

WebAssembly (сокр. WASM) — технология запуска предварительно скомпилированного бинарного кода в браузере на стороне клиента. Впервые была представлена в 2015 году и на текущий момент поддерживается большинством современных браузеров.
Один из распространенный сценариев использования — предварительная обработка данных на стороне клиента перед отправкой файлов на сервер. В этой статье разберемся как это делается.
Перед началом
Про архитектуру WebAssembly и общие шаги допольно подробно написано здесь и тут. Мы же пройдемся только по основным фактам.
Работа с WebAssembly начинается с предварительной сборки артефактов, необходимых для запуска скомпилированного кода на стороне клиента. Их два: собственно сам бинарный WASM файл и JavaScript прослойка, через которую можно вызывать экспортированные в него методы.
Пример простейшего кода на C++ для компиляции
#include <algorithm>
extern "C" {
int calculate_gcd(int a, int b) {
while (a != 0 && b != 0) {
a %= b;
std::swap(a, b);
}
return a + b;
}
}Для сборки используется Emscripten, который кроме основного интерфейса подобных компиляторов, содержит дополнительные флаги, через которые задается конфигурация виртуальной машины и экспортируемые методы. Простейший запуск выглядит примерно так:
em++ main.cpp --std=c++17 -o gcd.html -s EXPORTED_FUNCTIONS='["_calculate_gcd"]' -s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]'Указанием в качестве объекта *.html файла подсказывает компилятору, что нужно создать также простую html-разметку с js консолью. Теперь если запустить сервер на полученных файлах, увидим эту консоль с возможностью запуска _calculate_gcd:
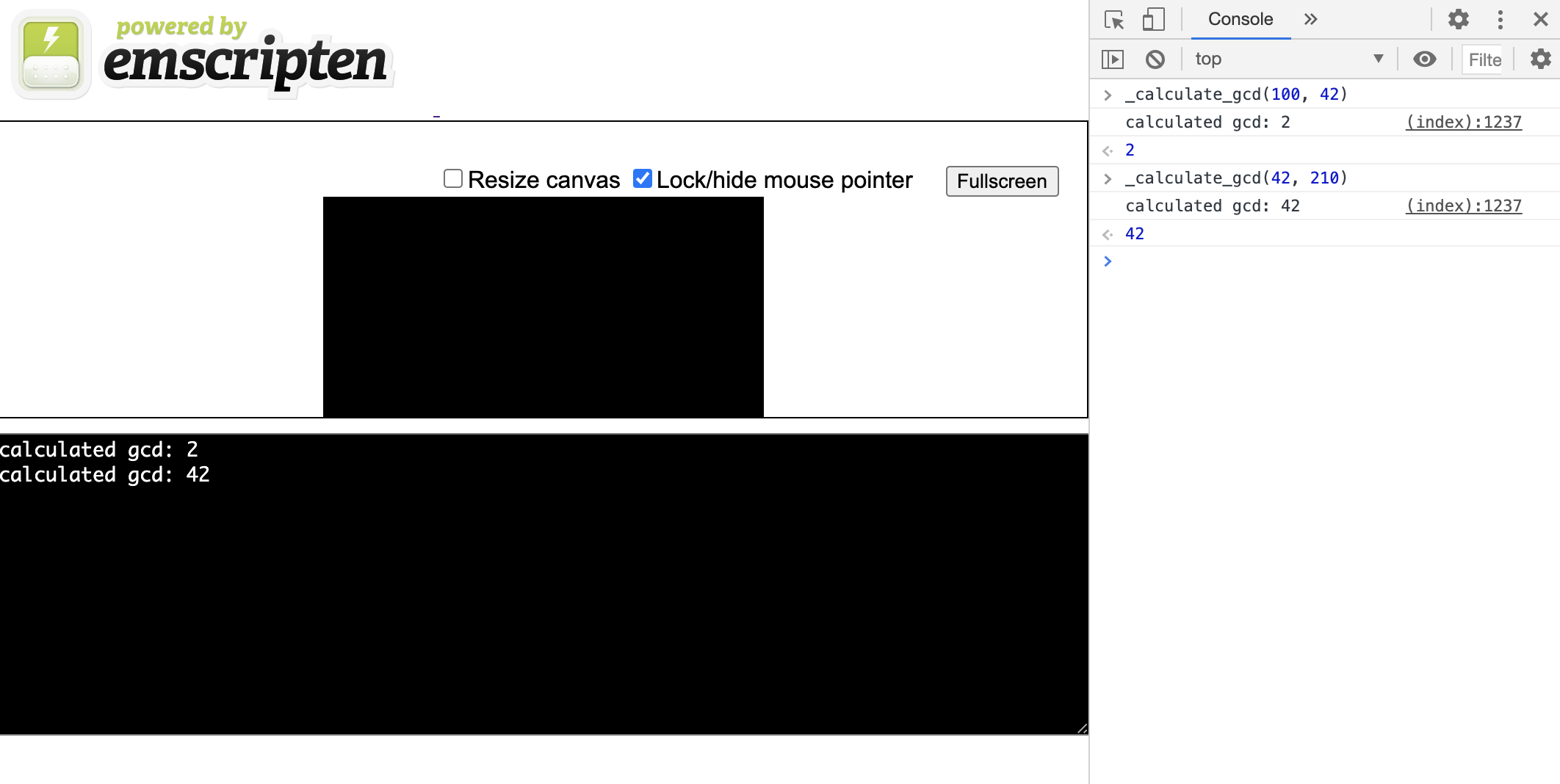
Обработка данных
Разберем ее на простом примере lz4-компрессии с помощью библиотеки, написанной на C++. Замечу, что на этом множество поддерживаемых языков не заканчивается.
Несмотря на простоту и некоторую синтетичность примера, это довольно полезная иллюстрация того, как работать с данными. Аналогичным образом над ними можно выполнять любые действия, для которых достаточно мощностей клиента: предобработка изображений перед отправкой на сервер, компрессия аудио, подсчет различных статистик и многое другое.
Весь код целиком можно найти тут.
С++ часть
Используем уже готовую реализацию lz4. Тогда main файл будет выглядеть весьма лаконично:
#include "lz4.h"
extern "C" {
uint32_t compress_data(uint32_t* data, uint32_t data_size, uint32_t* result) {
uint32_t result_size = LZ4_compress(
(const char *)(data), (char*)(result), data_size);
return result_size;
}
uint32_t decompress_data(uint32_t* data, uint32_t data_size, uint32_t* result, uint32_t max_output_size) {
uint32_t result_size = LZ4_uncompress_unknownOutputSize(
(const char *)(data), (char*)(result), data_size, max_output_size);
return result_size;
}
}Как можно видеть, в нем просто объявлены внешние (используя ключевое слово extern) функции, внутри вызывающие соответствующие методы из библиотеки с lz4.
Вообще говоря, в нашем случае этот файл бесполезен: можно сразу использовать нативный интерфейс из lz4.h. Однако в более сложных проектах (например, объединяющих функционал разных библиотек), удобно иметь такую общую точку входа с перечислением всех используемых функций.
Далее компилируем код используя уже упомянутый компилятор Emscripten:
em++ main.cpp lz4.c -o wasm_compressor.js -s EXPORTED_FUNCTIONS='["_compress_data","_decompress_data"]' -s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]' -s WASM=1 -s ALLOW_MEMORY_GROWTH=1Размер полученных артефактов настораживает:
$ du -hs wasm_compressor.*
112K wasm_compressor.js
108K wasm_compressor.wasm
Если открыть JS файл-прослойку, можно увидеть примерно следующее:

