
Это краткое отступление в текущей серии статей о том, как избегать введения сервисов для различных сущностей. Интересный разговор за ужином привёл к мыслям, которые я решил записать.
В 1967 году Джин Амдал представил довод против параллельных вычислений. Он утверждал, что рост производительности ограничен, поскольку только часть задачи поддаётся распараллеливанию. Размер остальной «последовательной части» отличается в разных задачах, но она есть всегда. Этот довод стал известен как закон Амдала.
Если построить график «ускорения» выполнения задачи в зависимости от количества выделенных ей параллельных процессоров, вы увидите следующее:
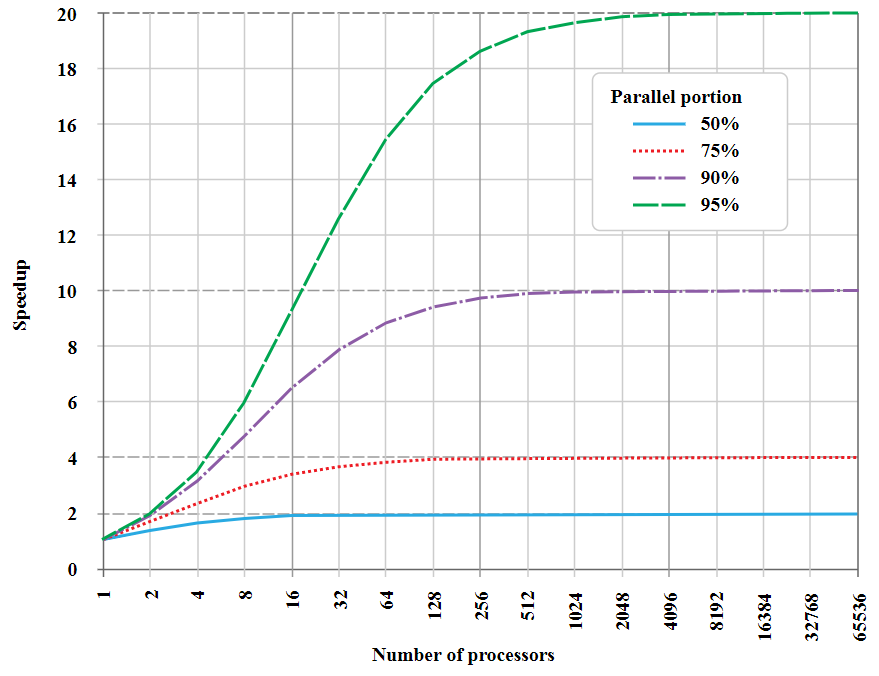
Это асимптотический график для фрагмента, который не поддаётся распараллеливанию («последовательная часть»), поэтому существует верхний предел максимального ускорения
В законе Амдала интересно то, что в 1969 году на самом деле было совсем немного многопроцессорных систем. Формула основана на другом принципе: если последовательная часть в задаче равна нулю, то это не одна задача, а несколько.
Нил Гюнтер расширил закон Амдала на основе наблюдений за измерениями производительности многих машин и вывел универсальный закон масштабируемости (Universal Scalability Law, USL). В нём используется два параметра: один для «конкуренции» (которая похожа на последовательную часть), а второй для «непоследовательности» (incoherence). Непоследовательность соотносится со временем, потраченным на восстановление согласованности, то есть общего взгляда на мир разных процессоров.
В одном CPU издержки согласования возникают из-за кэширования. Когда одно ядро изменяет строку кэша, оно указывает другим ядрам извлечь эту строку из кэша. Если всем нужна одна и та же строка, они тратят время на её загрузку из основной памяти. (Это немного упрощённое описание… но в более точной формулировке всё равно есть издержки согласования).
На всех узлах БД возникают издержки согласования из-за алгоритмов согласования и сохранения последовательности данных. Штраф платится при изменении данных (как в случае транзакционных БД) или при чтении данных в случае согласованных в конечном счёте хранилищ.
