
О чём речь? Что за задача топологической оптимизации?
Вот представьте, что нужно, например, задизайнить какой-нить мост, многоэтажное здание, крыло самолёта, лопатку турбины или да не важно что. Обычно, это решается путём нахождения специалиста, например, архитектора, который бы с помощью своих знаний матана, сопромата, целевой области, а так же своего опыта, интуиции, тестовых макетов и т.д. и т.п. создавал бы нужный проект. Тут важно, что этот полученный проект был бы хорош только в меру хорошести этого специалиста. А этого, очевидно, не всегда достаточно. Поэтому когда компьютеры стали достаточно мощными, мы стали пытаться переложить подобные задачи на них. Ибо
Такие задачи получили название "задачи структурной оптимизации", т.е. генерации оптимального дизайна несущих нагрузку механических структур [1]. Подразделом задач структурной оптимизации являются задачи топологической оптимизации (собственно, именно на них конкретно сфокусирована рассматриваемая работа, но это сейчас совершенно не суть и об этом потом). Типовая задача топологической оптимизации выглядит примерно так: для некого заданного концепта (мост, дом, и т.д.) в пространстве в двух или трёх измерениях, имея конкретные ограничения в виде материалов, технологий и иных требований, имея некоторые внешние нагрузки, нужно задизайнить оптимальную структуру, которая будет держать нагрузки и удовлетворять ограничениям.
- "Задизайнить" по сути означает найти/описать некоторое подпространство исходного пространства, которое надо заполнить строительным материалом.
- Оптимальность может быть выражена, например, в виде требования минимизации общего веса структуры при ограничениях в виде максимально допустимых напряжений в материале и возможных смещениях при заданных нагрузках.
Чтобы решить эту задачу на компьютере, целевое пространство решений дискретизируется в набор конечных элементов (пикселей для 2D и вокселей для 3D) и далее с помощью какого-то алгоритма компьютер решает, заполнить ли этот каждый индивидуальный элемент материалом или оставить его пустым?

(Изображение из "Developments in Topology and Shape Optimization", Chau Hoai Le, 2010)
Так вот, уже из постановки задачи видно, что её решение — вполне себе крупная заноза для учёных. Желающим некоторых подробностей могу предложить, например, посмотреть весьма старый (2010 года, что всё же много для активно развивающейся области), зато достаточно подробный и легко гуглящийся диссер Chau Hoai Le с названием "Developments in Topology and Shape Optimization" [2], откуда я стащил верхнюю и нижнюю картинки.
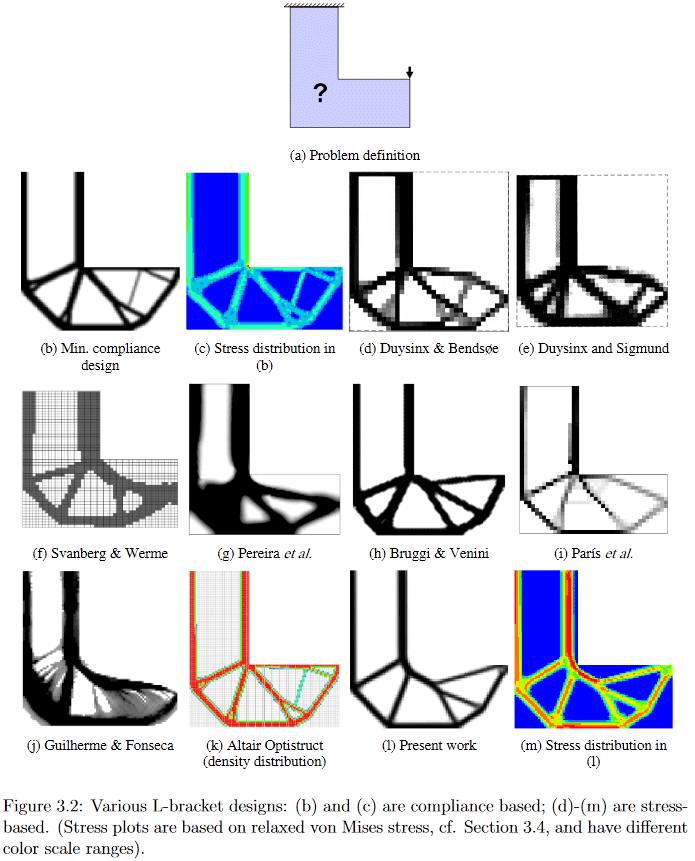
(Изображение из "Developments in Topology and Shape Optimization", Chau Hoai Le, 2010)
В качестве примера, на этой картинке хорошо видно, как очень по разному разными алгоритмами генерится решение вроде бы простой проблемы дизайна L-образного подвеса.
Так вот, теперь вернёмся к рассматриваемой работе.
Авторы весьма остроумно предложили решать такие задачи оптимизации с помощью дифференцируемой физической модели и хорошо известных в Машинном Обучении методов градиентного спуска, используя в качестве параметров модели веса и входы нейронной сети. По их словам (кода нет, и вообще нет ничего, кроме статьи и большого файла с примерами [4]), это даёт или такой же результат, как лучшие бейслайны на простых задачах, или лучшие бейслайнов на сложных.
