
Привет, меня зовут Виталий Корж, я Dev Lead из Luxoft. Последние пару лет мы с командой занимаемся разработкой в области Digital Asset Management. Эта статья — небольшая ретроспектива на эволюцию монолитного приложения в множество сервисов. Она будет полезна разработчикам и QA-специалистам как уровня middle, так и senior.
Если вам надоела сервисная анархия, хочется порядка, но вы не знаете как начать его наводить — этот материал для вас.
Когда долго работаешь в какой-то сфере, начинаешь замечать, что одни и те же решения перманентно повторяются в разных проектах. Дело в том, что все участники процесса (архитектор, разработчики и QA-специалисты ) время от времени идут на некоторые компромиссы и выполняют полностью все условия.
Во время работы над различными проектами мне неоднократно приходилось сталкиваться с тем, что одни и те-же механики изобретались заново или использовались повторно. Тем не менее, с каждым разом приходит все большее понимание того что нужно и определенные практики превращаются в шаблоны и заготовки «про-запас».
В живой рабочей среде набор практик никогда не застывает и всегда изменяется под влиянием новых идей и экспертизы. Часть заготовок удаляются и на их место приходят новые, свежие решения.
При работе над проектом, состоящим из нескольких десятков сервисов постоянно приходится решать одни и те-же задачи. Весь цикл разработки можно разделить на этапы: согласование стиля, структуры и архитектуры проекта, экосистемы для приложения, контрактов для межсервисной коммуникации. Независимо от сложности и масштабности проекта, каждая команда привносит в него немного индивидуальности.
Рассматривая спектр систем от огромного монолита на одном конце, до функций на другом, всегда существует понимание, что все они в общем-то похожи. Каждая система по-своему принимает, обрабатывает сигналы и хранит состояния.
Для примера рассмотрим веб приложение.
Независимо от сложности и специфики проект можно разделить на несколько слоев:
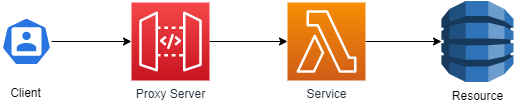
Чаще всего так выглядит диаграмма простого сервиса, отвечающего за одну сущность и работу с ней. Такой сервис состоит из контроллера, сервиса и ресурсов (база данных, файловая система, другие сервисы).
Примером такой конфигурации может быть классический FaaS проект, где одному REST ресурсу соответствует одна функция, выполняющая только одну задачу, используя какую то базу данных. Множество таких функций, работающие с общими ресурсами, можно рассматривать как единое распределенное приложение.
Независимо от гранулярности любой сервис можно свести к SRP. Понимание ответственности сервиса можно трактовать по разному и это нужно заранее оговорить.
Представленной модели часто может оказаться недостаточно. Клиент может требовать анализа сложных данных, требующих агрегации результатов из нескольких источников. В таком случае необходимо организовать связь между различными сервисами системы. Оптимальным вариантом может послужить шаблон оркестратора (Orchestration pattern), который способен объединять цепочки вызовов других сервисов в слаженный сценарий, дополнительно обрастая дополнительными возможностями.
Как следствие, развитие изначальной схемы будет выглядеть следующим образом:
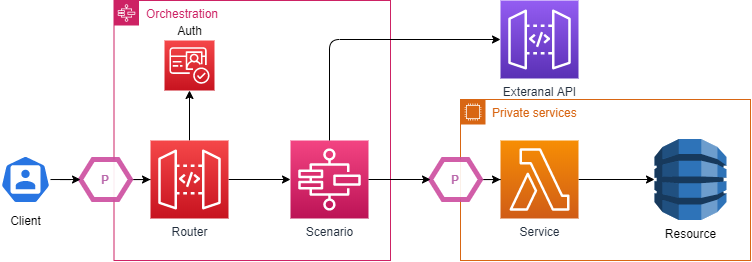
Если говорить образно, то каждый оркестратор представляет из себя некий пирог из маршрутизации, авторизации и сценариев, где требования определяют что должно происходить на каждом из этапов и как они могут быть реализованы. В последствии, сценарий формирует структуру и последовательность взаимодействий между сервисами.
В процессе постепенного развития системы, имея небольшое количество сервисов и не планируя дальнейшего роста, есть соблазн организовать доступ к системе через любой сервис, сделав все сервисы публичными.
