
Цель
Научить нейронную сеть отличать «плохую» музыку от «хорошей» или показать, что нейронная сеть на это неспособна (данная конкретная ее реализация).

Этап первый: нормализация данных
Учитывая что музыка это совокупность несчетного числа звуков просто так «скормить» ее нейронной сети не выйдет, соответственно нужно определить что именно сеть будет «слушать». Вариантов выделения из музыки «наиболее важных» особенностей бесконечное множество. Нужно определить что потребуется выделить из музыки. В качестве опорных данных я определил, что выделить нужно некоторое представление о частотах звуков используемых в музыке.
Я решил выделить именно частоты, т.к. во первых они различны для разных музыкальных инструментов.

Во вторых чувствительность слуха в зависимости от частоты различна и достаточно индивидуальна (в разумных пределах).
В третьих насыщенность трека определенными частотами достаточно индивидуальна, но при этом схожа для схожих композиций, к примеру соло на гитаре в двух различных, но похожих треках будет давать схожую картину «насыщенности» трека на уровне отдельных частот.
Таким образом задача нормализации сводится к выделению некоторой информации о частотах, которая показывает:
- как часто в композиции звучит звук из данного диапазона частот
- как громко он звучал
- как долго он звучал
- и так для каждого определенного диапазона частот (нужно разбить весь «слышимый» спектр на определенное число диапазонов).
Для выделения частотной насыщенности в треке на каждом временном интервале можно воспользоваться данными FFT, эти данные можно при желании вычислить вручную, но я воспользуюсь уже готовой открытой библиотекой Bass, точнее оболочкой для нее Bass.NET, которая позволяет получить эти данные более гуманно.
Для получения FFT данных с трека достаточно написать небольшую функцию.
После получения сырых данных необходимо их обработать.

Визуализация полученных данных
Во первых нужно определить на сколько частотных диапазонов делить искомый звук, от этого параметра зависит то насколько детализированным будет результат анализа, но и соответственно даст большую нагрузку на нейронную сеть (ей потребуется больше нейронов, чтобы оперировать большими данными). Для нашей задачи возьмем 1024 градации, это достаточно детальный спектр частот и сравнительно небольшое количество информации на выходе. Теперь необходимо определить как из N массивов float[] получить 1 массив, который содержит более менее всю необходимую нам информацию: насыщенность звука определенными спектрами, частота возникновения различных спектров звука, его громкость, его длительность.
С первым параметром «насыщенностью» все достаточно просто, можно просто просуммировать все массивы и на выходе мы получим как «много» было каждого спектра во всем треке, но это не будет отражать других параметров.
Чтобы «отразить» на конечном массиве и другие параметры можно суммировать немного сложней, не буду вдаваться в подробности реализации подобной «суммирующей» функции, т.к. число ее возможных реализаций фактически бесконечно.
