
Выкладываю второй доклад с нашего первого митапа, который провели в сентябре. В прошлый раз можно было почитать (и посмотреть) про использование Consul для масштабирования stateful-сервисов от Ивана Бубнова из BIT.GAMES, а сегодня поговорим про CICD. Точнее расскажет об этом наш системный администратор Егор Панов, который отвечает за доступность инфраструктуры и сервисов в Pixonic. Под катом — расшифровка выступления.
Начну с того, что игровая индустрия более рискованная — никогда не знаешь, что именно западет в сердце игроку. И поэтому мы создаем множество прототипов. Конечно, прототипы мы создаем на коленке из палочек, веревочек и других подручных материалов.
Казалось бы, при таком подходе сделать что-то, что потом можно будет поддерживать вообще невозможно. Но даже на этом этапе мы держимся. Держимся на трех китах:
Соответственно, если мы не выстроим свои процессы, например, деплой или CI (continuous integration) — рано или поздно мы придем к тому, что длительность тестирования все время будет увеличиваться и увеличиваться. И мы либо будем медленно все делать и потерям рынок, либо просто будем взрываться при каждом деплое.
Но CICD-процесс построить не так уж и просто. Некоторые скажут, ну да, я поставлю Jenkins, быстро что-то накликаю, вот у меня готовый CICD. Нет, это не только инструмент, это еще и практики. Начнем по порядку.

Первое. Во многих статьях пишут, что все нужно держать в одном репозитории: и код, и тесты, и деплой, и даже схему базы данных, и настройки IDE, общие для всех. Мы пошли своим путем.
Мы выделили разные репозитории: деплой у нас в одном репозитории, тесты — в другом. Это работает быстрее. Может быть вам не подойдет, но для нас это гораздо удобнее. Потому что есть один важный момент в этом пункте — нужно выстроить простой и прозрачный для всех гитфлоу. Конечно, вы можете где-то скачать готовый, но в любом случае его нужно под себя подстроить, улучшить. Для нас, например, деплой живет своим гитфлоу, который больше похож на GitHub-флоу, а серверная разработка живет по своему гитфлоу.
Следующий пункт. Нужно настроить полностью автоматическую сборку. Понятно, на первом этапе разработчик сам лично собирает проект, потом сам лично его деплоит при помощи SCP, сам запускает, сам отправляет, кому нужно. Этот вариант долго не прожил, появился bash-скрипт. Ну а так как окружение разработчиков все время меняется, появился специальный выделенный билдсервер. Он прожил очень долго, за это время мы успели увеличиться в серверах до 500, настроить конфигурирование серверов на Puppet, накопить на Puppet легаси, отказаться от Puppet, перейти на Ansible, а этот билдсервер продолжал жить.
Решили все поменять после двух звонков, третьего ждать не стали. История понятная: билдсервер — это единая точка отказа и, конечно же, когда нам нужно было что-то задеплоить, дата-центр полностью упал вместе с нашим билдсервером. А второй звонок: нам нужно было обновить версию Java — обновили на билдсервере, задеплоили на стейдж, все классно, все замечательно и тут же нужно было какой-то маленький багфикс запустить на прод. Конечно, мы забыли обратно откатить и все просто развалилось.
После этого переписали все так, чтобы весь билд мог происходить на абсолютно любом агенте TeamCity и переписали его на Ansible, потому что конфигурирование на Ansible, почему бы тогда этим же инструментом не воспользоваться и для деплоя.
Следующее правило: чем чаще коммитишь, тем лучше. А почему? Потому что есть четвертое: каждый коммит собирается. И на самом деле даже больше, чем каждый коммит. Я уже сказал, что у нас TeamCity, а он позволяет запустить коммит из вашей любимой IDE (вы догадываетесь, какую имею ввиду). Собственно, быстрая обратная связь, все замечательно.
Сломанный билд чинится сразу же. Как только ты настроил автоматический деплой, тут же нужно настроить автоматическую нотификацию в Slack. Все мы прекрасно знаем, что разработчик знает, как его код работает, только в тот момент, когда он его пишет. Поэтому: человек узнал — сразу же починил.
Тестируем на окружении, повторяющем прод. Тут все просто, мы выбрали Ansible и AWX. Кто-то может быть спросит, а как же Docker, Kubernetes, OpenShift, где все проблемы из коробки давным давно решены? Забыл сказать, у нас есть компоненты как Linux, так и Windows. И, например, Photon-сервер, который на Windows, мы только-только недавно смогли упаковать более менее нормально в 10 Гб докер-контейнер. Соответственно, у нас есть приложение на Windows, которое плохо упаковывается в контейнер; есть приложение на Linux (которое на Java), которое прекрасно запаковывается, но это и незачем, оно прекрасно работает, где бы ты его не запустил. Это же Java.
Дальше мы выбирали между Ansible и Chef. Они оба прекрасно работают с виндой, но Ansible оказался гораздо проще для нас. Когда мы уже установили AWX — вообще все огонь стало. В AWX есть секреты, есть графики, история. Можно вообще далекому от всего этого человеку показать, он сразу все увидит и все станет понятно.
И всегда нужно держать билд быстрым. Не знаю почему, но всегда, когда запускаешь новый проект, то про билдсервер, про агенты забываешь напрочь и выделяешь какой-то компьютер, который рядом валялся — вот это наш билдсервер. Эту ошибку повторять нежелательно, потому что все, о чем я говорю (быстрая обратная связь, плюсы) — оно все будет уже не таким актуальным, если на твоем собственном ноуте сборка будет запускаться гораздо быстрее, чем на какой-то ферме билдсерверов.

7 пунктов — и мы уже построили какой-то CI-процесс. Замечательно. На следующей схеме не видно, но сбоку есть еще Graylog. Кто читает наши статьи на Хабре, тот уже видел, как мы выбирали Graylog и как устанавливали. В любом случае он помогает отдебажить, если какая-то проблема все-таки случилась.
