

За последний год публикаций о микросервисах стало так много, что рассказывать что это и зачем нужно было бы пустой тратой времени, так что дальнейшее изложение будет сконцентрировано на вопросе — каким способом бы реализовали эту архитектуру и почему именно так и с какими проблемами столкнулись.
У нас в небольшом банке были большие проблемы: 3 python монолита связанных чудовищным количеством синхронных RPC взаимодействий с большим объемом legacy. Что бы хотя бы отчасти решить все возникающие при этом проблемы было принято решение перейти на микросервисную архитектуру. Но прежде чем решиться на такой шаг нужно ответить на 3 основных вопроса:
- Как разбить монолит на микросервисы и какими критериями следует при этом руководствоваться.
- Каким образом микросервисы будут взаимодействовать?
- Как осуществлять мониторинг?
Собственно кратким ответам на эти вопросы и будет посвящена данная статья.
Как разбить монолит на микросервисы и какими критериями следует при этом руководствоваться.
Этот, казалось бы простой вопрос, определил в конечном итоге всю дальнейшую архитектуру.
Мы — банк, соответственно вся система крутиться вокруг операций с финансами и различными вспомогательными вещами. Перенести финансовые ACID транзакции на распределенную систему с сагами безусловно можно, но в общем случае крайне трудно. Таким образом мы выработали следующие правила:
- Соблюдать S из SOLID применительно к микросервисам
- Транзакция должна целиком осуществляться в микросервисе — никаких распределенных транзакций на уроне БД
- Для работы микросервису в нужна информация из его собственной базы данных или из запроса
- Стараться обеспечить чистоту (в смысле функциональных языков) для микросервисов
Естественно одновременно и полностью удовлетворить их оказалось невозможным, но даже частичная реализация сильно упрощает разработку.
Каким образом микросервисы будут взаимодействовать?
Вариантов множество, но в конечном итоге их всех можно абстрагировать простым "микросервисы обмениваются сообщениями", но если реализовать синхронный протокол (например RPC через REST) то большинство недостатков монолита сохранятся, а вот достоинств микросервисов почти не появится. Так что очевидным решением было взять любой брокер сообщений и начать работать. Выбирая между RabbitMQ и Кафкой остановились на последней и вот почему:
- Кафка проще и предоставляет единственную модель передачи сообщений — Publish–subscribe
- Можно сравнительно просто получить данные из кафки второй раз. Это чрезвычайно удобно для отладки или исправления багов при некорректной обработке а также для мониторинга и логирования.
- Понятный и простой способ масштабирования сервиса: добавили партиций в топик, запустили больше подписчиков — остальное сделает кафка.
Дополнительно хочу обратить внимание на очень качественное и детальное сравнение.
Очереди на кафке+асинхронность позволяют нам:
- Ненадолго выключать любой микросервис для обновлений без заметных последствий для остальных
- Надолго выключать любой сервис и не возиться с восстановлением данных. Например недавно падал микросервис фискализации. Починили через 2 часа, он забрал необработанные счета из кафки и всё обработал. Не нужно было как раньше по HTTP логам и по отдельной таблице в БД восстанавливать что там должно было произойти и вручную проводить.
- Запускать тестовые варианты сервисов на актуальных данных с прода и сравнивать результаты их обработки с версией сервиса на проде.
В качестве системы сериализации данных мы выбрали AVRO, почему — описано в отдельной статье.
Но вне зависимости от выбранного способа сериализации важно понимать как будет проходить обновление протокола. Хотя AVRO и поддерживает Schema Resolution мы этим не пользуемся и решаем чисто административно:
- Данные в топики пишутся и читаются только через AVRO, название топика соответствует названию схемы (а у Confluent другой подход — они в старшие байты сообщения пишут ID AVRO схемы из реестра, таким образом в одном топике у них могут быть сообщения разного типа
- Если нужно дополнить или изменить данные, то создается новая схема с новым топиком в кафке, после чего все продюсеры переключаются на новый топик, а за ними — подписчики
Сами же схемы AVRO мы храним в git-субмодулях и подключаем ко всем кафка-проектам. Централизованный реестр схем решили пока не внедрять.
P.S.: Коллеги сделали opensource вариант но только с JSON-schema вместо AVRO.
