

Более пяти лет назад компания Backblaze опубликовала первый отчёт по использованию дисковых накопителей в своих серверах. Backblaze предоставляет услугу дешёвого облачного бэкапа. В основе их инфраструктуры — жёсткие диски потребительского класса. Компания собрала большую статистику по отказоустойчивости разных типов HDD. В то время парк накопителей Backblaze состоял в основном из дисков Seagate, Hitachi и WD, а самыми надёжными оказались диски Hitachi.
С тех пор Backblaze публикует статистику ежегодно, и сейчас пришло время очередного отчёта.
По состоянию на 31 декабря 2018 года у компании было 106 919 активных HDD, из них 1965 загрузочных дисков и 104 954 дисков с данными. В обзоре указаны коэффициенты отказов жёстких дисков с данными в дата-центрах компании. Также рассматриваются новые модели HDD, которые добавили в серверные стойки на протяжении 2018 года, включая модель HGST на 12 ТБ и Toshiba на 14 ТБ. Понятно, что по новым моделям пока не собрано много статистики, потому что их установили лишь недавно и количество небольшое. Так что ещё рано окончательно хоронить, например, модель Toshiba MG07ACA14TA с показателем отказов 3,03% (если привести к годовому исчислению). Может, просто попалась неудачная партия.
В таблице указаны только те модели, для которых собрана статистика хотя бы с 45 экземпляров (некоторые из таких накопителей использовались просто для тестирования). Цифра 45 — это минимальное количество, необходимое для заполнения одного модуля хранения Backblaze Storage Pod в дата-центре. Таким образом, из 104 954 жёстких дисков для анализа статистики осталось 104 778 штук.
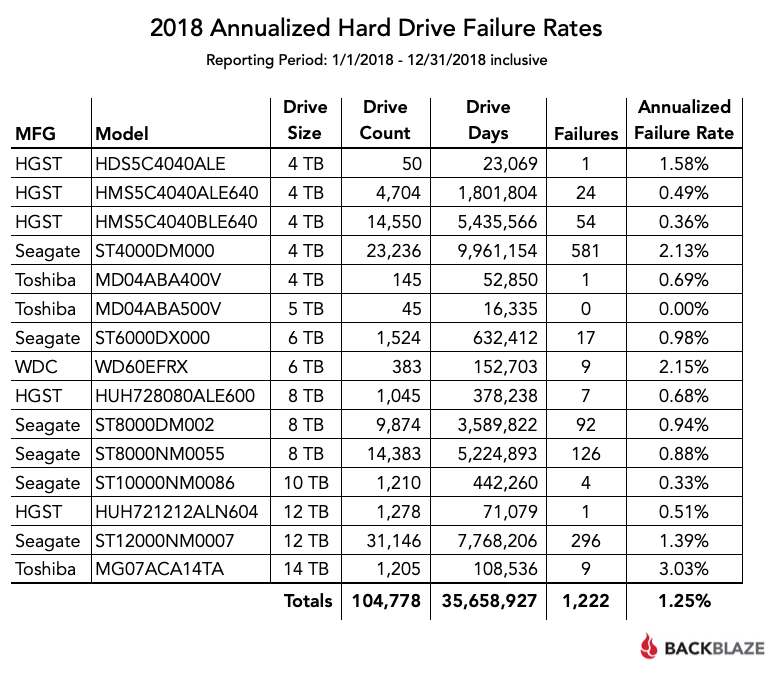
Примечание: годовой уровень отказов 0,00% означает, что на протяжении 2018 года не было ни одного отказа
Специалисты Backblaze признают, что по итогам 2018 года общий показатель отказов в годовом исчислении (Annualized Failure Rate, AFR) оказался очень хорошим: всего 1,25%. Для сравнения, в 2013 году цифры были гораздо хуже, а некоторые модели Seagate тогда сыпались вплоть до AFR 25,4% (модель Seagate Barracuda 7200, ST31500341AS). Особенно критичными для дисков Seagate тогда стали второй и третий годы эксплуатации.
