
Привет! Это рассказ о том, что нового в нашем плагине для баз данных. Мы выпускаем его, как отдельный продукт DataGrip, и поставляем почти во все другие наши IDE. Будет много картинок и гифок. Для тех, кому лень их смотреть:
Спасибо тем, кто пробует EAP-версии и сообщает в наш трекер о проблемах: это помогает не дотащить их до релиза :) Активные пользователи уже получили бесплатные подписки на год.

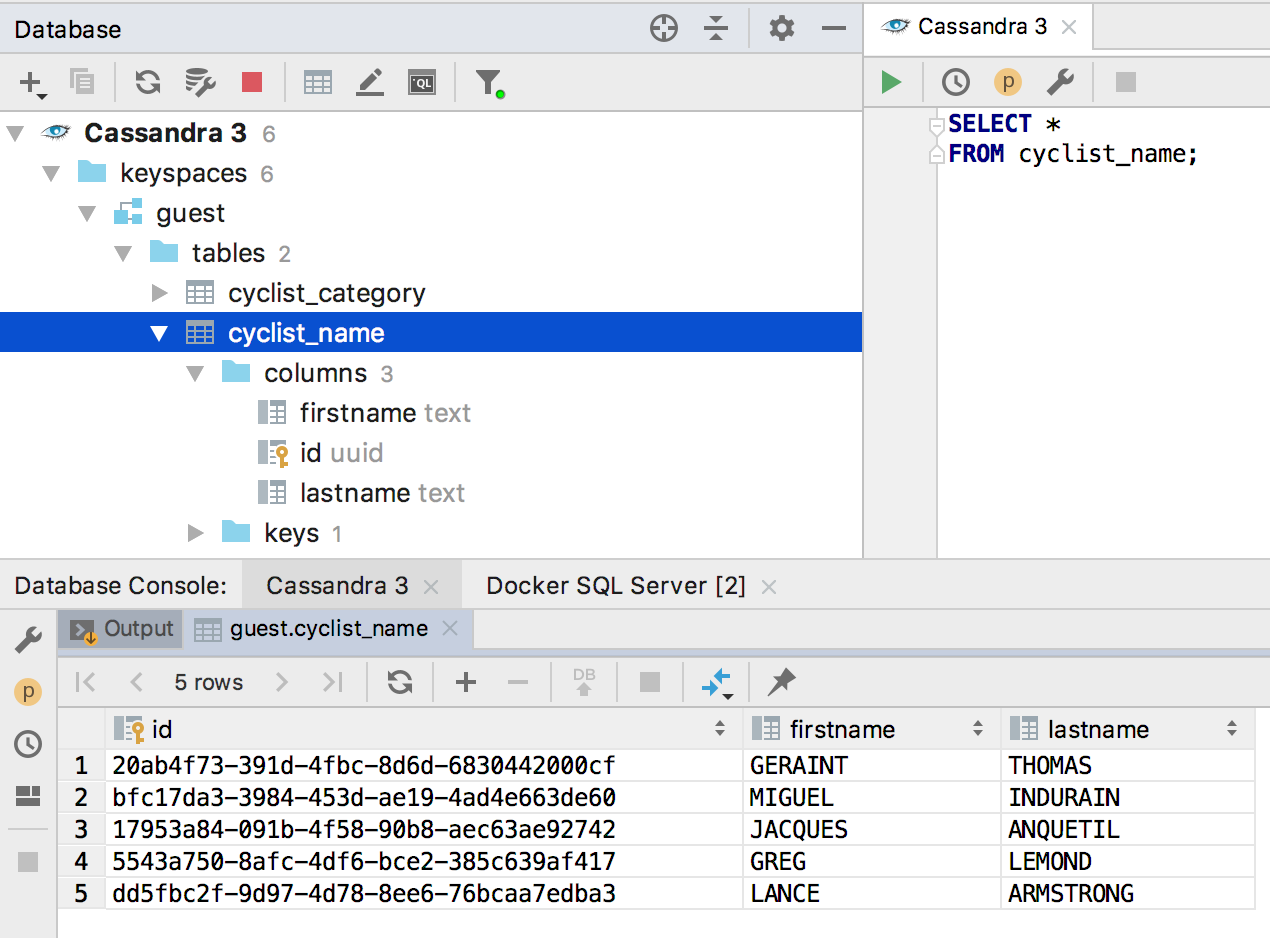
Потихоньку осваиваем NoSQL-базы. Пока только те, что используют SQL-подобные языки для запросов. Мы поддержали Clickhouse в 2018.2.2, а в этом релизе добавили Cassandra.
В этой подсистеме много нового.
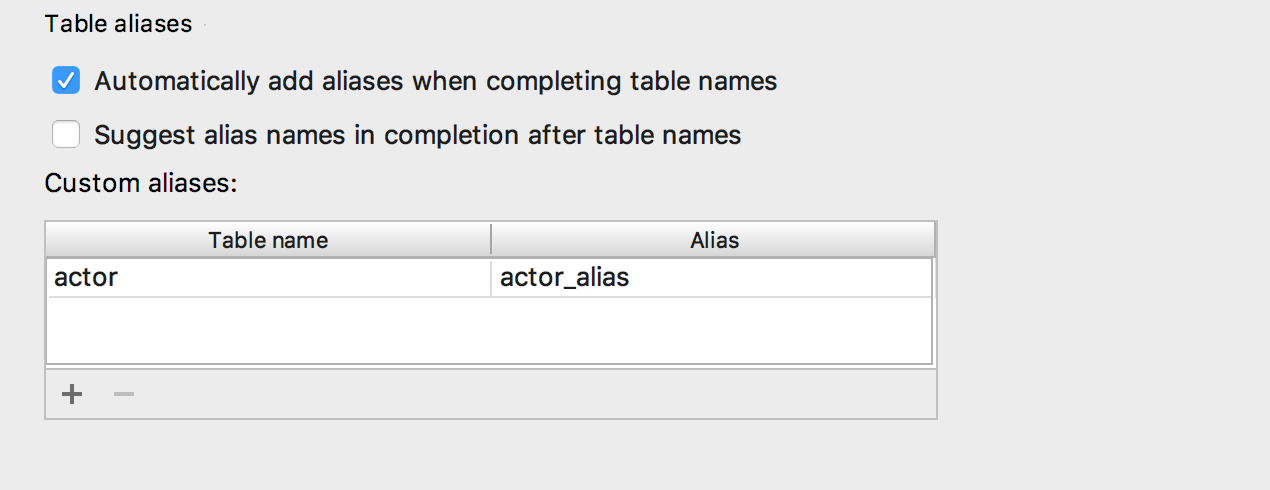
Добавили возможность вставлять псевдонимы автоматически после имён таблиц. Если предложенный нами псевдоним вас не устраивает, укажите — какие псевдонимы использовать для конкретных имён.
В итоге, работает так:
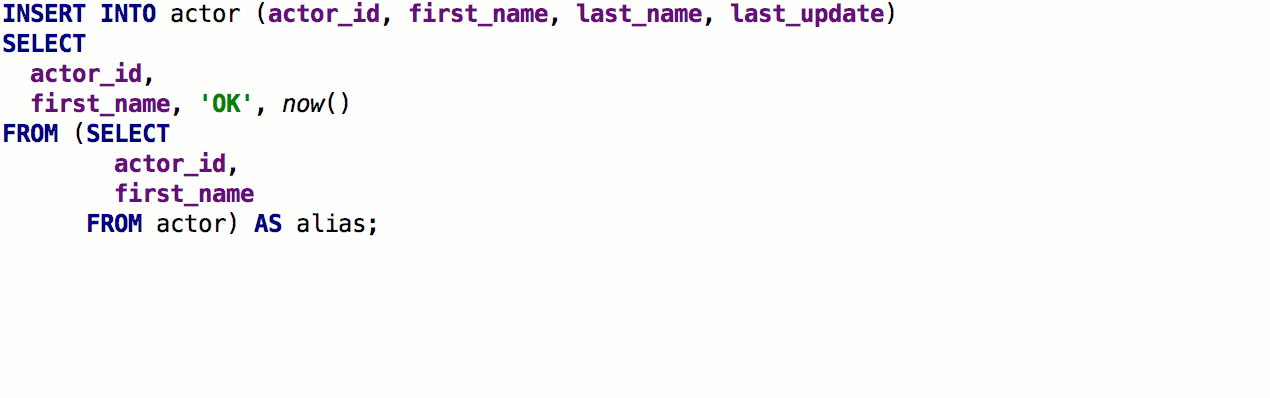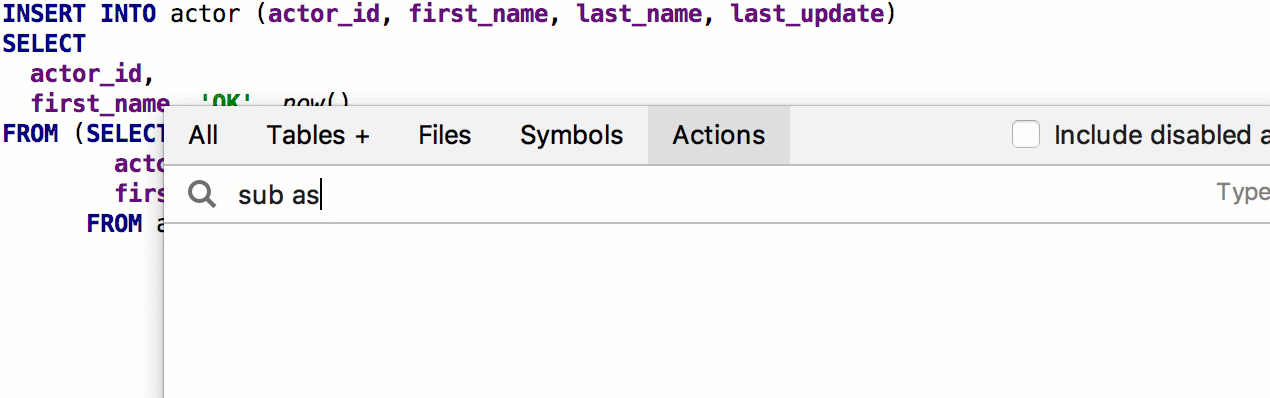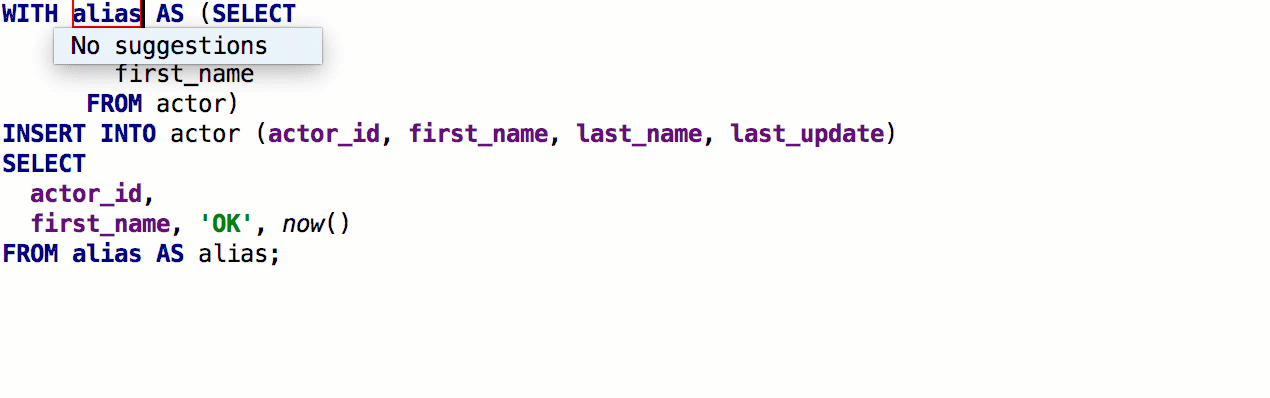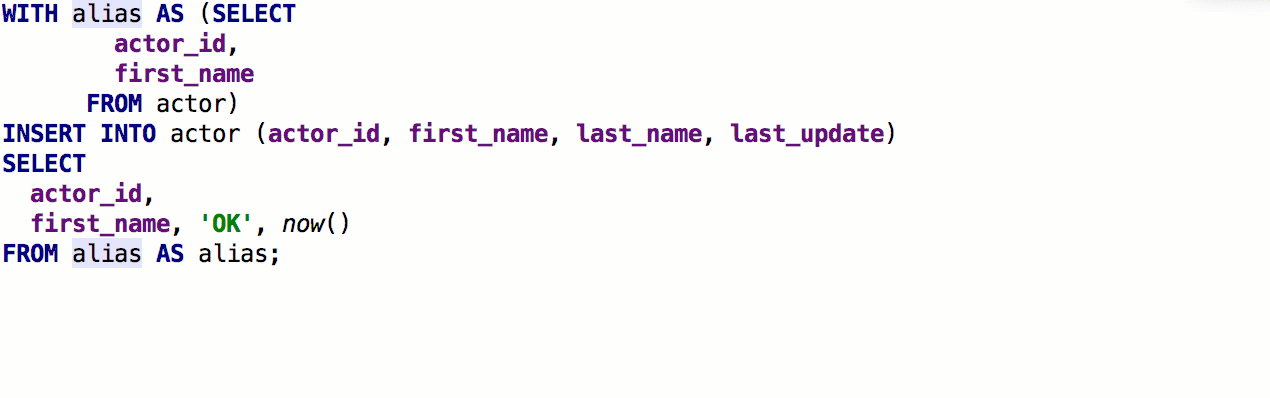
При использовании GROUP BY DataGrip предложит список неагрегированных столбцов.
