

Примерно в то же самое время было сделано сообщение о появлении проекта Vulcain. В это сообщение входили такие слова: «TL/DR: GraphQL вам больше не нужен!». И наконец — вышла замечательная статья Марка Ноттингема, посвящённая мощным возможностям HTTP/2, и тому, что эти возможности означают для тех, кто проектирует API. Ссылкой на эту статью поделился со своими подписчиками Даррел Миллер.
Происходящее заставило меня задуматься о GraphQL и об HTTP/2. Если всё вокруг начнёт работать с использованием HTTP/2 (и HTTP/3), будет ли это значить, что у нас не останется причин использовать GraphQL? Вот это мне и хотелось бы сегодня выяснить.
Новшества HTTP/2
Для начала давайте разберёмся с тем, что в технологии HTTP/2 способно повлиять на ценность GraphQL в глазах разработчиков. В HTTP/2 имеется много нового. Это, например, новый бинарный формат и улучшение сжатия заголовков. Но в нашем случае главную роль играет то, как при использовании HTTP/2 обрабатывается доставка запросов и ответов.
Открытие TCP-соединения — это ресурсозатратная операция. Клиенты, использующие HTTP/1, стремятся к тому, чтобы не выполнять её слишком часто. По этой причине, из-за большой дополнительной нагрузки на системы, разработчики часто пытались ограничить число запросов, прибегая к самым разным технологиям. Это, например, выполнение пакетных запросов, использование языков запросов, встраивание CSS/JS-кода в код страниц, использование спрайт-листов вместо отдельных изображений, и так далее. В HTTP/1.1. сделана попытка решить некоторые из этих проблем с использованием постоянных соединений и конвейерной обработки данных. Эти две технологии позволяли браузерам отправлять, в рамках одного соединения, несколько запросов, и получать ответы на них. Недостаток такой схемы обмена данными заключался в том, что она подвержена проблеме блокировки начала очереди (Head-of-line blocking). Эта проблема выражается в том, что один медленный запрос может замедлить обработку всех запросов, следующих за ним. Специалисты, которые занимались работой над HTTP/2, предложили разные способы решения этой проблемы. Вместе с новым бинарным протоколом HTTP/2 представляет и новую стратегию доставки данных. В ходе взаимодействия систем по протоколу HTTP/2 открывается единственное соединение, в рамках которого выполняется мультиплексирование запросов и ответов с использованием нового бинарного уровня, предназначенного для работы с кадрами, когда каждый кадр является частью потока. Клиенты и серверы, при использовании этого механизма, могут воссоздавать потоки запросов и ответов на основе сведений о них, которые есть в кадрах. Это позволяет HTTP/2 очень эффективно поддерживать обработку множества запросов, выполняемых в рамках единственного соединения.
Но это ещё не всё. В HTTP/2 имеется новая концепция, называемая Server Push. Если не вдаваться в детали, то можно сказать, что эта технология позволяет серверам заранее отправлять клиентам данные, выполняя это до того, как клиенты эти данные запрашивают. Наиболее яркие примеры подобного поведения — это заблаговременная отправка клиентам таблиц стилей и JavaScript-ресурсов. В ходе формирования ответа на HTTP-запрос сервер может выяснить, что для рендеринга HTML-страницы нужен некий CSS-файл, и заранее узнать о том, что клиент скоро обратится к нему за этим файлом. Это позволяет серверу отправить клиенту данный файл ещё до того, как клиент его запросит. Именно так работает вышеупомянутый проект Vulcain, используя эту технологию для организации эффективной загрузки связанных ресурсов.
Так, пока всё понятно. Но какое отношение всё это имеет к GraphQL?
GraphQL: один запрос, решающий все проблемы
Технология GraphQL отчасти обязана своей привлекательностью тем, что она помогает разработчикам справляться с недостатками, характерными для HTTP/1-соединений.
Именно поэтому GraphQL позволяет клиентам, за один сеанс связи с сервером, выполнять запросы на получение практически всего чего угодно. Это можно противопоставить Hypermedia-API, при использовании которых обычно нужно выполнять множество сетевых запросов (иногда, правда, ситуацию может улучшить кэширование).
