
Наконец-таки появилось русскоязычное руководство по языку Julia. Там реализовано полноценное введение в язык для тех, у кого мало опыта в программировании (остальным будет полезно для общего развития), так же имеется введение в машинное обучение и куча заданий для закрепления материала.
Во время поисков наткнулся на курс программирования для экономистов (помимо Джулии там есть и Питон). Опытные могут пробежаться по экспресс курсу или ознакомиться с книгой How to Think Like a Computer Scientist
Далее предоставлен перевод материала из блога Christopher Rackauckas 7 Julia Gotchas and How to Handle Them
Позвольте мне начать с того, что Julia замечательный язык. Я люблю её, это то, что я считаю самым мощным и интуитивно понятным языком, который я когда-либо использовал. Это, несомненно, мой любимый язык. Тем не менее, есть некоторые 'подводные камни', хитрые мелочи, о которых вам нужно знать. У каждого языка есть они, и одна из первых вещей, которую вы должны сделать, чтобы овладеть языком, это выяснить, что они из себя представляют и как их избежать. Смысл этого поста состоит в том, чтобы помочь вам ускорить этот процесс, разоблачая некоторые из наиболее распространенных ошибок, предлагающих альтернативные методы программирования.
Julia — хороший язык для понимания происходящего, потому что в ней нет магии. Разработчики Julia хотели иметь четко определенные правила поведения. Это означает, что все поведение может быть объяснено. Однако это может означать, что вам придется напрягать голову, чтобы понять, почему происходит именно то, а не другое. Вот почему я не просто собираюсь изложить некоторые общие проблемы, но я также собираюсь объяснить, почему они возникают. Вы увидите, что есть некоторые очень похожие шаблоны, и как только вы их осознаете, вы больше не опростоволоситесь ни на одном из них. Из-за этого у Джулии немного более крутая кривая обучения по сравнению с более простыми языками, такими как MATLAB / R / Python. Однако, как только вы это освоите, вы в полной мере сможете использовать лаконичность Джулии при получении производительности C / Fortran. А теперь копнём глубже.
Нежданчик раз: REPL (терминал) имеет глобальную область видимости
Это, безусловно, самая распространенная проблема, о которой сообщают новые пользователи Julia. Кто-то скажет: "Я слышал, Джулия быстра!", откроет REPL, быстро запишет какой-то хорошо знакомый алгоритм и выполнит этот скрипт. После его выполнения смотрят на время и говорят: "Подождите секунду, почему это медленно, как на Питоне?" Поскольку это такая важная и распространенная проблема, давайте потратим немного времени на изучение причин, по которым это происходит, чтобы понять, как этого избежать.
Небольшое отступление: почему Джулия быстра
Вы должны понимать, что Джулия — это не только компиляция кода, но и специализация типов (то есть компиляция кода, который специфичен для данных типов). Позвольте мне повторить: Джулия не является быстрой, потому что код компилируется с использованием JIT-компилятора, скорее секрет скорости в том, что компилируется код специфичный для типа.
Если вам нужна полная история, ознакомьтесь с некоторыми заметками, которые я написал для предстоящего семинара. Типоспецифичность определяется основным принципом дизайна Юлии: множественной диспетчеризацией. Когда вы пишете код:
function f(a,b)
return 2a+b
endкажется что это только одна функция, но на самом деле здесь создается большое количество методов. На языке Юлии, функция — это абстракция, а то, что на самом деле вызывается, это метод. Если вы вызовете f(2.0,3.0), то Джулия запустит скомпилированный код, который принимает два числа с плавающей запятой и возвращает значение 2a + b. Если вы вызовете f(2,3), то Джулия запустит другой скомпилированный код, который принимает два целых числа и возвращает значение 2a + b. Функция f является абстракцией или сокращением для множества различных методов, имеющих одинаковую форму, и такая схема использования символа f для вызова всех этих различных методов называется множественной диспетчеризацией. И это применяется повсюду: оператор + на самом деле является функцией, которая будет вызывать методы в зависимости от типов, которые он видит. Julia на самом деле получает свою скорость, потому что скомпилированный ею код знает свои типы, и поэтому скомпилированный код, который вызывает f (2.0,3.0), является именно скомпилированным кодом, который вы получите, определив ту же функцию в C / Fortran. Вы можете проверить это с помощью макроса code_native, чтобы увидеть скомпилированную сборку:
@code_native f(2.0,3.0)pushq %rbp
movq %rsp, %rbp
Source line: 2
vaddsd %xmm0, %xmm0, %xmm0
vaddsd %xmm1, %xmm0, %xmm0
popq %rbp
retq
nopЭто та же самая скомпилированная сборка, которую вы ожидаете от функции в C / Fortran, и она отличается от кода сборки для целых чисел:
@code_native f(2,3)
pushq %rbp
movq %rsp, %rbp
Source line: 2
leaq (%rdx,%rcx,2), %rax
popq %rbp
retq
nopw (%rax,%rax)Суть: REPL / Global Scope не допускает специфику типов
Это подводит нас к основной мысли: REPL / Global Scope работает медленно, потому что не допускает спецификацию типа. Прежде всего, обратите внимание, что REPL является глобальной областью действия, потому что Джулия разрешает вложенную область видимости для функций. Например, если мы определим
function outer()
a = 5
function inner()
return 2a
end
b = inner()
return 3a+b
endто увидим, что этот код работает. Это потому, что Юлия позволяет вам захватить а из внешней функции во внутреннюю функцию. Если вы примените эту идею рекурсивно, то поймете, что самой высокой областью является область, которая является непосредственно REPL (которая является глобальной областью действия модуля Main). Но теперь давайте подумаем о том, как функция будет компилироваться в этой ситуации. Реализуем то же самое, но используя глобальные переменные:
a=2.0; b=3.0
function linearcombo()
return 2a+b
end
ans = linearcombo()и
a = 2; b = 3
ans2= linearcombo()Вопрос: Какие типы должен принимать компилятор для a и b? Обратите внимание, что в этом примере мы изменили типы и по-прежнему вызывали ту же функцию. Она может иметь дело с любыми типами, которые мы к ней добавляем: плавающими, целыми числами, массивами, странными пользовательскими типами и т. д. На языке Julia это означает, что переменные должны быть в штучной упаковке, и типы проверяются при каждом использовании. Как вы думаете, выглядит скомпилированный код?
