

Небольшой модуль для работы с массивами в Python без использования сторонних библиотек (клон NumPy, но только на чистом Python).
Домашним заданием в университете задали написать программу, которая вычисляет нормы и разложения матрицы, но запретили использовать сторонние библиотеки. В выборе языка программирования не ограничивали. Я выбрал python (что было ошибкой, т.к. он намного медленнее Java и C/C++) и соответственно мне нельзя использовать NumPy. В процессе пришлось написать функции выполнения операций с массивами, функции нахождения миноров, определителя и тд. В итоге получилась мини библиотека для работы с массивами.
Мой код, написанный на чистом питоне намного медленнее NumPy, который производит вычисления на C и Fortran (плюс мой код не оптимизирован).
Что может МатЛОЛ:
- Сумма, разность и произведение матриц
- Произведение матрицы на число
- Транспонирование матрицы
- Минора матрицы
- Определитель матрицы
- Обратная матрица
- Союзная матрица
- Число обусловленности матрицы
- Первая, вторая (не доработана), Евклидова и бесконечная нормы матрицы
- Решение уравнения AX = B
- LU разложение
- Разложение Холецкого
- Метод Зейделя
Примеры использования MathLOL
Импортируем модуль:
# from mathlol import *
from mathlol import mathlol
Инициализация матрицы
matrix = mathlol()
matrix.set([[1, 2, 3],
[4, 5, 6],
[7, -8, 9]])
matrix.get() # Возвращает матрицу
Некоторые операции с матрицами
matrix * 2 # Произведение элементов матрицы на 2
A = [[0, 0, 0],
[0, 1, 0],
[0, 0, 0]]
# Произведение 2 матриц
matrix.dot(A)
matrix * A
matrix.transposition() # Транспонирование матрицы
matrix.minor(i = 0, j = 0) # Минор матрицы
matrix.determinant() # Определитель матрицы
matrix.inverse() # Обратная матрица
L, U = matrix.lu() # LU разложение
matrix.seidel(b = [[5.0], [9.0], [1.0]]) # Метод Зейделя
Так же есть функции для работы с векторами
vector = mathlol()
vector.set([1, 2, 3, 4, 5])
vector.checkvector() # Проверяет, является ли матрица вектором
vector.norm1_vector()
vector.norm2_vector()
vector.norm3_vector()
Другие примеры
Производительность MathLOL
Посмотрим скорость вычислений произведений матриц размера NxN. Матрицы заполнены рандомными целыми числами от -100 до 100.
from mathlol import mathlol
import time
import random
import matplotlib.pyplot as plt
# Создаём набор данных
data = {}
for i in range(10, 110, 10):
array = []
for i_ in range(i):
temp = []
for j_ in range(i):
temp.append(random.randint(-100, 100))
array.append(temp)
data[i] = array
# Производим вычисления и измеряем скорость
mlol_dot = {}
for key in data.keys():
matrix = mathlol()
matrix.set(matrix = data[key])
start = time.process_time()
result = matrix * matrix
end = time.process_time() - start
mlol_dot[key] = end
# Строим график
plt.plot(mlol_dot.keys(), mlol_dot.values())
plt.title("MathLOL \nПроизведение матриц")
plt.xlabel("Размер матрицы (NxN)")
plt.ylabel("Время (сек)")
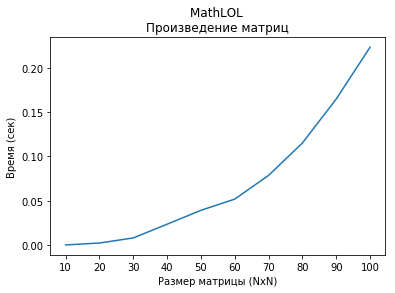
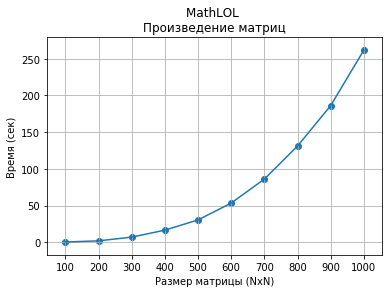
Скорость вычисления произведений матриц размера от 100x100 до 1000x1000
Сравним скорости вычислений numpy и mathlol. К сожалению, mathlol очень сильно уступал в скорости и я решил взять для numpy матрицы размеров от 100x100 до 1000x1000, а для mathlol от 10x10 до 100x100.
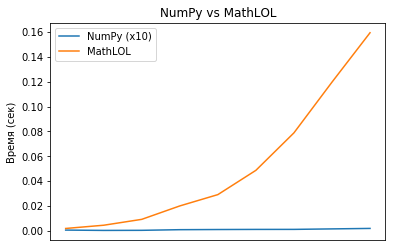
MathLOL вычислил произведение матрицы 100x100 на саму себя за 0.16 секунды, а NumPy вычислил произведение матрицы 1000x1000 на саму себя за 0.002 (!!!) секунды. Разница просто огромная.
У нас стояла задача просто реализовать различные функции для работы с матрицами, что мы и сделали, но программа с большими матрицами работает не так быстро как хотелось бы. Осталось доработать программу, добавить еще несколько функций (например, функция для вычисления числа Тодда), буду признателен если посмотрите код, укажете на ошибки и возможно поможете доработать код.
На этом все, код и примеры выложены на гитхабе.
P.S. В процессе написания статьи мне захотелось поэкспериментировать и встроить в свой модуль C/C++. Займусь этим в ближайшее время и посмотрим насколько удастся приблизиться к производительности NumPy.
Комментарии (21)