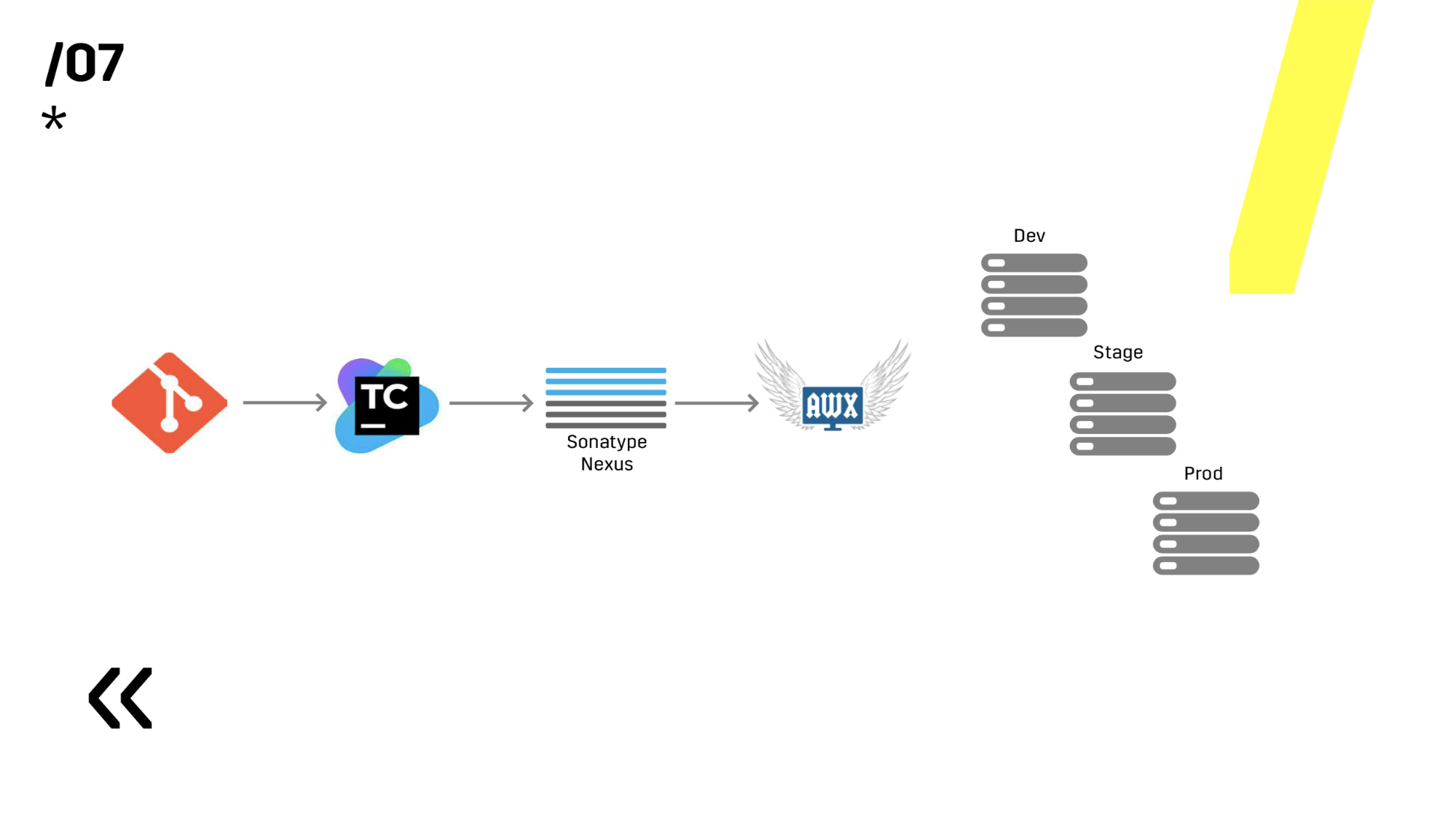
Вот на этой базе уже можно переходить к деплою.

Но про деплой я уже рассказал во втором пункте, поэтому не буду сильно останавливаться на этом. Скажу один лайфках: если вы используете Ansible, обязательно добавьте вот этот serial, который на слайде. Не раз бывало, что ты запускаешь что-то, а потом понимаешь, а я не то запустил, или не туда, или не то и не туда, а потом видишь, что это всего лишь один сервер. А мы потерять один сервер легко можем и ты просто его заново перезаливаешь, никто и не заметил.
Плюс установили хранилище артефактов на Nexus — он является единой точкой входа абсолютно для всех, не только для CI.
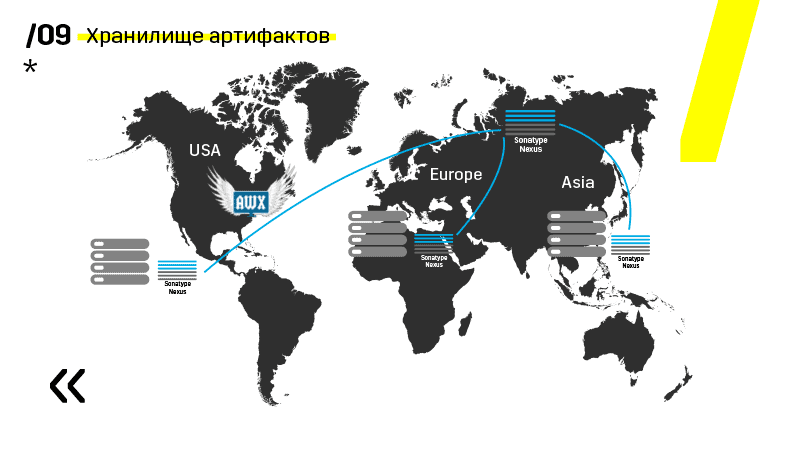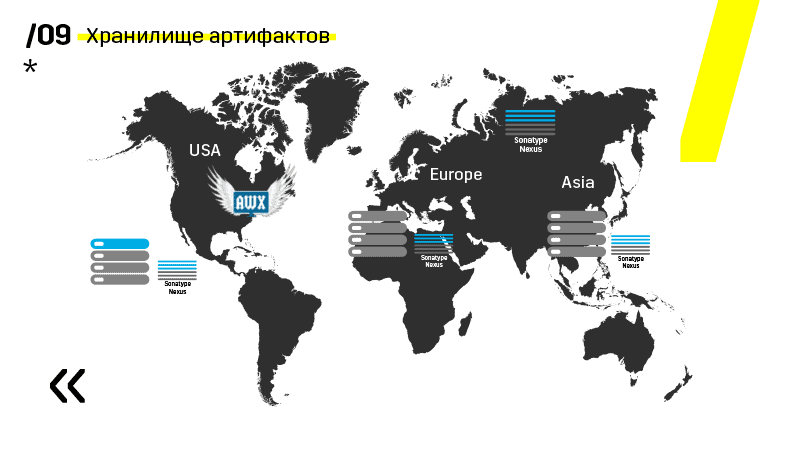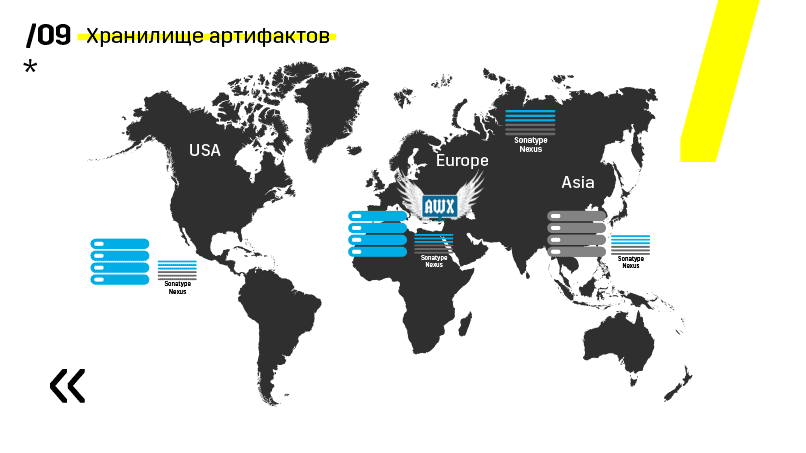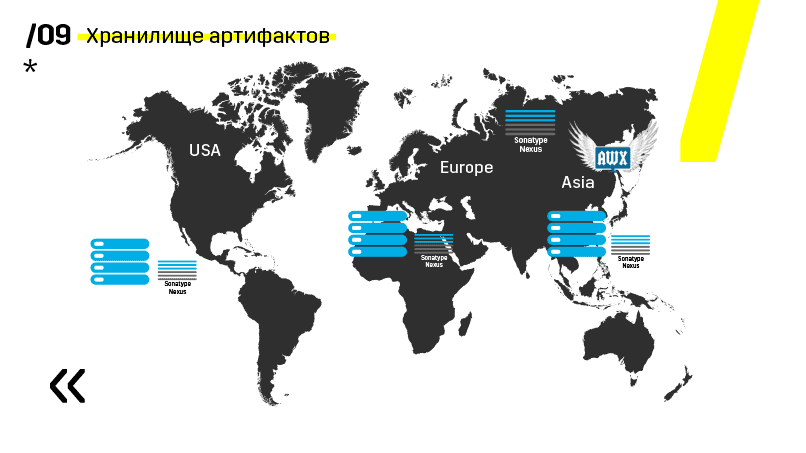
И это очень помогает нам обеспечить повторяемость. Ну и так как нексусы могут работать как прокси-сервисы в разных регионах, то они ускоряют деплой, установку rpm-пакетов, докер-образов, чего угодно.