pushq %rbp
movq %rsp, %rbp
pushq %r15
pushq %r14
pushq %r12
pushq %rsi
pushq %rdi
pushq %rbx
subq $96, %rsp
movl $2147565792, %edi # imm = 0x800140E0
movabsq $jl_get_ptls_states, %rax
callq *%rax
movq %rax, %rsi
leaq -72(%rbp), %r14
movq $0, -88(%rbp)
vxorps %xmm0, %xmm0, %xmm0
vmovups %xmm0, -72(%rbp)
movq $0, -56(%rbp)
movq $10, -104(%rbp)
movq (%rsi), %rax
movq %rax, -96(%rbp)
leaq -104(%rbp), %rax
movq %rax, (%rsi)
Source line: 3
movq pcre2_default_compile_context_8(%rdi), %rax
movq %rax, -56(%rbp)
movl $2154391480, %eax # imm = 0x806967B8
vmovq %rax, %xmm0
vpslldq $8, %xmm0, %xmm0 # xmm0 = zero,zero,zero,zero,zero,zero,zero,zero,xmm0[0,1,2,3,4,5,6,7]
vmovdqu %xmm0, -80(%rbp)
movq %rdi, -64(%rbp)
movabsq $jl_apply_generic, %r15
movl $3, %edx
movq %r14, %rcx
callq *%r15
movq %rax, %rbx
movq %rbx, -88(%rbp)
movabsq $586874896, %r12 # imm = 0x22FB0010
movq (%r12), %rax
testq %rax, %rax
jne L198
leaq 98096(%rdi), %rcx
movabsq $jl_get_binding_or_error, %rax
movl $122868360, %edx # imm = 0x752D288
callq *%rax
movq %rax, (%r12)
L198:
movq 8(%rax), %rax
testq %rax, %rax
je L263
movq %rax, -80(%rbp)
addq $5498232, %rdi # imm = 0x53E578
movq %rdi, -72(%rbp)
movq %rbx, -64(%rbp)
movq %rax, -56(%rbp)
movl $3, %edx
movq %r14, %rcx
callq *%r15
movq -96(%rbp), %rcx
movq %rcx, (%rsi)
addq $96, %rsp
popq %rbx
popq %rdi
popq %rsi
popq %r12
popq %r14
popq %r15
popq %rbp
retq
L263:
movabsq $jl_undefined_var_error, %rax
movl $122868360, %ecx # imm = 0x752D288
callq *%rax
ud2
nopw (%rax,%rax)Для динамических языков без специализации типов этот раздутый код со всеми дополнительными инструкциями настолько хорош, насколько только можно, поэтому Джулия замедляется до их скорости. Чтобы понять, почему это так важно, обратите внимание, что каждый фрагмент кода, который вы пишете в Джулии, компилируется. Допустим, вы пишете цикл в вашем скрипте:
a = 1
for i = 1:100
a += a + f(a)
endКомпилятор должен будет скомпилировать этот цикл, но поскольку он не может гарантировать, что типы не изменяются, он консервативно намотает портянку на все типы, что приводит к медленному выполнению.
Как избежать проблемы
Есть несколько способов избежать этой проблемы. Самый простой способ — всегда оборачивать ваши скрипты в функции. Например, предыдущий код примет вид:
function geta(a)
# can also just define a=1 here
for i = 1:100
a += a + f(a)
end
return a
end
a = geta(1)Это даст вам тот же результат, но, поскольку компилятор может специализироваться на типе a, он предоставит скомпилированный код, который вы хотите. Еще одна вещь, которую вы можете сделать, это определить ваши переменные как константы.
const b = 5Делая это, вы сообщаете компилятору, что переменная не изменится, и, таким образом, он сможет специализировать весь код, который использует ее, на типе, которым она является в настоящее время. Есть небольшая причуда, что Джулия на самом деле позволяет вам изменять значение константы, но не типа. Таким образом, вы можете использовать const чтоб сообщить компилятору, что вы не будете изменять тип. Тем не менее, обратите внимание, что есть некоторые небольшие причуды:
const a = 5
f() = a
println(f()) # Prints 5
a = 6
println(f())
# Prints 5
# WARNING: redefining constant aэто не работает, как ожидалось, потому что компилятор, понимая, что он знает ответ на f () = a (так как a является константой), просто заменил вызов функции на ответ, давая другое поведение, чем если бы a не был постоянной.
Мораль: не пишите свои сценарии непосредственно в REPL, всегда заключайте их в функцию.
