
Пользуясь случаем хочется выразить благодарность сообществу CoreHard за организацию очередной большой конференции в Минске и за предоставленную возможность выступить. А также за оперативную публикацию видеозаписей докладов на YouTube.
Итак, давайте перейдем к основной теме разговора. А именно к тому, какие подходы к упрощению многопоточного программирования в C++ мы можем использовать, как в коде будет выглядеть использование некоторых из этих подходов, какие особенности присущи конкретным подходам, что между ними общего и т.д.
Примечание: в оригинальной презентации к докладу были обнаружены ошибки и опечатки, поэтому в статье будут использованы слайды из обновленной и отредактированной версии, которую можно найти в Google Slides или на SlideShare.
«Голая многопоточноть» — это зло!
Начать нужно с многократно повторенной банальности, которая, тем не менее, все еще остается актуальной:
Многопоточное программирование на C++ посредством голых нитей, mutex-ов и condition variables – это пот, боль и кровь.
Хороший пример был недавно описан вот в этой статье здесь, на Хабре: "Архитектура мета-сервера мобильного онлайн-шутера Tacticool". В ней ребята рассказали о том, как они умудрились собрать, по всей видимости, полный спектр граблей, связанных с разработкой многопоточного кода на C и С++. Там были и «проходы» по памяти в результате гонок, и невысокая производительность из-за неудачного распараллеливания.
В результате все закончилось вполне закономерно:
Через пару недель, потраченных на поиск и исправление наиболее критических багов, мы решили, что проще переписать все с нуля, чем пытаться исправить все недостатки текущего решения.
Люди наелись C/С++ при работе над первой версией своего сервера и переписали сервер на другом языке.
Отличная демонстрация того, как в реальном мире, вне нашего уютного C++сообщества, разработчики отказываются от использования С++ даже там, где применение C++ все еще уместно и оправдано.
Но почему?
Но почему же, если многократно говорено, что «голая многопоточность» на C++ — это зло, люди продолжают использовать ее с упорством, достойным лучшего применения? Что тому виной:
- незнание?
- лень?
- NIH-синдром?
Ведь существует далеко не один проверенный временем и множеством проектов подход. В частности:
- actors
- communicating sequential processes (CSP)
- tasks (async, promises, futures, ...)
- data flows
- reactive programming
- ...
Остается надеяться, что основная причина — это все таки незнание. Вряд ли этому учат в ВУЗах. Значит молодые специалисты, приходя в профессию, используют то немногое, что им уже знакомо. И если затем багаж знаний затем не пополняется, то люди так и продолжают использовать голые threads, mutexes и condition_variables.
Сегодня мы поговорим о трех первых подходах из этого списка. Причем поговорим не абстрактно, а на примере одной простенькой задачки. Попробуем показать, как будет выглядеть решающий эту задачу код с использованием Actor-ов, CSP-шных процессов и каналов, а также с применением Task-ов.
Задача для экспериментов
Требуется реализовать HTTP-сервер, который:
- принимает запрос (ID картинки, ID пользователя);
- отдает картинку с «водяными знаками», уникальными для этого пользователя.
Например, такой сервер может потребоваться некому платному сервису, раздающему контент по подписке. Если картинка из этого сервиса затем где-то «всплывет», то по «водяным знакам» на ней можно будет понять, кому нужно «перекрыть кислород».
Задача абстрактная, она была сформулирована специально для данного доклада под влиянием нашего демо-проекта Shrimp (мы о нем уже рассказывали: №1, №2, №3).
Этот наш HTTP-сервер будет работать следующим образом:
 |
Получив запрос от клиента мы обращаемся к двум внешним сервисам:
- первый возвращает нам информацию о пользователе. В том числе оттуда мы получаем картинку с «водяными знаками»;
- второй возвращает нам исходное изображение
Оба эти сервиса работают независимо и мы можем обращаться к ним обоим одновременно.
Поскольку обработку запросов можно делать независимо друг от друга, и даже некоторые действия при обработке одного запроса можно делать параллельно, то напрашивается использование конкурентности. Самое простое, что приходит в голову, — это создание отдельной нити на каждый входящий запрос:
 |
Но модель «один-запрос=один-рабочий-поток» слишком дорогостоящая и она плохо масштабируется. Нам это не нужно.
Даже если подойти к количеству рабочих потоков расточительно, то все равно нам потребуется небольшое их количество:
 |
Здесь нам нужен отдельный поток для приема входящих HTTP-запросов, отдельный поток для собственных исходящих HTTP-запросов, отдельный поток для координации обработки принятых HTTP-запросов. А так же пул рабочих потоков для выполнения операций над изображениями (поскольку манипуляции над изображениями хорошо параллелятся, то обрабатывая картинку сразу не нескольких потоках мы сокращаем время ее обработки).
Следовательно, наша цель в том, чтобы обрабатывать большое количество параллельных входящих запросов на небольшом количестве рабочих нитей. Давайте посмотрим на то, как мы этого достигнем с помощью различных подходов.
Несколько важных disclaimer-ов
Прежде чем перейти к основному рассказу и разбору примеров кода нужно сделать несколько примечаний.
Во-первых, все нижеследующие примеры не привязаны к какому-то конкретному фреймворку или библиотеке. Любые совпадения в именах API-ных вызовов являются случайными и непреднамеренными.
Во-вторых, в приведенных ниже примерах нет обработки ошибок. Сделано это преднамеренно, дабы слайды получились компактными и обозримыми. А также чтобы материал уместился в отведенное на доклад время.
В-третьих, в примерах используется некая сущность execution_context, которая содержит информацию о том, что еще существует внутри программы. Наполнение этой сущности зависит от подхода. С случае с акторами в execution_context будут ссылки на других акторов. В случае с CSP, в execution_context будут CSP-шные каналы для связи с другими CSP-шными процессами. И т.д.
Подход №1: Actors
Про Модель Акторов в двух словах
При использовании Модели Акторов решение будет строится из отдельных объектов-акторов, каждый из которых обладает собственным приватным состоянием и это состояние недоступно никому, кроме самого актора.
Акторы взаимодействуют друг с другом посредством асинхронных сообщений. У каждого актора есть собственный уникальный почтовый ящик (очередь сообщений), в который отосланные актору сообщения сохраняются и откуда они извлекаются для последующей обработки.
Акторы работают по очень простым принципам:
- актор – это некая сущность, обладающая поведением;
- акторы реагируют на входящие сообщения;
- получив сообщение актор может:
- отослать некоторое (конечное) количество сообщений другим акторам;
- создать некоторое (конечное) количество новых акторов;
- определить для себя новое поведение для обработки последующих сообщений.
Внутри приложения акторы могут быть реализованы по-разному:
- каждый актор может быть представлен в виде отдельного потока ОС (это происходит, например, в С++ библиотеке Just::Thread Pro Actor Edition);
- каждый актор может быть представлен в виде stackful coroutine;
- каждый актор может быть представлен в виде объекта у которого кто-то вызывает методы-коллбэки.
Мы в своем решении будем использовать акторы в виде объектов с коллбэками, а сопрограммы оставим для CSP-подхода.
