

Предыстория
Началось все с простого желания посадить фруктовое дерево на своем участке. Сделать это, казалось бы, очень просто — приходишь в магазин и покупаешь саженец. Но в Америке первый вопрос, который задают продавцы, это сколько дерево получит солнечного света. Для Александра это оказалось гигантской загадкой — совершенно неизвестно, сколько солнечного света на участке.
Чтобы это узнать, школьник мог бы каждый день выходить во двор, смотреть, сколько солнечного света, и записывать это в блокнотик. Но это не дело — надо все оснастить оборудованием и автоматизировать.
В ходе выступления многие примеры запускались и воспроизводились в прямом эфире. Хотите более полную картину, чем в тексте, переключайтесь на просмотр видео.
Итак, чтобы не записывать наблюдения о погоде в блокнотик, есть большое количество устройств для интернет-вещей — Raspberry Pi, новый Raspberry Pi, Arduino — тысячи разных платформ. Но я выбрал для этого проекта устройство, которое называется Particle Photon. Оно очень просто в использовании, стоит 19 $ на официальном сайте.
В Particle Photon хорошо то, что это:
- 100% облачное решение;
- подходят любые датчики, например, для Arduino. Они все стоят меньше доллара.
Я сделал такой девайс и положил его в траву на участке. В нем есть Particle Device Cloud и консоль. Этот приборчик подключается через Wi-Fi hotspot и посылает данные: освещенность, температуру и влажность. Приборчик продержался 24 часа на маленькой батарейке, что достаточно неплохо.
Дальше мне нужно не только измерять освещенность и прочее и передавать их на телефон (что на самом деле хорошо — я могу в режиме реального времени видеть, какая у меня освещенность), но и хранить данные. Для этого, естественно, как ветеран MySQL, я выбрал MySQL.
Как мы записываем данные в MySQL
Я выбрал достаточно сложную схему:
- получаю данные из Particle-консоли;
- использую Node.js, чтобы записать их в MySQL.
Я использую Particle API JS, который можно скачать с сайта Particle. Устанавливаю соединение с MySQL и записываю, то есть просто делаю INSERT INTO values. Такой вот pipeline.
Таким образом, девайс лежит во дворе, подсоединяется по Wi-Fi к домашнему роутеру и с помощью протокола MQTT передает данные в Particle. Дальше та самая схема: на виртуальной машине работает программка на Node.js, которая получает данные от Particle и записывает их в MySQL.
Для начала я построил графики из сырых данных в R. На графиках видно, что температура и освещенность днем поднимаются, к ночи падают, а влажность повышается — это естественно. Но также на графике есть шум, это типично для приборов интернета вещей. Например, когда на устройство залез жучок и закрыл его, датчик может передать совершенно нерелевантные данные. Это будет важно при дальнейшем рассмотрении.
Сейчас поговорим про MySQL и JSON, что изменилось в работе с JSON с MySQL 5.7 в MySQL 8. Потом я покажу демо, для которого использую MySQL 8 (на момент доклада эта версия еще не была готова для продакшена, сейчас уже выпущен стабильный релиз).
Хранение данных в MySQL
Когда мы пытаемся хранить данные, полученные с датчиков, наша первая мысль — создать таблицу в MySQL:
CREATE TABLE 'sensor_wide' (
'id' int (11) NOT NULL AUTO_INCREMENT,
'light' int (11) DEFAULT NULL,
'temp' double DEFAULT NULL,
'humidity' double DEFAULT NULL,
PRIMARY KEY ('id')
) ENGINE=InnoDB
Здесь для каждого датчика и для каждого типа данных есть своя колонка: light, temperature, humidity.
Это достаточно логично, но есть проблема — это не гибко. Допустим, мы захотим добавить еще один датчик и измерять что-то еще. Например, некоторые люди измеряют остаток пива в кеге. Что делать в этом случае?
alter table sensor_wide
add water level double ...;
Как извратиться, чтобы в таблицу что-то добавить? Нужно сделать alter table, но если вы делали alter table в MySQL, то знаете, о чем я говорю, — это совершенно непросто. Alter table в MySQL 8 и в MariaDB реализовано намного проще, но исторически это большая проблема. Так что если нам нужно добавить колонку, например, с названием пива, то это будет не так-то просто.
Опять же датчики появляются, исчезают, что нам делать со старыми данными? Например, мы прекращаем получать информацию про освещенность. Или мы создаем новую колонку — как хранить то, чего там до этого не было? Стандартный подход — это null, но для анализа это будет не очень удобно.
Еще один вариант — это key/value store.
Хранение данных в MySQL: key/value
Это будет более гибко: в key/value будет название, например, temperature и соответственно данные.