Нежданчик два: Нестабильность типов
Итак, я только что высказал мнение о том, насколько важна специализация кода для типов данных. Позвольте мне задать вопрос, что произойдет, когда ваши типы могут измениться? Если вы догадались: "Ну, вы и в этом случае не можете специализировать скомпилированный код", тогда вы правы. Такая проблема известна как нестабильность типа. Они могут отображаться по-разному, но одним из распространенных примеров является то, что вы инициализируете значение простым, но не обязательно тем типом, которым оно должно быть. Например, давайте посмотрим на:
function g()
x=1
for i = 1:10
x = x/2
end
return x
endОбратите внимание, что 1/2 — это число с плавающей точкой в ??Julia. Поэтому, если мы начали с x = 1, целое число изменится на число с плавающей запятой, и, таким образом, функция должна скомпилировать внутренний цикл, как если бы он мог быть любого типа. Если бы вместо этого у нас было:
function h()
x=1.0
for i = 1:10
x = x/2
end
return x
endтогда вся функция сможет оптимально компилироваться, зная, что x останется числом с плавающей запятой (эта возможность для компилятора определять типы называется выводом типа). Мы можем проверить скомпилированный код, чтобы увидеть разницу:
pushq %rbp
movq %rsp, %rbp
pushq %r15
pushq %r14
pushq %r13
pushq %r12
pushq %rsi
pushq %rdi
pushq %rbx
subq $136, %rsp
movl $2147565728, %ebx # imm = 0x800140A0
movabsq $jl_get_ptls_states, %rax
callq *%rax
movq %rax, -152(%rbp)
vxorps %xmm0, %xmm0, %xmm0
vmovups %xmm0, -80(%rbp)
movq $0, -64(%rbp)
vxorps %ymm0, %ymm0, %ymm0
vmovups %ymm0, -128(%rbp)
movq $0, -96(%rbp)
movq $18, -144(%rbp)
movq (%rax), %rcx
movq %rcx, -136(%rbp)
leaq -144(%rbp), %rcx
movq %rcx, (%rax)
movq $0, -88(%rbp)
Source line: 4
movq %rbx, -104(%rbp)
movl $10, %edi
leaq 477872(%rbx), %r13
leaq 10039728(%rbx), %r15
leaq 8958904(%rbx), %r14
leaq 64(%rbx), %r12
leaq 10126032(%rbx), %rax
movq %rax, -160(%rbp)
nopw (%rax,%rax)
L176:
movq %rbx, -128(%rbp)
movq -8(%rbx), %rax
andq $-16, %rax
movq %r15, %rcx
cmpq %r13, %rax
je L272
movq %rbx, -96(%rbp)
movq -160(%rbp), %rcx
cmpq $2147419568, %rax # imm = 0x7FFF05B0
je L272
movq %rbx, -72(%rbp)
movq %r14, -80(%rbp)
movq %r12, -64(%rbp)
movl $3, %edx
leaq -80(%rbp), %rcx
movabsq $jl_apply_generic, %rax
vzeroupper
callq *%rax
movq %rax, -88(%rbp)
jmp L317
nopw %cs:(%rax,%rax)
L272:
movq %rcx, -120(%rbp)
movq %rbx, -72(%rbp)
movq %r14, -80(%rbp)
movq %r12, -64(%rbp)
movl $3, %r8d
leaq -80(%rbp), %rdx
movabsq $jl_invoke, %rax
vzeroupper
callq *%rax
movq %rax, -112(%rbp)
L317:
movq (%rax), %rsi
movl $1488, %edx # imm = 0x5D0
movl $16, %r8d
movq -152(%rbp), %rcx
movabsq $jl_gc_pool_alloc, %rax
callq *%rax
movq %rax, %rbx
movq %r13, -8(%rbx)
movq %rsi, (%rbx)
movq %rbx, -104(%rbp)
Source line: 3
addq $-1, %rdi
jne L176
Source line: 6
movq -136(%rbp), %rax
movq -152(%rbp), %rcx
movq %rax, (%rcx)
movq %rbx, %rax
addq $136, %rsp
popq %rbx
popq %rdi
popq %rsi
popq %r12
popq %r13
popq %r14
popq %r15
popq %rbp
retq
nopпротив
pushq %rbp
movq %rsp, %rbp
movabsq $567811336, %rax # imm = 0x21D81D08
Source line: 6
vmovsd (%rax), %xmm0 # xmm0 = mem[0],zero
popq %rbp
retq
nopw %cs:(%rax,%rax)Такая разница в количестве вычислений, чтоб получить одно и то же значение!
Как найти и справиться с нестабильностью типов

В этот момент вы можете спросить: "Ну, почему бы просто не использовать C, чтобы не приходилось искать эти нестабильности?" Ответ таков:
- Их легко найти
- Они могут быть полезны
Вы можете справиться с нестабильностью с помощью функциональных барьеров
Джулия дает вам макрос
code_warntype, чтобы показать, где находятся нестабильности типов. Например, если мы используем это в функцииg, которую мы создали:
@code_warntype g()
Variables:
#self#::#g
x::ANY
#temp#@_3::Int64
i::Int64
#temp#@_5::Core.MethodInstance
#temp#@_6::Float64
Body:
begin
x::ANY = 1 # line 3:
SSAValue(2) = (Base.select_value)((Base.sle_int)(1,10)::Bool,10,(Base.box)(Int64,(Base.sub_int)(1,1)))::Int64
#temp#@_3::Int64 = 1
5:
unless (Base.box)(Base.Bool,(Base.not_int)((#temp#@_3::Int64 === (Base.box)(Int64,(Base.add_int)(SSAValue(2),1)))::Bool)) goto 30
SSAValue(3) = #temp#@_3::Int64
SSAValue(4) = (Base.box)(Int64,(Base.add_int)(#temp#@_3::Int64,1))
i::Int64 = SSAValue(3)
#temp#@_3::Int64 = SSAValue(4) # line 4:
unless (Core.isa)(x::UNION{FLOAT64,INT64},Float64)::ANY goto 15
#temp#@_5::Core.MethodInstance = MethodInstance for /(::Float64, ::Int64)
goto 24
15:
unless (Core.isa)(x::UNION{FLOAT64,INT64},Int64)::ANY goto 19
#temp#@_5::Core.MethodInstance = MethodInstance for /(::Int64, ::Int64)
goto 24
19:
goto 21
21:
#temp#@_6::Float64 = (x::UNION{FLOAT64,INT64} / 2)::Float64
goto 26
24:
#temp#@_6::Float64 = $(Expr(:invoke, :(#temp#@_5), :(Main./), :(x::Union{Float64,Int64}), 2))
26:
x::ANY = #temp#@_6::Float64
28:
goto 5
30: # line 6:
return x::UNION{FLOAT64,INT64}
end::UNION{FLOAT64,INT64}Обратите внимание, что в начале мы говорим, что тип x — Any. Он будет использовать любой тип, который не обозначен как strict type, то есть это абстрактный тип, который необходимо помещать в коробку / проверять на каждом шаге. Мы видим, что в конце мы возвращаем x как UNION {FLOAT64, INT64}, что является еще одним нестрогим типом. Это говорит нам о том, что тип х изменился, вызвав трудности. Если мы вместо этого посмотрим на code_warntype для h, мы получим все строгие типы:
@code_warntype h()
Variables:
#self#::#h
x::Float64
#temp#::Int64
i::Int64
Body:
begin
x::Float64 = 1.0 # line 3:
SSAValue(2) = (Base.select_value)((Base.sle_int)(1,10)::Bool,10,(Base.box)(Int64,(Base.sub_int)(1,1)))::Int64
#temp#::Int64 = 1
5:
unless (Base.box)(Base.Bool,(Base.not_int)((#temp#::Int64 === (Base.box)(Int64,(Base.add_int)(SSAValue(2),1)))::Bool)) goto 15
SSAValue(3) = #temp#::Int64
SSAValue(4) = (Base.box)(Int64,(Base.add_int)(#temp#::Int64,1))
i::Int64 = SSAValue(3)
#temp#::Int64 = SSAValue(4) # line 4:
x::Float64 = (Base.box)(Base.Float64,(Base.div_float)(x::Float64,(Base.box)(Float64,(Base.sitofp)(Float64,2))))
13:
goto 5
15: # line 6:
return x::Float64
end::Float64Это указывает на то, что функция стабильна по типу и будет компилироваться по существу в оптимальный C-код. Таким образом, нестабильность типов не трудно найти. Что сложнее, так это найти правильный дизайн. Зачем разрешать нестабильность типов? Это давний вопрос, который привел к тому, что динамически типизированные языки доминируют на игровом поле сценариев. Идея заключается в том, что во многих случаях вы хотите найти компромисс между производительностью и надежностью.