Графическое представление полученного массива:
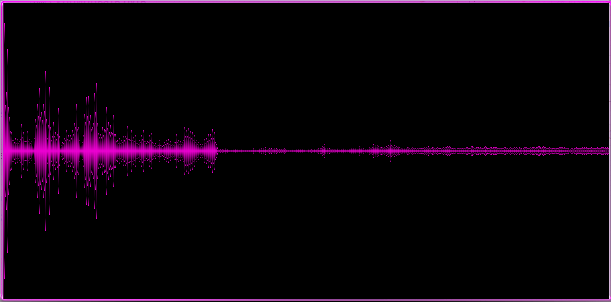
Пример 1. Относительно спокойная мелодия с элементами легкого рока, рояль и вокал
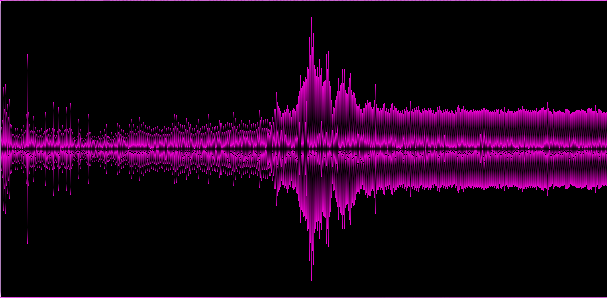
Пример 2. Относительно «мягкий» dubstep с элементами
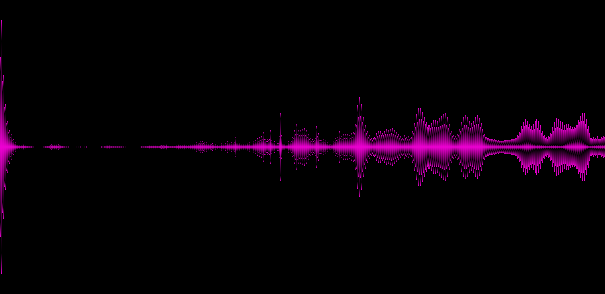
Пример 3. Музыка в стиле близком к trance
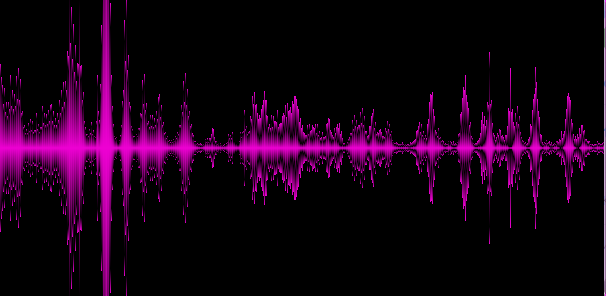
Пример 4. Pink Floyd
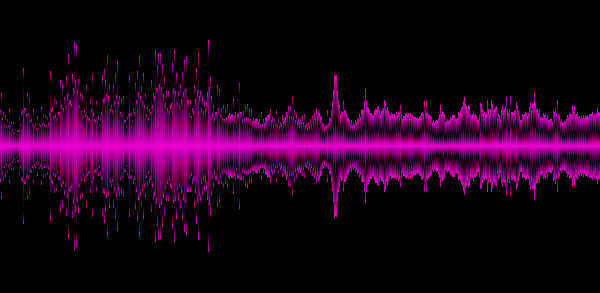
Пример 5. Van Halen
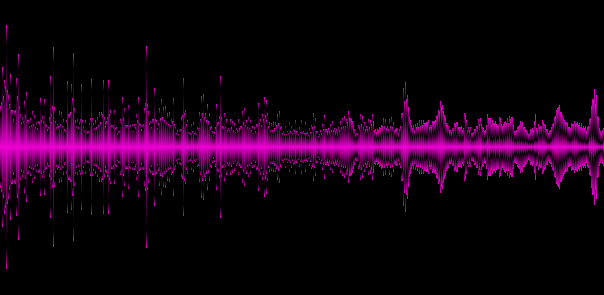
Пример 6. Гимн России
На приведенных примерах становится видно, что различные жанры дают различные «спектральные картины», это хорошо, значит мы выделили по крайней мере некоторые ключевые особенности трека.
Теперь нужно подготовить нейронную сеть, которую будем «обучать». Алгоритмов нейронных сетей много, часть лучше для определенных задач, часть хуже, я не ставлю цели изучить в контексте задачи все виды, я возьму первую попавшуюся под руку ее реализацию (спасибо dr.kernel), достаточно гибкую, чтобы ее приспособить к решению поставленной задачи. Я не выбираю «более подходящую» нейронную сеть, т.к. задача проверить «нейронную сеть» и если случайная ее реализация покажет хороший результат, то однозначно есть более подходящие виды нейронных сетей, что покажут результаты еще лучше, если же сеть не справится, то это покажет только, что данная нейронная сеть не справилась с задачей.
Данная нейронная сеть обучается данными, которые лежат в диапазоне от 0 до 1 и на выходе тоже дает значения от 0 до 1. Поэтому данные нужно привести к «пригодному виду». Привести данные к подходящему виду можно множеством способов, результат все равно будет похожий.
Этап второй: подготовка нейронной сети
Нейронная сеть, которую я использую определяется количеством слоев, количеством входных, выходных и количеством нейронов на каждом слое.
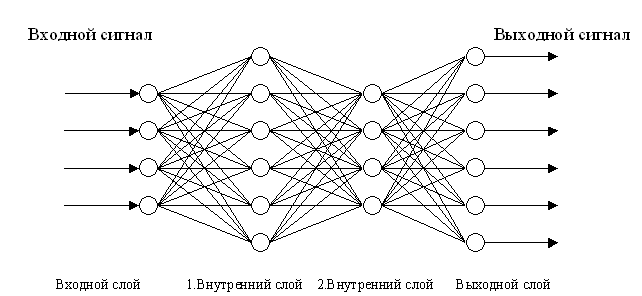
Очевидно, что не все конфигурации «одинаково полезны», но определенных методов для определения «лучшей» конфигурации для данной задачи мне неизвестны, если таковые вообще могут быть. Можно было бы просто попробовать несколько различных конфигураций и остановиться на той «что лучше подходит», но я пойду иным путем, я буду выращивать нейронную сеть эволюционным алгоритмом, позже в статье объясню как именно.
К данному моменту определены формат входных данных, нужно определить формат выходных данных. Очевидно можно просто делить треки на «хорошие» и «плохие» и будет достаточно 1 выходного нейрона, но я считаю, что хорошие и плохие понятие растяжимое, в частности определенная музыка лучше подходит для пробуждения утром, другая прогулки по городу по дороге на работу, третья для отдыха вечером после работы и т.д. то есть качество трека должно определяться еще и относительно времени суток и дня недели, итого 24*7 выходных нейронов.
