
Traffic_Warning: в статье демонстрируется множество примеров.

Методика тестирования
Обучение алгоритмов производится на относительно ограниченном наборе данных, и на практике рано или поздно встретятся изображения, которые будут неправильно обработаны. Невозможно заранее предсказать ценность алгоритма без тестирования в рамках конкретной задачи, отчётам разработчиков сложно доверять, ведь их задача — «продать» свою работу. Проверка алгоритма должна начинаться с тестирования на данных, которые повстречаются наиболее вероятно. Если первичные результаты удовлетворяют ожиданиям, следует оценить диапазон применимости, подбирая всё более маргинальные варианты. Для оценки качества работы алгоритмов тренированного глаза достаточно, но ради придания статье тончайшего налёта профессионального исследования, сравнение будет сопровождаться количественными оценками.
Алгоритм тестирования:
- Уменьшить эталонное изображение обратно пропорционально коэффициенту увеличения алгоритма (2 или 4 раза).
- «Заапскейлить» уменьшенное изображение тестируемым алгоритмом, а также Lancoz (базовая точка) и Topaz Gigapixel (предыдущий чемпион).
- Проверить адекватность увеличения.
- Проверить детали.
- Вычислить «попугаи».
Cравнить исходное и увеличенное изображения можно разными методами, начиная с квадратичного среднего и заканчивая специализированными нейросетями. Вменяемым выбором был бы MSSIM, поскольку он одновременно самый устойчивый и соответствует человеческому пониманию одинаковости картинок. Но так как чёткость увеличенного изображения формируется за счёт имитации текстур (грубо говоря, подбираются и вырисовываются микрокусочки от других изображений), то MSSIM покажет сильное отличие. Согласитесь, вне научного применения предпочтение получит правдоподобное чёткое изображение, но не математически точное мыло. При обучении нейросетей правдоподобность измеряется выделенной нейросетью, которая умеет оценивать реалистичность и качество. Но демонстрация циферок от чёрных ящиков не вызовет доверия, если только это не какой-то стандарт. Из оценок такого типа общепризнанным является VMAF, которую использует Netflix для подбора оптимальных настроек передачи и хранения видеопотоков. Эта интегральная оценка учитывает степень сходства оригинального и изменённого изображения и набор показателей качества картинки.
Кроме того, будут использоваться следующие косвенные оценки:
- «Резкость». Очень простая оценка, которая является аналогом второй производной. Чем более размыто изображение, тем меньше в нём резких переходов значений.
- Энтропия текстур. Мутноватая штука, но если на пальцах, то это показатель сложности «раскраски» поверхностей (запомнить цвет покрашенной стены проще, чем узор обоев).
- Размер файла PNG. Колхозная оценка общей энтропии изображения, чем больше размер файла, тем больше деталей в картинке.
Тестирование апскейла
В рамках проекта Real-ESRGAN доступно несколько предобученных моделей:
- RealESRGAN_x4plus — для общего применения, увеличение 4х
- RealESRNet_x4plus — устаревшая модель для общего применения, увеличение 4х
- RealESRGAN_x4plus_anime_6B — для рисованных изображений, увеличение 4х
- RealESRGAN_x2plus — для общего применения, увеличение 2х
- official ESRGAN_x4 — модель, использовавшаяся для публикации официальных результатов, увеличение 4х
Для тестирования подобраны изображения, которые представляют широкий диапазон того, что может пожелать заапскейлить среднестатистический землянин. Средний размер изображений после уменьшения в четыре раза составляет 350х250 пикселей. Бóльшая сторона исходных изображений имеет длину в диапазоне от 1200 до 2000 пикселей, приводить их целиком неуместно, поэтому только ссылки и уменьшенные версии.
Для проверки использована модель ESRGAN_SRx4_DF2KOST_official-ff704c30, которая субъективно превосходит прочие.
▍ Тестовое изображение «sample01»
Уменьшение 4x ➟ 300x200

