
Сегодня мы расскажем вам об одном интересном проекте. В нем использовались службы Microsoft Cognitive Services, которые позволяют с легкостью применять технологию искусственного интеллекта путем вызова REST API (и не нужно никакое обучение). И все это на примере милого робота JD Humanoid. Подробнее под катом!

Службы Cognitive Services также содержат клиентские библиотеки для различных языков программирования, что еще больше упрощает их использование. Мы решили интегрировать эти службы в приложение, созданное для управления роботом JD Humanoid компании EZ (далее в документе мы будем называть его просто «робот EZ»). Мы выбрали именно этого робота-гуманоида, поскольку его довольно просто собрать. Кроме того, к нему прилагаются .NET, UWP SDK и даже Mono SDK, что открывает широкие возможности его реализации с индивидуальными настройками.
В комплекте идет также приложение EZ Builder, которое позволяет управлять роботом EZ и реализовывать конкретные сценарии на основе встроенных функциональных плагинов и блоков Блокли. В основном оно предназначено для образовательных целей, но в нем имеется также функция создания движения (“movement creator”), которая позволяет создавать движения робота и экспортировать их, чтобы использовать в приложениях, созданных с помощью пакета SDK. Безусловно, это приложение — отличая отправная точка для настройки и начала работы с любым роботом EZ.
В основе приложения лежит существующий проект Windows Forms, в котором используются собственные возможности робота EZ и эффективно реализована работа с камерой. Взяв это приложение за основу, мы расширили его и подключили к следующим службам Cognitive Services: Face API, Emotion API, Speech API, Voice Recognition API, Language Understanding Intelligent Service, Speaker Recognition API, Computer Vision API, Custom Vision API. Благодаря этому у робота появились новые возможности:
Когнитивные возможности робота демонстрируются в этом видео.
Далее в этом документе мы коротко расскажем о том, как работать с пакетом SDK робота EZ, а также детально опишем сценарии реализации с использованием служб Cognitive Services.
Основное предварительное требование для работы с приложением — возможность подключения к роботу из кода нашего приложения, вызов движений и получение входящих изображений с камеры. Приложение выполняется на компьютере разработчика, поскольку робот EZ не имеет собственной среды выполнения и хранения, где можно было бы разместить и запустить приложение.
Таким образом, оно работает на компьютере, который подключается к роботу EZ через сеть WiFi, напрямую через точку доступа, включаемую самим роботом (режим АР), либо через сеть WiFi, созданную другим маршрутизатором (режим клиента). Мы выбрали второй вариант, поскольку он поддерживает подключение к Интернету при разработке и запуске приложения. Сетевые настройки при работе с роботом EZ подробно описаны здесь. При подключении к сети WiFi роботу EZ выделяется IP-адрес, который в дальнейшем используется для соединения с роботом из приложения. При использовании пакета SDK процедура следующая:
Поскольку камера робота EZ является изолированным сетевым устройством, мы должны к ней подключиться для дальнейшего использования.
В официальной Документации пакета SDK робота EZ приведены подробные примеры вызова специальных функций робота EZ, которые становятся доступными после подключения к нему.
Пакет SDK позволяет взаимодействовать с серводвигателем робота и контролировать его движения. Чтобы создать движение, необходимо задать фреймы (конкретные положения) и действия, состоящие из набора таких фреймов. Реализовать это в коде вручную не очень просто, но в приложении EZ Builder можно задавать фреймы, создавать из них действия, а затем экспортировать в код и использовать в приложении. Для этого нам нужно создать новый проект в EZ Builder, добавить плагин Auto Position и нажать кнопку с изображением шестеренки.
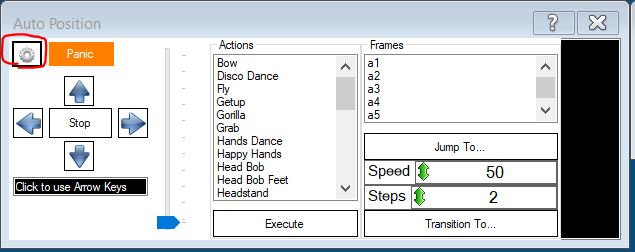
Рисунок 1. Плагин Auto Position
В дальнейшем вы сможете создавать новые фреймы на панели Frames, меняя углы серводвигателей робота. Следующий шаг — создание нужных движений из существующих на панели Action фреймов.
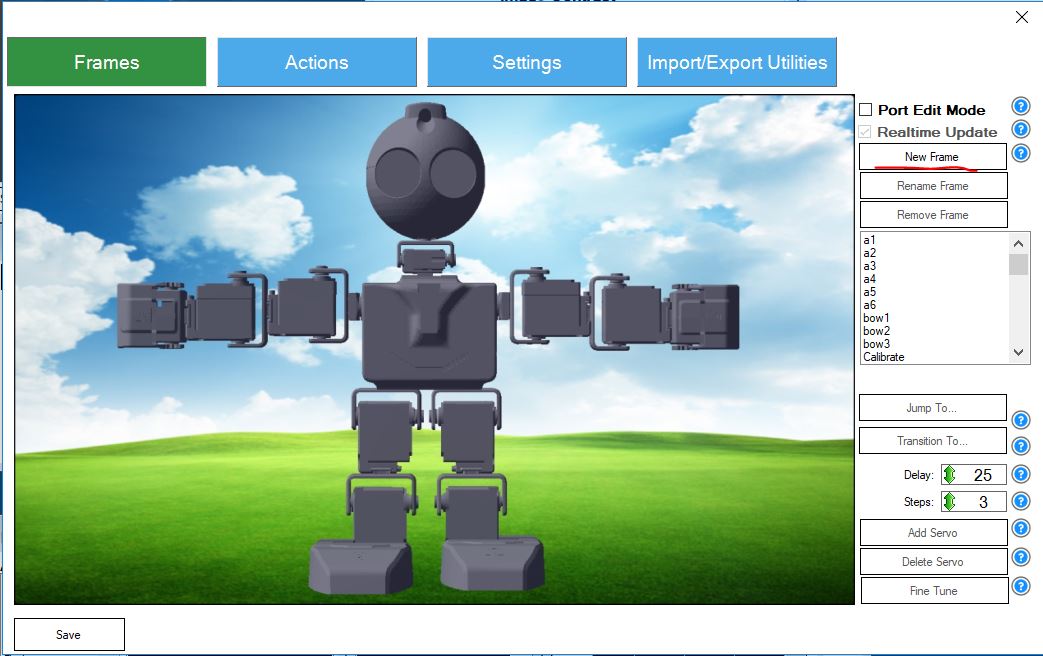
Рисунок 2. Фреймы Auto Position
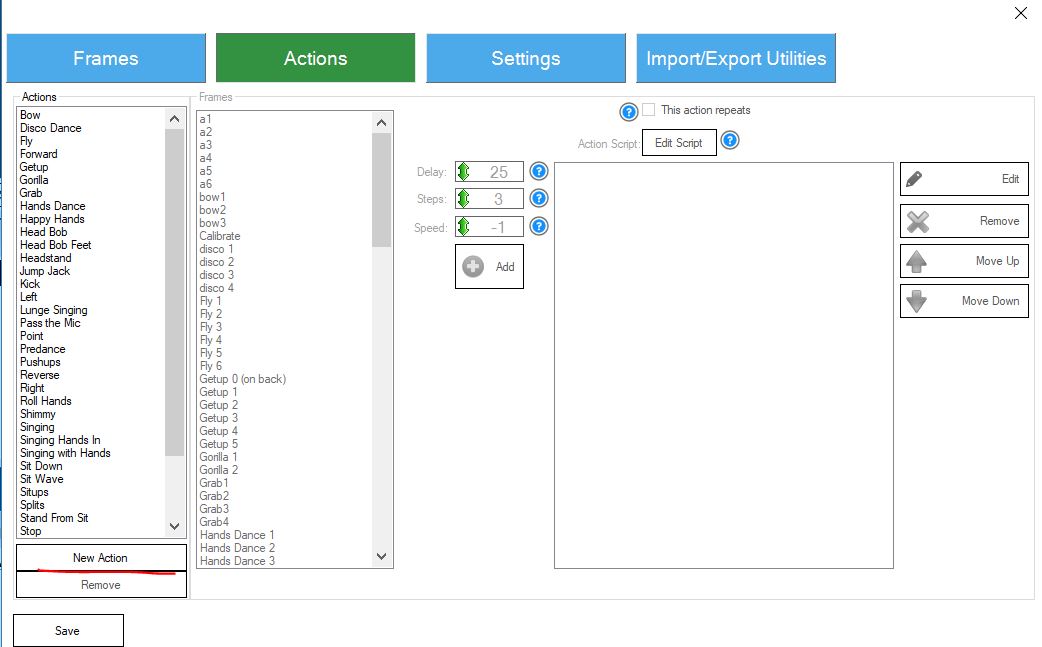
Рисунок 3. Действия Auto Position
Созданное действие можно экспортировать через панель инструментов импорта/экспорта.
