
Для начала я сгенерировал случайную строку символов (длиною от 0 до 1000).
def random_string(from_int, to_int):
return str(''.join(random.SystemRandom().choice(string.ascii_letters + string.digits + string.punctuation) for _ in range(random.randint(from_int, to_int))))Далее взял хеш MD5 от строки.
def md5_from_string(string):
return hashlib.md5(string.encode('utf-8')).hexdigest()После – просчитал, сколько цифр от 0 до 9 есть в хеше. На выборке из 1000 хешей получил такие данные:
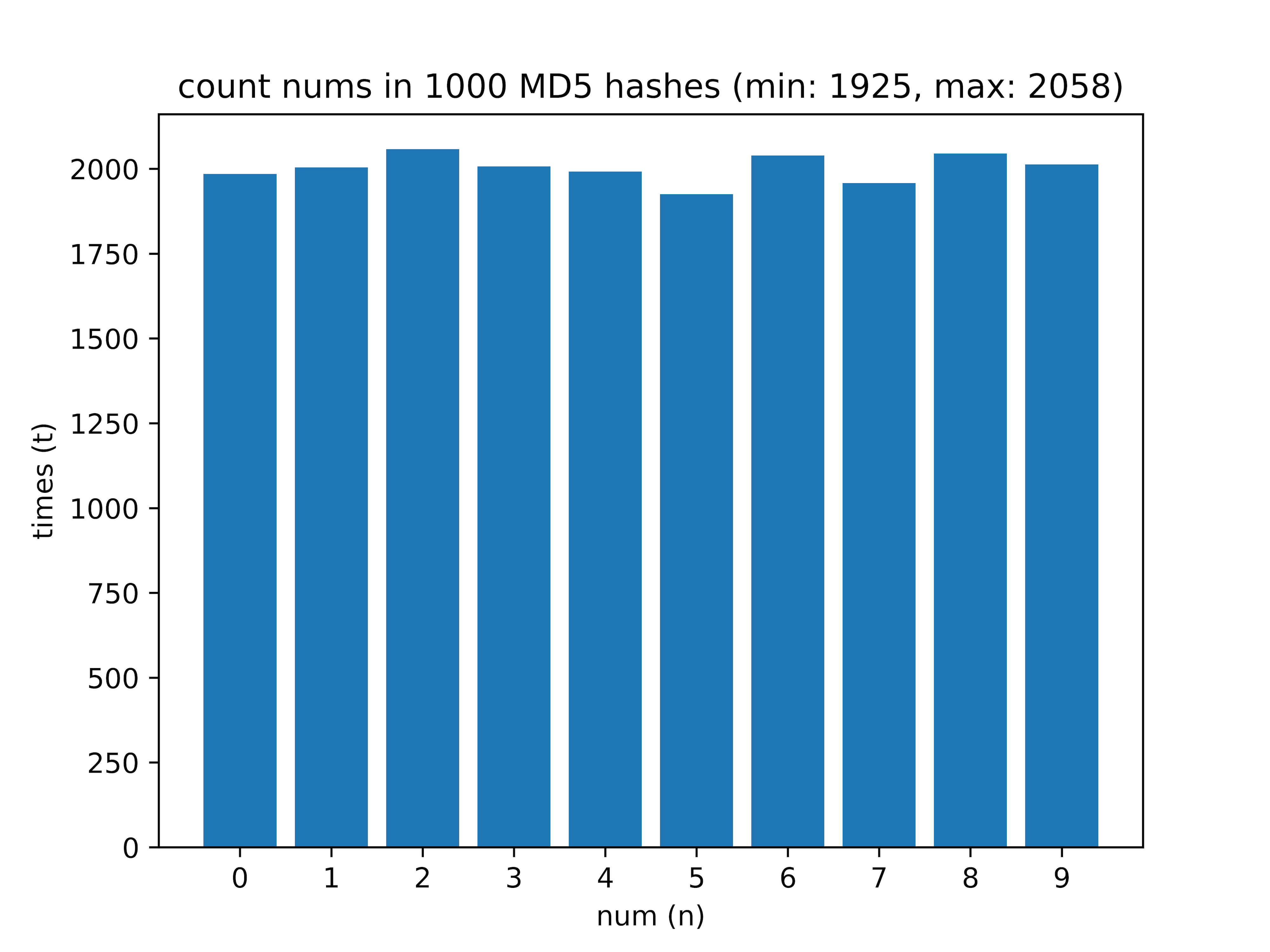
Здесь интересна разница между самой часто встречающейся цифрой и самой редко встречающейся (значение delta).