Теперь нужно определить выборку для обучения, для этого можно конечно взять все треки и сидеть отмечать в какое время их хочется послушать или лучше вообще никогда не слышать, но я не из тех кто бы сидел часами и отмечал треки, гораздо проще это сделать «по ходу пьесы», то есть во время прослушивания трека. То есть «обучающую» выборку должен сформировать плеер, во время прослушивания треков в котором можно было бы отметить трек «хорошим» или «плохим». И так представим, что такой плеер есть (он действительно есть, то есть был написан на основе открытых кодов другого плеера). После десятка часов прослушивания музыки в различные дни собираются данные для первой выборки. Каждый элемент выборки содержит входные данные (1024 значения спектральной картины трека) и выходные (24*7 значений от 0 до 1, где 0 совсем плохой трек и 1 очень хороший трек для каждого часа из 7 дней недели). При этом при отметке «хороший» трек + ставился на всех днях недели и часах, но в данный час\день недели +был больше, и аналогично для «плохой», то есть данные не 0 и 1, а некоторые значения между 0 и 1.
Данные для обучения есть, теперь нужно определить что считать обученной сетью, в данном случае можно считать, что для загруженных в нее данных отличие между откликом сети на входные данные не должно и исходными выходными данными должно быть минимально. Так же крайне важна возможность сети «предсказывать» по неизвестным ей данным, то есть не должна быть переобучена, с переобученной сети толку будет мало. Определить «качество отклика» проблем нет, для этого есть функция вычисляющая ошибку, остается вопрос как определить качество предсказания. Для решения этой проблемы достаточно обучать сеть на 1 выборке, но проверять качество на другой, при этом выборки должны быть случайны и элементы первой и второй не должны повторяться.
Алгоритм проверки уровня обучения сети найден, теперь нужно определить ее конфигурацию. Как я уже говорил для этого будет использоваться эволюционный алгоритм. Для этого возьмем стартовую конфигурацию, скажем 10 слоев, в каждом по 100 нейронов (этого будет однозначно мало и качество такой сети будет не очень хорошим), далее обучим за определенное число шагов (скажем 1000), после определим качество ее обучения. Далее переходим к «эволюции», создаем 10 конфигураций, каждая из которых является «мутантом» исходной, то есть у нее изменена в случайную сторону либо количество слоев, либо количество нейронов на каждом или некоторых слоях. Далее обучаем каждую конфигурацию тем же способом, что и исходную, выбираем лучшую из них и определяем ее как исходную. Данный процесс продолжаем до тех пор, пока не наступает такой момент, что мы не можем найти конфигурацию, которая обучается лучше чем исходная. Данную конфигурацию считаем лучшей, она оказалась способной лучше всех «запомнить» исходные данные и лучше всех предсказывает, то есть результат ее обучения наиболее качественный из возможных.
Эволюционный процесс занял порядка 6 часов для выборки размером в 6000 элементов, после пары часов оптимизаций процесс занимает около 30 минут, конфигурация может отличаться в различных выборках, но чаще всего конфигурация примерно из 7 слоев, с количеством нейронов плавно увеличивающихся к 3-4 слою и далее более быстро сокращается к последнему слою, своеобразный горб на 3-4 слое из 7, по всей видимости такая конфигурация наиболее «способная» для данной сети.
Итак сеть «выросла» и способна к обучения, начинается обычное для сети обучение, долгое и нудное (до 15 минут), после сеть готова «слушать музыку» и говорить «плохая» она или «хорошая».
Этап третий: сбор результатов
Вес «мозга» — конфигурации обученной сети составил 25 мб, вес будет различаться для различных выборок, в целом чем больше выборка тем больше нужно нейронов, чтобы справиться с ней, но вес среднестатистической сети будет примерно таким же.

Обучающая выборка состояла из «хороших» по моему скромному мнению треков, таких как Van Halen, Pink Floyd, классическая музыка (не любая), легкий рок, мелодичные и спокойные треки. «Плохой» в выборке по моему мнению считались реп, попса, слишком тяжелый рок.
Определим «индекс качества» случайных треков, который посчитает нейронная сеть после обучения.
- Van Halen — 29 pts
- Rammstein-Mutter(альбом) — 20-23 pts
- Rihanna — 26 pts
- The Punisher -11-17 pts
- Radiorama — 25 pts
- R Claudermann — 25-29 pts
- The Gregorians — 27-29 pts
- Pink Floyd — 29-33 pts
- Русский «рэп» низкого качества — 9-11 pts
- Красная плесень 16-19 pts
- Би-2 24-29 pts
- Високосный год — 25-33 pts
Вывод:
Первая попавшаяся нейронная сеть, после «эволюционной» настройки конфигурации и обучения показала наличие «навыков» определения характеристик трека. Нейронная сеть может быть научена «слушать музыку» и отделять треки, которые понравятся или не понравятся «слушателю», который ее обучал.
