
Любому программисту будет полезно понимание различных структур данных и способов анализа их производительности. Но на практике мне ни разу не пригождались АВЛ-деревья, красно-чёрные деревья, префиксные деревья, списки с пропусками, и т.д. Некоторые структуры данных я использую только для одного конкретного алгоритма и ни для чего больше (например, кучи для реализации очереди с приоритетом в алгоритме поиска пути A*).
В повседневной работе я обычно обхожусь на удивление малым количеством структур данных. Чаще всего мне пригождаются:
- Общие массивы данных (Bulk data) — способ эффективного хранения большого количества объектов.
- Слабые ссылки (Weak reference) (или дескрипторы (handle)) — способ обращения к объектам в bulk data без сбоев программы в случае, если объект удалён.
- Индексы — способ быстрого доступа к отдельным подмножествам в bulk data.
- Массивы массивов — способ хранения объектов bulk data с динамическими размерами.
Я посвящу несколько статей тому, как я обычно реализую все эти структуры. Давайте начнём с простейшей и самой полезной — bulk data.
Bulk Data
Для этого понятия не существует распространённого термина (или я о нём не знаю). Я называю «общим массивом данных» (bulk data) любую большую коллекцию похожих объектов. Например, это могут быть:
- Все пули в игре.
- Все деревья в игре.
- Все монеты в игре.
Или, если вы пишете код на более высоком уровне абстракции, это могут быть:
- Все сущности в игре.
- Все меши в игре.
- Все звуки в игре.
Обычно каждая система (рендеринга, звука, анимаций, физики и т.д.) в игре имеет пару разных типов объектов, которые ей необходимо отслеживать. Например, для системы звука это могут быть:
- Все звуковые ресурсы, которые могут воспроизводиться.
- Все звуки, воспроизводимые в данный момент.
- Все эффекты (затухания, изменения тона и т.п.), применяемые к звукам.
В случае bulk data я буду предполагать следующее:
- Порядок хранения объектов не важен. Т.е. мы воспринимаем массив как множество объектов.
- Каждый объект представлен как простая структура данных (POD-struct) фиксированного размера, которую можно перемещать или дублировать при помощи
memcpy().
Разумеется, можно придумать ситуации, в которых порядок важен. Например, если объекты обозначают элементы для рендеринга, то перед рендерингом нам может понадобиться отсортировать их спереди назад, чтобы снизить объём перерисовки.
Однако я считаю, что в большинстве случаев предпочтительнее сортировать данные так, как они используются, а не хранить данные в сортированном контейнере, таком как красно-чёрные деревья или B-деревья. Например, мы можем отсортировать рендерящиеся объекты спереди назад перед передачей их рендереру, или отсортировать файлы по алфавиту, прежде чем отобразить их на экране списком. Сортировка данных в каждом кадре может казаться затратной, но во многих случаях она выполняется за O(n) при помощи поразрядной сортировки (radix sort).
Поскольку я использую только простые структуры данных, то предпочитаю объектам C++ структуры C, потому что с ними проще понять, что происходит в памяти, и оценивать их производительность. Однако бывают ситуации, когда необходимо хранить в bulk data нечто, не имеющее фиксированного размера. например имя или список дочерних объектов. Я расскажу об этих случаях в отдельном посте, где мы рассмотрим «массивы массивов». Пока давайте предположим, что все объекты являются простыми структурами данных с фиксированным размером.
Например, вот как будут выглядеть структуры bulk data для нашей гипотетической системы звука:
typedef struct {
resource_t *resource; // Resource manager data
uint64_t bytes; // Size of data
uint64_t format; // Data format identifier
} sound_resource_t;
typedef struct {
sound_resource_t *resource; // Resource that's playing
uint64_t samples_played; // Number of samples played
float volume; // Volume of playing sound
} playing_sound_t;
typedef struct {
playing_sound_t *sound; // Faded sound
float fade_from; // Volume to fade from
float fade_to; // Volume to fade to
double fade_from_ts; // Time to start fade
double fade_to_ts; // Time to end fade
} playing_fade_t;При рассмотрении способов хранения bulk data нам нужно учитывать пару целей:
- Добавление и удаление объектов должны быть быстрыми.
- Данные должны быть расположены в удобном для кэширования виде, чтобы можно было быстро выполнять итерации по ним для обновления системы.
- Она должна поддерживать механизм ссылок — необходимо наличие способа передачи информации о конкретных объектах в bulk data. В показанном выше примере fade должен иметь возможность указать, какой именно звук подвергается затуханию. В примере я записал ссылки как указатели, но их реализация зависит от того, как устроены bulk data.
- Данные должны быть дружественными к аллокаторам — они должны использовать несколько крупных распределений памяти, а не распределять отдельные объекты в куче.
Два самых простых способов представления bulk data — это статический массив или вектор C++:
// Static array
#define MAX_PLAYING_SOUNDS 1024
uint32_t num_playing_sounds;
playing_sound_t playing_sounds[MAX_PLAYING_SOUNDS];
// C++ vector
std::vector<playing_sound_t> playing_sounds;Работать с массивом чрезвычайно просто, и он может отлично вам подойти, если точно известно количество объектов, необходимое в приложении. Если вы этого не знаете, то или впустую потратите память, или у вас закончатся объекты.
Вектор
std::vector — это тоже вполне достойное и простое решение, но здесь нужно учитывать некоторые аспекты:- Стандартная реализация
std::vectorиз Visual Studio медленно работает в режиме Debug из-за итераторов отладки. Им стоит присвоить значение _ITERATOR_DEBUG_LEVEL=0. - Для создания и уничтожения объектов
std::vectorиспользует конструкторы и деструкторы, а они в некоторых случаях могут быть значительно медленнее, чемmemcpy(). std::vectorнамного сложнее анализировать, чем реализация простого «растягивающегося буфера» (stretchy buffer).
Кроме того, без дополнительных мер ни обычные массивы, ни векторы не поддерживают ссылки на отдельные объекты. Давайте рассмотрим эту тему, а также другие важные конструктивные решения, участвующие в создании системы bulk data.