- Оригинал 1200x800
- Интерполяция Lancoz 300x200 ➟ 1200x800
- Апскейл Gigapixel 300x200 ➟ 1200x800
- Апскейл RealESRGAN 300x200 ➟ 1200x800
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample02»
Уменьшение 4x ➟ 350x231

- Оригинал 1400x922
- Интерполяция Lancoz 350x231 ➟ 1400x924
- Апскейл Gigapixel 350x231 ➟ 1400x924
- Апскейл RealESRGAN 350x231 ➟ 1400x924
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample03»
Уменьшение 4x ➟ 320x180

- Оригинал 1280x720
- Интерполяция Lancoz 320x180 ➟ 1280x720
- Апскейл Gigapixel 320x180 ➟ 1280x720
- Апскейл RealESRGAN 320x180 ➟ 1280x720
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample04»
Уменьшение 4x ➟ 350x232

- Оригинал 1400x929
- Интерполяция Lancoz 350x232 ➟ 1400x928
- Апскейл Gigapixel 350x232 ➟ 1400x928
- Апскейл RealESRGAN 350x232 ➟ 1400x928
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample05»
Уменьшение 4x ➟ 300x201

- Оригинал 1200x802
- Интерполяция Lancoz 300x201 ➟ 1200x804
- Апскейл Gigapixel 300x201 ➟ 1200x804
- Апскейл RealESRGAN 300x201 ➟ 1200x804
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample06»
Уменьшение 4x ➟ 238x128

- Оригинал 950x512
- Интерполяция Lancoz 238x128 ➟ 952x512
- Апскейл Gigapixel 238x128 ➟ 952x512
- Апскейл RealESRGAN 238x128 ➟ 952x512
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample07»
Уменьшение 4x ➟ 250x167

- Оригинал 1000x667
- Интерполяция Lancoz 250x167 ➟ 1000x668
- Апскейл Gigapixel 250x167 ➟ 1000x668
- Апскейл RealESRGAN 250x167 ➟ 1000x668
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample08»
Уменьшение 4x ➟ 300x200

- Оригинал 1200x800
- Интерполяция Lancoz 300x200 ➟ 1200x800
- Апскейл Gigapixel 300x200 ➟ 1200x800
- Апскейл RealESRGAN 300x200 ➟ 1200x800
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample09»
Уменьшение 4x ➟ 350x350

- Оригинал 1400x1400
- Интерполяция Lancoz 350x350 ➟ 1400x1400
- Апскейл Gigapixel 350x350 ➟ 1400x1400
- Апскейл RealESRGAN 350x350 ➟ 1400x1400
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample10»
Уменьшение 4x ➟ 375x250

- Оригинал 1500x1000
- Интерполяция Lancoz 375x250 ➟ 1500x1000
- Апскейл Gigapixel 375x250 ➟ 1500x1000
- Апскейл RealESRGAN 375x250 ➟ 1500x1000
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample11»
Уменьшение 4x ➟ 405x270

- Оригинал 1620x1080
- Интерполяция Lancoz 405x270 ➟ 1620x1080
- Апскейл Gigapixel 405x270 ➟ 1620x1080
- Апскейл RealESRGAN 405x270 ➟ 1620x1080
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample12»
Уменьшение 4x ➟ 450x300

- Оригинал 1800x1200
- Интерполяция Lancoz 450x300 ➟ 1800x1200
- Апскейл Gigapixel 450x300 ➟ 1800x1200
- Апскейл RealESRGAN 450x300 ➟ 1800x1200
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample13»
Уменьшение 4x ➟ 320x213

- Оригинал 1280x852
- Интерполяция Lancoz 320x213 ➟ 1280x852
- Апскейл Gigapixel 320x213 ➟ 1280x852
- Апскейл RealESRGAN 320x213 ➟ 1280x852
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample14»
Уменьшение 4x ➟ 272x181