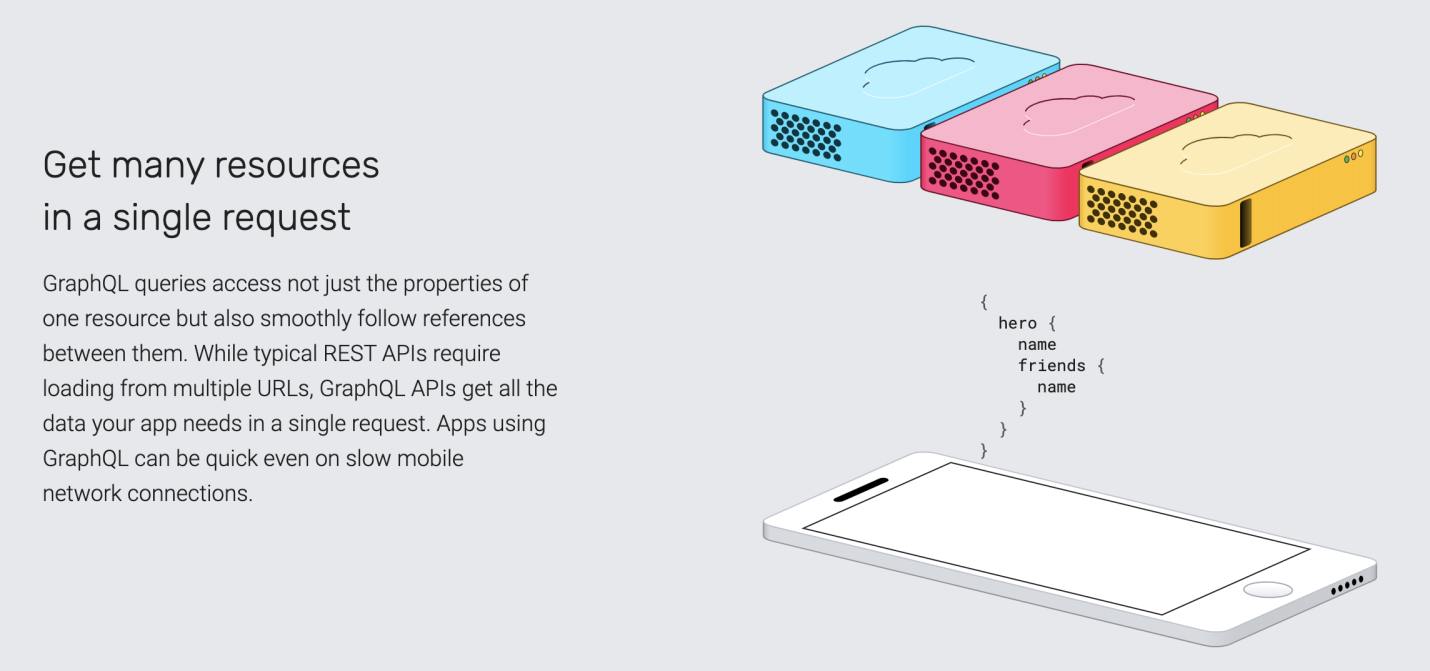
Возможность получения множества ресурсов в рамках единственного запроса — одна из сильных сторон GraphQL, к которой создатели этой технологии привлекают внимание её потенциальных пользователей
Многие из тех, кто говорит о том, что технология GraphQL с приходом HTTP/2 никому больше не нужна, имеют в виду именно эту возможность. Использование пакетных API, языков запросов (таких, как GraphQL), оптимизация отношений, и даже создание укрупнённых конечных точек, выглядят теперь уже не так привлекательно, как раньше. Всё дело в том, что «стоимость» выполнения запросов становится небольшой. И это — чистая правда. Но только ли поэтому мы пользуемся GraphQL? Я так не думаю.
Возможно, дело в том, что сейчас — всё ещё ранние дни HTTP/2-клиентов и некоторых серверных приложений?
