
В предыдущих статьях Google Earth Engine (GEE) как общедоступный суперкомпьютер и Google Earth Engine (GEE) как общедоступный каталог больших геоданных мы познакомились со способами удобного и быстрого доступа к каталогу космических снимков и их обработки. Теперь мы можем искать питьевую воду, различные минералы и вообще много всего. А еще можем вооружиться методами машинного обучения (ML) и сделать свою собственную карту сокровищ — прогноз для поиска золотых месторождений в любом месте мира. Как всегда, смотрите код и исходные данные (синтетические, конечно, ведь реальные данные — буквально на вес золота!) на GitHub: AU Prediction (ML)
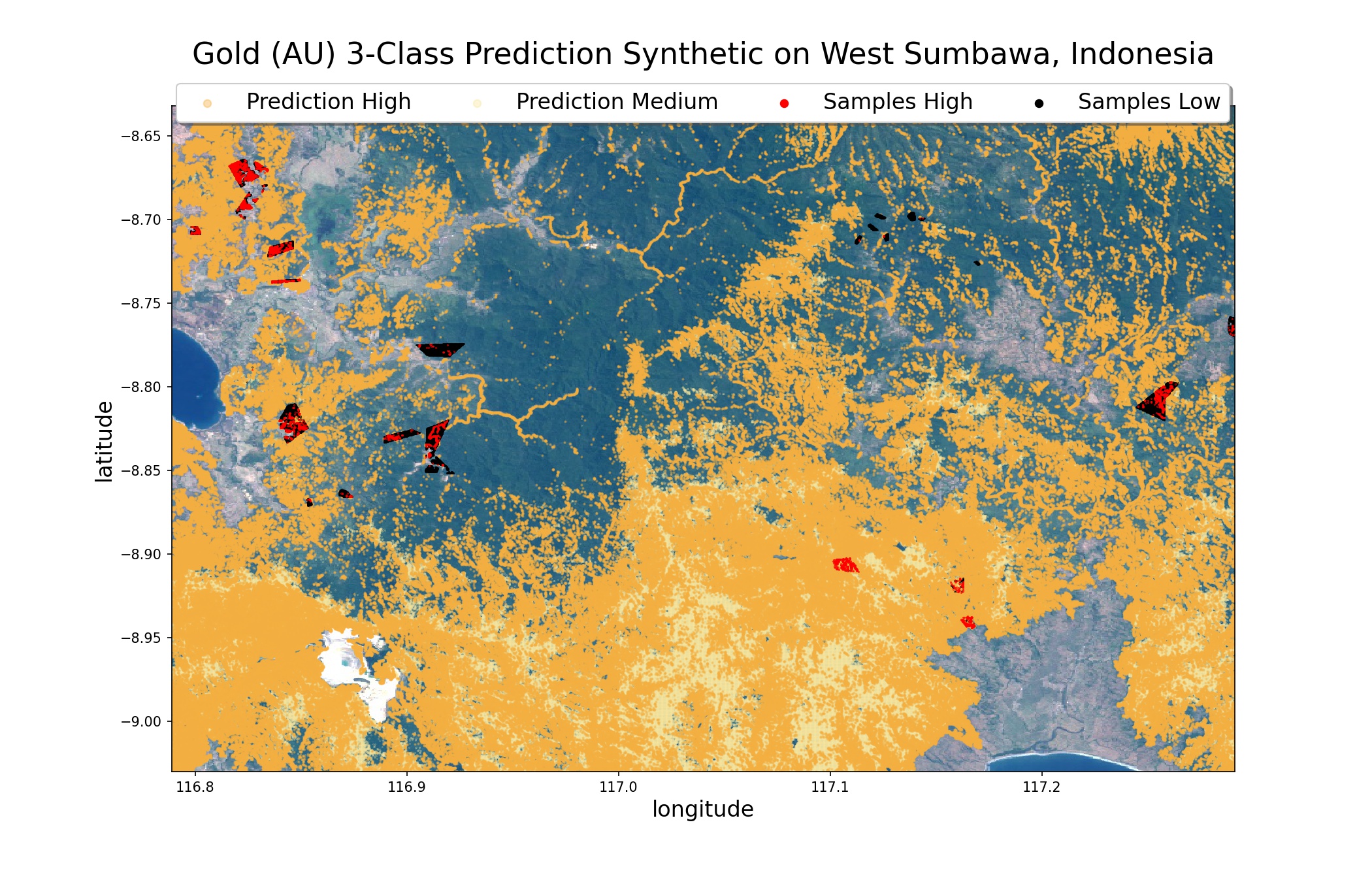
На острове Западная Сумбава с помощью построенного классификатора выделены прогнозируемые золотоносные участки.