Если построить график USL в зависимости от количества процессоров, то возникнет такая зелёная линия:
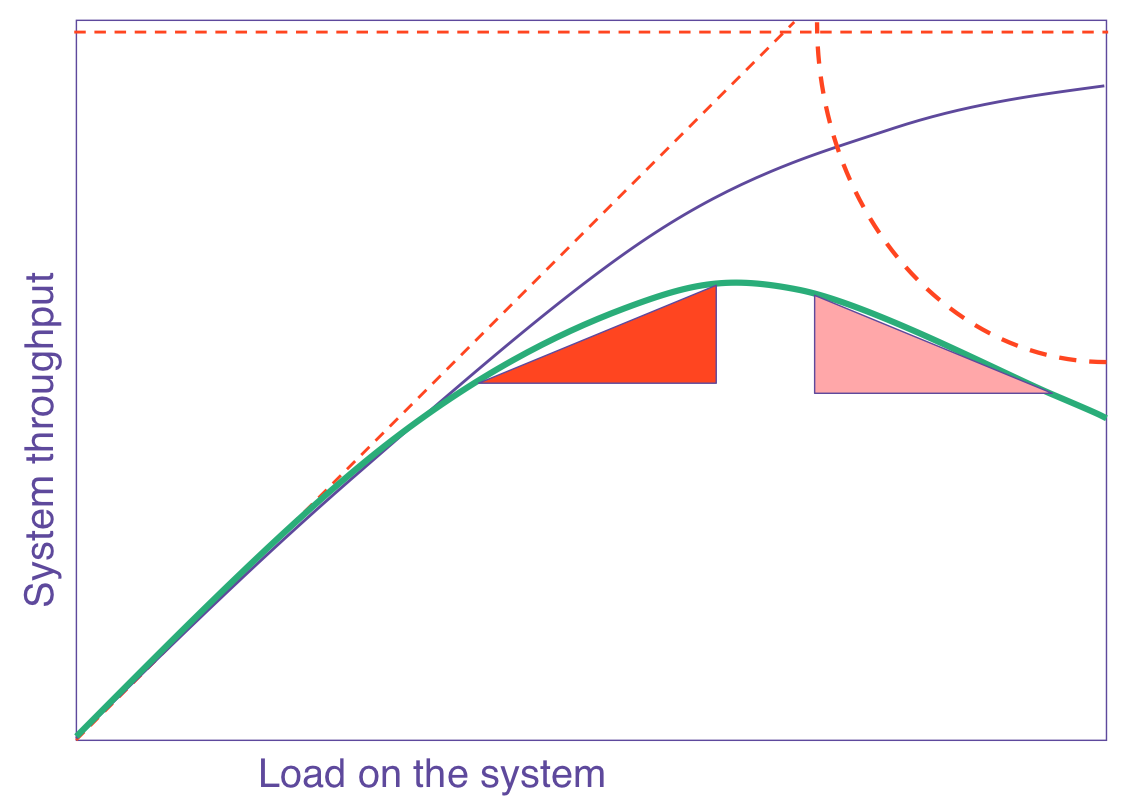
Фиолетовая линия показывает, что предсказал бы закон Амдала
Обратите внимание, что зелёная линия достигает пика, а затем снижается. Это означает, что есть определённое количество узлов, при которых производительность максимальна. Добавьте больше процессоров — и производительность снижается. Я видел такое в реальном нагрузочном тестировании.
Людям часто хочется увеличить количество процессоров и повысить производительность. Это можно сделать двумя способами:
Давайте попробуем аналогию. Если вычислительная «задача» — это проект, то можно представить количество людей в проекте как количество «процессоров», выполняющих работу.
В этом случае последовательная часть — это кусок работы, которую можно выполнить только последовательно, шаг за шагом. Это может быть темой для будущей статьи, но сейчас нас не интересует суть последовательной части.
Кажется, мы видим прямую аналогию с издержками согласования. Независимо от времени, которое члены команды тратят на восстановление общего взгляда на мир, издержки согласования присутствуют.