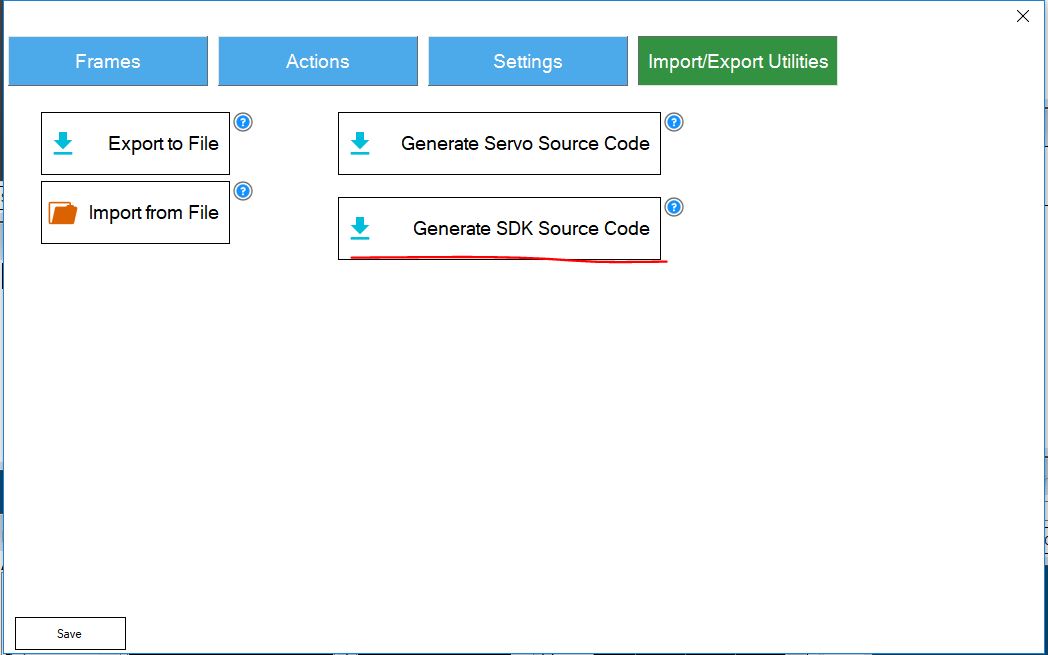
Рисунок 4. Экспорт исходного кода плагина Auto Position
Закончив экспорт действия, вы можете скопировать код и вставить его в свое приложение. Если мы будем использовать различные позиции, следует переименовать класс AutoPositions, присвоив ему имя, точно отражающее тип движения. Затем его можно использовать в коде следующим образом:
Поскольку в приложении мы используем изображения с камеры робота в качестве входных данных при вызове служб Cognitive Services, то мы должны найти способ получения этих изображений. Делается это так.
Как уже упоминалось, приложение выполняется на компьютере разработчика и просто отправляет роботу команды. Робот не имеет своей среды выполнения. Если нужно синтезировать речь (проще говоря, вы хотите, чтобы робот произнес пару фраз), то нужно выбрать один из двух вариантов, предлагаемых пакетом SDK. Первый вариант предусматривает использование стандартного аудиоустройства: звук будет воспроизводиться компьютером разработчика, а не динамиком робота. Этот вариант удобен в тех случаях, когда вам нужно, чтобы робот говорил через динамик компьютера, например, во время презентаций. Однако в большинстве случаев желательно, чтобы звук воспроизводился самим роботом. Ниже приводится реализация обоих вариантов вызова звуковой функции с помощью пакета SDK:
В этом разделе мы рассмотрим конкретные сценарии когнитивных функций, реализованных в приложении для управления роботом.
Вы можете приводить робота в действие, подавая голосовые команды через подключенный к компьютеру разработчика микрофон, поскольку у самого робота EZ микрофона нет. Сначала мы использовали пакет SDK робота EZ для распознавания речи. Как выяснилось, распознавание было недостаточно точным, и робот выполнял неправильные действия исходя из неверно понятых команд. Чтобы повысить точность распознавания и свободу действий при подаче команд, мы решили использовать интерфейс Microsoft Speech API, который преобразует речь в текст, а также службу Language Understanding Intelligent Service (LUIS) для распознавания действия, требуемого конкретной командой. Используйте ссылки на эти продукты, чтобы получить дополнительную информацию о них и начать работу.
Сначала следует создать приложение LUIS, в котором к каждой команде привязываются нужные нам действия. Процесс создания приложения LUIS описан в этом руководстве для начала работы. LUIS предлагает вариант работы через веб-интерфейс, где вы можете с легкостью создать приложение и задать нужные действия. Если необходимо, вы также можете создать сущности, которые приложение LUIS будет распознавать по отправляемым в службу командам. Результат экспорта приложения LUIS содержится в этом репозитории в папке LUIS Model.
После подготовки приложения LUIS мы реализуем следующую логику: ожидание голосовых команд, вызов интерфейса Microsoft Speech API, вызов службы распознавания LUIS. В качестве основы для этой функциональности мы использовали следующий образец.
Он содержит логику распознавания длинных и коротких фраз с микрофона или из файла .wav с последующим распознаванием действия службой LUIS или без него.
Мы использовали класс MicrophoneRecognitionClientWithIntent, который содержит функции ожидания команд микрофоном, распознавания речи и требуемого действия. Кроме этого, вызов функции ожидания коротких фраз осуществляется с помощью дескриптора SayCommandButton_Click.
Логика вызова команды использует дескриптор OnIntentHandler — здесь мы анализируем ответ, полученный от службы LUIS.