Стратегия удаления
Первое важное решение: что нужно делать при удалении объекта
a[i]. Вот три основных варианта:- Можно сместить все последующие элементы
a[i+1]>a[i],a[i+2]>a[i+1], и т.д., для закрытия пустого слота. - Можно переместить последний элемент массива в пустой слот:
a[i] = a[n-1]. - Или можно оставить слот пустым, создав в массиве «дырку». Эту дырку позже можно использовать для размещения нового объекта.
Первый вариант ужасен — на перемещение всех этих элементов тратится O(n). Единственная польза первого метода в том, что если массив отсортирован, то порядок в нём сохраняется. Но как сказано выше, порядок нас не волнует. Учтите, что если вы используете
a.erase() для удаления элемента std::vector, то произойдёт именно это!Второй вариант часто называется «замена и выталкивание» (swap-and-pop). Почему? Потому что если вы используете вектор C++, то этот вариант обычно реализуется заменой (swapping) элемента, который нужно удалить, на последний, с последующим удалением или выталкиванием (popping) последнего элемента:
std::swap(a[i], a[a.size() - 1]);
a.pop_back();Зачем всё это нужно? В C++, если мы выполняем присваивание
a[i] = a[n-1], то сначала должны удалить a[i], вызвав его деструктор, а затем вызываем конструктор копирования для создания копии a[n-1] в позиции i и, наконец, вызываем деструктор a[n-1] при сдвигании вектора. Если конструктор копирования выделяет память и копирует данные, то это может быть довольно плохо. Если использовать вместо присваивания std::swap, то можем обойтись только конструкторами move и не должны выделять память.Повторюсь, именно поэтому C++ я предпочитаю простые структуры данных и операции C. В C++ есть множество ловушек производительности, в которые можно попасть, если не знать, что творится внутри. В C операция swap-erase будет очень простой:
a.data[i] = a.data[--a.n];При использовании swap-and-pop объекты остаются плотно упакованными. Для размещения нового объекта достаточно просто прицепить его к концу массива.
Если же мы используем вариант «с дырками»I, то при размещении нового объекта нам в первую очередь нужно проверить, есть ли какие-нибудь свободные «дырки», которыми можно воспользоваться. Увеличивать размер массива стоит только тогда, когда свободных «дырок» нет. В противном случае в процессе удаления и создания объектов он будет неограниченно разрастаться.
Для отслеживания позиций дырок можно воспользоваться отдельным
std::vector<uint32_t>, но существует решение получше, которое не требует дополнительной памяти.Поскольку данные объекта в «дырке» ни для чего не используются, можно воспользоваться ею для хранения указателя на следующую свободную дырку. Таким образом, все дырки в массиве образуют односвязный список, и при необходимости мы можем добавлять и удалять из него элементы.
Такой вид структуры данных, в которой неиспользуемая память применяется для связывания свободных элементов, обычно называется списком освобождения (free list).
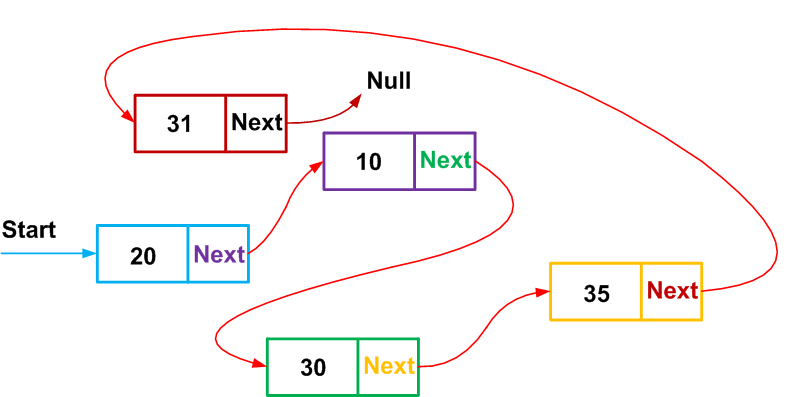
В традиционном связном списке особый элемент заголовка списка указывает на первый узел в списке, а последний элемент списка указывает на NULL, что означает конец списка. Вместо него я предпочитаю использовать кольцевой связный список, в котором заголовок — это просто особый элемент списка, а последний элемент списка указывает на элемент заголовка:
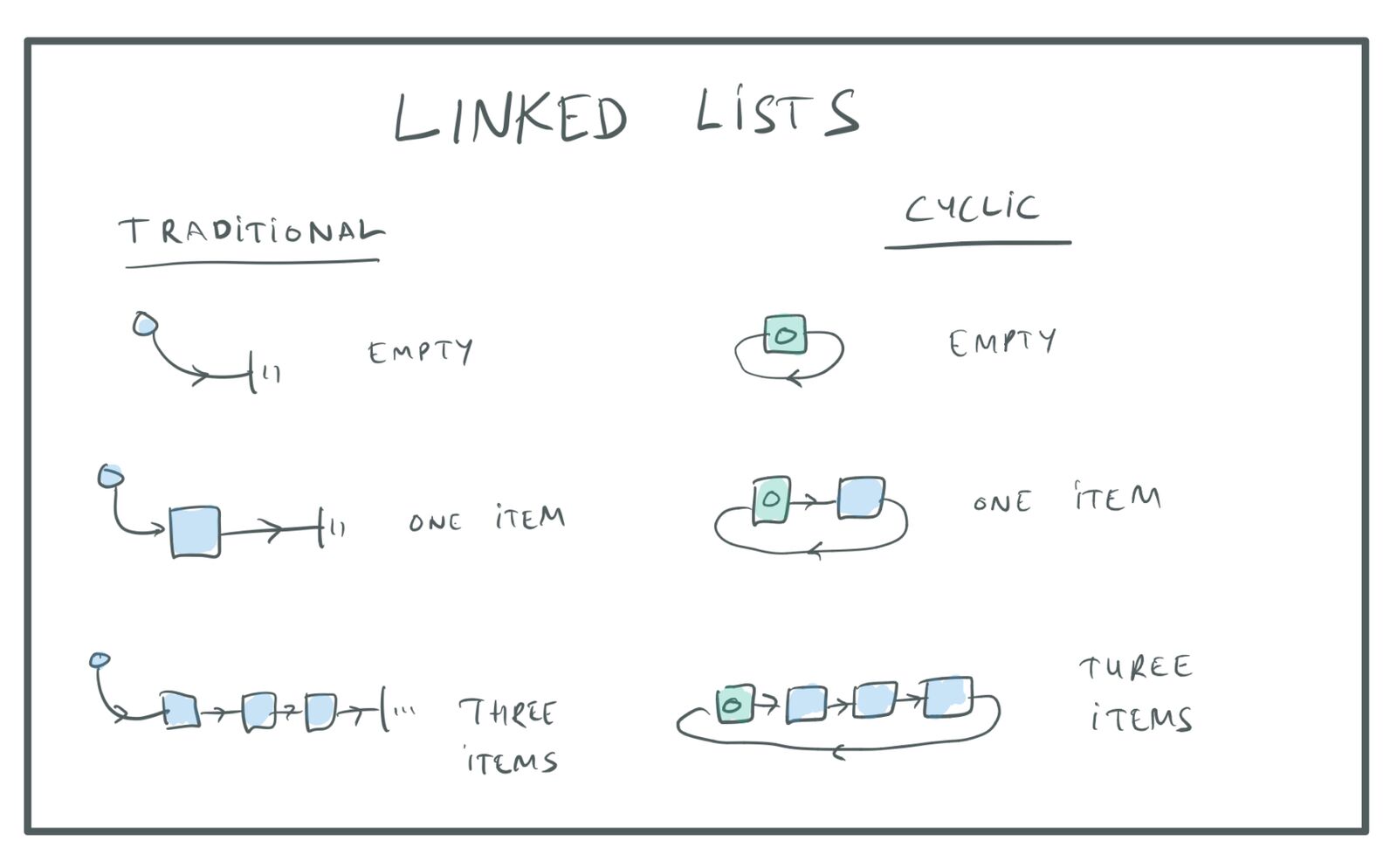
Традиционные и кольцевые связные списки.
Преимущество такого подхода заключается в том, что код становится намного проще благодаря уменьшению количества особых случаев в начале и конце списка.
Учтите, что если использовать для хранения объектов
