
Привет, Хабр! Меня зовут Антон Шкредов, я QA Lead в SuperJob. В День тестировщика хочу поделиться историей о том, как около четырех лет назад мы с командой перешли от ручного тестирования к автоматизации UI и какой профит в итоге получили. Под катом подробности про усталость от ручных тестов, с чего начали автоматизацию, какие инструменты использовали, а также про сложности и бонусы от внедрения.

Немного вводных данных
Дам несколько цифр для общего представления картины: нашим сервисом ежемесячно пользуется более 12 млн людей, в базе более 40 миллионов резюме и каждый год появляется 150 тысяч новых работодателей. SuperJob смело можно назвать высоконагруженным сервисом. Отдел тестирования занимается обеспечением качества основного сервиса SuperJob на всех платформах: Web, Mobile Web, iOS, Android. Но далее речь пойдет только про Web.
Первый этап. С чего мы начинали
Примерно четыре года назад в отделе тестирования SuperJob были только ручные тестировщики, которые даже не подозревали, что настанет день, когда не нужно будет проверять релиз вручную.
На первом этапе у нас вообще не было UI автотестов. Релиз выпускался один раз в неделю, после выполнения приемочного прогона вручную.
На каждую неделю назначался счастливчик дежурный тестировщик, который собственно и отвечал за выпуск релиза. Изменения выкатывались на релизный стенд и тестировщик в TestRail выполнял прогон приемочных тестов, а через два-три дня давал отмашку, что все ОК. И больше мы его никогда не видели. Шутка.

Стоит упомянуть, что все задачи, попавшие в релиз, предварительно тоже тестировались вручную.
Довольно скоро мы поняли, что нужно убирать рутину из нашей работы, к тому же бизнес хотел увеличить частоту выпуска релизов. По этим причинам мы приняли решение автоматизировать приемочное тестирование релиза. С этого начался наш путь от ручного тестирования к автоматизации.
Второй этап: автоматизируем приемочное и релизимся раз в день
В качестве инструментов для автоматизации тестирования мы выбрали Webdriver и Codeception. В то время Webdriver был самым известным на рынке инструментом для автоматизации. Тестовый фреймворк подобрали исходя из языка программирования PHP, на котором написан backend нашего продукта. Все это неслучайно: на данном этапе у нас не было опыта и экспертизы в вопросах автоматизации, поэтому мы много обращались за помощью к нашим разработчикам, чтобы написать сложную функцию или выстроить правильную архитектуру автотестов.
В течение полугода мы определились с фреймворком и языком, один из наших тестировщиков прошел внешние курсы по PHP, мы покрыли приемочное тестирование и начали релизиться один раз в день. Кроме того мы перестали вручную тестировать все задачи подряд, на ручное тестирование остались только новые фичи. Все остальные задачи проверялись уже в релизной ветке.
Прогон автотестов занимал 30 минут, 150 тестов шли одним потоком. А по окончании работы автотестов, дежурный тестировщик отсматривал их результаты и давал команду на выпуск версии.
Приемочное тестирование покрыто и работает автоматически — это уже успех, но нужно двигаться дальше.

Проблемы, с которыми мы остались один на один
На этом этапе у нас все еще оставались проблемы. Мы не могли надеяться только на приемочное тестирование, так как покрытие в 150 тестовых сценариев не охватывало весь сайт целиком. Мы точно могли сказать, что самые важные бизнес-функции работают, но при этом использовали страховку в виде ручного отсмотра задач, вошедших в релиз.
Ручная проверка по прежнему занимала много времени, мы не могли быстро получить обратную связь, и часто баги находились ближе ко времени выпуска релиза. Это могло отложить его или даже отменить, если были обнаружены критичные проблемы.
Ручное тестирование по-прежнему демотивировало тестировщиков, хотя рутины и монотонной работы стало значительно меньше. Плюс добавился стресс от приближающегося времени выпуска релиза. Раньше он мог хотя бы неспеша идти по задачам, а теперь требования бизнеса релизиться один раз в день перечеркнули неторопливые проверки.
Требования бизнеса, оставшиеся ручные проверки, монотонность работы — все это сподвигло нас на внедрение автоматизации на всех циклах работы.
