
Решил поделиться простым и ёмким на мой взгляд решением нейронной сети на С++.
Почему эта информация должна быть интересна?
Ответ: я старался в минимальном наборе запрограммировать работу многослойного перцептрона, да так, чтобы его можно было настраивать как душе угодно всего в нескольких строчках кода, а реализация основных алгоритмов работы на «С» позволит с лёгкостью переносить на «С» ориентированные языки(в прочем и на любые другие) без использования сторонних библиотек!
Прошу взглянуть на то, что из этого вышло
Про предназначение нейронных сетей я вам рассказывать не буду, надеюсь вас не забанили в google и вы сможете найти интересующую вас информацию(назначение, возможности, области применения и так далее).
Исходный код вы найдёте в конце статьи, а пока по порядку.
Начнём разбор
1) Архитектура и технические подробности
— многослойный перцептрон с возможностью конфигурации любого количества слоев с заданной шириной. Ниже представлен
inputNeurons = 100; //ширина входного слоя
outputNeurons =2; //ширина выходного слоя
nlCount = 4; //количество слоёв ( по факту их 3, указываемое число намеренно увеличено на 1
list = (nnLay*) malloc((nlCount)*sizeof(nnLay));
inputs = (float*) malloc((inputNeurons)*sizeof(float));
targets = (float*) malloc((outputNeurons)*sizeof(float));
list[0].setIO(100,20); //установка ширины INPUTS/OUTPUTS для каждого слоя
list[1].setIO(20,6); // -//-
list[2].setIO(6,3); // -//-
list[3].setIO(3,2); // -//- выходной слой
Обратите внимание, что установка ширины входа и выхода для каждого слоя выполняется по определённому правилу — вход текущего слоя = выходу предыдущего. Исключением является входной слой.
Таким образом, вы имеете возможность настраивать любую конфигурацию вручную или по заданному правилу перед компиляцией или после компиляции считывать данные из source файлов.
— реализация механизма обратного распространения ошибки с возможностью задания скорости обучения
myNeuero.h
#define learnRate 0.1 — установка начальных весов
myNeuero.h
#define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5)) Примечание: если слоёв больше трёх (nlCount > 4), то pow(out,-0.5) необходимо увеличивать, чтобы при прямом прохождении сигнала его энергия не сводилась к 0. Пример pow(out,-0.2)
— основа кода на С. Основные алгоритмы и хранение весовых коэффициентов реализовано в виде структуры на языке С, всё остальное является оболочкой вызывающей функции данной структуры, она же является отображением любого из слоёв взятом в отдельности
struct nnLay{
int in;
int out;
float** matrix;
float* hidden;
float* errors;
int getInCount(){return in;}
int getOutCount(){return out;}
float **getMatrix(){return matrix;}
void updMatrix(float *enteredVal)
{
for(int ou =0; ou < out; ou++)
{
for(int hid =0; hid < in; hid++)
{
matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]);
}
matrix[in][ou] += (learnRate * errors[ou]);
}
};
void setIO(int inputs, int outputs)
{
in=inputs;
out=outputs;
hidden = (float*) malloc((out)*sizeof(float));
matrix = (float**) malloc((in+1)*sizeof(float));
for(int inp =0; inp < in+1; inp++)
{
matrix[inp] = (float*) malloc(out*sizeof(float));
}
for(int inp =0; inp < in+1; inp++)
{
for(int outp =0; outp < out; outp++)
{
matrix[inp][outp] = randWeight;
}
}
}
void makeHidden(float *inputs)
{
for(int hid =0; hid < out; hid++)
{
float tmpS = 0.0;
for(int inp =0; inp < in; inp++)
{
tmpS += inputs[inp] * matrix[inp][hid];
}
tmpS += matrix[in][hid];
hidden[hid] = sigmoida(tmpS);
}
};
float* getHidden()
{
return hidden;
};
void calcOutError(float *targets)
{
errors = (float*) malloc((out)*sizeof(float));
for(int ou =0; ou < out; ou++)
{
errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]);
}
};
void calcHidError(float *targets,float **outWeights,int inS, int outS)
{
errors = (float*) malloc((inS)*sizeof(float));
for(int hid =0; hid < inS; hid++)
{
errors[hid] = 0.0;
for(int ou =0; ou < outS; ou++)
{
errors[hid] += targets[ou] * outWeights[hid][ou];
}
errors[hid] *= sigmoidasDerivate(hidden[hid]);
}
};
float* getErrors()
{
return errors;
};
float sigmoida(float val)
{
return (1.0 / (1.0 + exp(-val)));
}
float sigmoidasDerivate(float val)
{
return (val * (1.0 - val));
};
};
2) Применение
Тестирование проекта с набором mnist произошло удачно, удалось добиться условной вероятности распознавания рукописного текста 0,9795 (nlCount = 4, learnRate = 0.03 и несколько эпох). Основная цель теста была в проверке работоспособности нейронной сети, с чем она справилась.