std::vector, то указатели на объекты будут меняться при каждом перераспределении вектора. Это значит, что мы не можем использовать обычные указатели на связный список, потому что указатели постоянно меняются. Чтобы обойти эту проблему, можно использовать в качестве «указателей» связного списка индексы, поскольку индекс постоянно указывает на конкретный слот даже при перераспределении массива. Подробнее о перераспределении (reallocation) мы поговорим в следующем разделе.Можно выделить место для особого элемента заголовка списка, всегда храня его в слоте массива 0.
При этом код будет выглядеть примерно так:
// The objects that we want to store:
typedef struct {...} object_t;
// An item in the free list points to the next one.
typedef struct {
uint32_t next_free;
} freelist_item_t;
// Each item holds either the object data or the free list pointer.
typedef union {
object_t;
freelist_item_t;
} item_t;
typedef struct {
std::vector<item_t> items;
} bulk_data_t;
void delete_item(bulk_data_t *bd, uint32_t i) {
// Add to the freelist, which is stored in slot 0.
bd->items[i].next = bd->items[0].next;
bd->items[0].next = i;
}
uint32_t allocate_slot(bulk_data_t *bd) {
const uint32_t slot = bd->items[0].next;
bd->items[0].next = bd->items[slot].next;
// If the freelist is empty, slot will be 0, because the header
// item will point to itself.
if (slot) return slot;
bd->items.resize(bd->items.size() + 1);
return bd->items.size() - 1;
}Какая стратегия удаления самая лучшая? Перемещение последнего элемента в пустой слот, обеспечение плотной упаковки массива или сохранение всех элементов на своих местах с созданием «дырок» в массиве на месте удалённого элемента?
Принимая решение, нужно учесть два аспекта:
- Итерация по плотно упакованному массиву выполняется быстрее, потому что мы обходим меньше памяти и нам не нужно тратить лишнее время на пропуск пустых слотов.
- Если мы используем плотно упакованный массив, элементы будут перемещаться. Это значит, что мы не можем использовать индекс элемента как постоянный идентификатор для внешних ссылок на элементы. Нам придётся назначать каждому элементу другой идентификатор и использовать таблицу поиска для сопоставления этих постоянных ID с текущими индексами объектов. Эта таблица поиска может быть хеш-таблицей или вектором
std::vectorс дырками, как описано выше (второй вариант быстрее). Но как бы то ни было, нам потребуется дополнительная память для этой таблицы и лишний косвенный этап для поиска идентификаторов.
Выбор наилучшего варианта зависит от вашего проекта.
Вы можете сказать, что хранение плотно упакованного массива лучше, потому что итерации по всем элементам (для обновления системы) происходят чаще, чем сопоставление внешних ссылок. С другой стороны, можно сказать, что производительность «массива с дырками» хуже только в случае большого количества дырок, а в разработке игр нас обычно волнует производительность в наихудших случаях (мы хотим иметь частоту кадров 60 Гц, даже когда в игре выполняется максимум операций). В наихудшем случае у нас есть максимальное количество реальных объектов, и в этом случае в массиве не будет дырок. Дырки возникают только при снижении количества объектов, когда мы удаляем некоторые из этих объектов.
Также существуют стратегии, которые можно использовать для ускорения обработки массивов со множеством дырок. Например, мы можем отслеживать длины сплошных последовательностей дырок, чтобы за раз пропускать целые последовательности дырок, а не элемент за элементом. Так как эти данные нужны только для «дырок», а не для обычных элементов, можно хранить их вместе с указателем списка освобождения в незанятой памяти объектов и не тратить лишнюю память.