Для пяти человек в комнате эти издержки минимальны. Пятиминутка рисования маркером на доске раз в неделю или около того.
Для большой команды в нескольких часовых поясах штраф может вырасти и формализоваться. Документы и пошаговые руководства. Презентации для команды и так далее.
В некоторых архитектурах согласование не так важно. Представьте команду с сотрудниками на трёх континентах, но каждый работает над одной службой, которая использует данные в строго определённом формате и создаёт данные в строго определённом формате. Им не требуется согласованность в отношении изменений в процессах, но необходима согласованность в отношении любых изменений в форматах.
Иногда инструменты и языки могут изменить издержки согласования. Один из аргументов в пользу статической типизации — что она помогает взаимодействовать в команде. По сути, типы в коде являются механизмом трансляции изменений в модели мира. В динамически типизированном языке нам либо понадобятся вторичные артефакты (модульные тесты или сообщения чата), либо нужно создать границы, где одни отделы очень редко восстанавливают согласованность с другими.
Все эти методы направлены на уменьшение издержек согласования. Напомним, что чрезмерное масштабирование вызывает снижение пропускной способности. Так что если у вас высокие издержки на согласование и слишком много людей, то команда в целом работает медленнее. Я видел коллективы, где казалось, что мы можем сократить половину людей и работать вдвое быстрее. USL и издержки согласования теперь помогают понять, почему так происходит — это не просто очистка от мусора. Речь идёт о сокращении накладных расходов на обмен ментальными моделями.
В «Цикле страха» я ссылался на кодовые базы, где разработчики знали о необходимости крупномасштабных изменений, но боялись случайно нанести вред. Это означает, что излишне раздутая команда так и не достигла согласованности. Кажется, после потери согласованность очень трудно восстановить. Это означает, что игнорировать издержки согласования никак нельзя.
По-моему, USL объясняет интерес к микросервисам. Разделяя большую систему на всё более мелкие части, развёртываемые независимо друг от друга, вы уменьшаете последовательную часть работы. В большой системе с большим количеством участников последовательная часть зависит от объёма усилий на интеграцию, тестирование и развёртывание. Преимущество микросервисов в том, что они не нуждаются в интеграционной работе, интеграционном тестировании или задержке на синхронизированное развёртывания.
Но издержки согласования означают, что вы можете не получить желаемого ускорения. Возможно, здесь аналогия немного натянута, но я думаю, что можно рассматривать изменения интерфейса между микросервисами как требующие повторного согласования между командами. Если этого слишком много, то вы не получите желаемой выгоды от микросервисов.
Моё предложение: посмотрите на используемую архитектуру, язык, инструменты и команду. Подумайте, где теряется время на восстановление согласованности, когда люди вносят изменения в системную модель мира.
Ищите разрывы. Разрывы между внутренними границами системы и расколы внутри команды.
Используйте окружение для передачи изменений, чтобы процесс согласования происходил для всех, а не индивидуально.
Посмотрите на коммуникации вашей команды. Сколько времени и усилий уходит на обеспечение согласованности? Может, произвести небольшие изменения и уменьшить потребность в ней?
Закон Амдала
В 1967 году Джин Амдал представил довод против параллельных вычислений. Он утверждал, что рост производительности ограничен, поскольку только часть задачи поддаётся распараллеливанию. Размер остальной «последовательной части» отличается в разных задачах, но она есть всегда. Этот довод стал известен как закон Амдала.
Если построить график «ускорения» выполнения задачи в зависимости от количества выделенных ей параллельных процессоров, вы увидите следующее:
Это асимптотический график для фрагмента, который не поддаётся распараллеливанию («последовательная часть»), поэтому существует верхний предел максимального ускорения
От Амдала до USL
В законе Амдала интересно то, что в 1969 году на самом деле было совсем немного многопроцессорных систем. Формула основана на другом принципе: если последовательная часть в задаче равна нулю, то это не одна задача, а несколько.
