
tl;dr
github.com/QratorLabs/fastenum
pip install fast-enumЗачем нужно перечисление (enum)
(если вы все знаете — опуститесь до секции «Перечисления в стандартной библиотеке»)
Представьте, что вам нужно описать набор всех возможных состояний сущностей в собственной модели базы данных. Скорее всего, вы возьмёте пачку констант, определенных прямо в пространстве имен модуля:
# /path/to/package/static.py:
INITIAL = 0
PROCESSING = 1
PROCESSED = 2
DECLINED = 3
RETURNED = 4
...… или как статические атрибуты класса:
class MyModelStates:
INITIAL = 0
PROCESSING = 1
PROCESSED = 2
DECLINED = 3
RETURNED = 4Такой подход поможет сослаться на эти состояния по мнемоническим именам, в то время как в вашем хранилище они будут представлять собой обычные целые числа. Таким образом вы одновременно избавляетесь от магических чисел, разбросанных по разным участкам кода, заодно делая его более читабельным и информативным.
Однако, и константа модуля, и класс со статическими атрибутами страдают от внутренней природы объектов Python: все они изменяемы (мутабельны). Можно случайно присвоить значение своей константе во время выполнения, а отладка и откат сломанных объектов — отдельное приключение. Так что вы можете захотеть сделать пачку констант неизменяемыми в том смысле, что количество объявленных констант и их значения, на которые они отображаются, не будут изменяться во время выполнения программы.
Для этого вы можете попробовать организовать их в именованные кортежи с помощью
namedtuple(), как в примере:MyModelStates = namedtuple('MyModelStates', ('INITIAL', 'PROCESSING', 'PROCESSED', 'DECLINED', 'RETURNED'))
EntityStates = MyModelStates(0, 1, 2, 3, 4)Но выглядит такое не очень опрятно и читаемо, а объекты
namedtuple, в свою очередь, не очень то расширяемы. Допустим у вас есть UI, отображающий все эти состояния. Вы можете использовать свои константы в модулях, класс с атрибутами или именованные кортежи для их рендеринга (последние два рендерить легче, раз уж об этом зашла речь). Но такой код не дает возможности предоставить пользователю адекватное описание для каждого определенного вами состояния. Помимо этого, если вы планируете внедрить поддержку мультиязычности и i18n в своем UI, вы придете к осознанию, как быстро заполнение всех переводов для этих описаний становятся невероятно утомительной задачей. Совпадение имен состояний не обязательно будет означать совпадение описания, что означает, что вы не сможете просто отобразить все свои INITIAL состояния в одно и то же описание в gettext. Вместо этого ваша константа принимает следующий вид:INITIAL = (0, 'My_MODEL_INITIAL_STATE')Или же ваш класс становится таким:
class MyModelStates:
INITIAL = (0, 'MY_MODEL_INITIAL_STATE')Наконец, именованный кортеж превращается в:
EntityStates = MyModelStates((0, 'MY_MODEL_INITIAL_STATE'), ...)
Уже неплохо — теперь он гарантирует, что и значение состояния и заглушка перевода отображаются на языки поддерживаемые UI. Но вы можете заметить, что код, использующий эти отображения, превратился в бардак. Каждый раз, пытаясь присвоить значение сущности, приходится извлекать значение с индексом 0 из используемого вами отображения:
my_entity.state = INITIAL[0]my_entity.state = MyModelStates.INITIAL[0]my_entity.state = EntityStates.INITIAL[0]И так далее. Помните, что первые два подхода, использующие константы и атрибуты класса, соответственно, страдают от изменяемости.
И вот перечисления приходят к нам на помощь
class MyEntityStates(Enum):
def __init__(self, val, description):
self.val = val
self.description = description
INITIAL = (0, 'MY_MODEL_INITIAL_STATE')
PROCESSING = (1, 'MY_MODEL_BEING_PROCESSED_STATE')
PROCESSED = (2, 'MY_MODEL_PROCESSED_STATE')
DECLINED = (3, 'MY_MODEL_DECLINED_STATE')
RETURNED = (4, 'MY_MODEL_RETURNED_STATE')Вот и все. Теперь вы можете легко перебирать перечисление в вашем рендере (синтаксис Jinja2):
{% for state in MyEntityState %}
<option value=”{{ state.val }}”>{{ _(state.description) }}</option>
{% endfor %}Перечисление является неизменяемым как для набора элементов — нельзя определить новый член перечисления во время выполнения и нельзя удалить уже определенный член, так и для тех значений элементов, которые он хранит — нельзя [пере]назначать любые значения атрибута или удалять атрибут.