Когда закладываешь новый проект, желательно выбирать компоненты, которые легко поддаются автоматизации. Например с Photon-сервером нам это не удалось. В любом случае, это было лучшее решение по другим параметрам. А вот Cassandra, например, очень удобно обновляется и автоматизируется.
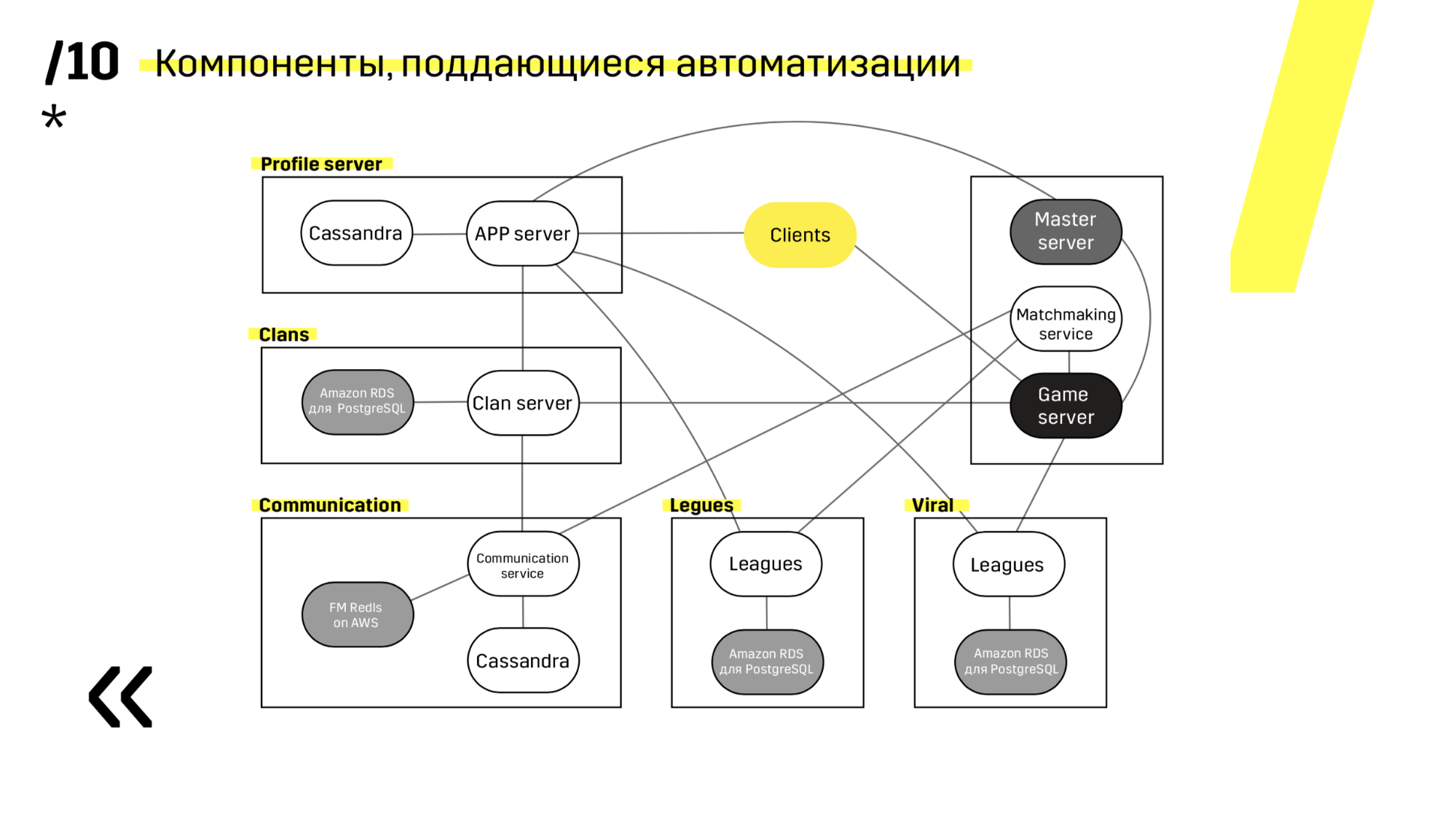
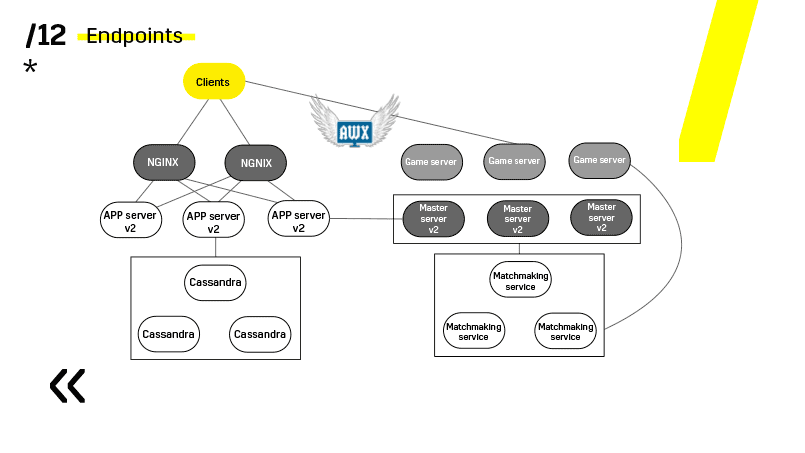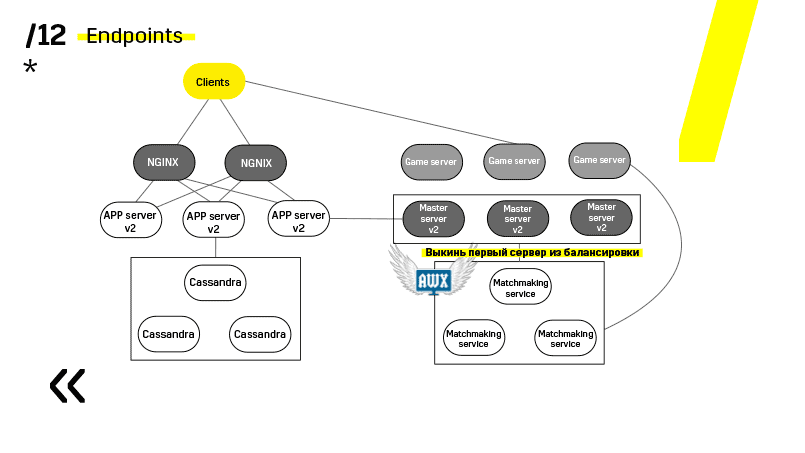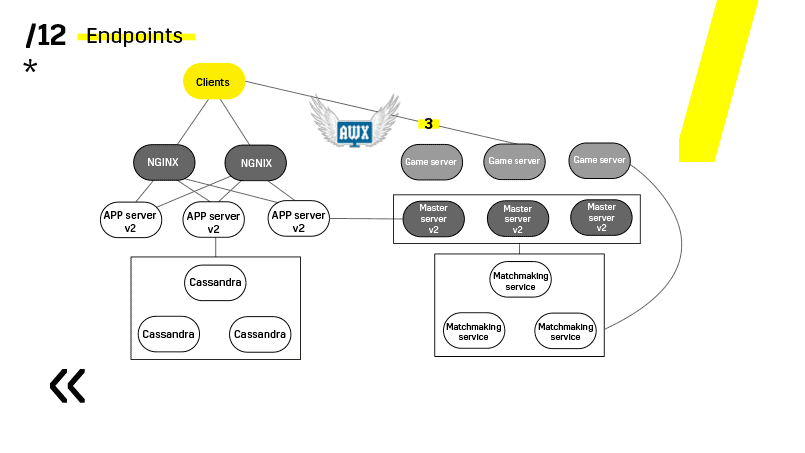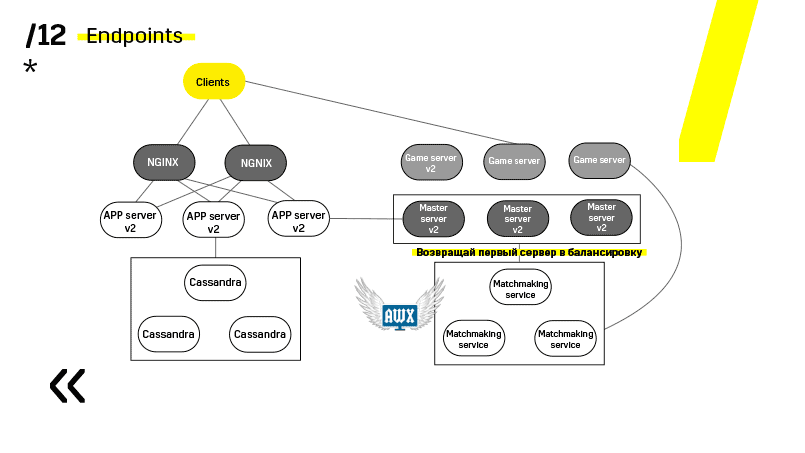
Вот пример одного из наших проектов. Клиент приходи на APP-сервер, где у него лежит профиль в БД Cassandra, а