Здесь для нас начался третий этап, который по сути длится до сих пор.
Третий этап: автоматизация регресса, новые инструменты и что у нас получилось
На третьем этапе мы собрали все силы, а также накопленный опыт в кулак и начали автоматизацию регресса.
Для этой задачи мы выбрали новые инструменты: Playwright + CodeceptJS + Allure TestOps.
На выбор инструментов повлияло несколько факторов. Во-первых затормозилось развитие фреймворка Codeception, который мы использовали ранее. Собственно сам автор Codeception стал пилить новый фреймворк — CodeceptJS. Во-вторых, сыграл тренд развития JavaScript и появления инструментов для тестирования на его основе.
Немного истории: сначала появился и активно развивался Puppeteer, который использовал Chrome DevTools. В то время у нас возникли сложные задачи на автоматизацию, а Puppeteer покрывал наши хотелки, поэтому мы стали с ним работать. К примеру, надо было проверять отправку запросов в сервисы сбора аналитики. С использованием Puppeteer данную задачу можно было выполнить непосредственно в самом тесте, использовав только один метод. С помощью WebDriver та же задача требовала разбора HAR логов после выполнения тестов и это было большой болью.
В один прекрасный день вся команда разработки Puppeteer перешла из Google в Microsoft и форкнула Puppeteer. На его основе начала создавать Playwright, который впоследствии и стал нашим основным инструментом для автоматизации тестирования.
По итогам работы мы полностью автоматизировали регрессионное тестирование. Все ручные тест-кейсы из TestRail теперь представляют собой 2500 автотестов, которые проходят за 30 минут в 15 параллельных потоках. Мы релизимся два раза в день.
Пример того, как выглядит наш тест
```
const I = actor();
Feature('Авторизация соискателя')
.tag('@auth');
let user;
Before(async () => {
user = await I.getUser(); // Создание соискателя с помощью тестового API
});
Scenario('Авторизация соискателя на главной', async ({ header, mainPage, authPage }) => {
I.amOnPage(mainPage.url);
I.click(header.button.login);
authPage.fillLoginFormAndSubmit(user.email, user.password);
await I.seeLoggedUserInterface();
}).tag('@acceptance');
```Больше нет никакого ручного отсмотра задач перед релизом. Теперь вручную мы тестируем только новые фичи (новый интерфейс или бизнес-логику), перед тем, как они будут автоматизированы. Все остальное, включая баги и мелкие правки, проверяется автоматически в TeamCity.
Сам процесс устроен таким образом: релиз выпускается два раза в день, первый — в 12:00 часов, при этом изменения от разработки не принимаются с 8:00, второй — в 16:30, изменения фиксируются в 14:00 часов. Автоматика создает ветку, в которой зафиксированы все изменения на dev, и после этого запускается наш регрессионный набор тестов. Примерно через 40 минут результат автотестов приходит в общий канал, где сидят дежурные разработчики и тестировщик.
