

Завтра будут официальные пресс-релизы о слиянии старожила Silicon Valley, компании MIPS, с молодой AI компанией Wave Computing. Информация об этом событии просочилась в СМИ вчера, и вскоре CNet, Forbes, EE Times и куча хайтек-сайтов вышла со статьями об этом событии. Поэтому сегодня Derek Meyer, президент объединенной компании (на фото снизу справа), сказал «ладно, распостраняйте инфо среди друзей» и я решил написать пару слов о технологиях и людях, связанных с этим событием.
Главный инвестор в MIPS и Wave — миллиардер Dado Banatao (на фото снизу в центре слева), который еще в 1980-х основал компанию Chips & Technoilogies, которая делала чипсеты для ранних персоналок. В Wave+MIPS есть и другие знаменитости, например Стивен Джонсон (на фото справа вверху), автор самого популярного C-компилятора начала 1980-х годов. MIPS хорошо известен и в России. В руках дизайнерши Смрити (на фото слева) плата из Зеленограда, где находятся лицензиаты MIPS Элвис-НеоТек и Байкал Электроникс.
Wave уже выпустила чип, который состоит из тысяч вычислительных блоков, по сути упрощенных процессоров. Эта конструкция оптимизирована для очень быстрых вычислений нейронных сетей. У Wave есть компилятор, который превращает dataflow граф в файл конфигурации для этой структуры.
Объединенная компания создаст чип, который состоит из смеси таких вычислительных блоков и многопоточных ядер MIPS. Сейчас Wave продает свою технологию в виде ящика для дата-центров, для вычислений нейронных сетей в облаке. Следующие чипы будут использоваться во встроенных устройствах.
Нейронные сети традиционно представляют в виде dataflow-графа. Это граф, в узлах которого находятся константы, переменные и арифметические операции над скалярами, векторами и матрицами:
Компания Google создала библиотеку TensorFlow, которая является API-ем для строительства таких графов и запуска вычислений на сетке — как обычного inference, так и тренировки с помощью backpropfgftion. Этот API чаще всего используется вместе с питоном, код на котором выглядит вот так:

При этом питон в примере выше использует переопределение арифметических операций, которые на самом деле не вычисляют, а строят граф в памяти. На C код для строительства графа в TensorFlow выглядит так:

В Гугле у меня есть знакомый украинский программист Михаил Симбирский, который использует TensorFlow на питоне. Гугловские нейросети используются например для анализа поведения пользователей с целью таргетирования им рекламы. Некоторые вычисления для тренировки нейросетей в гугле занимают дни и недели, несмотря на то, что гуглы используют NVidia GPU и собственные гугловские акселераторы. Это дело непростое, так как передача данных между процессорами и GPU отнимает много времени:
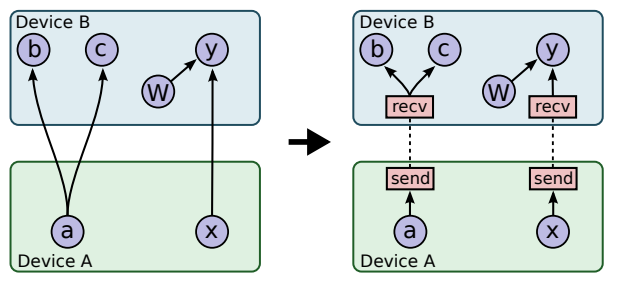
Одна из проблем конструкции из процессоров и GPU заключается в том, что GPU подолгу простаивает:

Другая проблема — недостаточная пропускная способность интерфейсов к памяти. Wave в комбинации с MIPS собирается решить и одну и другую проблему. В новых изделиях не процессор будет использовать акселератор как сопроцессор, а они будут работать вместе.
Для этого ядра MIPS будут модифицироваться, чтобы в конечном итоге создать стандартную аппаратную платформу для AI. Преимущество ядер MIPS I6400/I6500 («Самурай/Даймио») и MIPS I7200 (которое лицензировал MediaTek) — это многопоточность. Многопоточности у ARM нет. Вот как выглядит многопоточный конвейер у ядра MIPS I6400:
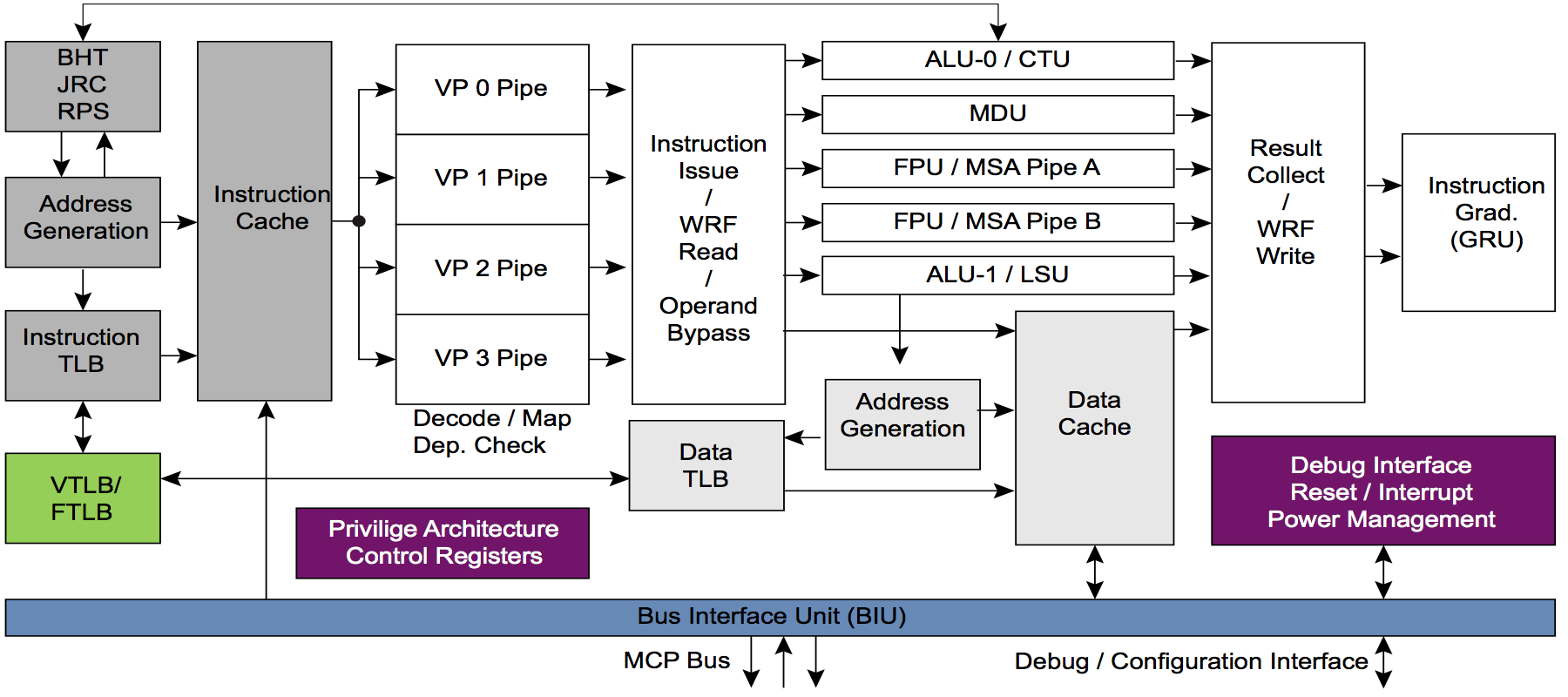
А теперь внимание вопрос к самым сообразительным комментаторам: какое, по-вашему, преимущество дает многопоточность для комбинации из CPU и аппаратного акселератора? В частности акселератора от Wave, который является вариантом так называемого CGRA — Coarse Grained Reconfigurable Array — крупнозернистых реконфигурируемых массивов.