Метод
Дальше я попробую описать, что и как конкретно авторы предложили делать, но сразу предупреждаю, что не гарантирую 100% правильности, ибо к моей уже несколько заржавевшей эрудиции в области ещё следует добавить кроме крайне скудной краткости описания ещё и некоторую общую "незрелость" статьи, находящейся, судя по наличию двух редакций за 4 дня, в процессе доработки.
Итак, их метод (применимый, как ненавязчиво напоминают авторы, к гораздо большему набору проблем оптимизации, чем только лишь одна структурная/топологическая оптимизация) глобально состоит из четырёх основных шагов.

(Изображение из рассматриваемой публикации)
Шаг 1, генерация кандидата.
Нейросеть (далее НС) используя случайный первичный входной вектор _beta (он так же, как и веса сети, является тренируемым параметром), генерит (какую-то) картинку решения (работа идет с 2D, но на 3D, думаю, так же можно распространить). В качестве НС-генератора используется апсемплинговая часть известной архитектуры U-Net.
Шаг 2, применение ограничений и конвертация кандидата в каркас физ.модели.
Значения пикселей конвертируются в значения физических плотностей (насколько я понимаю из [2], они бинарны) в два шага. Сначала ненормализованные пикселы=логиты конвертятся в валидные значения плотности с помощью сигмоиды, помогающей выдерживать ограничение на общий объём использованного материала — для всей картинки подбирается бинарным поиском число-bias, которое вычитается из каждого пиксела и результат прогоняется через обычную сигмоиду (а bias выбирается так, чтобы общий объём полученных таким образом плотностей был бы равен некоторому наперёд заданному объёму V0, подробнее на эту тему см. комментарий); затем полученные значения плотности конвертятся в физическую плотность в пикселе с помощью некого cone-filter с радиусом 2 (Предположу, что речь идёт о каком-то фильтре из аппарата математической морфологии, возможно это он описан в главе 3.1 Density Filtering работы [3]).
Короче, суть в том, что на этом шаге ненормализованный выход вполне обычной НС превращается в правильно нормализованный каркас физической модели, к которому уже применены необходимые априорные ограничения (в работе это используемое количество материала).
Шаг 3, оценка полученного каркаса физической моделью.
Полученный каркас прогоняется через дифференцируемый физический движок, чтобы получить вектор(/тензор?) сдвига конструкции под нагрузкой (в т.ч. гравитацией) U. Ключевое здесь — дифференцируемость движка, что позволяет получать градиенты (напомню, что градиентом функции является в общем случае тензор, составленный из частных производных функции по всем её аргументам. Градиент показывает направление и скорость изменения функции в текущей точке, поэтому, зная его, можно "подкручивать" аргументы так, чтобы с функцией происходило нужное изменение — она уменьшалась или увеличивалась). Такой дифференцируемый физический движок не надо писать с нуля, — они давно существуют и хорошо известны. Авторам потребовалось лишь сделать их сопряжение с пакетами расчёта нейросетей, типа TensorFlow/PyTorch.
Шаг 4, вычисление значения целевой функции для каркаса/кандидата.
Рассчитывается подлежащая минимизации скалярная целевая функция с(x), описывающая податливость (она обратна жесткости) полученного каркаса. Функция податливости зависит от полученного на прошлом шаге вектора сдвига U и матрицы жесткости конструкции К (мне не хватает знаний по topology optimization, чтобы понять, откуда берётся К, — предположу, что, похоже, она напрямую считается из каркаса).
/*
см. также комментарии (1) от kxx и (2) от 350Stealth
*/
И далее — готово. Поскольку всё создаётся в среде с автоматическим дифференцированием, то на этом этапе мы автоматически получаем все градиенты целевой функции, которые проталкиваются благодаря дифференцируемости всех преобразований по каждому шагу обратно вплоть до весов и входного вектора генерирующей нейросети. Веса и вх.вектор соответственно своим частным производным изменяются, вызывая необходимое изменение — минимизацию целевой функции. Далее происходит новый цикл прямого прохода по НС -> применение ограничений -> просчёт физ.модели -> расчёт целевой функции -> новые градиенты и обновление весов. И так до схождения алго.
Важный момент, описания которого я не нашёл в работе, — как выбирается общий объём конструкции V0, с помощью которого выполняется конвертация кандидатного решения в каркас на шаге 2. От его выбора, очевидно, чрезвычайно зависят свойства получаемого решения. По косвенным признакам (все примеры полученных решений [4] имеют по несколько экземпляров, отличающихся как раз по ограничению объёма), предположу, что они просто фиксируют V0 на некой сетке из диапазона [0.05, 0.5] и затем сами глазками смотрят получаемые решения с разными V0. Ну, для концептуальной работы этого, в общем, и так достаточно, хотя, конечно, было б ужасно интересно посмотреть вариант с подбором так же и этого V0, но, это пойдёт, видимо, на следующий этап развития работы.