Схема решения на базе Модели Акторов
На базе акторов общая схема решения нашей задачи будет выглядеть следующим образом:
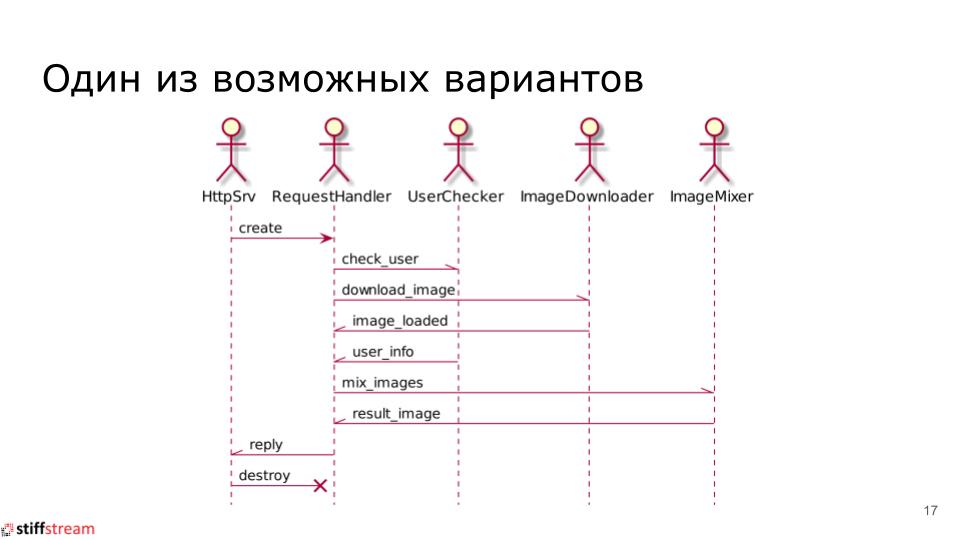 |
У нас будут акторы, которые создаются при старте HTTP-сервера и существуют все время, пока HTTP-сервер работает. Это такие акторы как: HttpSrv, UserChecker, ImageDownloader, ImageMixer.
При получении нового входящего HTTP-запроса мы создаем новый экземпляр актора RequestHandler, который будет уничтожен после выдачи ответа на входящий HTTP-запрос.
Код актора RequestHandler
Реализация актора request_handler, который координирует обработку входящего HTTP-запроса может иметь следующий вид:
class request_handler final : public some_basic_type {
const execution_context context_;
const request request_;
optional<user_info> user_info_;
optional<image_loaded> image_;
void on_start();
void on_user_info(user_info info);
void on_image_loaded(image_loaded image);
void on_mixed_image(mixed_image image);
void send_mix_images_request();
... // вся специфическая для фреймворка обвязка.
};
void request_handler::on_start() {
send(context_.user_checker(), check_user{request_.user_id(), self()});
send(context_.image_downloader(), download_image{request_.image_id(), self()});
}
void request_handler::on_user_info(user_info info) {
user_info_ = std::move(info);
if(image_)
send_mix_images_request();
}
void request_handler::on_image_loaded(image_loaded image) {
image_ = std::move(image);
if(user_info_)
send_mix_images_request();
}
void request_handler::send_mix_images_request() {
send(context_.image_mixer(),
mix_images{user_info->watermark_image(), *image_, self()});
}
void request_handler::on_mixed_image(mixed_image image) {
send(context_.http_srv(), reply{..., std::move(image), ...});
}Давайте разберем этот код.
У нас есть класс, в атрибутах которого мы храним или собираемся хранить то, что нам потребуется для обработки запроса. Также в этом классе есть набор коллбэков, которые будут вызываться в тот или иной момент.
Сперва, когда актор только-только создан, вызывается коллбэк on_start(). В нем мы отсылаем два сообщения другим акторам. Во-первых, это сообщение check_user для проверки ID клиента. Во-вторых, это сообщение download_image для загрузки исходного изображения.
В каждом из отосланных сообщений мы передаем ссылку на самих себя (вызов метода self() возвращает ссылку на актора, для которого вызвали self()). Это необходимо для того, чтобы нашему актору можно было отослать сообщение в ответ. Если мы ссылку на своего актора не отошлем, например, в сообщении check_user, то актор UserChecker не будет знать, кому же прислать информацию о пользователе.
Когда нам в ответ присылают сообщение user_info с информацией о пользователе, то вызывается коллбэк on_user_info(). А когда нам присылают сообщение image_loaded, то у нашего актора вызывается коллбэк on_image_loaded(). И вот внутри этих двух коллбэков мы видим особенность, присущую Модели Акторов: мы не знаем точно, в каком порядке нам придут ответные сообщения. Поэтому мы должны написать свой код так, чтобы не зависеть от порядка поступления сообщений. Поэтому в каждом из обработчиков сперва сохраняем в соответствующем атрибуте поступившую информацию, а затем проверяем, может у нас уже собрана вся нужная нам информация? Если это так, то мы можем двигаться дальше. Если нет, то будем ждать дальше.
Именно поэтому у нас в on_user_info() и on_image_loaded() есть if-ы, при выполнении которых вызывается send_mix_images_request().
В принципе, в реализациях Модели Акторов могут быть механизмы вроде selective receive из Erlang-а или stashing-а из Akka, посредством которых можно манипулировать порядком обработки входящих сообщений, но об этом сегодня говорить не будем, дабы не углубляться в дебри деталей различных реализаций Модели Акторов.
Итак, если вся нужная нам информация от UserChecker и ImageDownloader получена, то вызывается метод send_mix_images_request(), в котором актору ImageMixer отсылается сообщение mix_images. Коллбэк on_mixed_image() вызывается когда нам приходит ответное сообщение с результирующим изображением. Тут мы пересылаем это изображение актору HttpSrv и ждем пока HttpSrv сформирует HTTP-ответ и уничтожит ставшего ненужным RequestHandler-а (хотя, в принципе, ничто не мешает актору RequestHandler-у самоуничтожится в коллбэке on_mixed_image()).
Вот, собственно и все.
Реализация актора RequestHandler получилась довольно объемная. Но это за счет того, что нам нужно было описать класс с атрибутами и коллбэками, а затем еще и реализовать коллбэки. Но сама логика работы RequestHandler-а весьма тривиальная и разобраться в ней, не смотря на объем кода класса request_handler, несложно.
Особенности, присущие акторам
Теперь мы можем сказать несколько слов об особенностях Модели Акторов.
Акторы реактивны
Как правило, акторы реагируют только на входящие сообщения. Есть сообщения — актор их обрабатывает. Нет сообщений — актор ничего не делает.
Это особенно актуально для тех реализаций Модели Акторов, в которых акторы представляются в виде объектов с коллбэками. Фреймворк дергает коллбэк у актора и если актор не возвращает управление из коллбэка, то фреймворк не может обслуживать других акторов на этом же контексте.
Акторы подвержены перегрузкам
На акторах мы очень легко можем сделать так, что актор-producer будет генерировать сообщения для актора-consumer-а с гораздо более высоким темпом, чем актор-consumer будет способен обработать.
Это приведет к тому, что очередь входящих сообщений для актора-consumer-а будет постоянно расти. Рост очереди, т.е. рост потребления памяти в приложении, будет снижать скорость работы приложения. Это приведет к еще более быстрому росту очереди и, в итоге, приложение может деградировать до полной неработоспособности.
