

Пройдя длинный путь системного администрирования Linux-серверов, в качестве базовых инструментов для сбора статистики и мониторинга мы успели попробовать разные варианты реализации. Самописные скрипты (и даже веб-приложения), Cacti, Zabbix — наиболее устоявшиеся у нас в то или иное время опции, на смену которым в последние годы пришли Okmeter и Prometheus. В этой статье мы собрали и объединили: а) впечатления Okmeter по сотрудничеству с нами, б) обратную связь от тимлидов и инженеров компании «Флант» по использованию Okmeter в многочисленных и разнообразных обслуживаемых нами проектов (от малых до крупных, от достаточно тривиальных инсталляций веб-хостинга до кластеров Kubernetes).
Почему вообще Okmeter?
Выбор стороннего решения — Okmeter — вместо привычных нам self-hosted-инсталляций Zabbix, дополняемых централизованным мониторингом специфических сервисов (корректного функционирования веб-приложений, выполнения бэкапов, работоспособности cron-заданий…), случился далеко не сразу. Для того, чтобы мы согласились «отдать в чужие руки» столь важную часть процесса эксплуатации — сбор статистики и уведомления основной части мониторинга, — пришлось съесть немало кактусов. Однако накопленные колючки привели к пониманию, что для полноценного закрытия этого вопроса есть два пути: или делать свою разработку, или довериться готовому решению, которым, к нашему искреннему сожалению, оказывается вовсе не Open Source-продукт и к которому выдвигаются действительно серьёзные требования (как минимум, от его качества зависят штрафные санкции, зафиксированные в SLA, а как максимум — уровень нашего сервиса и репутация в целом).
Несмотря на то, что у нас есть небольшой отдел системной разработки, создавать своё в масштабах полноценной системы мониторинга (и поддерживать её в актуальном состоянии) — это не наша приоритетная деятельность (если говорить попросту, то долго и дорого). Поэтому год назад был выбран второй путь, и о принятом решении мы не сожалеем. Почему конкретно Okmeter? Тут нет простого ответа, но если говорить в целом, то нам понравились предоставляемые возможности и уровень надёжности, адекватные финансовые условия и перспективы сотрудничества (в частности — возможность доделок по нашим запросам).
Чем этот выбор помог на практике? Если людей принято встречать по одежке, то свои инструменты админы встречают по удобству конфигурации и дальнейшего обслуживания. И в случае с Okmeter наши инженеры описывают это так:
«Метрики (и графики) реально просто добавляются — достаточно подготовить JSON для Okmeter. Упрощение жизни в том, что мы перестали ставить и обслуживать Zabbix, мы не тратим время на его настройку, мы забыли про то, что какие-то графики перестали рисоваться вдруг (хотя чаще в этом были виноваты кривые руки). Базовые алерты автоматически добавляются, когда софт обнаруживается — это очень удобно, не забываешь добавить мониторинг».
«В Zabbix приходилось самому прикручивать шаблоны, собирать с разных шаблонов то, что реально нужно, а тут — оп! — и сразу рисуется».
«К счастью, одну инсталляцию Okmeter можно подключить к любой базе в проекте. Я даже RDS в AWS туда воткнул».
«Для нас и для клиентов очень показательны и часто используются метрики баз данных и nginx. Это у нас прям must have. Потому что в Zabbix’е фиг такое нарисуешь».
Взаимодействие
Несмотря на всю важность этих технических удобств, они не были единственным определяющим фактором. Принципиальную значимость нашему сотрудничество принесли возможности взаимовыгодного обмена результатами профильной деятельности.
Со стороны «Фланта» это выглядит так:
- В каком-то из проектов случилась нестандартная проблема.
- Мы её не смогли идентифицировать или (достаточно исчерпывающе/системно) понять на основе данных графиков.
- Проанализировали, какие дополнительные возможности мониторинга (какие данные, откуда, в каком виде) помогли бы улучшить ситуацию (т.е. наши действия и понимание) в следующий раз, и передали эти сведения в Okmeter.
