
Прежде всего, мотороллер не мой. Описанная в статье схема была опубликована Кэролайн Колийн и Джованни Плацоттой (C. Colijn, G. Plazzotta) в Systematic Biology. Но так как большая часть хабра вряд ли читает английские биологические журналы, я решил, что стоит кусок оттуда перевести.
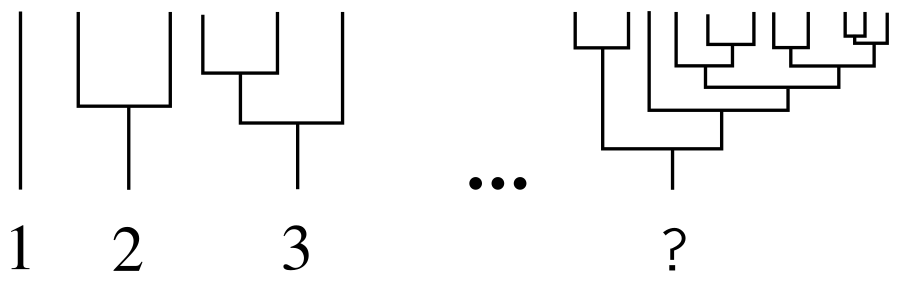
Предположим, что у нас уже есть некая схема нумерации, причём нумерация начинается с простейшего дерева, состоящего из одного листа. Назовём дерево, состоящее из двух поддеревьев с номерами k и j такими, что k >= j, (k, j)-деревом. Множество (k, j)-деревьев упорядочим лексикографически: (1), (1, 1), (2, 1), (2, 2), (3, 1), (3, 2)… Искомым номером как раз и будет место дерева в такой последовательности. То есть (1, 1)-дерево – это то же самое, что дерево № 2, (2, 1)-дерево – то же самое, что дерево № 3 и так далее. Можно проверить: на КДПВ так оно и есть.
Для перевода (k, j)-нотации в номера надо обратить внимание на то, что это по сути последовательность всех возможных пар натуральных чисел. Так как k >= j >= 1 по определению, то существует ровно k (k, j)-пар, от (k, 1) до (k, k), для любого k. Следовательно, (k, 1)-пара имеет номер (1+2+3+…+k-1) + 1, потому что ей предшествует (1 + 2 + 3 + … + k-1) пар. И, разумеется, номер (k, j)-пары больше номера (k, 1)-пары на (j-1). Подставив формулу для суммы арифметической прогрессии и сократив лишние единицы, мы приходим к следующей формуле:
Лишняя единица объясняется тем, что последовательность начинается не с (1, 1)-, а с (1)-дерева. Теперь номер любого произвольного дерева можно вычислить рекурсивным образом. Целевое дерево является по определению (k, j)-деревом, где k и j – поддеревья, растущие из его корня. k-дерево, в свою очередь, является (k1, k2)-деревом, где k1 и k2 – его поддеревья, и так далее до листьев, являющихся (1)-деревьями. Например:
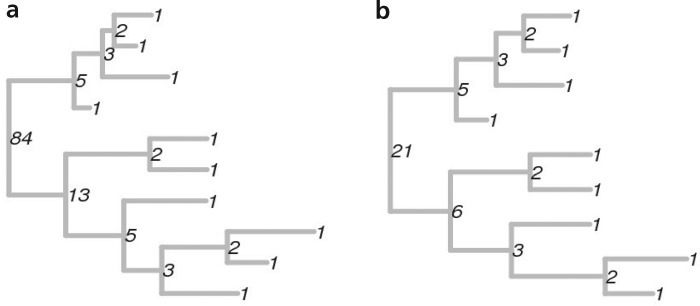
Из такого способа вычисления номера следует и практический смысл всей затеи. Собственно номера – прикольная штука, но не очень понятно, что с ней дальше делать. Разве что полюбоваться тем, как огромное число заняло всю вашу оперативку и хочет ещё (на практике: разметка примерно десятка деревьев с 500 листьями не влазит в 64 Гб даже с использованием gmpy2). Они слишком сильно варьируют даже с небольшими изменениями деревьев; два дерева на картинке выше, например, отличаются только тем, что в правом отсутствует один лист в самом низу. Но каждому дереву соответствует ещё и вектор номеров всех его внутренних узлов. А на векторах уже можно определить метрику дистанций (например, евклидову) и использовать её для кластеризации топологий деревьев. В оригинальной статье деревья были филогенетические и удалось выявить различия в эволюции вируса гриппа в США и тропиках. В тропиках заболевание встречается круглый год, поэтому наблюдаются все промежуточные формы (масса (k, 1)-поддеревьев справа). А вот в Америке грипп – дело сезонное и преимущественно заносится из-за границы, поэтому таких деревьев практически нет.