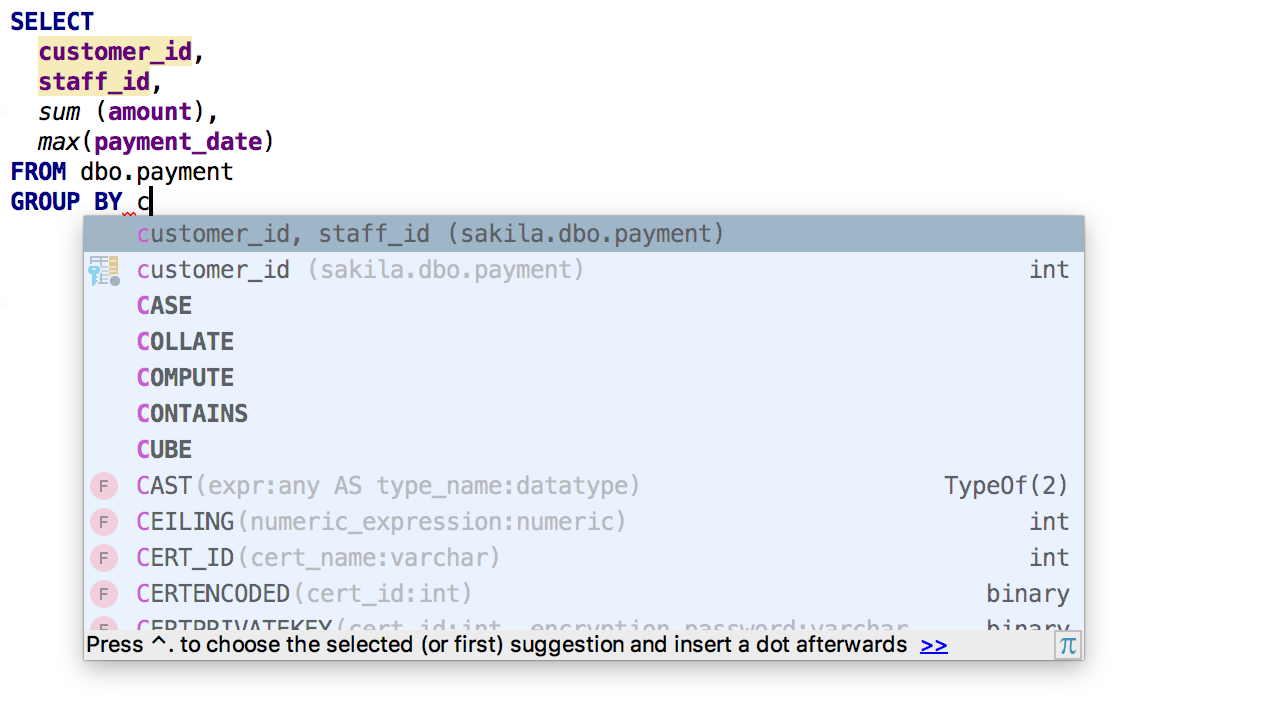
В предложении SELECT предлагается список всех столбцов.
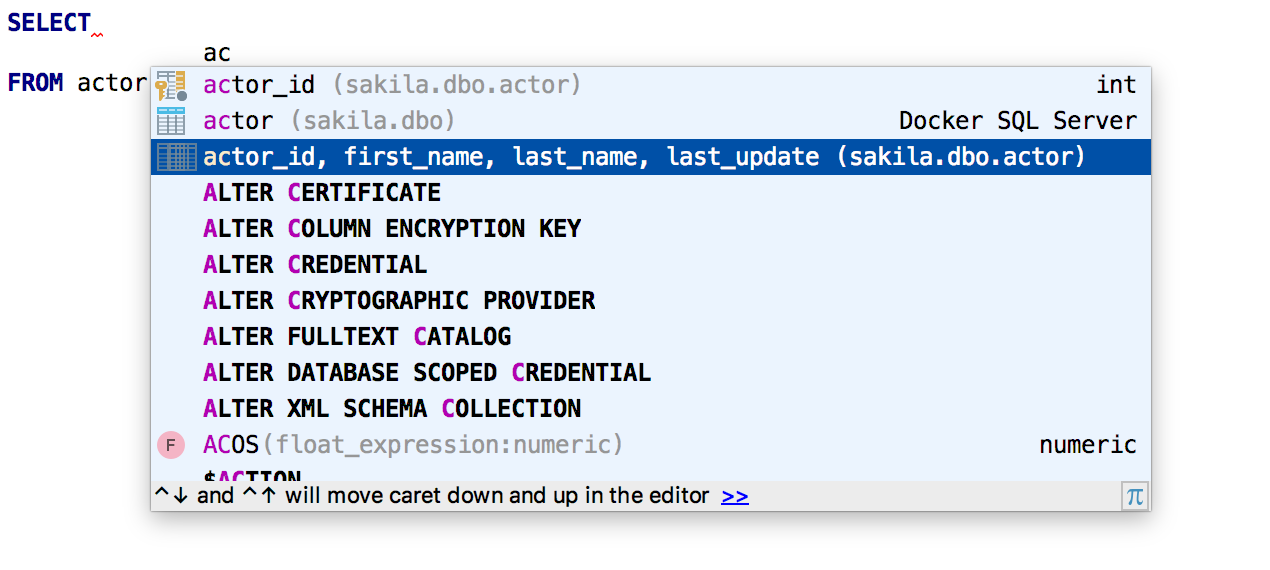
Автодополнение работает для именованных параметров.
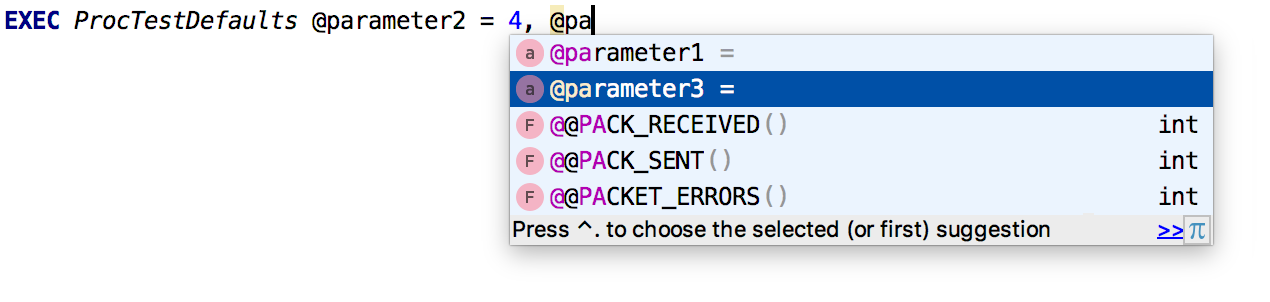
Ещё добавили информацию о контексте для одинаковых имён.
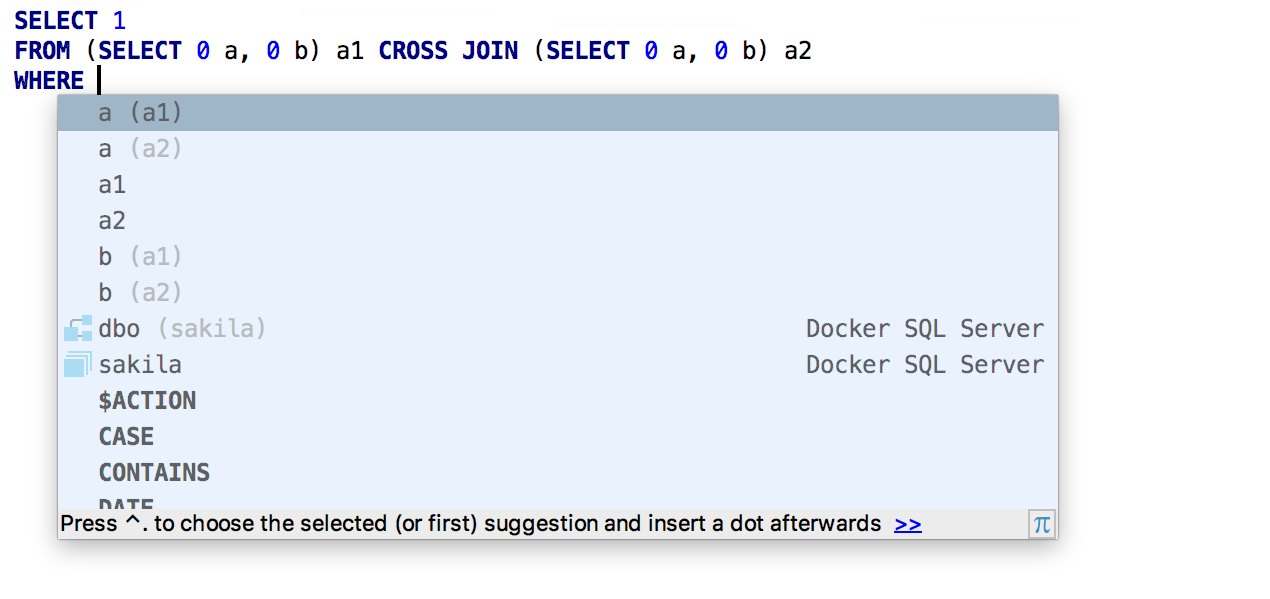
Наконец-то сделали postfix completion: это когда через точку пишут что-то, относящееся к объекту.