- Получили улучшения, которые распространились на все наши проекты.
События разворачивались подобным образом уже не один раз и позволили внести дополнения в мониторинг работы таких служб, как, например, Sphinx, php-fpm, Postfix…
Случались и другие сценарии взаимодействия — например, по наводке наших инженеров некоторые триггеры для MySQL доказали свою бесполезность, а также были найдены и исправлены десятки багов в плагинах для той же MySQL, Linux cgroups и других.
Всё это несёт очевидную пользу и для Okmeter: разработчики сервиса активно наращивают свою базу знаний и благодаря большому количеству разных клиентов, и благодаря консультациям по специфическим вопросам. Но вернёмся к технической стороне: как конкретно мы используем Okmeter и что особенно ценим?
Эксплуатация
1. Общая диагностика
Первое и самое очевидное применение — ежедневное обслуживание Linux-серверов, для чего мы особенно активно используем такие возможности, как:
- графики нагрузки на системные ресурсы (процессор, диск, память) по процессам, а также топ по запросам (последнее очень актуально для расследований аварий постфактум — хорошо видно, например, что какой-то процесс съел всю память час назад);
- графики nginx, графики времени ответа сервера, графики запросов на разные URL’ы (группируются без GET-параметров);
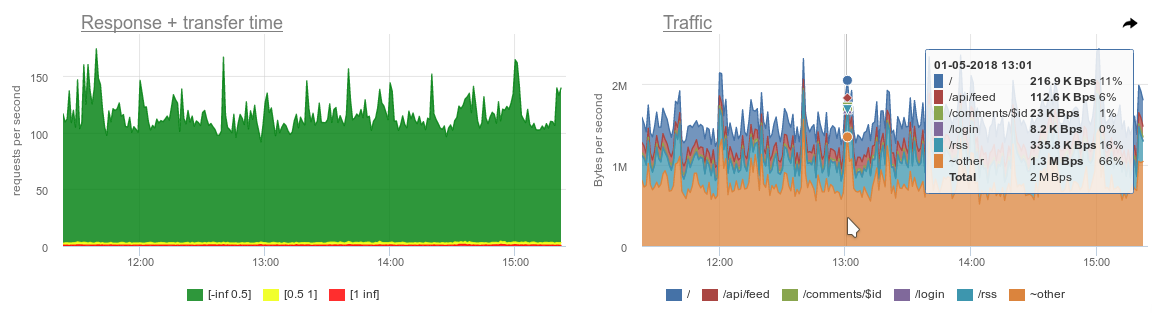
- статистика коннектов по портам и адресам;
- топ запросов в БД, который, как выразился один наш инженер, «божественнен».
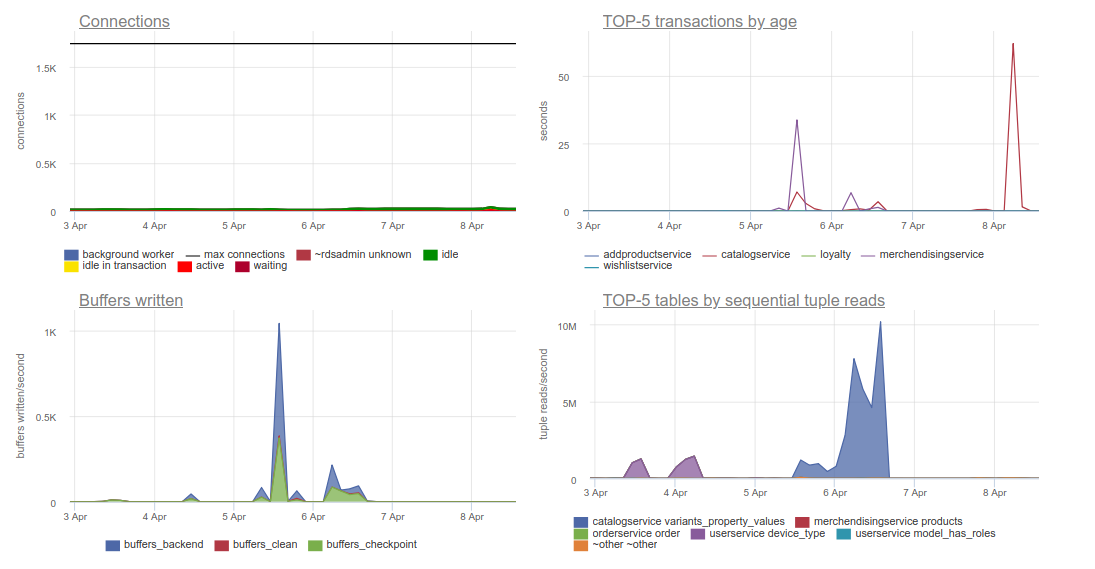
Всплеск по age (продолжительности транзакции) на графике справа наверху — следствие восстановления БД без индекса
2. Аудит
Другой частый случай применения Okmeter у нас — это аудит новых проектов. Ещё не начав обслуживание и лишь подписав предварительный NDA, мы выдаём клиенту команду для выполнения на всех серверах. Результат — мы видим множество метрик, полученных с помощью автоматического обнаружения сервисов.
Таким образом, статистика быстро добавляется даже на большое количество серверов, а получаемые стандартные графики позволяют сразу увидеть ряд показателей, помогающих понять состояние инфраструктуры и сформировать первые цели по её оптимизации/развитию:
- какие процессы есть на серверах и сколько потребляют ресурсов;
- нагрузки на СУБД и веб-сервер;
- размеры БД (актуально для Elasticsearch);
- … и т.п.
3. Контейнеры