Для реализации функции распознавания лиц и эмоций мы использовали службы Face API и Emotion API. Перейдя по приведенным выше ссылкам, вы сможете узнать больше об этих службах и о начале работы с ними, получить инструкции о создании ключа API и интеграции служб в ваше приложение.
Робот EZ способен самостоятельно распознавать лица, используя пакет SDK. Вызов служб Cognitive Services при этом не требуется. Однако это лишь базовый вид распознавания лиц без дополнительных параметров (например, возраста, пола, растительности на лице и т. п.). Но мы все же воспользуемся этой локальной функцией распознавания: она поможет понять, что на изображении присутствует лицо. После этого мы задействуем Cognitive Services Face API для получения дополнительных параметров лица. Благодаря этому отпадет необходимость в лишних вызовах API.
Функция робота EZ, выполняющая распознавание лиц, также предоставляет сведения о расположении лица на картинке. Мы решили воспользоваться этим, чтобы робот поворачивал голову, и его камера была направлена прямо на лицо. Мы заимствовали этот код из приложения Win Form в качестве основы нашего проекта. При этом мы добавили параметр чувствительности, который определяет скорость движения и корректировки положения головы робота.
Итак, чтобы интерфейс Face API мог идентифицировать конкретных людей, нам нужно создать группу таких людей, зарегистрировать их и обучить модель распознавания. Нам удалось сделать это без лишних усилий с помощью приложения Intelligent Kiosk Sample. Приложение можно скачать с github. Следует помнить о необходимости использовать одинаковый ключ Face API для приложения Intelligent Kiosk и приложения робота.
Для большей точности распознавания лиц целесообразно обучить модель на образцах изображения, снятых камерой, которая будет использоваться в дальнейшем (модель будет обучена на изображениях одинакового качества, что улучшит работу интерфейса Face Identification API). Для этого мы реализовали собственную логику, выполнение которой позволяет сохранять изображения с камеры робота. В дальнейшем они будут использоваться для обучения моделей Cognitive Services:
Далее мы запускаем метод HeadTracking, который выполняет функцию отслеживания, выявления и идентификации лиц. Одним словом, этот класс первым определяет, находится ли перед камерой робота лицо. Если да, то соответствующим образом меняется положение головы робота (производится отслеживание лица). Затем будет вызван метод FaceApiCommunicator, который, в свою очередь, вызовет интерфейсы Face API (выявление и идентификация лиц), а также интерфейс Emotion API. В последнем разделе производится обработка результата, полученного от интерфейсов Cognitive Services API.
В случае распознавания лица робот говорит: «Привет!» и добавляет имя человека, кроме случаев, когда робот определяет выражение грусти на его лице (с помощью интерфейса Emotion API). Тогда робот рассказывает забавную шутку. Если идентифицировать человека не удалось, робот просто говорит «привет». При этом он различает мужчин и женщин и выстраивает фразы соответственно. По результатам, полученным от интерфейса Face API, робот также делает предположение относительно возраста человека.
Ниже приводится код FaceApiCommunicator, в котором содержится логика обмена сообщениями с интерфейсами Face API и Emotion API.
Приложение робота поддерживает идентификацию человека не только по изображению лица, но и по голосу. Эти данные отправляются в интерфейс Speaker Recognition API. Вы можете использовать приведенную ссылку для получения дополнительной информации об этом API.
Как и в случае с Face API, службе Speaker Recognition необходима модель распознавания, обученная на голосовой информации из используемых динамиков. Сначала необходимо создать звуковой материал для распознавания в формате wav. Для этого подойдет приведенный ниже код. Создав звуковой материал для распознавания, мы будем использовать в качестве образца это приложение. С его помощью мы создадим профили людей, которых наш робот должен узнавать по голосу.
Следует иметь в виду, что в созданных профилях нет поля имени пользователя. Это значит, что вам нужно сохранить пару созданных значений ProfileId и Name в базе данных. В приложении мы храним эту пару значений в качестве записей в статическом списке:
Таким образом мы можем создать запись в формате .wav и затем отправить ее в службу Speaker Recognition (для регистрации или идентификации людей). Мы создали логику, которая позволяет записывать голосовые данные в файл .wav. Чтобы достичь этого результата из приложения .NET, используем сборку взаимодействия winmm.dll:
Затем мы создадим компонент SpeakerRecognitionCommunicator, отвечающий за связь с интерфейсом Speaker Recognition API:
Наконец, мы интегрировали рассмотренные ранее два функциональных элемента в обработчик ListenButton_Click. По первому щелчку мыши он инициирует запись голосовой информации, а по второму — отправляет запись в службу Speaker Recognition. Еще раз отметим, что робот EZ не оборудован микрофоном, для создания голосовой информации мы используем микрофон, подключенный к компьютеру разработчика (или встроенный микрофон компьютера).
Робот способен на естественном языке описывать то, что он «видит», то есть объекты, попадающие в поле зрения его камеры. Для этого используется интерфейс Computer Vision API. Мы создали вспомогательный метод, отвечающий за связь с Computer Vision API.
Мы задействуем этот метод, если в процессе распознавания команды выяснится, что необходимо использовать ComputerVision.
Робот также использует интерфейс Custom Vision API, который позволяет очень точно распознавать конкретные объекты. Для работы этой службы тоже нужна обученная модель. Это значит, что нам нужно загрузить набор изображений распознаваемых объектов с присвоенными тегами. Мы используем изображения, полученные от камеры робота, чтобы наша модель обучалась на изображениях того же качества, с которым будет работать впоследствии служба распознавания. Custom Vision API обеспечивает веб-интерфейс, через который можно загрузить изображения, присвоить им теги и обучить модель. После создания и обучения модели реализуем CustomVisionCommunicator, с помощью которого подключим нашего робота к опубликованной модели:
В нашем демонстрационном приложении интерфейс Custom Vision API используется в тех сценариях, когда робот пытается отыскать отвертку, или когда мы спрашиваем, не голоден ли он, а робот, в свою очередь, должен понять, предлагаем ли мы ему бутылочку масла или нет. Ниже приводится пример вызова Custom Vision API в сценарии, когда мы предлагаем роботу бутылочку масла:
В этом документе мы описали приложение, с помощью которого робот-гуманоид приобретает когнитивные способности. Реализованные сценарии предназначены для публичной демонстрации возможностей службы Cognitive Services, однако фрагменты этого кода подойдут для любого другого проекта, где целесообразно использовать искусственный интеллект служб Cognitive Services. Код также может пригодиться тем, кто работает с модификацией робота EZ и планирует использовать прилагаемый к нему пакет SDK в сочетании с Cognitive Services.
В процессе разработки мы пришли к нескольким выводам относительно робота EZ и Cognitive Services.
Speech API
Образец Speech Recognition
Language Understanding Intelligent Service (LUIS)
Face API
Emotion API
Speaker Recognition API
Образец распознавания звуковой информации с динамика
Computer Vision API
Custom Vision API
Intelligent Kiosk Sample (приложение UWP с различными демонстрационными сценариями, дополняющими Cognitive Services, например, анализом множества лиц)
EZ Robot SDK
Наиболее реалистичной доработкой является регистрация лиц и (или) людей и ассоциированных с ними голосовых фрагментов, а также вызов функции обучения моделей и их публикации для интерфейсов Face API и Speaker Recognition API непосредственно из приложения. Это обеспечит автономность и независимость работы в приложении-образце, который мы используем для этой цели сейчас.