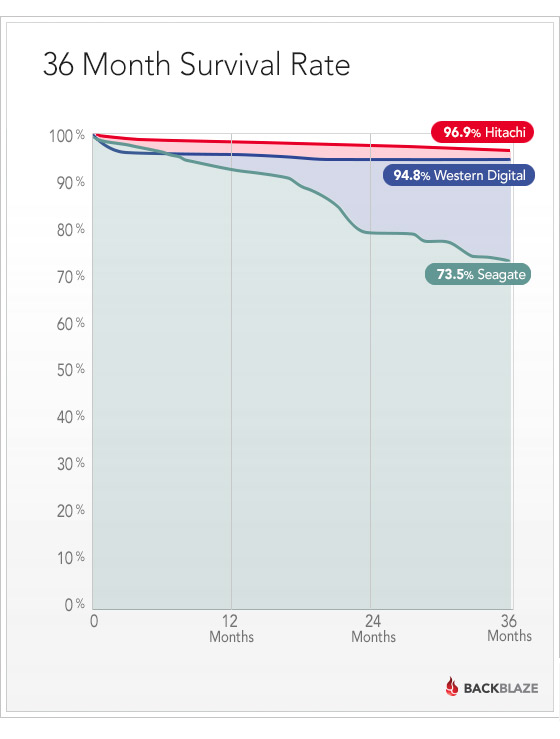
Статистика из первого отчёта Backblaze за 2013 год
Сейчас все модели проявили себя как весьма надёжные накопители. Исключение составляют случаи, когда в наличии было небольшое количество экземпляров конкретной модели (менее 500) и/или они все вместе наработали небольшое количество дней (менее 50 000). В этих случаях показатель AFR нельзя считать надёжным для принятия решений о покупке.
Общий показатель AFR для всех моделей за год составил всего 1,25%, что значительно ниже показателей предыдущих лет.
Backblaze пишет, что в 2018 году заметной тенденцией стала замена старых дисков на 2, 3 и 4 ТБ на накопители объёмом 8, 10, 12, а в четвёртом квартале — ещё на 14 ТБ. Можно предположить, что эта тенденция характерна не только для Backblaze, но и для всего потребительского рынка: многие пользователи в прошлом году сделали такой апгрейд. В 2018 году у Backblaze общий объём хранилища с вырос с 500 до более 750 петабайт, в среднем добавлялось по 75 дисков в день.
После прошлогодних апгрейдов в хранилище практически не осталось дисков Western Digital, сейчас работают всего 383 штуки, все на 6 ТБ, это лишь 0,37% общего количества накопителей.
Backblaze отмечает хорошие показатели дисков HGST (модель HUH721212ALN604). За первый месяц тестирования 1200 таких накопителей зарегистрирован всего один отказ, так что компания решила нарастить их парк. Но самым популярным диском в дата-центре стала модель Seagate на 12 ТБ (ST12000NM0007), на которой работает 29,7% фермы.
Следующая таблица сравнивает AFR по годам и демонстрирует, насколько более надёжными стали диски в 2018 году: количество отказов планомерно снижается третий год подряд.