Не думаю, что вопрос, вынесенный в заголовок этого раздела, служит достойным объяснением того, что мы всё ещё широко используем GraphQL. Но упомянуть об этом стоит. Использование HTTP/2 на уровне приложения в некоторых экосистемах — задача, которая пока далека от решения. Поищите, например, по словам «Rack/Rails over HTTP/2». Будет интересно. Всё дело в том, что множество серверных частей приложений построены с использованием паттерна запрос/ответ. В результате переход на концепцию потоков HTTP/2 — это не так уж и просто. Особенно — в случае с некоторыми фреймворками. Но это — недостойное оправдание, множество экосистем отлично поддерживают такую схему взаимодействия клиентов и серверов, и, в теории, нам всё ещё стоит стремиться к тому, чтобы усовершенствовать подобное взаимодействие. (Это поддерживает и большинство прокси-серверов, но непросто организовать что-то наподобие отправки данных клиенту по инициативе сервера в том случае, если серверное приложение «застряло» в прошлом, используя паттерн запрос/ответ).
GraphQL — это больше, чем уменьшение времени приёма-передачи данных, или оптимизация объёма передаваемой информации
Хотя уменьшение времени приёма-передачи данных и оптимизация объёма передаваемой информации — это те сильные стороны GraphQL, о которых постоянно приходится слышать, данная технология даёт нам гораздо больше.
Мощь технологии GraphQL заключается в её ориентированности на клиентские системы. Клиент — это та среда, в которой GraphQL идёт на множество компромиссов. В последние годы это многих беспокоило. Так, Даниэль Якобсон 5-7 лет назад написал много хороших статей о некоторых из этих проблем. Вот и вот — пара его публикаций. Он говорит в одной из них: «Наши REST API, хотя они и в состоянии обрабатывать запросы общего характера, не оптимизированы ни под один из подобных запросов».
Обратите внимание на то, что эта мысль справедлива не только в применении к технологии REST. Клиентским приложениям часто приходится выполнять больше запросов к серверу, чем хотелось бы их разработчикам. Приходится этим приложениям и заниматься приёмом от серверов ненужных данных. Это больше относится к проектированию API, которые хорошо было бы создавать так, чтобы они поддерживали бы множество различных вариантов их использования. Обычный способ решения этой проблемы заключается в том, чтобы клиентская логика располагалась бы как можно ближе к серверной логике. Пример такого подхода — клиентские адаптеры Netflix, упомянутые в этом материале 2012 года. С тех пор некоторые команды в Netflix даже перешли на GraphQL. На решение подобных проблем направлен и паттерн BFF.
Технология GraphQL меняет понятие границы между клиентом и сервером, помогая нам создавать серверные системы, способные включать в себя сведения о том, как ими будут пользоваться клиенты. Довольно ярко это проявляется при использовании технологии постоянных запросов, так как тут речь идёт, в сущности, о серверных ресурсах, сгенерированных по инициативе клиента.
При размышлении об актуальности GraphQL в HTTP/2-мире стоит помнить о том, что речь идёт о серверной абстракции. Поддержка различных вариантов использования серверных данных может приводить к проблемам в традиционных API, основанных на конечных точках. GraphQL позволяет тем, кто поддерживает API, сконцентрироваться на том, чтобы дать пользователям этих API широкий набор возможностей. При этом владельцы API могут не беспокоиться о росте нагрузки на существующие клиенты, и о том, что поддержка API значительно усложнится из-за необходимости поддержки множества различных ресурсов. (У поддержки множества различных ресурсов есть свои минусы. Так, подобные схемы усложняют оптимизацию производительности. Такие ресурсы не всегда хорошо поддаются кэшированию. С теми же проблемами сталкиваются и API, поддающиеся серьёзной настройке).
Разработка клиентских систем и GraphQL
В этом материале я, в основном, говорю о серверах, но важно помнить о том, что технологию GraphQL очень любят разработчики клиентов. Если фрагменты GraphQL соединить с компонентным подходом из современных фронтенд-фреймворков, то получится совершенно потрясающая абстракция. И, опять же, если добавить сюда ещё и постоянные запросы, то можно сказать, что GraphQL значительно облегчает жизнь разработчикам клиентских систем.