В вашем коде вы просто присваиваете значения вашим сущностям, вот так:
my_entity.state = MyEntityStates.INITIAL.valВсе достаточно понятно, информативно и расширяемо. Вот для чего мы используем перечисления.
Как мы смогли сделать его быстрее?
Перечисление из стандартной библиотеки довольно медленное, поэтому мы спросили себя — можем ли мы ускорить его? Как оказалось — можем, а именно, реализация нашего перечисления:
- В три раза быстрее по доступу к члену перечисления;
- В ~8,5 быстрее при доступе к атрибуту (
name,value) члена; - В 3 раза быстрее при доступе к члену по значению (вызов конструктора перечисления
MyEnum(value)); - В 1.5 раза быстрее при доступе к члену по имени (как в словаре
MyEnum[name]).
Типы и объекты в Python являются динамическими. Но существуют и инструменты для ограничения такой динамической природы объектов. Можно получить существенное повышение производительности с помощью
__slots__. Также существует потенциал выигрыша в скорости, если избегать использования дескрипторов данных там, где это возможно — но необходимо учитывать возможность значительного роста сложности приложения.Slots
К примеру, можно использовать объявление класса с помощью
__slots__ — в этом случае все экземпляры классов будут иметь только ограниченный набор свойств, объявленных в __slots__ и всех __slots__ родительских классов.Descriptors
По умолчанию интерпретатор Python возвращает значение атрибута объекта напрямую (при этом оговоримся, что в данном случае значение — это тоже объект Python, а не, например, unsigned long long в терминах языка Си):
value = my_obj.attribute # это прямой доступ к значению атрибута по указателю, который объект хранит для этого атрибута.Согласно модели данных Python, если значение атрибута является объектом, реализующим протокол дескрипторов, то при попытке получить значение этого атрибута интерпретатор сначала разыщет ссылку на объект, на который ссылается свойство, а затем вызовет у него специальный метод
__get__, которому передаст наш исходный объект в качестве аргумента:obj_attribute = my_obj.attribute
obj_attribute_value = obj_attribute.__get__(my_obj)Перечисления в стандартной библиотеке
По меньшей мере свойства
name и value членов стандартной реализации перечислений объявлены как types.DynamicClassAttribute. Это значит что когда вы попытаетесь получить значения name и value произойдет следующее:one_value = StdEnum.ONE.value # это то что вы пишете в коде
# а это то, что произойдет вкратце в действительности
one_value_attribute = StdEnum.ONE.value
one_value = one_value_attribute.__get__(StdEnum.ONE)# и это то, что __get__ делает на самом деле (в реализации python3.7):
def __get__(self, instance, ownerclass=None):
if instance is None:
if self.__isabstractmethod__:
return self
raise AttributeError()
elif self.fget is None:
raise AttributeError("unreadable attribute")
return self.fget(instance)# так как DynamicClassAttribute является декоратором над методами `name` и `value` стек вызовов __get__() заканчивается на:
@DynamicClassAttribute
def name(self):
"""The name of the Enum member."""
return self._name_
@DynamicClassAttribute
def value(self):
"""The value of the Enum member."""