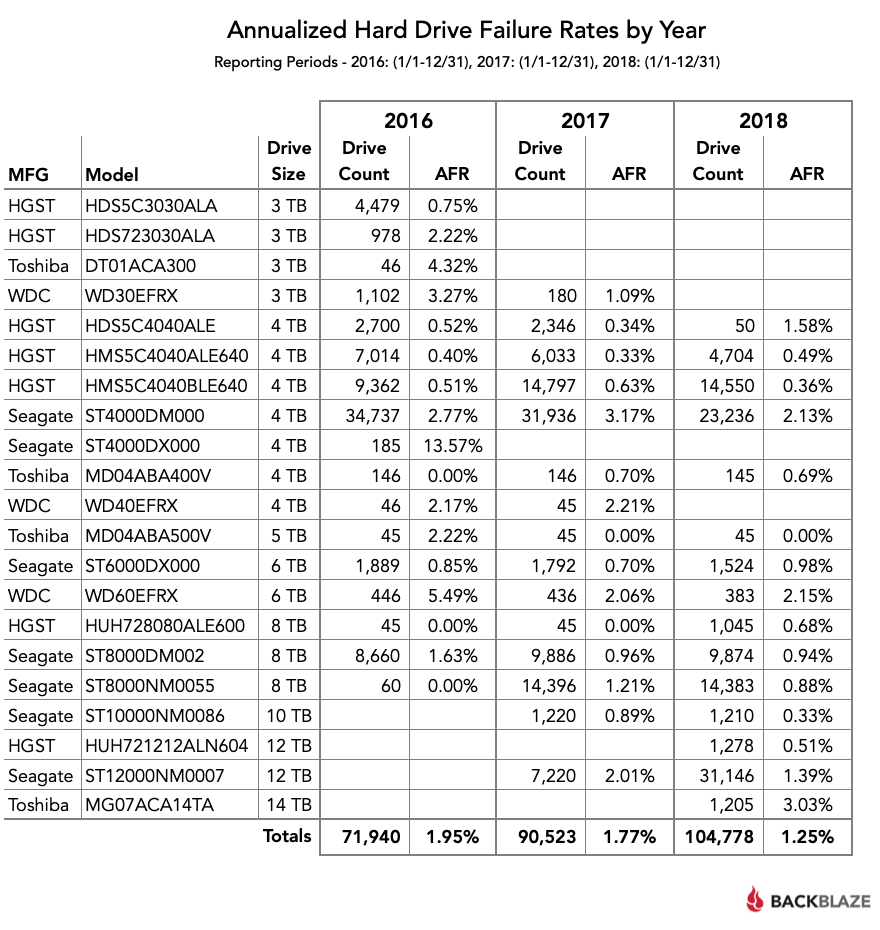
Ещё одно интересное наблюдение: ни один из 45 дисков Toshiba на 5 ТБ не вышел из строя со второго квартала 2016 года (модель MD04ABA500V). Также продолжает впечатлять надёжность дисков Seagate на 10 ТБ (модель ST10000NM0086) с AFR за прошлый год всего 0,33%, причём здесь 1220 дисков в общей сложности наработали около 500 000 дней, так что статистика вполне надёжная.
Наконец, в последней таблице приводятся показатели отказов жёстких дисков за всё время с апреля 2013 года — для тех моделей, которые находятся в эксплуатации до сих пор.
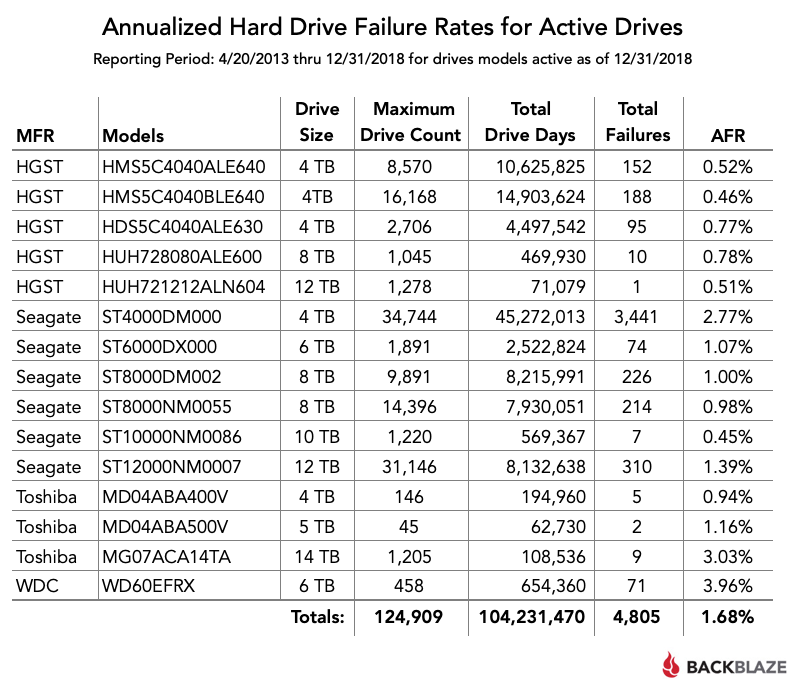
Полный набор данных этого обзора опубликован здесь. Если нужны только таблицы из этой статьи, можно скачать файл CSV с данными.