В контексте специфики эксплуатации кластеров Kubernetes у Okmeter пока не так много всего. Тем не менее, графики потребления ресурсов с разбивкой по контейнерам (или подам Kubernetes) — уже привычный нам must have, особенно актуальный из-за проблемного вывода
docker stats в случаях большого числа контейнеров, развёрнутых в K8s.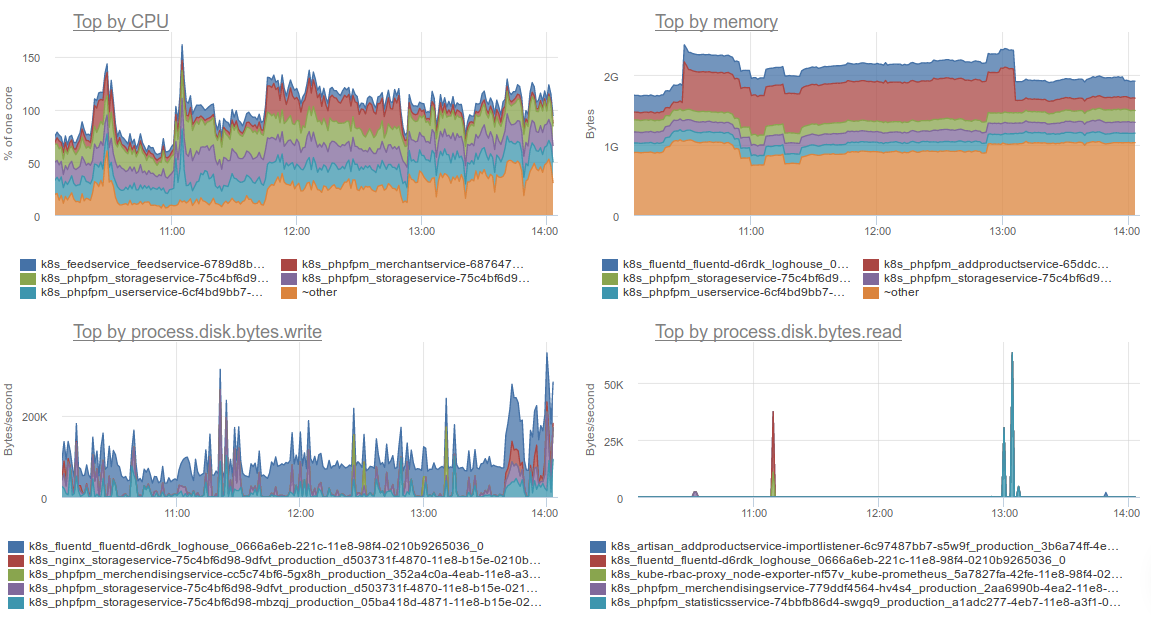
а) Потребление ресурсов с разбивкой по контейнерам
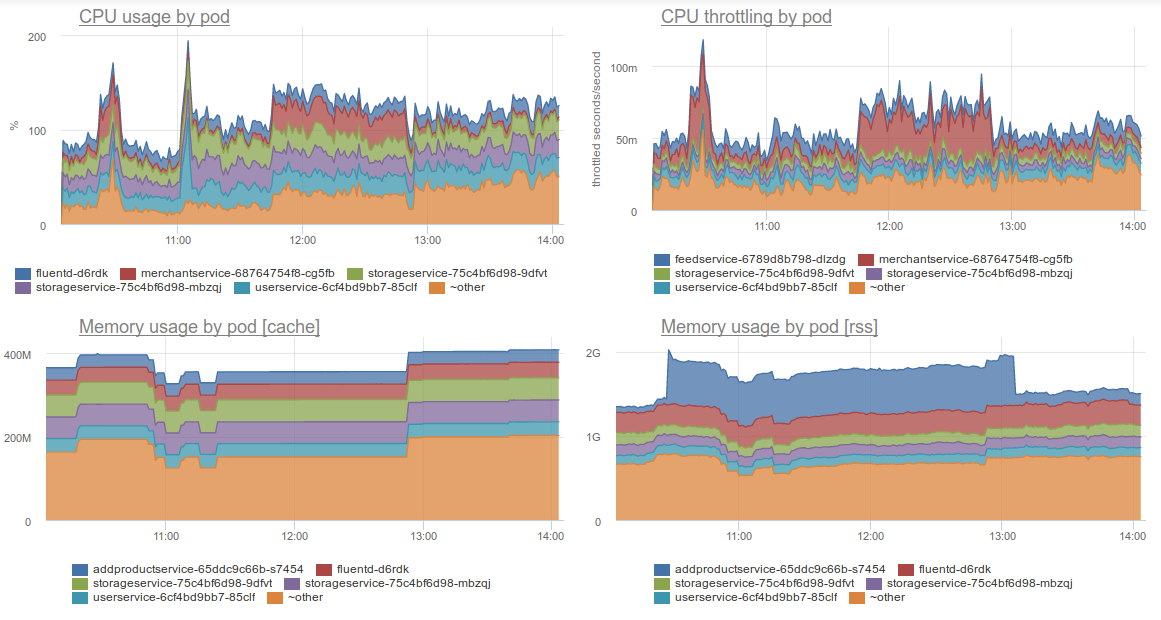
б) Потребление ресурсов с разбивкой по подам
Полноценная же поддержка Kubernetes только начала появляться, поэтому для мониторинга специфичных для K8s показателей мы сейчас больше используем Prometheus. Но известно и о перспективах Okmeter в этом направлении…
Okmeter и Kubernetes
Рассказывая о взаимодействии «Фланта» и Okmeter в целом (см. выше), мы умышленно опустили одну конкретную и наиболее интенсивную область совместных интересов — Kubernetes. Инженеры Okmeter используют наши знания и опыт по Kubernetes для разработки мониторинга K8s в своём сервисе.
В первую очередь это «живые» клиенты, то есть используемые в production кластеры с K8s. Каждая такая инсталляция — полезный источник данных для Okmeter, позволяющий видеть, как функционирует Kubernetes в реальной жизни, какова специфика и проблемы его применения, что по-настоящему важно его пользователям.