return self._value_Таким образом, вся последовательность вызовов может быть представлена следующими псевдокодом:
def get_func(enum_member, attrname):
# тут на самом деле идет поиск в __dict__, таким образом вычисления хеша и поиск в хеш-таблице тоже имеют место быть
return getattr(enum_member, f'_{attrnme}_')
def get_name_value(enum_member):
name_descriptor = get_descriptor(enum_member, 'name')
if enum_member is None:
if name_descriptor.__isabstractmethod__:
return name_descriptor
raise AttributeError()
elif name_descriptor.fget is None:
raise AttributeError("unreadable attribute")
return get_func(enum_member, 'name')Мы написали простой скрипт демонстрирующий вывод, описанный выше:
from enum import Enum
class StdEnum(Enum):
def __init__(self, value, description):
self.v = value
self.description = description
A = 1, 'One'
B = 2, 'Two'
def get_name():
return StdEnum.A.name
from pycallgraph import PyCallGraph
from pycallgraph.output import GraphvizOutput
graphviz = GraphvizOutput(output_file='stdenum.png')
with PyCallGraph(output=graphviz):
v = get_name()И после выполнения скрипт выдал нам следующую картинку:
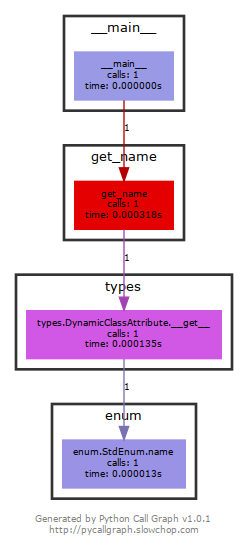
Это показывает, что каждый раз, когда вы обращаетесь к атрибутам
name и value членов перечислений из стандартной библиотеки, вызывается дескриптор. Этот дескриптор, в свою очередь, завершается вызовом из класса Enum из стандартной библиотеки метода def name(self), декорированного дескриптором.Сравните с нашим FastEnum:
from fast_enum import FastEnum
class MyNewEnum(metaclass=FastEnum):
A = 1
B = 2
def get_name():
return MyNewEnum.A.name
from pycallgraph import PyCallGraph
from pycallgraph.output import GraphvizOutput
graphviz = GraphvizOutput(output_file='fastenum.png')
with PyCallGraph(output=graphviz):
v = get_name()Что видно на следующем изображении:
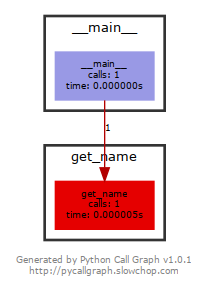
Все это действительно происходит внутри стандартной реализации перечислений каждый раз, когда вы обращаетесь к свойствам
name и value их членов. Это же и причина, по которой наша реализация быстрее.Реализация перечислений в стандартной библиотеке Python использует множество обращений к объектам, реализующим протокол дескрипторов данных. Когда мы попытались использовать стандартную реализацию перечислений в наших проектах, мы сразу же заметили, сколько было вызвано дескрипторов данных у
name и value. А поскольку перечисления использовались довольно обширно по всему коду, результирующая производительность была низкой.
Кроме того, стандартный класс Enum содержит несколько вспомогательных «защищенных» атрибутов:
_member_names_— список, содержащий все имена членов перечисления;_member_map_—OrderedDict, который отображает имя члена перечисления на его значение;_value2member_map_— словарь, содержащий сопоставление в обратную сторону: значения членов перечисления в соответствующие члены перечисления.
Поиск по словарю медленный, поскольку каждое обращение приводит к вычислению хеш-функции (если, конечно, не кешировать результат отдельно, что для неуправляемого кода не всегда возможно) и поиску в хеш-таблице, что делает эти словари не оптимальной основой для перечислений. Даже сам поиск членов перечислений (как в
StdEnum.MEMBER) является поиском по словарю.Наш подход
Свою реализацию перечислений мы создавали с оглядкой на элегантные перечисления в C и прекрасные расширяемые перечисления в Java. Основные функции, которые мы хотели реализовать у себя, были следующими:
- перечисление должно быть как можно более статическим; под «статическим» здесь подразумевается следующее — если что-то может быть вычислено только один раз и во время объявления, то оно должно быть вычислено в этот (и только в этот) момент;
- от перечисления нельзя наследоваться (оно должно быть «конечным» классом), если наследующий класс определяет новые члены перечисления — это верно для реализации в стандартной библиотеке, за тем исключением, что там наследование запрещено, даже если наследующий класс не определяет новых членов;
- перечисление должно иметь широкие возможности для расширения (дополнительные атрибуты, методы и т.д.)