Комментарии (67)



DaylightIsBurning
23.01.2019 15:21+1Не понимаю, почему они не фокусируются в своих отчётах на time-dependent survival rate, как на графике. Какой толк от Annualized Failure Rate, если они сами говорят, что этот показатель меняется во времени и для одной и той же модели будет разным в зависимости от возраста экземпляров. Наверняка распределение возрастов для разных моделей разной, тогда что о чем нам говорит AFR?
Вот нашел более полезный анализ:

lingvo
23.01.2019 20:05Да. И вопрос, как они меняют HDD — по мере отказов, или по истечению определенного срока службы?
DaylightIsBurning
23.01.2019 20:18Если считать как в в приведенном мной анализе, — это неважно, а так как в посте, то да, ерунда получается.
berez
23.01.2019 21:47ЕМНИП, по мере выхода новых винтов большего объема они закупают эти винты и заменяют ими старые, мелкие. Потому как количество данных постоянно растет, а держать кучу старых мелких дисков — это лишние расходы на электричество и обслуживание. Собственно, этот процесс постепенно привел к тому, что диски в их отчетах уже не совсем потребительские. Далеко не каждый потребитель готов купить себе дисочек на 12 терабайт.

blind_oracle
23.01.2019 15:22+1Могу подтвердить надежность Хитачей: много лет юзаю дома в режиме 24х7 3Тб модели HUA5C3030ALA640 и HUA723030ALA640 (5900 и 7200rpm), штук 15 в сумме — ни один не помер, даже Reallocated секторов нет. Уже лет 8 им, как мне кажется. Power-on Hours у многих более 6 лет.

Alexufo
24.01.2019 05:30Аниме? Семейные фото? Фильмы с Пауло Виладжо?
blind_oracle
24.01.2019 12:05+1Все вышеперечисленное и многое другое :)
Ну, на самом деле, там не все винты у меня — я родителям NAS делал в т.ч.
Хотя, я тут немного не в топике — эти винты скорее серверного класса, поэтому удивляться надежности не стоит наверное.cyberly
24.01.2019 14:15Во времена 11 серии Seagate у меня их было 2 обычных и один серверный. И «серверность» последнего совершенно никак не повлияла на его долголетие. Так что я думаю, enterprise может быть про гарантию, про прошивку, про оптимзации скорости или энергопотребления, но никак не про надежность. Ну и вообще, бывает еще «энтерпрайзнее», «брендовее» и дороже, например, у какого нибудь HP или Dell, но там просто такой же диск, салазки и наклейка.
CherryPah
25.01.2019 00:49Наклейка HP еще повышает шанс не нарваться на какую-нить неудачную партию винтов с повышенным шансом брака.
Да и вопрос гарантии при больших объемах, когда в ДЦ едешь с коробкой винтов под замену дохлым — становится навязчивым в финансовом плане.
Мы как-то закупили у непроверенного поставщика большую партию винтов и по результатам сборки схд в отбраковку ушло 7% — решили вернуть их по гарантии. Поставщик в результате кинул нас через одно место найдя на винтах какие-то невидимые невооруженным глазом следы физического воздействия. С брендовыми винтами с наклейкой HP думаю такой бы проблемы не было.
Хотя это конечно никак не может оправдать итоговую стоимость этой наклейки, в ынтерпрайзе она совсем уж какая-то неприличная становится
momai
24.01.2019 10:51Много лет держу дома сервер. Всего 6 хардов разного объема и производителя. С Сеагейтами раньше всегда была проблема, дохли регулярно. Сейчас уже 5 лет тьфу тьфу работают как надо все харды что есть. А там и сеагейт и вд и даже хитачи. У всех наработано уже больше 50к часов, а на некоторых и все 80, однако отказов нет, хоть и работают 24\7.