Далее, для того чтобы проследить изменение значения delta сделал выборки 10000, 100000, 1000000, 10000000 хешей.

Далее представлен список со значениями минимально и максимально встречающихся цифр и значении delta на выборках с разным количеством MD5 хешей:
- 100 — min: 179, max: 230, delta: 22.17%
- 1000 — min: 1925, max: 2058, delta: 6.46%
- 10000 — min: 19769, max: 20251, delta: 2.38%
- 100000 — min: 199297, max: 200846, delta: 0.77%
- 1000000 — min: 1997650, max: 2001690, delta: 0.20%
- 10000000 — min: 19991830, max: 20004818, delta: 0.06%
Что мы имеем: с увеличением количества хешей в массиве значение delta уменьшается и любая цифра почти с одной и той же вероятностью попадется в массиве. Таким образом, чем больше выборка – тем меньше разница между часто встречающимся и редко встречающимся цифрами. Соответственно и вероятность получения той или иной цифры в хеше — стремится к равномерности.
Эта информация легла в основу алгоритма, который мы реализовали на платформе для проведения конкурсов bepeam.com
Комментарии (39)

Aquahawk
23.05.2019 14:27+8Прекрасный пример нумерологии и отношения к криптографии как к магии. Такие вещи не так доказываются. Вот, специально для вас habr.com/ru/post/181372
iurii Автор
23.05.2019 14:30-3Тут нет «отношения к криптографии как к магии» — задача стояла не проанализировать криптографический алгоритм, а проанализировать результаты работы алгоритма хеширования.
Aquahawk
23.05.2019 14:34+5Вы можете доказать, что:
Соответственно и вероятность получения того или иного числа в хеше — равномерна.
Почему вы ставите численный эксперимент во вполне детерминированном алгоритме, который внятно описан? Почему результаты такого эксперименты вы считаете достаточными для такого утверждения? Вами проведены теоретические оценки масштабов ошибки как первого так и второго рода?
И отдельно, вы за три минуты статью про криптографию прочитали, или ответили не читая её?iurii Автор
23.05.2019 14:41-1… стремится к равномерности. Чем больше выборка хешей тем меньше разность между количеством самого часто встречаемого и самого редко встречаемого числа. Исходя из этого я делаю вывод что при увеличении массива хешей вероятность получения того или иного числа в хеше стремится к равномерности. Поправил в тексте.
Aquahawk
23.05.2019 14:48+3Ок, переобуваемся. Слово «стремится» в математике употребляется когда говорят о некоторой последовательности, предел которой существует. Предел имеет несколько разных определений, для которых доказана их равнозначность. Ещё раз, вы можете доказать что
что при увеличении массива хешей вероятность получения того или иного числа в хеше стремится к равномерности
Я не спорю с утверждением, это вполне может быть так и есть. Однако те выкладки которые вы приводите не позволяют сделать такого вывода. Вы неграмотно используете слова из математического аппарата, пытаетесь по наитию строить какие-то гипотезы и как-то их проверять.
iurii Автор
23.05.2019 14:50-3Я описал частный случай исследования вопроса, который передо мной стоял. Статья не претендует на полноту и не охватывает анализ алгоритма хеширования и его реализации.
И отдельно, вы за три минуты статью про криптографию прочитали, или ответили не читая её?
статья старая, читал ранее.Aquahawk
23.05.2019 14:52+4Так и напишите в шапке статьи что она является художественной заметкой содержащей некоторые математические термины, но не содержит доказательств, корректно поставленных экспериментов и не соответствует критериям научности.
nerudo
23.05.2019 14:51+3А цифры от A до F куда делись?
iurii Автор
23.05.2019 14:54-3По ним ситуация та же. Когда я делал просчет данных, которые нужны были для других целей и которые после включил в статью — использовал от 0 до 9.
nerudo
23.05.2019 14:56+1Это был тонкий намек, что сам по себе хэш шестнадцатиричный. Когда вы переводите его в десятичную систему вы сразу получаете неравномерность. Или на эти 2% и живете? ;)
PS А, извините, вы их отбрасываете. Тогда не знаю сколько процентов выходит…
berez
23.05.2019 14:52Я правильно понял? Вы берете хэш как hex, но считаете от него только цифры от 0 до 9?