На мой взгляд, если вам не нужно оптимизировать код для быстрых итераций, то скорее всего лучше использовать вариант «массива с дырками». Он более прост, не требует дополнительных структур поиска и в нём можно применять индекс объекта в качестве его ID, что очень удобно. Кроме того, отсутствие перемещения объектов позволяет устранить возможные баги.
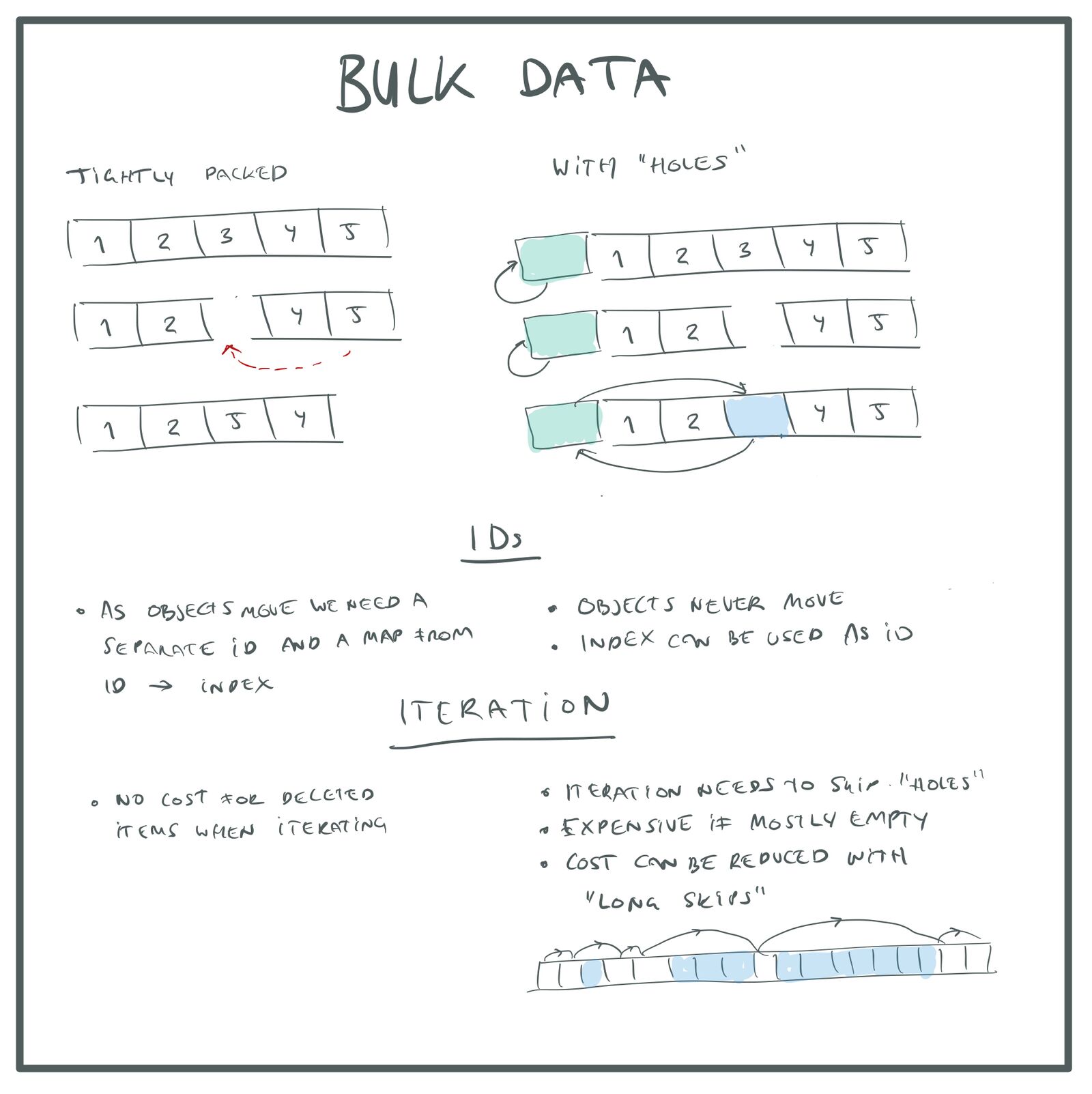
Стратегии удаления Bulk data.
Слабые указатели
В качестве примечания скажу, что можно легко реализовать для объектов bulk data поддержку «слабых указателей» или «дескрипторов».
Слабый указатель (weak pointer) — это ссылка на объект, способная неким образом определять, что объект, на который она ссылается, был удалён. Удобно в слабых указателях то, что они позволяют удалять объекты, не беспокоясь о том, кто на них может ссылаться. Без слабых указателей для удаления объекта нам бы понадобилось искать каждую отдельную ссылку и объявлять её недействительной. Это может быть особенно сложно, если ссылки хранятся в коде скриптов, на других компьютерах в сети и т.д.
Помните, что у нас уже есть ID, уникальным образом идентифицирующий существующие объекты. В варианте «с дырками» этот ID является просто индексом элемента (потому что элементы никогда не перемещаются). В случае плотно упакованных массивов этот индекс объекта является записью в массиве поиска.
