
dzeban Автор
Конечно, можно. Я скоро буду ковырять сам perf, думаю что-нибудь про него написать.