Некоторые тонкости
Каждый подписчик получает все сообщения из топика
Это специфика модели взаимодействия Publish–subscribe — будучи подписаны на топик подписчик получит их все. В результате если сервису нужны лишь некоторые из сообщений — ему придется их отфильтровать. Если же это станет проблемой то можно будет сделать отдельный сервис-роутер, который будет раскладывать сообщения по нескольким разным топикам, тем самым реализовывать часть функционала RabbitMQ, отсутствующего в кафке. Сейчас у нас один подписчик на питоне в один поток обрабатывает примерно 7-5 тыс сообщений в секунду, если же запускать с через PyPy то скорость вырастает до 11-15 тыс/сек.
Ограничение времени жизни указателя в топике
В настройках кафки есть параметр ограничивающие время, которые кафка "помнит" на каком месте читатель остановился — по умолчанию 2 дня. Хорошо бы поднять до недели, чтобы если проблема возникает в праздники и 2 дня не будет решена, то это не привело бы к потере позиции в топике.
Ограничение времени на подтверждение чтения
Если читатель кафки не подтверждает чтение за 30 сек (настраиваемый параметр) то брокер считает что что то пошло не так и при попытке подтвердить чтение возникает ошибка. Чтобы избежать этого мы при длительной обработке сообщения Отправляем подтверждения чтения без смещения указателя.
Граф связей получается трудным для восприятия
Если по-честному нарисовать все взаимосвязи в graphviz то возникает традиционный для микросервисов ёжик апокалипсиса с десятками связей в одном узле. Чтобы хоть как то сделать его (граф связей) читаемым мы договорились о следующей нотации: микросервисы — овалы, топики кафки — прямоугольники. Таким образом на одном графе удаётся отобразить и факт взаимодействия и его тип. Но, увы, становится не сильно лучше. Так что этот вопрос всё ещё открыт.
Как осуществлять мониторинг?
Ещё в рамках монолита у нас были логи в файлах и Sentry Но по мере перехода на взаимодействие через кафку и развертывания в k8s логи переместились в ElasticSearch и соответственно сначала мониторили читая логи подписчика в Эластике. Нет логов — нет работы.
За тем начали использовать Prometheus и kafka-exporter немного модифицировали его дашборд: https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
В результате получаем вот такие картинки:
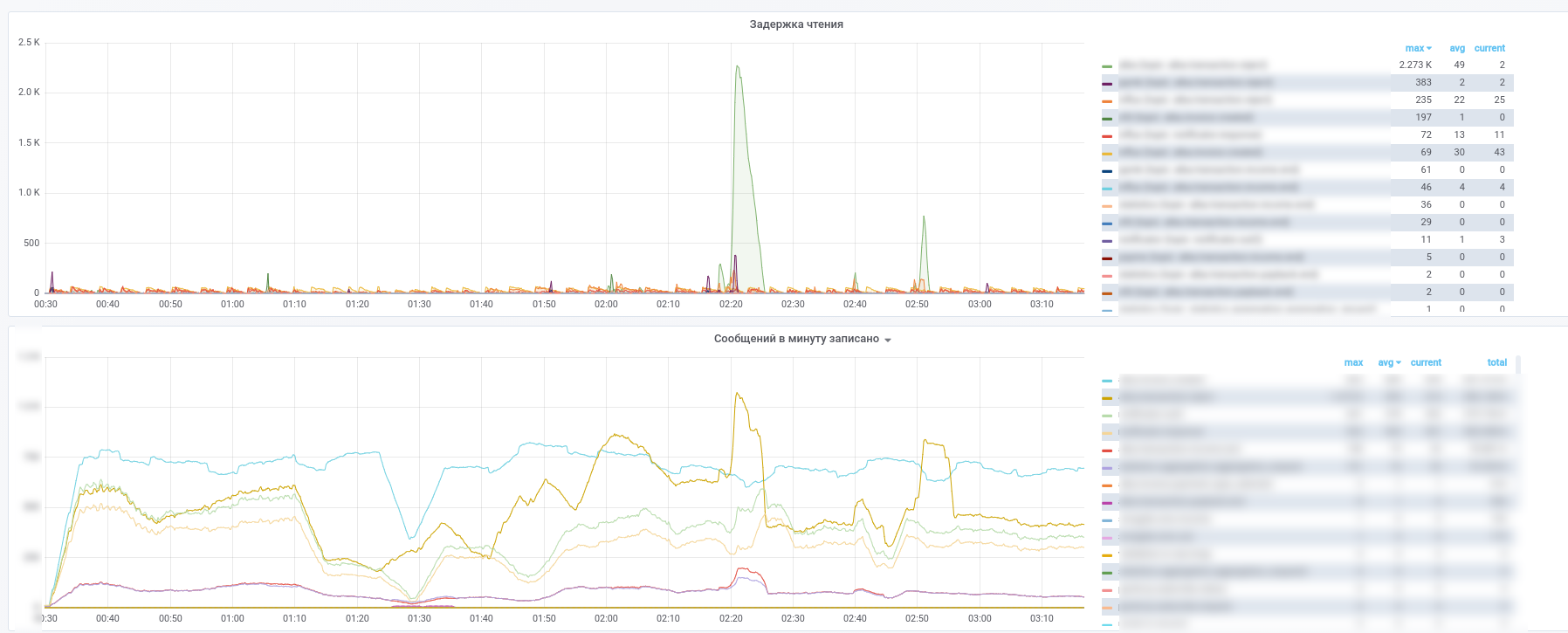
Срезу видно какой сервис какие сообщения перестал обрабатывать.