trapwalker
27.11.2019 14:19+4А почему вы даже копируете матрицу и то "вручную"? Есть же встроенные методы для этого.
import copy x1 = [[]] x2 = copy.deepcopy(x1) x1[0].append(1) print(x2) # [[]]
Заголовок спойлераdef copy(self, matrix = None): """ Возвращает копию матрицы """ if matrix == None: matrix = self.matrix result = [] if self.checkvector(matrix = matrix): for i in matrix: result.append(i) else: i = len(matrix) j = len(matrix[0]) for i_ in range(i): temp = [] for j_ in range(j): temp.append(matrix[i_][j_]) result.append(temp) return result
ilikeev Автор
27.11.2019 15:00Что вы вообще хотели сказать этой статьёй? Что первая наивная лабораторная на до сих пор незнакомом языке программирования — это хорошая тема для статьи?
Нет, чтобы опытные пользователи указали на ошибки. Преподаватель введёт матрицу максимум 4х4, проверит работу программы и всё, не будет копаться в коде и не укажет ошибки на которые вы указали. Спасибо, исправлю

uchitel
27.11.2019 15:16Конечно же Хабр это торт для избранных профи, а новички пусть собирают крошки :) Суть статьи в том, что человек учится, что-то делает, а ведь мог бы и ерундой заниматься. ЧСВ в статье нет. Возможно, в этой статье нет пользы именно для вас, так же как и для меня она абсолютно бесполезна. Но кому-то она пользу все-таки сможет принести. Впрочем, как и ваш добродушный, сердечный и теплый комментарий :)
trapwalker
27.11.2019 15:39+2В том-то и дело. Я боюсь, что кто-то придёт учиться по этой статье, по этому коду! Ума не приложу зачем я влез в эти каменты. Автор выбрал слишком дорогих репетиторов вместо того, чтобы почитать азы там, где это следовало бы.
На месте препода я бы влепил трояк, честно сказать, особенно если бы узнал про статью. Вообще не понятно о чем тут задание? Автора программировать пытались научить, или с матрицами работать?
Вот действительно, давайте придумаем такого сферического новичка в вакууме, которому эта статья могла бы оказаться полезной и при этом ко всему еще и не вредной. ХЗ.
uchitel
27.11.2019 16:24Ну не знаю. Судя по запросам, по которым ко мне попадают на сайт, «бывалые ребята» моим сайтом вообще не пользуются — идут к офдокам, зато видно что новички даже не понимают, что нужно гуглить. Но ведь все равно гуглят! Что-то типа «как в нампай плющить массивы» или «что такое -1 в a.reshape(5,-1)». А что если кому-то не повезло с преподом, или нет денег на онлайн школу и он вообще самоучка? Я сам был таким самоучкой, который к своему стыду, надо признаться, очень долго боялся именно вот таких комментариев и реакций. А еще я очень долго стремался, того что я всего лишь учитель информатики в начальной школе :) А еще я помню, как в далеком 2013 году пытался найти примеры реализации метода Полларда на Питоне и все что удалось найти это код подобный коду автора данной статьи. Но мне это помогло.
Новички хороши тем, что они имеют все шансы стать лучше нас. Но в том, что нужно поднимать, только тех кто хочет стоять я с вами согласен на все 100% (даже чуть больше, я же все-таки в школе работаю).
Наверное, мне нужно быть чуть строже и наконец-то снять розовые очки, но я ярый фанат фильма «Прирожденные убийцы» :)trapwalker
27.11.2019 17:59+1Пожалуй я тоже был слегка излишне язвителен по отношению к автору. Посыпаю голову пеплом. Но если автор еще разродится подобной статьёй с таким же кодом не потратив даже пару вечеров на чтение Лутца или просто постижение азов питона, то яду будет куда больше.
А так-то парень хоть взял и написал, да оформил, а у меня до сих пор все мои статьи в черновиках шлифуются. Скорее всего истина где-то посередине и лишний перфекционизм — тоже плохо.
uchitel
27.11.2019 14:48+1Картинка улыбнула :)
О Питоне складывается такое впечатление, что все удобное и понятное = очень медленное. Так что, если хочется выжать из него все возможное, то это использование всего, что ближе всего к языку Си, на котором он реализован: генераторы, кортежи, итераторы, слайсы. Однако, тоже самое можно сказать и про нумпу с нумбой. В конечном итоге все упирается в вопрос что важнее скорость разработки или скорость работы программы?
Но обычно все делается именно так как вы и делаете. Сначала быстро пишется прототип, а потом постепенно переводится на Си++ и Кьюду.
Обязательно, поделитесь результатами.trapwalker
27.11.2019 15:29+1все удобное и понятное = очень медленное
Ну вообще-то не всё так однозначно.
В данном случае автор как будто постарался написать на питоне как на C. Это всегда плохая идея — использовать язык не по назначению и не так, как было задумано разработчиками.
В коде рассматриваемой библиотеки всё написано совсем не по-питоновски.
А еще в некоторых случаях производительности питона достаточно, а вот в других языках недостаёт выразительности и простоты. "С" безусловно быстрее, но в нём нет сахара для ООП и прочего, бизнес-логика на нём будет нечитабельной.
Во многих случаях достаточно аккуратно написанного прототипа, чтобы отработать весь (порой не маленький) жизненный цикл приложения. Питон в этом смысле достаточно хорош, если не пытаться на нём делать вещи в которых он не эффективен.
Кстати, есть же еще архитектурные приёмы, которые позволяют разменять производительность на железо за счет масштабирования. Если хорошо написанный питоновский код окажется легче разделить и модифицировать для улучшения масштабируемости, чем хорошо написанный более нативный код на С/С++, то выбор питона уже оправдан, несмотря на в целом меньшую производительность.
Железо дёшево и дешевеет, а программисты, особенно хорошие низкоуровневые очень дороги и не дешевеют.
uchitel
27.11.2019 15:43Честно говоря я вообще как программист не профи. Преподаю информатику в начальной школе:))) Но помнится что-то подобное у Лутца в конце одной из его книг и написано. А может и не у Лутца. Что-то такое читал, но очень давно.