CREATE TABLE 'cloud_data' (
'id' int (11) NOT NULL AUTO_INCREMENT,
'name' varchar(255) DEFAULT NULL,
'data' text DEFAULT NULL,
'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
PRIMARY KEY ('id')
) ENGINE=InnoDB
В этом случае появляется другая проблема — нет типов. Мы не знаем, что мы храним в поле 'data'. Нам придётся его объявить полем text. Когда я создаю свой девайс интернета вещей, я знаю, какой там датчик и соответственно тип, но если понадобится хранить в той же таблице еще чьи-то данные, то я не буду знать, какие данные собираются.
Можно хранить много таблиц, но создавать одну целую новую таблицу на каждый датчик — не очень-то хорошо.
Что можно сделать? — Использовать JSON.
Хранение данных в MySQL: JSON
Хорошая новость в том, что в MySQL 5.7 можно хранить JSON как поле.
CREATE TABLE 'cloud_data_json' (
'id' int (11) NOT NULL AUTO_INCREMENT,
'name' varchar(255) DEFAULT NULL,
'data' JSON,
'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
PRIMARY KEY ('id')
) ENGINE=InnoDB;
До того, как появился MySQL 5.7, люди тоже хранили JSON, но как поле text. Поле JSON в MySQL позволяет хранить сам JSON наиболее эффективно. Кроме того, на основе JSON можно создать виртуальные колонки и на их основе индексы.
Единственная небольшая проблема — при хранении таблица возрастет в размере. Но зато мы получаем намного большую гибкость.
Поле JSON лучше для хранения JSON, чем поле text, потому что:
- Предоставляет автоматическую валидация документа. То есть если мы попытаемся туда записать что-то не валидное, выпадет ошибка.
- Это оптимизированный формат хранения. JSON хранится в бинарном формате, что позволяет переходить от одного документа JSON к другому — то, что называется skip.
Чтобы хранить данные в JSON, мы можем просто использовать SQL: сделать INSERT, поместить туда 'data' и получить данные с девайса.
…
stream.on('event', function(data) {
var query = connection.query(
'INSERT INTO cloud_data_json (client_name, data)
VALUES (?, ?)',
['particle', JSON.stringify(data)]
)
…
(demo)
Демо
Для демонстрации (здесь её начало на видео) примера используется виртуальная машина, в которой есть SQL.

Ниже фрагмент программы.
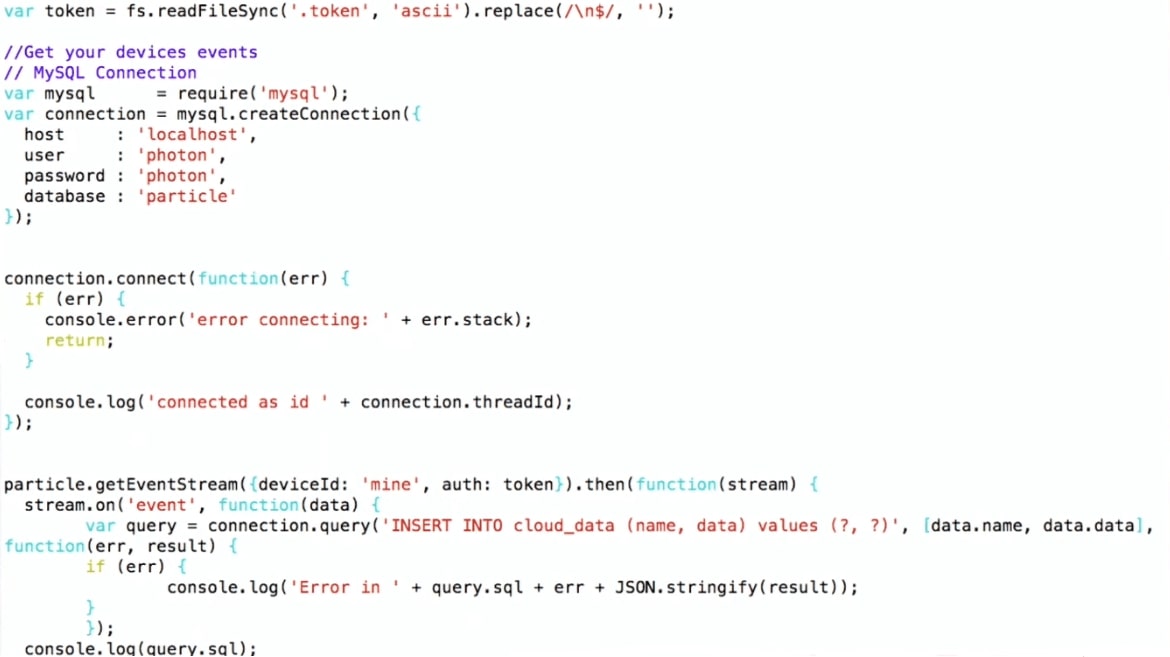
Я делаю
INSERT INTO cloud_data (name, data), получаю данные уже в формате JSON, и могу их прямо записать в MySQL, как есть, совершенно не думая о том, что там внутри.Как выяснилось, с помощью этого cloud можно получать доступ не только к данным моего устройства, но вообще ко всем данным, которые использует этот самый Particle. Кажется, это работает до сих пор. Люди, которые по всему миру используют Particle Photon, посылают какие-то данные: открыта дверь в гараже, или остаток пива такой-то, или что-то еще. Неизвестно, где эти девайсы находятся, но можно получить такие данные. Разница только в том, что, когда я получаю свои данные, я пишу что-то типа:
deviceId: 'mine'.При запуске кода мы получаем поток каких-то данных от чьих-то девайсов, которые что-то делают.
