
В предыдущей статье я описала как создать простую лямбду на Golang, которая принимает на вход простой объект из двух полей и такой же простой объект отдает на выходе. Теперь немного усложним задачу, подсоединив к лямбде в качестве источника данных Kinesis, а результат обработки записей Kinesis мы будем перекидывать в CloudSearch. Никакой особенной логики в лямбде не будет для упрощения: просто примем запросы от Kinesis, залогируем их в CloudWatch, преобразуем и отправим в CloudSearch.
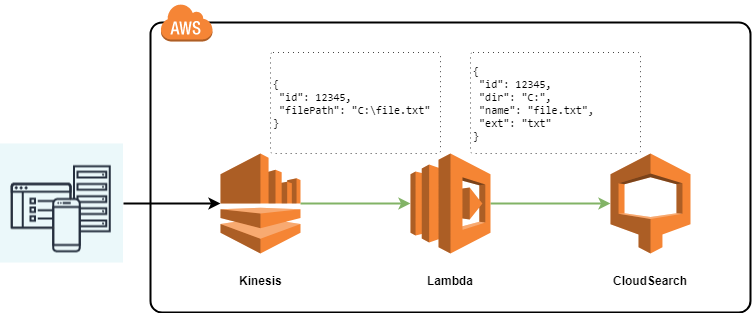
Событие Kinesis, которое мы ожидаем получить в функции выглядит следующим образом:
Здесь нас интересует поле data. Код функции Lambda, которая получает события из Kinesis и логирует данные поля data описан ниже: (Код взят здесь):
Теперь необходимо дополнить код, чтобы записывать измененные данные в CloudSearch
Здесь мы будем формировать полученные данные от Kinesis в наше представление для поискового домена (CloudSearch).
Данные от Kinesis приходят в закодированном base64 виде в поле data. После декодирования данные содержат следующие поля:
В CloudSearch мы отправляем данные следующего вида:
Поле id при этом мы сохраним в идетификаторе документа. С подготовкой данных для загрузки в CloudSearch можно подробно ознакомиться здесь. Если вкратце, то в CloudSearch мы оправляем json следующего вида:
где type — тип запросы, который принимает два значения: add или delete; id — идентификатор документа, а в нашем случае значение, сохраненное в объекте из кинесис в поле Id; fields — пары имя-значения, которые мы сохраняем в поисковом домене, в нашем случае — объект типа CloudSearchDocument.
Код ниже преобразует данные из коллекции Records объекта, пришедшего из Kinesis, в коллекцию данных, готовых для загрузки в CloudSearch:
Следующий код подключается к поисковому домену для загрузки в него подготовленных ранее данных:
Для того, чтобы собрать код, необходимо подгрузить билиотеки aws-sdk-go и aws-lambda-go:
Как собрать и задеплоить лямбду описано в предыдущей статье, здесь только необходимо добавить переменные среды через консоль Лямбда и подготовить новые тестовые данные:
Полный код доступен по ссылке.
Но вначале откроем консоль CloudSearch и создадим поисковый домен. Для домена я буду выбирать самый минимальный инстанс и количество репликаций = 1. Далее необходимо создать поля dir, name, ext. Для данных полей я выберу тип string, но некоторые из них могут иметь и другой тип, например, литеральное поле. Но все зависит от того, как вы будете манипулировать этими полями. Для более подробной информации лучше ознакомиться с документацией Amazon.