GraphQL — это целостная система, отличающаяся замечательными возможностями
GraphQL — это не нечто такое, что обладает совершенно уникальными возможностями. У этой системы есть альтернативы. Типизированная схема? То же самое есть и в OpenAPI! Серверные абстракции, поддерживающие разные варианты использования данных клиентами? Это можно реализовать множеством способов. Интроспекция? Использование Hypermedia позволяет клиентам обнаруживать действия и начинать работу с корневой сущности. Восхитительный инструмент GraphiQL? Уверен, нечто подобное создано и для OpenAPI. Возможности GraphQL всегда можно воссоздать, пользуясь другими технологиями. Однако GraphQL — целостная система. Именно это и привлекает к GraphQL столь обширную аудиторию разработчиков, которые с удовольствием этой системой пользуются. Подозреваю, что в этом кроется и одна из причин быстрого распространения и развития GraphQL. Кроме того, так как построение GraphQL-API хорошо документировано, GraphQL-библиотеки, рассчитанные на различные языки, обычно отличаются высоким качеством и популярностью.
Сеть — это всё ещё ограничивающий фактор (а, может быть, так будет всегда?)
Вот ещё одна мысль, на которой я хочу остановиться. Возникает такое ощущение, что сеть, если говорить о работе с API, всегда будет играть роль некоего ограничивающего фактора. При этом неважно то, насколько быстрыми будут сетевые запросы. Именно поэтому мы и не проектируем веб-API так же, как обычные объекты, используемые в разных языках программирования. Здесь, например, идёт речь о том, почему интерфейсы с высоким уровнем детализации не очень подходят для создания систем, рассчитанных на удалённую работу с ними.
В то время как HTTP/2, определённо, поощряет выполнение запросов с высокой детализацией, я думаю, что и здесь приходится идти на определённые компромиссы.
Может ли HTTP/2 помочь GraphQL?
Итак, GraphQL даёт в руки разработчика множество важных и полезных инструментов, но и HTTP/2 — тоже технология замечательная. Давайте посмотрим в будущее и подумаем о том, какие преимущества GraphQL-системы могут извлечь из использования HTTP/2. Например, это может выглядеть так:
query {
viewer {
name
posts(first: 100) @stream {
title
}
}
}Получается, что мы вполне можем пользоваться серверной абстракцией GraphQL, декларативным языком запросов этой технологии, и при этом задействовать возможности HTTP/2-потоков. Я так думаю, что тут используются веб-сокеты. Мне нужно ещё в этом разобраться, но я уверен в том, что многие уже исследуют такие GraphQL-директивы, как
@defer, @stream и @live.Итоги
HTTP/2 — это замечательная технология (а примеры, приведённые, здесь — это просто чудо какое-то). GraphQL можно воспринимать лишь как технологию, уменьшающую число сеансов связи клиента с сервером, или помогающую оптимизировать объёмы передаваемых данных. Если так — тогда тот, кто видит GraphQL с подобной точки зрения, будет вполне счастлив, используя API, основанные на возможностях HTTP/2. Однако если видеть в GraphQL совокупность технологий, дающую разработчику много полезного, то становится ясно, что сила GraphQL совсем не ограничивается улучшением использования сетевых ресурсов и экономией трафика.
Уважаемые читатели! Если вы пользуетесь технологией GraphQL — просим рассказать нам о том, что вам больше всего в ней не нравится.


Комментарии (33)

APXEOLOG
23.10.2019 12:53+1Уважаемые читатели! Если вы пользуетесь технологией GraphQL — просим рассказать нам о том, что вам больше всего в ней не нравится
Конкретно GraphQL:
- Нельзя просто вернуть все поля типа в запросе, нужно их перечислить (привет гора копипасты и регрессии из-за забытых полей при обновлении типа)
- Нет адекватного наследования
- Идеологически не совместим с REST
Плюс у разных имплементаций (например AppSync от AWS) хватает своих проблем сверх этого

i360u
23.10.2019 13:04Согласен с первыми двумя пунктами, но чем плоха несовместимость с REST? Зачем она?