Пример отчета по тестам
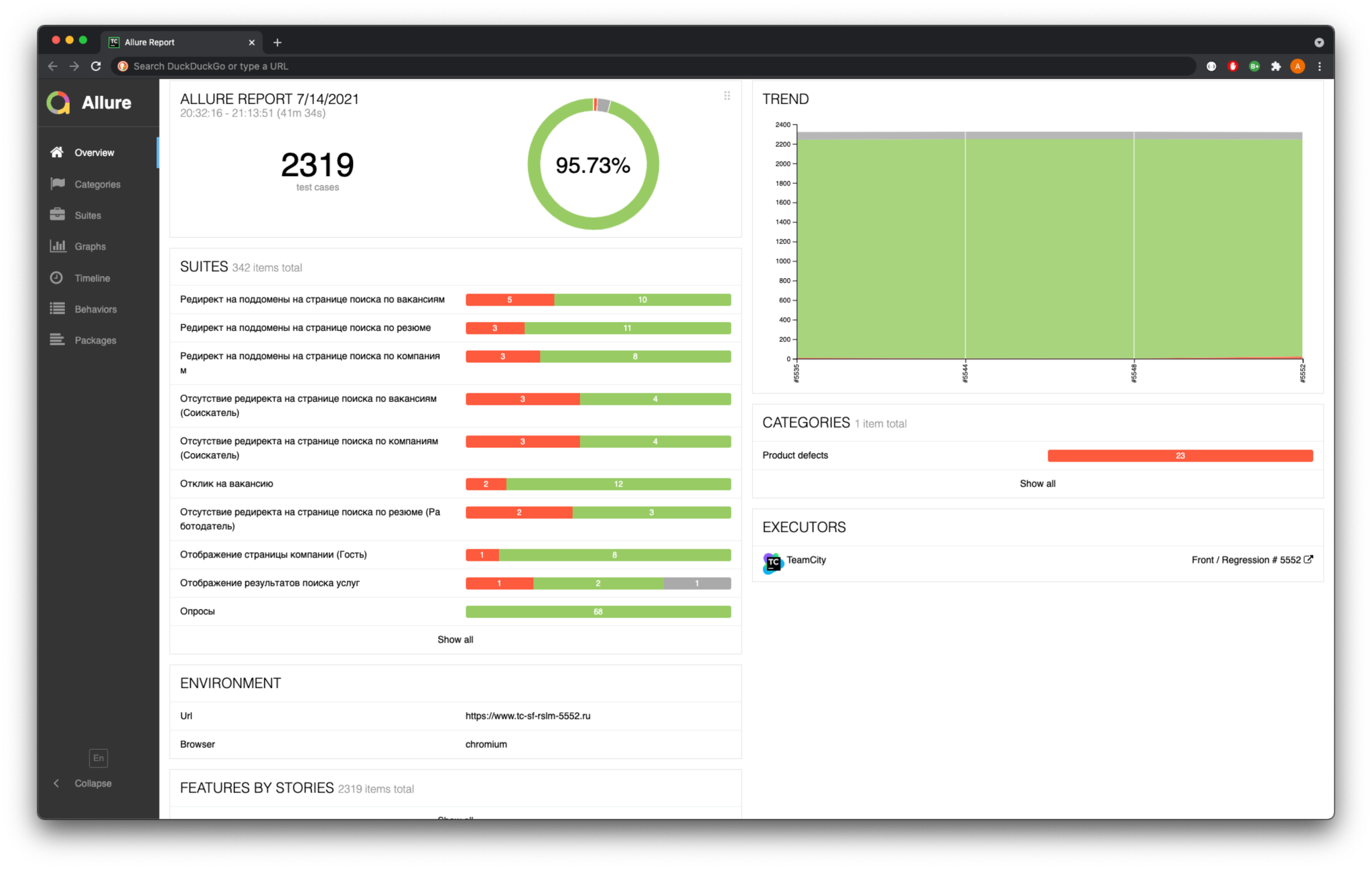
В случае, когда некоторые автотесты упали, дежурный тестировщик проводит разбор. Если находит баг, то переводит задачу на дежурного разработчика. Бывает, что тест упал, потому что произошли изменения в проекте, требующие актуализации теста. В этой ситуации дежурный тестировщик заводит задачу на актуализацию теста и фиксит его.
Два раза в день между релизами на dev мы гоняем регрессионные тесты. Это сделано для того, чтобы оперативно проверять не сломан ли dev, и утром, перед первым релизом, не ломать голову почему все упало, а успеть пофиксить с вечера.
Бонусы от новых инструментов
Все выбранные нами инструменты принесли нам ожидаемые, а иногда и неожиданные бонусы.
После того, как мы стали использовать Playwright вместо WebDriver, мы получили прирост скорости выполнения теста на 20%. И это только за счет смены инструмента. Кстати, на Хабр есть отличная переводная статья, где сравниваются несколько инструментов для автоматизации тестирования, в том числе WebDriver и Playwright.
Значительно облегчило нам жизнь то, что Playwright из коробки поддерживает кроссбраузерность, в отличие от Puppeteer. Про то, как мы пытались использовать кроссбраузерность для WebDriver и вспоминать страшно: это было очень больно, нестабильно и сложно для настройки. Сейчас же тест, который написан для Chrome, сразу работает и для Safari и для Firefox.
