
Отслеживание соединений (“conntrack”) является основной функцией сетевого стека ядра Linux. Она позволяет ядру отслеживать все логические сетевые соединения или потоки и тем самым идентифицировать все пакеты, которые составляют каждый поток, чтобы их можно было последовательно обрабатывать вместе.
Conntrack — это важная функция ядра, которая используется в некоторых основных случаях:
- NAT опирается на информацию от сonntrack, поэтому он может одинаково обрабатывать все пакеты из одного потока. Например, когда pod обращается к service Kubernetes, балансировщик нагрузки kube-proxy использует NAT для направления трафика на конкретный pod внутри кластера. Conntrack записывает, что для определенного соединения все пакеты к IP service должны отправляться в один и тот же pod, и что пакеты, возвращаемые pod’ом бэкенда, должны быть направлены NAT-ом обратно в pod из которого пришел запрос.
- Firewall’ы с отслеживанием состояния, такие как Calico, опираются на информацию от сonntrack, чтобы добавлять “ответный” трафик в белый список. Это позволяет вам написать сетевую политику, которая говорит: «разрешить моему pod’у подключаться к любому удаленному IP-адресу» без необходимости писать политику для явного разрешения ответного трафика. (Без этого вам пришлось бы добавить гораздо менее безопасное правило «разрешать пакеты в мой pod с любого IP».)
Кроме того, conntrack обычно повышает производительность системы (снижая потребление процессорного времени и время задержек пакетов), поскольку только первый пакет в потоке
должен пройти полную обработку стека сети, чтобы определить, что с ним делать. Смотрите пост «Сравнение режимов kube-proxy», чтобы увидеть пример того, как это работает.
Тем не менее, у conntrack есть свои ограничения...
Итак, где все пошло не так?
Таблица conntrack имеет настраиваемый максимальный размер, и, если она заполняется, соединения обычно начинают отклоняться или прерываться. Для обработки трафика большинства приложений в таблице достаточно свободного места, и это никогда не превратится в проблему. Тем не менее, есть несколько сценариев, при которых стоит задуматься об использовании таблицы conntrack:
- Наиболее очевидный случай, если ваш сервер обрабатывает чрезвычайно большое количество единовременно активных соединений. Например, если ваша таблица conntrack настроена на 128k записей, но у вас есть > 128k одновременных подключений, вы наверняка столкнетесь с проблемой!
- Немного менее очевидный случай: если ваш сервер обрабатывает очень большое количество соединений в секунду. Даже если соединения кратковременные, они продолжают отслеживаться Linux в течение некоторого периода времени (по умолчанию 120с). Например, если ваша таблица conntrack настроена на 128 тыс. записей и вы пытаетесь обработать 1100 подключений в секунду, они будут превышать размер таблицы conntrack, даже если соединения очень недолговечны (128k / 120с = 1092 соединений / с).
Есть несколько нишевых типов приложений, попадающих в эти категории. Кроме того, если у вас много недоброжелателей, то заполнение таблицы conntrack вашего сервера множеством полуоткрытых соединений может использоваться в рамках атаки типа «отказ в обслуживании» (DOS). В обоих случаях conntrack может стать ограничивающим узким местом в вашей системе. В некоторых случаях настройки параметров таблицы conntrack может быть достаточно для удовлетворения ваших потребностей — путем увеличения размера или сокращения тайм-аутов conntrack (но если вы сделаете это неправильно, то столкнетесь с большими трудностями). Для других случаев будет необходимо обойти conntrack для агрессивного трафика.
Реальный пример
Приведем конкретный пример: один крупный SaaS провайдер с которым мы работали имел ряд memcached-серверов на хостах (не виртуальных машинах), каждый из которых обрабатывал 50К+ кратковременных соединений в секунду.