В ней много лишнего: от комментариев до сервисных функций, большая часть которых не используется. Ситуацию можно исправить добавлением флага -O2, в Emscripten компиляторе он включает также оптимизацию js кода.
После этого js код выглядит более приятно:

Клиентский код
Нужно как-то вызвать обработчик на стороне клиента. Первым делом загрузим файл, предоставленный пользователем, через
FileReader, хранить сырые данные будем в примитиве Uint8Array:var rawData = new Uint8Array(fileReader.result);Далее нужно передать загруженные данные в виртуальную машину. Для этого сначала аллоцируем нужное количество байт методом _malloc, затем скопируем туда JS массив методом set. Для удобства выделим эту логику в функцию arrayToWasmPtr(array):
function arrayToWasmPtr(array) {
var ptr = Module._malloc(array.length);
Module.HEAP8.set(array, ptr);
return ptr;
}После загрузки данных в память виртуальной машины, нужно каким-то образом вызвать функцию из обработки. Но как эту функцию найти? Нам поможет метод cwrap — первым аргументом в нем указывается название искомой функции, вторым — возвращаемый тип, третьим — список с входными аргументами.
compressDataFunction = Module.cwrap('compress_data', 'number', ['number', 'number', 'number']);И наконец нужно вернуть готовые байты из виртуальной машины. Для этого пишем еще одну функцию, копирующую их в JS массив посредством метода
subarrayfunction wasmPtrToArray(ptr, length) {
var array = new Int8Array(length);
array.set(Module.HEAP8.subarray(ptr, ptr + length));
return array;
}Полный скрипт обработки входящих файлов лежит тут. HTML-разметка, содержащая форму загрузки файла и подгрузку wasm артефактов здесь.
Итог
Поиграться с прототипом можно здесь.
В результате получилась рабочая архивация, использующая WASM. Из минусов — текущая реализация технологии не позволяет освобождать аллоцированную в виртуальной машине память. Это создает неявную утечку, когда загружается большое количество файлов за одну сессию, но может быть исправлено переиспользованием уже существующей памяти вместо выделения новой.



UncleJey
Статья в корпоративном блоге ради статьи в корпоративном блоге. Можно не читать.
raamid
Минус не мой, но позволю себе не согласиться. В статье собраны в одном месте сведения, по достаточно актуальной тематике. Если бы эта статья попалась мне полгода назад, она сохранила бы мне пару дней.
UncleJey
ну вот именно что. Полгода — год назад этой информации было мало. И в ней была потребность.
shasoft
Всегда есть люди на «полгода» назад от вас. И им статья будет полезна.
dlinyj
Лично я пропустил эту тему и столкнулся с ней впервые читая эту статью. Мне показалось очень интересной технологией.