Службы Cognitive Services также содержат клиентские библиотеки для различных языков программирования, что еще больше упрощает их использование. Мы решили интегрировать эти службы в приложение, созданное для управления роботом JD Humanoid компании EZ (далее в документе мы будем называть его просто «робот EZ»). Мы выбрали именно этого робота-гуманоида, поскольку его довольно просто собрать. Кроме того, к нему прилагаются .NET, UWP SDK и даже Mono SDK, что открывает широкие возможности его реализации с индивидуальными настройками.
В комплекте идет также приложение EZ Builder, которое позволяет управлять роботом EZ и реализовывать конкретные сценарии на основе встроенных функциональных плагинов и блоков Блокли. В основном оно предназначено для образовательных целей, но в нем имеется также функция создания движения (“movement creator”), которая позволяет создавать движения робота и экспортировать их, чтобы использовать в приложениях, созданных с помощью пакета SDK. Безусловно, это приложение — отличая отправная точка для настройки и начала работы с любым роботом EZ.
В основе приложения лежит существующий проект Windows Forms, в котором используются собственные возможности робота EZ и эффективно реализована работа с камерой. Взяв это приложение за основу, мы расширили его и подключили к следующим службам Cognitive Services: Face API, Emotion API, Speech API, Voice Recognition API, Language Understanding Intelligent Service, Speaker Recognition API, Computer Vision API, Custom Vision API. Благодаря этому у робота появились новые возможности:
- Распознавание голосовых команд — помимо кнопок приложения Win Form, которые вызывают определенные действия робота, мы добавили функции распознавания речи и понимания естественного языка, чтобы наш робот EZ понимал произносимые вслух команды.
- Распознавание и идентификация лица — робот EZ способен распознавать лица по нескольким параметрам, а также идентифицировать людей по лицам.
- Распознавание эмоций — при распознавании лиц робот EZ также определяет эмоции.
- Распознавание говорящего — робот EZ способен узнавать людей по голосу.
- Компьютерное зрение — робот EZ также может описывать окружающую обстановку.
- Распознавание объектов по собственным параметрам — робот EZ способен распознавать специфические объекты, помещаемые в область его зрения.
Когнитивные возможности робота демонстрируются в этом видео.
Работа с пакетом SDK робота EZ
Далее в этом документе мы коротко расскажем о том, как работать с пакетом SDK робота EZ, а также детально опишем сценарии реализации с использованием служб Cognitive Services.
Подключение к роботу EZ
Основное предварительное требование для работы с приложением — возможность подключения к роботу из кода нашего приложения, вызов движений и получение входящих изображений с камеры. Приложение выполняется на компьютере разработчика, поскольку робот EZ не имеет собственной среды выполнения и хранения, где можно было бы разместить и запустить приложение.
Таким образом, оно работает на компьютере, который подключается к роботу EZ через сеть WiFi, напрямую через точку доступа, включаемую самим роботом (режим АР), либо через сеть WiFi, созданную другим маршрутизатором (режим клиента). Мы выбрали второй вариант, поскольку он поддерживает подключение к Интернету при разработке и запуске приложения. Сетевые настройки при работе с роботом EZ подробно описаны здесь. При подключении к сети WiFi роботу EZ выделяется IP-адрес, который в дальнейшем используется для соединения с роботом из приложения. При использовании пакета SDK процедура следующая:
using EZ_B;
//Подключение к роботу EZ с помощью SDK
var ezb = new EZB();
this.ezb.Connect("robotIPAddress");Поскольку камера робота EZ является изолированным сетевым устройством, мы должны к ней подключиться для дальнейшего использования.
var camera = new Camera(this.ezb);
this.camera.StartCamera(new ValuePair("EZB://" + "robotIPAddress"), CameraWidth, CameraHeight);В официальной Документации пакета SDK робота EZ приведены подробные примеры вызова специальных функций робота EZ, которые становятся доступными после подключения к нему.
Создание движений робота
Пакет SDK позволяет взаимодействовать с серводвигателем робота и контролировать его движения. Чтобы создать движение, необходимо задать фреймы (конкретные положения) и действия, состоящие из набора таких фреймов. Реализовать это в коде вручную не очень просто, но в приложении EZ Builder можно задавать фреймы, создавать из них действия, а затем экспортировать в код и использовать в приложении. Для этого нам нужно создать новый проект в EZ Builder, добавить плагин Auto Position и нажать кнопку с изображением шестеренки.
Рисунок 1. Плагин Auto Position
В дальнейшем вы сможете создавать новые фреймы на панели Frames, меняя углы серводвигателей робота. Следующий шаг — создание нужных движений из существующих на панели Action фреймов.
Рисунок 2. Фреймы Auto Position
Рисунок 3. Действия Auto Position
Созданное действие можно экспортировать через панель инструментов импорта/экспорта.
Рисунок 4. Экспорт исходного кода плагина Auto Position
Закончив экспорт действия, вы можете скопировать код и вставить его в свое приложение. Если мы будем использовать различные позиции, следует переименовать класс AutoPositions, присвоив ему имя, точно отражающее тип движения. Затем его можно использовать в коде следующим образом:
//Класс WavePositions создан с именем AutoPositions и переименован
private WavePositions wavePosition;
//Обработчик изменения подключения робота EZ
private void EzbOnConnectionChange(bool isConnected)
{
this.ezbConnectionStatusChangedWaitHandle.Set();
if (isConnected)
{
//После подключения к роботу создается экземпляр WavePosition
wavePosition = new WavePositions(ezb);
}
}
//Метод вызова действия Waving
private async void Wave()
{
wavePosition.StartAction_Wave();
//Повтор роботом действия Wave в течение 5 секунд
await Task.Delay(5000);
wavePosition.Stop();
//Перевод робота в исходную позицию
ezb.Servo.ReleaseAllServos();
}Получение изображения с камеры
Поскольку в приложении мы используем изображения с камеры робота в качестве входных данных при вызове служб Cognitive Services, то мы должны найти способ получения этих изображений. Делается это так.
var currentBitmap = camera.GetCurrentBitmap;
MemoryStream memoryStream = new MemoryStream();
currentBitmap.Save(memoryStream, System.Drawing.Imaging.ImageFormat.Jpeg);
memoryStream.Seek(0, SeekOrigin.Begin);
//Получаем из памяти поток данных, который отправляется в Cognitive ServicesГолосовые функции робота
Как уже упоминалось, приложение выполняется на компьютере разработчика и просто отправляет роботу команды. Робот не имеет своей среды выполнения. Если нужно синтезировать речь (проще говоря, вы хотите, чтобы робот произнес пару фраз), то нужно выбрать один из двух вариантов, предлагаемых пакетом SDK. Первый вариант предусматривает использование стандартного аудиоустройства: звук будет воспроизводиться компьютером разработчика, а не динамиком робота. Этот вариант удобен в тех случаях, когда вам нужно, чтобы робот говорил через динамик компьютера, например, во время презентаций. Однако в большинстве случаев желательно, чтобы звук воспроизводился самим роботом. Ниже приводится реализация обоих вариантов вызова звуковой функции с помощью пакета SDK:
//Используется стандартное аудиоустройство на компьютере разработчика
ezb.SpeechSynth.Say("Произносимый текст");
//Синтез речи напрямую через встроенный динамик робота
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream("Произносимый текст"));Интеграция Cognitive Services
В этом разделе мы рассмотрим конкретные сценарии когнитивных функций, реализованных в приложении для управления роботом.