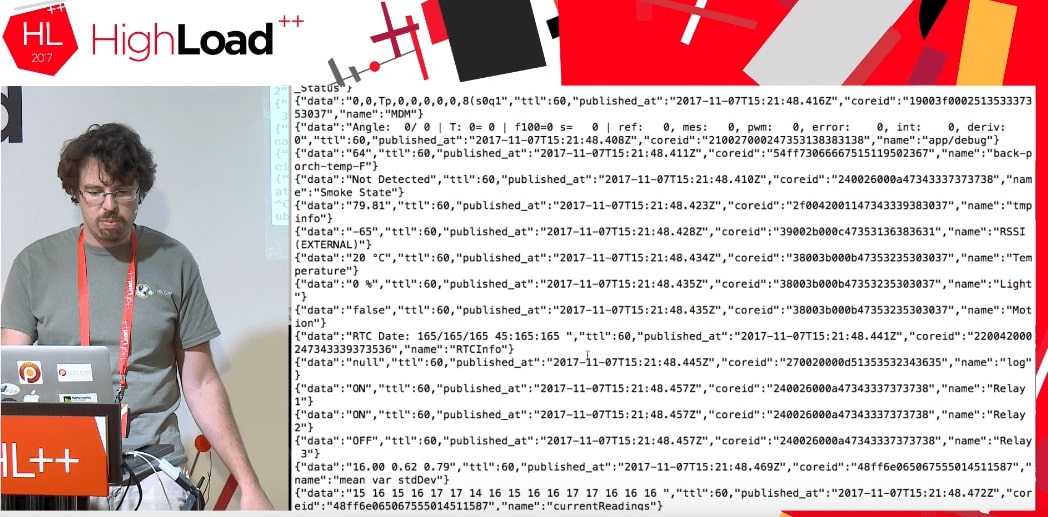
Мы совершенно не знаем, что это за данные: TTL, published_at, coreid, door status (дверь открыта), relay on.
Это прекрасный пример. Допустим, я попытаюсь положить это в MySQL в нормальную структуру данных. Я должен знать, что там за дверь, почему она открыта и какие вообще параметры может принимать. Если у меня есть JSON, то я записываю это прямо в MySQL в виде JSON-поля.
Пожалуйста, все записалось.
Document store
Document store — это попытка в MySQL сделать хранилище для JSON. Я очень люблю SQL, хорошо с ним знаком, могу сделать любой SQL-запрос и т.д. Но многие не любят SQL по разным причинам, и Document store может стать для них решением, потому с его помощью можно абстрагироваться от SQL, подключиться к MySQL и прямо туда записывать JSON.

Есть еще одна возможность, которая появилась в MySQL 5.7: использовать другой протокол, другой порт, также нужен и другой драйвер. Для Node.js (на самом деле для любых языков программирования — PHP, Java и пр.) мы подключаемся к MySQL по другому протоколу и можем передавать данные в формате JSON. Опять же я не знаю, что у меня в этом JSON — информация про двери или что-то еще, просто данные в MySQL сбрасываю, а что там, разберемся потом.
const mysqlx = require('@mysql/xdevapi*);
// MySQL Connection
var mySession = mysqlx.gctSession({
host: 'localhost', port: 33060, dbUser: 'photon*
});
…
session.getSchema("particle").getCollection("cloud_data_docstore")
.add( data )
.execute(function (row) {
}).catch(err => {
console.log(err);
})
.then( -Function (notices) {
console.log("Wrote to MySQL")
});
...https://dev.mysql.com/doc/dev/connector-nodejs/
Если хотите с этим поэкспериментировать, можно сконфигурировать MySQL 5.7 на то, чтобы он понимал и слушал на соответствующем порту Document store или X DevAPI. Я использовал connector-nodejs.
Это пример того, что я туда записываю: пиво и пр. Я совершенно не знаю, что там. Сейчас просто запишем, а проанализируем потом.

Следующий пункт нашей программы — как посмотреть, что там?
Хранение данных в MySQL: JSON + индексы
В JSON и MySQL 5.7 есть отличная функция, которая может вытащить поля из JSON. Это такой синтаксический сахар на функцию JSON_EXTRACT. Мне кажется, это очень удобно.