Например, если после SELECT написать имяТаблицы.afrom — раскроется в список столбцов и предложение FROM. Или, на наш взгляд самое удобное, можно дописать .cast к колонке или переменной.
Лучше один раз увидеть:

Автодополнение стало лучше для оконных функций: автоматически добавляется OVER() и каретка ставится в нужное место.

Важная штука, которую давно пора было сделать: использование псевдонима вместо таблицы. Нажмите на таблице Alt+Enter > Introduce alias. Использования таблицы будут заменены на псевдонимы.

После предыдущего релиза мы получили подробный фидбек от speshuric. Например, он нашёл много неочевидных сценариев для Extract subquery as a CTE. Этот рефакторинг вызывается через меню Refactor > Extract > Subquery as CTE, но мы советуем привыкать к Find Action (Ctrl+Shift+A).
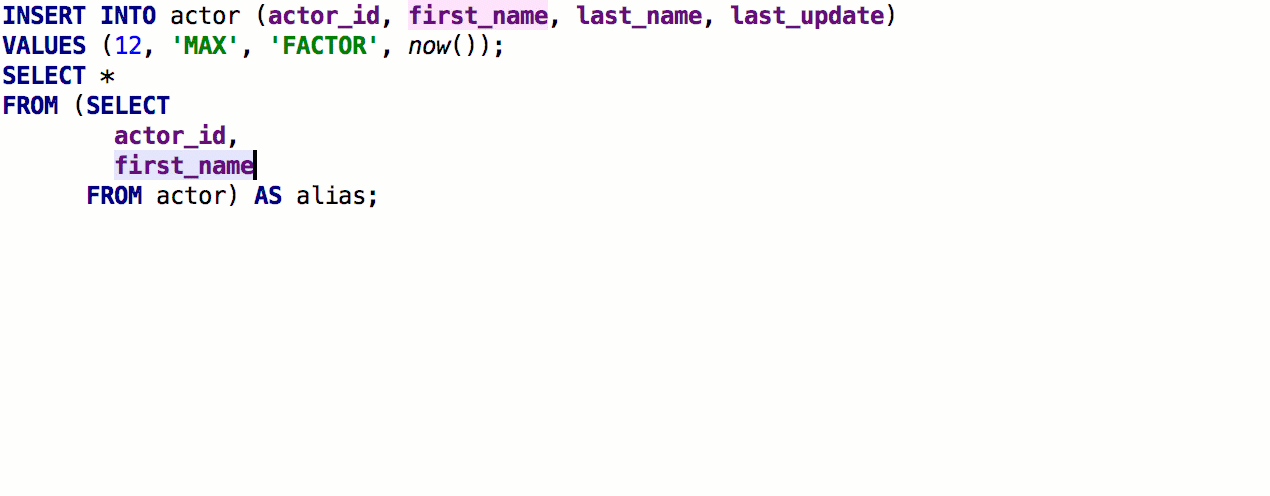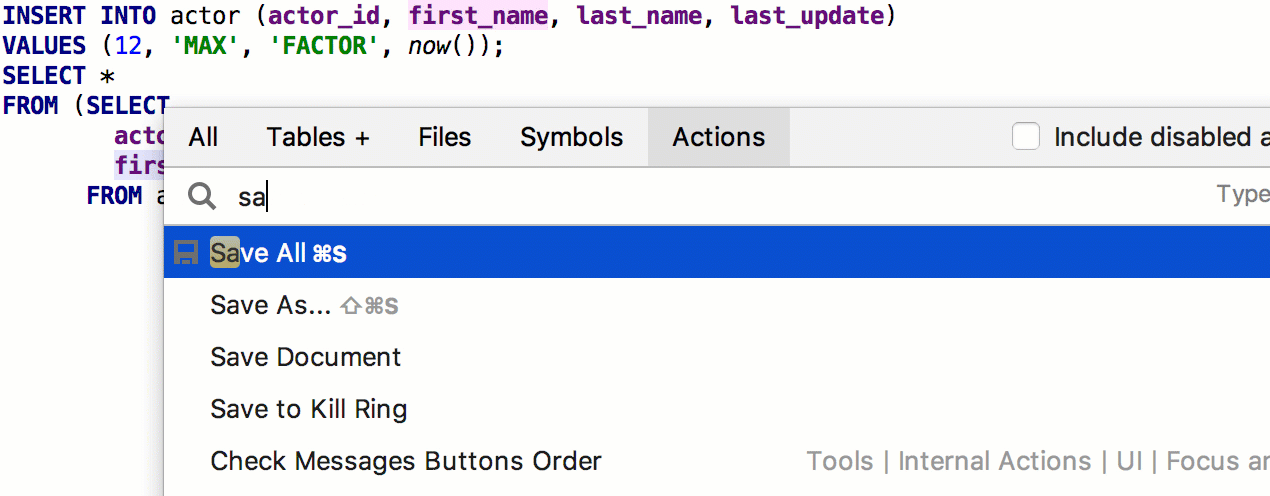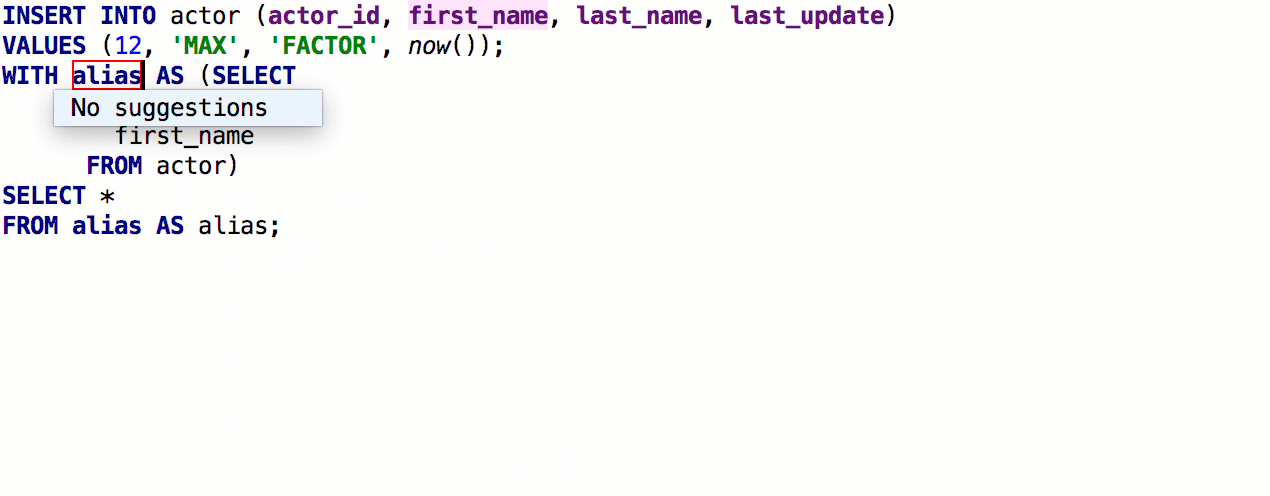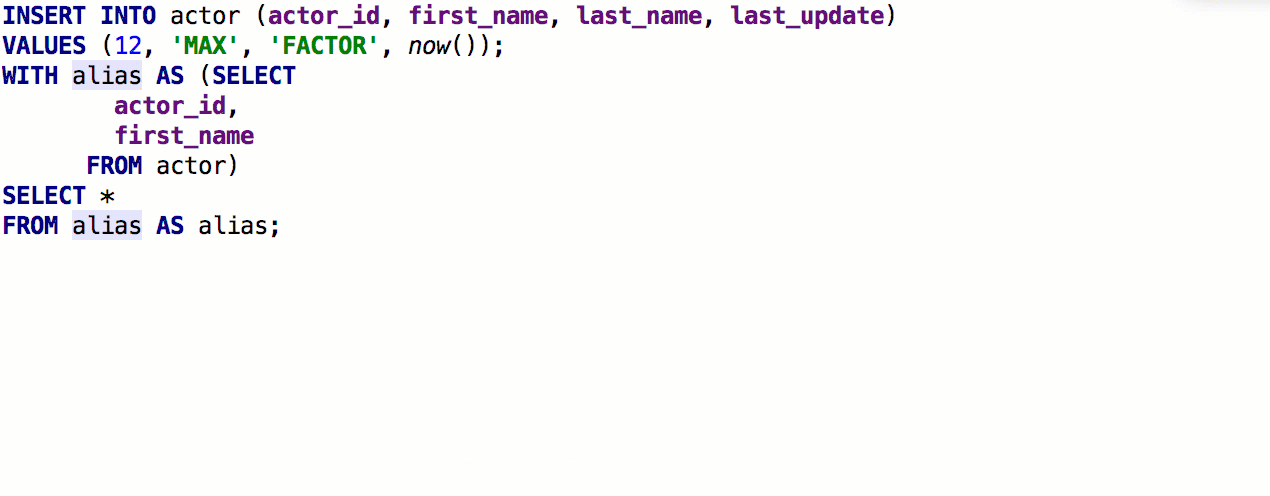
Что мы сделали:
– Новое имя для CTE не конфликтует с существующими: DBE-6496
– Правильно определяем контекст, если запрос обёрнут в другое выражение: DBE-6503, DBE-6517
– Не предлагаем рефакторинг в случае AS TableName: DBE-6490
– Поддержали для MySQL 8.
– Работает как надо с глубокими подзапросами. DBE-7332, DBE-7333
Шаблоны кода можно привязывать к диалектам — шаблон может работать для одних баз, и не работать для других.