Они экспериментировали с конфигурацией conntrack, увеличивали размеры таблиц и сокращали время отслеживания, но конфигурация была ненадежной, значительно увеличилось потребление ОЗУ, что было проблемой(порядка ГБайтов!), а соединения были настолько короткими что conntrack не создавал своего обычного выигрыша в производительности (уменьшение потребления ЦП или задержек пакетов).
В качестве альтернативы они обратились к Calico. Сетевые политики Calico позволяют не использовать conntrack для определенного вида трафика (используя для политик опцию doNotTrack). Это обеспечило им необходимый уровень производительности плюс дополнительный уровень безопасности, предоставляемый Calico.
На что придется пойти, чтобы обойти conntrack?
- Сетевые политики do-not-track, как правило, должны быть симметричны. В случае SaaS-провайдера: их приложения работали внутри защищаемой зоны и поэтому при помощи сетевой политики они могли добавить в белый список трафик от других конкретных приложений, которым разрешался доступ к memcached.
- Политика do-not-track не учитывает направление соединения. Таким образом, в случае взлома memcached-сервера с него теоретически можно попытаться подключиться к любому из memcached-клиентов, если он использует правильный исходный порт. Однако, если вы корректно определили сетевую политику для своих клиентов memcached, то эти попытки подключения все равно будут отклонены на стороне клиента.
- Политика do-not-track применяется к каждому пакету, в отличие от обычных политик, которые применяются только для первого пакета из потока. Это может увеличить расход ресурсов CPU на один пакет, так как для каждого пакета нужно применять политику. Но для кратковременных соединений этот расход уравновешивается сокращением расхода ресурсов на обработку conntrack. Для примера, в случае SaaS провайдера, количество пакетов для каждого соединения было очень небольшим, поэтому дополнительный расход ресурсов CPU при применении политик к каждому пакету был оправдан.
Приступим к тестам
Мы проводили тест на одном pod'е с memcached-сервером и множеством pod'ов memcached-клиентов, запущенных на удаленных нодах, так что бы мы могли запускать очень большое количество соединений в секунду. Сервер с pod'ом memcached-сервера имел 8 ядер и 512k записей в conntrack таблице (стандартно настроенный размер таблицы для хоста).