Например, вы можете прочитать таблицу с веб-страницы, в которой целые смешаны с числами с плавающей запятой. В Julia вы можете написать свою функцию так, чтобы, если бы все они были целыми числами, она хорошо скомпилировалась, а если бы все они были числами с плавающей запятой, она также хорошо скомпилировалась. А если они смешанные? Это все еще будет работать. Это гибкость / удобство, которое мы знаем и любим из такого языка, как Python / R. Но Джулия прямо скажет вам (через code_warntype), когда вы пожертвуете производительностью.
Как справиться с нестабильностями типов
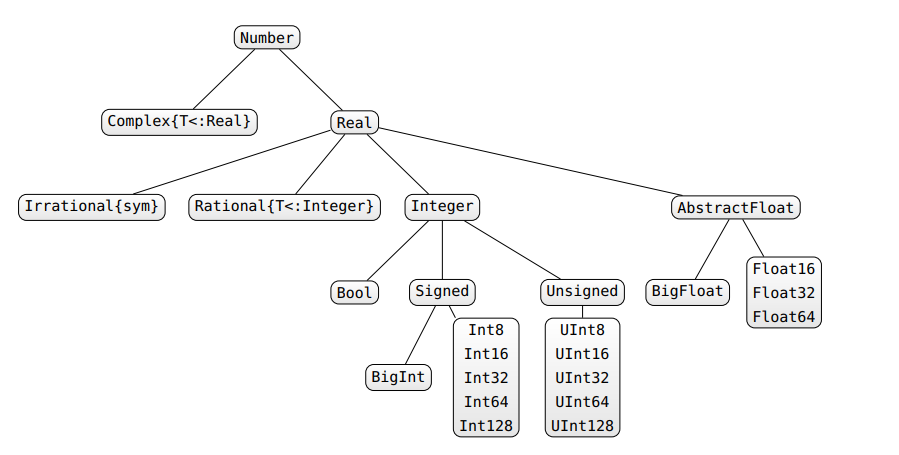
Есть несколько способов справиться с нестабильностями типов. Прежде всего, если вам нравится что-то вроде C / Fortran, где ваши типы объявлены и не могут измениться (что обеспечивает стабильность типов), вы можете сделать это в Julia:
local a::Int64 = 5Это делает a 64-разрядным целым числом, и если будущий код попытается изменить его, будет выдано сообщение об ошибке (или будет выполнено правильное преобразование. Но поскольку преобразование не будет автоматически округляться, оно, скорее всего, вызовет ошибки). Посыпьте их вокруг своего кода, и вы получите стабильность типов, аля, C / Fortran. Менее сложный способ справиться с этим — с помощью утверждений типа. Здесь вы помещаете тот же синтаксис на другую сторону знака равенства. Например:
a = (b/c)::Float64Оно как бы говорит: "вычислите b / c и убедитесь, что на выходе есть Float64. Если это не так, попробуйте выполнить автоматическое преобразование. Если преобразование не может быть легко выполнено, выведите ошибку". Размещение таких конструкций поможет вам убедиться, что вы знаете, какие типы участвуют. Однако в некоторых случаях нестабильность типов необходима. Например, допустим, вы хотите иметь надежный код, но пользователь дает вам что-то сумасшедшее, типа:
arr = Vector{Union{Int64,Float64}}(undef, 4)
arr[1]=4
arr[2]=2.0
arr[3]=3.2
arr[4]=1что представляет собой массив 4x1 целых чисел и чисел с плавающей запятой. Фактическим типом элемента для массива является Union {Int64, Float64}, который, как мы видели ранее, был нестрогим, что может привести к проблемам. Компилятор знает только, что каждое значение может быть целым числом или числом с плавающей запятой, но не какой элемент какого типа. Это означает, что наивно выполнять арифметику с этим массивом, например:
function foo{T,N}(array::Array{T,N})
for i in eachindex(array)
val = array[i]
# do algorithm X on val
end
endбудет медленным, так как операции будут в штучной упаковке. Однако мы можем использовать множественную диспетчеризацию для запуска кодов специализированным образом. Это известно как использование функциональных барьеров. Например:
function inner_foo{T<:Number}(val::T)
# Do algorithm X on val
end
function foo2{T,N}(array::Array{T,N})
for i in eachindex(array)
inner_foo(array[i])
end
endОбратите внимание, что из-за множественной диспетчеризации вызов inner_foo вызывает либо метод, специально скомпилированный для чисел с плавающей запятой, либо метод, специально скомпилированный для целых чисел. Таким образом, вы можете поместить длинное вычисление в inner_foo и при этом сделать его хорошо работающим, не уступая строгой типизации, которую дает вам функциональный барьер.
Таким образом, я надеюсь, что вы видите, что Юлия предлагает хорошее сочетание производительности строгой типизации и удобства динамической типизации. Хороший программист Julia получает в свое распоряжение и то, и другое, чтобы максимизировать производительность и / или производительность при необходимости.