Полный исходный код приложения на C# и скомпилированную версию можно скачать на GitHub.
Внешний вид приложения, в котором реализован весь описанный в статье функционал:
Надеюсь, мой опыт в данном исследовании поможет в будущем тем, кто захочет изучить возможности нейронных сетей.
Комментарии (16)

ZlodeiBaal
29.07.2015 22:27Пробовали сделать сравнительное исследование?
Послушать незнакомой музыки и расставить цифирьки, а потом посмотреть что расставила сеть?
vpuhoff Автор
30.07.2015 12:42Как раз это сделал на третьем этапе, просто исполнителей из «Общей кучи» выбирал более менее известных, чтобы читателю было ясно какой это жанр и соотносится ли результат с тем, чего пытался добиться.

efremovaleksey
30.07.2015 02:01+1Попробуйте оперировать двумя составляющими моно (A+B) и разностной (A-B). Басы, вокал, главные инструменты будут в первой, а всё, что отвечает за панорамирование «вглубину», в том числе немаловажные во многих стилях стереоэффекты — во второй.
Т.к. во второй практически никогда нет НЧ, их можно отбросить.vpuhoff Автор
30.07.2015 12:43Спасибо, не подумал, что можно было так сделать, сохранил себе, попробую изменить алгоритм создания «спектральной картины».
mrgloom
02.08.2015 13:04+1Пару лет назад была такая вот попытка:
habrahabr.ru/post/161005
habrahabr.ru/post/194724
Еще вот есть датасет:
labrosa.ee.columbia.edu/millionsong
www.kaggle.com/c/msdchallenge
Кстати не знаю есть ли что то основанное чисто на анализе сырых данных песен?
spotify — тут вроде коллаборативная фильтрация как и на last.fm без анализа содержимого самих песен
www.slideshare.net/erikbern/collaborative-filtering-at-spotify-16182818
www.slideshare.net/erikbern/mlhadoop-nyc-predictive-analytics-2
pandora — тут вроде бы эксперты проставляют тэги.vpuhoff Автор
03.08.2015 12:24За ссылки спасибо, стало понятно откуда у меня эта идея взялась, помню как раз после прочтения второй ссылки захотелось повторить. Было бы интересно все 3 проекта объединить в один, вышел бы достаточно сильный продукт. Соревнования интересные, но давно закончились. В целом сервисов достаточно много, первоначально как раз думал взять за основу один из них, но из за
адскогонедружелюбного API и «анализатора» заточенного под cpp решил написать свой, заодно упорядочить накопившиеся знания по анализу звука. К тому же все сервисы работают исключительно через интернет, хотел сделать самостоятельный, независимый ни от чего проект.mrgloom
16.08.2015 18:46marsyasweb.appspot.com/download/data_sets
вот еще, датасет для классификации по музыкальным жанрам.
Cydoor
Интересно, а можно ли еще выявить корреляцию с настроением человека, собрать базу разной музыки и реализовать адаптивный музыкальный плеер?
Аналогов вроде бы еще не было?
LaCTuK
Если вместо «Настроения» подставить «то, чем человек планирует заниматься под музыку», то беглый поиск выдает, что Google play музыка уже умеет это и многое другое (+погода, +время суток)
shtorman
функционал есть и у Яндекс.Радио, и у inmood, вопрос в реализации, эффективности и точности определения того, что хотел пользователь.
Искренне желаю творческого развития проекту автора и новых нейронных сетей!
vpuhoff, может поделитесь ссылками на материал по изучению нейронных сетей?
… опечатка: «то есть результат ее обучения наиболее качественный из возможных.»
vpuhoff Автор
Аналоги конечно есть, интерес был решить задачу самостоятельно, для изучения нейронной сети так сказать на практике, к тому же аналоги по большей части онлайн и заставить их работать со своей фонотекой было бы проблематично (но на телефоне вполне можно, не знаю правда насколько умный алгоритм переключения будет без интернета).
Спасибо, опечатку поправил. К сожалению ссылок не сохранилось, т.к. в основе была 1 нейронная сеть, исходный код которой приведен и большое количество хаотичной информации в голове, которую как я надеялся немного упорядочу, пока буду решать конкретную задачу.
vpuhoff Автор
Плеер как раз реализован, shuffle с использованием pts, которые дает нейронная сеть, база соответственно тоже есть, но локальная, из той музыки, что слушатель даст программе. Для серьезной базы нужна медиатека побольше моей.
AlexanderG
А в качестве источника данных о настроении использовать энцефалограф Emotiv EPOC.
vpuhoff Автор
Было бы классно попробовать, если бы не его цена, пока не готов потратить 500$ ради 1 эксперимента к сожалению)