
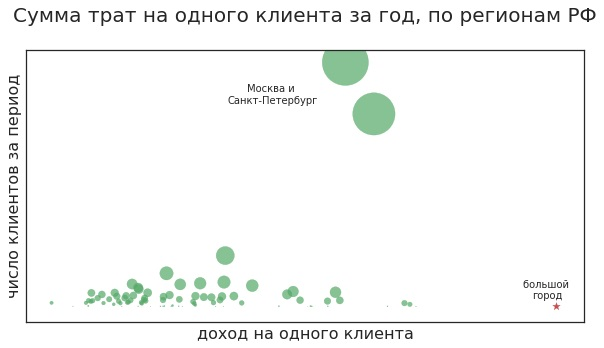
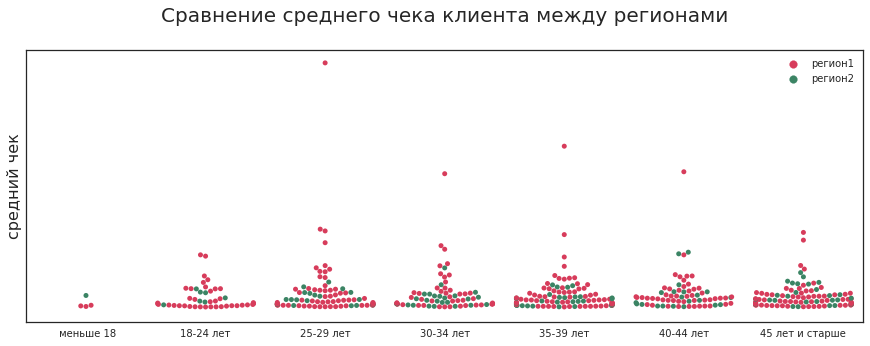
Какие вопросы имеются в виду? Например: уйдёт ли клиент? Нередко клиенты уходят, если в магазине нет нужного товара. Например, женщина каждый месяц покупает особый крем за 10 тысяч рублей и может выбирать из двух магазинов косметики. В одном из них часто отсутствует нужный товар, а во втором проблем с наличием нет. Скорее всего, она станет постоянно покупать во втором, пусть и чуть дороже.
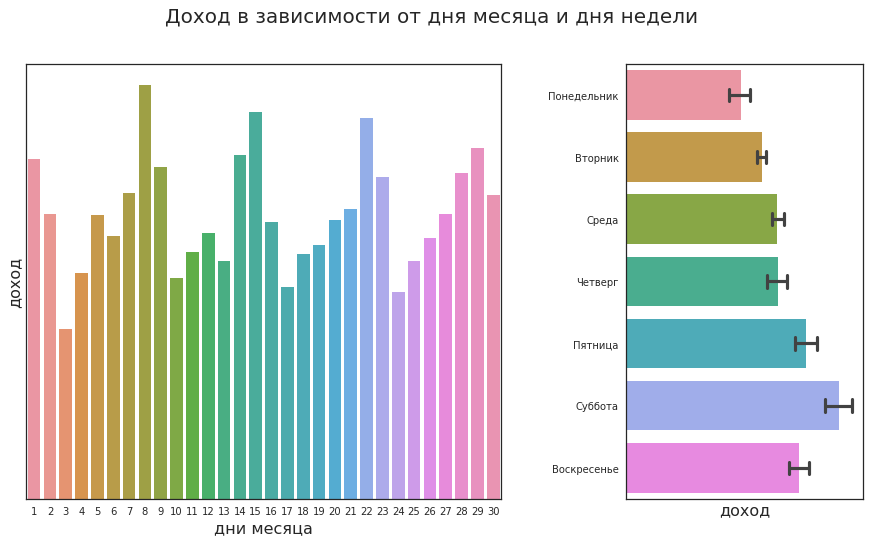
Другой актуальный вопрос: как оптимизировать работу персонала? Например, нужно спланировать рабочие смены кассиров и продавцов-консультантов. Один способ подразумевает использование статистического анализа. Аналитик оценивает активность клиентов в зависимости от дня недели и видит, что в субботу покупают больше всего, а в пятницу и в воскресенье чуть меньше. Эту гипотезу проверяют статистическими тестами, а выводы передают руководству.
