
Привет, Хабр! Меня зовут Максим Васильев, я работаю аналитиком и менеджером проектов в FINCH. Сегодня я хотел бы рассказать, как с помощью ElasticSearch, мы смогли обработать 15 млн запросов за 6 минут и оптимизировать ежедневные нагрузки на сайте одного из наших клиентов. К сожалению, придётся обойтись без имён, так как у нас NDA, надеемся, что содержание статьи от этого не пострадает. Let`s go.
На нашем бэкенде мы создаем сервисы, которые обеспечивают работоспособность сайтов и мобильного приложения нашего клиента. Общую структуру можно увидеть на схеме:
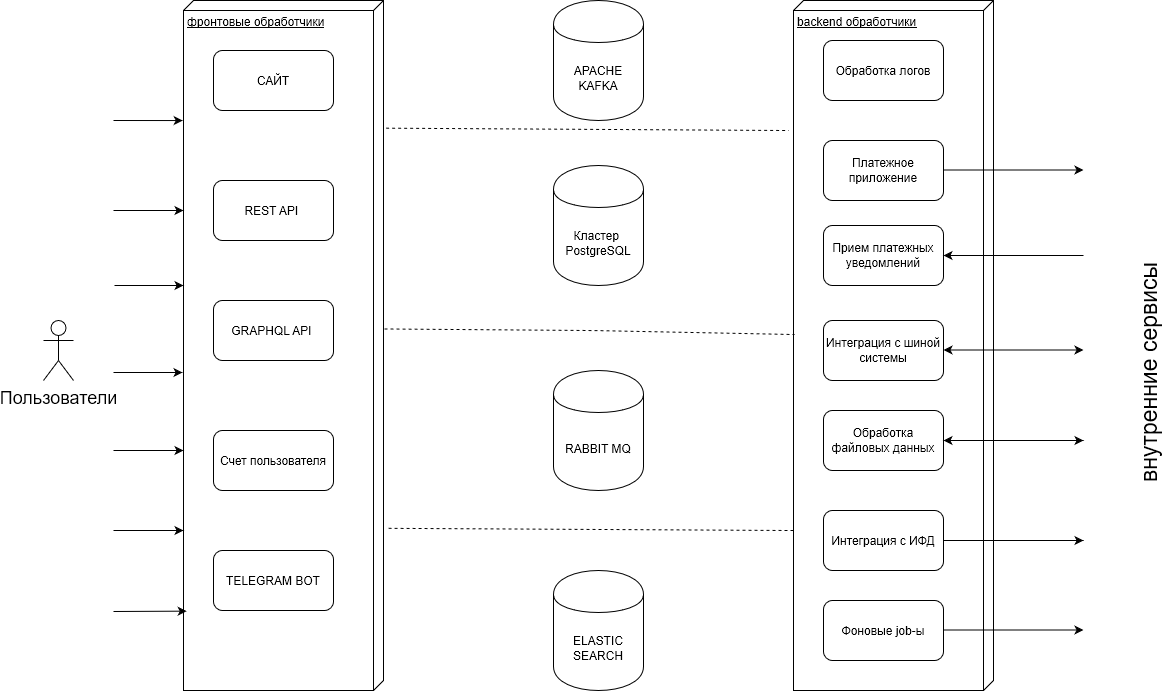
В процессе работы мы обрабатываем большое кол-во транзакций: покупок, выплат, операций с балансами пользователей, по которым храним много логов, а также импортируем и экспортируем эти данные во внешние системы.
Также идут и обратные процессы, когда мы получаем данные от клиента и передаем их пользователем. Помимо этого еще существуют процессы по работе с платежами и бонусными программами.
Изначально в качестве единственного хранилища данных мы использовали PostgreSQL. Его стандартные для СУБД преимущества: наличие транзакций, развитый язык выборки данных, широкий инструментарий для интеграции; в сочетании с хорошей производительностью довольного долго удовлетворяли наши потребности.
Мы хранили в Postgres абсолютно все данные: от транзакций до новостей. Но количество пользователей росло, а вместе с ним и количество запросов.
Для понимания, годовое количество сеансов в 2017 году только на десктопном сайте — 131 млн. За 2018 — 125 млн. 2019 снова 130 млн. Добавьте туда еще 100-200 млн от мобильной версии сайта и мобильного приложения, и вы получите колоссальное количество запросов.
С ростом проекта, Postgres перестал справляться с нагрузкой, мы не успевали — появилось большое количество разнообразных запросов, под которые мы не смогли создать достаточное количество индексов.
Мы понимали, что есть необходимость в других хранилищах данных, которые бы обеспечили наш потребности и сняли нагрузку с PostgreSQL. В качестве возможных вариантов рассматривали Elasticsearch и MongoDB. Последний проигрывал по следующим пунктам:
Так мы выбрали для себя Elastic и приготовились к переходу.