Нежданчик 3: Eval работает на глобальном уровне

Одной из самых сильных сторон Юлии являются ее возможности метапрограммирования. Это позволяет вам легко писать программу, генерирующую код, эффективно сокращая объем кода, который вы должны писать и поддерживать. Макрос — это функция, которая запускается во время компиляции и (обычно) выплевывает код. Например:
macro defa()
:(a=5)
endзаменит любой экземпляр defa на код a = 5 (:(a = 5) — это quoted expression. Код Джулии — это выражения, и, следовательно, метапрограммирование — это сборка выражений).
Вы можете использовать это, чтобы построить любую сложную программу на Julia, которую пожелаете, и поместить ее в функцию как тип действительно умного сокращения. Однако иногда вам может потребоваться непосредственно оценить сгенерированный код. Юлия дает вам функцию eval или макрос @eval для этого. В общем, вы должны стараться избегать eval, но есть некоторые коды, где это необходимо, например, моя новая библиотека для передачи данных между различными процессами для параллельного программирования. Тем не менее, обратите внимание, что если вы используете его:
@eval :(a=5)тогда это будет оцениваться в глобальном масштабе (REPL). Однако исправление такое же, как и для глобальных нестабильностей / типов. Например:
function testeval()
@eval :(a=5)
return 2a+5
endне даст хорошего скомпилированного кода, так как a было по существу объявлено в REPL. Но мы можем, например, ввести локальную переменную и присвоить ей тип:
function testeval()
@eval :(a=5)
b = a::Int64
return 2b+5
endЗдесь b — это локальная переменная, и компилятор может сделать вывод, что ее тип не изменится, и, таким образом, мы имеем стабильность типов и живем в стране хорошей производительности. Так что работать с eval не сложно, вы просто должны помнить, что он работает в REPL.
Нежданчик 4: Как разбивать выражения
В Julia есть много случаев, когда ожидается синтаксическое завершение выражения. По этой причине операторы продолжения строки не нужны: Джулия будет просто читать, пока выражение не закончится.
Простое правило, верно? Просто убедитесь, что вы помните, как заканчиваются функции. Например:
a = 2 + 3 + 4 + 5 + 6 + 7
+8 + 9 + 10+ 11+ 12+ 13
aПохоже, что она будет оценивать до 90, но вместо этого дает 27. Почему? Поскольку a = 2 + 3 + 4 + 5 + 6 + 7 является полным выражением, поэтому оно будет иметь значение a = 27, а затем пропускается глупость +8 + 9 + 10+ 11+ 12+ 13, Чтобы продолжить строку, нам нужно было убедиться, что выражение не завершено:
a = 2 + 3 + 4 + 5 + 6 + 7 +
8 + 9 + 10+ 11+ 12+ 13Это даст 90, как мы хотели. Это может сбить вас с толку в первый раз, но потом привыкнете.
Эта неоднозначность специфична для всех языков с опциональной точкой с запятой в конце выражения. Универсальная рекомендация — писать знак в конце строки, если есть перенос выражения на следующую строку. rssdev10
Более сложная проблема связана с определениями массивов. Например:
x = rand(2,2)
a = [cos(2*pi.*x[:,1]).*cos(2*pi.*x[:,2])./(4*pi) -sin(2.*x[:,1]).*sin(2.*x[:,2])./(4)]
b = [cos(2*pi.*x[:,1]).*cos(2*pi.*x[:,2])./(4*pi) - sin(2.*x[:,1]).*sin(2.*x[:,2])./(4)]с первого взгляда можно подумать, что a и b — это одно и то же, но это не так! Первый даст вам (2,2) матрицу, а второй — (1-мерный) вектор размера 2. Чтобы увидеть, в чем проблема, вот более простая версия:
a = [1 -2]
b = [1 - 2]В первом случае есть два числа: 1 и -2. Во втором есть выражение: 1-2. Это из-за специального синтаксиса для определений массива. Обычно очень приятно писать:
a = [1 2 3 -4
2 -3 1 4]и получать матрицу 2x4. Тем не менее, за удобство приходится расплачиваться. Однако эту проблему также легко избежать: вместо конкатенации с использованием пробела используйте функцию hcat:
a = hcat(cos(2*pi.*x[:,1]).*cos(2*pi.*x[:,2])./(4*pi),-sin(2.*x[:,1]).*sin(2.*x[:,2])./(4))Задача решена!
Подводный камень №5: Представления, Копирование и Глубокая копия

Представление (View) — виртуальная (логическая) таблица, представляющая собой поименованный запрос (алиас к запросу), который будет подставлен как подзапрос при использовании представления.
В отличие от обычных таблиц реляционной БД, представление не является самостоятельной частью набора данных, хранящегося в базе. Содержимое представления динамически вычисляется на основании данных, находящихся в реальных таблицах. Изменение данных в реальной таблице БД немедленно отражается в содержимом всех представлений, построенных на основании этой таблицы.
Один из способов добиться хороших результатов работы Джулии — работа с "представлениями". "Массив" на самом деле является представлением о непрерывном пятне памяти, которое используется для хранения значений. "Значение" массива — это указатель на ячейку памяти (и информация о его типе). Это дает интересное (и полезное (иногда)) поведение. Например, если мы запустим следующий код:
a = [3;4;5]
b = a
b[1] = 1тогда в конце мы получим, что a — это массив [1; 4; 5], т. е. изменение b изменяет a. Причина в том, что b = a устанавливает значение b равным значению a. Поскольку значение массива является его указателем на ячейку памяти, то, что фактически получает b, не является новым массивом, скорее оно получает указатель на ту же ячейку памяти (именно поэтому изменение b меняет a). Это очень полезно, так как позволяет сохранять один и тот же массив в разных формах. Например, мы можем иметь матрицу и векторную форму матрицы, используя:
a = rand(2,2) # Makes a random 2x2 matrix
b = vec(a) # Makes a view to the 2x2 matrix which is a 1-dimensional arrayТеперь b является вектором, но изменение b все еще меняет a, где b индексируется путем считывания столбцов. Обратите внимание, что все это время массивы не копировались, и поэтому эти операции были слишком дешевыми (то есть, нет причин избегать их в чувствительном к производительности коде). Теперь немного подробностей. Обратите внимание, что синтаксис для нарезки массива создаст копию в правой части. Например:
c = a[1:2,1]создаст новый массив и присвоит ему идентификатор с (таким образом, изменение c не изменит a). Это может быть необходимым поведением, однако обратите внимание, что копирование массивов является дорогостоящей операцией, которую следует избегать, когда это возможно. Таким образом, вместо этого мы создали бы более сложные представления, используя:
d = @view a[1:2,1]
e = view(a,1:2,1)И d, и e — это одно и то же, и изменение d или e изменит a, потому что оба не будут копировать массив, а просто создавать новые переменные, которые указывают только на первый столбец а. (Другая функция, которая создает представления, — это reshape, которая позволяет изменять форму массива.) Если этот синтаксис находится слева, то это представление. Например:
a[1:2,1] = [1;2]изменит a, потому что в левой части a[1:2,1] совпадает с view (a, 1:2,1), что указывает на ту же память, что и a. Так как копировать-то? Ну, мы можем использовать функцию копирования:
b = copy(a)Теперь, поскольку b является копией a, а не представлением, изменение b не изменит a. Если мы уже определили a, есть удобная копия copy! (B, a) на месте, которая по существу будет проходить по циклу и записывать значения a в местоположения a (но для этого необходимо, чтобы b был уже определен и с правильным размером). Но теперь давайте сделаем немного более сложный массив. Например, Vector {Vector}:
a = [ [1, 2, 3], [4, 5], [6, 7, 8, 9] ]Каждый элемент а является вектором. Что происходит, когда мы копируем?