Но такой анализ может не учитывать многих сочетаний факторов. Например, если 7 марта приходится на среду — купят ли в этот день больше, чем в пятницу (ведь в обычное время пятница – более популярный день, чем остальные будни)? А выпускные? Или местные праздники? Чем больше факторов, тем труднее их все учесть с помощью простых правил. И вместо того, чтобы бесконечно усложнять правила, можно построить модель, которая спрогнозирует спрос на конкретный день.
Наш проект в non-food ритейле
В данном случае нужно было проанализировать базу покупателей (примерно 2,5 млн человек) и предсказать, кто из них вернётся в магазин в ближайшие две недели. Мы взяли два метода библиотеки CatBoost — CatBoostClassifier и CatBoostRegressor, первая — для прогнозирования состава аудитории, вторая — для выбора самых востребованных товаров в ближайшие 2 недели. CatBoost вышел в самом начале нашего проекта, это был свежий подход к работе с категориальными признаками. А поскольку номенклатура товаров нашего заказчика содержит очень много категориальных фич, мы с удовольствием попробовали новинку в работе. После подбора параметров модель сразу же оправдала наши надежды точным прогнозированием. Не зря CatBoost — одна из самых популярных сегодня моделей градиентного бустинга.
Для модели взяли статистику за 2017 год:
- чеки: кому принадлежит бонусная карта из чека, когда сделана покупка, что купили, размер скидки, покупка это или возврат.
- демография: регион и город проживания клиента, дата рождения и пол, согласия на рассылки по телефону или почте.
- товары: к какой категории или сегменту относятся покупки, область применения и т.д.
Очистили данные от шума (карты продавцов, возвраты, покупки услуг, а не товаров) и посчитали нужные критерии (процент скидки, возраст). После этого вычислили самый большой и самый маленький чек у каждого покупателя, среднюю, медианную и максимальную скидку, сколько раз человек приходил и сколько товаров из каких категорий покупал. Эти параметры пересчитали на промежутки: последняя неделя, две недели, месяц, три месяца. Такая скрупулезная работа позволила построить модели с высокой точностью прогнозирования.
Агрегировали данные для моделей и запустили расчёты. Первая модель предсказала, кто из покупателей придёт в ближайшие две недели, а вторая выдавала рекомендации: какие товары (до уровня артикула) купит конкретный человек. Кстати, требование прогнозировать популярность конкретных артикулов значительно усложняло задачу (обычно бизнесу достаточно прогнозов по категориям и наименованиям товаров, а не позициям).
Клиенты, рекомендованные моделью для целевой рассылки, за один визит имели более крупный медианный чек, а за анализируемый период купили суммарно на бо?льшую сумму, чем прочие клиенты.
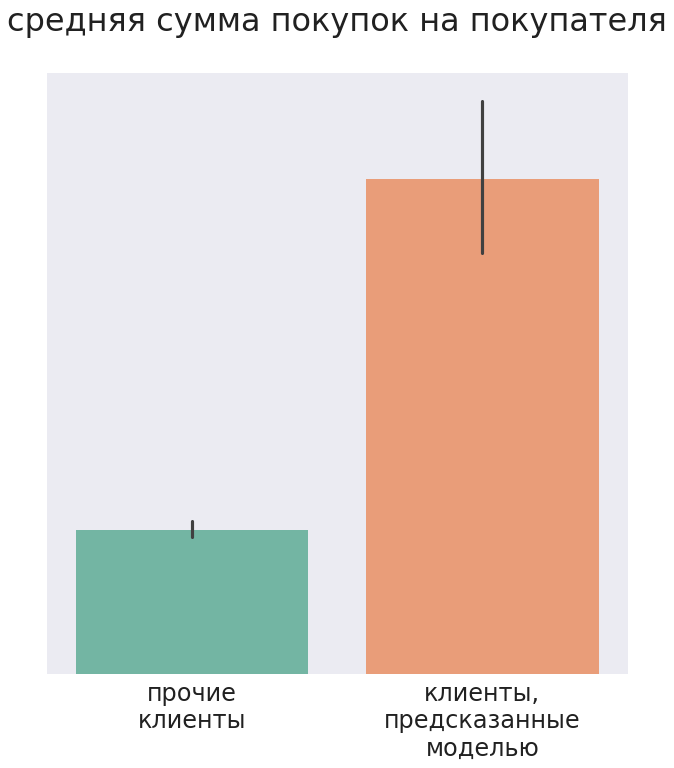
В итоге после рассылки около 30% клиентов приобрели хотя бы один товар из трех, предсказанных моделью.