Дополнительно все сообщения из ключевых (платежные транзакции, нотификации от партнеров и т.п.) топиков копируются в InfluxDB, заведенную в ту же grafana. Так что мы можем не только фиксировать сам факт передачи сообщений, но делать разнообразные выборки по содержимому. Так что ответы на вопросы вида "каково среднее время задержки ответа от сервиса" или "Сильно ли отличается поток транзакций сегодня от вчерашнего по этому магазину" всегда под рукой.
Так же для упрощения разбора инцидентов мы используем следующий подход: каждый сервис при обработке сообщения дополняет его метаинформацией содержащей UUID выданный при появлении в системе и массив записей типа:
- название сервиса
- UUID процесса обработки в данном микросервисе
- timestamp начала процесса
- длительность процесса
- набор тегов
В результате по мере прохождения сообщения через вычислительный граф сообщение обогащается информацией о пройденном на графе пути. Получается аналог zipkin/opentracing для MQ, позволяющий получив сообщение легко восстановить его путь на графе. Особую ценность это приобретает в тех случаях, когда на графе возникают циклы. Помните пример с маленьким сервисом, доля в платежах которого составляет всего 0.0001% Анализируя мета-информацию в сообщении он может определить — являлся ли они инициатором платежа, не обращаясь при этом в БД для сверки.
Комментарии (24)

alatushkin
22.02.2019 22:42Ох… А вы точно "банк"? Где же все эти традиционные soa и esb? Выглядит так что вы переизбрали их, только менее надёжные (очередь вместо шины и нет распределенных транзакций)
Расскажите, как у вас решается ситуация, когда "простое масштабирование" приводит к тому, что порядок транзакций в базе может произвольно не соответствовать порядку в очереди. Особенно в ситуации, когда бизнесовые правила успешности следующих зависят от предыдущих.
Так же вызывает вопросы надёжность вашего решения вот в каком кейсе: вы прочли сообщение из очереди, выполнили бизнессстранзакцию, сделали коммит в базе, и тут ваш процесс упал или случился сетеовой сбой и кафке вы не смогли сообщить об успешной обработке. Как система отработает?

amarao
22.02.2019 23:20Последний вопрос называется «невозможность выполнить что-либо ровно 1 раз в распределённой системе». Либо at least once, либо at most once.
kkirsanov2 Автор
23.02.2019 01:29Ох… А вы точно «банк»?
Где же все эти традиционные soa и esb? Выглядит так что вы переизбрали их, только менее надёжные
Охи трудно комментировать.
A ESB нет из разных вариантов решения проблем выбрали тот, который описан.
(очередь вместо шины и нет распределенных транзакций)
Есть распределенные транзакции но не между сервисами, а внутри. А нет их между сервиссами т.к. сделать полноценные распределенные транзакции при такой архитектуре трудно.