b = copy(a)
b[1][1] = 10
a3-element Array{Array{Int64,1},1}:
[10, 2, 3]
[4, 5]
[6, 7, 8, 9]Обратите внимание, что это также изменит a[1][1] на 10! Почему это случилось? Мы использовали copy для копирования значений a. Но значения a были массивами, поэтому мы скопировали указатели в ячейки памяти на b, поэтому b фактически указывает на те же массивы. Чтобы исправить это, используем deepcopy:
b = deepcopy(a)Это рекурсивно вызывает копирование таким образом, что мы избегаем этой проблемы. Опять же, правила Джулии очень просты и в них нет магии, но иногда вам нужно быть повнимательней.
Головная боль №6: Временные распределения, векторизация и функции In-Place
В MATLAB / Python / R вам советуют использовать векторизацию. В Julia вы, возможно, слышали, что "девекторизованный код лучше". Векторизованные коды дают временные выделения (т. е. они создают промежуточные массивы, которые не нужны, и, как отмечалось ранее, выделения массивов являются дорогостоящими и замедляют ваш код). По этой причине вы захотите объединить ваши векторизованные операции и записать их на месте (in-place), чтобы избежать распределения. Что я имею в виду на месте? Функция in-place (mutable function) — это функция, которая обновляет значение, а не возвращает значение. Если вы собираетесь постоянно работать с массивом, это позволит вам продолжать использовать один и тот же массив вместо создания новых массивов на каждой итерации. Например, если вы написали:
function f()
x = [1;5;6]
for i = 1:10
x = x + inner(x)
end
return x
end
function inner(x)
return 2x
endзатем каждый раз, когда вызывается inner, он будет создавать новый массив, который будет возвращать 2x. Очевидно, нам не нужно продолжать создавать новые массивы. Таким образом, вместо этого у нас может быть кэш-массив y, который будет содержать вывод примерно так:
function f()
x = [1;5;6]
y = Vector{Int64}(3)
for i = 1:10
inner(y,x)
for i in 1:3
x[i] = x[i] + y[i]
end
copy!(y,x)
end
return x
end
function inner!(y,x)
for i=1:3
y[i] = 2*x[i]
end
nothing
endКопнём глубже. inner!(y, x) ничего не возвращает, но меняет y. Поскольку y является массивом, значение y является указателем на фактический массив, и, поскольку в функции эти значения были изменены, inner! (y, x) будет молча изменять значения у. Функции, которые делают это, называются mutable (ну, допустим "мутаторы"). Они обычно обозначаются знаком ! И обычно меняют первый аргумент (это просто так условились).
Таким образом, при вызове inner!(y, x) массив не выделяется. Точно так же copy!(y, x) — это встроенная функция, которая записывает значения x в y, обновляя последний. Как видите, это означает, что каждая операция изменяет только значения массивов. Создаются только два массива: начальный массив для x и начальный массив для y. Первая функция создавала новый массив каждый раз, когда вызывался x + inner(x), и, таким образом, в первой функции было создано 11 массивов. Поскольку распределение массивов стоит дорого, вторая функция будет работать быстрее.
Хорошо, что мы можем работать быстро, но синтаксис немного раздулся, когда нам пришлось выписывать циклы. Вот тут-то и происходит слияние петель (loop-fusion). Начиная с Julia v0.5 вы можете использовать . символ для векторизации любой функции (также известной как широковещание (broadcast), потому что она на самом деле вызывает функцию широковещания). Хотя круто, что f.(x) — это то же самое, что применять f к каждому значению x, но круче то, что циклы сливаются. Если вы просто применили f к x и создали новый массив, то x = x + f. (x) будет иметь копию. Однако вместо этого мы можем обозначить все как векторизованные операции:
x .= x .+ f.(x).= Будет делать поэлементное равенство, так что это, по сути, станет кодом
for i = 1:length(x)
x[i] = x[i] + f(x[i])
endТаким образом, другой способ написать нашу функцию был бы:
function f()
x = [1;5;6]
for i = 1:10
x .= x .+ inner.(x)
end
return x
end
function inner(x)
return 2x
endПоэтому мы все еще получаем краткий векторизованный синтаксис MATLAB / R / Python, но эта версия не создает временных массивов и, следовательно, будет быстрее. Вот как вы можете использовать синтаксис языка сценариев, но при этом получать скорость, подобную C / Fortran.
Вывод: выучите правила, поймите их и катайтесь как сыр в масле
Еще раз повторим: у Юлии нет магии компилятора, только простые правила. Изучите правила хорошо, и все это будет второй натурой. Я надеюсь, что это поможет вам при знакомстве с Джулией. В первый раз, когда вы сталкиваетесь с ошибкой, сложно понять откуда счастья привалило. Но как только вы разберетесь, то уже будете готовы.