Теперь компания может точнее прогнозировать продажи: ритейлер знает, кто придет к нему в ближайшее время и что купит. Это помогает не только оптимизировать логистику, но и снизить сопутствующие расходы. Например, если конкретный клиент обычно ничего не покупает зимой, то не нужно отправлять ему SMS в январе. Модели также оптимизируют рассылки: специалист на основе прогноза сразу понимает, кому отправить e-mail, а кому — срочное SMS.
Подводные камни
Они есть в любой ML-задаче — были и в нашей. Например, мы проверяли, помогают ли рассылки с рекомендациями товаров повысить продажи. Для этого предсказанный сегмент покупателей разделили на три группы:
- Контрольная — рассылку не получали.
- Группа с напоминаниями — получали общий текст от магазина.
- Группа с рекомендациями — получали SMS с тремя конкретными товарами, предсказанными моделью.
Оказалось, что люди, получившие рекомендации, покупали меньше, чем клиенты, не получавшие рассылок. Меньше был и средний чек, и количество приобретенных товаров. T-тест показал, что различия были статистически значимы (pvalue=0,017).
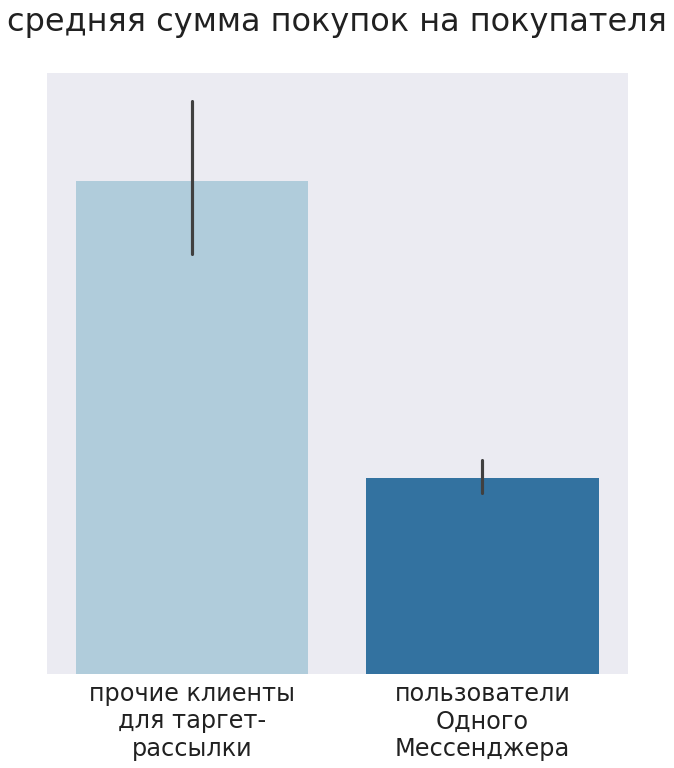
Мягко говоря, такие результаты всех обескуражили. Стали искать причину и выяснили, что магазины отправляли клиентам сообщения в определенный мессенджер, а его пользователи в нашем сегменте изначально покупали меньше по сравнению с другими клиентами. Об этом не знали даже маркетологи заказчика. Так что эксперимент получился некорректным, но по его результатам мы добавили в модель параметр «пользователь мессенджера». Этот случай демонстрирует, как тщательно нужно выбирать каналы для общения с клиентами.
Какие ещё можно сделать выводы?
- Данных много не бывает.
- Иногда взгляд аналитика со стороны приводит к свежей идее.
Сегментация клиентов
Анализ данных позволяет обнаружить закономерности, которые были скрыты в ранее доступной информации. Хорошим примером служит сравнение групп клиентов с помощью RFM-сегментации (Recency Frequency Monetary) и сегментации с использованием алгоритмов ML.
В RFM-сегментации используются три основных показателя:
- давность последней покупки,
- частота покупок за период,
- сумма, потраченная клиентом.
На основании этих данных выделяют основные группы: «транжиры», «лояльные клиенты», «почти потерянные клиенты» и т.п. А маркетологи уже включают нужную целевую группу в определенную рассылку или делают предложение именно для этой группы.