Мы используем поиск по словарю в единственном случае — это обратное отображение значения
value на член перечисления. Все остальные вычисления выполняются только один раз во время объявления класса (где используются метаклассы для настройки создания типов).В отличие от стандартной библиотеки, мы обрабатываем только первое значение после знака
= в объявлении класса в качестве значения члена:A = 1, 'One' в стандартной библиотеке весь кортеж 1, "One" рассматривается как значение value;A: 'MyEnum' = 1, 'One' в нашей реализации только 1 рассматривается как значение value.Дальнейшее ускорение достигается за счет использования
__slots__ где это возможно. В классах Python, объявленных с использованием __slots__ у экземпляров не создается атрибут __dict__, который содержит отображение имен атрибутов на их значения (поэтому вы не можете объявить какое-либо свойство экземпляра, которое не упомянуто в __slots__). Кроме того, доступ к значениям атрибутов, определенных в __slots__, осуществляется по константному смещению в указателе экземпляра объекта. Это высокоскоростной доступ к свойствам, поскольку он позволяет избежать вычислений хеша и сканирования хеш-таблиц.Каковы дополнительные фишки?
FastEnum не совместим ни с какой версией Python до 3.6, поскольку повсеместно использует аннотации типов, внедренные в Python 3.6. Можно предположить, что установка модуля
typing из PyPi поможет. Краткий ответ — нет. Реализация использует PEP-484 для аргументов некоторых функций, методов и указателей на тип возвращаемого значения, поэтому любая версия до Python 3.5 не поддерживается из-за несовместимости синтаксиса. Но, опять же, самая первая строка кода в __new__ метакласса использует синтаксис PEP-526 для указания типа переменной. Так что Python 3.5 тоже не подойдет. Можно перенести реализацию на более старые версии, хотя мы в Qrator Labs, как правило, используем аннотации типов когда это возможно, так как это сильно помогает в разработке сложных проектов. Ну и в конце-концов! Вы же не хотите застрять в Python до версии 3.6, поскольку в более новых версиях нет обратной несовместимости с вашим существующим кодом (при условии, что вы не используете Python 2), а ведь в реализации asyncio была проделана большая работа по сравнению с 3.5, на наш взгляд, стоящая незамедлительного обновления.Именно это в свою очередь делает ненужным специальный импорт
auto, в отличие от стандартной библиотеки. Вы просто даете указание, что член перечисления будет экземпляром этого перечисления, не предоставляя значение вообще — и значение будет сгенерировано для вас автоматически. Хотя Python 3.6 достаточен для работы с FastEnum, имейте в виду, что сохранение порядка следования ключей в словарях было представлено только в Python 3.7 (а мы не стали отдельно для случая 3.6 использовать OrderedDict). Мы не знаем каких-либо примеров, где сгенерированный автоматически порядок значений важен, поскольку мы предполагаем, что, если разработчик предоставил окружению задачу генерации и назначения значения члену перечисления, значит, само по себе значение ему не так уж важно. Тем не менее, если вы все еще не перешли на Python 3.7, мы вас предупредили.Те, кому необходимо, чтобы их перечисления начинались с 0 (нуля) вместо значения по умолчанию (1), могут сделать это с помощью специального атрибута при объявлении перечисления
_ZERO_VALUED, который не будет сохранен в полученном классе.Однако, существуют некоторые ограничения: все имена членов перечисления должны быть написаны ЗАГЛАВНЫМИ буквами, иначе они не будут обработаны метаклассом.
Наконец, вы можете объявить базовый класс для ваших перечислений (имейте в виду, что базовый класс может сам использовать метакласс, поэтому вам не нужно предоставлять метакласс всем подклассам) — достаточно определить общую логику (атрибуты и методы) в этом классе и не определять членов перечисления (так что класс не будет «финализирован»). После можно объявить столько наследующих классов этого класса, сколько захотите, а сами наследники при этом будут иметь общую логику.