Второй важный момент, которого я так и не понял, это как они накладывают ограничения/требования на конкретный вид нужного решения. Т.е. если отделить мост от здания ещё можно благодаря физической модели (здание имеет полную опору, а мост — только в граничных концах), то как отделить, допустим, здание в 3 этажа от здания в 4 этажа?
Третьим непонятным лично мне моментом является вопрос устройства и дифференцируемости того самого cone-filter, с помощью которого на втором шаге нормализованные плотности превращаются в физические плотности (которые вроде бы бинарны?), используемые физической моделью. Впрочем, судя по всему, оба эти последние непонятные момента являются вполне стандартными в топологической оптимизации, поэтому авторы и не заостряли на них внимания.
Как это работает?
Оказалось, что для маленьких (в терминах размера пространства решения = количества пикселей) проблем, метод даёт ± аналогичное качество результатов, как и лучшие традиционные методы топологической оптимизации, но на больших (размер сетки от 2^15 и более пикселей, т.е., напр, от 128*256 и более) получение качественных решений методом более вероятно, чем лучшим традиционным (из 116 тестированных задач метод дал предпочтительное решение в 99 задачах, против 66 предпочтительных у лучшего традиционного).
Более того, вот тут начинается кое-что особенно интересное. Традиционные методы топологической оптимизации в больших задачах страдают от того, что на ранних этапах работы быстро формируют мелкомасштабную паутину, которая потом мешает развитию крупномасштабных структур. Это приводит к тому, что полученный результат бывает трудно/невозможно воплотить физически в жизнь. Поэтому вынужденно существует целое направление в задачах оптимизации топологии, которое изучает/придумывает методы, как же сделать получаемые решения более технологически удобными.
Здесь же, судя по всему, благодаря свёрточной сети, оптимизация происходит одновременно на нескольких пространственных масштабах одновременно, что позволяет избежать/сильно уменьшить "паутину" и получать более простые, но качественные и технологически-friendly решения!
Кроме того, опять же благодаря свёрточности сети, получаются вообще принципиально иные, чем в стандартных-традиционных методах, решения.
Например, в дизайнах:
- консольной балки (cantilever beam) метод нашёл решение всего из 8 составных частей, в то время как лучший традиционный — 18.
- моста с тонкими опорами (thin support bridge) метод выбрал одну опору с древоподобным паттерном ветвления, а традиционный — две опоры
- крыши (roof) метод использует колонны, а традиционный — ветвящийся паттерн. И т.д.
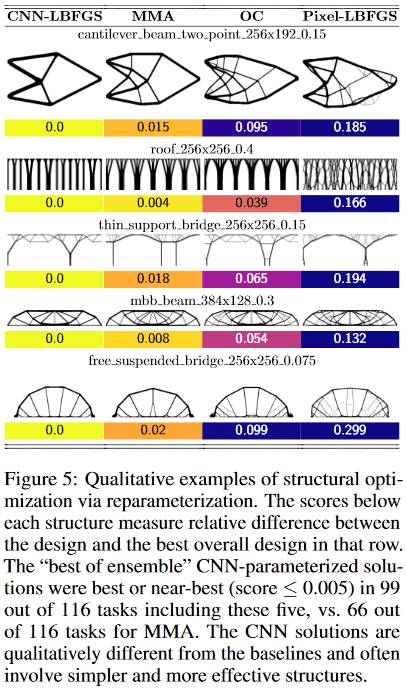
(Изображение из рассматриваемой публикации)
Что в целом в этой работе особенного?
Я никогда не видел такого использования нейросети. Обычно нейросети используют для получения некоторой очень хитрой и сложной функции y=F(x, theta) (где х — аргумент, а theta — настраиваемые параметры), которая умеет делать что-нибудь полезное. Например, если х — картинка с камеры автомобиля, то значением y функции может быть, например, признак есть ли в опасной близости к машине пешеход. Т.е. тут важно, что ценным является сам конкретный вид функции, которая многократно используется для решения какой-то задачи.
Здесь же — нейросеть используется как хитрое хранилище-модификатор-настройщик параметров некоторой физической модели, которое в силу самой своей архитектуры накладывает определённые ограничения на значения и вариации изменений этих параметров (собственно, примеры под заголовком Pixel-LBFGS представляют собой попытку оптимизировать пиксели напрямую, не используя нейросеть для их генерации, — результаты видны, НС важна). Вот тут-то становится критически важным свёрточность использованной нейросети, потому что именно её архитектура позволяет "поймать" концепт инвариантности переноса и немного поворота (представьте, что вы распознаёте текст с картинки — вам важно извлечь именно текст и при этом совершенно не важно, в какой части картинки он расположен и как повёрнут, — т.е. вам нужны инвариантность по переносу и повороту). В данной же задаче, какая-нибудь физическая палка, являющейся единицей строения и множество которых мы оптимизируем, всё так же остаётся ею независимо от положения и ориентации в пространстве.