Data в нашем случае — название колонки, в которой хранится JSON, а name — это наше поле. Name, data, published_at — это все мы таким образом можем вытащить.
select data->>'$.name' as data_name,
data->>'$.data' as data,
data->>'$.published_at' as published
from cloud_data_json
order by data->'$.published_at' desc
limit 10;
В этом примере я хочу посмотреть, что у меня записалось в таблицу MySQL, и 10 последних записей. Я делаю такой запрос и пытаюсь его выполнить. К сожалению, это будет работать очень долго.
Логичным образом MySQL в данном случае не будет использовать никаких индексов. Мы вытаскиваем данные из JSON и пытаемся применить какие-то фильтры и сортировку. В этом случае у нас получится Using filesort.
EXPLAIN select data->>'$.name' as data_name ...
order by data->>'$.published_at' desc limit 10
select_type: SIMPLE
table: cloud_data_json
possible_keys: NULL
key: NULL
…
rows: 101589
filtered: 100.00
Extra: Using filesort
Using filesort — это очень плохо, это внешняя сортировка.
Хорошая новость в том, что можно сделать 2 шага, чтобы это ускорить.
Шаг 1. Создание виртуальной колонки
mysql> ALTER TABLE cloud_data_json
-> ADD published_at DATETIME(6)
-> GENERATED ALWAYS AS
(STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
Я делаю EXTRACT, то есть вытаскиваю данные из JSON и на его основе создаю виртуальную колонку. Виртуальная колонка в MySQL 5.7 и в MySQL 8 не хранится — это просто возможность создать отдельную колонку.
Вы спросите, как же так, ты же говорил, что ALTER TABLE — это такая долгая операция. Но здесь все не так плохо. Создание виртуальной колонки происходит быстро. Там есть loсk, но на самом деле в MySQL есть lock на всех DDL-операциях. ALTER TABLE — достаточно быстрая операция, и она не перестраивает всю таблицу.
Мы здесь создали виртуальную колонку. Мне пришлось сконвертировать дату, потому что в JSON она хранится в формате iso, а здесь MySQL использует совершенно другой формат. Для создания колонки я назвал ее, дал ей тип и сказал, что буду туда записывать.
Для оптимизации исходного запроса нужно вытащить published_at и name. Published_at уже есть, name проще — просто делаем виртуальную колонку.
mysql> ALTER TABLE cloud_data_json
-> ADD data_name VARCHAR(255)
-> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
Шаг 2. Создание индекса
В коде ниже я создаю индекс на published_at и выполняю запрос:
mysql> alter table cloud_data_json add key (published_at);
Query OK, 0 rows affected (0.31 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select data_name, published_at, data->>'$.data' as data from
cloud_data_json order by published_at desc limit 10\G
table: cloud_data_json
type: index
possible_keys: NULL
key: published_at
key_len: 9
rows: 10
filtered: 100.00
Extra: Backward index scan
Видно, что на самом деле MySQL использует индекс. Это оптимизация order by. В данном примере data и name не индексируются. MySQL использует order by data, и так как у нас есть индекс на published_at, то он его и использует.
Более того, я бы мог в order by вместо published_at использовать тот же самый синтаксический сахар
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ"). MySQL бы все равно понял, что есть индекс на эту колонку и начал бы его использовать.С этим на самом деле есть небольшая проблемка. Допустим, я хочу отсортировать данные не только по published_at, но еще и по названию.
mysql> explain select data_name, published_at, data->>'$.data' as data from
cloud_data_json order by published_at desc, data_name asc limit 10\G
select_type: SIMPLE
table: cloud_data_json
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 101589
filtered: 100.00
Extra: Using filesort
Если ваше устройство обрабатывает десятки тысяч событий в секунду, published_at не даст хорошей сортировки, так как будут дубликаты. Поэтому мы добавляем еще одну сортировку по data_name. Это типичный запрос не только для интернета вещей: дайте мне 10 последних событий, но отсортируйте их по дате, а потом, например, по фамилии человека по возрастанию. Для этого в примере выше есть два поля и указаны два ключа сортировки: descending и ascending.
Прежде всего в этом случае MySQL не будет использовать индексы. В данном конкретном случае MySQL решает, что полный скан таблицы будет выгоднее, чем использование индекса, и опять используется очень медленная операция filesort.
New in MySQL 8.0
descending/ascending
В MySQL 5.7 такой запрос оптимизировать нельзя, если только за счет других вещей. В MySQL 8 появилась реальная возможность указывать сортировку для каждого поля.
mysql> alter table cloud_data_json
add key published_at_data_name
(published_at desc, data_name asc);
Query OK, 0 rows affected (0.44 sec)
Records: 0 Duplicates: 0 Warnings: 0
Самое интересное, что ключ descending/ascending после названия индекса давно был в SQL. Даже в самой первой версии MySQL 3.23 можно было указать published_at descending или published_at ascending. MySQL это принимал, но ничего не делал, то есть сортировал всегда в одном направлении.