Если вы знакомы с FPGA (Field Programmable Gate Array) / ПЛИС (Программируемые Логические Интегральные Схемы), то идея CGRA в чем-то похожа, но они работают не с отдельными битами, а с целыми шинами по 8-64 бита и в каждой ячейке есть ALU, а для нескольких ячеек — арифметический сопроцессор. Вот так выглядит все иерархия:
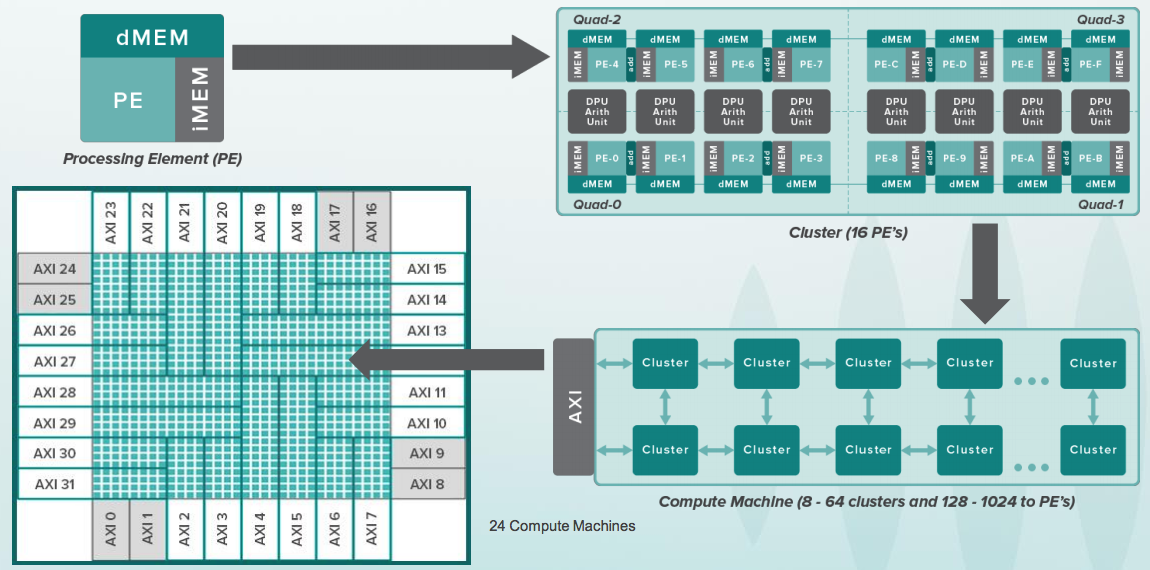
А вот так выглядит одна реконфигурируемая ячейка. У нее есть небольшой буфер с инструкциями, которые напоминают простые команды 8-битных аккумуляторных микроконтроллеров, например 6502 который стоял в первых компьютерах Apple. При этом, процессоры в древних Apple работали с частотой пару мегагерц, а ячейки в CGRA работают с частотой несколько гигагерц. Кроме этого в Apple процессор был один, а тут таких ячеек 16 тысяч:

Кристалл у Wave получается понятно огромный, поэтому приходится использовать локально-синхронные схемы с тактовым сигналом на каждую группу из ячеек. Но самая большая проблема — это не аппаратная, а программная. Граф для вычисления сетки приходится раскидывать на эту кучу устройств с точным знанием, в каком цикле будет что вычисляться. Это называется static scheduling. Поэтому Wave нанял кучу компиляторщиков, включая известнейшего зубра — Стивена Джонсона, который стоял у истоков вместе с Керниганом и Ричи. Вот что писал про Стивена Джонсона Деннис Ритчи:
В 1980-е Си быстро набирал популярность и компиляторы стали доступны практически на каждой машине и операционной системе; в частности, он стал популярным как язык программирования для персональных компьютеров, причем одновременно как для разработчиков коммерческого программного обеспечения для этих машин, так и для рядовых пользователей, увлекающихся программированием. В начале десятилетия практически каждый компилятор был основан на pcc Джонсона; к 1985 было уже много компиляторов, созданных независимыми разработчиками.Когда мне было 18 лет (в 1988 году) и я был студентом МФТИ, Стивен Джонсон был моим Богом. Я участвовал в разработке двух компиляторов на основе его Portable C Compiler. Один компилятор был для Электроники СС БИС, «Красного Крея», советского аналога векторного суперкомпьютера Cray-1. Второй компилятор был для Орбиты 20-700, встроенного компьютера в советских истребителях МиГ-29 и других начала 1980-х годов.
Поэтому я просто обязан был сфотографироваться с Стивеном Джонсоном. Он рассказал мне про другие тулы, которые он делал как для Unix, так и для автоматизации проектирования, автоматического профилирования и т.д.