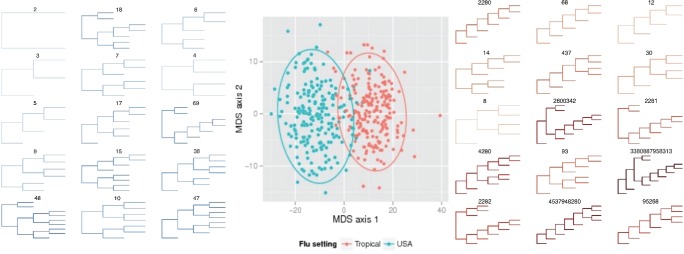
В оригинальной статье ещё есть масса интересного: в частности, генерализация для не-двоичных деревьев, разные практически полезные варианты метрик дистанции, доказательство того, что это действительно метрики в строгом смысле, определение математических операций над деревьями и прочее такое. Если вдруг захочется поиграться, то авторский код на R и моя имплементация на питоне доступны на гитхабе. И то и другое, правда, рассчитано на филогенетические деревья.
Комментарии (15)

KennyGin
12.04.2018 13:40По-моему, получилась хорошая учебная задачка для студентов-программистов. Тут вам и рекурсия, и деревья, и приложение к реальным проблемам из биологии.
Скажем, на том же Haskell можно сделать совсем коротко.
import Data.Tree n = Node "Node" a = n [n [n [n [n [], n []], n []], n []], n [n [n [], n []], n [n [], n [n [n [], n []], n []]]]] b = n [n [n [n [n [], n []], n []], n []], n [n [n [], n []], n [n [], n [n [], n []]]]] num :: Tree t -> Int num (Node _ []) = 1 num (Node _ [t1, t2]) = k * (k - 1) `div` 2 + j + 1 where (k, j) = if n1 > n2 then (n1, n2) else (n2, n1) (n1, n2) = (num t1, num t2)
Как и можно ожидать, 'num a' возвращает 84, 'num b' возвращает 21.

dmagin
13.04.2018 17:56Я что-то не понял — каким образом нумерация деревьев помогает решить задачу их кластеризации? Как будто бы это две совершенно разных задачи, нет?
Для кластеризации вроде как нужно задать метрику между деревьями, то есть определить функцию похожести деревьев, так? На рисунке два похожих дерева, но у одного номер 84, у другого — 21. Ну и как определить расстояние между ними?
А на векторах уже можно определить метрику дистанций (например, евклидову)
Как конкретно метрика определяется, поясните, пожалуйста.
synedra Автор
14.04.2018 05:11На картинке в левом дереве 3 узла№2, 2 узла №3 и 2 узла №5, а в правом 3 узла№2, 2 узла №3 и 1 узел №5 (и сколько-то других узлов, но смотрим для примера на эти). За счёт этого топологии можно представить в виде векторов `(3, 2, 2)` и `(3, 2, 1)` и между ними уже считать евклидову дистанцию.
dmagin
14.04.2018 09:33Да, спасибо, стало понятнее. Сверткой по номерам поддеревьев получаем вектор дерева. Но отражает ли норма разности таких векторов различие деревьев остаётся под вопросом ввиду нестабильности нумерации. Когда малое изменение дерева (добавление ветки) приводит к большим изменениям номеров веток.
Кажется, что можно найти более адекватные метрики.