Введение
Задача поиска коренных (первичных) и сопутствующих россыпных (вторичных) месторождений по ортофото и космоснимкам давно известна и хорошо изучена. Порядок работы примерно такой: смотрим геологическое строение территории, выбираем те породы, которые содержат интересующие нас минералы, берем для этих пород известные спектральные отклики из соответствующих каталогов и анализируем многоспектральные (или гиперспектральные, если таковые есть) космоснимки в поисках нужных пород и потенциальных месторождений. Если искомых минералов нам нужно много, то ищем непосредственно по их спектральным характеристикам. Можно и самостоятельно спектральные отклики разных минералов составить, если есть данные геохимии. Есть исследования, что спектры отражения минералов за счет их аккумуляции растительностью в листве преобразуются в спектры поглощения и тоже могут быть обнаружены, равно как и повышенное содержание искомых минералов в воде, так что необходима предварительная классификация территории на наличие суши, воды и растительности. При этом нужно помнить, что размер пикселов отличается в разы даже для разных каналов одного снимка, не говоря уж про снимки разных миссий. А еще времена года следует учесть, чтобы не удивляться, почему классификатор растительности для экватора так плохо работает зимой в заснеженной Сибири. Кстати, в краях вечного лета хоть и нет снега, зато присутствует вечная облачность, так что не удаётся найти ни одного полностью безоблачного снимка и нужно делать композитную мозаику, совмещая множество снимков и для каждого пиксела выбирая наилучший по качеству (существует уйма алгоритмов, конечно, но идеального нет).
Вручную (хоть и на компьютере, оксюморон) все это делается, но делается медленно и разными несогласованными методами с несомненным преобладанием человеческого фактора. Хорошо нам знакомая и необходимая итеративная работа невозможна, так как нет автоматизированного способа повторять подготовку данных и их анализ. Для нас задача становится решаемой благодаря наличию доступа к единому многолетнему архиву всех необходимых космических снимков, рельефа и производных от него материалов, а также синхронизированных по времени масок облачности и классификаторов (вода, суша, растительность и других) на Google Earth Engine.