Псевдонимы и как они могут помочь
Предположим, что у вас есть код, использующий:
package_a.some_lib_enum.MyEnumИ что класс MyEnum объявлен следующим образом:
class MyEnum(metaclass=FastEnum):
ONE: 'MyEnum'
TWO: 'MyEnum'Теперь, вы решили что хотите сделать кое-какой рефакторинг и перенести перечисление в другой пакет. Вы создаете что-то вроде этого:
package_b.some_lib_enum.MyMovedEnumГде MyMovedEnum объявлен так:
class MyMovedEnum(MyEnum):
passТеперь вы готовы к этапу, на котором перечисление, расположенное по старому адресу, считается устаревшим. Вы переписываете импорты и вызовы этого перечисления так, что теперь используется новое название этого перечисления (его псевдоним) — при этом можно быть уверенными, что все члены этого перечисления-псевдонима на самом деле объявлены в классе со старым названием. В вашей документации о проекте вы объявляете, что
MyEnum устарел и будет удален из кода в будущем. Например, в следующем релизе. Предположим, ваш код сохраняет ваши объекты с атрибутами, содержащими члены перечислений с помощью pickle. На этом этапе вы используете MyMovedEnum в своем коде, но внутренне все члены перечислений по-прежнему являются экземплярами MyEnum. Ваш следующий шаг — поменять местами объявления MyEnum и MyMovedEnum, чтобы MyMovedEnum не был подклассом MyEnum и объявлял все свои члены сам; MyEnum, с другой стороны, теперь не объявляет никаких членов, а становится просто псевдонимом (подклассом) MyMovedEnum.Вот и все. При перезапуске ваших приложений на этапе
unpickle все члены перечисления будут переобъявлены как экземпляры MyMovedEnum и станут связаны с этим новым классом. В тот момент, когда вы будете уверены, что все ваши хранимые, например, в базе данных, объекты были повторно десериализованы (и, возможно, сериализованы опять и сохранены в хранилище) — вы можете выпустить новый релиз, в котором ранее помеченный как устаревший класс MyEnum может быть объявлен более ненужным и удаленным из кодовой базы.Попробуйте сами: github.com/QratorLabs/fastenum, pypi.org/project/fast-enum.
Плюсы в карму идут автору FastEnum — santjagocorkez.
UPD: В версии 1.3.0 стало возможно наследоваться от уже имеющихся классов, например,
int, float, str. Члены таких перечислений успешно проходят проверку на равенство чистому объекту с тем же значением (IntEnum.MEMBER == int(value_given_to_member)) и, само собой, на то, что они являются экземплярами этих унаследованных классов. Это, в свою очередь, позволяет члену перечисления, унаследованного от int, быть прямым аргументом в sys.exit() в качестве кода возврата интерпретатора python. Комментарии (17)

trapwalker
18.12.2019 11:29Можно случайно присвоить значение своей константе во время выполнения, а отладка и откат сломанных объектов — отдельное приключение.
Я всё понимаю, но это уж из разряда злобных буратино. В Питоне много таких мест, где можно «нечаянно» отпилить себе что-нибудь расчёской, не самая большая это, ИМХО, проблема.
Эдак во втором питоне тоже «нечаянно» можно было присвоить:True = False
Хоть на уровне модуля максимум, но тоже «страашененько».
В третьем «слава богу» запретили, вздохнул спокойно=).
Но в целом `Enum` быстрый — это хорошо. Не понятно почему его в штатную библиотеку таким эффективным не включили. С другими типами не выпендривались же.
santjagocorkez
18.12.2019 17:51+1Дополнительно, в отличие от модуля с константами или класса со статическими атрибутами, Enum (даже штатный) решает очень важную задачу, которую иными средствами решить будет затруднительно: через typing и соответствующие синтаксические конструкции языка можно дать разработчику возможность очень строго контролировать что и где меняется. По той простой причине, что никакую другую аннотацию кроме
: intне получится навесить на констату модуля или статический классовый атрибут, если его значение и правда целое число. Как тогда на уровне TYPE_CHECKING хотя бы выводить предупреждения? Enum же можно присваивать "как есть" — то есть,my_obj.obj_attr: StdEnum = StdEnum.ENUM_MEMBER. Поскольку гарантируется, чтоisinstance(StdEnum.ENUM_MEMBER, StdEnum), тайпчекер поймает любые другие значения, кроме членов нашего Enum. А уж доставать значения из члена уже можно "потом", когда объект планируется передать куда-нибудь наружу (то есть, сериализовать). Причем, в нашей реализации pickle уже поддерживается, равно, как и в штатном Enum.

prostomarkeloff
18.12.2019 13:00Ну как-то не знаю. Не думаю, что это будет уж сильно полезно в реальных проектах/библиотеках.


random1st
18.12.2019 18:05Ожидал как минимум сишного расширения, а там текста с комментариями больше, чем кода

iroln
18.12.2019 16:04+1class MyEnum(metaclass=FastEnum): ONE: 'MyEnum' TWO: 'MyEnum'
По-моему, вот эти аннотации для элементов перечисления выглядят неестественно и некрасиво. Понятно, что таким образом вы заменили
auto(), но на самом деле нет. Ваше решение имеет серьёзные недостатки: оно ограниченно и несовместимо с Enum из stdlib.