Классическая полносвязная сеть, к примеру, тут бы, скорее всего, не сработала (так же хорошо), потому что её архитектура позволяет слишком многое/малое (ну вот да, такой дуализм, как посмотреть). В то же время, несмотря на то, что НС остаётся тут всё той же очень хитрой и сложной функцией y=F(x, theta), в этой задаче нам в конечном счёте вообще наплевать и на её аргумент х, и на её параметры theta, и на то, как будет использоваться функция. Нас волнует только лишь одно-единственное её значение y, которое получается в процессе оптимизации одной конкретной целевой функции для одной конкретной физической модели, в которой {x, theta} — всего лишь настраиваемые параметры!
Вот это, по-моему, афигенно крутая и новая идея! (хотя, конечно, потом, как всегда, может оказаться, что Шмидхубер описал её ещё в начале 90х, но поживём — увидим)
Вообще, по смыслу метод несколько напоминает обучение с подкреплением — там НС используется, грубо говоря, как "хранилище опыта" действующего в некоторой среде агента, которое обновляется по мере получения обратной связи среды на действия агента. Только там это самое "хранилище опыта" используется постоянно для принятия агентом новых решений, а тут — это всего лишь хранилище параметров физ.модели, от чего нам интересен лишь один-единственный итоговый результат оптимизации.
Ну и последнее. Интересный момент бросился в глаза.
Вот так выглядят оптимальные решения для задачи многоэтажного здания:
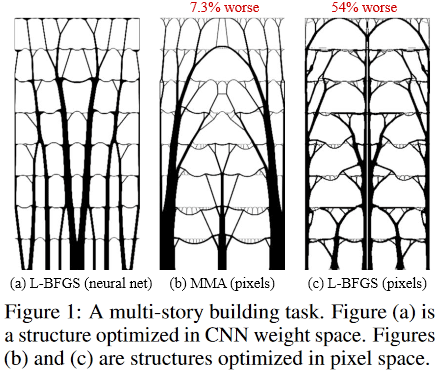
(Изображение из рассматриваемой публикации)
А вот так:

устроена внутри фантастическая Sagrada Familia, — Храм Святого Семейства, расположенный в Барселоне, Испания, который «дизайнил» гениальный Антонио Гауди.
[1] вариант определения задачи структурной/топологической оптимизации
[2] "Developments in Topology and Shape Optimization"
[3] Morphology-based black and white filters for topology optimization
[4] примеры решений
Комментарии (47)

nickname21
29.09.2019 20:46(размер сетки от 2^15 и более пикселей, т.е., напр, от 128*256 и более)
Тут наверное имеется ввиду в одном линейном направлении, то бишь 32768*32768 ~ 1млрд элементов.
Типа этого:

Arech Автор
29.09.2019 20:57Тут наверное имеется ввиду в одном линейном направлении, то бишь 32768*32768 ~ 1млрд элементов.
Нет, думаю, что моя оценка верна. Столь большие модели они не пробовали делать, это довольно ясно следует из статьи и сопроводительного файла примеров.nickname21
29.09.2019 21:01Ну может быть. Но это странно, что сетку 200x200 уже считают «большой» в статье… Игрушечная сетка, по моему мнению…
Arech Автор
29.09.2019 21:10Потому что это Академия, а не Продакшен. У них задача — придумать новый метод, опробовать его и показать возможности и потенциальные бенефиты. Для этого мегаразмеров в задачах не нужно.
nickname21
29.09.2019 21:22Так во всех статьях для задачек используют 100 на 100 сетки. Они я так понял утверждают, что на больших сетках нейросеть выигрывает? И 200 на 200 они считают уже большой? Чего то я не догоняю…

slovak
29.09.2019 23:54>> И чем мельче сетка, тем более оптимальную конструкцию вроде можно выжать. И тем более «фрактальной»(ажурной) она будет.
Если штрафовать за фрактальность в кост функции — то может и не быть.Arech Автор
30.09.2019 10:26Как Вы хотите описать то, что Вы называете «фрактальностью» в целевой функции?
(это не фрактальность, конечно. Более того, фрактальность может быть ценным и полезным качеством — посмотрите на древоподобные решения опор, они и надёжны и красивы. И фрактальны)
nickname21
29.09.2019 20:55формируют мелкомасштабную паутину, которая потом мешает развитию крупномасштабных структур. Это приводит к тому, что полученный результат бывает трудно/невозможно воплотить физически в жизнь.
А сейчас вроде как 3д принтеры (лазерные) по металлу есть, и точность по-моему до микрометров (?) Так что вполне можно печатать 3д структуры. Потом можно еще заливать пустоты эпоксидкой например, для большей прочности и надежности, и получать таким образом «3д-композит». Кто нибудь знает, додумывались в мире до такого или еще нет? Пытался кто нибудь такое делать?Arech Автор
29.09.2019 21:01«Можно делать» не значит «нужно делать». 3D печать ещё очень дорогое удовольствие и будет таковым скорее всего ещё долго. Поэтому проста и дешевизна тех.процесса — почти всегда и везде очень важны.