Ниже мы рассмотрим работу на «условной задаче».
Исходные данные:
-2 случайных входных вектора размером в 100 значений
-нейросеть со случайной генерацией весов
-2 заданные цели
Код в функции main()
{
//!!!________ ДЛЯ ВЫВОДА ВМЕСТО qDebug() можете использовать std::cout или std::cerr
myNeuro *bb = new myNeuro();
//----------------------------------INPUTS----GENERATOR-------------
/! создаём 2 случайнозаполненных входных вектора
qsrand((QTime::currentTime().second()));
float *abc = new float[100];
for(int i=0; i<100;i++)
{
abc[i] =(qrand()%98)*0.01+0.01;
}
float *cba = new float[100];
for(int i=0; i<100;i++)
{
cba[i] =(qrand()%98)*0.01+0.01;
}
//---------------------------------TARGETS----GENERATOR-------------
// создаем 2 цели обучения
float *tar1 = new float[2];
tar1[0] =0.01;
tar1[1] =0.99;
float *tar2 = new float[2];
tar2[0] =0.99;
tar2[1] =0.01;
//--------------------------------NN---------WORKING---------------
// первичный опрос сети
bb->query(abc);
qDebug()<<"_________________________________";
bb->query(cba);
// обучение
int i=0;
while(i<100000)
{
bb->train(abc,tar1);
bb->train(cba,tar2);
i++;
}
//просмотр результатов обучения (опрос сети второй раз)
qDebug()<<"___________________RESULT_____________";
bb->query(abc);
qDebug()<<"______";
bb->query(cba);
}Результат работы нейронной сети
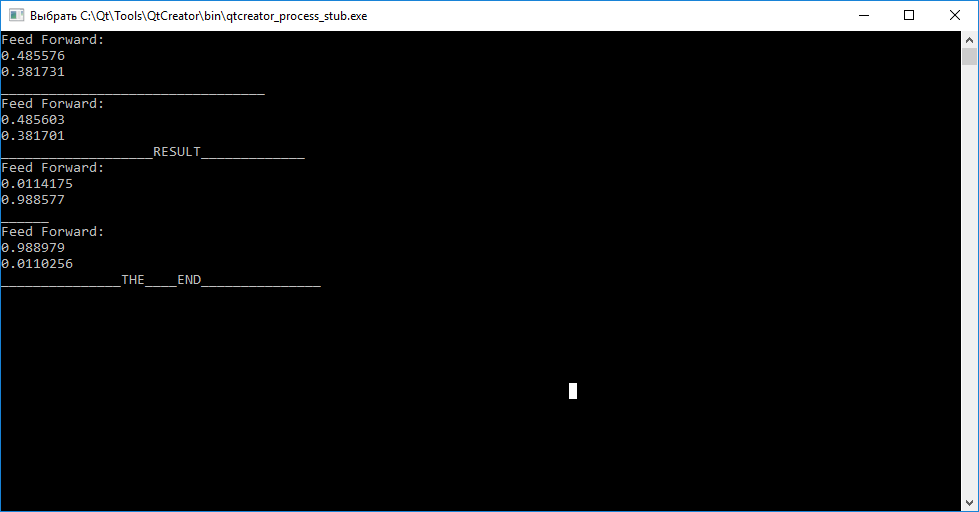
Итоги
Как вы видите, вызов функции query(inputs) до обучения для каждого из векторов не даёт нам судить об их отличиях. Далее, вызывая функцию train(input, target), для обучения с целью расстановки весовых коэффициентов так, чтобы нейросеть в последующем могла различать входные вектора.
После завершения обучения наблюдаем, что попытка сопоставить вектору «abc» — «tar1», а «cba» — «tar2» удалась.