Распознавание голосовых команд
Вы можете приводить робота в действие, подавая голосовые команды через подключенный к компьютеру разработчика микрофон, поскольку у самого робота EZ микрофона нет. Сначала мы использовали пакет SDK робота EZ для распознавания речи. Как выяснилось, распознавание было недостаточно точным, и робот выполнял неправильные действия исходя из неверно понятых команд. Чтобы повысить точность распознавания и свободу действий при подаче команд, мы решили использовать интерфейс Microsoft Speech API, который преобразует речь в текст, а также службу Language Understanding Intelligent Service (LUIS) для распознавания действия, требуемого конкретной командой. Используйте ссылки на эти продукты, чтобы получить дополнительную информацию о них и начать работу.
Сначала следует создать приложение LUIS, в котором к каждой команде привязываются нужные нам действия. Процесс создания приложения LUIS описан в этом руководстве для начала работы. LUIS предлагает вариант работы через веб-интерфейс, где вы можете с легкостью создать приложение и задать нужные действия. Если необходимо, вы также можете создать сущности, которые приложение LUIS будет распознавать по отправляемым в службу командам. Результат экспорта приложения LUIS содержится в этом репозитории в папке LUIS Model.
После подготовки приложения LUIS мы реализуем следующую логику: ожидание голосовых команд, вызов интерфейса Microsoft Speech API, вызов службы распознавания LUIS. В качестве основы для этой функциональности мы использовали следующий образец.
Он содержит логику распознавания длинных и коротких фраз с микрофона или из файла .wav с последующим распознаванием действия службой LUIS или без него.
Мы использовали класс MicrophoneRecognitionClientWithIntent, который содержит функции ожидания команд микрофоном, распознавания речи и требуемого действия. Кроме этого, вызов функции ожидания коротких фраз осуществляется с помощью дескриптора SayCommandButton_Click.
using Microsoft.CognitiveServices.SpeechRecognition;
private void SayCommandButton_Click(object sender, EventArgs e)
{
WriteDebug("---Начало записи через микрофон с распознаванием действия ----");
this.micClient =
SpeechRecognitionServiceFactory.CreateMicrophoneClientWithIntentUsingEndpointUrl(
this.DefaultLocale,
Settings.Instance.SpeechRecognitionApiKey,
Settings.Instance.LuisEndpoint);
this.micClient.AuthenticationUri = "";
//Дескриптор времени распознавания требуемого действия
this.micClient.OnIntent += this.OnIntentHandler;
this.micClient.OnMicrophoneStatus += this.OnMicrophoneStatus;
//Дескрипторы событий для результатов распознавания речи
this.micClient.OnPartialResponseReceived += this.OnPartialResponseReceivedHandler;
this.micClient.OnResponseReceived += this.OnMicShortPhraseResponseReceivedHandler;
this.micClient.OnConversationError += this.OnConversationErrorHandler;
//Запуск распознавания речи через микрофон
this.micClient.StartMicAndRecognition();
}Логика вызова команды использует дескриптор OnIntentHandler — здесь мы анализируем ответ, полученный от службы LUIS.
private async void OnIntentHandler(object sender, SpeechIntentEventArgs e)
{
WriteDebug("---Получение действия обработчиком OnIntentHandler () ---");
dynamic intenIdentificationResult = JObject.Parse(e.Payload);
var res = intenIdentificationResult["topScoringIntent"];
var intent = Convert.ToString(res["intent"]);
switch (intent)
{
case "TrackFace":
{
//Запуск отслеживания и распознавания лиц
ToggleFaceRecognitionEvent?.Invoke(this, null);
break;
}
case "ComputerVision":
{
var currentBitmap = camera.GetCurrentBitmap;
var cvc = new CustomVisionCommunicator(Settings.Instance.PredictionKey, Settings.Instance.VisionApiKey, Settings.Instance.VisionApiProjectId, Settings.Instance.VisionApiIterationId);
var description = await cvc.RecognizeObjectsInImage(currentBitmap);
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream(description));
break;
}
//... прочие действия/Команды
default: break;
}
}Распознавание и идентификация лиц и эмоций
Для реализации функции распознавания лиц и эмоций мы использовали службы Face API и Emotion API. Перейдя по приведенным выше ссылкам, вы сможете узнать больше об этих службах и о начале работы с ними, получить инструкции о создании ключа API и интеграции служб в ваше приложение.
Робот EZ способен самостоятельно распознавать лица, используя пакет SDK. Вызов служб Cognitive Services при этом не требуется. Однако это лишь базовый вид распознавания лиц без дополнительных параметров (например, возраста, пола, растительности на лице и т. п.). Но мы все же воспользуемся этой локальной функцией распознавания: она поможет понять, что на изображении присутствует лицо. После этого мы задействуем Cognitive Services Face API для получения дополнительных параметров лица. Благодаря этому отпадет необходимость в лишних вызовах API.
Функция робота EZ, выполняющая распознавание лиц, также предоставляет сведения о расположении лица на картинке. Мы решили воспользоваться этим, чтобы робот поворачивал голову, и его камера была направлена прямо на лицо. Мы заимствовали этот код из приложения Win Form в качестве основы нашего проекта. При этом мы добавили параметр чувствительности, который определяет скорость движения и корректировки положения головы робота.
Итак, чтобы интерфейс Face API мог идентифицировать конкретных людей, нам нужно создать группу таких людей, зарегистрировать их и обучить модель распознавания. Нам удалось сделать это без лишних усилий с помощью приложения Intelligent Kiosk Sample. Приложение можно скачать с github. Следует помнить о необходимости использовать одинаковый ключ Face API для приложения Intelligent Kiosk и приложения робота.
Для большей точности распознавания лиц целесообразно обучить модель на образцах изображения, снятых камерой, которая будет использоваться в дальнейшем (модель будет обучена на изображениях одинакового качества, что улучшит работу интерфейса Face Identification API). Для этого мы реализовали собственную логику, выполнение которой позволяет сохранять изображения с камеры робота. В дальнейшем они будут использоваться для обучения моделей Cognitive Services:
//Сохранение изображений для обучения набора данных
var currentBitmap = camera.GetCurrentBitmap;
currentBitmap.Save(Guid.NewGuid().ToString() + ".jpg", ImageFormat.Jpeg);Далее мы запускаем метод HeadTracking, который выполняет функцию отслеживания, выявления и идентификации лиц. Одним словом, этот класс первым определяет, находится ли перед камерой робота лицо. Если да, то соответствующим образом меняется положение головы робота (производится отслеживание лица). Затем будет вызван метод FaceApiCommunicator, который, в свою очередь, вызовет интерфейсы Face API (выявление и идентификация лиц), а также интерфейс Emotion API. В последнем разделе производится обработка результата, полученного от интерфейсов Cognitive Services API.