потом идет на мастер-сервер, который при помощи матчмейкинга дает ему уже гейм-сервер с какой-то комнатой. Все остальные сервисы сделаны в виде «приложения — БД» и обновляется точно таким же образом.
Второй момент — нужно обеспечить простую малосвязанную архитектуру для деплоя. Нам это удалось.
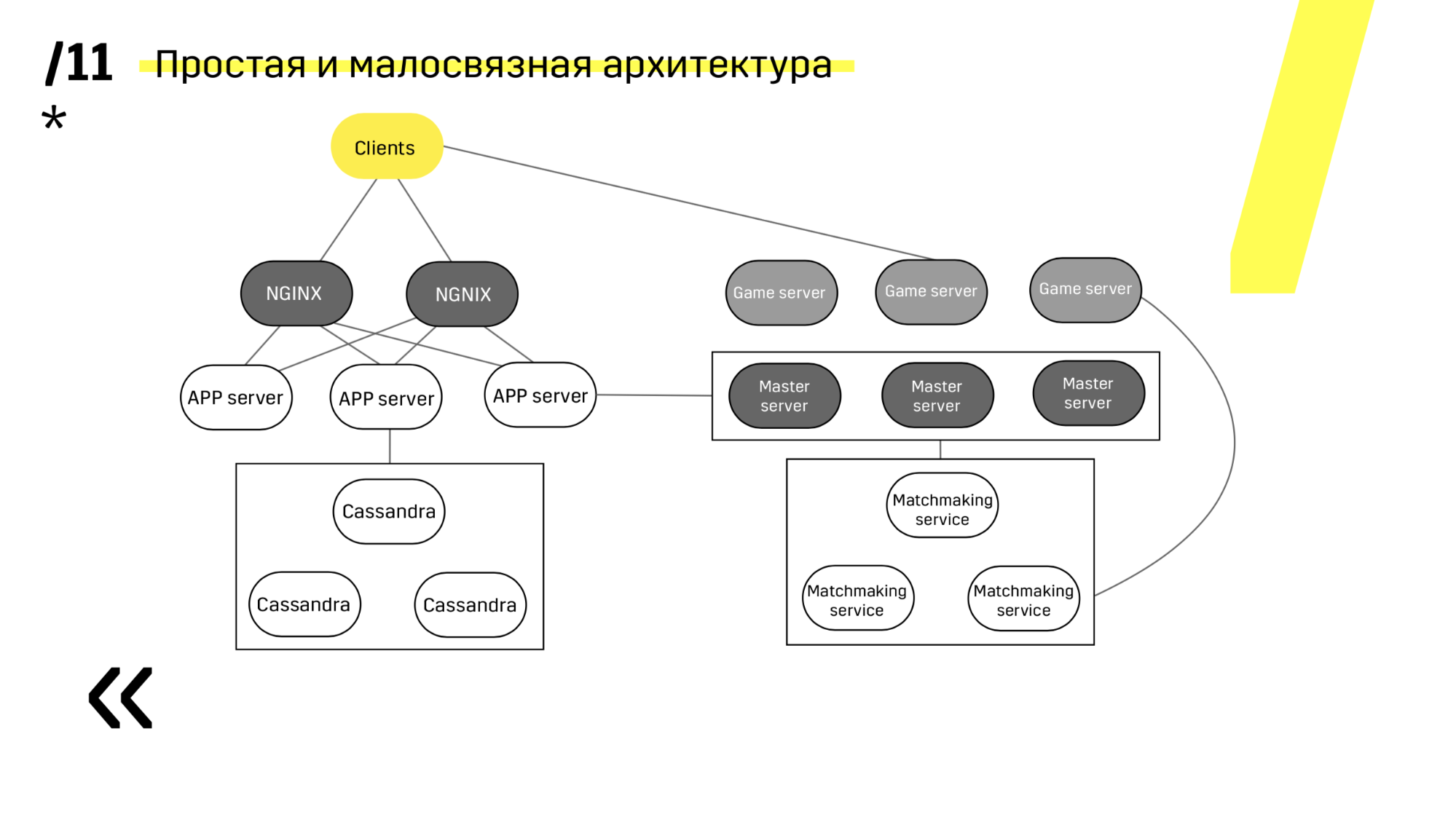
Смотрите, обновляем например app-сервер. У нас есть выделенные сервисы дискавери, которые реконфигурируют балансировщик, поэтому мы просто приходим к app-сервер, тушим его, он вылетает из балансировки, обновляем и все. И так с каждым по отдельности.