APXEOLOG
23.10.2019 13:14В идеальном мире она не нужна, но в реальном мире это означает, что если вы делаете рефакторинг существующего REST приложения и хотите импользовать GraphQL, то вам по сути нужно выкинуть все что есть и начать с нуля

Pydeg
23.10.2019 15:16+1Нельзя просто вернуть все поля типа в запросе, нужно их перечислить
Это в корне противоречит идее graphql, когда сам клиент говорит серверу что ему сейчас конкретно нужно, но в принципе, возможность получить все поля есть — можно через интроспекцию узнать существующие поля и сформировать запрос. Только зачем? Может сегодня вам и нужны все поля, но завтра добавляется новое поле в схему и уже будет overfetching. А масштабы overfetching'a через какой-нибудь год я боюсь даже представить.
привет гора копипасты
Чтобы избавиться от копипасты существуют Fragments
регрессии из-за забытых полей при обновлении типа
Не совсем понял о чем вы, но если про проблемы версионирования, то лучшая практика версионирования для graphql (и по-моему для любого апи) это когда обновление схемы происходит через добавление, а устаревшее просто депрекейтится, но продолжает работать и ломание обратной совместимости без смены эндпоинта не предполагается, хотя, конечно же, это возможно.APXEOLOG
23.10.2019 15:31Это в корне противоречит идее graphql, когда сам клиент говорит серверу что ему сейчас конкретно нужно
Вот кстати этот конкретно концепт я не считаю безопасным. Потому что клиент (в плохих руках) может попросить больше, чем ему нужно (если он знает названия полей). А на бэкэ делать отдельную фильтрацию — это еще больше накладных расходов к использованю GraphQL
Чтобы избавиться от копипасты существуют Fragments
Насколько я понял, данная фича относится к запросам, а не к типам. Просто возможность описать группу полей одним словом в контексте запроса. Иерархию типов на такой не построить
Ах да, я вспомнил еще один недостаток: input type'ы. Не знаю как у других, но у меня в проекте они применяются при создани объектов и представляют собой точную копию самого типа в 99% случаев. И вот тут бы как раз и пригодилось наследование
Не совсем понял о чем вы
Нет, это когда у вас есть тип и два десятка запросов, включающие его. И при добавлении нового поля в тип нужно не забыть проверить все существующие запросы и убедиться, что там в возврате это поле указано (если оно нужно конечно)
Pydeg
23.10.2019 16:53Потому что клиент (в плохих руках) может попросить больше, чем ему нужно (если он знает названия полей)
В каком смысле больше, чем нужно? Graphql же отдает данные согласно схеме, которую вы описываете и реализовываете, и нельзя запросить больше, чем описано в самой схеме
Иерархию типов на такой не построить
Фрагменты нужны только для клиента, а типы описываются в схеме на сервере и там можно реализовывать наследование типов и любые другие вещи, которые поддерживаются языком программирования.
Ах да, я вспомнил еще один недостаток: input type'ы. Не знаю как у других, но у меня в проекте они применяются при создани объектов и представляют собой точную копию самого типа в 99% случаев. И вот тут бы как раз и пригодилось наследование
Сама схема, как мне кажется, и не должна поддерживать наследование, потому что это больше относится к деталям реализации, и клиента в принципе мало волнует как на сервере это все устроено, у него просто есть input и какой-то output.
Схема чаще всего генерируется на языках программирования (для js, например, это делается с помощью graphql-js, для других языков библиотеки указаны тут), и если язык поддерживает наследование, то там можно наследовать типы как захочется и вообще делать все, что позволяет система типов языка, при этом сама схема для клиента останется «плоской». В нашем проекте мы именно так и делаем, это в том числе позволяет решить и ту проблему, о которой вы написали.
И при добавлении нового поля в тип нужно не забыть проверить все существующие запросы и убедиться
Не понятно, вы о сервере или о клиенте. На сервере в запросах/мутациях всегда возвращается полный тип и дополнительно что-то в них изменять, если в типе добавится поле, не нужно — клиент сразу может запросить это поле из любого места, в котором этот тип используется.