В MySQL 8 это поправили и теперь такая фича есть. Можно создать поле с сортировкой по убыванию и с сортировкой по умолчанию.
Вернемся на секунду назад и посмотрим на пример из шага 2 еще раз.
Почему это работает, а то — нет? Это работает потому, что в MySQL-индексы — это B-tree, а индексы B-tree можно читать и с начала, и с конца. В данном случае MySQL читает индекс с конца и все хорошо. Но если мы делаем descending и ascending, то прочитать нельзя. Можно прочитать в одном порядке, но совместить две сортировки нельзя — нужно пересортировать.
Так как мы оптимизируем совершенно конкретный случай, то можем для него создать индекс и указать конкретную сортировку: здесь published_at — descending, data_name — ascending. MySQL использует этот индекс, и все будет хорошо и быстро.
mysql> explain select data_name, published_at, data->>'$.data' as data from
cloud_data_json order by published_at desc limit 10\G
select_type: SIMPLE
table: cloud_data_json
partitions: NULL
type: index
possible_keys: NULL
key: published_at_data_name
key_len: 267
ref: NULL
rows: 10
filtered: 100.00
Extra: NULL
Это фича MySQL 8, который сейчас, на момент публикации уже доступен и готов для использования в продакшене.
Вывод результатов
Еще есть две интересные штуки, которые я хочу показать:
?1. Pretty print, то есть красивый вывод данных на экран. При обычном SELECT JSON будет не форматирован.
mysql> select json_pretty(data) from cloud_data_json
where data->>'$.data' like '%beer%' limit 1\G
…
json_pretty(data): {
"ttl": 60,
"data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44",
"name": "LOG_DATA_DEBUG",
"coreid": "3600....",
"published_at": "2017-09-28T18:21:16.517Z"
}
?2. Можно сказать, чтобы MySQL вывел результат в виде JSON array или JSON object, указать поля, и тогда вывод будет форматирован в виде JSON.
Полнотекстовый поиск внутри документов JSON
Если мы используем гибкую систему хранения и не знаем, что внутри нашего JSON, то было бы логично использовать полнотекстовый поиск.
К сожалению, полнотекстовый поиск имеет свои ограничения. Первое, что я попробовал — это просто создать полнотекстовый ключ. Я попытался сделать такую штуку:
mysql> alter table cloud_data_json_indexes add fulltext key (data);
ERROR 3152 (42000): JSON column ’data’ supports indexing only via generated columns on a specified ISON path.
К сожалению, это не работает. Даже в MySQL 8 создать полнотекстовый индекс просто по полю JSON, к сожалению, невозможно. Я бы конечно хотел иметь такую функцию — возможность поиска хотя бы по ключам JSON была бы очень полезна.
Но если это пока невозможно, давайте создадим виртуальную колонку. В нашем случае есть поле data, и нам интересно было бы посмотреть, что там внутри.
mysql> ALTER TABLE cloud_data_json_indexes
-> ADD data_data VARCHAR(255)
-> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data);
ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns.
К сожалению, это тоже не работает — на виртуальной колонке нельзя создать полнотекстовый индекс.
Раз так, давайте создадим хранимую колонку. MySQL 5.7 позволяет объявить колонку хранимым полем.
mysql> ALTER TABLE cloud_data_json_indexes
-> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4
-> GENERATED ALWAYS AS (data->>'$.name') STORED;
Query OK, 123518 rows affected (1.75 sec)
Records: 123518 Duplicates: 0 Warnings: 0
mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name);
Query OK, 0 rows affected, 1 warning (3.78 sec)
Records: 0 Duplicates: 0 Warnings: 1
mysql> show warnings;
+------------+--------+---------------------------------------------------+
| Level | Code | Message |
+------------+--------+---------------------------------------------------+
| Warning | 124 | InnoDB rebuilding table to add column FTS_DOC_ID |
+------------+--------+---------------------------------------------------+
В предыдущих примерах мы создавали виртуальные колонки, которые не хранятся, но индексы создаются и хранятся. В данном случае мне пришлось сказать MySQL, что это колонка STORED, то есть она будет создана и данные в нее будут скопированы. После этого MySQL создал полнотекстовый индекс, для этого пришлось пересоздать таблицу. Но это ограничение на самом деле InnoDB и InnoDB fulltext search: приходится пересоздавать таблицу, чтобы добавить специальный идентификатор полнотекстового поиска.