Мастер-сервера обновляются почти идентично. Клиент пингует каждый мастер-сервер в регионе и идет на тот, на котором пинг лучше. Соответственно, если мы обновляем мастер-сервер, то может быть игра чуть-чуть помедленнее будет идти, но обновляется это легко и просто.
Гейм-сервера обновляются немного по-другому, потому что там все-таки идет игра. Мы идем в матчмейкинг, просим его выкинуть определенный сервер с балансировки, приходим на гейм-сервер, ждем, пока игр не станет ровно ноль, и обновляем. Потом возвращаем обратно в балансировку.
Ключевой момент здесь, это ендпоинты, которые есть у каждого из компонентов, и с которыми легко и просто общаться. Если вам нужен пример, то есть Elasticsearch-кластер. При помощи обычных http-запросов в JSON можно легко с ним общаться. И он сразу в этом же JSON отдает всякие разные метрики и высокоуровневую информацию о кластере: зеленый, желтый, красный.
Проделав эти 12 шагов, мы увеличили количество окружений, стали больше тестировать, деплой у нас ускорился, люди начали получать быструю обратную связь.

Что очень важно, мы получили простоту и скорость экспериментов. А это очень важно, ведь когда много экспериментов, мы легко можем отсеять ошибочные идеи и остановится на верных. И не на основе каких-то субъективных оценок, а на основе объективных показателей.
На самом деле я уже и не слежу, когда у нас там деплой происходит, когда релиз. Нет этого ощущения «о, релиз!», всё собрались и мурашки по коже. Сейчас это такая рутинная операция, я в чатике периодически вижу, что что-то зарелизилось, ну и ладно. Это реально круто. Ваши сисадмины будут реветь от радости, когда вы так сделаете.
Но мир не стоит на месте, он иногда подпрыгивает. Нам есть, что улучшать. Например, логи билда хотелось бы тоже засунуть в Graylog. Это потребует еще доработать логирование, чтобы была не какая-то отдельная история, а четко: вот так билд собирался, так тестировался, так деплоился и так он ведет себя на проде. И continuous monitoring — с этим история посложнее.

Мы используем Zabbix, а он вообще не готов к таким подходам. Скоро выйдет 4-я версия, узнаем что там и если все плохо, то придумаем другое решение. Как это у нас получится — расскажу на следующем митапе.
А что происходит, когда вы задеплоили какой-то мусор в продакшн? Например, вы что-то по перформансу не рассчитали и на интегрейшене все ок, а в продакшене смотрите — у вас серваки начинают падать. Как вы откатываетесь обратно? Есть какая-то кнопка «спаси меня»?
Мы пробовали сделать автоматизацию обратной откатки. Можно потом на докладах рассказывать, как она классно работает, как все это замечательно. Но во-первых, мы разрабатываем так, чтобы версии были обратносовместимы и тестируем это. И когда мы сделали эту полностью автоматическую штуку, которая что-то там проверяет и обратно откатывает, а потом начали с этим жить, то поняли, что мы сил в нее вкладываем гораздо больше, чем если просто возьмем и той же самой педалью запустим старые версии.
По поводу автоматического обновления деплоя: почему вы вносите изменения на текущий сервер, а не добавляете новый и просто добавляете его в таргетгруп или балансер?
Так быстрее.
Например, если вам нужно обновить версию Java, вы меняете стейт инстенса на Амазоне, обновляя версию Java или еще что-то, то как вы откатываетесь в таком случае? Вы делаете изменения на рабочем сервере?
Да, каждый компонент работает прекрасно с новой версией и старой. Да, может быть придется перезалить сервер.
Бывают изменения стейтов, когда возможны большие проблемы…
Тогда взорвемся.
Просто мне кажется добавить новый сервер и просто поместить его за балансер в таргетгруп — небольшая по сложности задача и довольно хорошая практика.
Мы хостимся на железе, не в облаках. Нам добавить сервер — это можно, но немного дольше, чем просто в облаке накликать. Поэтому мы берем наш текущий сервер (у нас не такая загрузка, чтобы мы не могли вывести часть машин) — выводим часть машин, их обновляем, пускаем туда продашкн-трафик, смотрим, как это работает, если все окей, то докатываем дальше на все остальные машины.
Вы говорите, если каждый коммит собирается и если все плохо — разработчик сразу все правит. Как вы понимаете, что все плохо? Какие процедуры с коммитом проделываются?
Естественно, первое время это какое-то ручное тестирование, обратная связь медленная. Потом уже какими-то автотестами на Appium все это покрывается, работает и дает какую-то обратную связь о том, упали тесты или не упали.
Т.е. сначала каждый коммит выкатывается и тестеры его смотрят?
Ну не каждый, это практика. Мы одну практику из этих 12 пунктов сделали — ускорились. На самом деле это долгая и упорная работа, может быть в течении года. Но в идеале потом приходишь к этому и все работает. Да, нужны какие-то автотесты, хотя бы минимальный набор, о том что у тебя это все работает.
И вопрос поменьше: там на картинке App-сервер и так далее, вот что там мне интересно? Вы сказали, что Докера у вас вроде бы нет, что же такое сервер? Голая Java или что?
Где-то это Photon на винде (гейм-сервер), App-сервер — это Java-приложение на Томкате.
Т.е. никаких виртуалок, никаких контейнеров, ничего?
Ну Java это, можно сказать, контейнер.
И Ансиблом все это раскатывается?
Да. Т.е. в определенный момент мы просто не стали вкладываться в оркестракцию, потому что зачем? Если в любом случае винду надо будет точно так же менеджить отдельно, а тут одним инструментом покрывается абсолютно все.
А базу данных как деплоите? Зависимость к компоненту или к сервису?
В самом сервисе есть схема, которая задеплоит, когда он появился и нужно разрабатывать так, чтобы ничего не удаляли, а просто что-то добавлялось и было это обратно совместимо.
А база у вас тоже железная или база где-то в облаке в Амазоне?