Так же вызывает вопросы надёжность вашего решения вот в каком кейсе: вы прочли сообщение из очереди, выполнили бизнессстранзакцию, сделали коммит в базе, и тут ваш процесс упал или случился сетеовой сбой и кафке вы не смогли сообщить об успешной обработке. Как система отработает?
1) Каждое отправляемое сообщение снабжается UUID. При получении сообщения его UUID сравнивается с уже полученными и включается логика сервиса. Либо сообщение отбрасывается либо обновляется состояние в БД.
2) По возможности транзакция не закрывается, пока не получен ответ от кафки.alatushkin
23.02.2019 11:08Скажите, как называется банк в котором вы все это делаете?
kkirsanov2 Автор
23.02.2019 21:17Отвечу уклончиво — по питону в анамнезе и необходимости делать свою квази-ESB должно быть ясно что из первых с конца всевозможных рейтингов :)
amarao
Микросервисы никогда не были методом создать хорошую архитектуру. Они были (и являются) методом разделения компетенций. Люди с высокой компетенцией занимаются архитектурой и критическими сервисами, а второстепенные можно спихнуть на менее квалифицированных людей, обложив их фашистскими спецификациями и стандартами.
Главная разница между сервисной и микросервисной архитектурой в том, что микросервисное деление позволяет доводить этот процесс до «сервис на таску» или «сервис на человек».
Ценой же решения является вываливание ответственности (очень большой ответственности) за архитектуру на компетентных людей. Если кто-то не знает какая должна быть архитектура проекта, то сделав её микросервисной, человек получит куда более ужасную проблему, чем с кривой архитектурой в паре сервисов или монолитном приложении.
Перевод взаимодействя компонент с «внутри приложения» на сеть открывает новый класс ошибок — transient errors, вываливающиеся на operations. transient errors обладают таким свойством, что после того, как они случились, их нельзя отладить — они самопроходят. Просто что-то где-то флапает иногда. Достаточно, чтобы это раздражало и мешало, не достаточно, чтобы быть уверенным, что «оно не работает».
powerman
Хорошо сказано, но это не единственное основное свойство/задача микросервисов.
Не менее ценным свойством является защита от образования "большого комка грязи" в коде. В отсутствие компетентного архитектора аналогичный комок образуется в графе связей между микросервисами, но там от него вреда заметно меньше (по крайней мере он не парализует развитие проекта). Впрочем, при использовании ЯП с нужными для полноценной изоляции компонентов фичами и жёстком контроле их использования на ревью это свойство можно получить и без микросервисов — это будет не так надёжно и не так гибко (из-за требований к ЯП и качеству ревью), но зато намного дешевле.
amarao
Вот тут вот вы делаете ошибку. Если у вас образовался «комок грязи», то он в любом случае будет мешать разработке (потому что программист не будет знать где что брать и откуда что ожидать). Но если в монолитной архитектуре это головная боль только программистов, то в микросервисной — ещё и operation'а, который вынужден выяснять кому куда там надо, а кому не надо, и в какой момент неожиданно кто-то получает отлуп от контрека, исчерпание портов на исходящих соединениях или просто флапающий DNS.
Повторю, микросервисная архитектура позволяет удевешить производство продукта с хорошей архитектурой. Она ни на йоту не улучшает архитектуру для разработчиков и кратно ухудшает жизнь отдела эксплуатации.
powerman
Я согласен насчет дополнительных проблем для operation, но Вы не уловили суть проблемы: традиционный "большой комок грязи" не просто "будет мешать разработке", он разработку полностью парализует (экспоненциально увеличивая стоимость добавления новых фич до момента, когда переписать всё с нуля становится дешевле добавления следующей фичи). А в случае микросервисов "комок грязи" в связях между микросервисами добавит головной боли всем — и архитекторам, и разработчикам, и operation — но при этом скорость развития проекта упадёт (примерно) в два-три раза, а не экспоненциально, и это всё ещё намного лучше полного паралича.
amarao
А почему (при прочих равных) вынос комка грязи на уровень сети ускорит разработку?
Допустим, у меня компонента А хочет итерировать по потрошкам объекта из компоненты Б, и мы плохо понимаем все случаи, когда она это делает и что именно она там ищет.
