
Одна из классических схем нейронной сети для реализации алгоритма RL выглядит следующим образом:
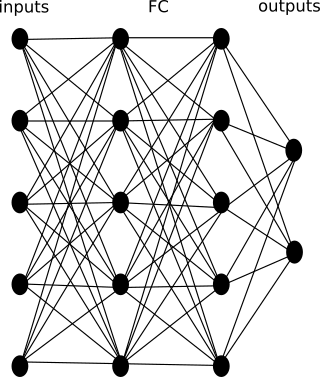
Где: inputs – входы в нейронную сеть; FC – (fully connected) архитектура скрытых слоев или CNN — FC – архитектура архитектура скрытых слоев (в зависимости о того, что подается на входы); outputs – выходы сети. Часто выходы сети это softmax слой, который выдает вероятность выполнения одного из действий из набора всех возможных действий.
Недостаток данной архитектуры, в том, что сложно реализовать выбор сразу нескольких одновременно выполняемых действий.
Для решения этой проблемы предлагается архитектура с слоем маски. Предлагаемая архитектура выглядит следующим образом:

Эта архитектура полностью соответствует классической архитектуре, но также включает слой маски действий. Выход у данной архитектуры один – это значение ценности действия (группы одновременно выполняемых действий). Слой маски действий может быть реализован в соответствии с псевдокодом ниже:
И использование этого кода демонстрирует следующий фрагмент кода:
Из кода слоя видно, что для каждого действия нейронная сеть учиться формировать некоторое представление действия в виде ряда весов. И эти представления либо проходят в сеть после слоя маски или же нет. В зависимости от операции эти веса могут проходить с заданием некоторой операции над всей группой весов действия (не только умножение на [0,1]). Таким образом формируется задание действий для вычисления сетью ценность группы выполняемых действий. (В классическом случае softmax слой вычислял ценность всех действий, в предлагаемой архитектуре нейронная сеть вычисляет ценность группы выбранных действий.)
(Определение ценности действия см. например, в Р.С. Саттон, Э.Г. Барто Обучение с подкреплением.)
Идея использования данной архитектуры для игры в тетрис в следующем. На входы мы подаем изображение стакана игры тетрис (один пиксель один квадратик). Мы группируем отдельные действия в группы действий. Оценка одного действия для нейронной сети это маска конечного положения фигуры в стакане. Фигура задается своими квадратиками в маске действий в слое маски действий в нейронной сети. Для выбора группы действий мы выбираем максимальную оценку действия (выход) из списка всех конечных положений текущей фигуры.

Рисунок. Показано поле (синие клетки) и падающая фигура (светло серые клетки). Конечное положение фигуры — это все возможные положения из которых фигура по правилам игры не может двигаться (не показаны).
В данном случае каждое действия разгон (несколько ускорений разгона), торможение (несколько возможных ускорений при торможении), а также несколько степеней поворота моделировалось в виде элементарных действий. Понятно, что одновременно может быть задействован поворот и одно из ускорений или же только одно действие поворота или одно действие ускорения. В данном случае архитектура позволяет задавать несколько элементарных действий одновременно для формирования комплексного действия.