Самая большая база железная, но есть и другие. Есть маленькие, RDS — это уже не железная, виртуальная. Те маленькие сервисы, которые я показывал: чаты, лиги, общение с фейсбуками, кланы, что-то из этого — RDS.
Мастер-сервер — что он из себя представляет?
Это, по сути, такой же гейм-сервер, только с признаком мастер и он является балансировщиком. Т.е. клиент пингует все мастера, потом получает тот, до которого пинг меньше, а уже мастер-сервер при помощи матчмейкинга собирает комнаты на гейм-серверах и отправляет игрока.
Я правильно понимаю, что на каждую выкатку вы пишите (если появились какие-то фичи) миграцию на обновление данных? Вы сказали, что берете старые артефакты и заливаете — а что с данными происходит при этом? Вы пишите миграцию на откат базы?
Это очень редкая операция с откатом. Да, пишешь ручками миграцию, а что делать.
Как обновление сервера синхронизируется с обновлениями клиента? Т.е. нужно вам новую версию игры выпустить — вы сначала обновите все сервера, потом обновятся клиенты? А сервер поддерживает и старую и новую версию?
Да, мы разрабатываем c feature toggling и feature dimming. Т.е. это специальная ручка, рычаг, который позволяет какую-то фичу включить потом. Можно абсолютно спокойно обновиться, увидеть то, что у тебя все работает, но фичу эту не включать. А когда ты уже клиента разогнал, тогда можешь фичидиммингом на 10% подкрутить, посмотреть, что все окей, а потом на полную.
Вы говорите, у вас отдельно хранятся части проекта в разных репозиториях, т.е. у вас есть какой-то процесс для разработки? Если вы меняете сам проект, то у вас тесты должны упасть, потому что вы поменяли проект. Значит тесты, которые лежат отдельно нужно, как можно быстрее поправить.
Я говорил вам про кита «плотное взаимодействие с тестировщиками». Эта схема с разными репозиториями очень хорошо работает, только если есть какое-то очень плотное общение. Для нас это не проблема, все друг с другом легко общаются, есть хорошая коммуникация.
Т.е. в вашей команде репозиторий с тестами поддерживают тестировщики? А автотесты отдельно лежат?
Да. Ты сделал какую-то фичу и можешь из репозитория тестировщиков набрать именно те автотесты, которые тебе нужны, а все остальное не проверять.
Такой подход, когда все быстро накатывается — вы можете себе позволить по каждому коммиту сразу идти в прод. Вы такой тактики и придерживаетесь или вы компонуете какие-то релизы? Т.е. раз в неделю, не по пятницам, не на выходных, какие-то у вас тактики релизные есть или фича готова, можно выпускать? Потому что, если вы делаете маленький релиз из маленьких фич, то у вас меньше шансов, что все сломается, а если что-то сломается, то вы точно знаете что.
Заставлять пользователей клиента каждые пять минут или каждый день новую версию скачивать — не айс идея. В любом случае ты будешь привязан к клиенту. Классно, когда у тебя web-проект, в котором ты можешь хоть каждый день обновляться и ничего не нужно делать. С клиентом история посложнее, у нас есть какая-то релизная тактика и мы ее придерживаемся.
Ты рассказал про автоматизацию выкатки на продуктовые сервера, а (я так понимаю) есть еще автоматизация выкатки на тест — а что с dev-средами? Есть ли какая-то автоматизация, разворачиваемая разработчиками?
Почти то же самое. Единственное, это уже не железные сервера, а в виртуалке, но суть примерно такая же. При этом на том же самом Ansible мы написали (у нас Ovirt) создание этой виртуалки и накатку на нее.
У вас вся история хранится в одном проекте вместе с продовыми и тестовыми конфигами Ansible или оно отдельно живет и развивается?
Можно сказать, что это отдельные проекты. Dev (devbox мы это называем) — это история, когда все в одном паке, а на проде — это распределенная история.
Начну с того, что игровая индустрия более рискованная — никогда не знаешь, что именно западет в сердце игроку. И поэтому мы создаем множество прототипов. Конечно, прототипы мы создаем на коленке из палочек, веревочек и других подручных материалов.
Казалось бы, при таком подходе сделать что-то, что потом можно будет поддерживать вообще невозможно. Но даже на этом этапе мы держимся. Держимся на трех китах:
- отличная экспертиза тестировщиков;
- плотное с ними взаимодействие;
- время, которое мы выдаем на тестирование.
Соответственно, если мы не выстроим свои процессы, например, деплой или CI (continuous integration) — рано или поздно мы придем к тому, что длительность тестирования все время будет увеличиваться и увеличиваться. И мы либо будем медленно все делать и потерям рынок, либо просто будем взрываться при каждом деплое.
Но CICD-процесс построить не так уж и просто. Некоторые скажут, ну да, я поставлю Jenkins, быстро что-то накликаю, вот у меня готовый CICD. Нет, это не только инструмент, это еще и практики. Начнем по порядку.
Первое. Во многих статьях пишут, что все нужно держать в одном репозитории: и код, и тесты, и деплой, и даже схему базы данных, и настройки IDE, общие для всех. Мы пошли своим путем.
Мы выделили разные репозитории: деплой у нас в одном репозитории, тесты — в другом. Это работает быстрее. Может быть вам не подойдет, но для нас это гораздо удобнее. Потому что есть один важный момент в этом пункте — нужно выстроить простой и прозрачный для всех гитфлоу. Конечно, вы можете где-то скачать готовый, но в любом случае его нужно под себя подстроить, улучшить. Для нас, например, деплой живет своим гитфлоу, который больше похож на GitHub-флоу, а серверная разработка живет по своему гитфлоу.
Следующий пункт. Нужно настроить полностью автоматическую сборку. Понятно, на первом этапе разработчик сам лично собирает проект, потом сам лично его деплоит при помощи SCP, сам запускает, сам отправляет, кому нужно. Этот вариант долго не прожил, появился bash-скрипт. Ну а так как окружение разработчиков все время меняется, появился специальный выделенный билдсервер. Он прожил очень долго, за это время мы успели увеличиться в серверах до 500, настроить конфигурирование серверов на Puppet, накопить на Puppet легаси, отказаться от Puppet, перейти на Ansible, а этот билдсервер продолжал жить.
Решили все поменять после двух звонков, третьего ждать не стали. История понятная: билдсервер — это единая точка отказа и, конечно же, когда нам нужно было что-то задеплоить, дата-центр полностью упал вместе с нашим билдсервером. А второй звонок: нам нужно было обновить версию Java — обновили на билдсервере, задеплоили на стейдж, все классно, все замечательно и тут же нужно было какой-то маленький багфикс запустить на прод. Конечно, мы забыли обратно откатить и все просто развалилось.
После этого переписали все так, чтобы весь билд мог происходить на абсолютно любом агенте TeamCity и переписали его на Ansible, потому что конфигурирование на Ansible, почему бы тогда этим же инструментом не воспользоваться и для деплоя.