И разумеется сфотографировался и с инвестором во все это дело Дадо Банатао. Давным-давно Дадо Банатао создал чипсет для первых писишек. Он отлаживал драйверы вместе с Балмером. «Иногда в комнату заходил Билл Гейтс, который нам мешал» — говорит Дадо Банатао. Теперь у него, согласно интернету, пять миллиардов долларов. Он самый известный хай-тек филлипинец, создает центр AI и ведет другие образовательные программы на своей родине.

Больше всего денег Дадо Банатао сделал на компании Marvell. Вот ее офис в Санта-Кларе в лучах вечернего солнца:

В Wave работает много людей которые раньше работали в MIPS. А некоторые из MIPS было в Silicon Graphics, так как MIPS был частью Silicon Graphics в 1990-е годы. В те времена процессоры MIPS стояли в графических станциях, которые использовались в Голливуде для съемок первых реалистичных графических фильмов типа «Парк Юрского Периода». Вот эти графические станции вместе с сибирской девушкой Ириной в Музее Истории Компьютеров в Маунтин-Вью, Калифорния:

В конце сегодняшнего парти в честь завтрашнего официального объявления и вчерашних публикаций в прессе состоялось поедание тортов и распивание шампанского:

Завтра будет много работы — от Verilog RTL (моих прямых обязанностей) до обсуждения архитектуры, приложений и даже разговоров с data scientist-ами (они себя ощущают из другой Вселенной, причем это взаимно и с электронщиками, и с компиляторщиками).
Комментарии (35)

xztau
15.06.2018 11:01ARM уже у японцев. Теперь и MIPS туда поматросить отдали. А ведь Трамп вроде как запретил продавать его в Азию.
djiggalag
15.06.2018 11:49Меня интересует та область искусственного интеллекта, которую используют для потокового перевода речи(Speech-to-Speech Real-Time Translation), когда уже данную технологию доведут до ума, и когда качество перевода уже нельзя будет отличить от человеческого.
reversecode
15.06.2018 11:57Перефразируйте вопрос, когда уже в голову робота можно будет запихнуть сознание человека?
YuriPanchul Автор
15.06.2018 18:58Все текущие технологии искуственного интеллекта не имеют вообще никакого отношения к сознанию. Не существует никаких оснований считать, что оно вообще может возникнуть у конструкции на основе логических элементов/D-триггеров/конечных автоматов, и следовательно компьютеров, нейросетей на ускорителях и т.д. Несмотря ни на какое программирование.
modix
18.06.2018 04:14Как не существует и никаких оснований считать противоположное.
YuriPanchul Автор
18.06.2018 04:24Разумеется. Не существует никаких оснований считать, что на Альфа Центавра не могут жить синие гуманоиды, похожие на Чебурашку. Ну и что? Считать, что они наверное там живут?
Все современные компьютеры вместе с программами любой сложности сводятся к конечному автомату или к модели Хоффмана последовательностных схем. Их можно представить в виде большого количества арифмометров с ручками, связанных рычагами с обратной связью. Ручка играет роль синхросигнала. Если вы не думаете, что у одного арифмометра может возникнуть сознание, то почему вы думаете, что если уставить арифмометрами стадион, то у них возникнет сознание?

