

Если в двух словах, то нужно это для того, чтобы платформа Node.js могла бы достигнуть новых высот в тех областях, в которых раньше она показывала не самые замечательные результаты. Речь идёт о выполнении вычислений, интенсивно использующих ресурсы процессора. Это, в основном, является причиной того, что Node.js не отличается сильными позициями в таких сферах, как искусственный интеллект, машинное обучение, обработка больших объёмов данных. На то, чтобы позволить Node.js хорошо показать себя в решении подобных задач, направлено немало усилий, но тут эта платформа пока выглядит куда скромнее, чем, например, в деле разработки микросервисов.
Автор материала, перевод которого мы сегодня публикуем, говорит, что решил свести техническую документацию, которую можно найти в исходном пулл-запросе и в официальных источниках, к набору простых практических примеров. Он надеется, что, любой, кто разберёт эти примеры, узнает достаточно для того, чтобы приступить к работе с потоками в Node.js.
О модуле worker_threads и флаге --experimental-worker
Поддержка многопоточности в Node.js реализована в виде модуля
worker_threads. Поэтому для того, чтобы воспользоваться новой возможностью, этот модуль надо подключить с помощью команды require.Учтите, что работать с
worker_threads можно только используя флаг --experimental-worker при запуске скрипта, иначе система этот модуль не найдёт.Обратите внимание на то, что флаг включает в себя слово «worker» (воркер), а не «thread» (поток). Именно так то, о чём мы говорим, упоминается в документации, в которой используются термины «worker thread» (поток воркера) или просто «worker» (воркер). В дальнейшем и мы будем придерживаться такого же подхода.
Если вы уже писали многопоточный код, то, исследуя новые возможности Node.js, вы увидите много такого, с чем уже знакомы. Если же раньше вы ни с чем таким не работали — просто продолжайте читать дальше, так как здесь будут даны соответствующие пояснения, рассчитанные на новичков.
О задачах, которые можно решать с помощью воркеров в Node.js
Потоки воркеров предназначены, как уже было сказано, для решения задач, интенсивно использующих возможности процессора. Надо отметить, что применение их для решения задач ввода-вывода — это пустая трата ресурсов, так как, в соответствии с официальной документацией, внутренние механизмы Node.js, направленные на организацию асинхронного ввода-вывода, сами по себе гораздо эффективнее, чем использование для решения той же задачи потоков воркеров. Поэтому сразу решим, что вводом-выводом данных с помощью воркеров мы заниматься не будем.
Начнём с простого примера, демонстрирующего порядок создания и использования воркеров.
Пример №1
const { Worker, isMainThread, workerData } = require('worker_threads');
let currentVal = 0;
let intervals = [100,1000, 500]
function counter(id, i){
console.log("[", id, "]", i)
return i;
}
if(isMainThread) {
console.log("this is the main thread")
for(let i = 0; i < 2; i++) {
let w = new Worker(__filename, {workerData: i});
}
setInterval((a) => currentVal = counter(a,currentVal + 1), intervals[2], "MainThread");
} else {
console.log("this isn't")
setInterval((a) => currentVal = counter(a,currentVal + 1), intervals[workerData], workerData);
}Вывод этого кода будет выглядеть как набор строк, демонстрирующих счётчики, значения которых увеличиваются с разной скоростью.
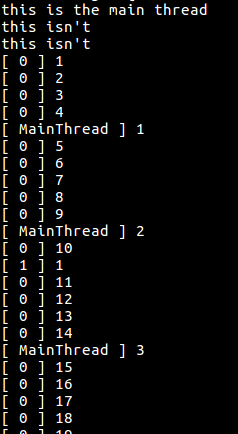
Результаты работы первого примера
Разберёмся с тем, что тут происходит:
- Инструкции внутри выражения
ifсоздают 2 потока, код для которых, благодаря параметру__filename, берётся из того же скрипта, который передавался Node.js при запуске примера. Сейчас воркеры нуждаются в полном пути к файлу с кодом, они не поддерживают относительные пути, именно поэтому здесь и используется данное значение.