Следующее правило: чем чаще коммитишь, тем лучше. А почему? Потому что есть четвертое: каждый коммит собирается. И на самом деле даже больше, чем каждый коммит. Я уже сказал, что у нас TeamCity, а он позволяет запустить коммит из вашей любимой IDE (вы догадываетесь, какую имею ввиду). Собственно, быстрая обратная связь, все замечательно.
Сломанный билд чинится сразу же. Как только ты настроил автоматический деплой, тут же нужно настроить автоматическую нотификацию в Slack. Все мы прекрасно знаем, что разработчик знает, как его код работает, только в тот момент, когда он его пишет. Поэтому: человек узнал — сразу же починил.
Тестируем на окружении, повторяющем прод. Тут все просто, мы выбрали Ansible и AWX. Кто-то может быть спросит, а как же Docker, Kubernetes, OpenShift, где все проблемы из коробки давным давно решены? Забыл сказать, у нас есть компоненты как Linux, так и Windows. И, например, Photon-сервер, который на Windows, мы только-только недавно смогли упаковать более менее нормально в 10 Гб докер-контейнер. Соответственно, у нас есть приложение на Windows, которое плохо упаковывается в контейнер; есть приложение на Linux (которое на Java), которое прекрасно запаковывается, но это и незачем, оно прекрасно работает, где бы ты его не запустил. Это же Java.
Дальше мы выбирали между Ansible и Chef. Они оба прекрасно работают с виндой, но Ansible оказался гораздо проще для нас. Когда мы уже установили AWX — вообще все огонь стало. В AWX есть секреты, есть графики, история. Можно вообще далекому от всего этого человеку показать, он сразу все увидит и все станет понятно.
И всегда нужно держать билд быстрым. Не знаю почему, но всегда, когда запускаешь новый проект, то про билдсервер, про агенты забываешь напрочь и выделяешь какой-то компьютер, который рядом валялся — вот это наш билдсервер. Эту ошибку повторять нежелательно, потому что все, о чем я говорю (быстрая обратная связь, плюсы) — оно все будет уже не таким актуальным, если на твоем собственном ноуте сборка будет запускаться гораздо быстрее, чем на какой-то ферме билдсерверов.
7 пунктов — и мы уже построили какой-то CI-процесс. Замечательно. На следующей схеме не видно, но сбоку есть еще Graylog. Кто читает наши статьи на Хабре, тот уже видел, как мы выбирали Graylog и как устанавливали. В любом случае он помогает отдебажить, если какая-то проблема все-таки случилась.
Вот на этой базе уже можно переходить к деплою.
Но про деплой я уже рассказал во втором пункте, поэтому не буду сильно останавливаться на этом. Скажу один лайфках: если вы используете Ansible, обязательно добавьте вот этот serial, который на слайде. Не раз бывало, что ты запускаешь что-то, а потом понимаешь, а я не то запустил, или не туда, или не то и не туда, а потом видишь, что это всего лишь один сервер. А мы потерять один сервер легко можем и ты просто его заново перезаливаешь, никто и не заметил.
Плюс установили хранилище артефактов на Nexus — он является единой точкой входа абсолютно для всех, не только для CI.
И это очень помогает нам обеспечить повторяемость. Ну и так как нексусы могут работать как прокси-сервисы в разных регионах, то они ускоряют деплой, установку rpm-пакетов, докер-образов, чего угодно.
Когда закладываешь новый проект, желательно выбирать компоненты, которые легко поддаются автоматизации. Например с Photon-сервером нам это не удалось. В любом случае, это было лучшее решение по другим параметрам. А вот Cassandra, например, очень удобно обновляется и автоматизируется.
Вот пример одного из наших проектов. Клиент приходи на APP-сервер, где у него лежит профиль в БД Cassandra, а потом идет на мастер-сервер, который при помощи матчмейкинга дает ему уже гейм-сервер с какой-то комнатой. Все остальные сервисы сделаны в виде «приложения — БД» и обновляется точно таким же образом.
Второй момент — нужно обеспечить простую малосвязанную архитектуру для деплоя. Нам это удалось.
Смотрите, обновляем например app-сервер. У нас есть выделенные сервисы дискавери, которые реконфигурируют балансировщик, поэтому мы просто приходим к app-сервер, тушим его, он вылетает из балансировки, обновляем и все. И так с каждым по отдельности.
Мастер-сервера обновляются почти идентично. Клиент пингует каждый мастер-сервер в регионе и идет на тот, на котором пинг лучше. Соответственно, если мы обновляем мастер-сервер, то может быть игра чуть-чуть помедленнее будет идти, но обновляется это легко и просто.
Гейм-сервера обновляются немного по-другому, потому что там все-таки идет игра. Мы идем в матчмейкинг, просим его выкинуть определенный сервер с балансировки, приходим на гейм-сервер, ждем, пока игр не станет ровно ноль, и обновляем. Потом возвращаем обратно в балансировку.
Ключевой момент здесь, это ендпоинты, которые есть у каждого из компонентов, и с которыми легко и просто общаться. Если вам нужен пример, то есть Elasticsearch-кластер. При помощи обычных http-запросов в JSON можно легко с ним общаться. И он сразу в этом же JSON отдает всякие разные метрики и высокоуровневую информацию о кластере: зеленый, желтый, красный.
Проделав эти 12 шагов, мы увеличили количество окружений, стали больше тестировать, деплой у нас ускорился, люди начали получать быструю обратную связь.
Что очень важно, мы получили простоту и скорость экспериментов. А это очень важно, ведь когда много экспериментов, мы легко можем отсеять ошибочные идеи и остановится на верных. И не на основе каких-то субъективных оценок, а на основе объективных показателей.
На самом деле я уже и не слежу, когда у нас там деплой происходит, когда релиз. Нет этого ощущения «о, релиз!», всё собрались и мурашки по коже. Сейчас это такая рутинная операция, я в чатике периодически вижу, что что-то зарелизилось, ну и ладно. Это реально круто. Ваши сисадмины будут реветь от радости, когда вы так сделаете.
Но мир не стоит на месте, он иногда подпрыгивает. Нам есть, что улучшать. Например, логи билда хотелось бы тоже засунуть в Graylog. Это потребует еще доработать логирование, чтобы была не какая-то отдельная история, а четко: вот так билд собирался, так тестировался, так деплоился и так он ведет себя на проде. И continuous monitoring — с этим история посложнее.
Мы используем Zabbix, а он вообще не готов к таким подходам. Скоро выйдет 4-я версия, узнаем что там и если все плохо, то придумаем другое решение. Как это у нас получится — расскажу на следующем митапе.
Вопросы из зала
А что происходит, когда вы задеплоили какой-то мусор в продакшн? Например, вы что-то по перформансу не рассчитали и на интегрейшене все ок, а в продакшене смотрите — у вас серваки начинают падать. Как вы откатываетесь обратно? Есть какая-то кнопка «спаси меня»?