Все это является прямым следствием асинхронного взаимодействия акторов. Поскольку операция send, как правило, неблокирующая. А сделать ее блокирующей непросто, т.к. актор может делать send самому себе. И если очередь для актора заполнена, то на send-е самому себе актор будет заблокирован и на этом его работа прекратится.
Так что при работе с акторами нужно уделять серьезное внимание проблеме перегрузки.
Много акторов — это не всегда решение
Как правило, акторы — это легковесные сущности и существует соблазн создавать их в своем приложении в большом количестве. Можно создать и десять тысяч акторов, и сто тысяч, и миллион. И даже сто миллионов акторов, если железо вам позволяет.
Но проблема в том, что поведение очень большого количества акторов сложно отследить. Т.е. у вас может быть часть акторов, которые явно работают правильно. Часть акторов, которые либо явно работают неправильно, либо вообще не работают и вы об этом точно знаете. Но может быть и большое количество акторов, про которых вы не знаете ничего: работают они вообще, работают ли они правильно или неправильно. А все потому, что когда у вас в программе сто миллионов автономных сущностей с собственной логикой поведения, то следить за этим всем очень непросто.
Поэтому может получиться так, что создавая большое количество акторов в приложении мы не решаем свою прикладную задачу, а получаем еще одну проблему. И, поэтому, нам может быть выгодно отказаться от простых акторов, решающих одну-единственную задачу, в пользу более сложных и тяжеловесных акторов, выполняющих несколько задач. Но зато таких «тяжелых» акторов у нас в приложении будет меньше и нам проще будет за ними следить.
Куда смотреть, что брать?
Если кто-то захотел попробовать поработать с акторами в C++, то нет смысла строить собственные велосипеды, есть несколько готовых решений, в частности:
- SObjectizer (поддержи отечественного производителя!)
- C++ Actor Framework (CAF)
- QP/C++
Вот эти три варианта являются живыми, развивающимися, кросс-платформенными, задокументированными. А еще их можно бесплатно попробовать. Плюс еще несколько вариантов разной степени [не]свежести можно найти в списке в Wikipedia.
SObjectizer и CAF предназначены для использования в достаточно высокоуровневых задачах, где можно применять исключения и динамическую память. А фреймворк QP/C++ может быть интересен тем, кто связан с embedded-разработкой, т.к. именно под эту нишу он и «заточен».
Подход №2: CSP (communicating sequential processes)
CSP на пальцах и без матана
Модель CSP очень похожа на Модель Акторов. Мы также строим свое решение из набора автономных сущностей, каждая из которых обладает своим собственным приватным состоянием и взаимодействует с другими сущностями только посредством асинхронных сообщений.
Только сущности эти в модели CSP называются «процессы».
Процессы в CSP являются легковесными, без какого либо распараллеливания своей работы внутри. Если нам нужно что-то распараллеливать, то мы просто запускаем несколько CSP-шных процессов, внутри которых уже нет никакого распараллеливания.
Взаимодействуют CSP-шные процессы друг с другом через асинхронные сообщения, но сообщения отсылаются не в почтовые ящики, как в Модели Акторов, а в каналы. Каналы можно рассматривать как очереди сообщений, как правило, фиксированного размера.
В отличии от Модели Акторов, где для каждого актора автоматически создается почтовый ящик, каналы в CSP должны создаваться явно. И если нам нужно, чтобы два процесса взаимодействовали друг с другом, то мы должны сами создать канал, а потом сказать первому процессу «ты будешь писать сюда», а второму процессу должны сказать: «ты будешь читать вот отсюда».
При этом у каналов есть, как минимум, две операции, которые нужно вызывать явным образом. Во-первых, это операция write (send) для записи сообщения в канал.
Во-вторых, это операция read (receive) для чтения сообщения из канала. И необходимость явным образом вызывать read/receive отличает CSP от Модели Акторов, т.к. в случае с акторами операция read/receive может быть вообще скрыта от актора. Т.е. акторный фреймворк может извлекать сообщения из очереди актора и вызывать обработчик (коллбэк) для извлеченного сообщения.
Тогда как CSP-шный процесс сам должен выбрать момент для вызова read/receive, затем CSP-шный процесс должен определить, что за сообщение он получил и выполнить обработку извлеченного сообщения.
Внутри нашего «большого» приложения CSP-шные процессы могут быть реализованы по-разному:
- CSP-шный процесс может быть реализован отдельной нитью ОС. Получается дорогое решение, но зато с вытесняющей многозадачностью;
- CSP-шный процесс может быть реализован сопрограммой (stackful coroutine, fiber, green thread, ...). Это намного дешевле, но многозадачность только кооперативная.
Далее будем считать, что CSP-шные процессы представлены в виде stackful coroutines (хотя показанный ниже код вполне может быть реализован и на нитях ОС).
Схема решения на базе CSP
Схема решения на базе модели CSP будет очень сильно напоминать аналогичную схему для Модели Акторов (и это неспроста):
 |
Здесь также будут сущности, которые запускаются при старте HTTP-сервера и работают все время — это CSP-шные процессы HttpSrv, UserChecker, ImageDownloader и ImageMixer. На каждый новый входящий запрос будет создаваться новый CSP-шный процесс RequestHandler. Этот процесс отсылает и принимает те же самые сообщения, что и при использовании Модели Акторов.
Код CSP-шного процесса RequestHandler
Вот так может выглядеть код функции, реализующей CSP-шный процесс RequestHandler:
void request_handler(const execution_context ctx, const request req)
{
auto user_info_ch = make_chain<user_info>();
auto image_loaded_ch = make_chain<image_loaded>();
ctx.user_checker_ch().write(check_user{req.user_id(), user_info_ch});
ctx.image_downloader_ch().write(download_image{req.image_id(), image_loaded_ch});
auto user = user_info_ch.read();
auto original_image = image_loaded_ch.read();
auto image_mix_ch = make_chain<mixed_image>();
ctx.image_mixer_ch().write(
mix_image{user.watermark_image(), std::move(original_image), image_mix_ch});
auto result_image = image_mix_ch.read();
ctx.http_srv_ch().write(reply{..., std::move(result_image), ...});
}Здесь все достаточно тривиально и регулярно повторяется один и тот же шаблон:
- сперва мы создаем канал для получения ответных сообщений. Это необходимо, т.к. у CSP-шного процесса нет своего почтового ящика «по умолчанию», как у акторов. Поэтому, если CSP-шный процесс что-то хочет получить, то он должен озадачится созданием канала, куда это «что-то» будет записано;
- затем мы отсылаем свое сообщение CSP-шному процессу-исполнителю. А в этом сообщении указываем канал для ответного сообщения;
- затем мы выполняем операцию read из канала, куда нам должны прислать ответное сообщение.
Очень хорошо это видно на примере общения с CSP-шным процессом ImageMixer:
auto image_mix_ch = make_chain<mixed_image>(); // Создали канал.
ctx.image_mixer_ch().write( // Отослали сообщение.
mix_image{..., image_mix_ch}); // В сообщении передали ответный канал.
auto result_image = image_mix_ch.read(); // Дождались ответа.Но отдельно стоит заострить внимание вот на этом фрагменте:
auto user = user_info_ch.read();
auto original_image = image_loaded_ch.read();Здесь мы видим еще одно серьезное отличие от Модели Акторов. В случае CSP мы можем получать ответные сообщения в том порядке, который нас устраивает.