А буковки a-f куда деваете? Отбрасываете? Почему? Зачем? А если весь хэш — это нечто вроде aafdeccdeffaabcaadf?
UPD: Ай, чуточку опоздал :)iurii Автор
23.05.2019 14:58А если весь хэш — это нечто вроде aafdeccdeffaabcaadf?
Проверял. Такова вероятность есть, но, например, на выборке в 1000000 хешей все равно в хеше присутствует минимум 8 цифр.

Aquahawk
23.05.2019 15:08Вот вы только что прекрасно продемонстрировали, что на миллионе хешей работает некое правило, что там от 8 цифр. При этом вы знаете что в общем случае это не так. И я могу это доказать контрпримером: abababababababababababababababab это валидное значение MD5 которое сильно вылетает за рамки результатов вашего эксперимента, о том что в хеше минимум 8 цифр. Ваши выкладки с статье обладают ровно той же доказательной способностью что и этот эксперимент с подсчётом количества цифр.
iurii Автор
23.05.2019 15:15+1Есть вероятность того что может быть хеш без цифр, например:
MD5 ("cbaabcdljdac") = cadbfdfecdcdcdacdbbbfadbcccefabd
как и вероятность того что MD5 хеш будет полностью цифровой:
MD5 ("aooalg") = 68619150135523129199070648991237Aquahawk
23.05.2019 15:17+1Но ваш эксперимент на целом миллионе хешей показал что так не бывает. Я к тому что качество этого эксперимента и того что описан в статье идентично, они ничего не показывают. Нельзя на основе такого эксперимента делать выводы.
iurii Автор
23.05.2019 15:27Но ваш эксперимент на целом миллионе хешей показал что так не бывает.
Нет, вполне могло быть что попадется хеш с меньшим количеством цифр, на скриншоте — анализ миллиона случайных хешей.
Я к тому что качество этого эксперимента и того что описан в статье идентично, они ничего не показывают.
Для меня данные, которые я получил и показал в статье показывают то, что с увеличением количества хешей в массиве значение delta уменьшается и любая цифра почти с одной и той же вероятностью попадется в массиве. На выборке из 100 хешей delta равна 22.17%, но на 10000000 — 0.06%. Для меня эти данные имеют прикладной характер и для проверки этого и делался эксперимент.
alexprey
23.05.2019 19:09С таким же успехом равномерно распределяются и обычные числа из функции рандома
berez
23.05.2019 15:36Эта информация легла в основу алгоритма, который мы реализовали на платформе для проведения конкурсов bepeam.com
А чем вас не устроил обычный генератор случайных чисел? Практически все они генерят вполне себе равномерно распределенные числа от 0 до скольки скажете. Совершенно непонятно, зачем мудохаться с md5 и выкусывать из hex-строки только цифры, рискуя остаться с очень коротким результатом.iurii Автор
23.05.2019 15:48-1Благодаря алгоритму определения победителя, который мы реализовали на bepeam.com любой посетитель может проверить достоверность результата розыгрыша, обычные генераторы такой возможности не дают.
berez
23.05.2019 16:36А нельзя ли — вкратце — сей алгоритм описать?
Помню, был лет двадцать назад бум всяких онлайн-рулеток, так в одной из них предлагалось для проверки честности скачать зашифрованный rar-архив.
Предполагалось примерно такое взаимодействие с пользователем:
1. На сервере «загадывается», куда попадет шарик, и формируется архивчик с загаданным числом.
2. Пользователь скачивает архив и делает ставку.
3. После розыгрыша пользователю дается пароль для расшифровки архива, и он может убедиться, что загадано было именно то, что нарисовалось на экране.
Понятно, что способ проверки был очень муторный и никто этим не занимался.iurii Автор
23.05.2019 17:31Алгоритм описан на сайте к каждому розыгрышу, например: https://bepeam.com/ua/124/?howTo=Y(укр). Основная идея его в том что каждый может проверить достоверность результата и исключить фальсификации в розыгрыше.
berez
23.05.2019 18:48Сразу вижу как минимум одну граблю: «назначенное число» может оказаться слишком большим («назначили» считать с десятой, а в хэше всего 2 цифры, остальное буквы). Еще неясно, кто именно назначает это магическое число и зачем. Сразу ясно — для манипуляций.