- Оригинал 1087x725
- Интерполяция Lancoz 272x181 ➟ 1088x724
- Апскейл Gigapixel 272x181 ➟ 1088x724
- Апскейл RealESRGAN 272x181 ➟ 1088x724
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample15»
Уменьшение 4x ➟ 300x200

- Оригинал 1200x800
- Интерполяция Lancoz 300x200 ➟ 1200x800
- Апскейл Gigapixel 300x200 ➟ 1200x800
- Апскейл RealESRGAN 300x200 ➟ 1200x800
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample16»
Уменьшение 4x ➟ 280x280

- Оригинал 1120x1120
- Интерполяция Lancoz 280x280 ➟ 1120x1120
- Апскейл Gigapixel 280x280 ➟ 1120x1120
- Апскейл RealESRGAN 280x280 ➟ 1120x1120
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample17»
Уменьшение 4x ➟ 320x180

- Оригинал 1280x720
- Интерполяция Lancoz 320x180 ➟ 1280x720
- Апскейл Gigapixel 320x180 ➟ 1280x720
- Апскейл RealESRGAN 320x180 ➟ 1280x720
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample18»
Уменьшение 4x ➟ 512x341

- Оригинал 2048x1365
- Интерполяция Lancoz 512x341 ➟ 2048x1364
- Апскейл Gigapixel 512x341 ➟ 2048x1364
- Апскейл RealESRGAN 512x341 ➟ 2048x1364
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample19»
Уменьшение 4x ➟ 267x200

- Оригинал 1066x800
- Интерполяция Lancoz 267x200 ➟ 1066x800
- Апскейл Gigapixel 267x200 ➟ 1066x800
- Апскейл RealESRGAN 267x200 ➟ 1066x800
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample20»
Уменьшение 4x ➟ 350x350

- Оригинал 1400x1400
- Интерполяция Lancoz 350x350 ➟ 1400x1400
- Апскейл Gigapixel 350x350 ➟ 1400x1400
- Апскейл RealESRGAN 350x350 ➟ 1400x1400
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample21»
Уменьшение 4x ➟ 256x205

- Оригинал 1024x819
- Интерполяция Lancoz 256x205 ➟ 1024x820
- Апскейл Gigapixel 256x205 ➟ 1024x820
- Апскейл RealESRGAN 256x205 ➟ 1024x820
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
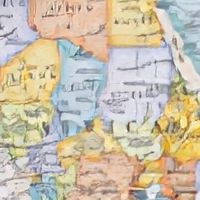 |
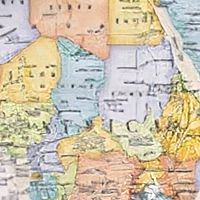 |
 |
 |
 |
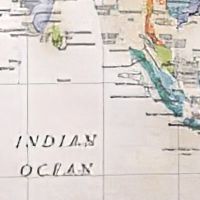 |
 |
▍ Тестовое изображение «sample22»
Уменьшение 4x ➟ 250x167

- Оригинал 1000x667
- Интерполяция Lancoz 250x167 ➟ 1000x668
- Апскейл Gigapixel 250x167 ➟ 1000x668
- Апскейл RealESRGAN 250x167 ➟ 1000x668
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
▍ Тестовое изображение «sample23»
Уменьшение 4x ➟ 512x341