Сам по себе ID нельзя использовать в качестве слабого указателя, потому что ID могут использоваться многократно. Если элемент удаляется и в том же слоте создаётся новый элемент, то мы никак не сможем понять это по одному только ID. Чтобы получить слабый указатель, нужно скомбинировать ID с полем
generation («поколение»):typedef struct {
uint32_t id;
uint32_t generation;
} weak_pointer_t;Поле
generation — это поле в struct объекта, отслеживающее, сколько раз был повторно использован слот в массиве bulk data. (В случае с плотной упаковкой он отслеживает, сколько раз был повторно использован слот в массиве поиска.)При удалении элемента мы увеличиваем номер поколения в его слоте. Чтобы проверить, действителен ли ещё слабый указатель, мы проверяем, совпадает ли
generation в struct слабого указателя с поколением слота, обозначенного его id. Если они совпадают, то исходный объект, на который мы ссылаемся, всё ещё существует. Если нет, это означает, что он удалён, а слот или находится в списке освобождения, или был использован повторно.Учтите, что поскольку поле
generation необходимо и для «дырок», и для существующих объектов, нужно хранить его за пределами объединения:typedef struct {
uint32_t generation;
union {
object_t;
freelist_item_t;
};
} item_t;Стратегия распределения
Если для хранения данных элемента вы используете
std::vector, то когда массив заполнится и его нужно будет увеличить, весь массив элементов будет перераспределён. Существующие элементы копируются в новый массив.std::vector увеличивается геометрически. Это значит, что каждый раз, когда вектору нужно увеличиться, количество распределённых элементов умножается на какой-то коэффициент (обычно на ?2). Геометрический (экспоненциальный) рост важен, потому что сохраняет постоянство затрат на увеличение массива.При перераспределении массива нам нужно переместить все элементы, для чего требуется O(n). Однако при увеличении массива мы добавляем место для ещё n элементов, потому что удваиваем размер. Это значит, что нам не нужно будет снова увеличивать массив, пока не добавим в него ещё n элементов. То есть затраты на увеличение равны O(n), но мы выполняем их только на *O(n)*-ный раз записи в массив, то есть в среднем затраты на запись одного элемента равны O(n) / O(n) = O(1).
Затраты на запись элемента называют амортизированной постоянной, потому что если усреднить все выполняемые записи, то затраты окажутся постоянными. Однако нам не стоит забывать, что прежде чем мы усредним, затраты оказываются сильно скачкообразными. Через каждые O(n) записей мы получаем пик высотой O(n):

Затраты на запись в
std::vector.Давайте также посмотрим, что произойдёт, если мы не будем использовать геометрический рост. Допустим, вместо удвоения памяти во время роста мы просто будем добавлять ещё 128 слотов. Перемещение старых данных по-прежнему стоит нам O(n), но теперь его нужно выполнять через каждые 128 добавляемых элементов, то есть усреднённые затраты теперь будут равны O(n) / O(128) = O(n). Затраты на запись элемента в массив пропорциональны размеру массива, поэтому когда массив становится большим, он начинает работать с черепашьей скоростью. Упс!
Стратегия распределения
std::vector — это хороший стандартный вариант, неплохо работающий в большинстве случаев, но у него есть некоторые проблемы:- «Амортизированная постоянная» не очень хорошо подходит для ПО реального времени. Если у вас есть очень большой массив, допустим, в сотни миллионов элементов, то увеличение этого массива и перемещение всех элементов может вызвать заметное торможение частоты кадров. Это проблематично по той же причине, по которой проблематична в играх сборка мусора. Не важно, насколько низки средние затраты, если в некоторых кадрах затраты могут скачкообразно увеличиваться, вызывая глитчи игры.
- Аналогично, эта стратегия распределения в случае больших массивов может впустую тратить много памяти. Допустим, у нас есть массив из 16 миллионов элементов и нужно записать в него ещё один. Это заставит массив увеличиться до 32 миллионов. Теперь у нас есть в массиве 16 миллионов элементов, которые мы не используем. Для платформы с низким объёмом памяти это очень много.
- Наконец, перераспределение перемещает объекты в памяти, делая недействительными все указатели на объекты. Это может стать источником багов, которые сложно отследить.
Показанный ниже код является примером багов, которые могут возникнуть при перемещении объектов:
// Create two items and return the sum of their costs.
float f(bulk_data_t *bd) {
const uint32_t slot_1 = allocate_slot(bd);
item_t *item_1 = &bd->items[slot_1];
const uint32_t slot_2 = allocate_slot(bd);
item_t *item_2 = &bd->items[slot_2];
return item_1->cost + item_2->cost;
}Проблема здесь заключается в том, что функции
allocate_slot() может понадобиться перераспределить массив, чтобы создать место для item_2. В этом случае item_1 будет перемещён в память и указатель на item_1 перестанет быть действительным. В этом конкретном случае мы можем устранить ошибку, переместив присваивание item_1, но подобные баги могут проявляться и более незаметно. Лично меня они кусали много раз.Такая ситуация вероломна ещё и тем, что баг вылезет только тогда, когда перераспределение массива происходит точно в момент распределения
slot_2. Программа долгое время может работать правильно, пока что-нибудь не изменит паттерн распределения, после чего сработает баг.Все эти проблемы можно решить использованием другой стратегии распределения. Вот некоторые из вариантов:
- Мы можем распределить последовательность геометрически растущих буферов: 16, 32, 64, …, но сохранять старые буферы при распределении новых. Например, первые 16 элементов хранятся в одном буфере, следующие 32 элемента в следующем, и т.д… Чтобы отслеживать все эти буферы, мы можем хранить указатели на них в отдельном
std::vector. - Мы можем распределить последовательность буферов фиксированного размера и хранить столько элементов, сколько поместится в каждом буфере. Так как мы можем подбирать размер буферов, то можно сделать их кратными размеру страницы. Благодаря этому они могут распределять память непосредственно из виртуальной памяти и не проходить через кучу. Учтите, что использование фиксированного размера не обеспечивает в этом случае производительности O(n) для
push(), потому что мы никогда не перемещаем старые элементы. - Можно использовать систему виртуальной памяти для резервирования огромного массива, достаточного для хранения максимального количества объектов, которое нам понадобится, и пользоваться только той памятью, которую мы используем.
Повторюсь, каждый метод имеет свои достоинства и недостатки. Последний хорош тем, что элементы по-прежнему хранятся в памяти рядом друг с другом, а нам нужно отслеживать единственный буфер, поэтому не требуются дополнительные векторы или списки. Он требует задать максимальный размер массива, но пространство виртуальных адресов настолько велико, что обычно можно без малейших проблем указать любое огромное число.
Если вы не можете использовать решение с виртуальной памятью, то какой подход будет лучше — фиксированный размер или блоки с геометрическим ростом? Если массив очень мал, то фиксированный размер тратит много лишней памяти. Например, если блок имеет размер 16 тысяч элементов, то вы используете все эти 16 тысяч, даже если в массиве всего один элемент. С другой стороны, при геометрическом росте вы будете впустую тратить память при очень большом массиве, потому что в среднем последний распределённый блок будет заполнен на 50 %. Для большого массива это может быть много мегабайт.