В случае распознавания лица робот говорит: «Привет!» и добавляет имя человека, кроме случаев, когда робот определяет выражение грусти на его лице (с помощью интерфейса Emotion API). Тогда робот рассказывает забавную шутку. Если идентифицировать человека не удалось, робот просто говорит «привет». При этом он различает мужчин и женщин и выстраивает фразы соответственно. По результатам, полученным от интерфейса Face API, робот также делает предположение относительно возраста человека.
private async void HeadTracking()
{
if (!this.headTrackingActive)
{
return;
}
var faceLocations = this.camera.CameraFaceDetection.GetFaceDetection(32, 1000, 1);
if (faceLocations.Length > 0)
{
//Процедура распознавания лица производится только раз в секунду
if (this.fpsCounter == 1)
{
foreach (var objectLocation in faceLocations)
{
this.WriteDebug(string.Format("В H:{0} V:{1} выявлено лицо человека", objectLocation.HorizontalLocation, objectLocation.VerticalLocation));
}
}
}
//Возврат в начало, если лицо не выявлено
if (faceLocations.Length == 0)
{
return;
}
//Регистрация первого положения лица (ТОЛЬКО ОДНО)
var faceLocation = faceLocations.First();
var servoVerticalPosition = this.ezb.Servo.GetServoPosition(HeadServoVerticalPort);
var servoHorizontalPosition = this.ezb.Servo.GetServoPosition(HeadServoHorizontalPort);
//Track face
var yDiff = faceLocation.CenterY - CameraHeight / 2;
if (Math.Abs(yDiff) > YDiffMargin)
{
if (yDiff < -1 * RobotSettings.sensitivity)
{
if (servoVerticalPosition - ServoStepValue >= mapPortToServoLimits[HeadServoVerticalPort].MinPosition)
{
servoVerticalPosition -= ServoStepValue;
}
}
else if (yDiff > RobotSettings.sensitivity)
{
if (servoVerticalPosition + ServoStepValue <= mapPortToServoLimits[HeadServoVerticalPort].MaxPosition)
{
servoVerticalPosition += ServoStepValue;
}
}
}
var xDiff = faceLocation.CenterX - CameraWidth / 2;
if (Math.Abs(xDiff) > XDiffMargin)
{
if (xDiff > RobotSettings.sensitivity)
{
if (servoHorizontalPosition - ServoStepValue >= mapPortToServoLimits[HeadServoHorizontalPort].MinPosition)
{
servoHorizontalPosition -= ServoStepValue;
}
}
else if (xDiff < -1 * RobotSettings.sensitivity)
{
if (servoHorizontalPosition + ServoStepValue <= mapPortToServoLimits[HeadServoHorizontalPort].MaxPosition)
{
servoHorizontalPosition += ServoStepValue;
}
}
}
this.ezb.Servo.SetServoPosition(HeadServoVerticalPort, servoVerticalPosition);
this.ezb.Servo.SetServoPosition(HeadServoHorizontalPort, servoHorizontalPosition);
//Выявление ЛИЦА
//Распознавание лица с помощью API
var currentBitmap = camera.GetCurrentBitmap;
(var faces, var person, var emotions) = await FaceApiCommunicator.DetectAndIdentifyFace(currentBitmap);
//Если лицо выявлено, и робот не подает речевой сигнал
if (person != null && !ezb.SoundV4.IsPlaying)
{
//Если у человека грустное лицо
if (emotions[0].Scores.Sadness > 0.02)
{
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream("У тебя грустный вид, но я попробую тебя развеселить. Расскажу тебе одну шутку! Вот она. Моя собака постоянно гонялась за велосипедистами. Дошло до того, что мне пришлось отобрать у нее байк". ));
//Ждем, пока робот закончит говорить
Thread.Sleep(25000);
}
else
{
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream("Привет" + person.Name));
Wave();
}
}
//Если выявлены лица, но не установлены их владельцы
else if (faces != null && faces.Any() && !ezb.SoundV4.IsPlaying)
{
if (faces[0].FaceAttributes.Gender == "male")
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream("Здравствуйте, незнакомец! На вид вам лет " + faces[0].FaceAttributes.Age));
else
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream("Здравствуйте, незнакомка! На вид вам лет " + faces[0].FaceAttributes.Age));
Wave();
}
}Ниже приводится код FaceApiCommunicator, в котором содержится логика обмена сообщениями с интерфейсами Face API и Emotion API.
using Microsoft.ProjectOxford.Common.Contract;
using Microsoft.ProjectOxford.Emotion;
using Microsoft.ProjectOxford.Face;
using Microsoft.ProjectOxford.Face.Contract;
using System;
using System.Collections.Generic;
using System.Drawing;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace EZFormApplication.CognitiveServicesCommunicators
{
public class FaceApiCommunicator
{
private const string FaceApiEndpoint = "https://westeurope.api.cognitive.microsoft.com/face/v1.0/";
private static List<FaceResult> personResults = new List<FaceResult>();
private static DateTime lastFaceDetectTime = DateTime.MinValue;
public static async Task<(Face[] faces, Person person, Emotion[] emotions)> DetectAndIdentifyFace(Bitmap image)
{
FaceServiceClient fsc = new FaceServiceClient(Settings.Instance.FaceApiKey, FaceApiEndpoint);
EmotionServiceClient esc = new EmotionServiceClient(Settings.Instance.EmotionApiKey);
//Выявление ЛИЦА
//Добавить в качестве параметра интервал между процедурами распознавания
Emotion[] emotions = null;
Person person = null;
Face[] faces = null;
//Распознавание производится один раз в 10 секунд
if (lastFaceDetectTime.AddSeconds(10) < DateTime.Now)
{
lastFaceDetectTime = DateTime.Now;
MemoryStream memoryStream = new MemoryStream();
image.Save(memoryStream, System.Drawing.Imaging.ImageFormat.Jpeg);
//Нужно начать поиск
memoryStream.Seek(0, SeekOrigin.Begin);
faces = await fsc.DetectAsync(memoryStream, true, true, new List<FaceAttributeType>() { FaceAttributeType.Age, FaceAttributeType.Gender });
if (faces.Any())
{
var rec = new Microsoft.ProjectOxford.Common.Rectangle[] { faces.First().FaceRectangle.ToRectangle() };
//Распознавание эмоций
//Нужно начать поиск; из-за проблем параллельного доступа следует создать новый поток данных в памяти
memoryStream = new MemoryStream();
image.Save(memoryStream, System.Drawing.Imaging.ImageFormat.Jpeg);
memoryStream.Seek(0, SeekOrigin.Begin);
//Вызываем Emotion API и включаем информацию для распознавания овала лица,
//поскольку в этом случае вызов проще реализовать — для работы Emotion API не нужно распознавать наличие лица
emotions = await esc.RecognizeAsync(memoryStream, rec);
//Идентификация человека
var groups = await fsc.ListPersonGroupsAsync();
var groupId = groups.First().PersonGroupId;
//Интересует только первый подходящий человек
var identifyResult = await fsc.IdentifyAsync(groupId, new Guid[] { faces.First().FaceId }, 1);
var candidate = identifyResult?.FirstOrDefault()?.Candidates?.FirstOrDefault();
if (candidate != null)
{
person = await fsc.GetPersonAsync(groupId, candidate.PersonId);
}
}
}
return (faces, person, emotions);
}
}
public class FaceResult
{
public string Name { get; set; }
public DateTime IdentifiedAt { get; set; }
}
}Распознавание звука с динамика
Приложение робота поддерживает идентификацию человека не только по изображению лица, но и по голосу. Эти данные отправляются в интерфейс Speaker Recognition API. Вы можете использовать приведенную ссылку для получения дополнительной информации об этом API.