1. Мы начали переход с сервиса поиска точек продаж. У нашего клиента суммарно есть около 70 000 точек продаж, и при этом требуется несколько типов поиска на сайте и в приложении:
Если говорить по организацию, то в Postgres у нас лежит источник данных как по карте, так и по новостям, а в Elastic делаются Snapshot’ы от оригинальных данных. Дело в том, что изначально Postgres не справлялся с поиском по всем критериям. Мало того, что было много индексов, они могли еще и пересекаться, поэтому планировщик Postgres терялся и не понимал какой индекс ему использовать.
2. Следующий на очереди был раздел новостей. На сайте каждый день появляются публикации, чтобы пользователь не потерялся в потоке информации, данные нужно сортировать перед выдачей. Для этого и нужен поиск: на сайте можно искать по текстовому совпадению, а заодно подключать дополнительные фильтры, так как они тоже сделаны через Elastic.
3. Потом мы перенесли обработку транзакций. Пользователи могут покупать определенный товар на сайте и участвовать в розыгрыше призов. После таких покупок, мы обрабатываем большое количество данных, особенно в выходные и праздники. Для сравнения, если в обычные дни количество покупок составляет где-то 1,5-2 млн, то в праздники цифра может достигать 53 млн.
При этом данные нужно обработать за минимальное время — пользователи не любят ждать результата несколько дней. Через Postgres таких сроков никак не добьешься — мы часто получали блокировки, и пока мы обрабатывали все запросы, пользователи не могли проверить получили они призы или нет. Это не очень приятно для бизнеса, поэтому мы перенесли обработку в Elasticsearch.
Сейчас обновления настроены событийно, по следующим условиям:
Здесь еще раз стоит сказать о плюсах Elastic. В Postgres во время отправки запроса, нужно ждать пока он честно обработает все записи. В Elastic можно отправить 10 тыс. записей, и сразу начать работать, не дожидаясь, пока записи разойдутся по всем Shards. Конечно, какой-то Shard или Replica могут не увидеть данные сразу, но очень скоро все будет доступно.
Есть 2 способа интеграции с Elastic:
Благодаря HTTP-интерфейсу мы можем использовать библиотеки, которые дают асинхронную реализацию HTTP клиента. Мы можем использовать преимущество Batch и асинхронного API, что в итоге даёт высокую производительность, которая очень помогла в дни крупной акции (об этом ниже)
Немного цифр для сравнения:
Сейчас мы написали менеджер запросов по HTTP, который строит JSON, как Batch/не Batch и отправляет через любой HTTP клиент вне зависимости от библиотеки. Так же можно выбирать синхронно или асинхронно отправлять запросы.
В некоторых интеграциях мы все еще используем официальный transport client, но это лишь вопрос ближайшего рефакторинга. При этом для обработки используется собственный клиент, построенный на базе Spring WebClient.
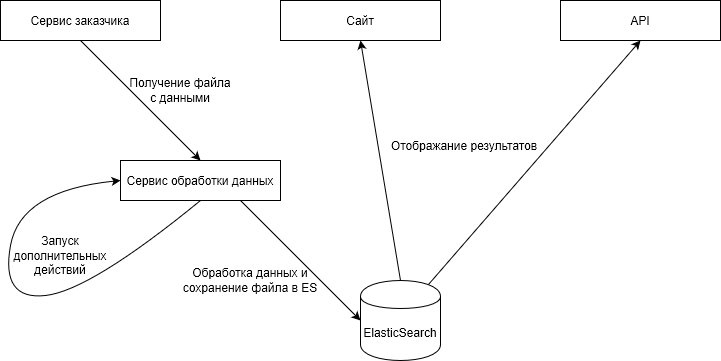
Раз в год на проекте проходит большая акция для пользователей — это тот самый Highload, так как в это время мы работаем с десятками миллионов пользователей одновременно.
Обычно пики нагрузок бывают в праздничные дни, но эта акция — совсем другой уровень. В позапрошлом году в день акции мы продали 27 580 890 единиц товара. Данные обрабатывались более получаса, что вызывало неудобство у пользователей. Пользователи получили призы за участие, но стало понятно, что процесс нужно ускорять.
В начале 2019 года мы решили, что нужен ElasticSearch. Целый год мы организовывали обработку получаемых данных в Elastic и их выдачу в api мобильного приложения и сайта. В итоге на следующий год во время акции мы обработали 15 131 783 записей за 6 минут.