Интересно, что в MySQL 8 появилась новая кодировка UTF8MB4 для смайликов. Конечно, не совсем для них, а потому что в UTF8MB3 есть некоторые проблемы с русским, китайским, японским и другими языками.
mysql> ALTER TABLE cloud_data_json_indexes
-> ADD data_data TEXT CHARACTER SET UTF8MB4
-> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED
Query OK, 123518 rows affected (3.14 sec)
Records: 123518 Duplicates: 0 Warnings: 0
Соответственно MySQL 8 должен хранить данные JSON в UTF8MB4. Но то ли из-за того, что Node.js коннектится к Device Cloud, и там записано что-то не так, или это баг бета-версии, этого не произошло. Поэтому мне пришлось сконвертировать данные, перед тем как записать их в хранимую колонку.
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json,
ADD FULLTEXT KEY ft_json(data_name, data_data);
Query OK, 0 rows affected (1.85 sec)
Records: 0 Duplicates: 0 Warnings: 0
После этого я смог создать полнотекстовый поиск на двух полях: на названии JSON и на данных JSON.
Not only IoT
JSON — это не только интернет вещей. Он может использоваться для других интересных штук:
- Custom fields (CMS);
- Complex structures и т.д.;
Некоторые вещи могут быть намного удобнее реализованы с помощью гибкой схемы хранения данных. На Oracle OpenWorld приводился отличный пример: резервирование мест в кинотеатре. Реализовать это в реляционной модели очень сложно — получается много зависимых таблиц, джойнов и т.д. С другой стороны, мы можем хранить весь зал как структуру JSON, соответственно, записывать его в MySQL в другие таблицы и использовать обычным образом: создать индексы на основе JSON и т.д. Сложные структуры удобно хранить в формате JSON.

Это дерево, которое было успешно посажено. К сожалению, через несколько лет его съели олени, но это уже совсем другая история.
Этот доклад — отличный пример того, как из одной темы на большой конференции, вырастает целая секция, а потом и обособленное отдельное мероприятие. В случае интернета вещей у нас получилась InoThings++ — конференция для профессионалов рынка интернета вещей, которая 4 апреля пройдет уже во второй раз.
Центральным событием конференции, похоже, станет круглый стол «Нужны ли нам национальные стандарты в Интернете Вещей?», который органично дополнят всесторонние прикладные доклады. Приходите, если и ваши высоконагруженные системы верно двигаются к IIoT.
Комментарии (28)

Sergery8205
12.03.2019 14:38+1Прекрасный пример, особенно с индексами понравилось. Когда-то давно использовал именно бинарные поля для хранения древовидных структурированных данных. Действительно — не все удобно в реляционной модели хранить, хотя возможно. Интересно, есть ли поля типа JSON в Oracle?!

surly
12.03.2019 21:43Интересно, есть ли поля типа JSON в Oracle?!
Есть. В комплекте документации ему посвящена целая книга:
Oracle® Database: JSON Developer's Guide
eefadeev
12.03.2019 15:50Я прошу прощения, а сделать вариант не с одной таблицей (в которой пытаться хранить вообще всё на свете), а, скажем, с тремя (Типы датчиков, Измерения, Значения) — не позволила религия или отсутствие достаточной квалификации в проектировании БД? Или тогда бы статьи не получилось и было бы скучно и просто?
unhega
12.03.2019 16:49А можно подробнее ваш пример реализации? Сейчас столкнулся с тем, что вынужден хранить в одной таблице несколько видов измерений для удобства. У меня правда sqlite, потому просто текст, но сути не меняет — задача очень похожа на ту, что приводится в выступлении и ваше видение проблемы помогло бы взглянуть с другой стороны.
eefadeev
12.03.2019 17:19Для начала нужно разобраться что вы понимаете под «видами» измерений: показания из разных источников (датчиков в исходном примере) или показания разных типов (время, целое число, число с плавающей запятой, текст и т.п.).
Общая идея крайне проста — обобщать и разделять :) В случае условий в начале статьи (несколько датчиков опрашиваются одновременно с заданной периодичностью) у вас получается одна таблица, в которой у вас описаны ваши датчики (тип, название, время фактического существования, возможно ещё что-то), вторая таблица — измерения (собственно моменты времени, на которые вы получаете показатели) и третья, ссылающаяся на первые две, в которой будут лежать значения полученные с соответствующего датчика в указанный момент времени.
В первой таблице — по одной записи на каждый датчик.
Во второй таблице — по одной записи на каждый факт снятия показаний.
В третьей таблице — по несколько записей на каждый факт снятия показаний (в зависимости от того, с какого количества датчиков снимались данные).
Примерно так (дальше уже можно накручивать).

TimsTims
12.03.2019 17:07> В этом случае появляется другая проблема — нет типов. Мы не знаем, что мы храним в поле 'data'. Нам придётся его объявить полем text.
Стоп, но ведь json это тоже себе text. И он сам уже при распаковке будет решать, что это: целое, дробное, или текст. А раз так, то какая разница с первой реализацией что вы предложили? Ведь раз вы доверяете JSON'у хранить типы, то что мешает вам производить манипуляции с конвертацией данных при чтении? Например для поля 1, всегда конвертировать строку, например «231» в число 231. А для поля 2 все значения оставлять строкой, хоть там будет «222», или «огурец».