Ещё раз скажу, что в разработке игр важнее оптимизировать код под наихудший случай, поэтому меня не очень волнуют пустые траты памяти на маленькие массивы, если большие массивы всегда демонстрируют хорошую производительность. Общий объём потраченной впустую памяти никогда не будет больше *16 K * n*, где n — количество отдельных массивов bulk data в проекте, и я не считаю, что у нас будет множество различных массивов (всего по несколько штук на каждую систему).
Блоки фиксированного размера имеют и два других преимущества. Во-первых, вычисления для поиска элемента по его индексу выполняется проще, это всего лишь
blocks\[i / elements_per_block\][i % elements_per_block]. Во-вторых, распределение памяти непосредственно из виртуальной памяти намного эффективнее, чем обращение к динамическому распределителю (heap allocator), благодаря отсутствию фрагментации.В заключение хочу сказать, что если вы используете для хранения данных вариант «с дырками», то по-моему стоит отойти от стратегии распределения через
std::vector, чтобы объекты получали постоянные указатели, которые никогда не меняются. Скорее всего наилучшим решением будет большой массив виртуальной памяти, но если вы не можете его реализовать, то вторым по оптимальности вариантом будет последовательность блоков фиксированного размера.Учтите, что поскольку такой подход делает указатели на объекты постоянными, теперь в дополнение к ID мы можем использовать для ссылок на объекты указатели на объекты. Преимущество этого в том, что мы можем получать доступ к объектам напрямую, без выполнения поиска индексов. С другой стороны, указателю нужно 64 бита памяти, а для индекса обычно хватает 32 бит (4 миллиарда объектов — это много).
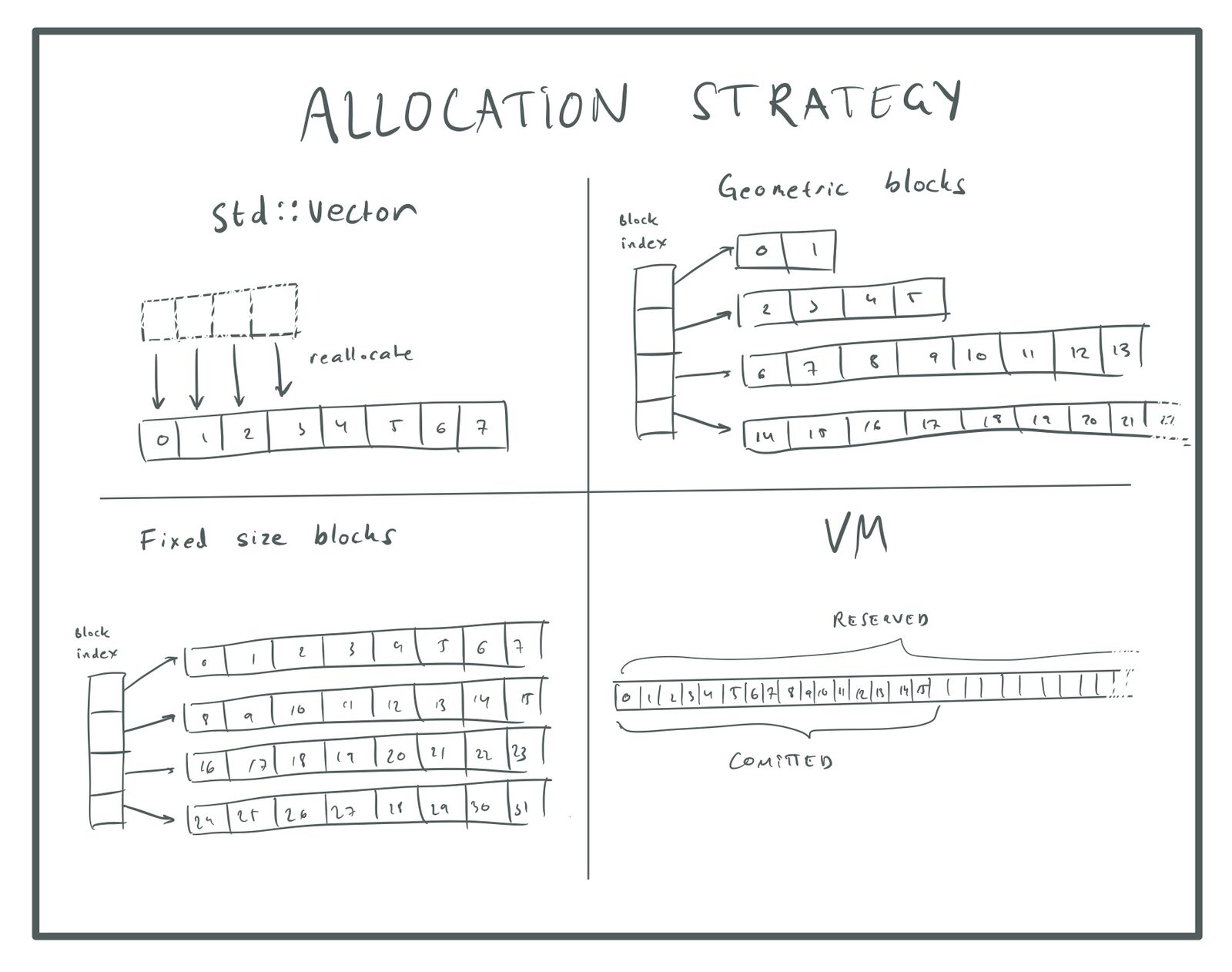
Стратегии распределения
Массив структур и структура массивов
Ещё одним важным конструктивным решением является выбор между массивом структур (Array of Structures, AoS) и структурой массивов (Structure of Arrays, SoA). Разницу лучше показать на примере. Допустим, у нас есть одна система частиц, в которой частицы имеют срок жизни, позицию, скорость и цвет:
typedef struct {
float t;
vec3_t pos;
vec3_t vel;
vec3_t col;
} particle_t;Обычный способ её хранения заключался бы в помещении множества этих struct в массив. Именно поэтому мы называем его «массивом структур». То есть:
uint32_t num_particles;
particle_t *particles;Разумеется, вместо обычного массива можно использовать любую из рассмотренных выше стратегий.