Поскольку, желающих купить товар и участвовать в розыгрыше призов в акциях у нас очень много, то это временная мера. Сейчас мы отправляем актуальную информацию в Elastic, но в дальнейшем планируем архивную информацию за прошлые месяцы переносить в Postgres, как перманентное хранилище. Чтобы не засорять индекс Elastic, который тоже имеет свои ограничения.
На данный момент мы перенесли на Elastic все сервисы, которые хотели и на этом пока сделали паузу. Сейчас мы поверх основного персистентного хранилища в Postgres строим индекс в Elastic, который принимает на себя пользовательскую нагрузку.
В дальнейшем мы планируем переносить сервисы если мы понимаем, что запрос данных становится слишком многообразным и ищется по неограниченному количеству колонок. Это уже задача не для Postgres.
Если нам будет нужен полнотекстовый поиск в функционале или если у нас появится много разнообразных критериев поиска то мы уже знаем, что это нужно переводить в Elastic.
Спасибо, что прочитали. Если у вас в компании тоже используются ElasticSearch и есть собственные кейсы реализации, то расскажите. Будет интересно узнать как у других :-)
Как устроен проект
На нашем бэкенде мы создаем сервисы, которые обеспечивают работоспособность сайтов и мобильного приложения нашего клиента. Общую структуру можно увидеть на схеме:
В процессе работы мы обрабатываем большое кол-во транзакций: покупок, выплат, операций с балансами пользователей, по которым храним много логов, а также импортируем и экспортируем эти данные во внешние системы.
Также идут и обратные процессы, когда мы получаем данные от клиента и передаем их пользователем. Помимо этого еще существуют процессы по работе с платежами и бонусными программами.
Короткая предыстория
Изначально в качестве единственного хранилища данных мы использовали PostgreSQL. Его стандартные для СУБД преимущества: наличие транзакций, развитый язык выборки данных, широкий инструментарий для интеграции; в сочетании с хорошей производительностью довольного долго удовлетворяли наши потребности.
Мы хранили в Postgres абсолютно все данные: от транзакций до новостей. Но количество пользователей росло, а вместе с ним и количество запросов.
Для понимания, годовое количество сеансов в 2017 году только на десктопном сайте — 131 млн. За 2018 — 125 млн. 2019 снова 130 млн. Добавьте туда еще 100-200 млн от мобильной версии сайта и мобильного приложения, и вы получите колоссальное количество запросов.
С ростом проекта, Postgres перестал справляться с нагрузкой, мы не успевали — появилось большое количество разнообразных запросов, под которые мы не смогли создать достаточное количество индексов.
Мы понимали, что есть необходимость в других хранилищах данных, которые бы обеспечили наш потребности и сняли нагрузку с PostgreSQL. В качестве возможных вариантов рассматривали Elasticsearch и MongoDB. Последний проигрывал по следующим пунктам:
- Медленная скорость индексации с ростом объема данных в индексах. У Elastic скорость не зависит от объема данных.
- Нет полнотекстового поиска
Так мы выбрали для себя Elastic и приготовились к переходу.
Переход на Elastic
1. Мы начали переход с сервиса поиска точек продаж. У нашего клиента суммарно есть около 70 000 точек продаж, и при этом требуется несколько типов поиска на сайте и в приложении:
- Текстовый поиск по названию населённого пункта
- Геопоиск в заданном радиусе от какой-то точки. Например, если пользователь хочет увидеть какие точки продаж ближе всего к его дому.
- Поиск по заданному квадрату – пользователь очерчивает квадрат на карте, и ему показываются все точки в этом радиусе.
- Поиск по дополнительным фильтрам. Точки продаж отличаются друг от друга по ассортименту
Если говорить по организацию, то в Postgres у нас лежит источник данных как по карте, так и по новостям, а в Elastic делаются Snapshot’ы от оригинальных данных. Дело в том, что изначально Postgres не справлялся с поиском по всем критериям. Мало того, что было много индексов, они могли еще и пересекаться, поэтому планировщик Postgres терялся и не понимал какой индекс ему использовать.
2. Следующий на очереди был раздел новостей. На сайте каждый день появляются публикации, чтобы пользователь не потерялся в потоке информации, данные нужно сортировать перед выдачей. Для этого и нужен поиск: на сайте можно искать по текстовому совпадению, а заодно подключать дополнительные фильтры, так как они тоже сделаны через Elastic.
3. Потом мы перенесли обработку транзакций. Пользователи могут покупать определенный товар на сайте и участвовать в розыгрыше призов. После таких покупок, мы обрабатываем большое количество данных, особенно в выходные и праздники. Для сравнения, если в обычные дни количество покупок составляет где-то 1,5-2 млн, то в праздники цифра может достигать 53 млн.