Подготовка данных
Обычно геологи работают с одним или несколькими (выбранными на свой вкус) снимками лишь одной спутниковой миссии, мы воспользуемся техническим преимуществом платформы Google Earth Engine (GEE) и из тысяч доступных космических снимков сделаем качественные композитные растры для разных миссий (Landsat 8, Sentinel 2, ...) и дополним их детальным цифровым рельефом местности и некоторыми его характеристиками.
Остановимся подробнее на том, зачем нужны снимки с разных миссий, хотя и разрешение и спектральные каналы у них более-менее одинаковые. На самом деле, нет — разная оптика и ширина спектральных каналов и алгоритмы обработки обуславливают существенную разницу в результирующих изображениях. Ранее я уже публиковал свои результаты сравнения значений спектральных каналов разных миссий для классов поверхности (земля-вода-растительность) как раз для исследуемой территории: Compare Spectrograms of Hyperspectral and Multispectral Satellite Missions:
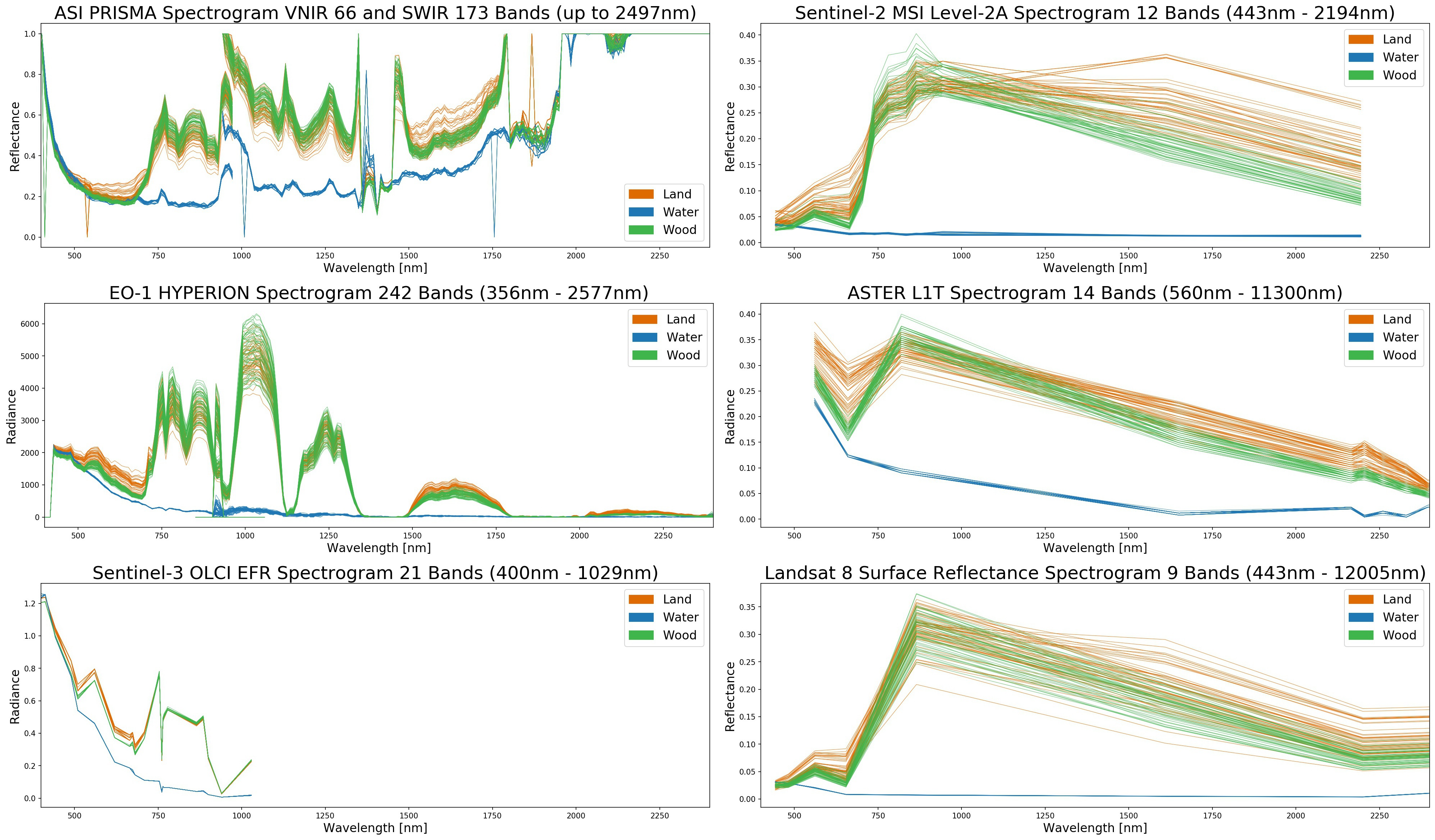
Как оказалось, в зависимости от миссии указанные классы могут как полностью разделяться, так и наоборот. А самая многообещающая гиперспектральные съемка с сотнями спектральных каналов (Гиперион, Призма) отличается низким качеством подавляющего большинства каналов (содержат белый шум, константное значение или артефакты на большей части изображения) и очень выборочным покрытием, так что ее использование на практике весьма ограничено.
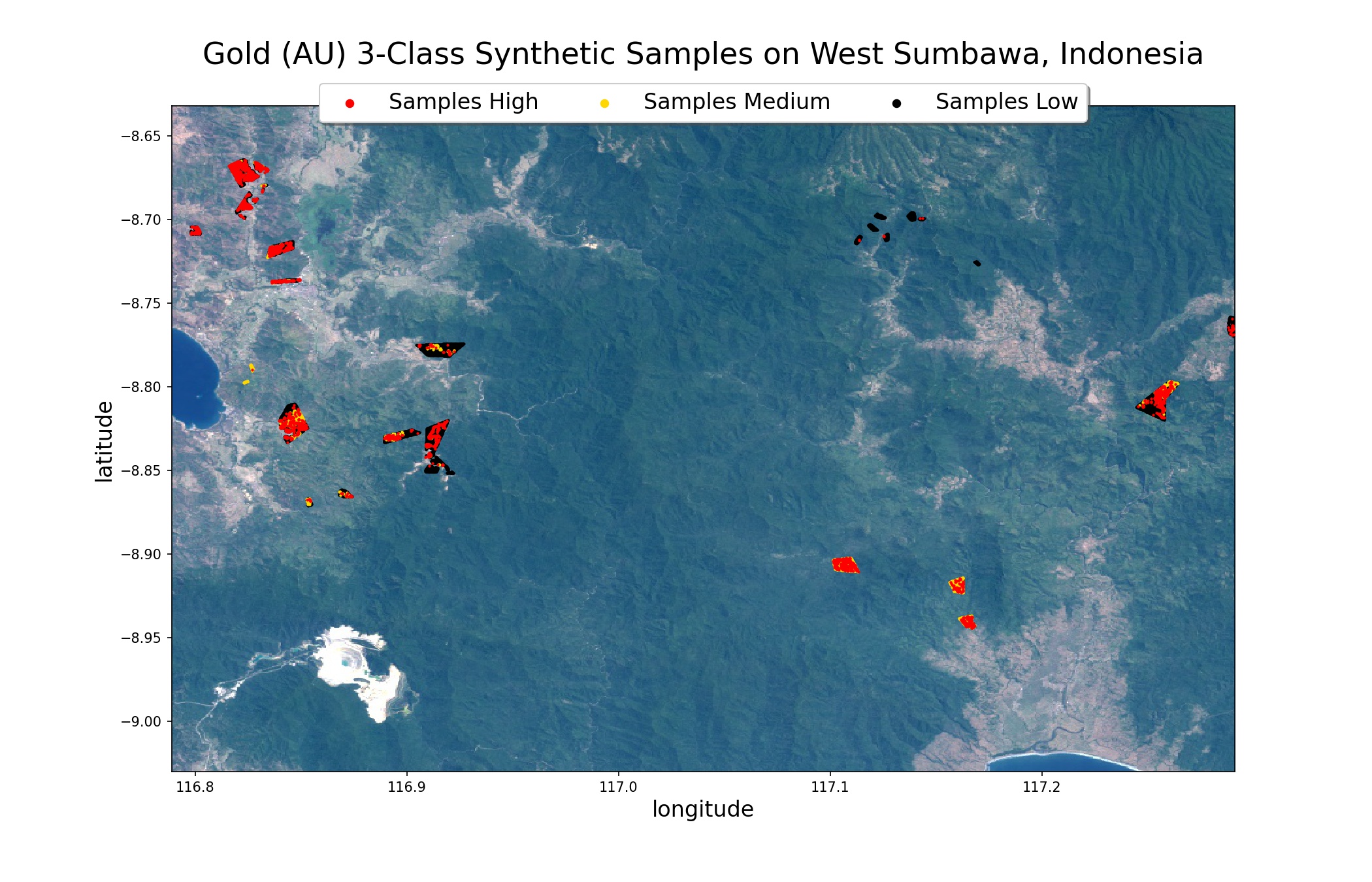
Для обучения классификатора можно использовать данные геохимии с измеренным содержанием минералов в собранных на территории пробах, известные перспективные участки и другие данные. При этом, на один пиксель космического снимка может приходиться целый набор проб от «пустых», с околонулевым содержанием, и до заоблачных «ураганных», словно мы уже нашли Эльдорадо. При подготовке данных приходится учитывать пространственное распределение проб — часто все пробы взяты в перспективных местах, выявленных по результатам предыдущих обследований, так что выборка чрезвычайно искажена, это видно на карте проб. Контуры перспективных участков позволяют получить намного большие выборки для обучения, но здесь мы уже ищем не корреляцию с содержанием минералов, а лишь похожие участки.