Рисунок. Кроме самого поля для выполнения действий моделью автомобиля (на котором красно-зелеными линиями обозначено цель парковки), также выводятся входы нейронной сети (внизу) и значения оценки действий для всех возможных действий в данном состоянии модели.
Аналогично с применением в игре тетрис архитектура может использоваться для других игр, где на поле могут задаваться ряды фигур и несколько действий одновременно (например, перемещений по игровому полю).
В робототехнике данная архитектура может выполнять роль мета-сети координирующей отдельные структурные элементы в общий ансамбль.
Также данная архитектура позволяет как использовать transfer learning для предобучения CNN части, так и наоборот в начале обучать RL часть нейронной сети, а потом уже обучать CNN часть на уже обученной RL сети на модельных данных. В примере при программировании игры тетрис был применен transfer learning с обучением в начале CNN части и FC части до слоя маски действий (то, что переноситься в результирующую сеть). В задаче паркинга ещё планирую применить обучение CNN части после обучения RL части (т.е. «вишенка» первая).
> Исходники программы примеры можно найти по ссылке
Где: inputs – входы в нейронную сеть; FC – (fully connected) архитектура скрытых слоев или CNN — FC – архитектура архитектура скрытых слоев (в зависимости о того, что подается на входы); outputs – выходы сети. Часто выходы сети это softmax слой, который выдает вероятность выполнения одного из действий из набора всех возможных действий.
Недостаток данной архитектуры, в том, что сложно реализовать выбор сразу нескольких одновременно выполняемых действий.
Для решения этой проблемы предлагается архитектура с слоем маски. Предлагаемая архитектура выглядит следующим образом:
Эта архитектура полностью соответствует классической архитектуре, но также включает слой маски действий. Выход у данной архитектуры один – это значение ценности действия (группы одновременно выполняемых действий). Слой маски действий может быть реализован в соответствии с псевдокодом ниже:
import numpy as np
class Layer:
def __init__(self, items, item_size, extra_size):
assert(items > 0)
assert(item_size > 0)
assert(extra_size >= 0)
self.items = items
self.item_size = item_size
self.extra_size = extra_size
def build(self):
self._expand_op = np.zeros((self.items, self.items*self.item_size), dtype=np.float32)
for i in range(self.items):
self._expand_op[i,i*self.item_size:(i+1)*self.item_size] = np.float32(1.0)
def call(self, inputs, ops):
op_mask_part = inputs[:self.items*self.item_size]
if self.extra_size > 0:
ext_part = inputs[self.items*self.item_size:]
else:
ext_part = None
# if ops in [-0.5, 0.5] or [-0.5 .. 0.5]:
ops1 = np.add(ops, np.float(0.5)) # optional
extended_op = np.matmul(ops1, self._expand_op)
if self.extra_size > 0:
return np.concatenate((np.multiply(op_mask_part, extended_op), ext_part))
else:
return np.multiply(op_mask_part,extended_op)
И использование этого кода демонстрирует следующий фрагмент кода:
items = 5
item_size = 10
extra_size = 20
l = Layer(items=items, item_size=item_size, extra_size=extra_size)
l.build()
inputs = np.random.rand(items*item_size+extra_size)
ops = np.random.randint(0, 2, (items,), dtype="int")
ops = ops.astype(dtype=np.float32) - np.float32(0.5)
result = l.call(inputs,ops)
Из кода слоя видно, что для каждого действия нейронная сеть учиться формировать некоторое представление действия в виде ряда весов. И эти представления либо проходят в сеть после слоя маски или же нет. В зависимости от операции эти веса могут проходить с заданием некоторой операции над всей группой весов действия (не только умножение на [0,1]). Таким образом формируется задание действий для вычисления сетью ценность группы выполняемых действий. (В классическом случае softmax слой вычислял ценность всех действий, в предлагаемой архитектуре нейронная сеть вычисляет ценность группы выбранных действий.)
(Определение ценности действия см. например, в Р.С. Саттон, Э.Г. Барто Обучение с подкреплением.)
Примеры использования предлагаемой архитектуры
Игра Тетрис
Идея использования данной архитектуры для игры в тетрис в следующем. На входы мы подаем изображение стакана игры тетрис (один пиксель один квадратик). Мы группируем отдельные действия в группы действий. Оценка одного действия для нейронной сети это маска конечного положения фигуры в стакане. Фигура задается своими квадратиками в маске действий в слое маски действий в нейронной сети. Для выбора группы действий мы выбираем максимальную оценку действия (выход) из списка всех конечных положений текущей фигуры.
Рисунок. Показано поле (синие клетки) и падающая фигура (светло серые клетки). Конечное положение фигуры — это все возможные положения из которых фигура по правилам игры не может двигаться (не показаны).
Агент моделирующий движение автомобиля
В данном случае каждое действия разгон (несколько ускорений разгона), торможение (несколько возможных ускорений при торможении), а также несколько степеней поворота моделировалось в виде элементарных действий. Понятно, что одновременно может быть задействован поворот и одно из ускорений или же только одно действие поворота или одно действие ускорения. В данном случае архитектура позволяет задавать несколько элементарных действий одновременно для формирования комплексного действия.
Рисунок. Кроме самого поля для выполнения действий моделью автомобиля (на котором красно-зелеными линиями обозначено цель парковки), также выводятся входы нейронной сети (внизу) и значения оценки действий для всех возможных действий в данном состоянии модели.
Другие возможные применения архитектуры
Аналогично с применением в игре тетрис архитектура может использоваться для других игр, где на поле могут задаваться ряды фигур и несколько действий одновременно (например, перемещений по игровому полю).
В робототехнике данная архитектура может выполнять роль мета-сети координирующей отдельные структурные элементы в общий ансамбль.
Также данная архитектура позволяет как использовать transfer learning для предобучения CNN части, так и наоборот в начале обучать RL часть нейронной сети, а потом уже обучать CNN часть на уже обученной RL сети на модельных данных. В примере при программировании игры тетрис был применен transfer learning с обучением в начале CNN части и FC части до слоя маски действий (то, что переноситься в результирующую сеть). В задаче паркинга ещё планирую применить обучение CNN части после обучения RL части (т.е. «вишенка» первая).
> Исходники программы примеры можно найти по ссылке
Комментарии (6)

pdima
06.06.2019 14:28не совсем понятно какую проблему такой подход пытается решить и как. если необходимо реализовать выбор сразу нескольких одновременно выполняемых действий — почему просто не использовать несколько групп выходов с своими софтмаксами?
klizardin Автор
06.06.2019 15:18Преимуществами (по сравнению с группой softmax) можно назвать, что у нас есть что-то вроде encoding-ов для каждого из действий из входных данных. Т.е. расширяются возможности для transfer learning. (Это упоминается в конце статьи.)
Geotyper
Так как из статьи не все понял, решил начать с примеров, если взять Тетрис, сколько времени(или итераций) он обучается до минимального уровня игры? запустил, но что-то прогресс не прирастает, пока 7000 итераций.
klizardin Автор
Долго обучается. Плюс применялось transfer learning для того, чтобы в начале обучить CNN часть. Иначе процесс и длительный и сходимость намного хуже. Уже есть обученные модели (они в каталоге tetris/models). Нужно было мне писать изначально очень хорошо оптимизированный код на C++ и подключать вмешними модулями к питону.
Также отмечу, что модели не оптимально обученные (как CNN часть так и основная модель). У меня тоже не хватило терпения на то, чтобы дождаться нужного результата. Да и задумывались проекты не как улучшение результатов RL алгоритмов, а только как демонстрация подхода архитектуры нейронной сети.
klizardin Автор
Тетрис сам по себе применяется как задача для тестирования алгоритмов RL. (Т.к. тетрис достаточно сложная задача.) Но оптимизировать ни сеть ни параметры обучения не было вычислительных ресурсов. Плюс CNN архитектура сети можно было сделать более совершенной. Но опять же в демонстрации архитектуры сети не стал это делать.