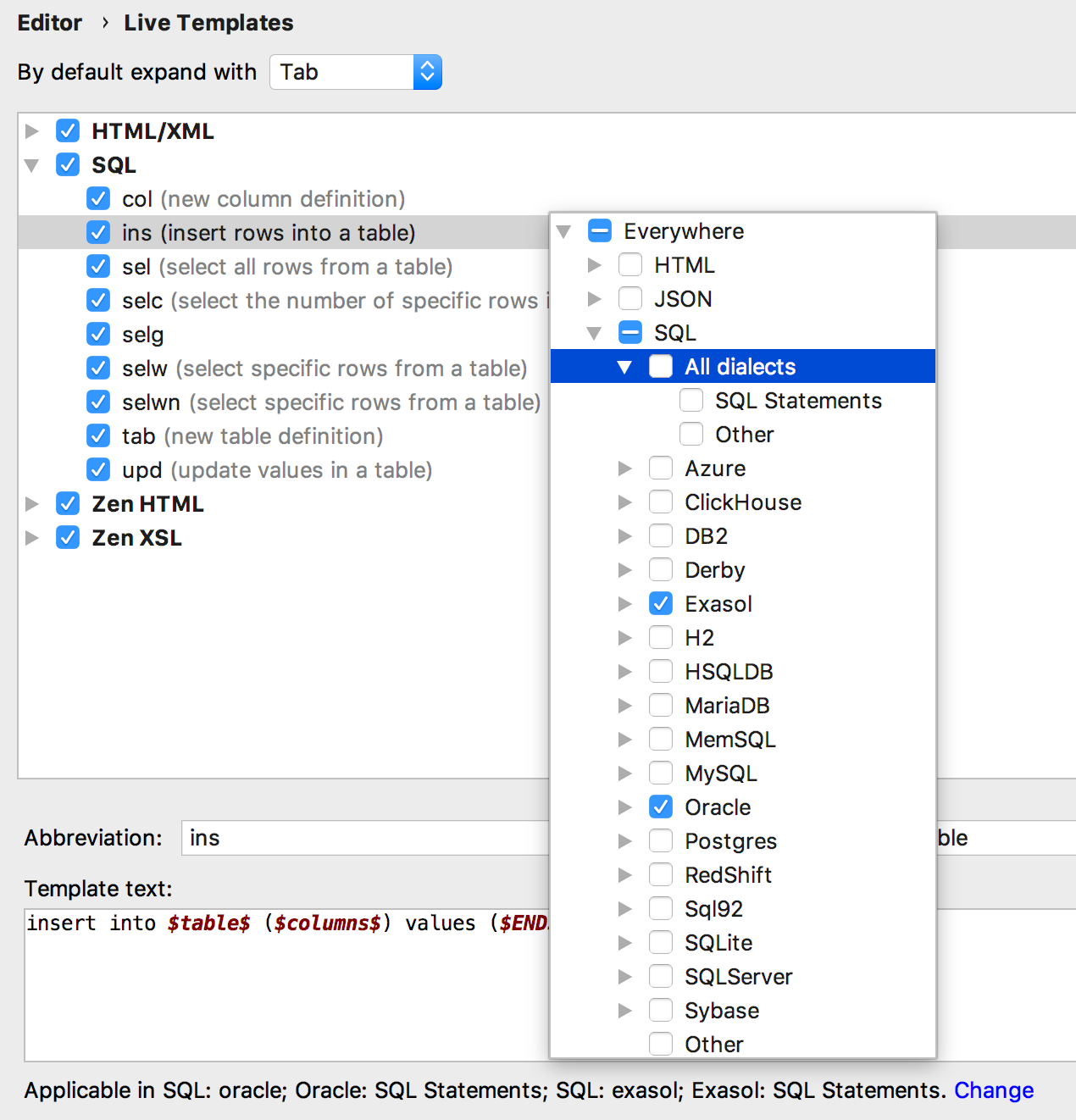
Что важнее: один и тот же шаблон может генерировать разный код для разных баз. Для этого создайте группы шаблонов для каждого диалекта, потому что одинаковые имена шаблонов не поддерживаются внутри одной группы (по умолчанию мы храним шаблоны в группе SQL).
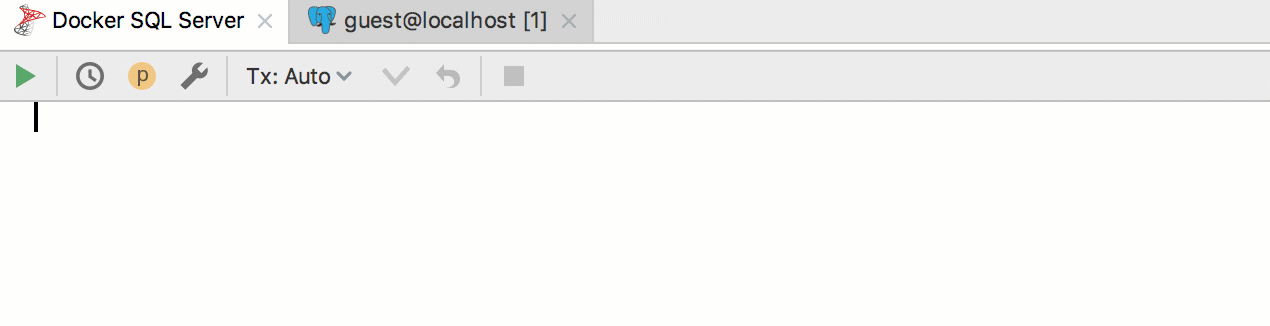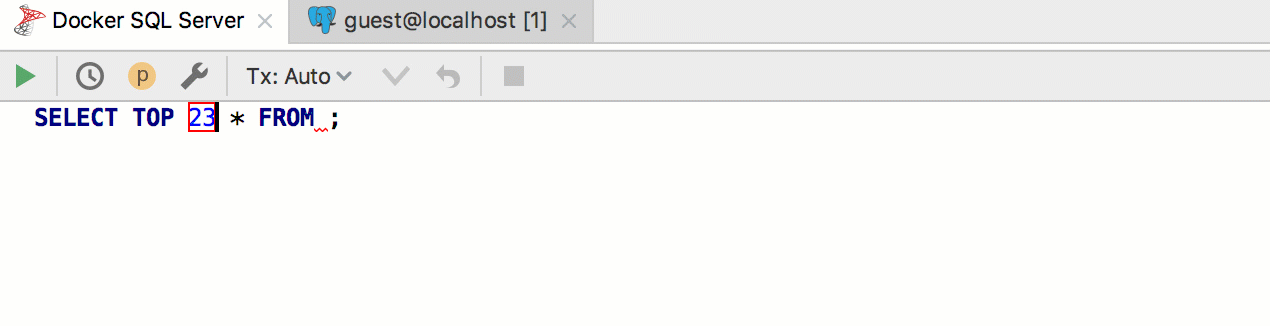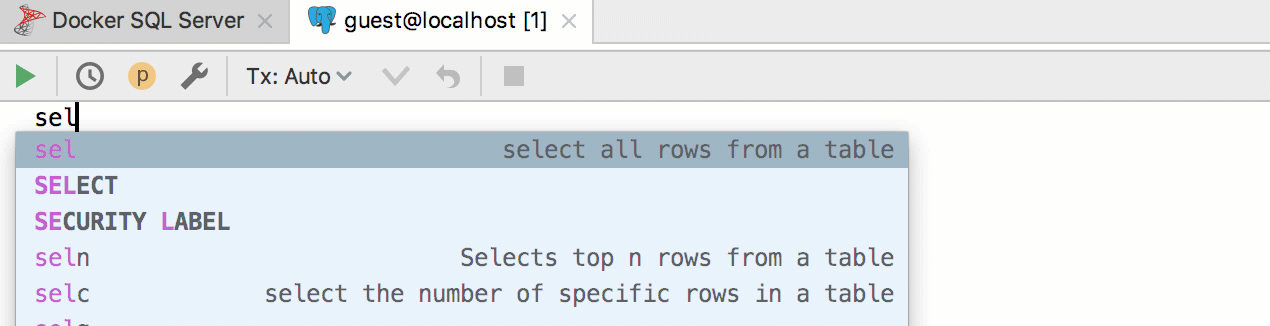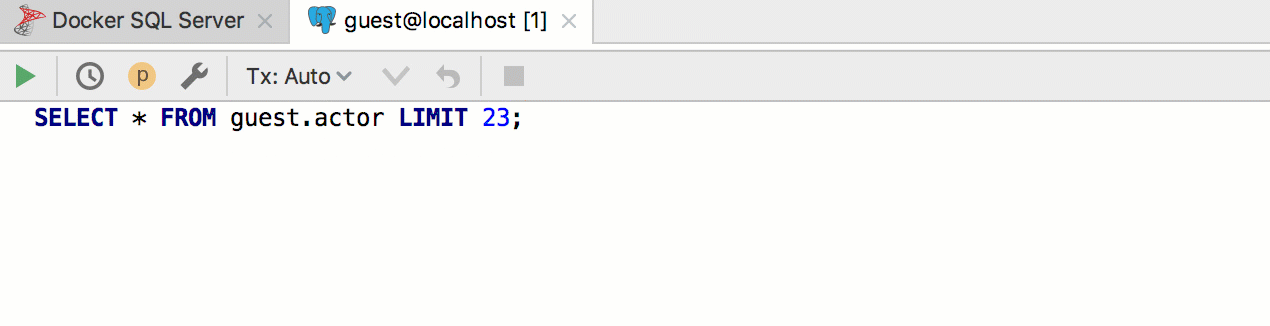
Например, хотим создать шаблон для вытаскивания первых n строк из таблицы. В postgreSQL и SQL Server для этого используется разный синтаксис, а мы будем всегда использовать шаблон