blind_oracle
24.01.2019 12:41Ну, износ механики чаще всего как раз происходит при парковке головок и старте-остановке (кроме подшипников шпинделя), поэтому возможно режим 24х7 как раз более щадящий для многих дисков…
Помнится, были какие-то (ноутбучные?) диски WD, которые парковались как бешеные при любом простое — у многих у меня было по 200-300к Load-In/Out в смарте. Лечилось утилиткой wdidle.alexanster
24.01.2019 13:54Это были WD Green, 3,5" 5к, которые парковали головки уже через 8 секунд.
berez
24.01.2019 14:55Нынешние WD Blue точно так же норовят упарковаться в ноль за пару дней. Помню, поставил в NAS свежую вэдешку WD30EZRZ, через пару дней посмотрел ее смарт — и офигел. Пришлось срочно искать, чем ей подкрутить время таймаута до парковки (подсказка: idle3ctl).
alexanster
24.01.2019 15:23Так несколько лет назад WD «упразднил» линейку Green, объединив её с Blue, а то у первой слишком много нелицеприятных отзывов было. И если раньше сразу понятно было: вот Blue — десктопный диск со средними характеристиками, а вот Green — тормознутое глючное убожество, то после этого стало нужно лезть и в характеристики и смотреть, кто есть ху. Короче, WD30EZRZ — это грин и есть.
blind_oracle
24.01.2019 15:46Может и они тоже, но мои были синие и 2.5" форм-фактором :)
Судя по комменту выше про слияние синих и зеленых — ожидаемо.

rrrrex
23.01.2019 15:40Каким образом 9 отказов на 1205 дисков превратились в 3.03%?
Да и для обычного пользователя эта статистика ни о чем не говорит. Эти диски стоят в серверах и у них другие условия эксплуатации.DaylightIsBurning
23.01.2019 15:57+2ну так уж прям «ниочем». Отличия могут быть, но в отсутствии других данных, статистика Backblaze — это очень хорошее приближение для домашнего NAS, к примеру.
vesper-bot
23.01.2019 16:14+2Эти 9 отказов произошли за 108536 дней совокупной работы 1205 дисков (т.е. за три месяца, 90 дней работы каждого диска в среднем). Т.е. за 3 месяца вылетело 9 дисков, «36 годовых», и 36/1205 это вполне три процента.

Smolnyj
23.01.2019 16:12-1Не очень понял, как они в последней таблице для ST4000DM000 получили 2,77% отказов.
Не, ну понятно что это фэйлз * 100 / каунт, и поделили на три с пловиной года ещё… но блин… три процента afr, или девять процентов за три года — для ЭТОЙ модели цифра вообще нереальная.
Что-то тут не так с этой математикой.vesper-bot
23.01.2019 16:16Число дисков как таковое здесь не играет вообще никак, так как они рабочие диски спустя сколько-то лет тоже меняют. А методика расчета простая, fails/total drive years, или fails*365/total drive days.
Smolnyj
23.01.2019 16:37+1А, ну да. Там же время везде в рассчётах участвует изначально, а не так, как я посчитал. Посему достаточно вывести диски из эксплуатации вовремя, до начала массовых отказов — и получишь прекрасный AFR.
Вот как раз выше DaylightIsBurning выложил картинку про survival rate. Там если глянуть в табличку «still in use» то по этой модели через три года от 35 тысяч остаётся 11, а ещё через год — 4. Вот эти цифры уже как-то пореальней выглядят.
Видимо, обнаружив всплеск afr их просто стали вовремя выводить из эксплуатации, «по симптомам и подозрениям», т.е. до того момента, когда фиксируется именно отказ накопителя. Вот оттого и получили такую щадящую статистику.
AVI-crak
24.01.2019 00:47-12Статистика вещь хорошая, но применяться должна в тех-же размерностях что и собиралась.
Например для покупателя одного диска — шанс его поломки в первый год эксплуатации будет равен 50%. Может сломаться, а может и нет.