Что если я хочу в value хранить объекты произвольного типа? Ваше решение умеет хранить только целые числа, более того, вы неявно обрабатываете кортежи в значениях, что выглядит довольно странно. Что если я хочу хранить в значении
NamedTuple? Enum из stdlib может являться субклассом str или int, он может использоваться как комбинация флагов (Flag, начиная с 3.7) и т. д. Вы выбросили всю эту функциональность.
Мне кажется, что более разумно было бы не создавать свой велосипед, которым никто не будет пользоваться кроме вас, а попытаться улучшить и ускорить реализацию Enum в stdlib.
santjagocorkez
18.12.2019 18:09Ваше решение имеет серьёзные недостатки: оно ограниченно и несовместимо с Enum из stdlib.
Полную совместимость с stdlib Enum никто и не обещал. Более того, из синтаксиса применения вполне очевидно, что они несовместимы (у нас реализация предоставляет только метакласс, а в стандартной библиотеке — пачка базовых классов)
Что если я хочу хранить в значении NamedTuple?
In [30]: class C(NamedTuple): ...: name: str ...: age: int ...: In [31]: class B(metaclass=FastEnum): ...: VASYA = C('Vasya', 42), ...: PETYA = C('Petya', 13), ...: In [32]: B.VASYA Out[32]: <B.VASYA: C(name='Vasya', age=42)> In [33]: B.VASYA.value Out[33]: C(name='Vasya', age=42) In [34]: B.VASYA.value.name Out[34]: 'Vasya'
Вы выбросили всю эту функциональность.
Нет, мы ее просто не реализовывали. Список реализованных функций, идентичных тому, что предоставляет стандартная библиотека опубликован. При желании Вы можете через формальное описание логики в init hook написать и свою реализацию mutually exclusive flag-like.
Мне кажется, что более разумно было бы не создавать свой велосипед, которым никто не будет пользоваться кроме вас
Давайте время покажет, будут пользоваться, или нет. Заявлять "никто" только лишь потому, что не реализованы IntEnum и FlagEnum — это равнозначно заявлению, что только и исключительно ими, собственно, и пользуются. А, с учетом того, что все операции так или иначе в них будут проходить через
.value, скорости будут настолько впечатляющими, что лучше уж магическими константами, чем с ними. Enum, который используется сам по себе и то лучше выглядит (в случае, если его.nameи.valueнужны крайне редко). Да я даже тест провел:
In [43]: class F(IntFlag): ...: A = 1 ...: B = 2 ...: C = 3 ...: In [62]: btime = %timeit -o B.PETYA.value.age | B.VASYA.value.age 140 ns ± 0.451 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) In [63]: intflag = %timeit -o F.A | F.B 1.15 µs ± 7.2 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) In [68]: intflag.average / btime.average Out[68]: 8.205303629774782
Как видите, те же 8 раз (это при том, что в моем случае с NamedTuple я еще дополнительно поле кортежа доставал)
Да, каждому пользователю библиотеки некоторую автоматизацию того, что уже предоставляется стандартной библиотекой, придется делать самостоятельно. Вполне вероятно, в нас полетят пулл-реквесты, и, может быть, библиотека пополнится наиболее востребованными дополнениями. Но свою главную задачу наша реализация решает: она быстрая, она позволяет исключить иммутабельность в рантайме, она реализует концепт Enum и, в конце концов, она расширяемая.
iroln
18.12.2019 18:36Хорошо, в вашем Enum можно хранить произвольные типы в value, но я всё равно не понимаю, зачем сделано вот так:
В отличие от стандартной библиотеки, мы обрабатываем только первое значение после знака = в объявлении класса в качестве значения члена:
A = 1, 'One' в стандартной библиотеке весь кортеж 1, "One" рассматривается как значение value;
A: 'MyEnum' = 1, 'One' в нашей реализации только 1 рассматривается как значение value.Какую проблему это решает? Это очень неявно и противоречит принципам pythonic. Насколько я понимаю, 'One' должно записаться в какое-то другое поле, которое надо явно определять через конструктор?