Еще непонятно, как именно вы шифруете емейлы. Если шифрование секретное — значит, организатор методом подбора может подогнать нужный хэш. Если шифрование открытое, то это подарок для спамеров.
И непонятно, как в примере вы из числа 8505 получили ID пэрэможця 1711. Какая-то магия.
JekaMas
23.05.2019 17:35Пользователь делает ставку.
Между пользователем и сервером проходит генерация ключей (distributed key generation).
Каждая сторона имеет по одному ключу BLS, например.
Каждая сторона подписывает одно и тоже значение (initial vector) и шлет подпись другой стороне.
Подпись другой стороны валидируется.
Если верна, то каждая сторона подписывает подпись и получает итоговую подпись. Которая для BLS детерминирована относительно ключей и initial vector.
Каждая сторона смотрит на итоговую подпись mod (сколько у нас допустимых значений для загадывания). И узнает была ли победа.
Схема где никто никому не доверяет, но все получается
xi-tauw
23.05.2019 16:50Простите, а что конкретно ваш алгоритм позволяет проверить? То, что конкретный участник правда проиграл или что у всех участников были равные шансы, даже если кто-то из участников знал чувствительные данные из внутрянки вашего сайта/алгоритма?
Если второе, то очень интересно. А если первое, то можете не утруждаться — таких алгоритмов можно с десяток за час придумать.JekaMas
23.05.2019 17:21Второе пахнет distributed source of randomness. Или еще чем-то, что имеет свойство verifiable.
iurii Автор
23.05.2019 17:34Алгоритм позволяет прозрачно выбрать победителя и каждый может проверить достоверность результата и отсутствие фальсификаций розыгрыша. Описание работы алгоритма на примере конкретного розыгрыша — https://bepeam.com/ua/124/?howTo=Y. Я подробнее опишу в отдельной статье.
xi-tauw
23.05.2019 17:45Понятно. То самое — любой легко убеждается, что он проиграл, а вы относительно легко подделываете нужный результат.
iurii Автор
23.05.2019 17:52Нет возможности подделать результат с тем чтобы выиграл «нужный» участник.
xi-tauw
23.05.2019 17:56За секунду до окончания вы блокируете прием новых участников в список. Дальше перебором вставляете псевдо имейл (из-за звездочек все равно не проверить реальный он или нет) и рассчитываете алгоритм, получая какой-то номер. Если номер не «загаданный», то повторяете. Мощность перебора у вас больше количества участников, так что рано или поздно перебор выдаст такой имейл, чтобы результат был подходящий. Учитывая скорость перебора, возможный предрасчет md5, я думаю, что той самой секунды хватит, чтобы никто не влез, а ваш «псевдоучастник» добавился.

humbug
23.05.2019 22:03+1О_о и что? Это же HEX представление хэша. Я могу сделать свой алфавит из abcdefghijklmno1 и анализировать частоту появления цифры 1 в хэше. Глупо же.
ZEvS_Poisk
Вы берете рандомную строку, хешируете, и анализируете хеш. Поскольку входная строка рандомная, то Вы ожидали на выходе хеша что-то менее рандомное?
Я думаю, что тот же результат можно получить и без хеширования, совсем.
Я понимаю, если бы Вы взяли 0000001, затем 0000002, затем 0000003 и т.д., и тогда проанализировали хеш от этого.
Какой смысл хешировать РАНД?
iurii Автор
Смысл был проверить распределение количества чисел в массиве хешей. Значение delta из массива случайных строк или 000000001...999999999 — результат будет приблизительно таким же.
ZEvS_Poisk
Я хотел сказать, что непонятна цель работы.
Выяснить что хеш md5 хорошо работает? Это и так известно, есть много профессиональных доказательств.
Выяснить, что функция RAND дает равномерное распределение? Тогда зачем ее хешировать?
Можно напрямую подвергнуть Вашему статанализу сразу функцию RAND.
И еще.
Странное утверждение, трудно понять что здесь сказано. Разница чего? Как разнятся «часто встречающиеся цифры» от «редко встречающихся цифр»?
А по моему, вероятность здесь статична и никуда не стремится.
P.S. Здесь Вас сильно «загнобили», но не унывайте, все образуется. :)
mehos
Статья была не про смысл, а про «смотри че я умею» на Пайтон.