Вам предоставляется возможность используя исходные коды самостоятельно протестировать работоспособность и поэкспериментировать с конфигурацией!
P.S.: данный код писался из QtCreator, надеюсь «заменить вывод» вам не составит труда, оставляйте свои замечания и комментарии.
P.P.S.: если кому интересен детальный разбор работы struct nnLay{} пишите, будет новый пост.
P.P.P.S.: надеюсь кому нибудь пригодится «С» ориентированный код для переноса на другие инструменты.
#include <QCoreApplication>
#include <QDebug>
#include <QTime>
#include "myneuro.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
myNeuro *bb = new myNeuro();
//----------------------------------INPUTS----GENERATOR-------------
qsrand((QTime::currentTime().second()));
float *abc = new float[100];
for(int i=0; i<100;i++)
{
abc[i] =(qrand()%98)*0.01+0.01;
}
float *cba = new float[100];
for(int i=0; i<100;i++)
{
cba[i] =(qrand()%98)*0.01+0.01;
}
//---------------------------------TARGETS----GENERATOR-------------
float *tar1 = new float[2];
tar1[0] =0.01;
tar1[1] =0.99;
float *tar2 = new float[2];
tar2[0] =0.99;
tar2[1] =0.01;
//--------------------------------NN---------WORKING---------------
bb->query(abc);
qDebug()<<"_________________________________";
bb->query(cba);
int i=0;
while(i<100000)
{
bb->train(abc,tar1);
bb->train(cba,tar2);
i++;
}
qDebug()<<"___________________RESULT_____________";
bb->query(abc);
qDebug()<<"______";
bb->query(cba);
qDebug()<<"_______________THE____END_______________";
return a.exec();
}
myNeuro.cpp
#include "myneuro.h"
#include <QDebug>
myNeuro::myNeuro()
{
//--------многослойный
inputNeurons = 100;
outputNeurons =2;
nlCount = 4;
list = (nnLay*) malloc((nlCount)*sizeof(nnLay));
inputs = (float*) malloc((inputNeurons)*sizeof(float));
targets = (float*) malloc((outputNeurons)*sizeof(float));
list[0].setIO(100,20);
list[1].setIO(20,6);
list[2].setIO(6,3);
list[3].setIO(3,2);
//--------однослойный---------
// inputNeurons = 100;
// outputNeurons =2;
// nlCount = 2;
// list = (nnLay*) malloc((nlCount)*sizeof(nnLay));
// inputs = (float*) malloc((inputNeurons)*sizeof(float));
// targets = (float*) malloc((outputNeurons)*sizeof(float));
// list[0].setIO(100,10);
// list[1].setIO(10,2);
}
void myNeuro::feedForwarding(bool ok)
{
list[0].makeHidden(inputs);
for (int i =1; i<nlCount; i++)
list[i].makeHidden(list[i-1].getHidden());
if (!ok)
{
qDebug()<<"Feed Forward: ";
for(int out =0; out < outputNeurons; out++)
{
qDebug()<<list[nlCount-1].hidden[out];
}
return;
}
else
{
// printArray(list[3].getErrors(),list[3].getOutCount());
backPropagate();
}
}
void myNeuro::backPropagate()
{
//-------------------------------ERRORS-----CALC---------
list[nlCount-1].calcOutError(targets);
for (int i =nlCount-2; i>=0; i--)
list[i].calcHidError(list[i+1].getErrors(),list[i+1].getMatrix(),
list[i+1].getInCount(),list[i+1].getOutCount());
//-------------------------------UPD-----WEIGHT---------
for (int i =nlCount-1; i>0; i--)
list[i].updMatrix(list[i-1].getHidden());
list[0].updMatrix(inputs);
}
void myNeuro::train(float *in, float *targ)
{
inputs = in;
targets = targ;
feedForwarding(true);
}
void myNeuro::query(float *in)
{
inputs=in;
feedForwarding(false);
}
void myNeuro::printArray(float *arr, int s)
{
qDebug()<<"__";
for(int inp =0; inp < s; inp++)
{
qDebug()<<arr[inp];
}
}myNeuro.h
#ifndef MYNEURO_H
#define MYNEURO_H
#include <iostream>
#include <math.h>
#include <QtGlobal>
#include <QDebug>