Заявлять "никто" только лишь потому, что не реализованы IntEnum и FlagEnum — это равнозначно заявлению, что только и исключительно ими, собственно, и пользуются.
Я не говорил "только лишь потому", я говорил, что вы позиционируете ваше решение как замену Enum из stdlib, которое работает значительно быстрее, но при этом не покрывает всю функциональность стандартной библиотеки, а также отличается в API. Лично мне, например, нужен IntEnum, чтобы в cli-приложениях использовать returncode, который не нужно явно приводить к int. Мелочь, но приятно. Также удобно использовать флаги с перегруженным оператором
in.
Вы привели пример с медленными флагами, но у вас вообще нет флагов. Поэтому я и написал, что было бы здорово ускорить Enum в stdlib, к тому же, я знаю, что это возможно, потому что такие попытки уже были и даже есть экспериментальный код, который проходит большинство тестов. То есть люди уже задумывались над производительностью Enum, не вы первые обратили на это внимание. Может быть нужно было хотя бы создать issue в багтрекере Python, чтобы привлечь внимание к проблеме?
santjagocorkez
19.12.2019 13:12Это очень неявно и противоречит принципам pythonic. Насколько я понимаю, 'One' должно записаться в какое-то другое поле, которое надо явно определять через конструктор?
Так наоборот же. Explicit > implicit. Если требуется в value хранить кортеж — пишем этот кортеж как единственное значение явно. Если требуется разбить его на поля в членах Enum — описываем это явно. Какой принцип нарушен? Тем более, в документации это описано.
вы позиционируете ваше решение как замену Enum из stdlib
Мы предлагаем более быструю реализацию перечислений, но не утверждали, что предлагаем эквивалентную реализацию, и уж тем более, как совместимую замену штатному.
а также отличается в API
Одно только отсутствие
auto()в таком случае будет приводить к API incompatibility. Но это заявленная несовместимость, не могу понять, что не так?
Может быть нужно было хотя бы создать issue в багтрекере Python, чтобы привлечь внимание к проблеме?
Они в курсе. Только с учетом того, что мы в 3.6 и 3.7 продолжаем испытывать проблемы с производительностью перечислений, они не справились. Их аргумент был — "может поменять public API" (и то, только для предложенного и в итоге принятого патча, что так и не исправило проблему доступа к
nameиvalue). Что ж, нам, в свою очередь, ехать, а не шашечки. Как только тот экспериментальный код будет принят в стандартную библиотеку и окажется либо сопоставимым по скорости с нашим, либо еще быстрее, мы с радостью переползем на него.
Лично мне, например, нужен IntEnum, чтобы в cli-приложениях использовать returncode, который не нужно явно приводить к int.
И, что замечательно, Вы, даже если решите воспользоваться FastEnum, продолжите иметь возможность объявить для int-like штатный Enum, в этом конкретном случае Вас вообще никак не затрагивает его скорость работы (лишняя даже секунда на завершение работы приложения — это пустяки). Тем более Вас вряд ли в этом конкретном Enum будет интересовать какая-либо совместимость с FastEnum на уровне сериализации.
santjagocorkez
19.12.2019 18:38+2Впрочем, это был интересный опыт.
Представляю версию 1.3.0, в которой можно вот так:
class IntEnum(int, metaclass=FastEnum): SYNTAX_ERROR = 1 CONFIG_FORMAT_MISFITS = 2 POLICY_VIOLATION = 3 IntEnum.POLICY_VIOLATION == 3 # True import sys sys.exit(IntEnum.CONFIG_FORMAT_MISFITS) # $? == 2 in bash
Только интами не ограничивается, как минимум, тестировалось на
str,float(в тесткейс внесено)

MrMrRobat
19.12.2019 23:59Посмотрел код, посравнивал со встроенным енумом — имхо, очень сырая имплементация получилась.
Колоссальные отличия в апи от встроенного енума и полное отсутсвие обратной совместимости, ничем немотивированная необходимость использования заглавных имён, отсутствие поддержки наследование от других типов, например, IntEnum.
Пропатчив стандартный Enum можно получить сопоставимые результаты по скорости, сохранив при этом полную совместимость с существующим кодом (выложу как-нибудь такой патч).