В варианте структуры массивов (SoA) мы использует отдельный массив для каждого поля struct:
uint32_t num_particles;
typedef struct {
float *t;
vec3_t *pos;
vec3_t *vel;
vec3_t *col;
} particles;На самом деле, мы можем пойти ещё дальше, ведь
vec3_t сам по себе является struct:uint32_t num_particles;
typedef struct {
float *t;
float *pos_x;
float *pos_y;
float *pos_z;
float *vel_x;
float *vel_y;
float *vel_z;
float *col_r;
float *col_g;
float *col_b;
} particles;Это кажется намного более сложным, чем наша исходная схема AoS, так зачем же вообще такое нужно? В поддержку такого подхода есть два аргумента:
- Некоторые алгоритмы работают только с подмножеством полей. Например, алгоритм
tick()затрагивает только полеt. Алгоритмsimulate_physics()затрагивает только поляposиvel. В схеме SoA в память загружаются только отдельные части struct. Если мы ограничены памятью (что часто бывает у современных процессоров), то это может оказать большое влияние. Например, функцияtick()будет затрагивать только 1/10 от памяти, а значит, получает ускорение в 10 раз. - Схема SoA позволяет нам загружать данные непосредственно в регистры SIMD для обработки. Это может оказать большое влияние, если мы ограничены FPU. При помощи AVX мы можем обрабатывать по восемь чисел float за раз, что даёт ускорение в 8 раз.
Значит ли это, что с этими ускорениями
tick() станет в 80 быстрее? Нет. Мы получим первое ускорение в 10 раз, только если мы полностью ограничены памятью, а если мы полностью ограничены памятью, SIMD не сможет позволить нам работать быстрее.Недостатки подхода SoA:
- Код становится сложнее.
- Больше давления на распределитель, потому что нам нужно распределить вместо одного целых десять отдельным массивов.
- Мы больше не сможем обращаться к отдельной частице через указатель
particle_t *, потому что поля частицы теперь разбросаны по разным местам. Необходимо обращаться к частице по индексу. - Для доступа к полям частицы по индексу требуется намного больше вычислений, потому что нам нужно выполнять отдельное вычисление индекса для каждого поля
- При обработке одной частицы нам нужно затрагивать данные в большем количестве мест (каждый массив), что может сильнее нагружать кеш. Так ли это будет на самом деле, зависит от специфики архитектуры памяти.
В качестве примера того, какие проблемы могут возникнуть с кешем, вспомните показанную выше struct частиц и представьте, что мы распределили все массивы при помощи VM (то есть они выровнены по границам четырёхкилобайтной страницы). Из-за этого выравнивания все 10 полей struct частиц будут привязаны к одному блоку кеша. Если кеш 8-канальный множественно-ассоциативный, то это значит, что все поля частицы не могут находиться в кеше одновременно. Упс!
Один из способов решения этой проблемы — сгруппировать частицы по размеру вектора SIMD. Например мы можем сделать следующее:
uint32_t num_particles;
typedef struct {
float t[8];
float position_x[8];
float position_y[8];
float position_z[8];
float velocity_x[8];
float velocity_y[8];
float velocity_z[8];
float color_r[8];
float color_g[8];
float color_b[8];
} eight_particles_t;
eight_particles_t *particles;В такой схеме мы по-прежнему можем при помощи SIMD-инструкций обрабатывать одновременно по восемь частиц, но поля одной частицы находятся довольно близко в памяти и у нас не возникает проблем с коллизиями кеш-строк, которые появлялись ранее. Это лучше и для системы распределения, потому что мы снова вернулись к одному распределению на целый массив частиц.
В данном случае алгоритм
tick() затронет 32 байта, пропустит 288 байт, затронет 32 байта и т.д. Это значит, что мы не получим полного 10-кратного ускорения, как в случае с отдельным массивом t. Во-первых, кеш-линии обычно имеют размер 64 байта, и поскольку мы используем только половину, то не можем ускориться больше, чем в 5 раз. Также могут возникнуть затраты, связанные с пропуском байтов, даже если мы будем обрабатывать полные кеш-строки, но на 100% я в этом не уверен.Чтобы решить эту проблему, можно поэкспериментировать с размером группы. Например, можно изменить размер группы на
[16], чтобы одно поле float заполняло кеш-линию целиком. Или, если вы используете метод с распределением блоков, можно просто задать для размера группы любое значение, помещающееся в блок:
AoS и SoA.
Что касается стратегии удаления, то SoA — не лучший выбор для варианта «с дырками», потому что если мы используем SIMD для одновременной обработки восьми элементов, то мы никаким образом не сможем пропустить дырки (если только все восемь элементов не являются «дырками»).
Так как SIMD-инструкции обрабатывают «дырки» так же, как и реальные данные, нам нужно гарантировать, что дырки содержат «безопасные» данные. Например, мы не хотим, чтобы операции с дырками приводили к исключениям в операциях с плавающей запятой или создавали субнормальные числа, снижающие производительность. Также мы не должны больше сохранять указатель
next списка освобождения при помощи объединения, потому что SIMD-операции перезапишут его. Вместо него нужно использовать поле struct.Если мы используем вариант с плотной упаковкой, то удаление будет немного более затратным, потому что придётся перемещать каждое поле по отдельности, а не целую struct за раз. Но так как удаление происходит намного реше, чем обновления, это не составит больших проблем.
Сравнивая AoS и SoA, могу сказать, что в большинстве случаев повышение производительности не стоит возни с написанием более громоздкого кода. Я бы использовал в качестве «стандартного» формата хранения для систем AoS и переходил к SoA в случае систем, требующих скорости SIMD-вычислений, например, систем отсечения и частиц. В таких случаях для достижения максимальной скорости я бы вероятно выбирал плотно упакованные массивы.