Хотим сперва дождаться user_info? Нет проблем, засыпаем на read-е до тех пор, пока user_info не появится. Если к этому времени image_loaded нам уже прислали, то оно просто будет ждать в своем канале пока мы его не прочитаем.
Вот, собственно, все, чем можно сопроводить показанный выше код. Код на базе CSP оказался компактнее, чем его аналог на базе акторов. Что не удивительно, т.к. здесь нам не пришлось описывать отдельный класс с методами-коллбэками. Да и часть состояния нашего CSP-шного процесса RequestHandler присутствует неявным образом в виде аргументов ctx и req.
Особенности CSP
Реактивность и проактивность CSP-шных процессов
В отличии от акторов CSP-шные процессы могут быть и реактивными, и проактивными, и теми и другими. Скажем, CSP-шный процесс проверил свои входящие сообщения, если они были, он их обработал. А потом, видя, что входящих сообщений нет, взялся перемножать матрицы.
Спустя какое-то время CSP-шному процессу матрицы перемножать надоело и он еще раз проверил наличие входящих сообщений. Новых не оказалось? Ну, ладно, пойдем перемножать матрицы дальше.
И вот эта возможность CSP-ных процессов выполнять какую-то работу даже в отсутствии входящих сообщений сильно отличает модель CSP от Модели Акторов.
«Родные» механизмы защиты от перегрузки
Поскольку, как правило, каналы являются очередями сообщений ограниченного размера и попытка записать сообщение в заполненный канал приостанавливает отправителя, то в CSP мы имеем встроенный механизм защиты от перегрузки.
Действительно, если у нас есть шустрый процесс-producer и медленный процесс-consumer, то процесс-producer быстро наполнит канал и его приостановят на очередной операции send. И процесс-producer будет спать до тех пор, пока процесс-consumer не освободит место в канале для новых сообщений. Как только место появится, процесс-producer проснется и накидает в канал новые сообщения.
Тем самым, при использовании CSP мы можем меньше переживать о проблеме перегрузки, нежели в случае Модели Акторов. Правда здесь есть свой подводный камень, о котором мы поговорим чуть позже.
Чем реализуются CSP-шные процессы
Мы должны решить, каким образом наши CSP-шные процессы будут реализованы.
Можно сделать так, что каждый CSP-шный процесс будет представлен отдельной нитью ОС. Получается дорогое и не масштабируемое решение. Но зато мы получаем вытесняющую многозадачность: если наш CSP-шный процесс начинает перемножать матрицы или делает какой-то блокирующий вызов, то ОС в конце-концов вытеснит его с вычислительного ядра и даст возможность поработать другим CSP-шным процессам.
Можно сделать так, что каждый CSP-шный процесс будет представлен сопрограммой (stackful coroutine). Это гораздо более дешевое и масштабируемое решение. Но здесь у нас будет только кооперативная многозадачность. Поэтому, если вдруг CSP-шный процесс займется перемножением матриц, то будет заблокирована рабочая нить с этим CSP-шным процессом и другими CSP-шными процессами, которые к ней же привязаны.
Тут может быть и еще один фокус. Допустим, мы задействуем стороннюю библиотеку, на внутренности которой мы не можем повлиять. А внутри библиотеки используются TLS-переменные (т.е. thread-local-storage). Мы делаем один вызов библиотечной функции и библиотека устанавливает значение какой-то TLS-переменной. Затем наша сопрограмма «переезжает» на другую рабочую нить, а это возможно, т.к. в принципе, сопрограммы могут мигрировать с одной рабочей нити на другую. Мы делаем следующий вызов библиотечной функции и библиотека пытается прочитать значение TLS-переменной. Но там уже может быть другое значение! И искать такой баг будет очень непросто.
Поэтому нужно тщательно отнестись к выбору способа реализации CSP-шных процессов. В каждом из вариантов есть свои сильные и слабые стороны.
Много процессов — это не всегда решение
Так же, как и с акторами, возможность создать много CSP-шных процессов в своей программе — это не всегда решение прикладной задачи, а создание себе дополнительных проблем.
Причем, плохая обозримость того, что происходит внутри программы — это только одна часть проблемы. Хочется заострить внимание еще на одном подводном камне.
Дело в том, что на CSP-шных каналах запросто можно получить аналог дедлока. Процесс A пытается записать сообщение в полный канал C1 и процесс A приостанавливают. Из канала C1 должен читать процесс B, который попытался записать в канал C2, который полон и, поэтому, процесс B приостановили. А из канала C2 должен был читать процесс A. Все, мы получили дедлок.
Если у нас всего два CSP-шных процесса, то подобный дедлок мы можем обнаружить в процессе отладки или даже при процедуре code review. Но если у нас миллионы процессов в программе, они активно общаются друг с другом, то вероятность возникновения подобных дедлоков существенно возрастает.
Куда смотреть, что брать?
Если кто-то хочет поработать с CSP в C++, то выбор здесь, к сожалению, не такой большой, как для акторов. Ну или я не знаю куда смотреть и как искать. В этом случае, я надеюсь, в комментариях поделятся другими ссылками.
Но, если мы хотим использовать у себя CSP, то в первую очередь нужно смотреть в сторону Boost.Fiber. Там есть и fiber-ы (т.е. сопрограммы), и каналы, и даже такие низкоуровневые примитивы, как mutex, condition_variable, barrier. Все это можно брать и использовать.
Если же вас устраивают CSP-шные процессы в виде нитей, то можно посмотреть и на SObjectizer. Там также есть аналоги CSP-шных каналов и сложные многопоточные приложения на SObjectizer-е можно писать вообще без акторов.
Actors vs CSP
Акторы и CSP-шые процессы очень похожи друг на друга. Неоднократно доводилось встречать утверждение, что эти две модели эквивалентны друг другу. Т.е. то, что можно сделать на акторах, можно чуть ли не 1-в-1 повторить на CSP-шных процессах и наоборот. Говорят, что это даже доказано математически. Но здесь я ничего не понимаю, поэтому не могу ничего утверждать. Но из собственных размышлений где-то на уровне бытового здравого смысла, все это выглядит достаточно правдоподобно. В каких-то случаях, действительно, акторов можно заменить CSP-шыми процессами, а CSP-шные процессы — акторами.
Тем не менее, у акторов и CSP есть несколько отличий, которые могут помочь определиться с тем, где выгодно или невыгодно использовать каждую из этий моделей.
Каналы vs почтовый ящик
У актора есть единственный «канал» для получения входящих сообщений — это его почтовый ящик, который для каждого актора создается автоматически. И актор извлекает сообщения оттуда последовательно, именно в том порядке, в котором сообщения в почтовый ящик попали.
И это довольно-таки серьезный вопрос. Допустим, в почтовом ящике актора сейчас три сообщения: M1, M2 и M3. Актор в данный момент заинтересован только в M3. Но прежде чем добраться до M3 актор извлечет сперва M1, затем M2. И что он будет с ними делать?
Опять же в рамках этого разговора не будем касаться механизмов selective receive из Erlang и stashing-а из Akka.
Тогда как CSP-шный процесс имеет возможность выбирать канал, из которого он в данный момент хочет читать сообщения. Так, у CSP-шного процесса может быть три канала: C1, C2 и C3. В данный момент CSP-шный процесс заинтересован только в сообщениях из C3. Именно этот канал процесс и читает. А к содержимому каналов C1 и C2 он вернется тогда, когда будет в этом заинтересован.