Например, с помощью RFM-сегментации можно выделить сегменты покупателей и представить их как точки в трехмерном пространстве:
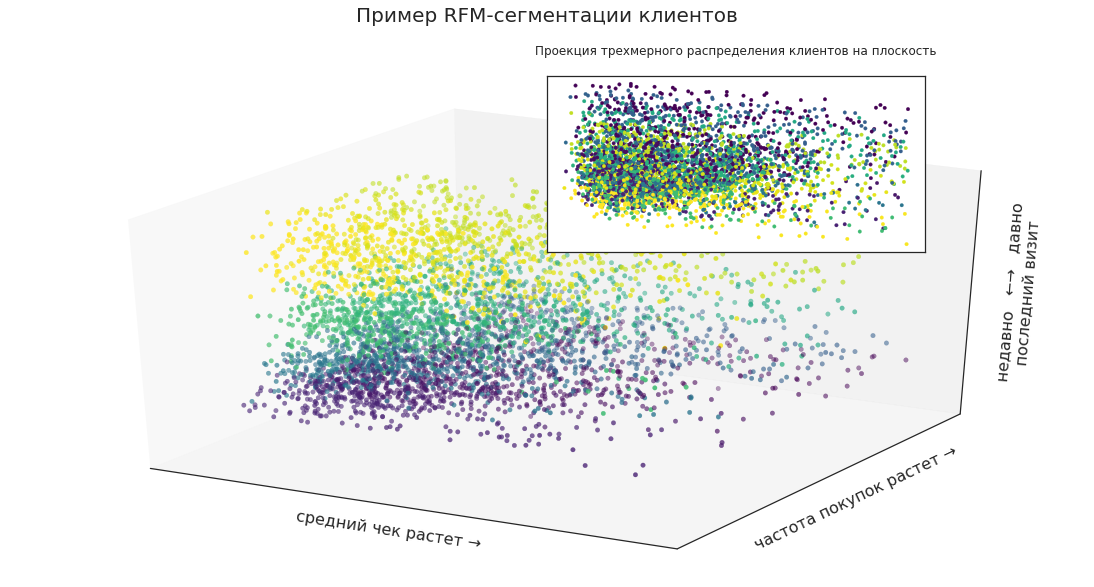
Это позволяет наглядно увидеть расположение определённых групп в общей массе клиентов, их пропорции и динамику изменений.
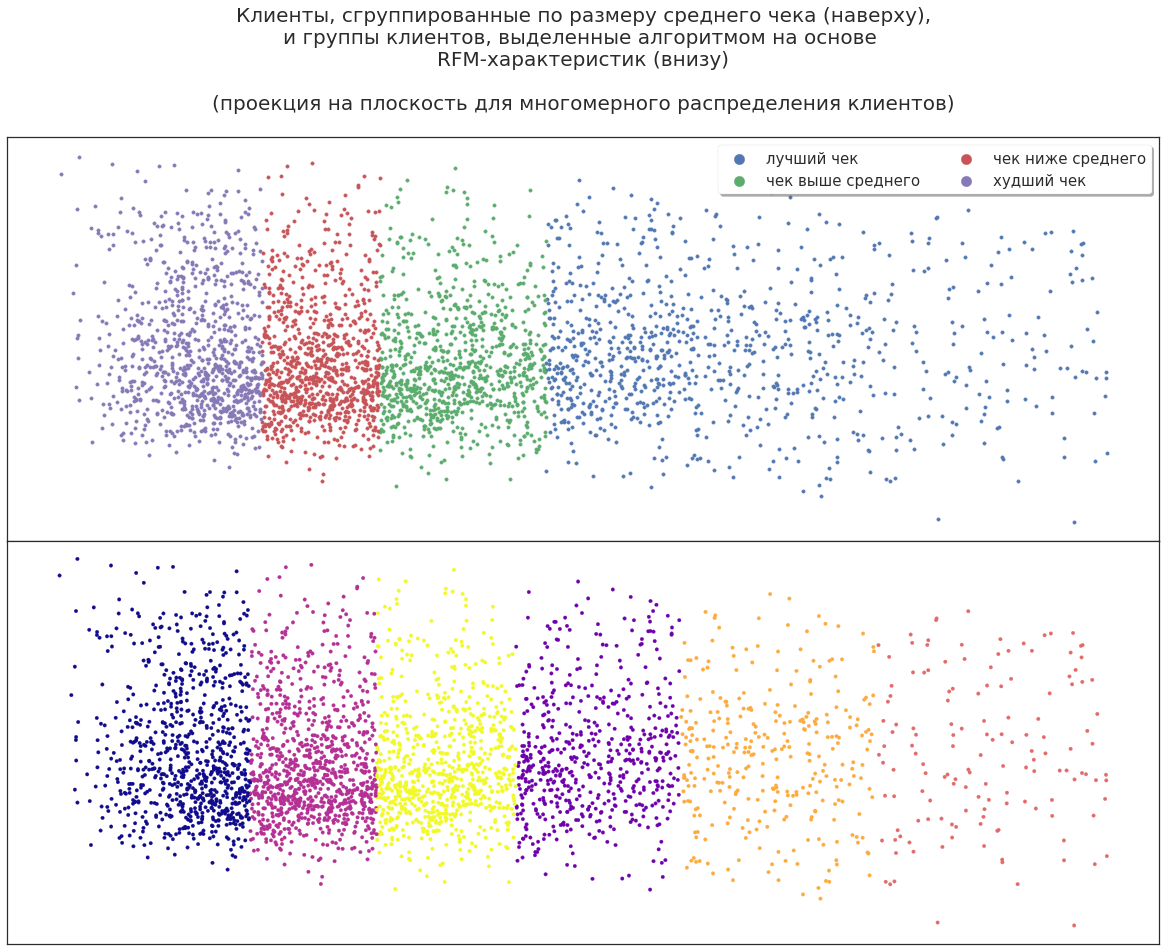
Теперь спроецируем трёхмерное распределение сегментов на плоскость. Клиентов можно разделить по приносимому компании доходу, чтобы включать в маркетинговые кампании самых прибыльных, но будет ли этого достаточно для эффективного планирования?
Даже в таких данных алгоритм машинного обучения находит дополнительные возможности: разбивает клиентов на новые большие группы. Можно проанализировать это разбиение, чтобы выяснить, почему алгоритм именно так разделил клиентов. Например, некоторые высокодоходные клиенты — эксперты, которые сопровождают своих заказчикаов на шоппинге и используют свои скидочные карты; некоторые активно делятся своими карточками с друзьями и знакомыми. То есть после первого применения ML можно получить дополнительную информацию о своих клиентах на основе всё тех же данных.
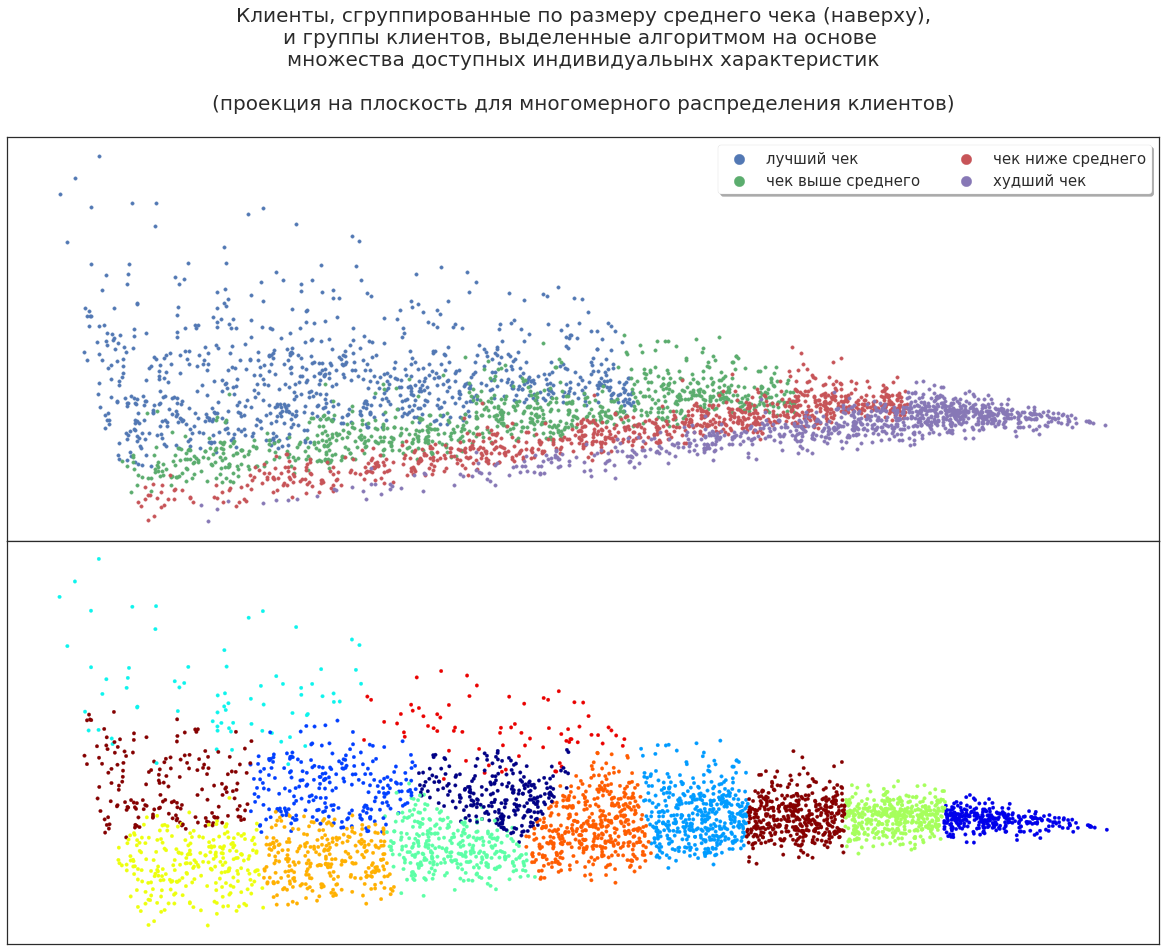