- Данные этим двум воркерам отправляют в виде глобального параметра, в форме атрибута
workerData, который используется во втором аргументе. После этого доступ к данному значению можно получить через константу с таким же именем (обратите внимание на то, как создаётся соответствующая константа в первой строке файла, и на то, как, в последней строке, она используется).
Тут показан очень простой пример использования модуля
worker_threads, ничего интересного здесь пока не происходит. Поэтому рассмотрим ещё один пример.Пример №2
Рассмотрим пример, в котором, во-первых, будем выполнять некие «тяжёлые» вычисления, а во-вторых, делать нечто асинхронное в главном потоке.
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
const request = require("request");
if(isMainThread) {
console.log("This is the main thread")
let w = new Worker(__filename, {workerData: null});
w.on('message', (msg) => { //Сообщение от воркера!
console.log("First value is: ", msg.val);
console.log("Took: ", (msg.timeDiff / 1000), " seconds");
})
w.on('error', console.error);
w.on('exit', (code) => {
if(code != 0)
console.error(new Error(`Worker stopped with exit code ${code}`))
});
request.get('http://www.google.com', (err, resp) => {
if(err) {
return console.error(err);
}
console.log("Total bytes received: ", resp.body.length);
})
} else { //код воркера
function random(min, max) {
return Math.random() * (max - min) + min
}
const sorter = require("./list-sorter");
const start = Date.now()
let bigList = Array(1000000).fill().map( (_) => random(1,10000))
sorter.sort(bigList);
parentPort.postMessage({ val: sorter.firstValue, timeDiff: Date.now() - start});
}Для того чтобы запустить у себя этот пример, обратите внимание на то, что этому коду нужен модуль
request (его можно установить с помощью npm, например, воспользовавшись, в пустой директории с файлом, содержащим вышеприведённый код, командами npm init --yes и npm install request --save), и на то, что он использует вспомогательный модуль, подключаемый командой const sorter = require("./list-sorter");. Файл этого модуля (list-sorter.js) должен находиться там же, где и вышеописанный файл, его код выглядит так:module.exports = {
firstValue: null,
sort: function(list) {
let sorted = list.sort();
this.firstValue = sorted[0]
}
}В этот раз мы параллельно решаем две задачи. Во-первых — загружаем домашнюю страницу google.com, во-вторых — сортируем случайно сгенерированный массив из миллиона чисел. Это может занять несколько секунд, что даёт нам прекрасную возможность увидеть новые механизмы Node.js в деле. Кроме того, тут мы измеряем время, которое требуется потоку воркера для сортировки чисел, после чего отправляем результат измерения (вместе с первым элементом отсортированного массива) главному потоку, который выводит результаты в консоль.
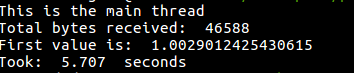
Результат работы второго примера
В этом примере самое главное — это демонстрация механизма обмена данными между потоками.
Воркеры могут получать сообщения из главного потока благодаря методу
on. В коде можно найти события, которые мы прослушиваем. Событие message вызывается каждый раз, когда мы отправляем сообщение из некоего потока с использованием метода parentPort.postMessage. Кроме того, тот же метод можно использовать для отправки сообщения потоку, обращаясь к экземпляру воркера, и получать их, используя объект parentPort.Теперь рассмотрим ещё один пример, очень похожий на то, что мы уже видели, но на этот раз уделим особое внимание структуре проекта.
Пример №3
В качестве последнего примера предлагаем рассмотреть реализацию того же функционала, что и в предыдущем примере, но на этот раз улучшим структуру кода, сделаем его чище, приведём его к виду, который повышает удобство поддержки программного проекта.
Вот код основной программы.