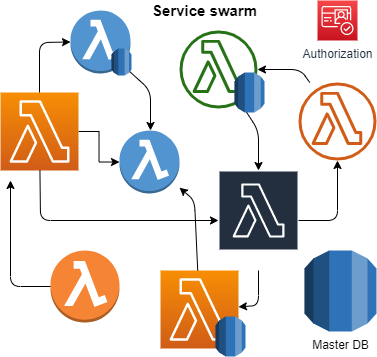
Следствием этого есть желание связать сервисы между собой, тем или иным способом. Со временем, желание не усложнять и не переделывать приводит к огромному разнообразию сервисов и архитектур, что в свою очередь усложняет обслуживание такой системы.
Порожденный хаос является не чем иным, как распределенным монолитом. Множество связанных по той или иной подсистем, обусловлено изначальной связанностью и желанием избежать излишнего дублирования функциональности в конкретном сервисе, приводит к ненужному дублированию системных узлов и усложняет дальнейшее развитие системы.
Причины образовавшегося хаоса стоит искать в невозможности определения границ ответственности того или иного сервиса. Ведь чем больше задач выполняет сервис, чем сложнее его ответы, тем отчетливее становятся видны контуры проблемы.
Для лучшего распределения ответственности, образовавшиеся сервисы стоит поделить на группы, тем самым организовав систему в несколько кластеров. Например, сервисы могут быть поделены на публичные и приватные, те к которым есть доступ извне и те которые используются только для системных нужд.
После разделения систем по ответственности, следует пересмотреть задачи которые каждый сервис решает. При этом, сервис не должен обрабатывать запросы и контролировать свое расписание для задач, привязанных ко времени. Координацию вызова различных сервисов стоит вынести в отдельный компонент, что позволит гибко настраивать и управлять цепочками вызовов, в то же время упрощая создание, изменение и поддержку каждого сервиса и системы в целом.
Все это позволит сформировать пользовательский фасад, за которым уже можно начинать перестройку.
Как уже отмечалось ранее, сервис должен выполнять одну задачу, будь то сохранение данных или вызовы других сервисов. Как следствие, каждый такой сервис может забрать общие для своей группы задачи, такие как авторизация и контроль доступа, упрощая систему в целом.
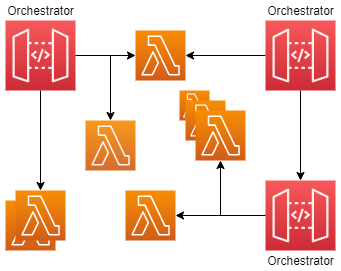
Сервис оркестрации, подобно ромашке, обрастает зависимостями и позволяет координировать коммуникацию между различными сервисами, в тоже время не ограничивая доступ к сервисам для других оркестраторов, которые в случае необходимости также могут общаться между собой.
Каждый из сервисов оркестрации обязан выполнять свою роль в системе, по возможности, не дублируя поведение.
Разделив сервисы по поведению, появляется возможность организации различного уровня доступа к сервисам и группам. Это позволит установить каждому сервису свои права и наделить каждого участника определенными привилегиями соответствующие его роли, что в свою очередь повысит защищенность каждого компонента системы от внешних и внутренних угроз.
Организовав систему в виде ярусов, возникает возможность управлять не только уровнем доступа и безопасностью, но и упростить каждый конкретный компонент.
А организация нескольких независимых клиентских интерфейсов с пересекающимся функционалом позволит развязать руки командам разработки и упростит дальнейшее развитие системы.
Приложения на различных слоях могут выполнять различные функции и само разнесение сервисов по различным слоям является дальнейшим развитием идеи разделения ответственностей между приложениями. А уровни упрощают ориентирование в зоопарке подсистем.