Создаем поисковый домен(кнопка Create a new Domain), заполняем имя и выбираем тип инстанса:

Создаем поля:

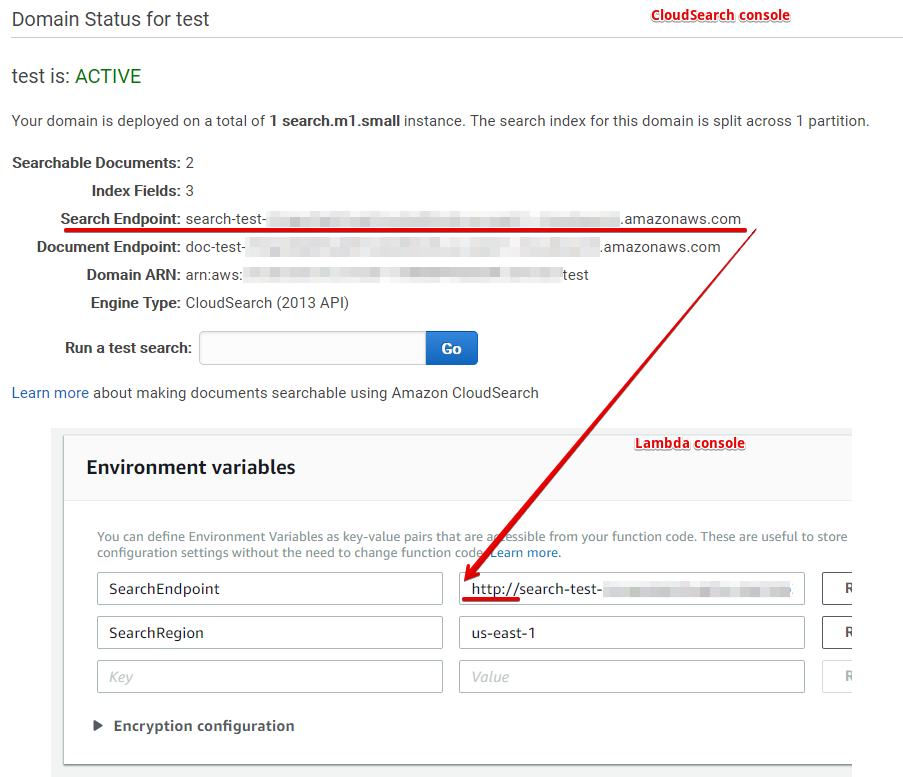
Домен создается около 10 минут, после того, как он станет активным, у вас будет Url поискового домена, который необходимо ввести в переменные среды в консоли Lambda, не забывайте перед Url указывать протокол как на изображении ниже, а также укажите регион, в котором находится поисковый домен:
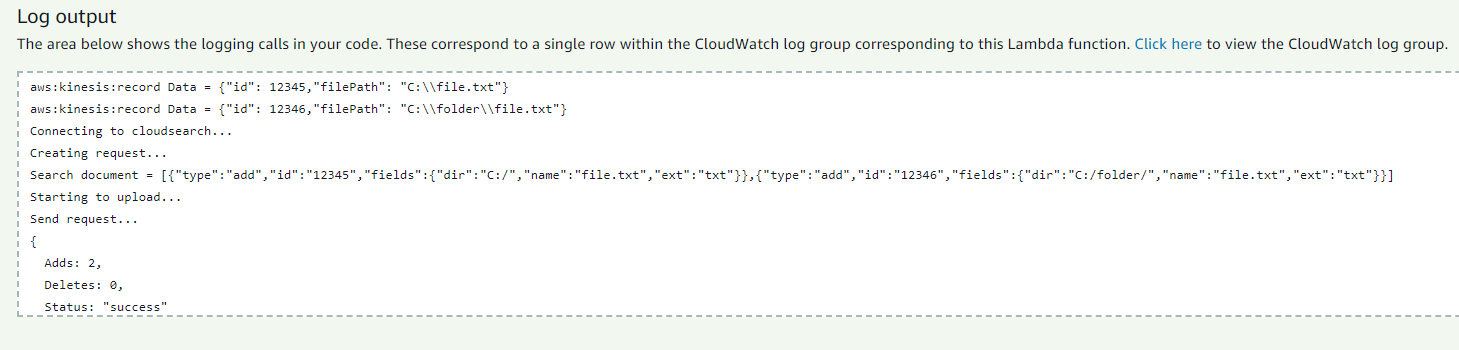
Теперь не забудьте выдать права лямбде через консоль IAM для работы с Kinesis, CloudWatch и CloudSearch. Kinesis можно подключить через консоль Lambda: для этого необходимо выбрать его в блоке Add triggers и заполнить поля, указав существующий в данном регионе стрим, количество записей в батче и позицию в стриме, с которой будет начинаться считывание. Мы можем протестировать работу лямбды, не подключая ее к кинесис, для этого нужно создать тест и добавить в него json следующего вида:
Для генерации других значений поля data можно воспользоваться ссылкой.