Sinatr
synedra Автор
Не компактнее, по крайней мере для относительно больших деревьев. Стандартный формат записи деревьев в бионформатике примерно такой:
(((А, B), (C, D)), E). Буквы — имена листьев, скобки объединяют соседние узлы. Могут быть ещё всякие приблуды для информации о внутренних узлах, но в простейшем случае так. Для данного дерева размер записи 21 символ, считая пробелы. Это, если я ничего не напутал, №8. Три бита. So far, so good. Но размер записи растёт примерно линейно от числа листьев, а номера во всяком случае не медленнее чисел Каталана, то есть сильно хуже, чем квадратично. На практике полный вектор номеров узлов для дерева после десятка листьев весит сильно больше, чем его запись в стандартной нотации.К тому же такое хранение будет некорректно. С точки зрения номеров
((A, B), C) = (A, (B,C)) = 3, а с точки зрения эволюционной информации в дереве это могут быть сильно разные штуки. Но это я со своей колокольни, конечно. Если кому-то надо хранить десятки тысяч топологий деревьев размером в десятки листьев, то может быть и выгода в хранении.arandomic
Тут двоичные деревья
Их хранят в массивах
Если именно топологию дерева кодировать (без payload в узлах), то достаточно по биту на каждый возможный узел/лист: 2^2^N (Где N — глубина дерева)
Завершающие нули можно отбросить.
synedra Автор
Не уверен, что представляю описываемый вами формат хранения. Можете чуть подробнее рассказать или там ссылку кинуть?
arandomic
Ошибся в расчетах.
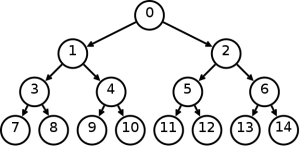
Просто в голове засели сбалансированные бинарные деревья
Есть способ хранения бинарных деревьев в массиве:
Хранится как:
Для отображения только топологии этот массив можно представить в виде бинарного вектора. (1 — есть узел, 0 — нет узла)
Но для разреженных деревьев будет дико неэффективно.
synedra Автор
В общем случае у (несбалансированного) дерева тогда будет несколько представлений, верно? Но каждое представление будет соответствовать только одному дереву, так что почему бы и нет. Можно в принципе придумать алгоритм, считающий для произвольной топологии наиболее короткое представление.
Эффективность будет сильно зависеть от сбалансированности дерева, в особенности количества (k, 1)-поддеревьев. Для каждого из них в правой части создаётся всегда столько же нулей, сколько узлов в k, минус 1. Любые (k,j)-поддеревья будут содержать в правой части меньше нулей, чем (k, 1), и тем меньше, чем k ближе к j. Размер представления получается где-то между 2n-1 и 2^n от числа листьев. Это без удаления завершающих нулей и ещё каких-нибудь оптимизаций.
arandomic
Это в смысле деревья:
и
равны?
Или я чего-то не понял?
Я как раз рассмотрел только простые оптимизации — удаление завершающих нулей и первой единицы.
synedra Автор
Да, равны. Как и 0-1-2-3-4-5-7-8-11-12-13-14, например. Очевидно, оптимальная запись с точки зрения завершающих нулей вторая в вашем комментарии.
Deosis
То есть, если я поменяю в корне правого и левого детей местами, то для вас дерево не изменится?
arandomic
Ну, если мы хотим отбросить информацию о хиральности, то достаточно все деревья сортировать слева направо — это минимизирует запись, да.
Я бы сказал максимально минимизирует — достаточно запомнить номер разряда, где кончаются единицы и начинаются нули.
Но в большинстве случаев насколько я знаю, эта информация имеет значение…
synedra Автор
Для большинства приложений (индексация данных, например) имеет. Но применительно к конкретно филогенетическим деревьям даже положение корня не всегда имеет значение, то есть деревья
((A, B), (C, D))и((C, (A, B)), D)часто считаются эквивалентными. Посмотрите, например, на КДПВ моего прошлого поста, там корня вообще нету. Зато очень важна информация, содержащаяся в листьях.