Получается так:
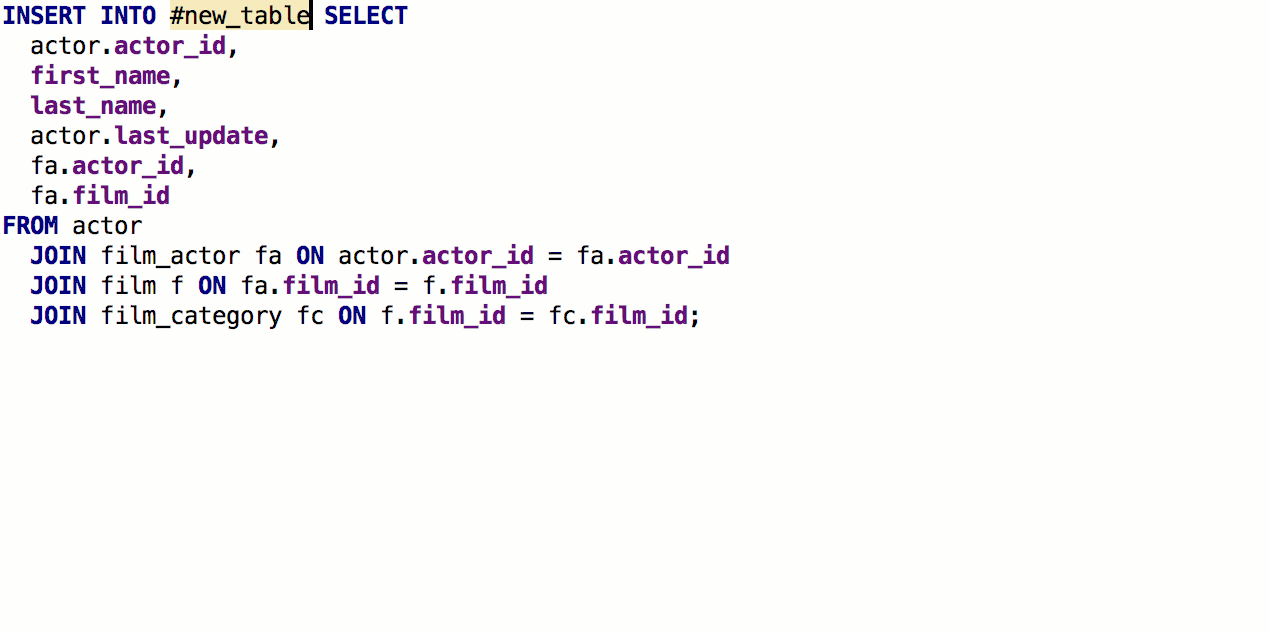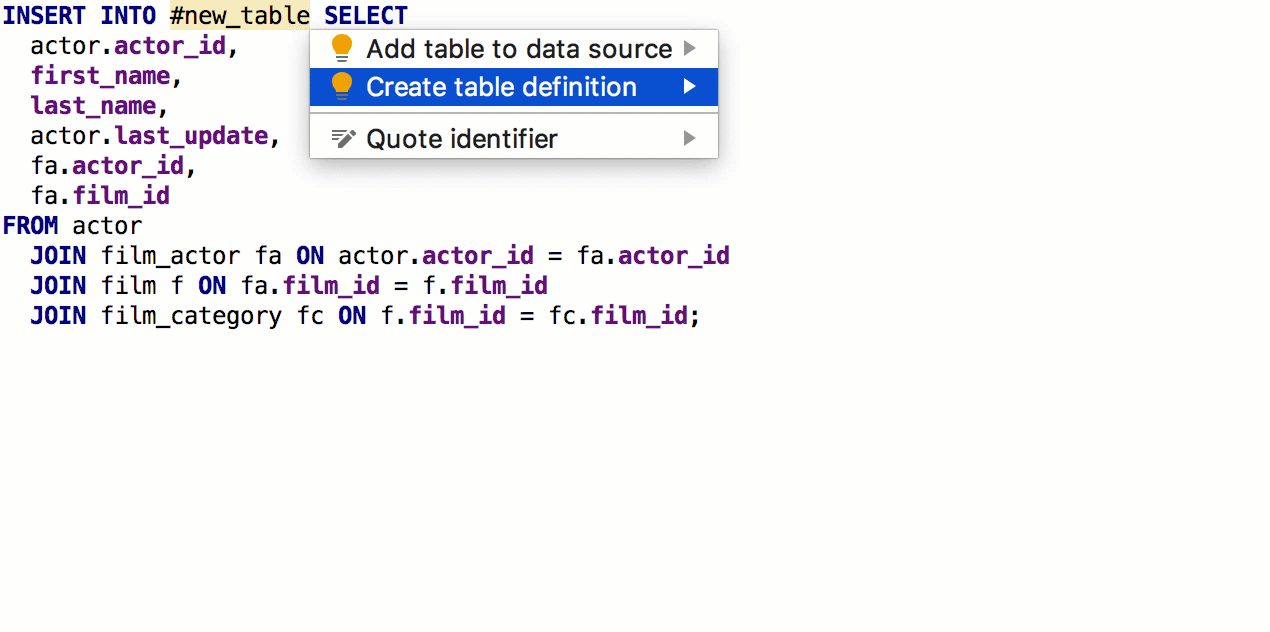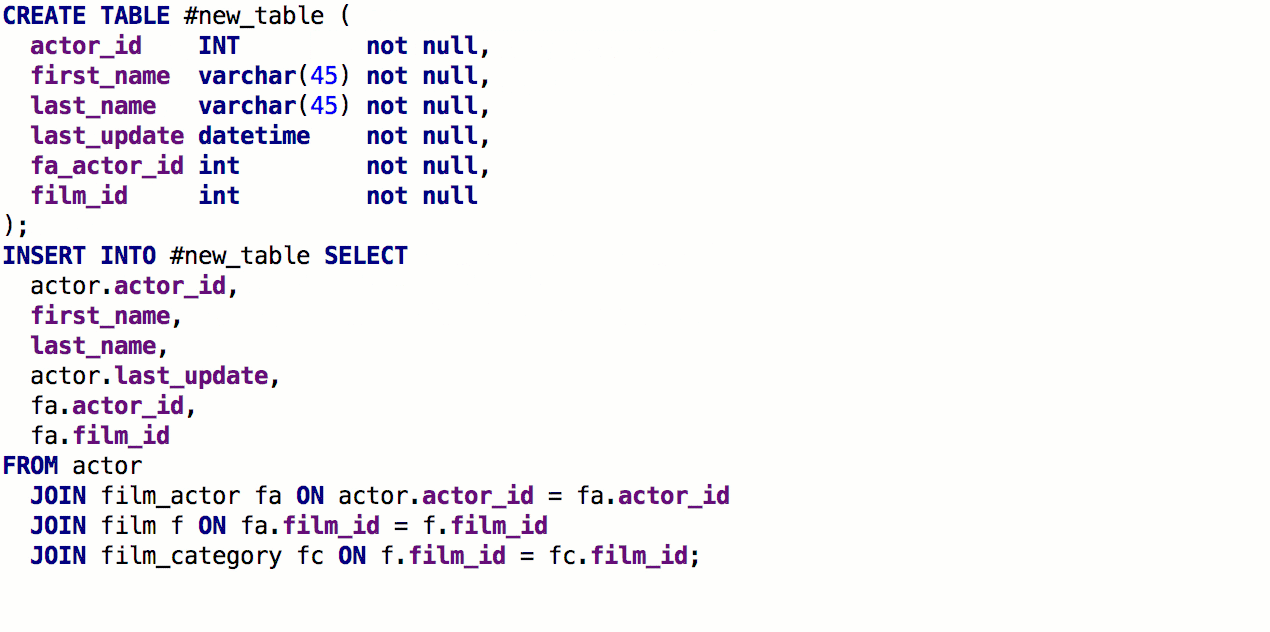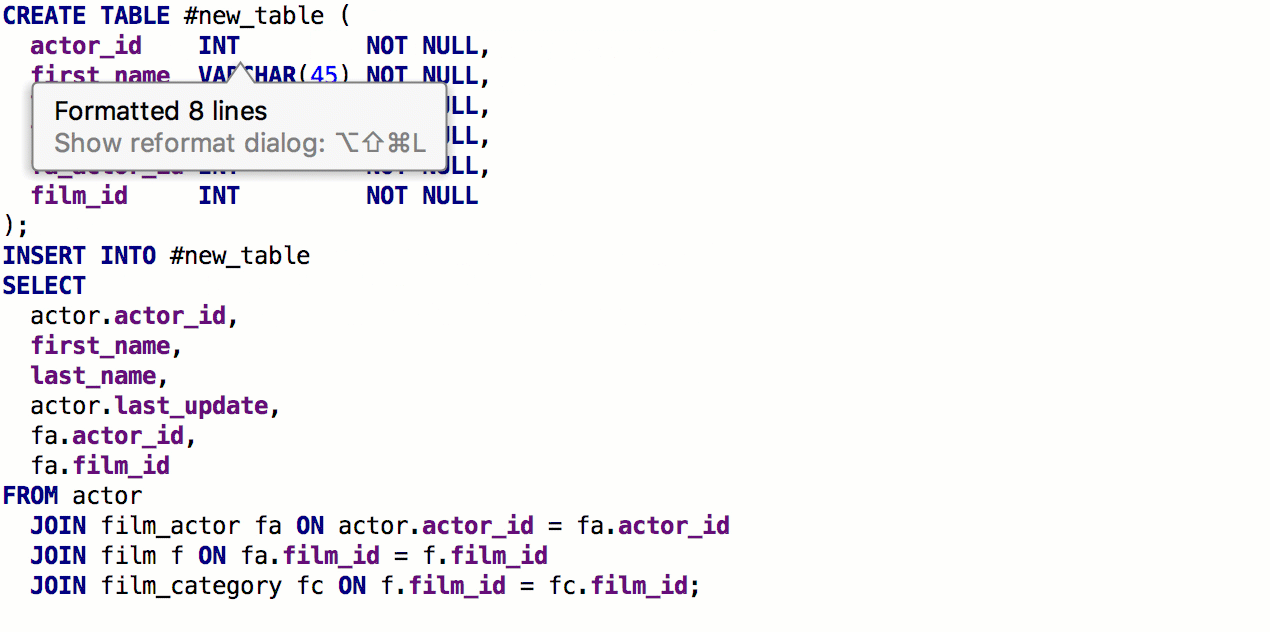
Из предложения SELECT теперь можно сгенерировать создание таблицы с такой же сигнатурой. Для этого нажмите Alt+Enter > Create table definition
И маленький фикс для шаблона INS — подсказки для имён столбцов показываются автоматически.

Добавили инспекции о небезопасных DELETE и UPDATE — предупредим, что вы потеряете данные.


А если запустите, уточним :)

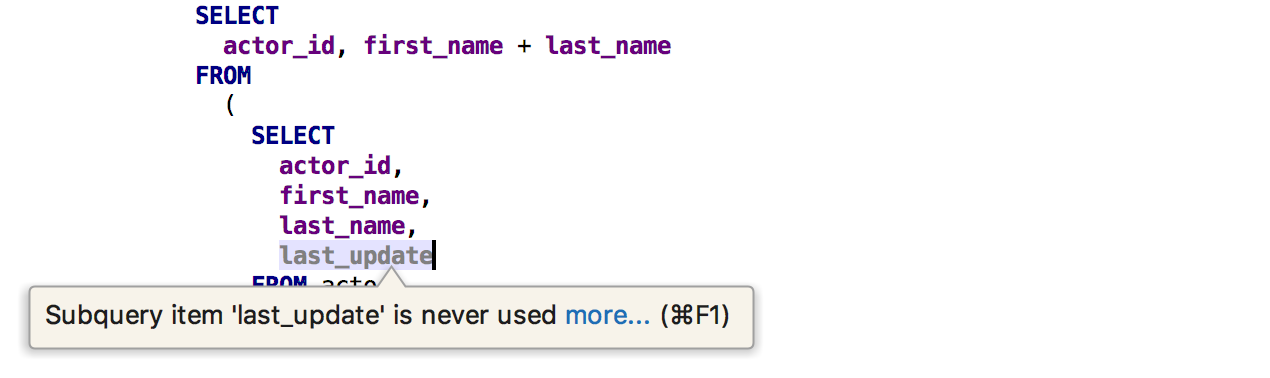
Ещё одна инспекция найдёт неиспользуемые столбцы из подзапроса.