но если понадобится хранить в той же таблице еще чьи-то данные, то я не буду знать, какие данные собираются.
Не знаете, что собираете, но хотите это анализировать? Как вы будете это анализировать, если не знаете, что это за данные? А если узнали потом в будущем, то что мешает при анализе их конвертировать из текста, в другой нужный формат?
Мне кажется, вы сами себе проблему придумали, и сами её героически решили, добавив других проблем, вроде полнотекстового поиска, и излишнего хранения длинных ключей (которые тоже обязательно индексируются), превращая mysql из реляционной бд, в nosql бд.

savostin
12.03.2019 20:50То есть если мы попытаемся туда записать что-то не валидное, выпадет ошибка
Имеется в виду не валидный JSON?
При создании виртуальных колонок нужно обязательно знать структуру JSON. Опять же не понятно что будет в виртуальной колонке для тех записей, в которых этого поля нет в JSON. Да и вообще так и не увидел никаких преимуществ JSON перед колонками — имхо больше мороки с ними (та же дата, как в примере!), чем «раз в год» сделать alter table.
А синтаксис «data->>'$.data'» это вообще тихий ужас. Обязательно придумать свой, да?surly
12.03.2019 21:48А синтаксис «data->>'$.data'» это вообще тихий ужас. Обязательно придумать свой, да?
В PostgreSQL тот же самый синтаксис. Стандарт же. Называется «SQL/JSON Path Expression».

maxshopen
13.03.2019 06:29+1Сначала автор пишет, что добавление новых колонок это не гибко, потом начинает добавлять по тем же задачам виртуальные колонки, но это уже почему то гибко, хотя при этом оказывается под не-гибкостью он вроде как имел ввиду тормознутость alter table…
Статья производит впечатление высосанной из пальца с целью показать что mysql умеет json. Напихать в поле разнородных и заранее неизвестных структур в одно поле json а потом раскладывать их черт пойми как по stored колонкам, чтобы был полнотекст. Не производит впечатление разумного решения. Ну или я чего-то не понял, какой-то гениальной мелочи, всё объясняющей
zhulan0v
13.03.2019 08:09Вот тоже не понял, вроде хотели уйти от колонок, но потом всё равно их притащили. В чем профит?

igorp1024
13.03.2019 11:07Я так понимаю, под негибкостью подразумевалась необходимость привлекать тормозной (при добавлении новой колонки с данными, а не индекса) ALTER TABLE. Без этого код приложения получает свободу в выборе данных для хранения без модификации DDL. В идеальном случе, конечно же, ибо всё равно будет нужно что-то индексировать и т.п.
InChaos
13.03.2019 12:43База данных — хранит данные. Заранее известные и хранящиеся для дальнейшего активного использования и использования. И никакой JSON насколько бы он не был удобный, не пересилит своим удобством скорость при анализе 10 млрд. записей по сравнению с негибкой, но оттюненной базой. Тут вроде ж доклад с HighLoad конференции или с урока информатики для пятилеток? И Никогда база не должны быть гибкой чтоб хранить помойку. Для помойки пойдет и обычный текстовый файл.
igorp1024
13.03.2019 13:00Дисклеймер на всякий случай: не стОит причислять меня к сторонникам или противникам описанного в докладе подхода.
А что до самого вопроса, увы не сталкивался с IoT и не могу говорить с т.зрения опыта. Но если рассматривать проблему в общем случае — полностью согласен, что JSON не самый лучший выбор по производительности. Но весь доклад-то и не рассматривает best-practices по организации хранения данных, а строится вокруг одного главного критерия:
Это достаточно логично, но есть проблема — это не гибко. Допустим, мы захотим добавить еще один датчик и измерять что-то еще. Например, некоторые люди измеряют остаток пива в кеге. Что делать в этом случае?
Т.е., как в работающей системе с миллионами записей добавлять/убирать виды показаний без останова самой системы.
Насколько хорошим является это решение — судить не мне, я просто отметил причины, по поводу которых у maxshopen возникли вопросы. Может, идея, предложенная eefadeev, действительно намного лучше
maxshopen
13.03.2019 18:53DDL модифицируется в любом случае, реальные вы колонки добавляете или виртуальные. Разница только в том, что при создании virtual сами данные не перестраиваются, поэтому это быстро. Но гибкость это немного другой термин, нежели производительность. В реальности изменение структур происходит часто — на этапе разработки (когда данных еще нет или мало), и очень редко — далее, а то и вовсе никогда. С другой стороны в случае virtual колонок их значения будут вытаскиваться из json при каждом запросе, что явно нифига не производительно. Если же их делать stored/persistent — то получилось шило на мыло (в плане якобы «гибкости»).