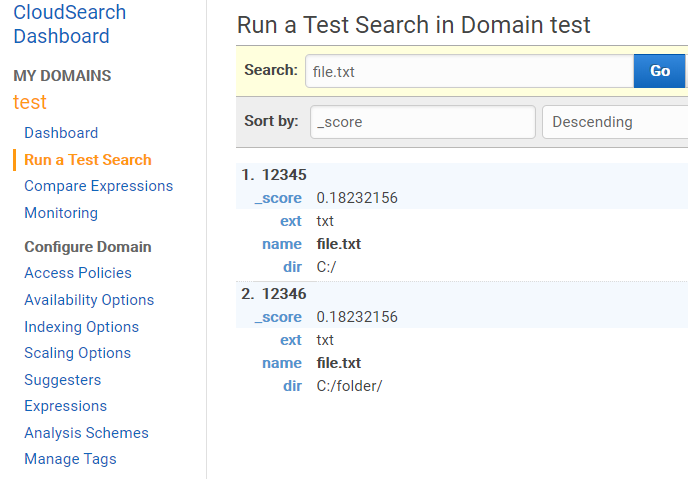
Результат работы также можно посмотреть в поисковом домене:
Дополнительные материалы:
Код поиска документов в поисковом домене на Go.
В следующей статье планируется рассмотрение CloudFormation скрипта для автоматического создания и подключения Lambda, Kinesis, CloudSearch.
Событие Kinesis, которое мы ожидаем получить в функции выглядит следующим образом:
{
"Records": [
{
"awsRegion": "us-east-1",
"eventID": "<event-id>",
"eventName": "aws:kinesis:record",
"eventSource": "aws:kinesis",
"eventSourceARN": "arn:aws:kinesis:us-east-1:<xxxxxxxx>:stream/<stream>",
"eventVersion": "1.0",
"invokeIdentityArn": "arn:aws:iam::<xxxxxx>:role/<role>",
"kinesis": {
"approximateArrivalTimestamp": <timestamp>,
"data": <data>,
"partitionKey": "<partionkey>",
"sequenceNumber": "<sequenceNumber>",
"kinesisSchemaVersion": "1.0"
}
}
]
}Здесь нас интересует поле data. Код функции Lambda, которая получает события из Kinesis и логирует данные поля data описан ниже: (Код взят здесь):
package main
import (
"context"
"fmt"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-lambda-go/lambda"
)
func handler(ctx context.Context, kinesisEvent events.KinesisEvent) error {
for _, record := range kinesisEvent.Records {
kinesisRecord := record.Kinesis
dataBytes := kinesisRecord.Data
dataText := string(dataBytes)
fmt.Printf("%s Data = %s \n", record.EventName, dataText)
}
return nil
}
func main() {
lambda.Start(handler)
}Теперь необходимо дополнить код, чтобы записывать измененные данные в CloudSearch
Здесь мы будем формировать полученные данные от Kinesis в наше представление для поискового домена (CloudSearch).