Давайте расширим набор характеристик клиентов: добавим пол, возраст, особенности поведения и прочее. Как теперь алгоритм распределит покупателей?
Например, есть группа, которая охватывает как лучших клиентов (самых прибыльных), так и их «соседей», приносящих меньшую прибыль. Почему алгоритм выделил эту группу — вопрос для аналитика. Быть может, эти клиенты при дополнительном стимулировании покажут большую доходность. Или, напротив, эти клиенты не особо перспективны и повышение доходности было случайным отклонением, — стимулировать их дополнительно бессмысленно. Можно выдвинуть различные теории, но проверять их приходится экспериментально.
Планирование складов — прогнозирование продаж
Дальше у проекта возможны несколько вариантов развития. Например, можно прогнозировать покупки в конкретном магазине на ближайший период. Тогда администратор магазина сможет вовремя заказать с центрального склада нужные товары.
Анализ покупок в конкретной торговой точке поможет сформировать и выкладку товаров на витринах. К примеру, если в магазин приходит много покупателей-мужчин, отдел с мужской продукцией не стоит размещать в дальнем углу.
Нельзя забывать о так называемой каннибализации магазинов. То есть, если две точки продаж одной сети находятся рядом (например, в разных концах одной улицы), одна из них может оттягивать клиентов на себя, а вторая будет простаивать. Можно построить модель, которая станет отслеживать подобные явления и сигнализировать об этом.
***
Одним словом, машинное обучение — мощный инструмент, который может многое. Часто при построении моделей выявляются неочевидные закономерности, о которых не знали даже бизнес-пользователи. Однако качество модели очень сильно зависит от качества и количества данных.
Аналитики Дирекции по разработке и внедрению ПО, «Инфосистемы Джет»
Комментарии (18)

Helgich
20.11.2018 09:38Божественные диаграммы! Полное отсутствие читабельности!

ivansibaha
20.11.2018 15:18я так понял, они после уменьшения размерности.
Helgich
20.11.2018 15:56+1они просто красивые, разноцветные, информация представлена в неочевидном виде. Там, где должно быть по одному значению каждого цвета (вторая сверху), налеплено точек так… я вот не понимаю, что они там все делают?
У 3Д информативность нулевая.
В общем надо или уделять визуализации данных больше внимания или всё таблицами предоставлять, проще будет.
Vplusplus
20.11.2018 23:18Нет, это тоже спам, только маркетинговый. Сложная диаграмма, красивая, но не понятная никому.