AndrewShmig
13.03.2019 10:09Коллеги, а может подскажете, как хранить кастомные формы пользовательские — JSON или какие-то структуры с набором таблиц?
Пример: есть проект, у проекта пользователь может создавать произвольную форму из произвольных полей (текст, значение, интервал и т.п.) аля бриф.
Как сию структуру лучше хранить для последующей работы и выборки / формировании статистических данных и группировок?eefadeev
13.03.2019 13:17Для начала хорошо бы ответить на вопрос «А зачем вообще хранить ЭТО в БД?»
AndrewShmig
14.03.2019 00:04Поясните, чайнику, как лучше-то сделать? И как можно это НЕ хранить в БД, если проект многопользовательский и… файлы? Как-то странно их использовать. Какие-то ещё варианты? Смутно представляю себе, чем заменить MySQL в системе без костылей по работе с другим типом хранилища.
eefadeev
14.03.2019 09:26+1Смотрите: если вы храните формы в БД значит, вероятнее всего, при работе они формируются динамически. Любой вменяемый специалист по интерфейсам скажет вам что динамическая генерация UI — это путь в ад.
Но если очень хочется или по-другому никак не получается то, навскидку, есть два основных варианта (в условиях когда форма действительно может быть произвольной): вариация на тему EAV или JSON. В принципе (это к моему изначальному вопросу) вы с этими данными будете делать ровно две вещи: класть их в БД (целиком для одной формы) и читать их оттуда (ровно так же — целиком для одной формы). Поэтому на сегодняшний день я бы, пожалуй, смотрел в сторону JSON'а.
u_story
14.03.2019 22:07Есть ещё вариант добавить N столбцов заранее в таблицу и использовать их по мере потребности.
AndrewShmig
14.03.2019 22:47Конфигурации абсолютно произвольные могут быть, поэтому заранее добавить вряд ли имеет смысл. Я рассматривал изначально вариант создания нескольких таблиц: одна для хранения информации о самой форме, а вторая — поля + тип данных + FK на форму родительскую. Правда как потом статистику по этому делать и гибкие выборки с фильтрам — так глубоко и не заходил.
eefadeev
14.03.2019 23:05Из всего многообразия вариантов это, пожалуй, самый неудачный. Так делать не надо вообще никогда. Нужно объяснять почему?
rudinandrey
13.03.2019 16:02Как извратиться, чтобы в таблицу что-то добавить? Нужно сделать alter table, но если вы делали alter table в MySQL, то знаете, о чем я говорю, — это совершенно непросто. Alter table в MySQL 8 и в MariaDB реализовано намного проще, но исторически это большая проблема.
прошу прощения, а что с этим не так? По моему в MySQL это всегда было просто. Вот в MSSQL не просто да, но у MySQL с этим по моему никогда проблем не было.maxshopen
13.03.2019 17:50Предполагаю, что имеется ввиду то, что когда делается ALTER TABLE на больших таблицах — то в связи с пересозданием таблицы это занимает продолжительное время + lock
enabokov
14.03.2019 03:28А в чём тут high load? Рассказали про такой тип данных в MySQL, но не сравнили скорость работы по сравнению с типизированным колонками, с другими реализациями JSON-хранилищ. Половина статьи — как обойти функциональные ограничения типа JSON в MySQL. ALTER TABLE — «не хорошо», а вот полное пересоздание таблицы ради хранимых колонок, дублирующих данные — это можно. Извлёк для себя то, что для хранения динамической схемы MySQL по-прежнему не пригоден. Надо или сильно улучшать реализацию типа JSON, либо вообще делать отдельный движок хранения.
enabokov
14.03.2019 03:40По моему мнению для хранения исторических данных не нужны транзакционные СУБД. Нам не нужно потом править или удалять записи. Нам нужно делать отчёты, вертеть так и сяк, «майнить».
asmm
14.03.2019 14:07В MySQL 5.7 такой запрос оптимизировать нельзя, если только за счет других вещей. В MySQL 8 появилась реальная возможность указывать сортировку для каждого поля.
Самое интересное, что ключ descending/ascending после названия индекса давно был в SQL. Даже в самой первой версии MySQL 3.23 можно было указать published_at descending или published_at ascending. MySQL это принимал, но ничего не делал, то есть сортировал всегда в одном направлении.
Наверное можно сделать виртуальный «обратный» столбец и проиндексировать поля в asc. Т.е.
ALTER TABLE cloud_data_json ADD published_at_desc INT GENERATED ALWAYS AS (-1 * UNIX_TIMESTAMP(STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ"))) VIRTUAL ; alter table cloud_data_json add key published_at_data_name (published_at_desc, data_name) ; select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at_desc, data_name limit 10 ;
johndow
>в MySQL 8 появилась новая кодировка UTF8MB4 для смайликов.
эм. хм. MySQL 5.5 Reference Manual