Нил Гюнтер расширил закон Амдала на основе наблюдений за измерениями производительности многих машин и вывел универсальный закон масштабируемости (Universal Scalability Law, USL). В нём используется два параметра: один для «конкуренции» (которая похожа на последовательную часть), а второй для «непоследовательности» (incoherence). Непоследовательность соотносится со временем, потраченным на восстановление согласованности, то есть общего взгляда на мир разных процессоров.
В одном CPU издержки согласования возникают из-за кэширования. Когда одно ядро изменяет строку кэша, оно указывает другим ядрам извлечь эту строку из кэша. Если всем нужна одна и та же строка, они тратят время на её загрузку из основной памяти. (Это немного упрощённое описание… но в более точной формулировке всё равно есть издержки согласования).
На всех узлах БД возникают издержки согласования из-за алгоритмов согласования и сохранения последовательности данных. Штраф платится при изменении данных (как в случае транзакционных БД) или при чтении данных в случае согласованных в конечном счёте хранилищ.
Эффект USL
Если построить график USL в зависимости от количества процессоров, то возникнет такая зелёная линия:
Фиолетовая линия показывает, что предсказал бы закон Амдала
Обратите внимание, что зелёная линия достигает пика, а затем снижается. Это означает, что есть определённое количество узлов, при которых производительность максимальна. Добавьте больше процессоров — и производительность снижается. Я видел такое в реальном нагрузочном тестировании.
Людям часто хочется увеличить количество процессоров и повысить производительность. Это можно сделать двумя способами:
- Уменьшить последовательную часть
- Уменьшить издержки согласования
USL в человеческих коллективах?
Давайте попробуем аналогию. Если вычислительная «задача» — это проект, то можно представить количество людей в проекте как количество «процессоров», выполняющих работу.
В этом случае последовательная часть — это кусок работы, которую можно выполнить только последовательно, шаг за шагом. Это может быть темой для будущей статьи, но сейчас нас не интересует суть последовательной части.
Кажется, мы видим прямую аналогию с издержками согласования. Независимо от времени, которое члены команды тратят на восстановление общего взгляда на мир, издержки согласования присутствуют.
Для пяти человек в комнате эти издержки минимальны. Пятиминутка рисования маркером на доске раз в неделю или около того.
Для большой команды в нескольких часовых поясах штраф может вырасти и формализоваться. Документы и пошаговые руководства. Презентации для команды и так далее.
В некоторых архитектурах согласование не так важно. Представьте команду с сотрудниками на трёх континентах, но каждый работает над одной службой, которая использует данные в строго определённом формате и создаёт данные в строго определённом формате. Им не требуется согласованность в отношении изменений в процессах, но необходима согласованность в отношении любых изменений в форматах.
Иногда инструменты и языки могут изменить издержки согласования. Один из аргументов в пользу статической типизации — что она помогает взаимодействовать в команде. По сути, типы в коде являются механизмом трансляции изменений в модели мира. В динамически типизированном языке нам либо понадобятся вторичные артефакты (модульные тесты или сообщения чата), либо нужно создать границы, где одни отделы очень редко восстанавливают согласованность с другими.
Все эти методы направлены на уменьшение издержек согласования. Напомним, что чрезмерное масштабирование вызывает снижение пропускной способности. Так что если у вас высокие издержки на согласование и слишком много людей, то команда в целом работает медленнее. Я видел коллективы, где казалось, что мы можем сократить половину людей и работать вдвое быстрее. USL и издержки согласования теперь помогают понять, почему так происходит — это не просто очистка от мусора. Речь идёт о сокращении накладных расходов на обмен ментальными моделями.
В «Цикле страха» я ссылался на кодовые базы, где разработчики знали о необходимости крупномасштабных изменений, но боялись случайно нанести вред. Это означает, что излишне раздутая команда так и не достигла согласованности. Кажется, после потери согласованность очень трудно восстановить. Это означает, что игнорировать издержки согласования никак нельзя.