Как и в случае с Face API, службе Speaker Recognition необходима модель распознавания, обученная на голосовой информации из используемых динамиков. Сначала необходимо создать звуковой материал для распознавания в формате wav. Для этого подойдет приведенный ниже код. Создав звуковой материал для распознавания, мы будем использовать в качестве образца это приложение. С его помощью мы создадим профили людей, которых наш робот должен узнавать по голосу.
Следует иметь в виду, что в созданных профилях нет поля имени пользователя. Это значит, что вам нужно сохранить пару созданных значений ProfileId и Name в базе данных. В приложении мы храним эту пару значений в качестве записей в статическом списке:
public static List<Speaker> ListOfSpeakers = new List<Speaker>() { new Speaker() { Name = "Marek", ProfileId = "d64ff595-162e-42ef-9402-9aa0ef72d7fb" } };Таким образом мы можем создать запись в формате .wav и затем отправить ее в службу Speaker Recognition (для регистрации или идентификации людей). Мы создали логику, которая позволяет записывать голосовые данные в файл .wav. Чтобы достичь этого результата из приложения .NET, используем сборку взаимодействия winmm.dll:
class WavRecording
{
[DllImport("winmm.dll", EntryPoint = "mciSendStringA", ExactSpelling = true, CharSet = CharSet.Ansi, SetLastError = true)]
private static extern int Record(string lpstrCommand, string lpstrReturnString, int uReturnLength, int hwndCallback);
public string StartRecording()
{
//MCIErrors — пользовательский перечень ошибок вывода межпрограммного взаимодействия
var result = (MCIErrors)Record("open new Type waveaudio Alias recsound", "", 0, 0);
if (result != MCIErrors.NO_ERROR)
{
return "Error code: " + result.ToString();
}
// Создание специальных настроек вывода в формат .wav для соответствия требованиям службы Speaker Recognition
result = (MCIErrors)Record("set recsound time format ms alignment 2 bitspersample 16 samplespersec 16000 channels 1 bytespersec 88200", "", 0, 0);
if (result != MCIErrors.NO_ERROR)
{
return "Error code: " + result.ToString();
}
result = (MCIErrors)Record("record recsound", "", 0, 0);
if (result != MCIErrors.NO_ERROR)
{
return "Error code: " + result.ToString();
}
return "1";
}
public string StopRecording()
{
var result = (MCIErrors)Record("save recsound result.wav", "", 0, 0);
if (result != MCIErrors.NO_ERROR)
{
return "Error code: " + result.ToString();
}
result = (MCIErrors)Record("close recsound ", "", 0, 0);
if (result != MCIErrors.NO_ERROR)
{
return "Error code: " + result.ToString();
}
return "1";
}
}Затем мы создадим компонент SpeakerRecognitionCommunicator, отвечающий за связь с интерфейсом Speaker Recognition API:
using Microsoft.ProjectOxford.SpeakerRecognition;
using Microsoft.ProjectOxford.SpeakerRecognition.Contract.Identification;
...
class SpeakerRecognitionCommunicator
{
public async Task<IdentificationOperation> RecognizeSpeaker(string recordingFileName)
{
var srsc = new SpeakerIdentificationServiceClient(Settings.Instance.SpeakerRecognitionApiKeyValue);
var profiles = await srsc.GetProfilesAsync();
//Сначала выберем набор профилей, с которыми будет сравниваться голосовая информация
Guid[] testProfileIds = new Guid[profiles.Length];
for (int i = 0; i < testProfileIds.Length; i++)
{
testProfileIds[i] = profiles[i].ProfileId;
}
//IdentifyAsync больше не работает, поэтому нам нужно реализовать механизм запроса результатов
OperationLocation processPollingLocation;
using (Stream audioStream = File.OpenRead(recordingFileName))
{
processPollingLocation = await srsc.IdentifyAsync(audioStream, testProfileIds, true);
}
IdentificationOperation identificationResponse = null;
int numOfRetries = 10;
TimeSpan timeBetweenRetries = TimeSpan.FromSeconds(5.0);
//
while (numOfRetries > 0)
{
await Task.Delay(timeBetweenRetries);
identificationResponse = await srsc.CheckIdentificationStatusAsync(processPollingLocation);
if (identificationResponse.Status == Microsoft.ProjectOxford.SpeakerRecognition.Contract.Identification.Status.Succeeded)
{
break;
}
else if (identificationResponse.Status == Microsoft.ProjectOxford.SpeakerRecognition.Contract.Identification.Status.Failed)
{
throw new IdentificationException(identificationResponse.Message);
}
numOfRetries--;
}
if (numOfRetries <= 0)
{
throw new IdentificationException("Срок операции идентификации истек");
}
return identificationResponse;
}
}Наконец, мы интегрировали рассмотренные ранее два функциональных элемента в обработчик ListenButton_Click. По первому щелчку мыши он инициирует запись голосовой информации, а по второму — отправляет запись в службу Speaker Recognition. Еще раз отметим, что робот EZ не оборудован микрофоном, для создания голосовой информации мы используем микрофон, подключенный к компьютеру разработчика (или встроенный микрофон компьютера).
private async void ListenButton_Click(object sender, EventArgs e)
{
var vr = new WavRecording();
if (!isRecording)
{
var r = vr.StartRecording();
//если успешно
if (r == "1")
{
isRecording = true;
ListenButton.Text = "Прекратить ожидание звуковой информации";
}
else
WriteDebug(r);
}
else
{
var r = vr.StopRecording();
if (r == "1")
try
{
var sr = new SpeakerRecognitionCommunicator();
var identificationResponse = await sr.RecognizeSpeaker("result.wav");
WriteDebug(Идентификация завершена);
wavePosition.StartAction_Wave();
var name = Speakers.ListOfSpeakers.Where(s => s.ProfileId == identificationResponse.ProcessingResult.IdentifiedProfileId.ToString()).First().Name;
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream("Привет " + имя));
await Task.Delay(5000);
wavePosition.Stop();
ezb.Servo.ReleaseAllServos();
}
catch (IdentificationException ex)
{
WriteDebug("Speaker Identification Error: " + ex.Message);
wavePosition.StartAction_Wave();
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream("Привет, незнакомец"));
//Ждем, пока робот закончит говорить
await Task.Delay(5000);
wavePosition.Stop();
ezb.Servo.ReleaseAllServos();
}
catch (Exception ex)
{
WriteDebug("Ошибка: " + сообщение);
}
else
WriteDebug(r);
isRecording = false;
ListenButton.Text = "Распознавание голоса";
}
}Компьютерное зрение
Робот способен на естественном языке описывать то, что он «видит», то есть объекты, попадающие в поле зрения его камеры. Для этого используется интерфейс Computer Vision API. Мы создали вспомогательный метод, отвечающий за связь с Computer Vision API.
using Microsoft.ProjectOxford.Vision;
...