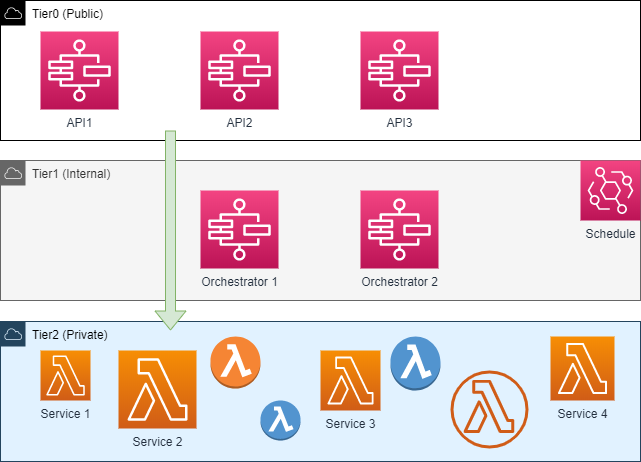
В тоже время, системные сервисы, а также сложные асинхронные сценарии не должны быть доступными извне. При этом они должны сохранять доступ ко всем компонентам системы
Распределив сервисы по ярусам следует учитывать что сервисы с одного яруса не могут общаться между собой, связи между яруса соответствуют своей топологии, их ранг условен и некоторые из них могут быть прозрачны для приложений, что находится уровнем выше.
Такой подход требует стандартизации интерфейсов взаимодействия между компонентами, что соответствуют определенным контрактам.
Это позволит полностью абстрагироваться от реализаций, что в свою очередь упрощает масштабирование проекта и замену конечных компонентов при надобности.
Говоря со стороны простого обывателя, данная схема позволит решить часть задач, но помимо сервисов существуют другие аспекты хорошей экосистемы, такие как развертывание сервисов, прозрачность процессов и мониторинг состояний.
Какие бы задачи нашему приложению не приходилось решать, все они должны где-то выполняться. В случае с облачной архитектурой, лучше всего данную проблему решают контейнеры. Следовательно, каждое наше приложение должно быть правильно упаковано и подготовлено для дальнейшего использования.
Упаковывая приложение нужно помнить о задачах поддержки и отладки. Также важно заложить возможность конфигурации образа на этапе развертывания, чтобы избежать, в случае изменения настроек окружения, ненужных манипуляций.
В зависимости от условий, можно хранить различные сборки одного приложения или предусмотреть данную возможность, разделив артефакты приложения и образов системы, как вариант.
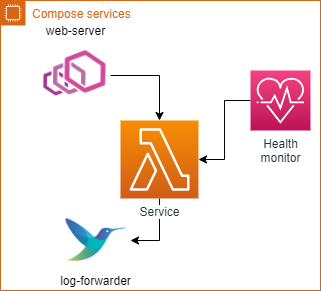
Важной частью окружения каждого сервиса также должен быть независимый веб-сервер, который позволит настроить доступ к приложению. Также он должен быть доступным в те моменты когда приложение не может выполнять свою роль.
Стоит также помнить о необходимости собирать и проксировать логи. Стоит утвердить единый формат для всех сервисов, для упрощения анализа сообщений в дальнейшем. Сбор логов не должен зависеть от приложения. Существует множество коллекторов для логов которые позволяют считывать контент как из файлов так и непосредственно из приложения. Независимо от того какой способ будет использован такое разделение позволит выделить сбор логов в независимый процесс.
Отслеживание маршрутизации запросов — один из ключевых компонентов распределенной системы, и стоит предусмотреть возможность подключения соответствующих инструментов.
Сервис-монитор — также неотъемлемая часть любой инфраструктуры, позволяющая знать какие версии сервисов и где они запущены. Его присутствие способствует оперативному реагированию на различные неполадки. Невозможно представить систему без должной системы мониторинга, как на уровне сервиса, так и на уровня контейнера.
Для слаженной работы приложения на всех этапах необходимо настроить CI/CD, независимо от выбранного инструмента. Он должен позволять собирать статистику и повторное выполнение команд, при возможности унифицировать все процессы для пайплайнов одной команды уменьшая количество ручных манипуляций.
Не ищите универсальное решение, найдите то, которое хорошо решает вашу задачу, и реализуйте его так, чтобы за него не было стыдно.
Если вам надоела сервисная анархия, хочется порядка, но вы не знаете как начать его наводить — этот материал для вас.
Когда долго работаешь в какой-то сфере, начинаешь замечать, что одни и те же решения перманентно повторяются в разных проектах. Дело в том, что все участники процесса (архитектор, разработчики и QA-специалисты ) время от времени идут на некоторые компромиссы и выполняют полностью все условия.
Во время работы над различными проектами мне неоднократно приходилось сталкиваться с тем, что одни и те-же механики изобретались заново или использовались повторно. Тем не менее, с каждым разом приходит все большее понимание того что нужно и определенные практики превращаются в шаблоны и заготовки «про-запас».