Данные от Kinesis приходят в закодированном base64 виде в поле data. После декодирования данные содержат следующие поля:
type KinesisEventData struct {
FilePath string `json:"filePath"`
Id int `json:"id"`
}В CloudSearch мы отправляем данные следующего вида:
type CloudSearchDocument struct {
Directory string `json:"dir"`
FileName string `json:"name"`
FileExtension string `json:"ext"`
}Поле id при этом мы сохраним в идетификаторе документа. С подготовкой данных для загрузки в CloudSearch можно подробно ознакомиться здесь. Если вкратце, то в CloudSearch мы оправляем json следующего вида:
[
{"type": "add",
"id": "12345",
"fields": {
"dir": "С:",
"name": "file.txt",
"ext": "txt"
}
}
]где type — тип запросы, который принимает два значения: add или delete; id — идентификатор документа, а в нашем случае значение, сохраненное в объекте из кинесис в поле Id; fields — пары имя-значения, которые мы сохраняем в поисковом домене, в нашем случае — объект типа CloudSearchDocument.
Код ниже преобразует данные из коллекции Records объекта, пришедшего из Kinesis, в коллекцию данных, готовых для загрузки в CloudSearch:
var amasonDocumentsBatch []AmazonDocumentUploadRequest
//Preparing data
for _, record := range kinesisEvent.Records {
kinesisRecord := record.Kinesis
dataBytes := kinesisRecord.Data
fmt.Printf("%s Data = %s \n", record.EventName, string(dataBytes))
//Deserialize data from kinesis to KinesisEventData
var eventData KinesisEventData
err := json.Unmarshal(dataBytes, &eventData)
if err != nil {
return failed(), err
}
//Convert data to CloudSearch format
document := ConvertToCloudSearchDocument(eventData)
request := CreateAmazonDocumentUploadRequest(eventData.Id, document)
amasonDocumentsBatch = append(amasonDocumentsBatch, request)
}
Следующий код подключается к поисковому домену для загрузки в него подготовленных ранее данных:
if len(amasonDocumentsBatch) > 0 {
fmt.Print("Connecting to cloudsearch...\n")
svc := cloudsearchdomain.New(session.New(&aws.Config{
Region: aws.String(os.Getenv("SearchRegion")),
Endpoint: aws.String(os.Getenv("SearchEndpoint")),
MaxRetries: aws.Int(6),
}))
fmt.Print("Creating request...\n")
batch, err := json.Marshal(amasonDocumentsBatch)
if err != nil {
return failed(), err
}
fmt.Printf("Search document = %s \n", batch)
params := &cloudsearchdomain.UploadDocumentsInput{
ContentType: aws.String("application/json"),
Documents: strings.NewReader(string(batch)),
}
fmt.Print("Starting to upload...\n")
req, resp := svc.UploadDocumentsRequest(params)
fmt.Print("Send request...\n")
err = req.Send()
if err != nil {
return failed(), err
}
fmt.Println(resp)
}
Для того, чтобы собрать код, необходимо подгрузить билиотеки aws-sdk-go и aws-lambda-go:
go get -u github.com/aws/aws-lambda-go/cmd/build-lambda-zip
go get -d github.com/aws/aws-sdk-go/Как собрать и задеплоить лямбду описано в предыдущей статье, здесь только необходимо добавить переменные среды через консоль Лямбда и подготовить новые тестовые данные:
os.Getenv("SearchRegion")
os.Getenv("SearchEndpoint")
Полный код доступен по ссылке.
Но вначале откроем консоль CloudSearch и создадим поисковый домен. Для домена я буду выбирать самый минимальный инстанс и количество репликаций = 1. Далее необходимо создать поля dir, name, ext. Для данных полей я выберу тип string, но некоторые из них могут иметь и другой тип, например, литеральное поле. Но все зависит от того, как вы будете манипулировать этими полями. Для более подробной информации лучше ознакомиться с документацией Amazon.