Исходя из вышесказанного, я совершенно не понимаю зачем нужна штука, описанная в посте.
Upd. коммент написал до обсуждения с iroln, только сейчас прошел модерацию. Вижу что вроде как добавилась поддержка миксинов, но остальные вопросы остались.
santjagocorkez
20.12.2019 13:12ничем немотивированная необходимость использования заглавных имён
Посмотрите
enum.EnumMeta.__getattr__. Это то самое место, избежав использования которого мы ускорили доступ к члену перечисления в три раза. Плата совсем небольшая: пусть и не обязательное с точки зрения PEP8, но много где применяемое правило писать имена константных атрибутов классов заглавными буквами.
Пропатчив стандартный Enum можно получить сопоставимые результаты по скорости, сохранив при этом полную совместимость с существующим кодом (выложу как-нибудь такой патч).
Только, если можно, сразу в виде PR сюда и ссылкой в это обсуждение. Спасибо.
MrMrRobat
20.12.2019 14:12Посмотрите
enum.EnumMeta.__getattr__. Это то самое место, избежав использования которого мы ускорили доступ к члену перечисления в три раза.Я знаю, за счёт чего вы достигли такую скорость. Только вопрос был про заглавные атрибуты, и я не вижу связи между удалением
__getattr__и необходимостью писать всё с большой буквы.
Только, если можно, сразу в виде PR сюда и ссылкой в это обсуждение. Спасибо.
Хотите PR? Он есть у меня :)
bpo-39102: Increase Enum performance up to 10x times (3x average) #17669 (https://github.com/python/cpython/pull/17669)
Попробовать патч на python можно установив этот пакет: https://github.com/MrMrRobat/fastenum
Пояснение(код отличается от PR, т. к. решил выкинуть вещи, связанные с поддержкой Python <3.6 и DynamicClassAttribute. Наверное всё же приведу к одному виду с PR, как будет время)
Griboks
Покажите, пожалуйста, тесты производительности ваших и нативных перечислений. Слабо верится в такие крутые результаты.
Вы пытались использовать typing.Final? Какая у него производительность? Это стандартная защита от переназначения, которая срабатывает ещё до запуска кода.
Почему вы решили расширить библиотеку, а не препроцессор (аля свой typing.Final), если вам требуется скорость? Согласитесь, что проверить переназначение полей класса перед деплоем или сборкой намного быстрее и эффективнее.
santjagocorkez
Тесты производительности мы описали прямо в README.md в репозитории (в самом конце). Окружение, в котором делались тесты — ipython.
typing.Final, во-первых, нововведение версии 3.8, а, с учетом гарантии (на текущий момент) совместимости с python 3.6, использовать его нет смысла, а во-вторых, даже описание говорит о том, что это все еще не более, чем аннотация типа. В документации по модулю typing так и говорится, что во время выполнения не производится никаких проверок.
Препроцессоры (содержимое модуля typing, и основанные на нем, к примеру, mypy, если я правильно понял) в основной своей массе не являются чем-либо пригодным для работы с ними в runtime. За исключением NamedTuple и TypedDict там, в общем-то, не с чем работать в каком-либо виде, кроме как с аннотациями. А аннотации сами по себе — это те же словари (
type.__annotations__), что небыстро и костыльно. Вдобавок, даже mypy, по слухам, весьма своеобразно поддерживает модуль typing. Ну и, к тому же, за отсутствием typing.Final как такового, мы вряд ли сможем поймать присвоение атрибуту класса (и, тем более, константе модуля) какого-либо значения, которое в остальных аспектах полностью удовлетворяет требованиям аннотации типа. Например:За исключением "финальности", остальные проверки типов ничего плохого в этом не увидят (это как раз беда "мутабельности" в рантайме).
https://github.com/python/cpython/blob/3.8/Lib/typing.py#L415 вот "реализация" Final в cpython 3.8. Патчить тайпчекер любыми способами было бы, на мой взгляд, сильно сложнее, нежели написать то, что мы создали. При этом мы обеспечили действительную иммутабельность в рантайме без необходимости пользователям нашей библиотеки каким-либо образом видоизменять свой деплой.
Griboks
Спасибо. У меня, конечно, получились не такие радужные тесты, но всё-равно быстрее только class fields. Всё-равно не понимаю, зачем делать статические проверки в рантайме.