А вот если купить и эксплуатировать сразу тысячу дисков — тогда статистика с большой долей вероятности совпадёт.Zettabyte
24.01.2019 02:39+8для покупателя одного диска — шанс его поломки в первый год эксплуатации будет равен 50%. Может сломаться, а может и нет
Напишите, пожалуйста, на Хабр пост-мини-лекцию по теории вероятностей.
А то заинтриговали тем, что будет с этим диском на второй год работы: он станет надёжнее (0.5 * 0.5 = 0.25 = 25%) или гарантированно умрёт (0.5 + 0.5 = 1 = 100%)?
А на третий? Ещё окрепнет (0.5 * 0.5 * 0.5 = 0.125 = 12.5%) или умерев, с вероятностью 50% прихватит с собой соседа (0.5 + 0.5 + 0.5 = 1.5 = 150%)?
Особенно интересно было бы оценить, что ждёт этот жёсткий диск в XXII веке — он станет самым надёжным устройством во вселенной (p = 7,8886090522101180541172856528279e-31 = 7,8886e-29%) или выйдя из строя, гарантированно аннигилирует Солнечную систему (p = 5000%)?AVI-crak
24.01.2019 04:02-5Напишите, пожалуйста, на Хабр пост-мини-лекцию по теории вероятностей.
Уже написал, чуть выше в первом моём сообщении. Это всё что нужно знать про теорию вероятностей и про статистику в чистом виде.
Вероятность поломки жёстких дисков будет совпадать в ситуации когда их количество, место и способ эксплуатации будет совпадать с условиями сбора первоначальной статистики. По этому не стоит рассматривать отчёты от Backblaze — как рекламный листок для покупки одного!, самого надёжного диска для своего компьютера.leftleg
24.01.2019 07:46+2По этому не стоит рассматривать отчёты от Backblaze — как рекламный листок для покупки одного!, самого надёжного диска для своего компьютера.
Конечно не стоит, скорее стоит рассматривать как рекламный листок для покупки ~14 тысяч дисков для своего дата-центра.
А если серьезно, то статистика на то и статистика, тем более техническая и она полезна для специалистов, чтобы получать хоть какую-нибудь оценку качества оборудования на реальной системе.
AVI-crak
24.01.2019 23:11Забавно наблюдать реакцию читателей хаба, у которых только-что отобрали надежду.
Но лучше так, чем вопли о потерянных данных с единственного винчестера.

Hardened
24.01.2019 05:38Интересно, как они решают вопрос с падающей производительностью. При замене 3ТБ дисков на 12ТБ количество шпинделей сокращается в 4 раза. IOPS и полоса для SATA дисков не особо растут с годами
cyberly
24.01.2019 08:30Они писали об этом где-то в своем блоге (https://www.backblaze.com/blog/) Насколько я помню, они этот вопрос никак не решают, потому что в их конкретном случае такой проблемы нет. Продают они, в основном, место для бэкапов, поэтому обмен данными у них относительно неактивный.
berez
24.01.2019 10:16При замене 3ТБ дисков на 12ТБ количество шпинделей сокращается в 4 раза.
У них storage pods вроде как на 45 дисков. Заменяются все диски сразу (ибо RAID). В результате объем хранимых данных растет, а количество шпинделей в поде — то же самое.blind_oracle
24.01.2019 12:45Я думаю имеется в виду не общее кол-во шпинделей, а кол-во шпинделей на условный ТБ места. И этот показатель как раз падает при примерно сравнимой скорости работы дисков в 4Тб и 12Тб…
CherryPah
24.01.2019 17:05Шпинделей то то же количество, но в результате на ту же корзину может записаться в 4 раза больше данных и юзать ее будет в 4 раза больше клиентов подняв интенсивность записи в те же самые 4 раза.
Но в случае бэкапов вопрос иопса конечно стоит не так остроHardened
24.01.2019 21:34Есть несколько моментов, которые могут поднять уровень IO нагрузки на диски:
1) механизм индексации файлов и изменений — пофаловый backup новых версий документов или на уровне измененных блоков
2) использование дедупликации для еще большей эффективности по capacity
Кроме всего прочего, есть еще такой момент, как восстановление. И если домашнему пользователю важно в первую очередь, что восстановиться в принципе возможно, до бизнес-клиент еще хочет и разумный срок получить, а не несколько дней / недель.