Стоит рассмотреть и ещё один вариант — хранение данных в AoS и генерирование временных данных SoA для обработки каким-нибудь алгоритмом. Например, я бы делал один проход по данным AoS и записывал их во временный буфер SoA, обрабатывал этот буфер, а затем записывал результаты обратно как AoS (при необходимости). Поскольку в таком случае я точно знаю алгоритм, который будет обрабатывать эти данные, то могу оптимизировать формат хранения под него.
Учтите, что такой подход хорошо работает с вариантом «хранения блоков». Можно обработать один 16-тысячный блок за раз, преобразовать его в SoA, выполнить алгоритм и записать результаты обратно. Для хранения временных данных понадобится только scratch buffer на 16 тысяч элементов.
Заключение
У любого подхода есть свои достоинства и недостатки, но «по умолчанию» я рекомендую хранить bulk data для новой системы следующим образом:
Массив структур с «дырками» и постоянными указателями, или распределёнными как один большой зарезервированный объём в VM (если это возможно), или как массив блоков фиксированного размера (по 16 тысяч или в размере, оптимально подходящем к вашим данным).
Для случаев, когда нужны очень быстрые вычисления значений для данных:
Структура массивов плотно упакованных объектов, сгруппированных по 8 для обработки SIMD и распределённые как один большой зарезервированный объём в VM или как массив блоков фиксированного размера.
В следующий раз мы рассмотрим тему индексирования этих данных.
Комментарии (14)

dmxvlx
04.10.2019 09:50В своё время, для минимизации времени на аллокации при работе с аудио данными в реальном времени, использовал очереди, и дёргал буферы оттуда:
queue<audio_buffer<float>> in_, out_, free_;
внутри audio_buffer всё тот же std::vector, и даже если стоял фильтр на выход с другим рэйтом, то change capacity происходил два раза: первый при создании аудио-буфера под размер входящих данных(если в очереди свободных не оказывалось ни одного), и второй (И ТО если на выходе имеем бОльший рэйт) уже непосредственно перед ресэмплингом.
И всё нормально работало (после обработки сигнал подавался на аудио выход): без лагов и тормозов, с ресэмплингом и наложением нескольких фильтров.
Если руки растут откуда надо, можно и на векторах запрогить не хуже bulk-data way storage, конечно будет некоторый оверхэд по RAM, но отпадает необходимость ручками выделять/освобождать/ресайзить.
PS: AVL-ки по сравнению с RBtree имеют худшую производительность на вставках/удалении элементов. Префиксные деревья для строковых ключей хороши.
CrazyNiger
04.10.2019 09:51Для этого понятия не существует распространённого термина (или я о нём не знаю). Я называю «общим массивом данных» (bulk data) любую большую коллекцию похожих объектов
Дак это же обычный односвязный список.
PatientZero Автор
04.10.2019 09:57Bulk data — это массив, списком в нём являются только «дырки», непустые элементы ничего друг о друге не знают.

Gorthauer87
04.10.2019 10:49А это разве не примерно то, что находится под капотом у аллокаторов памяти?

nobodyhave
04.10.2019 15:35Но на практике мне ни разу не пригождались АВЛ-деревья, красно-чёрные деревья, префиксные деревья, списки с пропусками, и т.д.
Либо человек делает что-то весьма специфическое, либо он чего-то не знает. В той же Java например TreeMap и TreeSet это красно-черное дерево. Да, не самая часто используемая структура данных, но мне ей приходилось достаточно регулярно пользоваться.
Возможно конечно имеется ввиду дерево написанное самим. Тогда соглашусь.picul
04.10.2019 16:12Вот как раз взвешенное бинарное дерево может понадобиться только в очень специфических случаях, так как есть такая штука как хэш-таблица, против которой у дерева лишь одно преимущество — оно поддерживает отсортированный порядок.
nobodyhave
04.10.2019 17:04Да, об этом я и говорю. Указанные структуры именно что сортированные. И иногда они пригождались именно из-за того, что поддерживали отсортированный порядок.
Еще они будут неплохи в случае, если по какой-то причине нельзя гарантировать хорошую хэш функцию, так как в этом случае хэш таблица может деградировать до O(N), а дерево будет lg(N)picul
04.10.2019 17:59Хмм, ну я вот не вспомню сходу, когда мне важен был именно отсортированный порядок — ИМХО это достаточно редкая ситуация. В общем, пожалуй, каждому свое.
А что имеется в виду под «нельзя гарантировать хорошую хэш-функцию»?dmxvlx
04.10.2019 18:47Время на генерацию хэша для значения ключа и вставки ноды (unordered structure storage — hash based), превышают, или даже равно времени вставки ноды для ordered structure storage.
UPD: Ну или это связано с коллизиями хэша...
nobodyhave
04.10.2019 23:33Ну, достаточно банальный вариант когда у есть необходимость держать сортированный список при постоянных вставках и удалениях.
Про хэш ответили выше. Либо ключи такие, что много коллизий, либо хэш считать долго. Но это еще более редкий случай, сам вживую не сталкивался.
4eyes
04.10.2019 19:37Из относительно недавних применений деревьев:
Union-find: определение пересекаемости множеств. Есть ли у нас общие друзья на фейсбуке?
Binary space partition: быстрый поиск ближайшего объекта на карте.
Правда, это все из разряда поиграться и забить.
SmallSnowball
04.10.2019 22:56В геймдеве стараются избегать мэпов в целом. Не то чтобы они никогда не пригождались, но если что-то можно сделать на массивах/любых других кэш-френдли структурах, это делается на них. Тем более стараются избегать stlных мэпов(которые тоже красночерные), которые на каждую ноду делают аллокацию из кучи (если свой аллокатор не писать)
Static_electro
Если конструкторы и деструкторы "значительно медленнее, чем memcpy()" — это верный признак того, что memcpy() там использовать не получится/нельзя.
Вообще, интересный обзорный пост, только я бы не советовал его считать истиной в последней инстанции в 2019 году.