Создаем поисковый домен(кнопка Create a new Domain), заполняем имя и выбираем тип инстанса:
Создаем поля:
Домен создается около 10 минут, после того, как он станет активным, у вас будет Url поискового домена, который необходимо ввести в переменные среды в консоли Lambda, не забывайте перед Url указывать протокол как на изображении ниже, а также укажите регион, в котором находится поисковый домен:
Теперь не забудьте выдать права лямбде через консоль IAM для работы с Kinesis, CloudWatch и CloudSearch. Kinesis можно подключить через консоль Lambda: для этого необходимо выбрать его в блоке Add triggers и заполнить поля, указав существующий в данном регионе стрим, количество записей в батче и позицию в стриме, с которой будет начинаться считывание. Мы можем протестировать работу лямбды, не подключая ее к кинесис, для этого нужно создать тест и добавить в него json следующего вида:
{
"Records": [
{
"awsRegion": "us-east-1",
"eventID": "shardId-000000000001:1",
"eventName": "aws:kinesis:record",
"eventSource": "aws:kinesis",
"eventSourceARN": "arn:aws:kinesis:us-east-1:xxx",
"eventVersion": "1.0",
"invokeIdentityArn": "arn:aws:iam::xxx",
"kinesis": {
"approximateArrivalTimestamp": 1522222222.06,
"data": "eyJpZCI6IDEyMzQ1LCJmaWxlUGF0aCI6ICJDOlxcZmlsZS50eHQifQ==",
"partitionKey": "key",
"sequenceNumber": "1",
"kinesisSchemaVersion": "1.0"
}
},
{
"awsRegion": "us-east-1",
"eventID": "shardId-000000000001:1",
"eventName": "aws:kinesis:record",
"eventSource": "aws:kinesis",
"eventSourceARN": "arn:aws:kinesis:us-east-1:xxx",
"eventVersion": "1.0",
"invokeIdentityArn": "arn:aws:iam::xxx",
"kinesis": {
"approximateArrivalTimestamp": 1522222222.06,
"data": "eyJpZCI6IDEyMzQ2LCJmaWxlUGF0aCI6ICJDOlxcZm9sZGVyXFxmaWxlLnR4dCJ9",
"partitionKey": "key",
"sequenceNumber": "2",
"kinesisSchemaVersion": "1.0"
}
}
]
}Для генерации других значений поля data можно воспользоваться ссылкой.
Результат работы также можно посмотреть в поисковом домене:
Дополнительные материалы:
Код поиска документов в поисковом домене на Go.
В следующей статье планируется рассмотрение CloudFormation скрипта для автоматического создания и подключения Lambda, Kinesis, CloudSearch.
random1st
Два момента. Ни один вменяемый человек не будет такие вещи руками в консоли делать — это только как вариант потестировать. Кстати, я рекомендую Terraform как альтернативу громоздкому и малофункциональному Cloudformation. И второй — CloudSearch вообще мертворожденный сервис, дорогой и неудобный в использовании. Уж лучше ElasticSearch использовать. Вообще выглядит охренеть как вырванным из контекста — ни зачем, ни почему.
GolovinskayaAlbina Автор
CloudSearch неудобный в использовании — давайте здесь конкретику: почему он неудобен. Я имею опыт работы и с первым сервисом и со вторым — ElasticSearch. Второй мы используем для логирования, потому что здесь он и правда оказывается очень удобным в первую очередь возможностями работы с такого типа разнообразными данными, как логи.
GolovinskayaAlbina Автор
Теперь про Terraform — да, альтернатива, но если в вашем стеке горячие решения от амазон, то он не подходит. В нем не поддерживаются некоторые амазоновские сервисы
random1st
Terraform — это не альтернатива, это единственный нормальный вариант. Когда получится тысяч 50 так строк Cloudformation с кучей nested stacks, поймете, о чем я говорю. К тому же ни один вменяемый архитектор не будет в продакшен решениях использовать так называемые «горячие решения» от Амазона. Lambda до приличного состояния допилили за два года, ECS так и не взлетел, CloudSearch дружно игнорируется, Data Pipeline крив до безобразия, Beanstalk хорош только на этапе бутстрапа и типовых решений, дальше замучаешься наступать на грабли и т.п. Что касается клаудсерча — да он банально меньше возможностей предоставляет, чем elasticsearch, единственная причина, по которой я получил в нем экпириенс — я работал с ним еще до релиза AWS ElasticSearch.