nickname21
29.09.2019 21:05Ну миллионеры и миллиардеры могут себе позволить. Для firefly aerospace Макс Поляков вроде бы смог позволить купить себе 3д принтер. Я же и не утверждаю, что на каждом заводе должны стоять. Но на каждом заводе и задачи такие (как в статье) решать не нужно…
Arech Автор
29.09.2019 21:13Не согласен. Их как раз много где нужно решать (да практически везде найдётся что-то, что можно/нужно сделать эффективнее и лучше), но вот позволить себе ими пользоваться могут очень немногие. В т.ч. и из-за нетехнологичности даваемых результатов.
nickname21
29.09.2019 21:18+1Инженеры могут и без этих задачек с помощью сопромата хорошо оптимизировать сплошную детальку. И до сих пор в основном так и делают. Обычная параметрическая оптимизация. Топологическую оптимизацию используют видимо лишь топовые фирмы типа Мерседес, Тойота и Боинги. И то, потом на основе результата обводят всё вручную и еще раз оптимизируют параметрической оптимизацией.
sshikov
29.09.2019 22:01То что точность до микрон, еще не означает, что размер изделия достаточен. По вполне понятным причинам чем больше размер принтера — тем сложнее сделать сам принтер достаточно жестким и точным (это в общем верно для любого станка). Так что да, дорогое удовольствие, если хочется и размеры и точность.
Насчет композита — не уверен, что для таких изделий применяли, но в целом почему нет? Все эти тонкие структуры — они хорошо работают на растяжение, и плохо на сжатие (потеря устойчивости). Это вполне верно даже для точких стенок обычных баков, так что проблема давно известна, как и много лет известны некоторые решения (типа сотовых конструкций).

perfect_genius
29.09.2019 21:47Интересно, как справился бы генетический алгоритм.
Arech Автор
29.09.2019 21:58О том, что их можно использовать пишут практические везде, но реальных примеров успешных использований не видел. Предположу, что как и в почти всех остальных случаях — очень медленно и, вероятно, плохо. Тут эффективный градиентный спуск, а ГА лишь несколько лучше случайного блуждания. И тоже подвержен локальным оптимумам.
Короче, в большинстве мне известных случаев, к ГА приходят совсем от безысходности, когда ничего умнее придумать не удаётся…
kxx
29.09.2019 23:45матрицы жесткости конструкции К
Матрица жесткости рассчитывается на основе свойств материала (модуль Юнга), длин стержней (если говорить про стрежневые системы типа ферм) и моментов инерции сечений. В простейшем случае (круг, квадрат) можно связать площадь сечения и момент инерции. Возможно, U-Net субоптимально генерирует базовую структуру и «толщины» стержней, что позволяет вычислить и матрицу жесткости. А далее минимизируется truss compliance, т.е. Fu/2 с учетом Ku=F, где F — нагрузки, u — смещения узлов системы, K — матрица жесткости.Arech Автор
30.09.2019 10:21Спасибо за ценное уточнение!
(первый комент по делу, не зря писал!)
Добавил в текст со ссылкой.
Немного уточню.
U-Net не то, что бы «субоптимально генерирует базовую структуру»… Она сначала вообще генерирует шум, который потом под давлением градиента целевой функции эволюционирует в решение. U-Net всегда генерирует просто монохромную картинку (примеры есть на врезках). На шаге 2 эта картинка с помощью нескольких хитрых трюков нормализуется (с точки зрения картинки — на общее количество нужного чёрного пигмента, с точки зрения физики — на общее количество нужного конструкции материала) и бинаризуется в чёрно-белую (я назвал полученное изображение каркасом, но я не уверен, что это общепринятый термин, — пока другого нет, оставляю). В этих шагах я уверен, и они описаны в статье. Соответственно, далее, учитывая Ваш комментарий, остаётся предположить, что зная свойства материала (допустим, бетона), можно ответить на вопрос, какая была бы матрица жесткости для конструкции из такого материала, описываемой таким каркасом.
kxx
30.09.2019 14:08Еще небольшое дополнение насчет того,
как выбирается общий объём конструкции V0
общий объем можно задать как 1, а решением задачи будут соотношения между объемами элементов конструкции (которые суммируются к 1).Arech Автор
30.09.2019 18:24Наверное, это работает в обычных методах, но здесь так нельзя. Я не останавливался подробно на этом моменте в описании, думал и так понятно, но поясню.
Сначала цитата из работы (самый конец второй страницы):

Значения выходного слоя использованной НС представляют собой то, что в Машинном Обучении стали называть «логитами», — «сырой» результат (как правило, линейной, = скалярное произведение) комбинации входов нейрона с весами этих входов. Они потенциально могут иметь значения (-inf,+inf). Для дальнейшего использования логиты, надо, очевидно, как-то нормализовать в какой-то ограниченный диапазон, причём так, чтобы выполнялось ограничение на максимально допустимое количество «включённых» значений (другими словами, на максимально допустимое количество чёрного пигмента, который потребуется, чтобы нарисовать полученную картинку).