#define learnRate 0.1
#define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5))
class myNeuro
{
public:
myNeuro();
struct nnLay{
int in;
int out;
float** matrix;
float* hidden;
float* errors;
int getInCount(){return in;}
int getOutCount(){return out;}
float **getMatrix(){return matrix;}
void updMatrix(float *enteredVal)
{
for(int ou =0; ou < out; ou++)
{
for(int hid =0; hid < in; hid++)
{
matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]);
}
matrix[in][ou] += (learnRate * errors[ou]);
}
};
void setIO(int inputs, int outputs)
{
in=inputs;
out=outputs;
hidden = (float*) malloc((out)*sizeof(float));
matrix = (float**) malloc((in+1)*sizeof(float));
for(int inp =0; inp < in+1; inp++)
{
matrix[inp] = (float*) malloc(out*sizeof(float));
}
for(int inp =0; inp < in+1; inp++)
{
for(int outp =0; outp < out; outp++)
{
matrix[inp][outp] = randWeight;
}
}
}
void makeHidden(float *inputs)
{
for(int hid =0; hid < out; hid++)
{
float tmpS = 0.0;
for(int inp =0; inp < in; inp++)
{
tmpS += inputs[inp] * matrix[inp][hid];
}
tmpS += matrix[in][hid];
hidden[hid] = sigmoida(tmpS);
}
};
float* getHidden()
{
return hidden;
};
void calcOutError(float *targets)
{
errors = (float*) malloc((out)*sizeof(float));
for(int ou =0; ou < out; ou++)
{
errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]);
}
};
void calcHidError(float *targets,float **outWeights,int inS, int outS)
{
errors = (float*) malloc((inS)*sizeof(float));
for(int hid =0; hid < inS; hid++)
{
errors[hid] = 0.0;
for(int ou =0; ou < outS; ou++)
{
errors[hid] += targets[ou] * outWeights[hid][ou];
}
errors[hid] *= sigmoidasDerivate(hidden[hid]);
}
};
float* getErrors()
{
return errors;
};
float sigmoida(float val)
{
return (1.0 / (1.0 + exp(-val)));
}
float sigmoidasDerivate(float val)
{
return (val * (1.0 - val));
};
};
void feedForwarding(bool ok);
void backPropagate();
void train(float *in, float *targ);
void query(float *in);
void printArray(float *arr,int s);
private:
struct nnLay *list;
int inputNeurons;
int outputNeurons;
int nlCount;
float *inputs;
float *targets;
};
#endif // MYNEURO_HUPD:
Исходники для проверке на mnist лежат по«github.com/mamkin-itshnik/simple-neuro-network»
Тут же имеется графическое описание работы. Если кратко то при опросе сети тестовыми данными, вам выводится значение каждого из выходных нейронов (10 нейронов соответствует цифрам от 0 до 9). Для принятия решения о изображенной цифре, необходимо знать индекс максимального нейрона. Цифра = индекс + 1 (не забываем откуда нумеруются значения в массивах))
2)MNIST
«www.kaggle.com/oddrationale/mnist-in-csv» (при необходимости использования меньшего dataset, просто ограничьте счётчик while при чтении CSV файла ПС: пример на гит имеется)
Комментарии (24)

Hardcoin
13.02.2019 14:25-1А зачем? Как упражнение, навыки с++ потренировать — понятно. Но вы не используете векторизацию, то есть практического смысла мало.
mamkin_ITshnik Автор
13.02.2019 15:46+1Зачем что? Что вы понимаете под практическим смыслом? распишите подробнее
Hardcoin
13.02.2019 16:05Зачем вы реализовали этот проект. Однако ответ я уже увидел выше — вам не понравились сторонние библиотеки и вы реализовали свою. Ваше право.
Практический смысл — это когда и где использовать. Реализацию сети без векторных операций лично я бы не рекомендовал использовать нигде и никогда, поэтому вопрос и возник, зачем было сделано именно так. Сейчас я вижу, что сформулирован он был не очень ясно.