Мы измеряли разницу в производительности между: без сетевой политики; с обычной Calico политикой; и Calico do-not-track политикой.
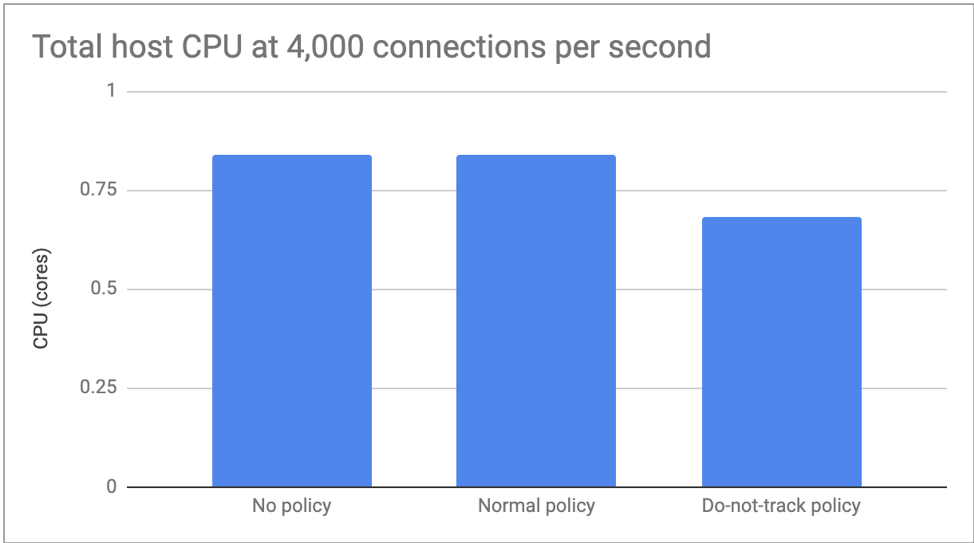
Для первого теста мы задали количество коннектов до 4.000 в секунду, поэтому мы могли сфокусироваться на разнице потребления CPU. Здесь не было существенных отличий между отсутствием политики и обычной политики, но do-not-track увеличила потребление CPU примерно на 20% :
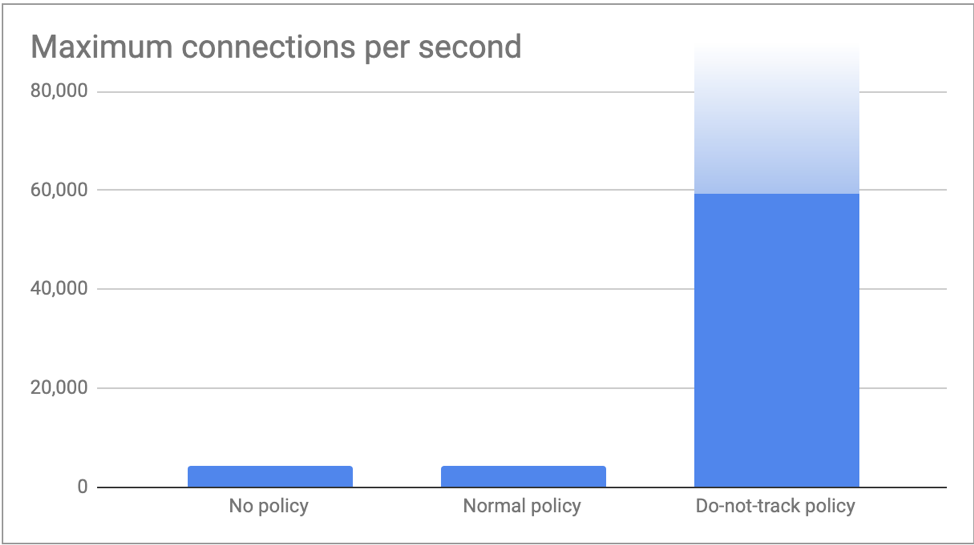
Во втором тесте мы запустили столько соединений, сколько могли сгенерировать наши клиенты и измеряли максимальное количество соединений в секунду, которое мог отработать наш memcached-сервер. Как и ожидалось, в случае “без политик” и “обычная политика” оба достигли лимита conntrack в более чем 4,000 соединений в секунду (512k / 120s = 4,369 соединений/с). С do-not-track политикой наши клиенты отправляли 60,000 соединений в секунду без каких-либо проблем. Мы уверены, что могли бы увеличить это число, подключив большее количество клиентов, но чувствуем, что этих цифр уже достаточно, чтобы проиллюстрировать посыл этой статьи!
Заключение
Conntrack — это важная функция ядра. Он отлично выполняет свою работу. Зачастую его используют ключевые компоненты системы. Однако, в некоторых определенных сценариях, перегрузка из-за conntrack перевешивает обычные преимущества, которые он дает. В данном сценарии сетевые политики Calico могут быть использованы, чтобы выборочно отключать использование conntrack при этом повышая уровень сетевой безопасности. Для всего остального трафика conntrack продолжает быть вашим товарищем!


amarao
Да. Контрек дорого. Особенно, в ядре. Потому у нас и есть conntrackd. Но state — всё равно дорого и никуда вы от этого не денетесь.
Tangeman
conntrackd тут ничем не помогает — его единственная функция — репликация состояний в кластере файрволлов, он не может больше чем может сам netfilter в ядре. Ещё умеет делать flush и статистику — всё.
amarao
Он лучше в том смысле, что просмотр статистики не фризит трафик (как в случае попытки посмотреть в ядерные proc-файлы для conntrack).
А стейт — дорого. У всех. Даже у топовых srx'ов есть вполне себе лимиты на число wing (половинка flow).