Реактивность и проактивность
Как правило, акторы реактивны и работают только тогда, когда у них есть входящие сообщения.
Тогда как CSP-шые процессы могут выполнять какую-то работу даже в отсутствии входящих сообщений. В каких-то сценариях это отличие может играть важную роль.
Конечные автоматы
По сути акторы являются конечными автоматами (КА). Поэтому если в вашей предметной области конечных автоматов много, да еще и если это сложные, иерархические конечные автоматы, то реализовать их на базе модели акторов вам может быть гораздо проще, чем добавляя реализацию КА в CSP-шный процесс.
В C++ нет пока родной поддержки CSP
Опыт языка Go показывает, насколько легко и удобно пользоваться моделью CSP когда ее поддержка реализована на уровне языка программирования и его стандартной библиотеки.
В Go легко создавать «CSP-шые процессы» (aka goroutines), легко создавать и работать с каналами, есть встроенный синтаксис для работы сразу с несколькими каналами (Go-шный select, который работает не только на чтение, но и на запись), стандартная библиотека знает про гороутины и может переключать их когда гороутина выполняет блокирующий вызов из stdlib.
В C++ пока поддержки stackful coroutines нет (на уровне языка). Поэтому работа с CSP в C++ может выглядеть, местами, если не костыльно, то… То уж точно она требует к себе гораздо больше внимания, чем в случае того же Go.
Подход №3: Tasks (async, future, wait_all, ...)
Про Task-based подход самыми общими словами
Смысл Task-based подхода в том, что если у нас есть сложная операция, то мы разбиваем эту операцию на отдельные шаги-задачи, где каждая задача (она же task) выполняет какую-то одну подоперацию.
Запускаем эти задачи специальной операцией async. Операция async возвращает объект-future, в который после выполнения задачи будет помещено значение, возвращенное задачей.
После того, как мы запустили N задач и получили N объектов-future, нам нужно все это как-то провязать в цепочку. Вроде того, что когда завершаются задачи №1 и №2, то возвращенные ими значения должны попасть в задачу №3. А когда завершается задача №3, то возвращенное значение должно быть передано в задачи №4, №5 и №6. И т.д., и т.п.
Для такой «провязки» используются специальные средства. Такие, например, как метод .then() у объекта-future, а также функции wait_all(), wait_any().
Такое объяснение «на пальцах» может быть не очень понятно, поэтому давайте перейдем к коду. Может быть в разговоре про конкретный код ситуация прояснится (но не факт).
Код request_handler-а для Task-based подхода
Код по обработке входящего HTTP-запроса на базе task-ов может выглядеть следующим образом:
void handle_request(const execution_context & ctx, request req)
{
auto user_info_ft = async(ctx.http_client_ctx(),
[req] { return retrieve_user_info(req.user_id()); });
auto original_image_ft = async(ctx.http_client_ctx(),
[req] { return download_image(req.image_id()); });
when_all(user_info_ft, original_image_ft).then(
[&ctx, req](tuple<future<user_info>, future<image_loaded>> data) {
async(ctx.image_mixer_ctx(), [&ctx, req, d=std::move(data)] {
return mix_image(get<0>(d).get().watermark_image(), get<1>(d).get());
})
.then([req](future<mixed_image> mixed) {
async(ctx.http_srv_ctx(), [req, im=std::move(mixed)] {
make_reply(...);
});
});
});
}Давайте попробуем разобраться с тем, что здесь происходит.
Сперва мы создаем задачу, которая должна запуститься на контексте нашего собственного HTTP-клиента и которая запрашивает информацию о пользователе. Возвращенный объект-future мы сохраняем в переменной user_info_ft.
Далее мы создаем похожую задачу, которая также должна запуститься на контексте нашего собственного HTTP-клиента и которая загружает исходное изображение. Возвращенный объект-future сохраняется в переменной original_image_ft.
Далее нам нужно дождаться выполнения двух первых задач. Что мы прямо так и записываем: when_all(user_info_ft, original_image_ft). Когда оба объекта-future получат свои значения, тогда мы запустим еще одну задачу. Эта задача возьмет битовую маску с «водяными знаками» и оригинальное изображение и запустит еще одну задачу на контексте ImageMixer-а. Эта задача смикширует изображения и когда она завершиться, на контексте HTTP-сервера запустится еще одна задача, которая сформирует HTTP-ответ.
Наверное такое объяснение происходящее в коде не сильно прояснило. Поэтому давайте пронумеруем наши задачи:
 |
И посмотрим на зависимости между ними (из которых проистекает порядок выполнения задач):
 |
А если мы теперь наложим эту картинку на наш исходный код, то, я надеюсь, станет понятнее:
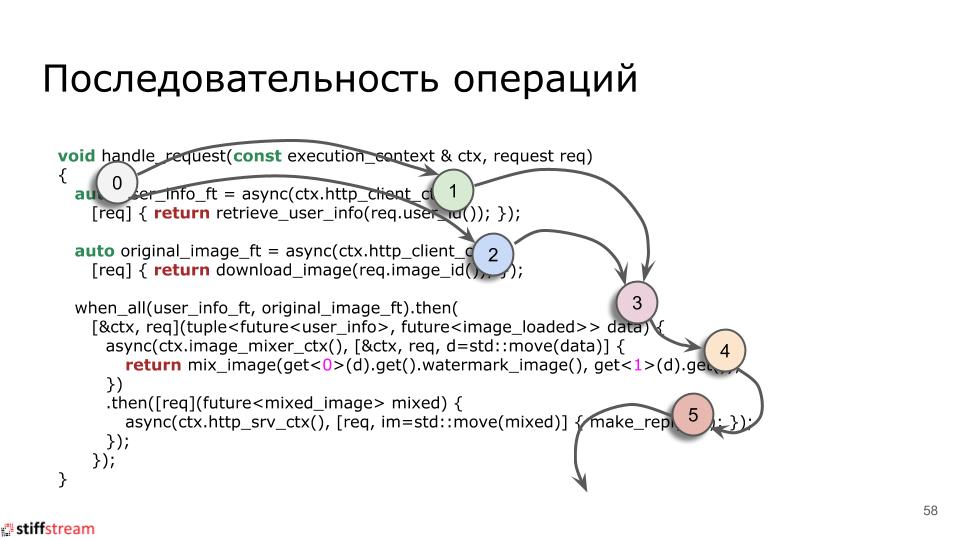 |
Особенности Task-based подхода
Обозримость
Первая особенность, которая уже должна стать очевидной — это обозримость кода на Task-ах. С ней не все хорошо.
Здесь же можно упомянуть такую штуку, как callback hell. С ней хорошо знакомы Node.js-программисты. Но и C++ники, которые плотно работают с Task-ами, также окунаются в этот самый callback hell.
Обработка ошибок
Еще одна интересная особенность — это обработка ошибок.
С одной стороны, в случае использования async и future с доставкой информации об ошибки до заинтересованной стороны может быть даже проще, чем в случае акторов или CSP. Ведь если в CSP процесс A отсылает запрос процессу B и ждет ответного сообщения, то при возникновении у B ошибки при выполнении запроса нам нужно решить, как доставлять ошибку процессу A:
- либо мы сделаем отдельный тип сообщения и канал для его получения;
- либо мы отдаем результат единственным сообщением, в котором будет std::variant для нормального и ошибочного результата.