Yermack
13.02.2019 17:31Помню, когда был молодым и впечатлительным (полгода назад), узнав про нейросети сразу же кинулся делать свой перцептрон и тоже на С++. Я тогда заморочился с перегрузкой всех матричных операций, а потом, чтоб избавиться от этого узкого места, выполнил всё в виде функций, ну и там ввод вывод в файлы, все-дела, но так и не решил проблему с памятью: там все веса между слоями класса Матрица, а чтоб создать массив этого класса состоящий из матриц разного размера пришлось изголяться с указателями, чтобы вызывать конструктор с параметрами. Тут если интересно. Все проблемы решились переходом на Java
mamkin_ITshnik Автор
14.02.2019 12:33Желающие поучаствовать в развитии проекта с возможным преломлением на практике — писать сюда mamkin.itshnik@gmail.com
Wilk
14.02.2019 13:29В Вашем C ++ не обнаружено.
mamkin_ITshnik Автор
14.02.2019 14:18Посмотрите внимательный. Да немного, но есть, да можно переписать в С, но зачем мне искажать заголовок? Напишите решение где ++ больше или в ассемблер закатайте. Сообщество только выйграет от разнообразия материала. Каждый сам решит что ему ближе. По нейросетям много развелись статей, не хватает наверно DeepLearning на Assembler
Wilk
14.02.2019 14:29Вы могли бы значительно упростить код, если бы вместо C-style массивов с malloc использовали std::vector. Уже это добавило бы плюсов в код, сделало бы его проще, понятнее и надёжнее. Выше в комментариях уже замечали, что в коде есть (была?) ошибка, связанная с неправильным вычислением размера участка памяти. Соответственно, все циклы, которые работают с массивами, могли бы быть преобразованы в range-based циклы, что избавило бы Вас от магических чисел в коде.
С двумерной матрицей немного сложнее, т.к. в стандартной библиотеке нет подобного типа. Поскольку код, в целом, учебный, можно было бы обойтись кошмаром типа вектора векторов. Это как минимум решило бы проблемы с управлением памятью. Если же хочется написать красивее, то можно использовать Eigen или подобную библиотеку для операций над матрицами и векторами. Можно, конечно, свой класс двумерной матрицы придумать, но это выходит за рамка задачи создания нейронной сети.mamkin_ITshnik Автор
14.02.2019 16:22Изначально vector<vector<....> был! Да удобней с памятью, но грамоздко показалось, вот и решил в С-образно сделать да и в struct загнать. Ну переоценил силы немного, бывает
Wilk
14.02.2019 16:51Если хочется краткости, то можно использовать using:
using MyMatrix = std::vector< std::vector < float > >
Пишется один раз, после чего использование становится намного проще. Единственное что, возвращать по значению из функции не всегда может быть разумно. Но у Вас всё же структура, вполне можно обойтись без get/set методов — они ничего не прячут, да и для примера реализации не нужны.mamkin_ITshnik Автор
14.02.2019 23:41ну точно… в struct по дефолту все в public. Забавная не состыковка myneuro.h,
private:в ++ для указателей на структуру нет необходимости указывать
struct nnLay *list;struct. Для полного юмора указатель на структуру в «С» виде размещен в привате класса на плюсах. А никто и не заметил.
gbg
У вас есть ряд проблем с качеством кода.
-Неуместное использование макросов вместо constexpr-значания и constexpr-функции.Коротко: макросы хуже из-за того, что компилятор втыкает их в текст чисто механически, в отличие от constexpr, где он будет знать тип выражения и сможет ругаться в случае мест, подозрительных на ошибку и потерю точности.
-malloc и new в одной куче. Так на С++ писать нельзя — обязательно перепутаете пары malloc/free new/delete и засадите в программу неопределенное поведение, которое будет сложно отладить.
-отчасти, прошлый пункт компенсируется тем, что у вас деструкторов и очистки ресурсов просто нет. Да, программа при выходе все сама почистит, однако где гарантия, что ваш код не скопипастят в другую программу? Раз материал с намеком на обучение, не учите сразу плохому, мне после ваших обучалок, условно, джунов на работу брать.
-Использование сырых указателей — в ту же кучу камней — облом писать очистку руками? Заставь компилятор все почистить, благо это просто — RAII + смартпоинтеры называется.
-Куча магических констант по коду. Уж лучше юзать макросы, чем так поступать.
-Хранение индекса массива в переменной типа int — да, болваны-преподаватели любят так писать (благо слово всего из трех букв выходит), и в книжках тоже так пишут. Но это закладывает в программу страшную проблему под названием «несовместима с 64 битными архитектурами при обработке больших массивов». Просто юзайте size_t.