Раньше у нас A шарился в коде в Б, теперь, когда у нас тренд на микросервисную архитектуру, мы пишем RPC в Б, которое позволяет сделать get_all и сериализует свои потрошки. A периодически делает get_all, и что оно с ним делает — не понятно. А ещё A иногда меняет Б, так что Б реализует запрос update, имеющий форму eval() (ибо никто не понимал что делать и сделали как смогли).
Дано: микросервисная архитектура с хорошо описанным интерфейсом: get_all и update.
Кому от этого легче стало?
powerman
Это происходит потому, что этот RPC с большей вероятностью не добавят, нежели добавят. А в монолите это сделают наверняка. Происходит так потому, что добавить новый вызов RPC — намного дороже. Требуется координация между командами разрабатывающими разные микросервисы, требуется доказать команде отвечающей за Б что новый RPC реально необходим, требуется подождать пока эта таска будет реализована командой Б (а у них свои таски и приоритеты), требуется обновить документацию на API, в процессе есть высокий шанс огрести от архитектора который заметит эту активность, требуется добавить на дашборды мониторинг и алерты для ошибок нового RPC, etc. Дорого. Очень. (Причём это мы говорим про добавление RPC, а нередко хочется изменить существующий, что ещё дороже если изменения не совместимы.) А в монолите это сделать, наоборот, крайне дешево.
В результате в микросервисной архитектуре разработчики более склонны искать способы решить проблему используя уже существующее API, а не срезать углы просверливая новые "дырочки" в других сервисах. И обычно этому способствует тот факт, что разработке существующего API архитектор уделил намного больше внимания, чем обычно уделяется внутренним интерфейсам внутри монолита — зная, что изменять API дорого его изначально проектируют более качественно.
amarao
координация между командами разрабатывающими разные микросервисы
Т.е. мы переходим к следующей важной особенности микросервисов: это для межкомандного взаимодействия. Если весь проект пилят 5 человек, каждый из которых чуть-чуть архитектор, то между какими командами взаимодействовать? А главное, кто будет реджектить кривые коммиты?
Вы расказываете про «работающую модель микросервисов» (при наличии толкового архитектора и модератора), а я вам рассказываю про то, во что микросервисы превращаются у команды, которая «устала от монолита и хочет хорошей архитектуры».
Получается как в анекдоте «сказал „отставить разврат“ и откопал стюардессу».
powerman
Нет, не переходим. Координация между командами — это не ключевой элемент, это просто одна из составляющих высокой цены (которая и является ключевым элементом) изменений API.
Если проект пилят 5 человек, то цена координации сильно уменьшается, но остаются все остальные составляющие цены. Если, к тому же, у проекта нет нормального архитектора, нет мониторинга, нет ревью, и практически отсутствует документация на API — вот тогда мы получим то, что Вы описываете: кошмар намного хуже монолита, причём если монолит был кошмаром только для разработчиков, то в случае микросервисов кошмар ощущают ещё и operation.
amarao
Вот, таким образом, без описываемых кусков, мы получаем кошмар, причём не в одном месте, а всюду.
А теперь последствия: в условиях, когда команда не справляется с архитектурой, притаскивание микросервисов делает хуже.
powerman
Полностью с этим согласен, и никогда не утверждал обратного. Я всегда говорил, что микросервисная архитектура требует намного более высокой компетенции от архитектора, что сложность никуда не исчезает, а переносится из кода на уровень связей между микросервисами, etc.
А в последнее время вообще стараюсь использовать "встроенные микросервисы", когда микросервисы проектируются так же тщательно, но при этом они остаются внутри монолита. Их реализация полноценно изолируется, другим частям монолита недоступно ничего помимо API (обычные вызовы функций, без сетевого I/O) этих встроенных микросервисов (в частности, у каждого из них своя БД), но они не выносятся в отдельные сетевые сервисы пока в этом не появляется реальная необходимость. Это значительно снижает стоимость их разработки на начальном этапе, упрощает развёртывание, сильно упрощает изменение их API при необходимости (но это не только плюс, но и минус, как я упоминал выше, так что — только под жёстким контролем архитектора). Получается монолит, который всё ещё требует такой же высокой компетенции архитектора как и микросервисы, проектирование которого требует столько же времени как и проектирование микросервисов (потому что это оно и есть), развёртывание которого немного сложнее обычного т.к. ему нужно передать много отдельных параметров для всех встроенных микросервисов (включая подключения к разным БД), но который, тем не менее, сохраняет многие плюсы микросервисов и обходится значительно дешевле полноценных микросервисов, несмотря на возможность довольно быстро на них развалиться.