arheops
27.11.2019 17:44А задача Питона и не стоит как «сделать все быстро». Его задача — сделать понятно и, соответственно, удешевить дальнейшую разработку и рефакторинг.
А те части, где критична скорость — переписывают на C или даже ASM. Уже после того, как алгоритм отработан и работает в живом проекте. Собственно упомянутая NumPy из этого и родилась.

iroln
27.11.2019 18:30+2Клон NumPy
Какой же это клон. Где всё это в вашем "клоне"?
- a powerful N-dimensional array object
- sophisticated (broadcasting) functions
- tools for integrating C/C++ and Fortran code
- useful linear algebra, Fourier transform, and random number capabilities
numpy — это титанический труд, а у вас всего лишь несколько операций над матрицами, сделанные в лоб и тяп-ляп. :)
forester11
27.11.2019 18:31Ну, как раз для работы с векторами и матрицами — питон — очень популярная платформа. Особенно сейчас столкнулся с машинным обучением — и там практически вся (начальная) разработка моделей выполняется на питоне + визуализация через Jupyter Notebook + модули к нему. Очень удобненько, этакая замена Excel'у и MatLab'у но с паблик модулями и человеческим синтаксисом. :)
Еще и в Docker впихивается чтобы инженерам удобней было поднять весь эсперимент где требуется.
А потом уже разработанную модель можно грузить в продакшен как удобно — tensorflow можно и напрямую в плюсах поднять. Ну и питон код что подготавливает данные обычно нет проблем воспроизвести в том же С/С++, в сумме все в плюсе (програмистам легко понять и воспроизвести, математикам ненадо заморачиватся проблемами низко-уровневых языков).

diogen4212
28.11.2019 04:26ох уж университетское программирование… хорошо, что не заставили писать код от руки с табличкой внизу (
trapwalker
28.11.2019 11:10Да ладно! Было бы желание. Я в том смысле, что преподы обычно с удовольствием разрешают взять в качестве задания свою собственную тему студента. Да и не важно на каких примерах осваивать профессию, просто если это интересная тема, то она и выполняется с бОльшим желанием.
А вот такие синтетические формальные задания, как мне кажется, получают те, кому не очень-то и интересно то, чему они учатся и у них нет идей поинтереснее.diogen4212
28.11.2019 11:47После того, как я увидел это, пропала вся вера в жизнь и отечественное образование… Мне повезло больше, я хотя бы в университете в 6-ом Билдере на С++ код писал, а тут человек в техникуме учится.
Интерес и цели не всегда формируются во время учёбы… Мне кажется, чтобы точно понять, чем хочешь заниматься и насколько это нравится, нужно где-то поработать по этой специальности хотя бы немного и погрузиться в рутину. Выйти из мира идей, так сказать.trapwalker
28.11.2019 12:39Ну я в детстве тоже писал программы в тетрадочке потому, что не было компьютера дома, а в школе урок информатики и кусочек времени после уроков, когда удавалось дорваться до компов слишком коротки.
Я бы сказал, что интерес — это скорее вопреки всему, хотя, наверно, хороший учитель порой способен пробудить его к своей теме.

nikolay_karelin
28.11.2019 08:32Можно сделать сильно быстрее, если взять модуль array из стандартной библиотеки. Но все-таки еще лучше пользоваться numpy — это почти часть языка, есть несколько встроенных в Python вещей чисто для нужд numpy.


{kind=link}
stepdi
Интересно, насколько list comprehension ускорил бы (много где вижу for — append)
evgenyk
Они практически одинаковы по производительности.