USL и микросервисы
По-моему, USL объясняет интерес к микросервисам. Разделяя большую систему на всё более мелкие части, развёртываемые независимо друг от друга, вы уменьшаете последовательную часть работы. В большой системе с большим количеством участников последовательная часть зависит от объёма усилий на интеграцию, тестирование и развёртывание. Преимущество микросервисов в том, что они не нуждаются в интеграционной работе, интеграционном тестировании или задержке на синхронизированное развёртывания.
Но издержки согласования означают, что вы можете не получить желаемого ускорения. Возможно, здесь аналогия немного натянута, но я думаю, что можно рассматривать изменения интерфейса между микросервисами как требующие повторного согласования между командами. Если этого слишком много, то вы не получите желаемой выгоды от микросервисов.
Что с этим делать?
Моё предложение: посмотрите на используемую архитектуру, язык, инструменты и команду. Подумайте, где теряется время на восстановление согласованности, когда люди вносят изменения в системную модель мира.
Ищите разрывы. Разрывы между внутренними границами системы и расколы внутри команды.
Используйте окружение для передачи изменений, чтобы процесс согласования происходил для всех, а не индивидуально.
Посмотрите на коммуникации вашей команды. Сколько времени и усилий уходит на обеспечение согласованности? Может, произвести небольшие изменения и уменьшить потребность в ней?
qbertych
Я. И. Перельман, "Занимательная механика", о совместной работе нескольких лошадей
Razoomnick
Слоник: Слушай, а как ты думаешь, вот если много людей, скажем, тысяча… без подручных средств…
Колезев: Чувствую, сейчас будет очень тупой вопрос. Даже боюсь представить.
Слоник: Смогут ли они отмудохать бегемота?
https://bash.im/quote/323216
zambas
Уменьшения бутылочных горлышек процессов всегда является приоритетом в любых системах, тут главное соблюдать баланс
bugdesigner
Получается, что создание современных суперкомпьютеров с тысячами процессоров лишено практического смысла — только померятлся количеством флопсов с конкурентами. Ведь загрузить этого монстра на 100% вряд ли получится, кроме как на синтетических тестах.
Danik-ik
Обывательское мнение: Есть задачи, которые реально распараллеливаются. Скажем, поиск каких-то паттернов в накопленных массивах данных (астрономия). Есть задачи, которые с точки зрения бизнеса — одна задача, а на самом деле — куча однотипных почти не связанных процессов (возможно банковские процессы какие-то). Первые ЭВМ, к примеру, рассчитывали баллистические, кажется (или навигационные?) таблицы — однотипные несвязанные действия над каждым элементом из огромного исходного массива данных.
Но лучше, конечно, спросить тех, кто реально это эксплуатирует: что они там запускают?
sibirier
вычисления погоды, расчет квантово-химических процессов, квантово-физических процессов, моделирование сложных газодинамических систем (ракеты)
DimaTiunov
Сначала делают такие прототипы, а потом выдумывают задачи. Обычно так)
AAngstrom
Помимо уже сказаного про задачи, которые хорошо параллелятся, стоит заметить, что эти монстры нужны, чтобы там много людей одновременно могло запускать задачи поменьше (используя систему очередей для задач).
LiderMaximum
Дай Бог, чтобы до руководителей дошло, что 50% процессов невозможно распараллелить, потому что они линейные! Каждый должен делать свою работу и не делать чужую.
Еще один момент, что необходимо проводить работу над ошибками. Ошибаются и косячат все, а вот исправляются далеко не многие. Исправляйтесь и совершенствуйтесь!
ggo
USL не объясняет интерес, а это и есть ответ, почему микросервисы для бизнеса интереснее, чем монолит (в общем случае).
Если сформулировать человеческим языком:
Когда у вас трудится 200 человек в монолите, то количество внутреннего трения сотрудников между собой таково, что любой здравый менеджер хватается за голову.
Если поделить 200 человек на 10 независимых команд, которые свои сервисы будут пилить относительно независимо, то внутреннее трение существенно уменьшается (в общем случае). Но возрастают затраты на получение согласованного состояния всех сервисов.