Второй нюанс. Посмотрите на этот фрагмент картинки этапов метода:

Красной стрелкой я указал вариант графического изображения выдаваемых сетью логитов (очищенная картинка справа — это уже обработанный «каркас»). НС, особенно пока настройка параметров ещё сошлась окончательно, не даст идеальной картинки. Там будет присутствовать некий шум и артефакты. Хотя со временем донастройки он и будет уменьшаться, но он никогда не сойдёт в нуль, а само его присутствие будет «размывать» полезный сигнал, влиять на градиент там, где этого не нужно и т.д. и т.п. Короче, надо бы как-то сделать так, чтобы усилить сильные логиты и ослабить слабые (опять же, выполняя при этом ограничения на объём).
Вот что сделали авторы. Есть логистическая функция(у авторов почему-то отсутствует знак «минус» перед х^, но это скорее всего просто опечатка). Вот для наглядности её график:

Эта функция хороша тем, что отображает область определения (-inf,+inf) в область значений (0,1) так, что за счёт экспоненты даже небольшое отклонение аргумента от 0 очень быстро начинает отображаться почти в граничные значения (~0 для х<<0 или ~1 для x>>0). Соответственно, применив её к ненормированному изображению за счёт нелинейности мы получим почти-бинарное изображение (но оно всё ещё будет дифференцироваться, в отличие от пороговой функции).
Теперь вспоминая нюанс номер 2, мы можем сразу увидеть, что если применять сигмоиду к логитам «в лоб», то у нас возможна ситуация, когда, например, даже полезный сигнал может оказаться сильно ниже «порога отсечения» (условно, значения, при котором аргумент сигмоиды отображается почти в нуль), или шум окажется сильно выше «порога отсечения». Соответственно, чтобы изменить порог отсечения, надо просто уменьшить или увеличить аргумент сигмоиды на какую-то величину, — ей является в терминах авторов работы величина b(x^,V0). Если её выбирать для исходного изображения (x^) так, чтобы «объём» (сумма значений всех точек-пикселей отнесённая к общей площади?) преобразованного изображения оказалась бы равна V0, то одновременно с улучшением соотношения сигнал/шум и нормализацией картинки в (0,1) мы ещё получим и выполнение требования на общий объём конструкции.
Таким образом, я думаю, что просто так взять и задать общий объём в 1 (или любое другое наперёд выбранное число) нельзя, потому что это одновременно влияет и на «порог» сигмоиды, — можно случайно отсечь полезный сигнал. По этой причине авторы и пробовали несколько значений V0, вместо того, чтобы просто использовать соотношения элементов конструкции
nickname21
30.09.2019 23:33Ну а если более обще, то матрица жесткости получается из интеграла энергии (Лагранжиана)
E = integral( sigma**epsilon, dV ), (** — это двойное скалярное произведение, или свертка тензоров по всем индексам, а они сами тензора симметричные) где sigma — тензор напряжений, epsilon — тензор деформаций. Размерность как раз Па*1*м^3 = Н/м^2*м^3 = Н*м = Дж.
sigma = E**epsilon — тензор напряжений связан с тензором деформаций физическим законом (в данном случае линейным), а сам тензор epsilon выражается через производные от перемещений du[i]/dx[j].
Таким образом когда всё собрать, при этом задать линейным или квадратичным законом функцию на элементе u[i](x, y, z) и проинтегрировать каждый элемент, то получим матрицу жесткости, из условия равенства в соседних элементах u[i] (пока что неизвестных) То бишь получается система u^T*K*u = Fu. F — это силы приложенные к узлам, это слагаемое тоже должно быть под интегралом, точнее интеграл по поверхности, который преобразуется по закону Гаусса-Остроградского в интеграл по объему, ну да Бог с ним. И если взять производную(или точнее, вариацию) получаются как раз K*u = F. Или типа того, может что-то перепутал…
Как итог, матрица жесткости полностью определяется физическим законом = свойствами материала, и геометрией детали (точнее даже формами и сопряжениями конечных элементов). Ну и само собой тем, как мы задали функцию перемещений на каждом элементов (линейно, квадратично, или еще как).nickname21
01.10.2019 00:09А кстати тензор E (это 4-валентный тензор!) имеет 3^4 = 81 компоненту, но в силу симметрии (sigma и epsilon — симметричны), независимыми остаются 21 параметр вроде бы, если не путаю. Как раз 21 параметра достаточно, чтобы описать полностью анизотропное тело (в линейных областях конечно). Но так как композиты обычно плоские, то из них остаются только в плоскости 6 штук (Ex, Ey, gamma_xy, mu_xy...), или около того.
Для изотропного тела E и G достаточно. Или E, mu. E G связаны формулой посредством mu.
Можно еще полезть в нелинейную область, но это уже другая история, можно и от температур зависимость взять…
Ракеты кстати (поражающие) рассчитываются так, чтобы их корпус работал и в нелинейной области физического закона. Изделия всё-таки одноразовые…kxx
03.10.2019 13:18Ну так-то в пакетах типа ANSYS для типовых элементов (link, beam, shell и т.д.) матрицы жесткости уже заданы — иначе просчет конечно-элементных моделей длился бы вечность.
А вообще в статье как-то слишком поверхностно описана сама НС.Arech Автор
03.10.2019 13:43А вообще в статье как-то слишком поверхностно описана сама НС.
Наверное, потому, что для достижения заявленной цели статьи — описания метода, она не важна. Не?