И не забываем про B2 Cloud Object Storage. Насколько я помню, там тот же аппаратный backend, что и под backup…
DrunkBear
24.01.2019 11:18Работаю с кластерами Hadoop, заметил забавную вещь: максимум отказов у нового, только из коробки, железа и у железа ближе к истечению гарантийного срока.
Между этими временными отрезками происходит минимум отказов.cyberly
24.01.2019 11:56Ну, это давно известная закономерность…
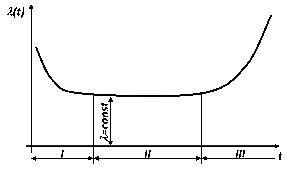
Типичная зависимость интенсивности отказов от времени: I — период приработки и отказов некачественных изделий; II — период нормальной эксплуатации; III — период старения (отказы вызваны износом деталей или старением материалов)
lingvo
24.01.2019 12:11Вот собственно для дна этой ванны и имеет значение AFR. Но для этого надо грамотно учитывать все данные — выкидывать из статистики детскую смертность и вследствие износа.
Alexufo
24.01.2019 14:21Но подождите, период старения как и нормальной работы может задаваться маркетологами. Это в плановой экономике может и работает.
cyberly
24.01.2019 14:36А зачем? Потребность в замене дисков и так обеспечена постоянно растущими объемами хранимых данных. Ну и специально портить показатели надежности у товара, у которого с ними и так не все гладко и для которого долгий срок службы — важное конкурентное преимущество, как-то странно. С таким маркетингом, кмк, можно очень быстро заработать дурную славу и вообще слиться с рынка, особенно в b2b, где считают окупаемость.
Dioxin
Впечатляет статистика невысоких отказов дисков больших объемов — научились делать однако.
Еще интересен факт малого количества дисков WD — боятся испарения гелия?
FeNUMe
По статистике видно же что ВДшки дохнут намного чаще и от них отказываются.
Loki3000
Как раз по статистике ничего не видно: 45 штук вестернов, против десятков тысяч каких-нибудь сегейтов — хреновая база для сбора статистики.
FeNUMe
45 штук вестернов ОСТАЛОСЬ, смотрите статистику за предыдущие годы, там были партии по несколько тысяч.
berez
Помнится, почитывал их бложик и там как раз были рассуждения о закупке дисков различных производителей. Так вот, там все диктуется не прикидками «надежный-ненадежный», а ценой и возможностью купить крупную партию. Кроме того, ненадежные диски — это обычно отдельные неудачные партии, а не все вообще диски одного производителя.
Конкретно про WD смутно вспоминается, что в среднем их цена была выше, чем у конкурентов аналогичного объема, а возможности купить крупную партию почему-то не было.
Можно было купить дешевые WD-шки во внешних корпусах, а потом сидеть и выламывать их, но они от этого отказались: во-первых, теряется гарантия, а во-вторых, инженеры должны заниматься более интересными делами, чем раскурочивание тысяч внешних дисков.
А надежность у них обеспечивается избыточностью и активным мониторингом дисковых массивов, так что плюс-минус пара процентов сдохших дисков для бизнеса некритична.
Dioxin
Их и куплено было мало, статистика слабая.
BaLaMuTt
Что странно. Похоже что инженеры-вредители делавшие раньше убогие диски для сигейта которые дохли пачками все ушли в WD и теперь гадят уже там. При этом надёжность дисков HGST вопросов не вызывает — видимо туда криворукие из сигейта ещё не добрались). В целом же для домашнего использования похоже как рулила тошиба так и рулит.
dartraiden
Дешевые тошибы дохнут ничуть не реже накопителей прочих производителей.
konchok
HGST это вроди бывшее дисковое подразделение IBM, у которых свои давние традиции вредительства(вспомним серию DTLA)
Fails
Ух, вспомнил, как 15 лет назад этот DTLA после того, как я отрендерил какую-то секвенсорную музыку в Wav, начал дико скрежетать. Данные пришлось тогда выуживать через загрузочный диск с DOS'ом, и не дай Бог случайно зайти в некоторые каталоги, из-за которых диск тоже начал скрежетать.