Как только вы по-настоящему поймете эти правила, ваш код будет скомпилирован до C / Fortran, в то время как он написан на кратком высокоуровневом языке сценариев. Соедините это с фьюжн-трансляцией и метапрограммированием, и вы получите безумную производительность для объема кода, который вы пишете!
Вот вам вопрос: какие выкидоны Джулии я пропустил? Оставьте комментарий, объясняющий нежданчик и как с этим справиться. Кроме того, ради интереса, какие ваши любимые ошибки из других языков? [Моим должен быть тот факт, что в Javascript внутри функции var x = 3 делает x локальным, а x = 3 делает x глобальным. Автоматические глобалы внутри функций? Это дало некоторые безумные ошибки, из-за которых я больше не хочу использовать Javascript!]
Комментарии (17)

kirtsar
12.03.2019 23:17+1Самое забавное, что если не оборачивать в функцию, то не будет работать с глобальными переменными:
# does not work u = 1 for i in 1 : 5 u += 1 end
Ещё один классный «прикол» :)
2^(-1) # works x = -1 2^x # DomainError
Ну и ещё один gotcha (не ошибка даже, а просто медленнее работает): это обход массивов по строкам (а не столбцам. как сделал бы любой уважающий себя FORTRANист :)
На discourse.julialang.org часто ещё вопросы интересные задают в стиле «у меня это работает медленно, какого ХРЕНА!!!111», и не всегда они тривиальные )
Yermack Автор
13.03.2019 09:05Первый пример понравился, просто никогда такого не замечал, так как работаю в Jupyter, а он работает на уровень ниже Глобальной области видимости.
Второй выдал
DomainError with -1: Cannot raise an integer x to a negative power -1. Make x a float by adding a zero decimal (e.g., 2.0^-1 instead of 2^-1), or write 1/x^1, float(x)^-1, or (x//1)^-1
То есть, скорей всего возведение в отрицательную степень инта вынудило бы создавать переменную флоат, которую бы возвращали, а так разработчики нас вынуждают возводить вещественное число, чтоб вычисления можно было проводить непосредственно на нем.
(вспоминаю gotcha на С/С++ когда всё занулялось из-за деления на инт)
Короче, нежданчики будут везде, и хорошо быть предупрежденным.
А что на счет Julia, то я нашел её очень удобной: можно быстро набросать абстрактные вычисления, всё проверить, а потом ускорить, а то и скачать готовый пакет. Да и сам процесс кодинга приятен, но в моем случае это скорее страстное хоббиkirtsar
13.03.2019 15:52+2У меня лично в REPL'e вот это:
2^(-1)
ошибки никакой не вызывает, а вот это:
x = -1 2^x
вызывает
DomainError. Причем я скорее сначала был удивлен не почему 2-е ругается, а как возможно, чтобы 1-е работало.
Поясню: каждая функция в Main-е вылизана насколько это возможно, а тут выходит явнаяtype instability: на вход подаётся 2Int, а на выходе может быть какInt(2^2), так иFloat(2^(-1)).
Чтобы обеспечить стабильность типов нужно либо явно каждый раз проверять, больше ли x чем 0 в выражении 2^x, а это долго, либо какая-то хитрость. Оказалось, что хитрость: просто2^(-1)не напрямую вызываетpowили что-то подобное, но сначала хитро парсится за счёт этого -. Т.е. фактически, если выражение имеет вид ...^(-...), то оно работает немного по-другому.
Поэтому если "спрятать"x = -1, то сразу "ломается", поскольку уже не имеет вид "a^(-..)"
В частности,
2^(1 - 2)
тоже кидает ошибку ;)

technic93
13.03.2019 08:53Как дела с проверками выхода за границы массивов?
Yermack Автор
13.03.2019 09:10При выходе за границы будет ругаться, побочный эффект — замедление работы с массивом, это если хотите безопасности. А потом с помощью специальной приписки-макроса эту проверку можно убрать, и вот у нас опять производительность С
rssdev10
13.03.2019 12:34У программистов на императивных языках программирования есть привычка использовать избыточные конструкции. Однако в Julia можно многие из них не использовать. Например индексы массива. Очень часто они вообще не нужны. Либо индексы могут быть вычислены автоматически (без необходимости вспоминать, с нуля они начинаются или с единицы). Например, традиционный вариант цикла:
let res = 0 x = [1:0.5:10...] # массив от 1 до 10 с шагом 0.5 for i = 1 : length(x) res = res + 1 / x[i] end println(res) # 5.195479314287365 end
Однако в коде видно, что индекс мы не используем по прямому назначению. Значит код может быть переписан как:
let res = 0 x = [1:0.5:10...] for item in x res = res + 1 / item end println(res) # 5.195479314287365 end
Более того, мы же видим, что и цикл, в общем-то с точки зрения того, что требуется получить, является избыточным. Нас интересует результат свёртки массива по операции. Значит можем выразить эти действия лакончиным:
x = [1:0.5:10...] res = mapreduce(item -> 1/item, +, x) println(res) # 5.195479314287365
Имя метода здесь —
mapreduce, значит аргументы им соответствют. Функцияitem -> 1/itemотносится кmap. Функция+— кreduce.
Для случая простой свёртки без
map, можем просто использоватьreduce.
Если же действительно нужен индекс, то можно заставить Julia взять его самостоятельно.
let res = 0 x = [1:0.5:10...] for i in eachindex(x) res = res + i / x[i] end println(res) # 32.80452068571264 end
Но в примере видим, что нас интересовал индекс и элемент, а не индекс для того, чтобы взять элемент. Значит можем заменить код:
let res = 0 x = [1:0.5:10...] for (i, item) in enumerate(x) res = res + i / item end println(res) # 32.80452068571264 end
Но и в этом случае нас не просили писать цикл, а просили вычилить результат по каждому индексу и элементу. Значит, можем заменить на:
x = [1:0.5:10...] res = mapreduce(((i, item),) -> i/item, +, enumerate(x)) println(res) # 32.80452068571264
В последнем примере конструкция
((i, item),)указывает, что надо разобрать первый аргумент изtuple.kirtsar
13.03.2019 15:46Можно вроде бы обойтись и без явного выделения массива, т.е.
x = 1 : 0.5 : 10
будет работать быстрее, чем явное выделение, ну и mapreduce дружит, да и вообще может быть использован везде, где может использоваться
x = [1 : 0.5 : 10 ...]rssdev10
13.03.2019 16:08julia> x = 1 : 0.5 : 10 1.0:0.5:10.0 julia> typeof(x) StepRangeLen{Float64,Base.TwicePrecision{Float64},Base.TwicePrecision{Float64}}
julia> x = [1 : 0.5 : 10...] 19-element Array{Float64,1}: 1.0 1.5 2.0 2.5
Не везде это будет работать, где может быть использован массив.