На клиенте же действительно, это поле нужно будет добавлять в запросы, где это необходимо. Логика здесь такая же, как и в отсутствии явной возможности запросить все поля типа — избавиться от overfetching'a. А решить проблему множественных изменений в коде при добавлении нового поля в запросы, опять же, позволяют fragments.bgnx
23.10.2019 20:57В каком смысле больше, чем нужно?
Скорее всего подразумевалось что больше чем нужно для отображения ui. То есть плохой пользователь может вручную собрать н-этажный запрос и отправить на сервер
Чтобы решить эту проблему можно пытаться анализировать вложенность, сложность, ставить таймауты на время запроса но есть куда более простое решение — на этапе сборки фронта вытащить все graphql-запросы и заменить их айдишниками в клиентском коде и загрузить эти запросы на сервер. И тогда клиент просто не сможет построить н-этажный запрос потому что сервер будет принимать только те запросы которые были вытащены из клиентского кода при сборке фронта.
vintage
23.10.2019 22:02все graphql-запросы и заменить их айдишниками в клиентском коде и загрузить эти запросы на сервер
Как такому запросу передать параметры?
bgnx
23.10.2019 23:35Вместе с айдишником запроса. Например если где-то в компоненте нужно загрузить какие-то данные
const projectWithTasks = await gql`{ project(id: ${router.params.id}){ id, name, tasks(archived: ${router.params.archived}){ id, name, completed } } }`
то некий плагин на этапе сборки заменит код выше на примерно такой, сохранив аргументы запроса
const projectWithTasks = await gql("id3433523", router.params.id, router.params.archived)
ну а сервер получив айдишник вытащит нужный запрос и подставит в него переданные аргументы
vintage
24.10.2019 10:59некий плагин
Это мы сейчас фантазируем или это есть в спецификации GQL? Так-то плагин такой можно хоть для SQL запросов сделать. А можно пойти дальше и прямо фигачить JS-код получения данных, который так же выносится на сервер, оставляя на клиенте лишь id ручки.
Впрочем, дебажить такое приложение, где все запросы имеют вид
GET /3433523/473842/true— то ещё удовольствие.bgnx
24.10.2019 16:07Это мы сейчас фантазируем или это есть в спецификации GQL?
Я сам graphql не использую поэтому не в курсе. Просто предлагаю решение которое объективно лучше чем пытаться анализировать вложенность, сложность или ставить таймауты на обработку либо оставлять ддос-дыру когда плохой юзер может сформировать запрос с н-этажный вложенностью и положить сервер
А можно пойти дальше и прямо фигачить JS-код получения данных, который так же выносится на сервер, оставляя на клиенте лишь id ручки.
Вооот, вы все правильно поняли — как только мы имеем возможность написать код на клиенте который будет загружен на бэк то рано или поздно появится мысль — а зачем нам этот ограниченный формат graphql который годится всего лишь для вытаскивания вложенных сущностей для которого все равно нужно будет писать большую часть логики в резолверах (проверку прав, фильтрацию и т.д) если можно сразу написать код любой логики обработки запроса используя удобный орм и этот код на этапе сборки заменится айдишником и будет загружен на сервер. В итоге что graphql что rest становятся лишней абстракцией (или технической деталью не говоря уже про транспорты в виде http с его статус-кодами и кучей способов пробросить данные (url, headers, body) или вебсокетов) на пути к высокоуровневой коммуникации клиента с сервером
Впрочем, дебажить такое приложение, где все запросы имеют вид GET /3433523/473842/true — то ещё удовольствие.
Вообще-то удобство дебага это второстепенная задача, не так часто разработчики будут заниматься дебагом если они будут использовать статическую типизацию которая будет пронизывать код клиента и код внутри бэкенд-обработчиков вместе с орм. Но если все же нужно удобно дебажить то можно передавать данные запроса не через url а внутри тела и там для дев-режима включить передачу кода самого запроса и будет сразу понятно что это за запрос. А поскольку плагин может видеть окружающий код то он также может включить и имя переменной куда этот запрос присваивается или даже ссылку которая сразу откроет редактор в нужном месте. Либо можно вообще написать плагин к девтузлам и там реализовать все возможные удобства
vintage
24.10.2019 18:49Н-этажный запрос составит нерадивый фронтендер, а злоумышленних им просто воспользуется.