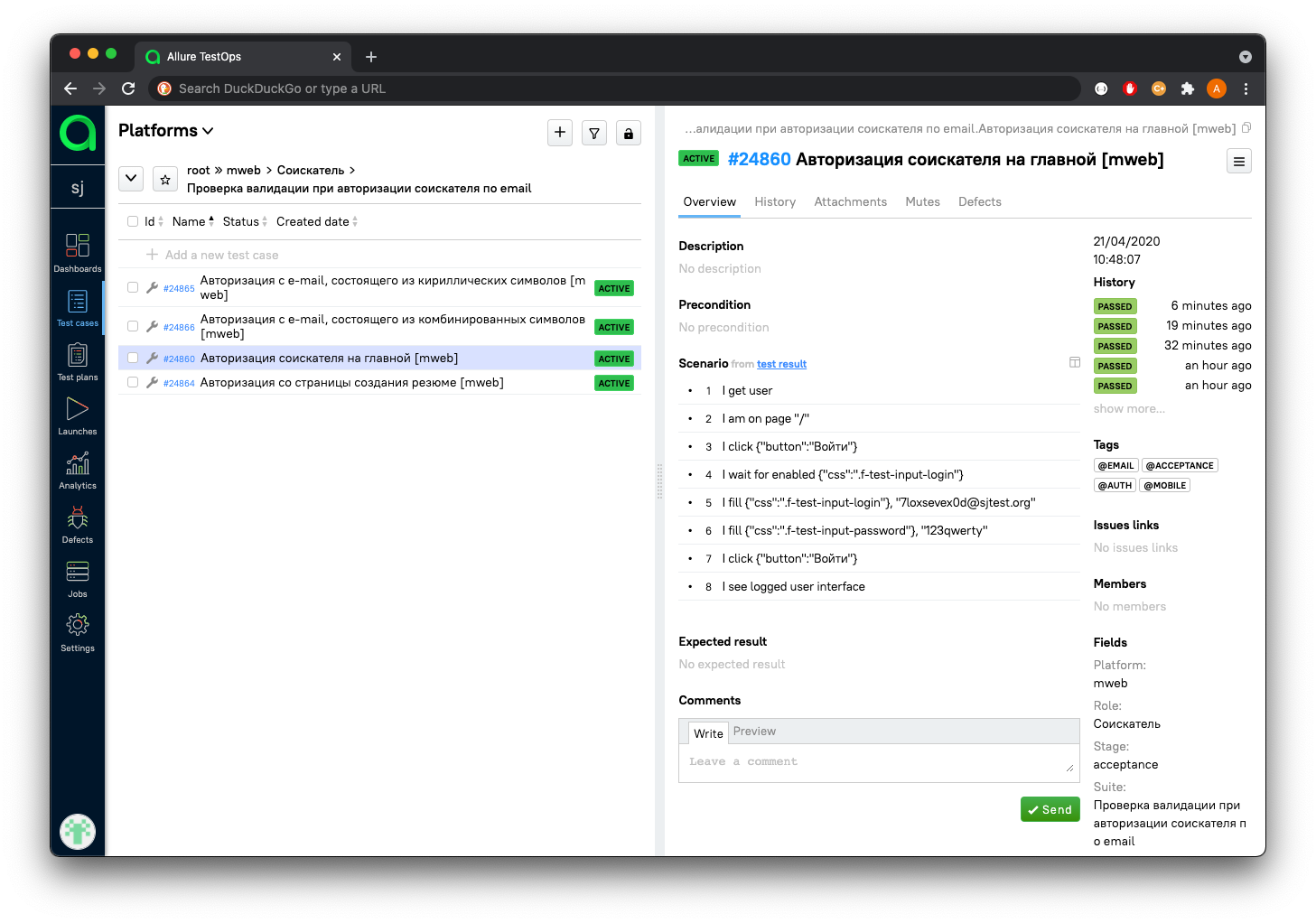
Еще одним приятным бонусом от использования Playwright стали скриншотные проверки. Playwright из коробки умеет скриншотить как всю страницу, так и отдельные элементы на ней, чтобы использовать это в качестве эталонов. Allure в свою очередь умеет удобно показывать разницу между эталоном и результатом теста.