При этом данные нужно обработать за минимальное время — пользователи не любят ждать результата несколько дней. Через Postgres таких сроков никак не добьешься — мы часто получали блокировки, и пока мы обрабатывали все запросы, пользователи не могли проверить получили они призы или нет. Это не очень приятно для бизнеса, поэтому мы перенесли обработку в Elasticsearch.
Периодичность
Сейчас обновления настроены событийно, по следующим условиям:
- Точки продаж. Как только к нам приходят данные из внешнего источника, мы сразу же запускаем обновление.
- Новости. Как только на сайте редактируют какую-либо новость, она автоматически отправляется в Elastic.
Здесь еще раз стоит сказать о плюсах Elastic. В Postgres во время отправки запроса, нужно ждать пока он честно обработает все записи. В Elastic можно отправить 10 тыс. записей, и сразу начать работать, не дожидаясь, пока записи разойдутся по всем Shards. Конечно, какой-то Shard или Replica могут не увидеть данные сразу, но очень скоро все будет доступно.
Способы интеграции
Есть 2 способа интеграции с Elastic:
- Через нативный клиент по TCP. Нативный драйвер постепенно вымирает: его перестают поддерживать, на нем очень неудобный синтаксис. Поэтому мы его практически не используем и стараемся полностью отказаться от него.
- Через HTTP интерфейс, в котором можно использовать как JSON запросы, так и синтаксис Lucene. Последнее — текстовый движок, который использует Elastic. В таком варианте мы получаем возможность Batch через JSON-запросы по HTTP. Именно этот вариант мы стараемся использовать.
Благодаря HTTP-интерфейсу мы можем использовать библиотеки, которые дают асинхронную реализацию HTTP клиента. Мы можем использовать преимущество Batch и асинхронного API, что в итоге даёт высокую производительность, которая очень помогла в дни крупной акции (об этом ниже)
Немного цифр для сравнения:
- Сохранение пользователей получивших призы в Postgres в 20 потоков без группировок: 460713 записей за 42 секунды
- Elastic + реактивный клиент на 10 потоков + batch на 1000 элементов: 596749 записей за 11 секунд
- Elastic + реактивный клиент на 10 потоков + batch на 1000 элементов: 23801684 записей за 4 минуты
Сейчас мы написали менеджер запросов по HTTP, который строит JSON, как Batch/не Batch и отправляет через любой HTTP клиент вне зависимости от библиотеки. Так же можно выбирать синхронно или асинхронно отправлять запросы.
В некоторых интеграциях мы все еще используем официальный transport client, но это лишь вопрос ближайшего рефакторинга. При этом для обработки используется собственный клиент, построенный на базе Spring WebClient.
Большая акция
Раз в год на проекте проходит большая акция для пользователей — это тот самый Highload, так как в это время мы работаем с десятками миллионов пользователей одновременно.
Обычно пики нагрузок бывают в праздничные дни, но эта акция — совсем другой уровень. В позапрошлом году в день акции мы продали 27 580 890 единиц товара. Данные обрабатывались более получаса, что вызывало неудобство у пользователей. Пользователи получили призы за участие, но стало понятно, что процесс нужно ускорять.
В начале 2019 года мы решили, что нужен ElasticSearch. Целый год мы организовывали обработку получаемых данных в Elastic и их выдачу в api мобильного приложения и сайта. В итоге на следующий год во время акции мы обработали 15 131 783 записей за 6 минут.
Поскольку, желающих купить товар и участвовать в розыгрыше призов в акциях у нас очень много, то это временная мера. Сейчас мы отправляем актуальную информацию в Elastic, но в дальнейшем планируем архивную информацию за прошлые месяцы переносить в Postgres, как перманентное хранилище. Чтобы не засорять индекс Elastic, который тоже имеет свои ограничения.
Заключение/выводы
На данный момент мы перенесли на Elastic все сервисы, которые хотели и на этом пока сделали паузу. Сейчас мы поверх основного персистентного хранилища в Postgres строим индекс в Elastic, который принимает на себя пользовательскую нагрузку.
В дальнейшем мы планируем переносить сервисы если мы понимаем, что запрос данных становится слишком многообразным и ищется по неограниченному количеству колонок. Это уже задача не для Postgres.
Если нам будет нужен полнотекстовый поиск в функционале или если у нас появится много разнообразных критериев поиска то мы уже знаем, что это нужно переводить в Elastic.
???
Спасибо, что прочитали. Если у вас в компании тоже используются ElasticSearch и есть собственные кейсы реализации, то расскажите. Будет интересно узнать как у других :-)
tenbits
Если не секрет, а какой у вас месячный расход на инфраструкту? И на сколько он изменился с добавлением elasticsearch серверов?
Norovy
Привет! Спасибо за вопрос
К сожалению, это NDA. Но вообще «Эластик» не экономит деньги, а лишь позволяет ускорить развертывание больших пачек данных