А другая — неиспользуемый код.

SQL Generator (Ctrl/Cmd+Alt+G) научился писать результаты в файл: для этого нажмите кнопку Save.
По умолчанию доступны два способа организации файлов, но если вам нужны какие-то ещё, пишите в комментариях.
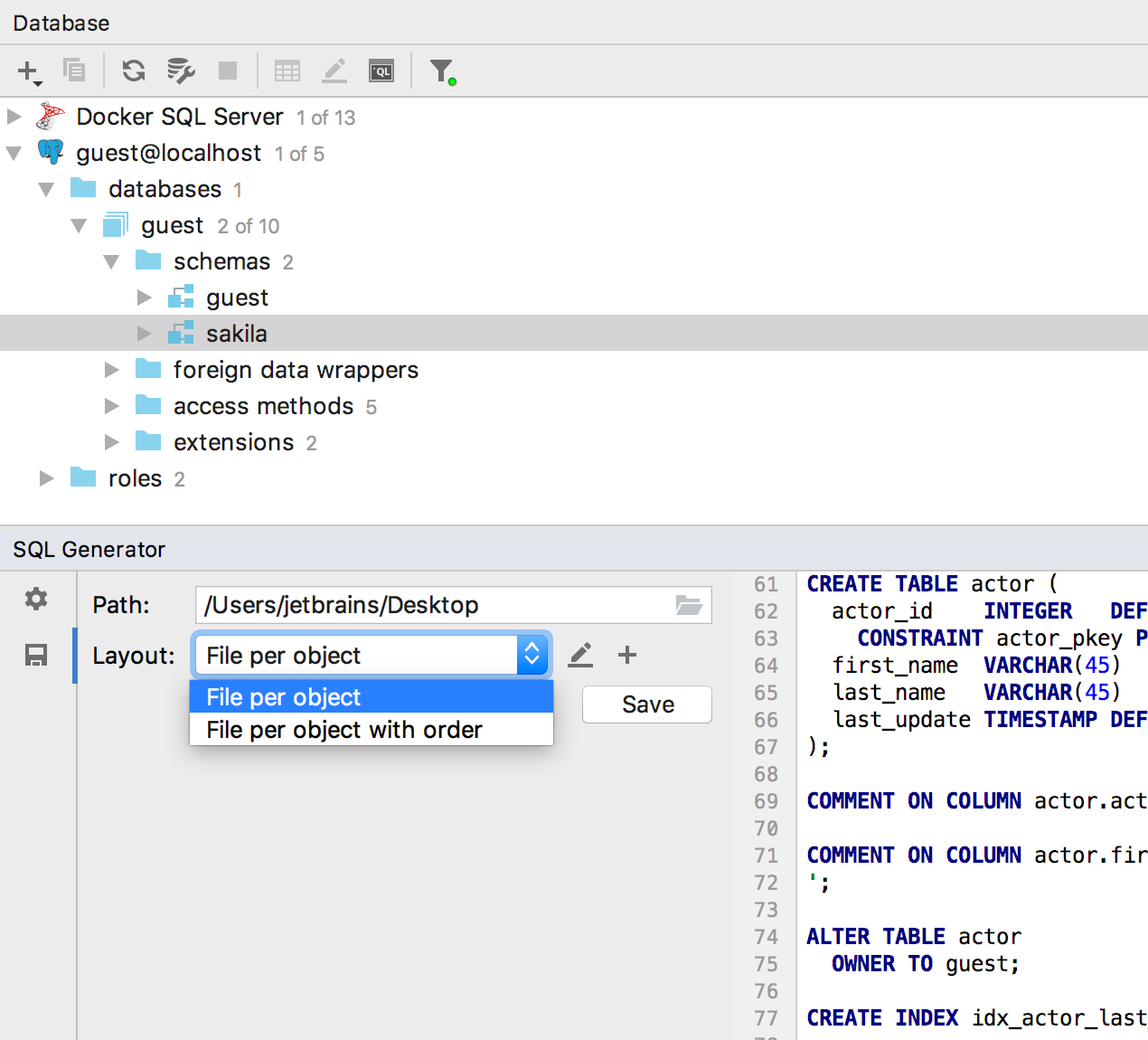
Или уже сейчас, если нажать на карандашик справа, можете редактировать соответствующие скрипты на groovy. Или создавать свои.
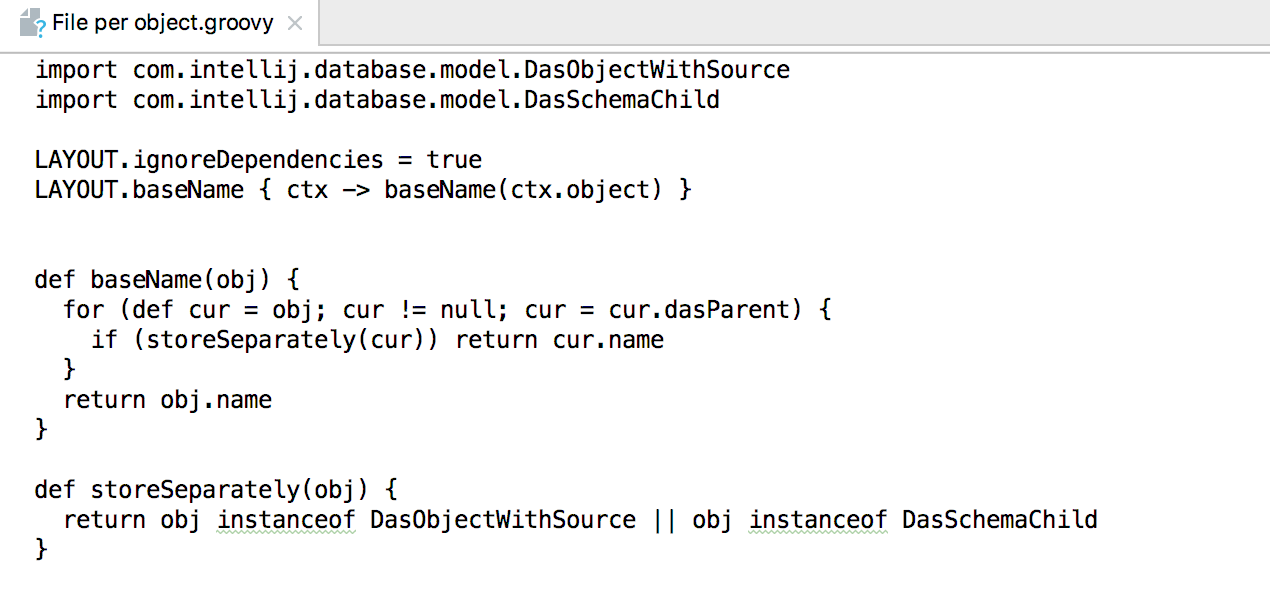
Поддержали расширения в PostgreSQL.
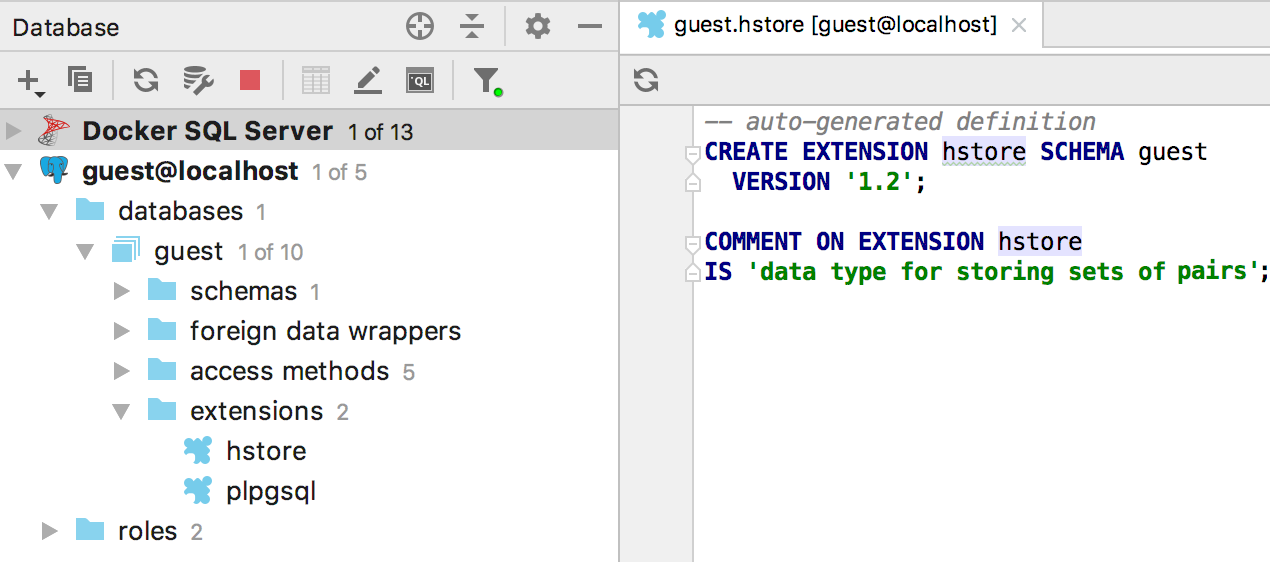
Показываем статистику в информационном окне для источника данных (Ctrl+Q для Windows/Linux, F1 для OSX), в том числе количество различных объектов.