Успех протокола HTTP во многом обязан удобству его дебага. А успех REST во многом обязан его независимости от языков и фреймворков.
Kroid
24.10.2019 11:56И graphql превращается… в удалённый вызов процедур. Почему бы тогда сразу какой-нибудь json-rpc не заюзать, зачем эти велосипеды?
APXEOLOG
24.10.2019 09:39Фрагменты нужны только для клиента, а типы описываются в схеме на сервере и там можно реализовывать наследование типов и любые другие вещи, которые поддерживаются языком программирования.
GraphQL типы описываются в GraphQL схеме и никакого отношения к языкам программирования не имеют
Сама схема, как мне кажется, и не должна поддерживать наследование, потому что это больше относится к деталям реализации, и клиента в принципе мало волнует как на сервере это все устроено, у него просто есть input и какой-то output.
Меня, как разработчика серверной части это очень волнует. И мне кажется, что если технологией невозможно пользоваться без копипасты и схемо- и кодо- генераторов, то это как минимум вызывает вопросы
Схема чаще всего генерируется на языках программирования (для js, например, это делается с помощью graphql-js)
Не для всех кейсов подходят схемо-генераторы. Например не думаю, что у вас получится подружить graphql-js и AWS AppSync. Когда приходится писать схему руками — замечаешь указанные мной проблемы.

stealthnsk
23.10.2019 13:06+1Одна из самых больших проблем GraphQL — что он изначально не рассчитан на то, чтобы на сервере работать единым запросом. Это удобно, когда нужно собрать данные из разных источников, но когда нужно получить данные из реляционной БД — начинаются костыли. Есть отдельные библиотеки для того, чтобы собирать SQL-запросы с JOIN на сервере, но они работают через боль. Плюс отсутствие версионирования API из коробки и многие другие ограничения.
Самое смешное, что есть отличный стандарт oData, в котором это реализуется очень удобно.APXEOLOG
23.10.2019 13:17+1А представьте какая боль с NoSQL, когда у вас даже джоинов нет
xDiezz
23.10.2019 15:17+1Пихать всюду NoSQL когда нужно SQL в принципе боль.

babylon
24.10.2019 00:22Нет никакой боли если есть e4x запросы которые могут сгенерировать любой результирующий объект с любыми входящими контекстами. Другое дело что немногие о нём знают. Я знаю потому что механизм был реализован ещё в ActionScript 3. Я не помню такого что бы я не мог нарезать объект из дата провайдеров. Полный обход также доступен. Другое дело как сами данные подстроить под такие запросы. Требуется навык. Но на мой вкус легче в сравнении с SQL и программно управлять такими запросами удобнее даже если заменить ими интерфейсы. Количество лишнего кода будет стремиться к нулю. Я знаю о чём говорю. Обратная задача свёрток тоже решаема. Правда другими способами.
http://xmlhack.ru/texts/07/xquery_abstraction/xquery_abstraction.html
Статья древняя, но правильнаяstealthnsk
24.10.2019 07:42Да, NoSQL не отменяет джойнов, в конце концов он же «Not only» и позволяет получить данные одним запросом. Вопрос в том, насколько это позволяют сделать реализации GraphQL. Тот же сервер Apollo по умолчанию делает отдельные запросы к провайдеру данных для каждого случая.
Pydeg
23.10.2019 15:31что он изначально не рассчитан на то, чтобы на сервере работать единым запросом
Почему? Тут нет никакой разницы с рестом, приходит обычный http-запрос, а дальше в его рамках можно хоть транзакцию в базе данных открывать, хоть распределенную транзакцию.
Есть отдельные библиотеки для того, чтобы собирать SQL-запросы с JOIN на сервере, но они работают через боль
Потому что формировать графовую структуру на JOIN'ах в принципе боль. Вместе с graphql лучше всего dataloader использоватьstealthnsk
24.10.2019 07:51Если писать полностью свою реализацию, то всё просто. Но тогда не получится нормально съэкономить. А вот с готовыми решениями — проблема в том, что они по умолчанию каждую сущность дёргают отдельно.