modix
18.06.2018 05:29Каждый нейрон, является, грубо говоря, вычислителем(арифмометром), который принимает, обрабатывает и передаёт информацию, однако сам по себе не обладает сознанием. Сознание возникает как свойство работы всей системы, а не отдельных её компонентов. Поэтому вопрос тут в мощности компьютеров, точности моделирования и абстракции нейронов, реализованных на кремнии.
modix
18.06.2018 05:39P.S. Я не утверждаю, что сознание можно реализовать на современной архитектуре, а лишь говорю, что нет весомых обстоятельств утверждать, что нельзя.
Khort
18.06.2018 08:32Строго говоря, в модели Хаффмана не было регистров и клока. В его время в качестве памяти использовали линии задержки, синхронных схем еще не существовало, а Мур и Мили еще футбол во дворе гоняли. Рисунок не верен, и я бы его даже студентам не стал показывать.
Khort
18.06.2018 09:37Вот схема из советского перевода американского учебника (Switching Theory Volume I Only: Combinational Circuits, 1965 by Raymond E. Miller )

enclis
15.06.2018 12:27Одна из проблем конструкции из процессоров и GPU заключается в том, что GPU подолгу простаивает
и идёт ссылка на статью от 9 ноября 2015 года, в тот же день был зарелизен самый первый tensorflow версии 0.5. Первые версии tensorflow работали чуть ли не в 4 раза медленее чем тот же theano, видимо, потому что создатели tensorflow поначалу не особо запаривались над оптимизацией. Конец 2015 года это всё ещё Maxwell… Короче, много времени уже утекло и сейчас это проблема до сих пор присутствует, но её влияние сведено к минимуму, благодаря оптимизации в том числе в CUDA/cuDNN.
beeruser
15.06.2018 16:47Многопоточности у ARM нет.
У ядер ARMH нет, а вообще есть.
Например у ThunderX2 — SMT4YuriPanchul Автор
15.06.2018 19:03Да, согласен, это Cavium перенес свои наработки в своем MIPS-based SMT в свой же ARM-based дизайн
beeruser
15.06.2018 23:54+1К слову сказать это ещё Broadcom сделал. Cavium уже готовый дизайн купили.
YuriPanchul Автор
16.06.2018 02:17А вы часом не путаете Cavium и NetLogic?
beeruser
16.06.2018 06:20+1Нет, я ничего не путаю
www.anandtech.com/show/12694/assessing-cavium-thunderx2-arm-server-reality/3
RomanSt
15.06.2018 18:58Вопрос: когда можно будет провести эксперимент с подобным оборудованием?
Дело в том, что я уже проверял подобные маркетинговые утверждения этой весной. Представитель одной крупной международной компании заявлял, что если взять видеокарту за $500 и сравнить их решение за те же деньги, то разница будет всего в 3 раза в пользу видеокарты. Когда я провел эксперименты с TensorFlow, в соответствии с инструкциями технического специалиста из этой компании, то оказалось в 160 раз. Я не скептик, я действительно хочу найти альтернативу GPU.YuriPanchul Автор
15.06.2018 19:05Первые устройства с текущей версией Wave ускорителя только начали приходить для опробывания к клиентам, поэтому ответ на вопрос «когда это может купить каждый» я еще не знаю.
Khort
15.06.2018 23:19Wave очень сомнительная контора. Исторически они отпочковались от асинхронных стартапов, которые проводили исследования на деньги военных. Асинхронные разработки не пошли, поэтому несколько лет Wave буксовали, переименовались один-два раза и вдруг — о чудо! Оказывается, они уже занимаются AI, выпустили чип и даже купили мипс. По крайней мере, я рад за мипс :-) Но вот интересно, а осталось ли хоть что то асинхронное в сегодняшнем Wave?
YuriPanchul Автор
16.06.2018 02:19+1Индивидуальные ячейки и группы по 8 штук из них сидят на одном clock-е, но вот при коммуникации между ячейками появляется асинхронность, из-за очень большого размера чипа.
Khort
16.06.2018 08:22Знаете, почему они Wave? У асинхронщиков еще с середины 70х появился термин -волновая (фактически — конвейерная) обработка информации. Принцип тот же, что и у ряда из падающих фишек домино, только если бы фишки потом вставать могли — тоже волной, но противоположно направленной. Т.е. в схеме идет два встречных процесса, прямая волна — обработка информации, и встречная волна — гашение. Когда образовали стартап Wave, они вроде бы собирались делать асинхронные чипы по волновому принципу, отсюда и название. Ну что же, значит только это слово и осталось от асинхроники. Так же как Achronix уже давно не асинхронный. Жаль.
YuriPanchul Автор
16.06.2018 08:45Про wave pipelining я что-то видел, хотя так и не понял, как он работает.
Khort
16.06.2018 08:55+1Это один из двух принципов работы асинхронных схем, популярный в основном в Америке. Я там писал выше уже про домино. Если поставить фишки домино в ряд, а потом толкнуть первую, то они повалятся — волной. А потом надо представить что после падения, фишки встают обратно, получается обратно направленная волна. Т.е. две встречных волны — одна валит фишки, вторая подымает. Вот и весь принцип wave pipelining (абстрагируясь от реализации). Фактически, схема является большим конвейером. Если схема не конвейерная, этот метод не работает. Еще забавный момент — у волны должен быть источник, в литераторе его называли водителем ритма rhythm driver. Структура конвейера может быть многомерной, но rhythm driver только один, иначе будет нарушаться целостность пакетов на стыках волн от разных драйверов. В общем, все это интересно, но дальше исследований не пошло.
YuriPanchul Автор
16.06.2018 17:27Я это посмотрю для общего развития, спасибо. Про домино у нас в MIPS есть знающие это дело, я слышал VP Engineering это упоминал.
Brak0del
16.06.2018 17:25Интересная статья, ещё бы больше тех. деталей или цикл статей.
А теперь внимание вопрос к самым сообразительным комментаторам: какое, по-вашему, преимущество дает многопоточность для комбинации из CPU и аппаратного акселератора?
Наверно дело в том, что благодаря многопоточности проц может отправить запрос на доступ к акселератору и пока данный поток будет ожидать освобождения этого акселератора, другой поток проца может заняться полезной работой. Аналогично, для случая статического планирования на время ожидания акселератора можно запланировать выполнение какой-то задачи.
Также интересно, почему они остановились на static-scheduling, если я не подзабыл матчасть, он ведь консервативен, т.е. какая-то часть ресурса всё равно будет простаивать. Почему отказались от каких-то элементов динамического планирования? В любом случае, интересно было бы узнать больше софтово-компиляторных подробностей и решений этой системы.YuriPanchul Автор
16.06.2018 17:32*** Наверно дело в том, что благодаря многопоточности проц может отправить запрос на доступ к акселератору и пока данный поток будет ожидать освобождения этого акселератора, другой поток проца может заняться полезной работой. ***
Это очевидный, но не единственный ответ. Если вы посмотрите MIPS MT ACE, вам может прийти в голову и нечто другое — www.mips.com/downloads/mips-mt-principles-of-operation
reversecode
Захожу в ваш раздел только что бы увидеть блондинку, если перестанете ее публиковать, думаю читаемость ваших статей уменьшится
YuriPanchul Автор
Поправил!
reversecode
А это точно не из старых архивных фото? Помниться она уже как то в музее ходила
Публика желает ее новых приключений