А в случае future все проще: мы извлекаем из future либо нормальный результат, либо нам бросают исключение.
Но, с другой стороны, мы можем запросто нарваться на каскад ошибок. Например, в задаче №1 возникло исключение, это исключение попало в объект future, который был передан в задачу №2. В задаче №2 мы попытались взять значение из future, но получили исключение. И, скорее всего, мы это же исключение выбросим наружу. Соответственно, оно попадет в следующий future, который пойдет в задачу №3. Там так же возникнет исключение, которое, вполне возможно, также будет выпущено наружу. И т.д.
Если наши исключения будут логироваться, то затем в логе мы сможем увидеть неоднократное повторение одного и того же исключения, которое переходит от одной задачи в цепочке к другой задаче.
Отмена Task-ов и таймеры/таймауты
И еще одна очень интересная особенность Task-based похода — это отмена задач если что-то пошло не так. В самом деле, допустим, мы создали 150 задач, выполнили первые 10 из них и поняли, что все, дальше работу продолжать нет смысла. Как нам отменить 140 оставшихся? Это очень и очень хороший вопрос :)
Еще один похожий вопрос — это как подружить задачи с таймерами и таймаутами. Допустим, мы обращаемся к какой-то внешней системе и хотим ограничить время ожидания 50-ью миллисекундами. Как нам взвести таймер, как среагировать на истечение тайм-аута, как прервать цепочку задач, если таймаут истек? Опять же, спросить проще, чем ответить :)
Читинг
Ну и еще к разговору об особенностях Task-based подхода. В показанном примере был применен небольшой читинг:
auto user_info_ft = async(ctx.http_client_ctx(),
[req] { return retrieve_user_info(req.user_id()); });
auto original_image_ft = async(ctx.http_client_ctx(),
[req] { return download_image(req.image_id()); });Здесь я отправил на контекст нашего собственного HTTP-сервера две задачи, каждая из которых выполняет внутри блокирующую операцию. На самом деле для того, чтобы можно было обрабатывать два запроса к сторонним сервисам в параллель, здесь нужно было создавать свои цепочки асинхронных задач. Но я этого не стал делать для того, чтобы решение получилось более-менее обозримым и поместилось на слайд презентации.
Actors/CSP vs Tasks
Мы рассмотрели три подхода и увидели, что если акторы и CSP-шные процессы похожи друг на друга, то Task-based подход не похож ни на кого из них. И может сложиться впечатление, что Actors/CSP следует противопоставлять Task-ам.
Но лично мне нравится другая точка зрения.
Когда мы говорим про Модель Акторов и CSP, то мы говорим про декомпозицию своей задачи. Мы выделяем в своей задаче отдельные самостоятельные сущности и описываем интерфейсы этих сущностей: какие сообщение они отсылают, какие получают, по каким каналам сообщения ходят.
Т.е. работая с акторами и CSP мы говорим про интерфейсы.
Но, допустим, мы разбили задачу на отдельных акторов и CSP-шные процессы. Как именно они выполняют свою работу?
Когда же мы беремся за Task-based подход, мы начинаем говорить про реализацию. Про то, как выполняется конкретная работа, какие подоперации выполняются, в каком порядке, как эти подоперации связаны по данным и т.д.
Т.е. работая с Task-ами мы говорим про реализацию.
Следовательно, Actors/CSP и Tasks не столько противостоят друг другу, сколько дополняют друг друга. Actors/CSP могут использоваться для декомпозиции задачи и определения интерфейсов между компонентами. А Tasks затем могут использоваться в реализации конкретных компонентов.
Например, у нас при использовании Actor-ов есть такая сущность, как ImageMixer, которой нужно выполнять манипуляции с изображениями на пуле рабочих нитей. В общем-то ничто не мешает нам в реализации актора ImageMixer использовать Task-based подход.
Куда смотреть, что брать?
Если захотелось поработать с Task-ами в C++, то смотреть можно в сторону стандартной библиотеки грядущего C++20. Там уже добавили метод .then() к future, а также свободные функции wait_all() и wait_any. За подробностями можно обратиться к cppreference.
Так же есть уже далеко не новая библиотека async++. В которой, в принципе, есть все нужное, только чуть-чуть под другим соусом.
И еще есть еще более старая библиотека Microsoft PPL. Которая также дает все, что нужно, но под своим соусом.
Отдельное дополнение по поводу библиотеки Intel TBB. Она не была упомянута в рассказе про Task-based подход поскольку, на мой взгляд, графы задач из TBB — это уже data flow подход. И, если данный доклад получит свое продолжение, то речь об Intel TBB обязательно зайдет, но в контексте рассказа про data flow.
Еще интересное
Недавно здесь, на Хабре, была статья Антона Полухина: "Готовимся к С++20. Coroutines TS на реальном примере".
Там рассказывается об объединении Task-based подхода со stackless coroutines из С++20. И получилось, что код на базе Task-ов по читабельности приблизился к читабельности кода на CSP-шных процессах.
Так что если кто-то заинтересовался Task-based подходом, то имеет смысл ознакомиться с данной статьей.
Заключение
Что ж, пора переходит к итогам, благо их не так уж и много.
Главное, что я хочу сказать, — это то, что в современном мире голая многопоточность вам может потребоваться разве что если вы разрабатываете какой-то фреймворк или решаете какую-то специфическую и низкоуровневую задачу.
А если вы пишете прикладной код, то вряд ли вам нужны голые нити, низкоуровневые примитивы синхронизации или какие-то lock-free алгоритмы вместе с lock-free контейнерами. Уже давно есть подходы, которые проверены временем и отлично себя зарекомендовали:
- actors
- communicating sequential processes (CSP)
- tasks (async, promises, futures, ...)
- data flows
- reactive programming
- ...
И главное, что для них в C++ есть готовые инструменты. Не нужно ничего велосипедить, можно брать, пробовать и, если понравилось, запускать в эксплуатацию.
Вот так просто: брать, пробовать и запускать в эксплуатацию.
Комментарии (42)

Sdima1357
22.11.2018 11:25+1Спасибо за статью, лет двадцать назад пришлось писать велосипед для модели, в этой классификации «актор». Последняя модель, таск, читается с трудом и не позволяет конфигурировать связи в runtime из внешнего конфига, хотя конечно ее можно адаптировать(написать на ней актор или CSP :). Модель «актор» позволяет конфигурировать связи в runtime.В моих приложениях это критично.
eao197 Автор
22.11.2018 11:28Спасибо за статью
Спасибо за отзыв!
Последняя модель, таск, читается с трудом и не позволяет конфигурировать связи в runtime из внешнего конфига
Имхо, Task-based подход имеет смысл там, где задачи формируются «по месту», в зависимости от того, что пришло на вход. И когда при обработке разных входящих воздействий можно строить разные наборы тасков.
То, о чем говорите вы — это уже из области task graph-ов, которые реализованы в Intel TBB. Но рассказ об этом подходе в доклад бы уже не поместился.
mayorovp
22.11.2018 11:31+1Таски просто находятся на слишком низком уровне чтобы там можно было что-то конфигурировать. Но их можно добавить к любому решению для конфигурирования связей в рантайме.