Dataloader умеет батчинг только если каждый случай явно реализовывать. А без произвольных запросов, смысл GraphQL сильно теряется. Произвольные запросы умеет строить Join Monster, но там есть свои ограничения.
А про графовую структуру на JOIN-ах:
Во-первых, вполне можно. Мы ещё в 2006-ом делали графовую БД на постгресе с использованием рекурсивных запросов.
Во-вторых, GraphQL, не взирая на своё название, всё-таки далеко не только про графы.

RouR
23.10.2019 13:47Поищите, например, по словам «Rack/Rails over HTTP/2». Будет интересно.… В результате переход на концепцию потоков HTTP/2 — это не так уж и просто. Особенно — в случае с некоторыми фреймворками.
А теперь замените слово HTTP/2 на GraphQL

DmitryKoterov
24.10.2019 05:24я уверен в том, что многие уже исследуют такие GraphQL-директивы, как defer, stream и live.
Зря уверены: в Apollo поддержку defer впилили и анонсировали, а потом выпилили. Про остальные и говорить не приходится. А Relay… ну если кто прорвется через него, то вроде бы там тоже «вот-вот будет, но пока не»: https://github.com/facebook/relay/issues/2194#issuecomment-526901224

ganqqwerty
24.10.2019 10:53+1Филя слишком утомился, считая байтики, и за деревьями не увидел леса. Такие технологии как graphql, hateoas, и sparql — это не про то, чтоб все быстро летало и экономится трафик, а про то, чтоб совсем не надо было проектировать API для сервисов. Я вообще раньше не задумывался, что использование graphql может привести к сокращению количества запросов, настолько десятый это вопрос.

{kind=link}
{kind=link}
denis-vc
24.10.2019 18:50Автор не осветил важный аспект, который эксплуатирует новый проект Дангласа. Даже два аспекта:
1) GraphQL запросы делает через Post, что уже некомильфо — нельзя использовать многие стратегии кэширования ответов.
2) много компактных структур данных имеют больше шансов на переиспользование. А значит и кэшировать мелкие ответы более выгодно. HTTP/2 снимает многие аргументы против такой стратегии. И уменьшает смысл в генерации монструозных документов на каждый "специальный случай".denis-vc
24.10.2019 19:18+1Если кто не в курсе, Данглас — автор нового проекта (и спецификации) https://github.com/dunglas/vulcain
А также Mercure и ApiPlatform (который поддерживает и GraphQL и несколько спецификаций классического REST).
Так что в его твитте есть немного желтизны — сам он вовсе не так радикально настроен.
iit
Как по мне, graphql это не столько про скорость и количество запросов а скорее как предоставление унифицированной точки доступа с единым форматом.
Своего рода proxy для api которое может запрашивать и изменять данные в куче разрозненых сервисов.
По сути wsdl нашего времени, но в виде proxy на node.js а не в виде большой ESB торчащей наружу.
JustDont
Вот только это так просто не работает. Пока у вас нет грамотного dsl, описывающего всё то, что можно извлечь через запросы — весь graphQL даёт не больше, чем любой нормальный транспортный формат данных (JSON). А когда у вас есть грамотный dsl, то вы его и на REST спокойно реализуете с тем же успехом.
Не надо думать, что если у вас есть куча разрозненных сервисов, работающих каждый по-своему, то graphql для вас что-то принцпиально изменит сам по себе. Всю унификацию вам так или иначе нужно будет написать руками.
ЗЫ: Я вообще имел дело с внедрением graphql несколько лет назад, и охотно соглашусь с заглавным тезисами статьи — «делать меньше запросов» было очень весомым плюсом graphql, это давало реальный прирост производительности в деле вытягивания данных на фронт и вообще выглядело хорошо. В остальном — большая часть того, что есть в graphql — не появляется там сама по себе только потому, что вы возьмете graphql.
iit
Само собой graphql явно не даст всех плюсов из коробки, нужно прикручивать обработчики руками описывая то что, как и откуда мы тянем и в какой вид приводим, как в прочем и при любом более менее адекватном api
UnnamedUA
node.js — ужас
github.com/hasura/graphql-engine
Karim_Morosov
Чем плох этот репозиторий?