Вы ещё, судя по всему, оригинальную работу не открывали. Там большинство из того, что я развёрнуто на несколько страниц тут описывал, там — полтора абзаца и отдельные фразы по тексту. И в целом — и не нужно иного, для понимания метода достаточно. Кому нужно — для того список ссылок и гугл…kxx
03.10.2019 14:05Я как раз про оригинальную статью и говорю — там по каждому вопросу буквально пара фраз. Не совсем понятно, как увязали опоры, нагрузки и точки их приложения с этой «картинкой плотностей», как потом определяли, достаточно ли прочна и устойчива конструкция.
Arech Автор
03.10.2019 14:15Понятно. Да, есть такое… и это ещё далеко не самая плохая статья, кстати…
как увязали опоры, нагрузки и точки их приложения с этой «картинкой плотностей», как потом определяли, достаточно ли прочна и устойчива конструкция
Предположу, что положение опоры, приложение нагрузки и прочее просто запрограммировано как частью физ.модели для данной конкретной задачи. Соответственно, прочность, устойчивость и некоторые иные качества будут являться следствиями целевой функции податливости. Большое её значение говорит, что «что-то явно не так», а градиент позволяет двигаться в сторону «более так».
homocomputeris
30.09.2019 01:15В чём отличие от этого (где-то на Хабре был перевод)?
Arech Автор
30.09.2019 10:33Ну, если Вы читали то, на что Вы дали ссылку, то не могли не заметить, что там описаны только волнующие пассы руками вроде: «deep learning… уууу...
blockchaingenerative models… уууу...» а потом так «Вжух!!!» и красивая картинка. И ни малейшей конкретики.homocomputeris
30.09.2019 15:37Это, конечно, правда. Но они, видать, посчитали это ноу-хау и решили не публиковать. Но, очевидно, вот эта новая статья не первый результат подобного рода.
Arech Автор
30.09.2019 16:45А я вот очень в этом неуверен. Дьявол в деталях и что и как там было сделано (если было сделано, чего я всё же не исключаю) может чрезвычайно и принципиально отличаться от подхода, изложенного в описанной работе. Без конкретного описания что и как там делалось писать какие-то умозаключения абсолютно бессмысленно; они не стоят электричества потраченного на их передачу.
Arech Автор
30.09.2019 17:37Ой, я не внимателен.
Они же написали, что основа — генеративные модели. Это совершенно другой инструмент.

DirectX
30.09.2019 10:31Кстати, вот интересное видео, где в числе прочего показано из каких предпосылок разрабатывался дизайн Sagrada Familia и как Гауди обошёлся без нейронных сетей для решения задачи оптимизации: www.youtube.com/watch?v=JlL6ZHChhQE

350Stealth
30.09.2019 12:57+1Интересная статья!
Несколько комментариев по ходу.
Матрица жесткости — это понятие из метода конечных элементов (МКЭ), нахождение которой там является целевой функцией и которая позволяет по заданным граничным условиям (загрузкам, закреплениям) и свойствам материала найти перемещения конечных элементов и деформацию всей конструкции. (Крылов О.В. «Метод конечных элементов»)
Обычно при решении задач оптимизации топологии используется SIMP-метод (Solid Isotropic Material with Penalization), суть которого — для решенной МКЭ-задачи, на основе матрицы напряжений создается матрица условных «плотностей» (матрица вещественных коэффициентов от 0 до 1), которая множится на матрицу жесткости модели. Те элементы, напряжения в которых были близки к 0, получают, соответственно, плотность (для расчета веса) и жесткость (для расчета деформаций) близкую к 0 и из последующего расчета выпадают. После этого МКЭ-задача заново запускается на расчет и т.д. до достижения заданных ограничений.
Собственно алгоритм построения матрицы «плотностей» и был (как я понял) сутью работы из статьи. Обычно используются различные статичные методы преобразования матриц, но здесь авторы решили каждому элементу МКЭ-модели присвоить отдельный нейрон сети и в качестве матрицы «плотностей» использовать весовые коэффициенты самой нейронки. Довольно оригинально, хотя и лежит на поверхности.Arech Автор
30.09.2019 13:04Спасибо за ценные дополнения! Добавлю ссылку на комент в статью.
SIMP-метод (Solid Isotropic Material with Penalization)
Действительно, авторы использовали «modified SIMP» из Andreassen, E., Clausen, A., Schevenels, M., Lazarov, B. S., and Sigmund, O. Efficient topologyoptimization in MATLAB using 88 lines of code.Structural and Multidisciplinary Optimization,43(1):1–16, 2011.
здесь авторы решили каждому элементу МКЭ-модели присвоить отдельный нейрон сети
поправка — выходной нейрон, точнее нейрон последнего слоя.