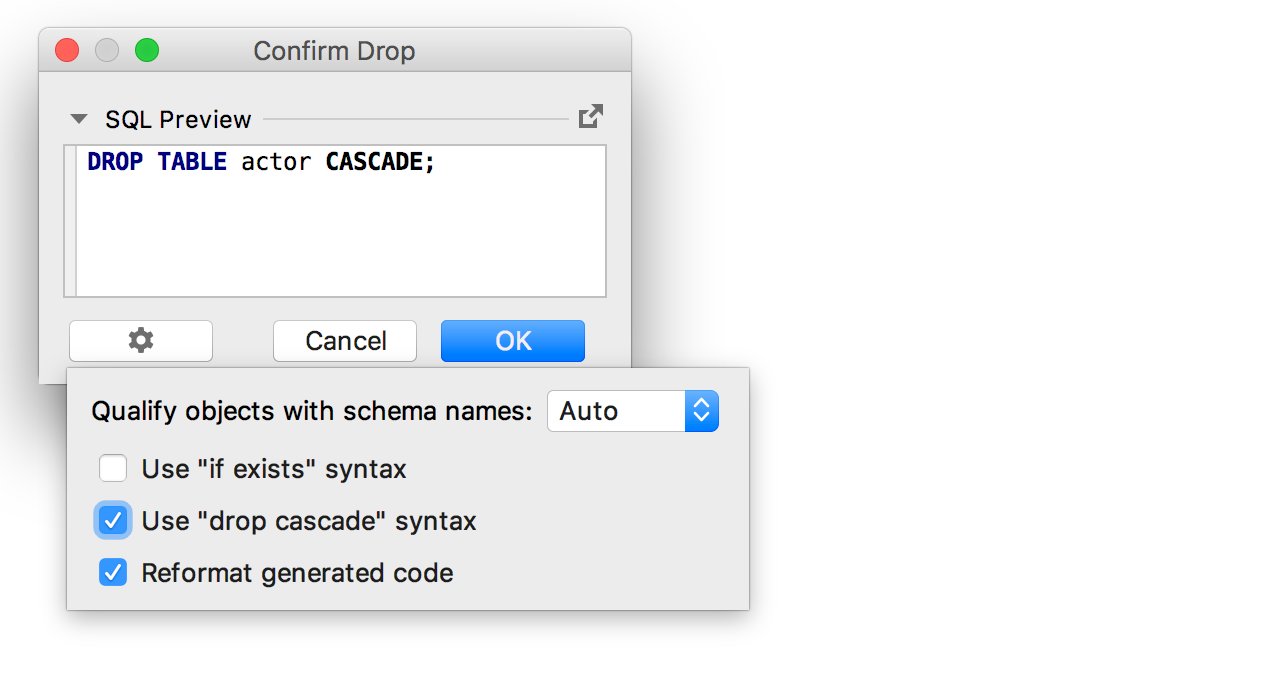
А при генерации кода для удаления объекта добавили опцию ‘Use drop cascade syntax’.
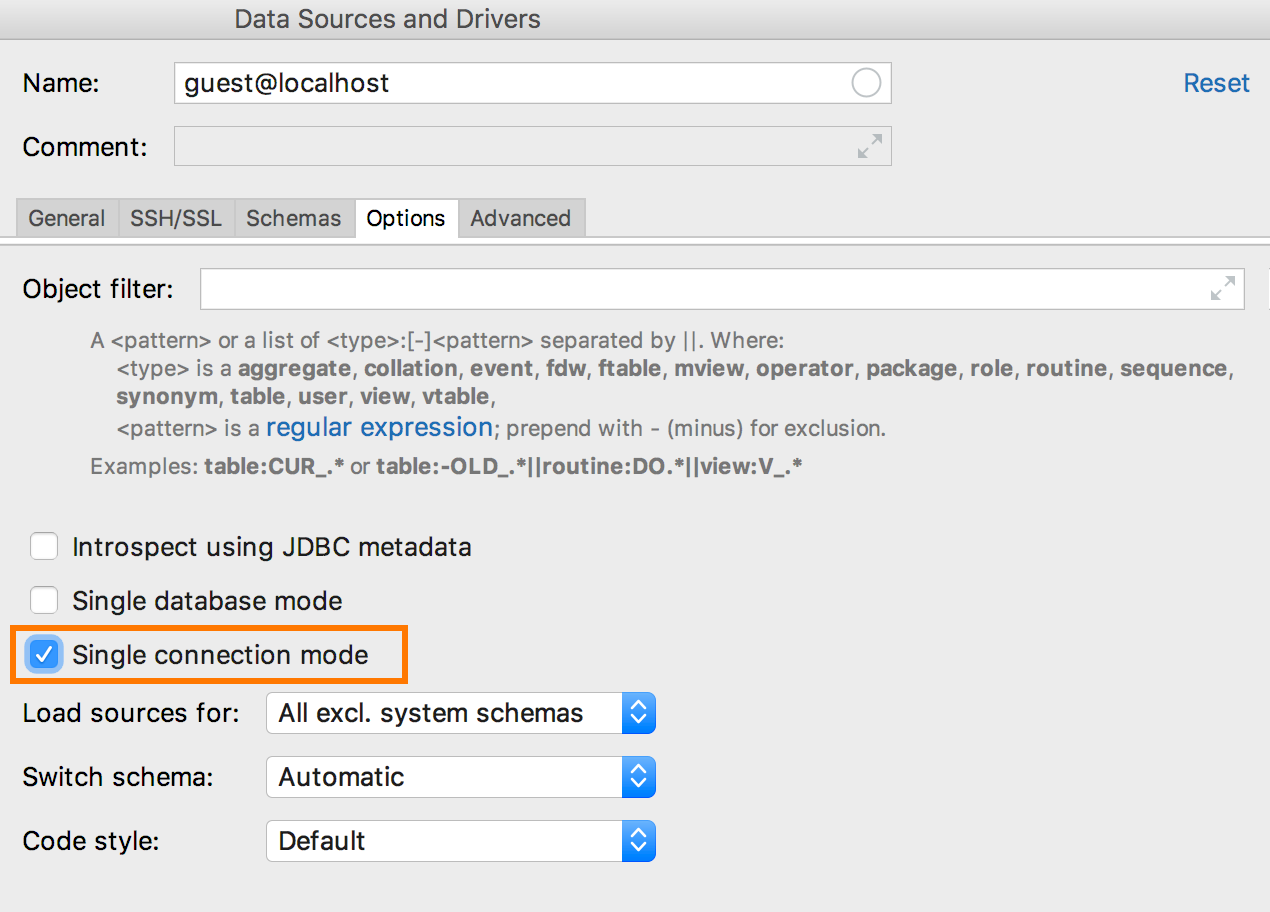
До нынешней версии каждая новая консоль означала новое соединение. Другие вещи, которым не требовалась консоль, тоже создавали отдельные подключения: запуск скриптов, импорт, графический интерфейс создания таблиц. В 2018.3, если включить Single connection mode в свойствах источника данных, вся работа с ним будет происходить через одно подключение.
В результате временные объекты появятся в дереве, а ещё консоли и редакторы данных будут работать внутри одной транзакции. Это — первый шаг к полному управлению подключениями, которым мы собираемся заняться.
А ещё сделали так, что IDE сама подсоединяется заново после простоя.
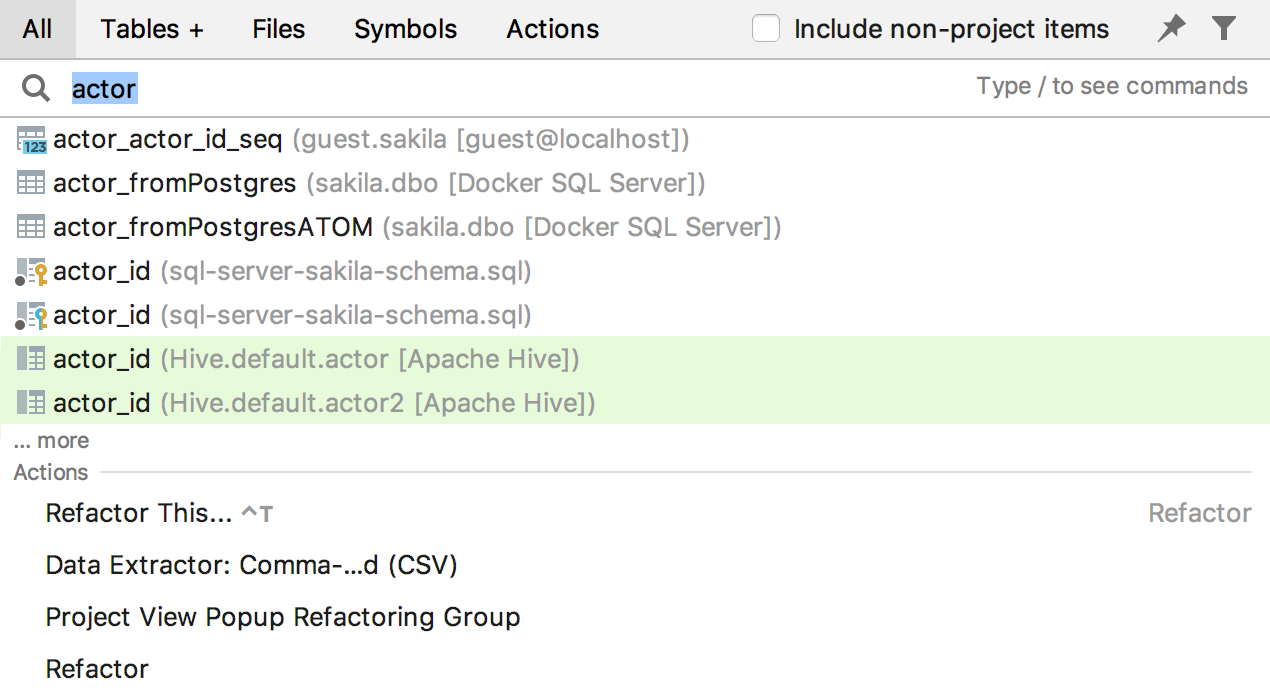
Платформа IntelliJ представила новый поиск: он соединил в себе разные типы поиска, которые были разрознены: Search Everywhere, Find Action, Go to table/view/procedure/, Go to File и Go to Symbol. В DataGrip вторая вкладка называется Tables, а в других IDE — Classes. Но делает она одно и то же: ищет и объекты базы данных, и классы. Клавиша Tab переключает вкладки.
Алгоритмы поиска мы серьёзно не меняли: если вдруг у вас раньше что-то искалось хорошо, а сейчас ищется плохо, пожалуйста пишите.