Да и, честно говоря, я не хотел менять типы, по сравнению с примерами выше. Просто использовал одну из конструкций для генерации массива.
kirtsar
13.03.2019 16:27+1Да я понимаю, что типы сильно разные, но с правильным дизайном это по идее должно работать везде, где требуется просто нечто, по чему можно итерироваться.
К примеру:
y = 1 : 0.5 : 10 x = zeros(length(y)) x .= y .+ y # in-place addition x .= 2 .* y # in-place multiplication y[7] # == 4rssdev10
13.03.2019 16:46+2using BenchmarkTools y = 1 : 0.5 : 10000000 x = zeros(length(y)) b = @benchmark begin x .= y .+ y # in-place addition x .= 2 .* y # in-place multiplication end #BenchmarkTools.Trial: # memory estimate: 192 bytes # allocs estimate: 3 # -------------- # minimum time: 117.716 ms (0.00% GC) # median time: 127.008 ms (0.00% GC) # mean time: 133.613 ms (0.00% GC) # maximum time: 194.349 ms (0.00% GC) # -------------- # samples: 38 # evals/sample: 1
y = [1 : 0.5 : 10000000...] x = zeros(length(y)) b2 = @benchmark begin x .= y .+ y # in-place addition x .= 2 .* y # in-place multiplication end #BenchmarkTools.Trial: # memory estimate: 96 bytes # allocs estimate: 4 # -------------- # minimum time: 59.379 ms (0.00% GC) # median time: 62.218 ms (0.00% GC) # mean time: 66.322 ms (0.00% GC) # maximum time: 132.069 ms (0.00% GC) # -------------- # samples: 76 # evals/sample: 1
technic93
14.03.2019 02:16Спасибо за ответ. Некоторые похожее фишки и в С++ даже завезли.
Итерация в for происходит по ссылке или по значению?
Правильно ли я понимаю что если использовать встроенные функции языка типа map, то там проверка индексов опускается?rssdev10
14.03.2019 08:25+1Итерация в for происходит по ссылке или по значению?
Я не совсем понимаю вопрос. Даже в C++ — итератор — отдельный класс. В Julia нет таких языковых понятий как ссылка и значение. Любое присвоение следует воспринимать как копирование ссылки (это не так на уровне машинного кода, но справедливо для модели языка). C-шных операторов &a, *a здесь тоже нет.
Правильно ли я понимаю что если использовать встроенные функции языка типа map, то там проверка индексов опускается?
Опять не понимаю вопрос. Если вопрос о том, выполняется ли реально внутренняя проверка, когда мы пишем a[i], чтобы i не вылетел за пределы, то ответ — не знаю. Скорее всего, не проверяется. Иначе на это придётся тратить процессорное время. Но при работе с итератором всегда идёт вычисление следующего элемента с проверкой границы.
Собственно, в примерах выше, я всего лишь продемонстрировал как избегать использование прямого обращения по индексу, чтобы не ошибиться с границами индексов. Это, конечно, ещё не Руби с его Enumerable. Но уже далеко не C++, с его довольно ограниченными итераторами.technic93
14.03.2019 17:14Имел ввиду
list = [1 2 3] for item in list item = item + 1 end
так будет работать? В rust/c++ можно захватывать по ссылке и по значению в такого рода for-конструкциях.
Да я имел ввиду насколько проверки замедляют код. Например если писать что-то типа
for (i=0;i<n;i++) {
x[i] = x[i]+1
}
То в некоторых случаях даже если в оператор есть проверка на i < n то много компиляторов умеют оптимизировать её, посколько такая же проверка содержится в условии цикла. Хотя для большинства случаев как Вы заметли лучше использовать синтаксис map, map-reduce, range-based-for.
Поэтому в rust например гарантируется что доступ к плохому индексу будет ругаться (panic). Поэтому стало интересно как аналогичную проблему решает Julia.rssdev10
14.03.2019 18:09list = [1 2 3]
for item in list
item = item + 1
end
У Julia всё просто. Воспринимаем переменную как ссылку на объект, но помним, что большинство операций не изменяют исходный объект (чистые функции и всё такое....). Соответственно, этот пример — бесполезен. item — локальная переменная. item + 1 не изменяет объект, на который ссылалась item.
julia> list = [1 2 3] 1?3 Array{Int64,2}: 1 2 3 julia> for item in list item = item + 1 end julia> list 1?3 Array{Int64,2}: 1 2 3
А вот такой пример приведёт к модификации (метод с суффиксом `!` является модифицирующим):
julia> list = [[1],[2],[3]] 3-element Array{Array{Int64,1},1}: [1] [2] [3] julia> for item in list push!(item, 1) end julia> list 3-element Array{Array{Int64,1},1}: [1, 1] [2, 1] [3, 1]
И такой пример также приведёт к модификации по той же причине. item ссылается на автономные объекты-массивы, каждый из которых может быть изменён:
julia> list = [[1],[2],[3]] 3-element Array{Array{Int64,1},1}: [1] [2] [3] julia> for item in list item .+= 1 end julia> list 3-element Array{Array{Int64,1},1}: [2] [3] [4]
Касаемо оптимизаций Julia на граничных значениях циклов — не отвечу. Скорее всего, что-то делает. В сущности, у неё есть возможность посмотреть генерируемый LLVM-код. По нему можно проверить.

lostmsu
До прочтения этой статьи я питал надежды, что придётся ботать новый язык для scientific computing. Но теперь похоже, что Julia — это красиво выглядящий костыль, где выстрелить себе в ногу также просто, как в Python.