Пример упавшего скриншотного теста

За счет скриншотных проверок мы значительно увеличили область видимости наших тестов и теперь можем ловить баги верстки. Весь релиз отдан на автотесты, а скриншотные проверки работают как дополнительная страховка.
У них конечно есть свои минусы, например, нестабильность, потому что любой интерфейс подвержен изменениям. Но на этот случай мы сделали специальный билд в TeamCity, который обновляет все эталоны. Мы запускаем билд на ветке, для которой требуется обновление скриншотов, и после успешного прохождения тестов, в эту же ветку автоматически прилетает коммит с новыми скринами.
Предновогодняя суета. Сердца требуют перемен и даже логотип нашей компании претерпел изменения. Из-за этого все тесты стали падать, скриншотные проверки не проходили. Тестировщик вручную, обливаясь потом, пыхтел и обновлял сотни скринов. После этой истории мы поняли, что необходимо автоматизировать обновление эталонных скриншотов.
А вот TMS Allure TestOps одним выстрелом убила двух зайцев. Во-первых, она аккумулировала в одном месте все наши билды, т.к. помимо приемочного, в TeamCity появился билд с регрессионным тестированием, билд для Safari и тд. Во-вторых, она заменила нам TestRail. Было важно собрать ручные и автоматизированные кейсы в одной системе, чтобы они не существовали как две разные сущности, а также вести документацию. Теперь после первого успешного прогона новых автотестов в TeamCity, они прилетают в систему Allure TestOps и становятся тестовой документацией.
Отдельной фичей стала перманентная поддержка актуальности документации: дежурный тестировщик фиксит упавший по причине обновления бизнес-логики автотест, а документация по нему автоматически обновляется в Allure TestOps. По итогу получаем всегда актуальную документацию, которую нет необходимости поддерживать отдельно.
Внутреннее обучение
Внедрив автоматизацию, мы получили возможность развивать наших тестировщиков в новом направлении. На втором этапе, когда мы занимались автоматизацией приемочных тестов, нам хватало одного автоматизатора. Но потом стало понятно, что мы планируем встраивать автоматизацию в процесс нашей работы и надо масштабироваться. К тому же, у нас были ребята, которые хотели научиться писать автотесты, а единственный автоматизатор все время обращался к ручным тестировщикам с просьбой поревьюить его автотесты на предмет покрытия.

И тогда мы внедрили внутреннее обучение длительностью три месяца, где тестировщик не только учится писать автотесты и знакомится с инструментами для тестирования, но и изучает JavaScript. В рамках курса мы проходим обучение на Хекслет, и это будет моей личной рекомендацией для всех новичков, которые хотят изучить JS.
Вот так примерно выглядит наш план обучения:
1. Обзор инструментов: CodeceptJS, Playwright.
2. Установка и конфигурация инструментов: CodeceptJS, Playwright.3. Создание и запуск тестов.
4. Фикс и дебаг упавших тестов.
5. Запуск тестов в CI: TeamCity.
6. Отчет о результатах тестирования: Allure.
7. Паттерны проектирования в автоматизации тестирования.
По итогу прохождения обучения, каждый тестировщик стал обладателем своего репозитория с автотестами на GitHub.
Итоги, профит и планы на будущее
Прохождение этого длинного пути к автоматизации тестирования принесло нам отличные результаты:
Быструю обратную связь. Время прохождения регресса уменьшилось с 3 дней до 30 минут.
Покрытие. Ни один тестировщик вручную за 30 минут не проверит 2500 тестовых сценариев и количество тестов продолжает расти.
Скорость доставки фич. Количество релизов увеличилось с 1 раза в неделю до 2 раз в день.
Развитие. Для каждого тестировщика открылась новая область развития в виде автоматизации и появилась возможность применить приобретенные навыки на практике в своем проекте. Новый грейд, в свою очередь, сопровождался прибавкой к ЗП.
Мы понимаем, что автоматизация — лишь одна из составляющих успеха, без активного вклада в процессы, в развитие навыков тестирования, мотивации команды, сбора и анализа метрик по результатам внедрения, она может отъедать ресурсы и ничего не приносить взамен.