andreyverbin
Если неуёмный и безжалостный креатив команды нужно останавливать и загонять его в загончик в виде сервиса и отгораживаться от него с помощью RPC или очередей, то у меня для вас плохая новость. Эту команду и проект ничего не спасёт и все быстро скатится к спагетти коду. С другой стороны, если креатив по делу, то совершенно не имеет значения микросервисы там или монолит. Сервисы сами появятся когда будут нужны.
powerman
Когда неуёмный креатив команды загоняют в загончик — не важно, в виде сервиса, слоя, интерфейса, компонента или класса — это называется архитектура. И вот когда её нет — тогда команду точно ничего не спасёт.
Что до спагетти — микросервисы, в частности, хороши тем, что большинство из них маленькие. Если в нем строк 500 полезного кода — там может быть спагетти и полное отсутствие внутренней архитектуры, и при этом всем будет плевать, потому что этот бардак не сказывается на остальной системе и не сильно усложняет сопровождение данного сервиса.
Но, в целом, в Ваших словах есть доля истины — микросервисы (по сравнению с монолитом) требуют большей компетенции от архитектора и меньшей от разработчиков, так что квалификация команды действительно может быть ниже обычной. Но на проекте это сказывается скорее положительно (можно нанять больше разработчиков и сильнее распараллелить разработку проекта, плюс разработчиков легче добавлять или заменять в середине проекта т.к. ниже порог входа для новых), даже не смотря на более низкое качество кода в среднем (это компенсируется простотой тестирования API их сервисов и значительно меньшей сложностью самих сервисов).
andreyverbin
Верно! А вот все остальное совершенно не верно. Навскидку
— Непонятно как замена MyModule.MethodA на HttpClient.Get(«mymodule/methoda») внезапно влияет на архитектуру?
— Непонятно, что мешает архитектору спроектировать интерфейсы между модулями также, как если бы он делал микросервисы и получить все преимущества микросервисной архитектуры без ее недостатков?
— Средний проект на 1 000 000 строк, микросервисов по 500 строк будет 2000. Почему бардак из 2000 модулей будет, а бардака из 2000 микросервисов не будет?
— Почему тестировать модуль «сложно», а тестировать микросервис просто?
— Почему микросервисы параллельно разрабатывать можно, а модули нельзя?
kkirsanov2 Автор
--и кратно ухудшает жизнь отдела эксплуатации.
Судя по моему опыту как раз становиться легче. Изрядная часть проблем вида «в большой системе что то сдохло — пускай программисты читают логи» превратились в «Сервис Б перестал обрабатывать задачи от А, пускай программисты читают логи сервиса Б». При этом задачи ждут в кафке и как починят — будут обработаны.
DMGarikk
а потом окажется что виноват сервис В из-за того что упал сервис Г от ошибки в сервисе Д… но это уже выяснят программисты… ну тоесть как обычно.
kkirsanov2 Автор
В конце концов всё всегда как обычно, слава Тьюрингу. Однако до наступления этого счастливого конца есть ещё ряд этапов, некоторые из которых стали заметно проще.
amarao
Сервис Б молча иногда жрёт задачи от А, А иногда молча не присылает задачи в… а куда он их слать должен? Документация? Ты сделал мой день, такой смешной шутки я давно не слышал.
… Нет, подожди, там же есть старая версия Б, которая вообще сама делала всё, а не требовала чего-то от A, так что мы сделали так, чтобы когда A выкатилось, мы просто чистили очередь задач от него, а новая должна начать их использовать.
(вы неявно предполагаете, что operation хорошо понимает архитектуру получившегося комка грязки. Он потому и комок, что его никто не понимает).
kkirsanov2 Автор
Жрёт в смысле принял, потерял, а сказал что обработал?
В топик кафки, за состоянием (скорость наполнения и статус обработки) мы получаем бесплатный мониторинг.
Интернета не было или просо отпуск?
Сам так не делаю и другим не советую.
Я явно знаю что понимание улучшилось. Естественно не по тому что какая то особая «микросервисная магия», а потому что одновременно с распилом монолита происходит рефакторниг.