public async Task<string> RecognizeObjectsInImage(Bitmap image)
{
//Используем конечную точку westeurope
var vsc = new VisionServiceClient(visionApiKey, "https://westeurope.api.cognitive.microsoft.com/vision/v1.0");
MemoryStream memoryStream = new MemoryStream();
image.Save(memoryStream, System.Drawing.Imaging.ImageFormat.Jpeg);
memoryStream.Seek(0, SeekOrigin.Begin);
var result = await vsc.AnalyzeImageAsync(memoryStream,new List<VisualFeature>() { VisualFeature.Description });
return result.Description.Captions[0].Text;
}Мы задействуем этот метод, если в процессе распознавания команды выяснится, что необходимо использовать ComputerVision.
case "ComputerVision":
{
var currentBitmap = camera.GetCurrentBitmap;
var cvc = new CustomVisionCommunicator();
var description = await cvc.RecognizeObjectsInImage(currentBitmap);
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream(description));
break;
}Распознавание объектов с пользовательскими параметрами
Робот также использует интерфейс Custom Vision API, который позволяет очень точно распознавать конкретные объекты. Для работы этой службы тоже нужна обученная модель. Это значит, что нам нужно загрузить набор изображений распознаваемых объектов с присвоенными тегами. Мы используем изображения, полученные от камеры робота, чтобы наша модель обучалась на изображениях того же качества, с которым будет работать впоследствии служба распознавания. Custom Vision API обеспечивает веб-интерфейс, через который можно загрузить изображения, присвоить им теги и обучить модель. После создания и обучения модели реализуем CustomVisionCommunicator, с помощью которого подключим нашего робота к опубликованной модели:
using Microsoft.Cognitive.CustomVision;
using Microsoft.Cognitive.CustomVision.Models;
...
class CustomVisionCommunicator
{
private string predictionKey;
private string visionApiKey;
private Guid projectId;
private Guid iterationId;
PredictionEndpoint endpoint;
VisionServiceClient vsc;
public CustomVisionCommunicator()
{
this.visionApiKey = Settings.Instance.VisionApiKey;
this.predictionKey = Settings.Instance.PredictionKey;
this.projectId = new Guid(Settings.Instance.VisionApiProjectId);
//меняется каждый раз при переобучении модели
this.iterationId = new Guid(Settings.Instance.VisionApiIterationId);
PredictionEndpointCredentials predictionEndpointCredentials = new PredictionEndpointCredentials(predictionKey);
//Создаем конечную точку прогнозирования, передаем учетные данные прогнозирования объекта, содержащего полученный ключ предсказания
endpoint = new PredictionEndpoint(predictionEndpointCredentials);
vsc = new VisionServiceClient(visionApiKey, "https://westeurope.api.cognitive.microsoft.com/vision/v1.0");
}
public List<ImageTagPrediction> RecognizeObject(Bitmap image)
{
MemoryStream memoryStream = new MemoryStream();
image.Save(memoryStream, System.Drawing.Imaging.ImageFormat.Jpeg);
//Нужно произвести поиск с начала
memoryStream.Seek(0, SeekOrigin.Begin);
var result = endpoint.PredictImage(projectId, memoryStream,iterationId);
return result.Predictions.ToList();
}
}В нашем демонстрационном приложении интерфейс Custom Vision API используется в тех сценариях, когда робот пытается отыскать отвертку, или когда мы спрашиваем, не голоден ли он, а робот, в свою очередь, должен понять, предлагаем ли мы ему бутылочку масла или нет. Ниже приводится пример вызова Custom Vision API в сценарии, когда мы предлагаем роботу бутылочку масла:
case "Голоден":
{
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream(("Да, я всегда хочу есть! Сейчас бы масла!")));
var currentBitmap = camera.GetCurrentBitmap;
var cvc = new CustomVisionCommunicator();
var predictions = cvc.RecognizeObject(currentBitmap);
if (RecognizeObject("масло"))
{
//Берет бутылку масла и пьет
grabPosition.StartAction_Takefood();
await Task.Delay(1000);
ezb.SoundV4.PlayData(ezb.SpeechSynth.SayToStream(("Вкусное масло")));
}
else
ezb.SpeechSynth.Say("Я не ем это");
break;
}Заключение
В этом документе мы описали приложение, с помощью которого робот-гуманоид приобретает когнитивные способности. Реализованные сценарии предназначены для публичной демонстрации возможностей службы Cognitive Services, однако фрагменты этого кода подойдут для любого другого проекта, где целесообразно использовать искусственный интеллект служб Cognitive Services. Код также может пригодиться тем, кто работает с модификацией робота EZ и планирует использовать прилагаемый к нему пакет SDK в сочетании с Cognitive Services.
Выводы
В процессе разработки мы пришли к нескольким выводам относительно робота EZ и Cognitive Services.
- Модели для Face API или Custom Vision необходимо обучать на изображениях того же качества, которое будет использоваться в дальнейшей работе. Если условия освещения могут измениться и сказаться на качестве изображений, необходимо обучать модели на основе изображений, полученных при разной освещенности. В случае со службой Custom Vision имеет смысл поэкспериментировать с фоном и ориентацией объекта.
- Для работы Speaker Recognition API необходимы голосовые данные в формате .wav с определенными настройками (см. раздел, посвященный службе Speaker Recognition, выше). В профиле нет поля имени, поэтому хранить данные нужно отдельно от приложения.
- Запись в формате .wav производится с помощью файла межпрограммного взаимодействия winmm.dll — мы создали модуль, который позволяет записывать звук и сохранять его в формате .wav. Поиск в интернете показал: это наиболее удобный способ реализации данной функции.
- Длительность вызова службы Speaker Recognition — если набор сравниваемых профилей и звуковых фрагментов достаточно велик, вызов API может занять много времени. Попробуйте ограничить размер набора сравниваемых профилей, если ваш сценарий позволяет это сделать.
- Функция голосового распознавания робота EZ не подходит для распознавания нескольких разных фраз — мы столкнулись с ситуацией, когда робот EZ выполнял действия, основываясь на неверно понятых фразах. Нам удалось решить эту проблему с помощью более совершенного интерфейса Cognitive Service Microsoft Speech API и службы Language Understanding Intelligent Service (LUIS).
- Робот EZ JD не справляется с точным движением вперед и не располагает ультразвуковым датчиком, что ограничило нас в реализации сценария, когда робот подходит к объекту и поднимает его с пола. Однако с учетом цены робота, его возможности для разработки достаточно обширны, а пакет SDK служит отличным дополнением для реализации сложных сценариев использования робота.
Полезные ссылки
Cognitive Services
Speech API
Образец Speech Recognition
Language Understanding Intelligent Service (LUIS)
Face API
Emotion API
Speaker Recognition API
Образец распознавания звуковой информации с динамика
Computer Vision API
Custom Vision API
Intelligent Kiosk Sample (приложение UWP с различными демонстрационными сценариями, дополняющими Cognitive Services, например, анализом множества лиц)
Робот EZ
EZ Robot SDK
Будущие доработки
Наиболее реалистичной доработкой является регистрация лиц и (или) людей и ассоциированных с ними голосовых фрагментов, а также вызов функции обучения моделей и их публикации для интерфейсов Face API и Speaker Recognition API непосредственно из приложения. Это обеспечит автономность и независимость работы в приложении-образце, который мы используем для этой цели сейчас.

BigD
А с кем в MS RU по bot framework можно пообщаться?
sahsAGU Автор
Приветствую. Напишите, пожалуйста, свой вопрос мне в личку.