Во-вторых, мы (по мере возникновения таких обращений) рассказываем о том, как вообще устроен Kubernetes, как он развёрнут у конкретных пользователей, а также — «как это взрывается» (какие бывают проблемы и на что смотреть в первую очередь).
Всё это позволило Okmeter не только улучшить свои познания в Kubernetes, но и убедиться в перспективности этой системы на рынке в целом. Наличие экспертов «в шаговой доступности» также привело к скорому внедрению K8s для собственных нужд, что соответствует применяемому в компании подходу dogfooding, а также дополнительно способствовало работе над поддержкой Kubernetes в самом сервисе.
Что обещают в этой самой поддержке?
- Распределение ресурсов кластера между запущенными в K8s сервисами. Все метрики можно будет смотреть в разрезе любых сущностей K8s: от Deployment до конкретного контейнера в конкретном поде.
- Автоматические триггеры на исчерпание сервисом лимита ресурсов.
- Проблемы в работе сервисов: перезапуски контейнеров, невозможность запустить нужное количество экземпляров и т.д.
- Capacity planning: сколько ресурсов уже «забронировано», сколько — осталось.
- Состояние компонентов K8s: etcd, dns, apiserver и т.д.
Основная идея — это постоянный аудит базовых настроек Kubernetes, созданный на основе рекомендаций инженеров «Фланта». И будет, конечно, деплой агента Okmeter в виде DaemonSet.
Описанные фичи уже начинают появляться в режиме бета-тестирования (за подробностями лучше обращаться к NikolaySivko), а их полноценный релиз ожидается к сентябрю.
Итоги
Имеющиеся результаты сотрудничества Okmeter и «Флант» — симбиоз и синергия: мы получили готовый инструмент, который играет важную роль в нашей деятельности (но не является достаточно рациональным для внутренней разработки), с возможностью его улучшения по возникающим потребностям, а сервис — обширную почву для пополнения своих знаний и профессиональную помощь по специфичным техническим вопросам. При этом на протяжении сотрудничества прослеживается тренд в эксплуатации от «обычных» проектов к кластерам Kubernetes, и развитие Okmeter в соответствующем направлении.
P.S.
Читайте также в нашем блоге:
- «Устройство и механизм работы Prometheus Operator в Kubernetes»;
- «Мониторинг с Prometheus в Kubernetes за 15 минут»;
- «10 очевидных шагов для подготовки инфраструктуры интернет-магазина к Чёрной пятнице»;
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- «Инфраструктура с Kubernetes как доступная услуга».
Комментарии (4)

Gasoid
15.05.2018 17:55+1А почему не Datadog?
- дешевле
- больше функций, интеграций
shurup Автор
16.05.2018 22:42Есть две стороны этого вопроса:
Во-первых, чисто технический. У Datadog нет такой автоматизации, как у Okmeter, чтобы все сервисы находились и мониторились «сами», без необходимости дополнительно настраивать/допиливать мониторинг. Детализация тоже проигрывает: если у Datadog сотни метрик с одной машины, то у Okmeter — тысячи. А это бывает критично для поиска источника проблем в случае их возникновения (необычных, конечно же).
Во-вторых, о том самом взаимодействии. Ребят из Okmeter мы лично знали, общались, видели общие взгляды на многие вопросы, быстро сошлись на взаимном желании помогать друг другу (для конечной пользы всем). Возможно, что и с другими сервисами удалось бы достичь чего-то подобного, но в случае масштабов Datadog это точно было бы на порядок сложнее, да и вероятности успеха (не только первой договорённости, но и быстрого/эффективного дальнейшего взаимодействия) явно меньше. А нам нужен был не просто хороший сервис, но и пресловутый «симбиоз», о котором статья.
crezd
А кто платит за OKmeter, вы или клиент?
shurup Автор
Всё сложно (нет возможности раскрывать публично все детали), но если вкратце, то обычно мы.