BaLaMuTt
Их собственно не просто так дятлами называли.
Vilgelm
Я понимаю что мой личный опыт не очень релевантен, но почему-то у меня практически все умершие диски это именно HGST и Hitachi (в основном 2.5). А еще они от рождения шумные как правило. При этом умер всего один Segate (но правда из старых, до 2009 года) и один WD. Toshiba еще не умирали (но первую Тошибу я купил года три назад).
Wernisag
Вот из домашнего, где-то до 2012 всегда пользовался Seagate. Потом как-то увидел у HGST диски с гарантией 5 лет, и из 3-х штук купленных примерно в одно время, все ещё работают.
Am0ralist
Ну вот в той конторе сейчас стопочка мертвых Seagate валяется разных времён. Хотя у самого 2 тб домашний, тьфу-тьфу, работает. Как и WD-ки, но для наса выбрал однозначно HGST по 6 тб.
megazloj
WD'шки все живые (из тех что у меня остались и не были проданы, например 200гб кажется 2004(5) года). Очень плохая личная статистика Seagate — посыпался 2тб и 500гб винты, в связи с чем больше никогда Seagate брать не буду. Еще увалился 500гб Hitachi.
duronus
Ну моя личная статистика, за 15 лет в течении 3-5 лет умерли ВСЕ seagate (серия 11-12 даже не вспоминаю, они просто как мухи дохли). По WD были и хорошие диски 2 из них досихпор работают и если умирали в первые 2 года то как правило с китайскими БП, но в целом можно считать отработали 5-6 лет и умерли все. Хитачи из около 30 штук умерло 3 шт причем все умерли в течении гарантии, остальные снимал тупо потому что ставил более новые. По тошиба если в ноуте умирали в течении 3-5 лет ВСЕ, если в NAS или кампудахторе то живут либо досих пор либо снял в рабочем состоянии и продал (тошибу начал брать недавно буквально последние 2-3 года назад)
P.s.: Кстати по сегату в одном серваке вообще чудо было, 15к на 600 гигов sas Seagete умирали по 1 раз в год, причем когда гарантия на сервак в целом кончилась те что поменяли (4 года назад к примеру) начали умирать по второму кругу, а вот те где вместо сегата присылали тошибу живут и не чихают. Замечу в одном серваке!!!
mspaint
«В целом же для домашнего использования похоже как рулила тошиба так и рулит.»
Для дома вообще рулит любой диск + бэкап важного на работе/облаке.
Я меняю диски после 3 лет эксплуатации, за 20 лет ни одного не померло. Не удивительно, ибо в 3% брака тяжело попасть. И разницы вообще нет, 0.2% брак у лучших или 3% у худших.
Я, кстати, WDшки всегда беру, которые якобы мусор.
qw1
mspaint
>Вероятность, что из 20 дисков с 3% брака откажет хотя бы один, равна 45%
Во первых, 45 это даже меньше 50% :) во вторых, если откажет до 3 лет, я его поменяю на новый по гарантии, это наоборот профит. Итого, для дома даже лучше падучие диски выбирать :)
DaylightIsBurning
А откуда цифра в «3% брака»? У Seagate есть модели с 50% доживаемостью до конца 3 года, по статистике Backblaze.
vesper-bot
Ну, ST10000NM0086 тоже гелиевый, а ставят, значит, не гелия боятся.
shteyner
Скорее всего отдел закупок ограничен какими-нибудь устоявшимися контрактами. Или же просто из WD скидку не смогли выбить. К примеру для хорошей скидки им нужно в год закупать по 10к дисков, а в год нужно 22к, вот и выбрали пару вендоров, которые предоставили лучшие условия.
yesyesyes
В оригинальной статье пишут, что HGST принадлежит WD. А именно с WD не договорились по хорошей цене.
greenxxl
Элементарно. Вагон винтов HGST сложнее купить, чем вагон винтов WD.