DaylightIsBurning
22.11.2018 21:50Спасибо за статью! Ждём теперь статью по Data flow!
eao197 Автор
22.11.2018 21:53Спасибо за статью!
Спасибо за отзыв!
Ждём теперь статью по Data flow!
Не факт, не факт. Была мысль сделать продолжение доклада на следующем CoreHard-е, но не известно, хватит ли сил и времени.
sashagil
22.11.2018 23:46Хотел бы добавить вот что по акторам и CSP — есть добротные книги, раскладывающие эти темы по полочкам, я их читал (не буду говорить, что эти книги — лучшие, но, по моему мнению, добротные). По акторам — книга автора QP (Miro Samek, «Practical UML Statecharts in C/C++»). По CSP — одноименная с названием подхода книга его изобретателя (Tony Hoar), она была переведена на русский году в 86-м примерно, «Взаимодействующие последовательные процессы».
eao197 Автор
23.11.2018 08:34По акторам — книга автора QP (Miro Samek, «Practical UML Statecharts in C/C++»).
Не читал.
«Взаимодействующие последовательные процессы»
ИМХО (здесь не зря ИМХО большими буквами, все очень и очень субъективно) эта книга хороша для студентов профильных ВУЗов, для исследователей в области computer science, для специалистов по верификации программ. Как эта книга может помочь при проектировании конкретного прикладного решения на базе CSP, для меня лично не понятно. И да, CSP-book — это и есть тот самый «матан», без которого хотелось в докладе обойтись в разговоре про CSP.
vm05s24
23.11.2018 08:30Хорошая статья, но к сожалению не упомянут такой замечательный инструмент, как boost::asio, а ведь он отлично подходит для решения такого рода задач.
eao197 Автор
23.11.2018 08:30+1Asio замечательный инструмент для асинхронного IO. Но для организации конкурентности в коде он слишком низкоуровневый.
ggo
23.11.2018 10:06И еще одна очень интересная особенность Task-based похода — это отмена задач если что-то пошло не так. В самом деле, допустим, мы создали 150 задач, выполнили первые 10 из них и поняли, что все, дальше работу продолжать нет смысла. Как нам отменить 140 оставшихся? Это очень и очень хороший вопрос :)
Еще один похожий вопрос — это как подружить задачи с таймерами и таймаутами.
Насколько я понимаю, Task-подход, это то, как работают современные rx-фреймворки.
А в современных rx-фреймворках все хорошо, с таймерами, таймаутами, отменами, контролем ошибок, и пр.
Следовательно, Actors/CSP и Tasks не столько противостоят друг другу, сколько дополняют друг друга. Actors/CSP могут использоваться для декомпозиции задачи и определения интерфейсов между компонентами. А Tasks затем могут использоваться в реализации конкретных компонентов.
Они действительно взаимодополняют друг друга.
Стоит только отметить, что Actors/CSP могут физически быть на разном железе. Тогда как описанный Task-подход, это то как устроена утилизация многоядерности на одной железке. (шарить треды в общем то некоторые ОС умеют, но массового применения это не нашло)mayorovp
23.11.2018 10:15+1Нет, rx использует абстракцию потока событий, а не асинхронной задачи. Выглядит оно, конечно, похоже: и там, и там колбек, который кто-то дернет когда придет время — но разница между потоком и задачей принципиальная. Потоки нужно явно останавливать, задача остановится сама. Для потока нельзя сделать co_await, для задачи — можно.
ggo
23.11.2018 10:33Что есть поток в конкретной среде разработки — вещь вполне конкретная.
А что есть задача? Чем она имплементируется? Наверно некоторая субстанция, которая что-то делает в отдельном потоке. Ой, опять вернулись к потоку.
При этом я понимая, что async/await это языковые конструкции. А rx-фреймворки — набор библиотек, возможно даже без async/await (ну нет их в конкретной языковой платформе, что поделать) Но чем они принципиально отличаются с точки зрения общей механики. И там, и там отдельные потоки, и там, и там, присутствует в том или ином виде event loop, даже если он не называется event loop.
И чем отличается асинхронная задача, от потока событий, который порождает ровно одно событие?eao197 Автор
23.11.2018 10:56потока событий, который порождает ровно одно событие?
Тем, что это оксюморон. Ну вроде «живой мертвец».
Лишено практического смысла. Нет, конечно в камментах на Хабре об этом можно потрепаться, но зачем это использовать при разработке софта?ggo
23.11.2018 17:39Ну что же вы так категорично.
Вот есть у вас обращение к удаленному сервису. Обернули вы вызов в Observable, и так как удаленный сервис возвращает один результат, ваш Observable тоже возвращает один результат — одно событие. И такой подход не является biased, а вполне практичный, никаких живых мертвецов.eao197 Автор
23.11.2018 17:56Обернули вы вызов в Observable
Обернули что именно? Кто, где и как будет вызов осуществлять?ggo
24.11.2018 06:53Обернули что именно? — > вызов внешнего удаленного сервиса
Кто, где и как будет вызов осуществлять? -> вызов дергает какойнибудь subscribereao197 Автор
24.11.2018 08:49Простите, но либо я не понимаю того, что вы предлагаете, либо вы предлагаете следующее:
Когда мне нужно сделать какую-то операцию (например, загрузить изображение), то я создаю некий observable объект. Скажем, ImageDownloadTask.
На появление этого объекта реагирует какой-то подписчик, который знает, как обслуживать такие объекты. Скажем, это будет ImageDownloadTaskPerformer.
Этот ImageDownloadTaskPerformer получает ImageDownloadTask как входящее событие и выполняет загрузку изображения.
После чего, как я понимаю, должен возникнуть еще один объект, скажем, DownloadImageInstance, на возникновение которого должен еще кто-то среагировать.
Правильно? Если нет, то раскройте свою мысли пошире, пожалуйста.
mayorovp
23.11.2018 10:57+1Задача — это абстракция некоторого значения, которое будет доступно в будущем. Видите, я обошелся без использования слова "поток".
И чем отличается асинхронная задача, от потока событий, который порождает ровно одно событие?
Набором гарантий. Если вам дан на вход произвольный поток событий — вы не можете сказать сколько их там будет. Соответственно, нужно или обрабатывать общий случай — или писать хрупкий код. Если же вы на вход получили задачу — вы всегда можете считать что событие будет ровно одно.
ggo
23.11.2018 17:32Данное определение Задачи безусловно непротиворечивое. Но я спрашивал про имплементацию. В конкретной языковой платформе. Как ни крути где-то под капотом будет поток, или какой-то его аналог. если в платформе нет честных threads.
mayorovp
23.11.2018 19:17Да не будет там никакого потока. Можете поискать реализацию в исходниках стандартной библиотеки если знаете где их найти.
Вот вам реализация задачи на javascript: github.com/taylorhakes/promise-polyfill/blob/master/src/index.js
Попробуйте найти тут хоть что-нибудь про потоки…
eao197 Автор
23.11.2018 10:54Насколько я понимаю, Task-подход, это то, как работают современные rx-фреймворки.
Я понимаю совсем по другому. RX-подход — это когда у нас есть поток событий и этот поток валится в одну точку входа (будь то задача, нить, сопрограмма или еще что-то). И уже в этой точке происходит обработка очередного события. Возможно, с использованием знаний о предыдущих событиях (т.е. с использованием состояния обработчика).