в качестве матрицы «плотностей» использовать весовые коэффициенты самой нейронки
Нет, веса и вход НС являются лишь параметрами, влияющими на значение выходных нейронов. Если НС представить за чёрный ящик, то его выходом (в данной задаче) являются значения нейронов последнего слоя.350Stealth
30.09.2019 15:04Ясно. Спасибо за разъяснения по поводу использования здесь нейронки. Надо будет внимательней перечитать оригинал :)
По поводу V0 — обычно в SIMP-методах задается Design Space (это вся доступная область модели, из которой потом убираются элементы), объем модели, который должен остаться (обычно в процентах от Design Space, я так понял это и есть V0) и допустимый предел деформаций конструкции, чаще всего в виде максимального перемещения какого-то одного элемента модели. Собственно, Design Space и предельные деформации задаются изначально, а величиной V0 играют, чтобы получить приемлемое соотношение веса (объема) и предельных напряжений.
nickname21
30.09.2019 23:38Действительно, авторы использовали «modified SIMP» из Andreassen, E., Clausen, A., Schevenels, M., Lazarov, B. S., and Sigmund, O. Efficient topologyoptimization in MATLAB using 88 lines of code.Structural and Multidisciplinary Optimization,43(1):1–16, 2011.
Если я не ошибаюсь этот метод впервые пошел с работы 1989 года, или около того от автора Sigmund, и его компании.Ой, сорри, не увидел modified, сам метод СИМП 1989 года.
tabmoo
30.09.2019 13:59Есть такой САПР, SolidThinking Inspire. Используется в индустрии, эффективно решает подобные задачи… Не знаю, какой там алгоритм, давно смотрел.
grigorym
03.10.2019 08:56Можно чуть поподробнее про «дифференцируемый физический движок». Он по чему дифференцируемый?
Arech Автор
03.10.2019 10:56По входам дифференцируемый, очевидно :)
Смотрите, вся эта конструкция (метод) работает, когда существует возможность вычислить градиент целевой функции, т.е. набор значений всех частных производных целевой функции по весам и входу НС. Т.е. иметь возможность для каждого конкретного значения веса/входа вычислить как (на сколько и в какую сторону) изменяется целевая функция в данной точке (пространства весов+входов). Чтобы это сделать, необходимо, чтобы вся цепочка преобразований, ведущая от данного веса до значения целевой функции, была бы дифференцируемой. Конкретно, с точки зрения физической модели это означает, аналогично, что мы должны иметь возможность вычислить, как бы изменялась целевая функция податливости конструкции при изменении любого из элементов, описывающих составные части каркаса. Соответственно, в таком случае физическая модель, позволяющая рассчитать податливость каркаса, будет являться дифференцируемой. Как-то это можно сделать, очевидно, но я не настоящий сварщик в теме вычислительной физики, конкретных деталей далее не скажу, надо разбираться…grigorym
03.10.2019 11:39Вот и я о том. Чем является вход для физического движка? Матрицей/кубом плотностей. Чем является выход движка? Предположим, что скаляром «поддатливости». Стало быть, такой движок кроме скаляра на выходе выдает еще и матрицу/куб производной «поддатливости» по плотности в каждой точке?
Arech Автор
03.10.2019 11:46На эту тему в тексте даже написано. Физ.движок рассчитывает тензор (скорее всего матрица) смещения элементов каркаса под нагрузкой. Далее из него и матрицы жесткости получается скаляр — целевая функция, описывающая податливость всей конструкции.
grigorym
03.10.2019 12:19Попытаюсь ещё раз объяснить. Вы расписали, что на выходе у любого такого движка. У дифференцируемого на выходе еще должна быть и производная/градиент. Производная чего по чему? Производная выхода по входу, так? Выход, по вашим словам — тензор (скорее всего матрица) смещения элементов под нагрузкой. На входе — матрица/куб плотностей. Так что из себя будет представлять производная? Что она описывает? Изменение всего тензора (скорее всего матрицы) при элементарном изменении плотности одного пикселя? Ведь изменение плотности любого из кубиков конструкции влияет на изменение смещения сразу во всей конструкции!
Arech Автор
03.10.2019 13:27Изменение всего тензора (скорее всего матрицы) при элементарном изменении плотности одного пикселя? Ведь изменение плотности любого из кубиков конструкции влияет на изменение смещения сразу во всей конструкции!
Да какое «изменение всего тензора»… Как вы это себе представляете?..
Изменение составляющих тензора же…
Вот пусть есть матричная функция Y=F(X), где X={x_ij} — какая-то матрица и Y={y_kl} какая-то матрица произвольной размерности. Градиент DF представляет собой тензор частных производных каждого значения функции по каждому аргумента { d(y_kl)/d(x_ij) }, т.е. иначе — каждому элементу Y в градиенте соответствует матрица производных этого элемента по каждому из входов, т.е. описание как меняется каждый элемент Y при элементарном изменении каждого элемента Х, полагая остальные элементы аргумента неизменными. — Это же самое обычное определение частной производной функции многих переменных, просто расширенное на случай матриц. Если это не понятно, то надо просто разбираться с понятием частных производных и их обобщениями, потом градиентными методами. Либо я, наверное, по прежнему не понимаю, что не понятно…
sshikov
>максимально допустимых стрессов в материале
Напряжений. Просто напряжений, нет?
Arech Автор
исправил на «напряжений», спасибо. Не знаю устоявшейся терминологии в этой области.