Для статьи я подготовил набор синтетических данных samples_synthetic_3class.geojson так, чтобы результаты классификаторов по реальным и синтетическим данным были достаточно схожи. Поскольку этот набор содержит довольно много данных, нам достаточно линейного классификатора.
Построение классификатора и анализ территории
На гитхабе представлено два ноутбука, в первом из которых GEE_export.ipynb подготавливаются и скачиваются необходимые данные с Google Earth Engine, а во втором West Sumbawa AU 3-Class Prediction Synthetic.ipynb выполняется обучение классификатора на полученных растрах и их последующая классификация. В коде даны ссылки на все используемые датасеты GEE, так что, при желании, их несложно заменить на другие. Поскольку использованный линейный классификатор достаточно прост и требует подбора лишь одного параметра, этот подбор выполняется автоматически непосредственно в ноутбуке.
Отмечу, что желательно использовать физические характеристики поверхности — функции от рельефа, отражательную способность для разных длин волн и так далее. Тем не менее, вместо отражающей способности земной поверхности (surface reflectance) для миссии Landsat-8 мы используем данные TOA (top of atmosphere), поскольку для этих спутников SR вычисляется по TOA недостаточно аккуратно и нужная нам корреляция теряется. Для Sentinel-2 такой проблемы нет.
Заключение
Сегодня мы совершили еще одно путешествие в мир обработки пространственных данных и научились майнить настоящее золото (и не только) из данных. В предыдущих статьях я рассказывал, как строить детальные геофизические модели, а сегодня мы обсудили, как быстро найти перспективные участки для последующего детального анализа. Если я соберусь написать следующую статью на эту тему, то в ней мы посмотрим, как использовать классификатор для выделения перспективных золотоносных участков в Сибири и как построить палеорельеф по моделям плотности для изучения и первичных и вторичных месторождений, а также сравним наши результаты с известными лицензионными участками.
P.S. С днем Геолога!


RigelNM
«также сравним наши результаты с известными лицензионными участками.»
Это и хотелось бы увидеть уже в этой статье.
N-Cube Автор
Оценка точности классификации доступна в ноутбуке на гитхабе (96.4%).