В живой рабочей среде набор практик никогда не застывает и всегда изменяется под влиянием новых идей и экспертизы. Часть заготовок удаляются и на их место приходят новые, свежие решения.
При работе над проектом, состоящим из нескольких десятков сервисов постоянно приходится решать одни и те-же задачи. Весь цикл разработки можно разделить на этапы: согласование стиля, структуры и архитектуры проекта, экосистемы для приложения, контрактов для межсервисной коммуникации. Независимо от сложности и масштабности проекта, каждая команда привносит в него немного индивидуальности.
Рассматривая спектр систем от огромного монолита на одном конце, до функций на другом, всегда существует понимание, что все они в общем-то похожи. Каждая система по-своему принимает, обрабатывает сигналы и хранит состояния.
Минимально возможный дизайн
Для примера рассмотрим веб приложение.
Независимо от сложности и специфики проект можно разделить на несколько слоев:
- Клиент
- Прокси сервер
- Сервис
- Ресурс
Чаще всего так выглядит диаграмма простого сервиса, отвечающего за одну сущность и работу с ней. Такой сервис состоит из контроллера, сервиса и ресурсов (база данных, файловая система, другие сервисы).
Примером такой конфигурации может быть классический FaaS проект, где одному REST ресурсу соответствует одна функция, выполняющая только одну задачу, используя какую то базу данных. Множество таких функций, работающие с общими ресурсами, можно рассматривать как единое распределенное приложение.
Независимо от гранулярности любой сервис можно свести к SRP. Понимание ответственности сервиса можно трактовать по разному и это нужно заранее оговорить.
Детализация
Представленной модели часто может оказаться недостаточно. Клиент может требовать анализа сложных данных, требующих агрегации результатов из нескольких источников. В таком случае необходимо организовать связь между различными сервисами системы. Оптимальным вариантом может послужить шаблон оркестратора (Orchestration pattern), который способен объединять цепочки вызовов других сервисов в слаженный сценарий, дополнительно обрастая дополнительными возможностями.
Как следствие, развитие изначальной схемы будет выглядеть следующим образом:
Если говорить образно, то каждый оркестратор представляет из себя некий пирог из маршрутизации, авторизации и сценариев, где требования определяют что должно происходить на каждом из этапов и как они могут быть реализованы. В последствии, сценарий формирует структуру и последовательность взаимодействий между сервисами.
Монолитный хаос
В процессе постепенного развития системы, имея небольшое количество сервисов и не планируя дальнейшего роста, есть соблазн организовать доступ к системе через любой сервис, сделав все сервисы публичными.
Следствием этого есть желание связать сервисы между собой, тем или иным способом. Со временем, желание не усложнять и не переделывать приводит к огромному разнообразию сервисов и архитектур, что в свою очередь усложняет обслуживание такой системы.
Порожденный хаос является не чем иным, как распределенным монолитом. Множество связанных по той или иной подсистем, обусловлено изначальной связанностью и желанием избежать излишнего дублирования функциональности в конкретном сервисе, приводит к ненужному дублированию системных узлов и усложняет дальнейшее развитие системы.
Перестройка
Причины образовавшегося хаоса стоит искать в невозможности определения границ ответственности того или иного сервиса. Ведь чем больше задач выполняет сервис, чем сложнее его ответы, тем отчетливее становятся видны контуры проблемы.
Для лучшего распределения ответственности, образовавшиеся сервисы стоит поделить на группы, тем самым организовав систему в несколько кластеров. Например, сервисы могут быть поделены на публичные и приватные, те к которым есть доступ извне и те которые используются только для системных нужд.
После разделения систем по ответственности, следует пересмотреть задачи которые каждый сервис решает. При этом, сервис не должен обрабатывать запросы и контролировать свое расписание для задач, привязанных ко времени. Координацию вызова различных сервисов стоит вынести в отдельный компонент, что позволит гибко настраивать и управлять цепочками вызовов, в то же время упрощая создание, изменение и поддержку каждого сервиса и системы в целом.
Все это позволит сформировать пользовательский фасад, за которым уже можно начинать перестройку.
Оркестрация
Как уже отмечалось ранее, сервис должен выполнять одну задачу, будь то сохранение данных или вызовы других сервисов. Как следствие, каждый такой сервис может забрать общие для своей группы задачи, такие как авторизация и контроль доступа, упрощая систему в целом.