NickSin
Мне кажется, что человек всю жизнь писал на С и решил пересесть на С++. Может быть поэтому столько «не стыковок»?
gbg
Больше похоже на бодрое студенчество на марше. Могу и ошибаться.
mamkin_ITshnik Автор
Спасибо за анализ, работа над ошибками будет. Согласен, чистоте кода было уделено недостаточно внимания, основная цель была заложить необходимую математику в код, чтобы другие начинающие разработчики не натыкались на использование сторонних библиотек ради пары функций. Повторюсь, весь функционал заложен в структуре на «С», которую я для примера обернул в ++ и qt.
gbg
Это один из самых неприятных вариантов развития событий — когда интеллектуально значимый код написан настолько грязно, что его невозможно поддерживать, адаптировать и так далее. В такой ситуации код легко может быть обесценен с формулировкой — «переписать нафиг».
raamid
Никнейм как бы намекает :)
А по делу — вопрос автору статьи: где вы брали данные и как подключали к программе? Хотелось бы самому такое пощупать, но, насколько я знаю база данных NNIST имеет размеры 28х28, которые в свою очередь были преобразованы из матрицы 20х20.
mamkin_ITshnik Автор
Добавил в конце статьи «UPD», применение для MNIST и ссылка на dataset. Откуда преобразовывали я не в курсе, главное знать что из 785 значений в строчке элемент «0» — маркер, далее 28х28 значений пикселей (1+28х28=785). В экспериментах не забывайте, чем больше сеть тем дольше ей обучаться, на глубоком обучении приходится вводить эпохи, менять скорость обучения (0,01-0,05 в данном случае) и корректировать значения начальных весов
raamid
Спасибо. Давно искал подобный материал, чтобы без библиотек, «голыми руками» пощупать нейросети. А то в соседней теме опять «хелловорды» на python затеяли.
Кстати, только сейчас заметил, что данные у вас генерируются, теперь разобрался.
raamid
На 64-разрядной системе программа вылетает с ошибкой «Segmentation fault». Нашел причину — проблема в выделении памяти. У вас в функции setIO в строке
matrix = (float**) malloc((in+1)*sizeof(float));
нужно указывать не sizeof(float), а sizeof(float*)
Возможно вы тестировали на 32 разрядной системе, там размер указателя совпадает с размером float и равен 4 байта.
На 64 разрядной системе размер указателя 8 байт, со всеми вытекающими последствиями — выделяется недостаточно памяти для массива указателей matrix.
mamkin_ITshnik Автор
Огромное спасибо, да действительно вы правы. На неделе подправлю, заодно в порядок приведу по советам gbg. В планах уйти от qt и перевести весь код на std. Ну а дальше будут фишки в отдельных ветках на git, типо свёртки и других приёмов. Главное сохранить максимальную простоту проекта
gbg
Я советую вам определиться с целью, которую вы перед собой ставите. Если стоит задача объяснить всю математику нейросетей на низком уровне, на уровне изложения того, как свертка выглядит с точки зрения операций с элементами матриц — это одно изложение, и там можно серьезно закопаться в оптимизацию алгоритма, в написание поддерживаемого математического кода (ваша первая попытка, увы вышла комом — ждем вторую! В качестве референса, можете почитать мои публикации — взыскательная публика не нашла в них серьезных проблем с качеством)
Если же речь идет о промышленной реализации нейросети, тогда не стоит делать велосипедной математики, а стоит взять Eigen, BLAS, ATLAS, Vienna CL и использовать их — они в любом случае окажутся быстрее и стабильнее.
mamkin_ITshnik Автор
Пока цель написание проекта с открытым и понятным исходным кодом, чтобы каждый мог хоть пошагово увидеть как сигнал проходит прямо, как обратно, как значения меняются, как функция активация влияет на результаты. Велосипед в разрезе. Версии 2.0 быть и скорее всего уже с разбором, на картинках с кусками кода отдельных функций
gbg
По математике к вам тоже есть замечание — в виду того, что вы обрезаете число, которое является степенью двойки при помощи остатка от деления (qrand()%98), вы получаете из равномерного распределения (насколько уместен этот термин в контексте ГПСЧ из стандартной библиотеки я не рассматриваю) уже не совсем равномерное.
Чтобы с этим не возиться, возьмите генераторы и преобразователи псевдослучайных величин из C++11