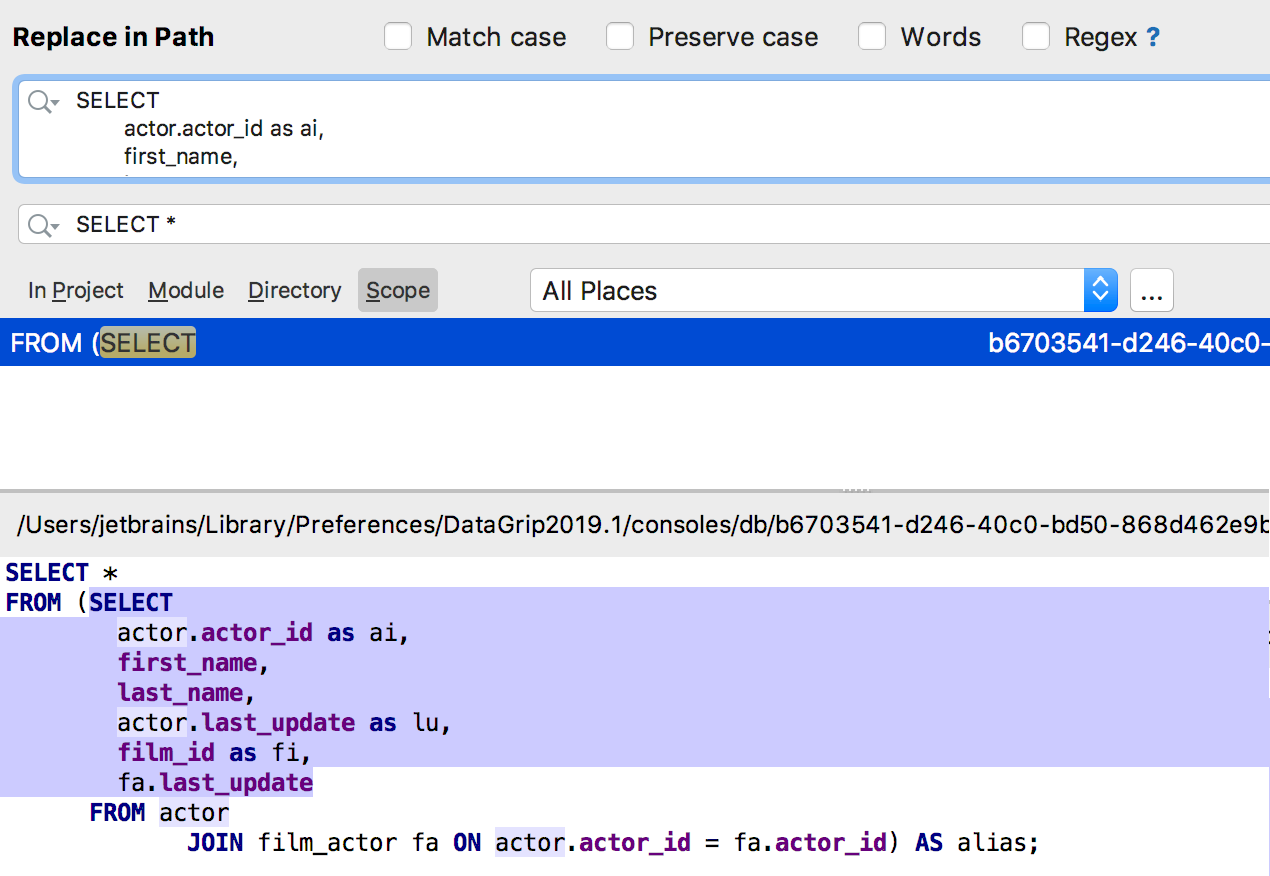
Несколько строк сразу теперь можно найти в «поиске везде» (Find in path). Для SQL особенно полезно — запрос найдётся внутри исходников объектов.
TODO-комментарии теперь могут быть многострочными. Чтобы в такой комментарий подцепились следующие строки, отделите их пробелом от символа комментария. Оформленные так задачи попадают в TODO Tool Window.
На картинке понятней:
Новая цветовая схема — очень контрастная.
Переключать схемы так: Нажмите Ctrl+` и выберите Look and Feel.
Появилось меню для выбора цвета источника данных в окне его свойств.
И немного дружелюбности добавили в поле выбора строк на страницу. Раньше, чтобы результат показывал все строки, нужно было сюда написать -1 :)
Теперь есть флажок.

Всё!
> Более подробно тут
> Скачать триал на месяц
> Твитер, который мы читаем
> Почта, которую мы читаем
> Баг-трекер
Команда DataGrip
- Поддержка Cassandra
- Создание SQL-файлов из объектов схемы
- Новые инспекции
- Много новых штук в автодополнении
- Работа с источником данных через одно подключение
- Новый поиск
- Высококонтрастная цветовая схема
Спасибо тем, кто пробует EAP-версии и сообщает в наш трекер о проблемах: это помогает не дотащить их до релиза :) Активные пользователи уже получили бесплатные подписки на год.
Поддержка Cassandra
Потихоньку осваиваем NoSQL-базы. Пока только те, что используют SQL-подобные языки для запросов. Мы поддержали Clickhouse в 2018.2.2, а в этом релизе добавили Cassandra.
Автодополнение
В этой подсистеме много нового.
Добавили возможность вставлять псевдонимы автоматически после имён таблиц. Если предложенный нами псевдоним вас не устраивает, укажите — какие псевдонимы использовать для конкретных имён.
В итоге, работает так:
При использовании GROUP BY DataGrip предложит список неагрегированных столбцов.
В предложении SELECT предлагается список всех столбцов.
Автодополнение работает для именованных параметров.
Ещё добавили информацию о контексте для одинаковых имён.
Наконец-то сделали postfix completion: это когда через точку пишут что-то, относящееся к объекту.
Например, если после SELECT написать имяТаблицы.afrom — раскроется в список столбцов и предложение FROM. Или, на наш взгляд самое удобное, можно дописать .cast к колонке или переменной.
Лучше один раз увидеть:
Автодополнение стало лучше для оконных функций: автоматически добавляется OVER() и каретка ставится в нужное место.
Рефакторинг
Важная штука, которую давно пора было сделать: использование псевдонима вместо таблицы. Нажмите на таблице Alt+Enter > Introduce alias. Использования таблицы будут заменены на псевдонимы.
После предыдущего релиза мы получили подробный фидбек от speshuric. Например, он нашёл много неочевидных сценариев для Extract subquery as a CTE. Этот рефакторинг вызывается через меню Refactor > Extract > Subquery as CTE, но мы советуем привыкать к Find Action (Ctrl+Shift+A).
Что мы сделали:
– Новое имя для CTE не конфликтует с существующими: DBE-6496
– Правильно определяем контекст, если запрос обёрнут в другое выражение: DBE-6503, DBE-6517
– Не предлагаем рефакторинг в случае AS TableName: DBE-6490
– Поддержали для MySQL 8.
– Работает как надо с глубокими подзапросами. DBE-7332, DBE-7333
Генерация кода
Шаблоны кода можно привязывать к диалектам — шаблон может работать для одних баз, и не работать для других.
Что важнее: один и тот же шаблон может генерировать разный код для разных баз. Для этого создайте группы шаблонов для каждого диалекта, потому что одинаковые имена шаблонов не поддерживаются внутри одной группы (по умолчанию мы храним шаблоны в группе SQL).
Например, хотим создать шаблон для вытаскивания первых n строк из таблицы. В postgreSQL и SQL Server для этого используется разный синтаксис, а мы будем всегда использовать шаблон
seln. Соответственно, реализуйте два шаблона в двух разных группах и присвойте им соответствующие диалекты.Получается так:
Из предложения SELECT теперь можно сгенерировать создание таблицы с такой же сигнатурой. Для этого нажмите Alt+Enter > Create table definition
И маленький фикс для шаблона INS — подсказки для имён столбцов показываются автоматически.
Анализ кода
Добавили инспекции о небезопасных DELETE и UPDATE — предупредим, что вы потеряете данные.
А если запустите, уточним :)
Ещё одна инспекция найдёт неиспользуемые столбцы из подзапроса.
А другая — неиспользуемый код.
Объекты базы данных
SQL Generator (Ctrl/Cmd+Alt+G) научился писать результаты в файл: для этого нажмите кнопку Save.
{kind=link}
По умолчанию доступны два способа организации файлов, но если вам нужны какие-то ещё, пишите в комментариях.
Или уже сейчас, если нажать на карандашик справа, можете редактировать соответствующие скрипты на groovy. Или создавать свои.
Поддержали расширения в PostgreSQL.
Показываем статистику в информационном окне для источника данных (Ctrl+Q для Windows/Linux, F1 для OSX), в том числе количество различных объектов.
А при генерации кода для удаления объекта добавили опцию ‘Use drop cascade syntax’.
Соединение
До нынешней версии каждая новая консоль означала новое соединение. Другие вещи, которым не требовалась консоль, тоже создавали отдельные подключения: запуск скриптов, импорт, графический интерфейс создания таблиц. В 2018.3, если включить Single connection mode в свойствах источника данных, вся работа с ним будет происходить через одно подключение.
В результате временные объекты появятся в дереве, а ещё консоли и редакторы данных будут работать внутри одной транзакции. Это — первый шаг к полному управлению подключениями, которым мы собираемся заняться.
А ещё сделали так, что IDE сама подсоединяется заново после простоя.
Поиск и навигация
Платформа IntelliJ представила новый поиск: он соединил в себе разные типы поиска, которые были разрознены: Search Everywhere, Find Action, Go to table/view/procedure/, Go to File и Go to Symbol. В DataGrip вторая вкладка называется Tables, а в других IDE — Classes. Но делает она одно и то же: ищет и объекты базы данных, и классы. Клавиша Tab переключает вкладки.
Алгоритмы поиска мы серьёзно не меняли: если вдруг у вас раньше что-то искалось хорошо, а сейчас ищется плохо, пожалуйста пишите.
Несколько строк сразу теперь можно найти в «поиске везде» (Find in path). Для SQL особенно полезно — запрос найдётся внутри исходников объектов.
TODO-комментарии теперь могут быть многострочными. Чтобы в такой комментарий подцепились следующие строки, отделите их пробелом от символа комментария. Оформленные так задачи попадают в TODO Tool Window.
На картинке понятней:
Интерфейс
Новая цветовая схема — очень контрастная.
Переключать схемы так: Нажмите Ctrl+` и выберите Look and Feel.
Появилось меню для выбора цвета источника данных в окне его свойств.
И немного дружелюбности добавили в поле выбора строк на страницу. Раньше, чтобы результат показывал все строки, нужно было сюда написать -1 :)
Теперь есть флажок.
Всё!
> Более подробно тут
> Скачать триал на месяц
> Твитер, который мы читаем
> Почта, которую мы читаем
> Баг-трекер
Команда DataGrip
gudvinr
Пожалуйста, поддержите фильтрацию схем в настройке
Object filterисточника данных, или учитывайтеpg_toast_*/pg_temp_*при выбореAll. excl. system schemasв постгресе.Утомляет постоянно их вручную скрывать, когда это нужно делать на нескольких серверах, где может быть много таких таблиц.
moscas Автор
На это есть тикет: youtrack.jetbrains.com/issue/DBE-5781
Нынешний фильтр, который работает для таблиц и других объектов того же уровня, фильтрует только отображение, а не инстроспекцию. То есть мы все равно считываем инфомрацию о «ненужных» объектах, показываем их в автодополнении, но не показываем в дереве.
Вероятно, стоит подумать о том, чтобы фильтры влияли на интроспекцию тоже.
gudvinr
Да хоть бы на отображение, пускай считываются. Неудобство создаёт то, что эти схемы в дереве занимают места больше, чем пользовательские таблицы.
moscas Автор
А вы раскрываете ноды с этими схемами?)
gudvinr
Нет, они же пустые, но когда на 500 схем приходится 400 на тосты, это немного затрудняет навигацию по списку между схемами, которые находятся до буквы
pи теми, которые после неё.moscas Автор
На всякий случай напомню, что если начать печатать, находясь в дереве будет работать навигация по искомой строке.
Но фильтр, конечно, надо сделать :)