
В прошлой статье я рассказал как для целей прогнозирования выручки люди построили большой и сложный excel файл (можете почитать тут). Мы решили вмешаться в этот стыд и предложили переделать модель прогноза так, чтобы было меньше ошибок, проще эксплуатация, появилась гибкость в настройке.
Какие ключевые проблемы в описанной модели:
- Данные, модель и представления смешаны в одну сущность. Из-за этого изменение хотя бы в одном элементы разрушает весь этот монолит.
- Чрезмерный расчет на ручную обработку, что плодит ошибки и опечатки в огромных количествах.
Что мы предложили:
- В начальной модели нигде не фигурировали исходные данные на которых она была построена. Мы предложили внести эти данные в формате 2-ой нормальной формы в сам файл Excel на 2 отдельных листа (продажи и кол-во клиентов). Благо, данные по продажам в нашей агрегации по месяцам — это всего лишь десятки тысяч строк, а не миллионы. Так же мы настроили получение этих данных при помощи Power Query напрямую из базы данных.
- Мы создали лист моделирования, который состоит из 3-х блоков:
- Сводная таблица выручки
- Сводная таблица кол-ва клиентов
- Расчетная таблица средних чеков
Каждая сводная это сводная таблица построенная на исходных данных в нужной для текущего моделирования детализации по отделам и подразделениям, в нужной детализации по периодам (месяцам).

- В Листе моделирования мы построили простые модели прогнозирования на базе исторических временных рядов. Мы продлевали ряды кол-ва клиентов и средний чек, а общую прогнозную выручку считали как произведение этих величин. Просмотрев данные мы придумали 3 модели прогнозирования: медиана по прошлым периодам, экспоненциальное тройное сглаживание и обнуление (когда нам нужен 0 прогноз).

- Вычисления среднего чека (факта) и выручки (прогноза) производится не путем ссылки на ячейки, а с использованием ВПР и отметки смещения, что позволяет сделать расчеты устойчивым к изменениям в исходных данных.
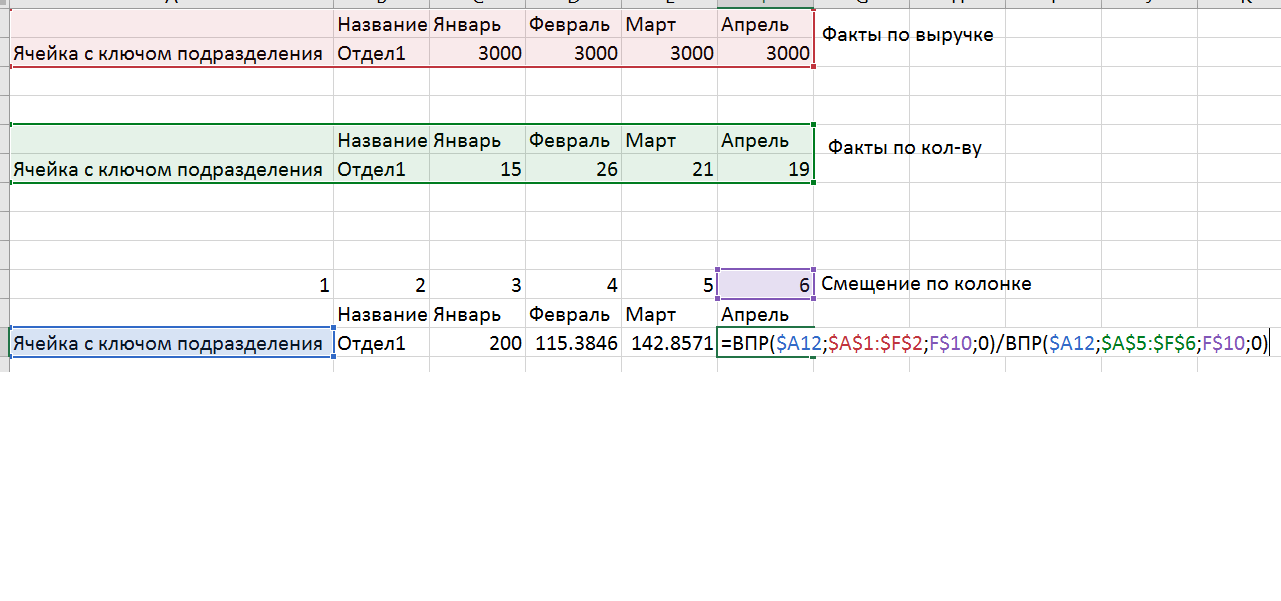
- Понятно, что теперь модель не читабельная пользователем, т.к. там слишком много значений. Для этого мы построили отдельные листы подразделений. Каждый лист имеет ячейку, которая выбирает, какие данные должны быть просуммированы в этот лист. На основе ВПР мы подтягиваем в лист данные с модельного листа.
- Само создание 30 листов по подразделениям сделано по специальной процедуре. Сначала создается первый лист, одного из подразделений, который содержит все возможные названия отделов. Если какого-то отдела в подразделении нет, то формулы подтягивают туда 0. Чтобы сделать все 30 подразделений, мы создаем дубликаты и меняем названия в управляющей ячейке (она используется для формирования ключа ВПР) и у нас оказываются нужные данные в форме представления. ВПР умеет использовать в качества ключа более 1 ячейки, если вы используете трюк: объедините нужные вам ячейки в одну при помощи конкатинации (функция СЦЕПИТЬ или символ &).
- В форму представления добавлен элемент, позволяющий управлять моделью: простой множитель к прогнозным значениям среднего чека и кол-ва. Этот элемент собирается на специальный технический лист при помощи функции ДВССЫЛ, которая позволяет использовать сгенерированную ссылку. С этого технического листа все эти корректировки при помощи ВПР переносятся на лист с моделью.

- Листы обобщения больше не является суммированием листов представления, а строятся точно так же, как и все остальные листы — путем суммирования данных на листе с моделью. В итоге представления являются чистыми представлениями и не имеют зависимостей между собой.
Что мы получили:
- Всегда понятно из каких цифр мы получили данные (т.к. сохранился запрос power Query).
- Мы можем изменить данные не сломав модель.
- Изменения в структуре и иерархии потребует небольших доработок (нужно изменить только названия в 1 листе представления и потом сделать его дубликаты).
- Мы радикально сократили кол-во потенциальных ошибок, т.к. большая часть данных заполняется при помощи формул, ссылок и ключей.
- Заказчик получил интерактивный прогноз, в котором он может менять значения сам и тут же получать прогноз.
- Смогли одновременно удовлетворить требованиям о том, что нам нужны данные и в годовом и месячном разрезе.
- Можно использовать в следующем бюджетном периоде.
- Можно менять модели прогнозирования, если эти нам покажутся не подходящими.
Почему мы решили остаться в экселе, а не переделали это на какие-то другие технологии?
- Нам нужно было оставить этот файл в эксплуатации текущих сотрудников. В рамках Excel нам проще показать, как все это работает и что они могут исправлять.
- Excel справляется с задачей и другие решения — лишние сущности.
- Заказчик привык к такой форме и его "переучивать" отдельные трудозатраты, которые мы не могли себе позволить.
Сколько нам понадобилось времени: примерно 5 рабочих дней, где 1 человек тратил по 2-4 часа в день и по итогам дня мы с ним делали ревью результатов.
vassabi
как говорится: «квадратиш. практиш. гут» ©