Наш процесс непрерывного совершенствования только начинается, мы распространяем наш опыт автоматизации и на другие платформы (iOS и Android), но это заслуживает отдельной темы для разговора, включая выбор инструментов (а выбрали мы XCTest и Kaspresso), а также сложности и решения при работе с мобильными платформами.
Спасибо, что дочитали статью до конца, наша команда подготовила праздничный квест ко Дню тестировщика. Жмите на ссылку, отвечайте на вопросы и делитесь результатами!
Комментарии (5)

Doman
16.11.2021 16:43Спасибо за статью! Скажите, а для чего вам CodeceptJS? Почему бы не использовать сам playwright с их собственным ранером?

melmoth_the_wanderer
16.11.2021 18:32+1Когда выбирали инструмент, playwright вообще не существовал еще. А у CodeceptJS конкурентов можно сказать и не было, все другие фреймворки на JS скорее заточены под unit-тестирование (jest, mocha, ava и т.д.).
Но на новом проекте как раз использовали тестраннер от playwright, он хорош, все задачи выполняет из коробки (вплоть до поддержки allure). Текущие автотесты переписывать уже не стоит, но в новых проектах будем использовать его.
pkuptcov
Спасибо за интересную статью. Расскажите, пожалуйста, следующее:
Во сколько потоков у вас запускаются GUI тесты?
Сколько у вас один инстанс браузера потребляет CPU и RAM?
Запускаете в обычном режиме или в headless? Большая разница по CPU и RAM?
Стабильность тестов выросла после перехода с Selenium Webdriver на Playwright? Если да, то насколько?
Selenoid не поддерживает Playwright. Хватает ли Вам параллельных потоков при прогоне тестов? Что будете делать при масштабировании? Ведь при запуске огромного количества тестов на одной виртуалке из-за создания множества контекстов, наверняка, тесты могут быть флаки в моменты пиковой нагрузки на CPU.
Какими инструментами тестируете API?
melmoth_the_wanderer
Спасибо за интерес к статье и крутые вопросы!
1. Запускаем тесты в 10 потоков, пользуемся встроенной в CodeceptJS фичей. Автотесты у нас атомарные, все завелось очень просто.
2. Сколько один инстанс браузера потребляет сильно зависит от того, что там вертится: посмотрел сейчас — увидел один хром, который использует до 140% одного CPU и порядка 400MB RAM. Количество воркеров лучше всего подтюнить по факту, мы пробовали гонять в разное количество потоков. На нашем железе и на нашем проекте оптимальней всего получилось 10.
3. Тут подход у нас простой, пишем тесты локально в headful-режиме, а в CI гоняем headless, там нам интерфейс ни к чему. Разницу между ними не замеряли.
4. Не могу дать точные цифры, потому что набора одинаковых тестов на 2-х инструментах у нас не было. Точно могу сказать, что стабильность повысилась за счет встроенных ожиданий самого Playwright. Также мы получили возможность добавить осознанности в наши автотесты, за счет доступа ко всем запросам. Например, мы часто ожидаем успешный ответ от бекенда, прежде чем начинать следующий шаг, делать это очень просто. PS: Пользуясь этим подходом, мы также проверяем отправку аналитики, если интересно, то скоро расскажу об этом подробнее здесь.
5. Selenoid довольно сильно нас выручил, когда мы использовали Webdriver, сейчас необходимость в нем пропала. С ростом количества тестов действительно возникает такой вопрос, даже больше скажу, текущие 30 минут для нас тоже много. Скорее всего, сейчас двинемся в сторону импакт-анализа, для более "умной" выборки тестов. Уже есть пара прототипов: как топорный — в виде парсинга коммита и попытки угадать затронутый функционал, так и более дорогой — в виде самописных анализаторов кода.
6. Мы используем Behat для тестов на API и Swagger для документирования. Кстати, недавно прикрутили к Behat-тестам отчет Allure, но пока не выгружаем их в TMS. Одна из задачек на будущее — добавить возможность запуска тестов через Allure TestOps по любой выборке (например, по конкретному эндпоинту) для всех слоев автотестов (в том числе, и UI-тестов на мобилках).