Поскольку есть поток событий, то в этот поток элементарно добавляются и события от таймера.
В случае с task-based подходом у нас нет потока событий. Есть конкретный таск, который должен выполниться на конкретном контексте при возникновении конкретных условий (в простейшем случае когда будет готов future, на который таск «повесили»). И, что важно, таски создаются «по месту», для обработки конкретной операции. Количество, типы и взаимосвязи между тасками определяются в зависимости от этой самой конкретной операции.
Стоит только отметить, что Actors/CSP могут физически быть на разном железе. Тогда как описанный Task-подход, это то как устроена утилизация многоядерности на одной железке.
Речь шла только об использовании Actors/CSP для упрощения многопоточности. Возможность создавать распределенные приложения на базе Actors/CSP выходит за рамки этого разговора.
pishet
Вообще, будущее программирование — именно за многопоточностью, ибо асинхронная модель исследована до дыр и себя исчерпала (node.js). Если мы имеем не просто http-сервер, а сложную логику обслуживания клиента, то самая лучшая абстракция сессии — это стек. Стек хранит всю историю вызовов, все локальные переменные, стек можно бэкапить в момент очистки, и мы получим фантастически полные логи. И разрабатывать, и отлаживать, и сапортить легче синхронный многопоточный код со стеком, чем извращения с колбэками. Потоки плохо масштабируются? Так это проблема реализации, в той же Java зеленые потоки существуют уже второе десятилетие. Единственное, что важно — иногда многопоточность может быть реализована кооперативно (в рамках одного сервиса например), а иногда вытесняюще (если используем сторонние компоненты). В первом случае меньше накладные расходы, но больше рисков.
eao197 Автор
Мне кажется, вы сейчас говорите о модели CSP (зеленые потоки и вот это вот все).
Ну и вопрос не в том, как именно будет выполняться работа в отдельном потоке. А в том, как потоки будут обмениваться информацией. Ведь поток существует не сам по себе, а чтобы взять что-то на себя, сделать это и отдать кому-то результат. И вопрос в том, как взаимодействие организовать, чтобы не получить гонок, дедлоков и, при этом, не тормозить.
pishet
Я немного радикальнее считаю. Если у вас есть сервис, который обслуживает клиентов, и логика этого обслуживания сложна (например вложенные IVR-меню, или сеанс с Алисой, или бизнес-процесс в системе электронного документооборота) — каждая пользовательская сессия должна быть представлена отдельным тредом, обязательно со своим отдельным стеком, с возможностью сериализации на диск, если ожидание долгое. Мы в 90-х все это делали, но приходилось эмулировать стек с помощью разных коллекций, не решились возложить все на JVM, хотя там уже была сериализация тредов, да Java нормально держала на одном процессоре до 3 тыс. тредов.
Сейчас, с развитием ИИ, простые сервисы типа вопрос-ответ будут заменяться сложными, а для них нет годных языковых средств.
А в вашем (простом) случае — конечно, каждый воркер должен иметь входящую очередь, весь обмен асинхронный, как Вы и написали.
PS
Дедлоки отлаживать проще простого — аттач дебаггером к стоящему серверу, распечатка стеков всех тредов, и через полчаса все понятно.
eao197 Автор
Но целью статьи было не показать, что какой-то подход лучше для обслуживания сложных HTTP-запросов, а какой-то хуже. Целью было показать наличие разных подходов, которые могут применяться разработчиками помимо работы с threads, mutexes, condition_variables, barriers и т.д. А задача такая для иллюстрации была выбрана потому, что она простая, понятная многим и, что важно, все три показанных подхода вполне применимы для ее решения. Тогда как data flows и reactive programming, рассказ о которых в доклад бы не поместился, для решения такой задачи были бы вряд ли уместны.
Видимо, мне везло сильно меньше, чем вам.
pishet
Кстати, шикарная идея с очередями фиксированной длины. Сам не додумался, а ведь действительно, при переполнении мы получаем всего-лишь отказ в обслуживании, а не крэш сервиса. CSP рулит пока :)
eao197 Автор
На самом деле там можно идти и еще дальше. Приостанавливать на запись в CSP-шный канал можно только на время. Если даже после паузы место в канале не появилось, можно предпринимать какую-то попытку очистки канала: выбрасывать самое старое сообщение, например. Или игнорировать новое. У нас в SObjectizer-е есть возможность этим управлять.
RPG18
Насколько понимаю, все зависит от реализации. Можно и у акторов ввести ограничение на размер ящика
eao197 Автор
Основной вопрос будет в том, что делать при попытке отсылки сообщения актору с полным ящиком.
RPG18
Это вполне можно отнести к graceful degradation, а решение выносить на уровень выше. Т.е. что лучше для бизнеса стараться все обслужить, обслуживать не всех или обслуживать всех, но понизить качество предоставляемой услуги.
eao197 Автор
RPG18
На уровень выше, это на уровень архитектуры. Мы можем притормозить писателя, а можем выкинуть ошибку и прекратить обработку входящих запросов на уровне сервиса, например для того, что бы другой инстанс сервиса его обработал.
eao197 Автор
Тем не менее, вопрос остается открытым. Актор A отсылает сообщение актору B и внутри send-а выясняется, что почтовый ящик актора B полон. Что делать send-у?
Мне кажется, что вы немного путаете уровни. У вас некий сервис реализован как совокупность общающихся акторов. Чтобы прекратить обработку сервисом входящих запросов вам нужно, чтобы какие-то акторы из его реализации распознали и среагировали на переполнение почтового ящика одного (или не одного) актора. И вопрос реализации вашего сервиса будет в том, как вы это будете делать (точнее, это будет один из вопросов).RPG18
Что делать send'у зависит от реализации, а реализация зависит от поставленных требований. send может вернуть ошибку и тогда актор А будет думать, что делать дальше.
Разве? Если send вернул актору A ошибку, то актор А может отправить сообщение супервизору(если использовать терминологию из Erlang), а тот уже может приостановить подключение новых соединений.
А можно сделать так, как вы предложили. Супервизор мониторит размер очередей у акторов, т.к. актор можем быть проактором.
eao197 Автор
На практике, правда, есть важный нюанс: результат send-а, как правило, никто не контролирует.
ggo
Во всех actor-фреймворках результат send'а куда-нибудь, да валится. А значит, вопрос контроля — это вопрос волеизъявления/знаний разработчика. Если бы send'ы неконтролируемо могли бы потеряться, говорить о детерминированности actor-процессов не приходилось бы.
eao197 Автор
Если так, то да. Наверное, нет фреймворков, в которых нельзя узнать результат send-а.
А это уже масло-масляное. Очевидно, что разработчик должен контролировать то, что он делает.
Здесь опять не понял.
Я говорю о том, что на практике мало кто пишет код так, чтобы проверять результат каждого send-а и предпринимать соответствующую реакцию на каждый неудачный send.
ggo
Апологеты rx считают что необязательно для каждой сессии держать свой тред.
И их полку прибывает, в последнее время.
А дедлоки отлаживать действительно не сложно (когда есть физический доступ к оборудованию с дедлоком). Сложнее их фиксить, а еще сложнее добиться чтобы их не было.
Поэтому и расцвели теоретики по actors, immutables, pure functions — чтобы дедлоков в принципе не было.