RuGrof
20.11.2018 12:29Хм… а если просто сделать мобильное приложение, где можно будет подписаться на акции по интересующему товару и предлагать пользователю подписываться на уведомления по покупаемому им товаром. Ну в уведомлениях писать «Товар рекомендованный искуственным интелектом».
SGordon123
20.11.2018 14:08А объем выборок не подскажете, когда это можно применять? Сеть Десяток магазинов, десяток — другой покупателей в день ( в зависимости от магазина) покупают пяток товаров на чек… Есть смысл анализировать?
JetHabr Автор
20.11.2018 15:55Датасет в несколько миллионов покупателей, десятки магазинов.
SGordon123
20.11.2018 16:33Это у Вас… Интересует начиная с каких объемов это может начать работать?
JetHabr Автор
20.11.2018 17:32Это может быть и один магазин с хорошо налаженным сбором данных о не очень многочисленных покупателях и транзакциях на протяжении нескольких лет. Или большая сеть, собравшая данные за несколько месяцев с несколькими миллионами транзакций. В конечном счете всё упирается именно в доступность данных.
Очевидно, что крафтовой лавке с десятком покупателей в месяц смысла нет точно, а сети, скажем, из десятка ларьков с фруктами может быть полезно, если они собирают данные о своих покупателях и их покупках.

McCow
22.11.2018 11:34Думаю понятие «статистической значимости» здесь применимо на 99,99%. Меня учили, что при анализе «человеков» ((С) Футурама) объём выборки в 1000 — минимально достаточен. При уменьшении этого числа точность деградирует значительно сильнее, чем повышается при его (даже значительном) увеличении.
Другими словами: 1000 — нормуль, 10000 — хорошо, 1 млн. — ещё лучше, 500 — скорее всего полня фигня.
HAPPYV0DKA
20.11.2018 14:49Какие обозначения приняты для нижней диаграммы?
JetHabr Автор
20.11.2018 15:55Это визуализация методом главных компонент: проекция на плоскость положения точек относительно друг друга в многомерном пространстве. Соответственно, оси — компонента 1 и компонента 2.
Fontanka135
21.11.2018 12:24Стали искать причину и выяснили, что магазины отправляли клиентам сообщения в определенный мессенджер, а его пользователи в нашем сегменте изначально покупали меньше по сравнению с другими клиентами. Об этом не знали даже маркетологи заказчика. Так что эксперимент получился некорректным, но по его результатам мы добавили в модель параметр «пользователь мессенджера»
Вам бы вообще стоило начать с корректной постановки задачи для A/B и A/A тестов, прежде чем фичи добавлять.
JetHabr Автор
21.11.2018 14:20У заказчика есть определенные ограничения, о которых не всегда известно в момент планирования эксперимента, плюс накладываются внешние факторы — например, решение о канале рассылки может приниматься не теми сотрудниками, с которыми вы планируете эксперимент. Выявленная нами особенность поведения этой группы покупателей стала новой информацией для маркетинга и была учтена в последующих экспериментах.
KinsleR
Оказалось, что люди, получившие рекомендации, покупали меньше, чем клиенты, не получавшие рассылок
Никто не любит спам :)
Furriest
Не факт, что тут именно про спам. Например, когда мне от одной крупной федеральной сети приходит рассылка о скидках на крепкий алкоголь — я чаще всего заезжаю в магазин именно за ним, а из прочего покупаю то, что вспомнится на бегу. А в другой день, без рассылки, я в тот же магазин наеду с готовым списком покупок, существенно превышающим первый кейс и по количеству позиций, и по сумме затрат.
JetHabr Автор
Ваше предположение вполне жизненное и тоже имеет право на существование, но в нашем случае была выявлена другая закономерность.
Мы сравнивали средний чек пользователей «одного мессенджера» (конкретного канала получения информации) со всеми остальными клиентами, вошедшими в таргет-рассылку (как получившими в итоге напоминание и/или рекомендации, так и нет). Конкретно для этих пользователей «одного мессенджера» средний чек был заметно ниже, чем для остальных в таргет-рассылке. Это может быть связано с большим числом факторов (этим мессенджером в принципе пользуются менее выгодные магазину клиенты, или менее выгодные клиенты оставляют этот мессенджер в качестве контакта при заполнении анкеты, или что-то еще), теорий может быть много.