Сервис оркестрации, подобно ромашке, обрастает зависимостями и позволяет координировать коммуникацию между различными сервисами, в тоже время не ограничивая доступ к сервисам для других оркестраторов, которые в случае необходимости также могут общаться между собой.
Каждый из сервисов оркестрации обязан выполнять свою роль в системе, по возможности, не дублируя поведение.
Разделив сервисы по поведению, появляется возможность организации различного уровня доступа к сервисам и группам. Это позволит установить каждому сервису свои права и наделить каждого участника определенными привилегиями соответствующие его роли, что в свою очередь повысит защищенность каждого компонента системы от внешних и внутренних угроз.
Структурирование
Организовав систему в виде ярусов, возникает возможность управлять не только уровнем доступа и безопасностью, но и упростить каждый конкретный компонент.
А организация нескольких независимых клиентских интерфейсов с пересекающимся функционалом позволит развязать руки командам разработки и упростит дальнейшее развитие системы.
Приложения на различных слоях могут выполнять различные функции и само разнесение сервисов по различным слоям является дальнейшим развитием идеи разделения ответственностей между приложениями. А уровни упрощают ориентирование в зоопарке подсистем.
В тоже время, системные сервисы, а также сложные асинхронные сценарии не должны быть доступными извне. При этом они должны сохранять доступ ко всем компонентам системы
Распределив сервисы по ярусам следует учитывать что сервисы с одного яруса не могут общаться между собой, связи между яруса соответствуют своей топологии, их ранг условен и некоторые из них могут быть прозрачны для приложений, что находится уровнем выше.
Такой подход требует стандартизации интерфейсов взаимодействия между компонентами, что соответствуют определенным контрактам.
Это позволит полностью абстрагироваться от реализаций, что в свою очередь упрощает масштабирование проекта и замену конечных компонентов при надобности.
Говоря со стороны простого обывателя, данная схема позволит решить часть задач, но помимо сервисов существуют другие аспекты хорошей экосистемы, такие как развертывание сервисов, прозрачность процессов и мониторинг состояний.
Обслуживающая инфраструктура
Какие бы задачи нашему приложению не приходилось решать, все они должны где-то выполняться. В случае с облачной архитектурой, лучше всего данную проблему решают контейнеры. Следовательно, каждое наше приложение должно быть правильно упаковано и подготовлено для дальнейшего использования.
Упаковывая приложение нужно помнить о задачах поддержки и отладки. Также важно заложить возможность конфигурации образа на этапе развертывания, чтобы избежать, в случае изменения настроек окружения, ненужных манипуляций.
В зависимости от условий, можно хранить различные сборки одного приложения или предусмотреть данную возможность, разделив артефакты приложения и образов системы, как вариант.
Важной частью окружения каждого сервиса также должен быть независимый веб-сервер, который позволит настроить доступ к приложению. Также он должен быть доступным в те моменты когда приложение не может выполнять свою роль.
Стоит также помнить о необходимости собирать и проксировать логи. Стоит утвердить единый формат для всех сервисов, для упрощения анализа сообщений в дальнейшем. Сбор логов не должен зависеть от приложения. Существует множество коллекторов для логов которые позволяют считывать контент как из файлов так и непосредственно из приложения. Независимо от того какой способ будет использован такое разделение позволит выделить сбор логов в независимый процесс.
Отслеживание маршрутизации запросов — один из ключевых компонентов распределенной системы, и стоит предусмотреть возможность подключения соответствующих инструментов.
Сервис-монитор — также неотъемлемая часть любой инфраструктуры, позволяющая знать какие версии сервисов и где они запущены. Его присутствие способствует оперативному реагированию на различные неполадки. Невозможно представить систему без должной системы мониторинга, как на уровне сервиса, так и на уровня контейнера.
Для слаженной работы приложения на всех этапах необходимо настроить CI/CD, независимо от выбранного инструмента. Он должен позволять собирать статистику и повторное выполнение команд, при возможности унифицировать все процессы для пайплайнов одной команды уменьшая количество ручных манипуляций.
Заключение
Не ищите универсальное решение, найдите то, которое хорошо решает вашу задачу, и реализуйте его так, чтобы за него не было стыдно.