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');
const request = require("request");
function startWorker(path, cb) {
let w = new Worker(path, {workerData: null});
w.on('message', (msg) => {
cb(null, msg)
})
w.on('error', cb);
w.on('exit', (code) => {
if(code != 0)
console.error(new Error(`Worker stopped with exit code ${code}`))
});
return w;
}
console.log("this is the main thread")
let myWorker = startWorker(__dirname + '/workerCode.js', (err, result) => {
if(err) return console.error(err);
console.log("[[Heavy computation function finished]]")
console.log("First value is: ", result.val);
console.log("Took: ", (result.timeDiff / 1000), " seconds");
})
const start = Date.now();
request.get('http://www.google.com', (err, resp) => {
if(err) {
return console.error(err);
}
console.log("Total bytes received: ", resp.body.length);
//myWorker.postMessage({finished: true, timeDiff: Date.now() - start}) //так можно отправлять сообщения воркеру
})А вот код, описывающий поведение потока воркера (в вышеприведённой программе путь к файлу с этим кодом формируется с помощью конструкции
__dirname + '/workerCode.js'):const { parentPort } = require('worker_threads');
function random(min, max) {
return Math.random() * (max - min) + min
}
const sorter = require("./list-sorter");
const start = Date.now()
let bigList = Array(1000000).fill().map( (_) => random(1,10000))
/**
//вот как получить сообщение из главного потока:
parentPort.on('message', (msg) => {
console.log("Main thread finished on: ", (msg.timeDiff / 1000), " seconds...");
})
*/
sorter.sort(bigList);
parentPort.postMessage({ val: sorter.firstValue, timeDiff: Date.now() - start});Вот особенности этого примера:
- Теперь код для главного потока и для потока воркера размещён в разных файлах. Это облегчает поддержку и расширение проекта.
- Функция
startWorkerвозвращает новый экземпляр воркера, что позволяет, при необходимости, отправлять этому воркеру сообщения из главного потока. - Здесь не нужно проверять, выполняется ли код в главном потоке (мы убрали выражение
ifс соответствующей проверкой). - В воркере показан закомментированный фрагмент кода, демонстрирующий механизм получения сообщений от главного потока, что, учитывая уже рассмотренный механизм отправки сообщений, позволяет организовать двусторонний асинхронный обмен данными между главным потоком и потоком воркера.
Итоги
В этом материале мы, на практических примерах, рассмотрели особенности использования новых возможностей по работе с потоками в Node.js. Если вы освоили то, о чём здесь шла речь, это значит, что вы готовы к тому, чтобы, посмотрев документацию, приступить к собственным экспериментам с модулем
worker_threads. Пожалуй, стоит ещё отметить, что эта возможность только появилась в Node.js, пока она является экспериментальной, поэтому со временем что-то в её реализации может измениться. Кроме того, если в ходе собственных экспериментов с worker_threads вы столкнётесь с ошибками, или обнаружите, что этому модулю не помешает какая-то отсутствующая в нём возможность — дайте знать об этом разработчикам и помогите улучшить платформу Node.js.Уважаемые читатели! Что вы думаете о поддержке многопоточности в Node.js? Планируете ли вы использовать эту возможность в своих проектах?

Комментарии (14)

hypnotic_signal
29.06.2018 17:29Или перестаньте переводить статьи, которые так же явно не стоит переводить. Данная фича интересна да, но интерес явно должен быть сосредоточен вокруг бенчмарков. API банально и похоже на типичную работу с событиями в node.js. Это вторая статья о потоках в ноде на хабре за эту неделю… обе можно дальше заголовков не читать, тот случай(как и многие другие) когда лучше сразу открывать доку nodejs.org/api/worker_threads.html
taliban
29.06.2018 17:39Тут больше описали смысл вообще этого, а не того как по мануалу с ним работать и какое у него апи. Это новая фича, по этому «keep calm and ignore posts with worker_threads».
hypnotic_signal
29.06.2018 18:02Извиняйте если кого-то задел, намерений таких нет, просто хотелось как раз сказать, что не стоит описывать смысл потоков используя Node.js, это не та технология. Работаю с нодой начиная с версии 0.4 и так сказать фанат этого стека, с интересом открывал статью, интерес не удовлетворен. Если кто-то сделает тесты на производительность(возможно я и сам сделаю по мере свободного времени) — будет круто. Это весь посыл.
taliban
29.06.2018 18:05Ну, производительность даже менять не нужно, ибо нода однопоточная и выигрыш будет 100% и очень серьезный при условии что теперь можно вынести синхронные операции в отдельный поток.