Мы пробовали сделать автоматизацию обратной откатки. Можно потом на докладах рассказывать, как она классно работает, как все это замечательно. Но во-первых, мы разрабатываем так, чтобы версии были обратносовместимы и тестируем это. И когда мы сделали эту полностью автоматическую штуку, которая что-то там проверяет и обратно откатывает, а потом начали с этим жить, то поняли, что мы сил в нее вкладываем гораздо больше, чем если просто возьмем и той же самой педалью запустим старые версии.
По поводу автоматического обновления деплоя: почему вы вносите изменения на текущий сервер, а не добавляете новый и просто добавляете его в таргетгруп или балансер?
Так быстрее.
Например, если вам нужно обновить версию Java, вы меняете стейт инстенса на Амазоне, обновляя версию Java или еще что-то, то как вы откатываетесь в таком случае? Вы делаете изменения на рабочем сервере?
Да, каждый компонент работает прекрасно с новой версией и старой. Да, может быть придется перезалить сервер.
Бывают изменения стейтов, когда возможны большие проблемы…
Тогда взорвемся.
Просто мне кажется добавить новый сервер и просто поместить его за балансер в таргетгруп — небольшая по сложности задача и довольно хорошая практика.
Мы хостимся на железе, не в облаках. Нам добавить сервер — это можно, но немного дольше, чем просто в облаке накликать. Поэтому мы берем наш текущий сервер (у нас не такая загрузка, чтобы мы не могли вывести часть машин) — выводим часть машин, их обновляем, пускаем туда продашкн-трафик, смотрим, как это работает, если все окей, то докатываем дальше на все остальные машины.
Вы говорите, если каждый коммит собирается и если все плохо — разработчик сразу все правит. Как вы понимаете, что все плохо? Какие процедуры с коммитом проделываются?
Естественно, первое время это какое-то ручное тестирование, обратная связь медленная. Потом уже какими-то автотестами на Appium все это покрывается, работает и дает какую-то обратную связь о том, упали тесты или не упали.
Т.е. сначала каждый коммит выкатывается и тестеры его смотрят?
Ну не каждый, это практика. Мы одну практику из этих 12 пунктов сделали — ускорились. На самом деле это долгая и упорная работа, может быть в течении года. Но в идеале потом приходишь к этому и все работает. Да, нужны какие-то автотесты, хотя бы минимальный набор, о том что у тебя это все работает.
И вопрос поменьше: там на картинке App-сервер и так далее, вот что там мне интересно? Вы сказали, что Докера у вас вроде бы нет, что же такое сервер? Голая Java или что?
Где-то это Photon на винде (гейм-сервер), App-сервер — это Java-приложение на Томкате.
Т.е. никаких виртуалок, никаких контейнеров, ничего?
Ну Java это, можно сказать, контейнер.
И Ансиблом все это раскатывается?
Да. Т.е. в определенный момент мы просто не стали вкладываться в оркестракцию, потому что зачем? Если в любом случае винду надо будет точно так же менеджить отдельно, а тут одним инструментом покрывается абсолютно все.
А базу данных как деплоите? Зависимость к компоненту или к сервису?
В самом сервисе есть схема, которая задеплоит, когда он появился и нужно разрабатывать так, чтобы ничего не удаляли, а просто что-то добавлялось и было это обратно совместимо.
А база у вас тоже железная или база где-то в облаке в Амазоне?
Самая большая база железная, но есть и другие. Есть маленькие, RDS — это уже не железная, виртуальная. Те маленькие сервисы, которые я показывал: чаты, лиги, общение с фейсбуками, кланы, что-то из этого — RDS.
Мастер-сервер — что он из себя представляет?
Это, по сути, такой же гейм-сервер, только с признаком мастер и он является балансировщиком. Т.е. клиент пингует все мастера, потом получает тот, до которого пинг меньше, а уже мастер-сервер при помощи матчмейкинга собирает комнаты на гейм-серверах и отправляет игрока.
Я правильно понимаю, что на каждую выкатку вы пишите (если появились какие-то фичи) миграцию на обновление данных? Вы сказали, что берете старые артефакты и заливаете — а что с данными происходит при этом? Вы пишите миграцию на откат базы?
Это очень редкая операция с откатом. Да, пишешь ручками миграцию, а что делать.
Как обновление сервера синхронизируется с обновлениями клиента? Т.е. нужно вам новую версию игры выпустить — вы сначала обновите все сервера, потом обновятся клиенты? А сервер поддерживает и старую и новую версию?
Да, мы разрабатываем c feature toggling и feature dimming. Т.е. это специальная ручка, рычаг, который позволяет какую-то фичу включить потом. Можно абсолютно спокойно обновиться, увидеть то, что у тебя все работает, но фичу эту не включать. А когда ты уже клиента разогнал, тогда можешь фичидиммингом на 10% подкрутить, посмотреть, что все окей, а потом на полную.
Вы говорите, у вас отдельно хранятся части проекта в разных репозиториях, т.е. у вас есть какой-то процесс для разработки? Если вы меняете сам проект, то у вас тесты должны упасть, потому что вы поменяли проект. Значит тесты, которые лежат отдельно нужно, как можно быстрее поправить.
Я говорил вам про кита «плотное взаимодействие с тестировщиками». Эта схема с разными репозиториями очень хорошо работает, только если есть какое-то очень плотное общение. Для нас это не проблема, все друг с другом легко общаются, есть хорошая коммуникация.
Т.е. в вашей команде репозиторий с тестами поддерживают тестировщики? А автотесты отдельно лежат?
Да. Ты сделал какую-то фичу и можешь из репозитория тестировщиков набрать именно те автотесты, которые тебе нужны, а все остальное не проверять.
Такой подход, когда все быстро накатывается — вы можете себе позволить по каждому коммиту сразу идти в прод. Вы такой тактики и придерживаетесь или вы компонуете какие-то релизы? Т.е. раз в неделю, не по пятницам, не на выходных, какие-то у вас тактики релизные есть или фича готова, можно выпускать? Потому что, если вы делаете маленький релиз из маленьких фич, то у вас меньше шансов, что все сломается, а если что-то сломается, то вы точно знаете что.
Заставлять пользователей клиента каждые пять минут или каждый день новую версию скачивать — не айс идея. В любом случае ты будешь привязан к клиенту. Классно, когда у тебя web-проект, в котором ты можешь хоть каждый день обновляться и ничего не нужно делать. С клиентом история посложнее, у нас есть какая-то релизная тактика и мы ее придерживаемся.
Ты рассказал про автоматизацию выкатки на продуктовые сервера, а (я так понимаю) есть еще автоматизация выкатки на тест — а что с dev-средами? Есть ли какая-то автоматизация, разворачиваемая разработчиками?
Почти то же самое. Единственное, это уже не железные сервера, а в виртуалке, но суть примерно такая же. При этом на том же самом Ansible мы написали (у нас Ovirt) создание этой виртуалки и накатку на нее.
У вас вся история хранится в одном проекте вместе с продовыми и тестовыми конфигами Ansible или оно отдельно живет и развивается?
Можно сказать, что это отдельные проекты. Dev (devbox мы это называем) — это история, когда все в одном паке, а на проде — это распределенная история.