hypnotic_signal
29.06.2018 18:25У нас с вами видимо разный подход к сравнительному анализу. В моей практике первый этап это технический анализ, графики, сводные таблицы с конкурирующими технологиями и т.д. И только потом утверждения где и в каком объеме будет «выигрыш». Нет никаких данных об издержках на сообщения между потоками, как себя поведет нода на большом количестве потоков и т.д. Это уже 3-ий коммент об одном и том же, что делает меня не лучше автора статьи, так что далее я пасс))
taliban
29.06.2018 18:43Ключевой была фраза «нода однопоточна», весь сервер однопоточен, любой синхронный код стопорит абсолютно всю очередь соединений пока он не выполнится. И если раньше такая проблема решалась микросервисами или другими решениями (не нода), то сейчас можно это обойти. Если вы не видите выигрыша, то будете дальше решать проблемы старыми способами. Это не замена евентам или асинхронности, это дополнение.
hypnotic_signal
29.06.2018 19:06Уважаемый, не стоит ванговать за методологии разработчиков о которых вы ничего не знаете и тем более рассказывать про однопоточность...(тут просто фейспалм). Я вижу выигрыш и ни слова не обронил против этого нового модуля, а так же с 99% вероятностью буду проводить тесты и изучать код под капотом. Не хотите объективных данных о его работе — ну хорошо, ваше право. А мое право проявлять интерес к сравнительному анализу, для того чтобы принимать решения в пользу производительности в каждом конкретном случае. Как правило работаю с большим объемом трафика и можете считать профессиональной деформацией — привычку думать заранее.
taliban
29.06.2018 19:34-1То что вы форкаете ноду, не значит что соединения не ждут при синхронных операциях, форков у вас гарантированно меньше чем соединений, так что не нужно этих пафосных фейспалмов. Я так же отвечу вашими же словами: я не говорил что тесты делать не нужно, и мне не нужно объективных данных. Так что не нужно делать выводы и за меня решать что мне нужно а что мне не нужно. Я лишь сказал что это нововведение 100% даст прирост в производительности ибо можно вынести синхронный код. Дальше вы уже надумали себе и спорите со своими выводами.
hypnotic_signal
29.06.2018 19:56Эх, еще бы понять о чем мы спорим. Спасибо за дискуссию, к сожалению ничего нового не узнал и свою позицию донести не смог.
funca
30.06.2018 00:07+1Один момент. В Node.js отродясь были «потоки», которые nodejs.org/api/stream.html. Как мне кажется слово уже занято, и использование его в другом контексте будет приводить к путанице. Во всяком случае, я до второго раздела не понимал о чем вообще новость.
Тот модуль который добавили сейчас, сначала называли просто worker, а потом дописали worker_threads. Но thread еще переводят как «нить», чтобы не путать с потоками. А название может еще поменяется потому, что тоже мало кому нравится.SimSonic
30.06.2018 07:56+1Те потоки, которые threads, подразумеваются как "потоки [выполнения программы]", а те, что streams — как "потоки [данных (или ввода/вывода)]". Слово Нить мне лично не нравится, и небольшая двойственность слова Поток мне совершенно не мешает. Это вполне устоявшийся термин в рунете.
funca
30.06.2018 00:28+1Что вы думаете о поддержке многопоточности в Node.js?
«Однопоточность» ноды это концептуальное выражение, а не то, как все там работает на самом деле. Node.js уже давно использует их для внутренних нужд. Если интересно, гуглить можно по слову «uv_threadpool_size».
Задача которую решают сейчас — вытащить эти возможности в юзерспейс (с завистью глядя на Web Workers в браузерах). Microsoft и Alibaba в разное время уже патчили ноду подобным образом. Они уж точно знают толк в, значит это точно кому-нибудь нужно. Но юная девушка тут всех опередила. :)
MrQuest
Перестаньте уже переводить слова, которые явно переводить не стоит: потоки воркеров, мерседес бенз… Ведь Вы же пишите Node.js, а не нод.джиэс.
S_Gonchar
Node.js — имя собственное, поэтому есть смысл оставить его без перевода.
А вот «worker threads» — в данном случае, имя нарицательное, и по-моему стоило перевести, как «рабочий поток» или «поток обработки».