- Оригинал 2048x1364
- Интерполяция Lancoz 512x341 ➟ 2048x1364
- Апскейл Gigapixel 512x341 ➟ 2048x1364
- Апскейл RealESRGAN 512x341 ➟ 2048x1364
| Lancoz | Gigapixel | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
*конец спойлера*
Далее будут таблицы с измерениями, но перед этим приведу примеры, которые наглядно продемонстрируют, как зависят значения от картинки.
| Изображение | VMAF | Резкость | Энтропия Т | Размер PNG |
|---|---|---|---|---|
Эталон
|
- | 13.43 | 35.100 | 86192 |
Смешивание двух изображений
|
0 | 14.30 | 34.630 | 91211 |
Легкое размытие
|
76.202 | 9.089 | 34.630 | 73769 |
Очень сильное размытие
|
0 | 0.585 | 25.425 | 31142 |
Небольшое добавление шума
|
71.508 | 14.44 | 38.98 | 112848 |
Только шум
|
5.023 | 22.24 | 46.34 | 152585 |
| Резкость | Энтропия Т | |||||||
|---|---|---|---|---|---|---|---|---|
| Изображение | Lncz | Ggpxl | RlSRGN | ориг. | Lncz | Ggpxl | RlSRGN | ориг. |
| sample01 | 4.808 | 9.987 | 10.91 | 13.38 | 34.404 | 35.458 | 35.934 | 36.183 |
| sample02 | 6.877 | 13.98 | 15.80 | 14.05 | 34.710 | 36.845 | 37.279 | 36.969 |
| sample03 | 4.006 | 8.985 | 9.579 | 10.66 | 34.581 | 36.657 | 37.550 | 37.464 |
| sample04 | 4.642 | 9.566 | 10.11 | 9.958 | 34.941 | 36.167 | 37.314 | 36.648 |
| sample05 | 3.279 | 8.140 | 7.852 | 8.600 | 33.012 | 34.206 | 34.449 | 34.100 |
| sample06 | 3.700 | 8.862 | 9.285 | 8.695 | 33.070 | 34.277 | 36.042 | 35.576 |
| sample07 | 3.912 | 10.43 | 14.94 | 11.68 | 29.422 | 31.893 | 35.169 | 33.416 |
| sample08 | 2.535 | 6.782 | 8.809 | 7.996 | 30.850 | 32.649 | 34.398 | 33.193 |
| sample09 | 3.318 | 9.598 | 9.974 | 9.736 | 26.678 | 28.092 | 29.321 | 28.086 |
| sample10 | 3.743 | 9.340 | 10.53 | 11.22 | 33.454 | 34.953 | 36.421 | 35.981 |
| sample11 | 4.061 | 8.909 | 9.631 | 8.728 | 32.131 | 33.907 | 35.637 | 35.230 |
| sample12 | 3.427 | 9.246 | 9.610 | 10.08 | 28.949 | 30.486 | 31.718 | 30.553 |
| sample13 | 2.153 | 6.405 | 6.647 | 7.666 | 29.660 | 30.980 | 31.623 | 31.214 |
| sample14 | 4.574 | 10.64 | 12.10 | 10.14 | 32.805 | 34.507 | 36.684 | 35.553 |
| sample15 | 3.872 | 9.374 | 9.971 | 9.030 | 32.555 | 34.075 | 36.128 | 34.956 |
| sample16 | 5.298 | 12.82 | 16.91 | 15.43 | 33.018 | 36.027 | 39.132 | 37.246 |
| sample17 | 4.396 | 9.462 | 9.781 | 11.78 | 31.430 | 33.032 | 33.470 | 32.714 |
| sample18 | 1.973 | 6.046 | 6.666 | 6.379 | 31.289 | 32.273 | 33.677 | 32.201 |
| sample19 | 4.602 | 11.57 | 13.21 | 13.82 | 32.734 | 34.925 | 36.793 | 35.987 |
| sample20 | 4.096 | 9.534 | 10.77 | 11.86 | 32.727 | 34.067 | 34.739 | 35.467 |
| sample21 | 5.177 | 12.22 | 13.77 | 14.71 | 33.251 | 35.719 | 37.279 | 37.607 |
| sample22 | 4.121 | 11.08 | 13.88 | 12.50 | 33.594 | 36.068 | 38.204 | 36.590 |
| sample23 | 4.695 | 11.91 | 16.39 | 15.49 | 31.826 | 36.248 | 39.623 | 38.458 |
| Размер PNG | VMAF | ||||||
|---|---|---|---|---|---|---|---|
| Изображение | Lncz | Ggpxl | RlSRGN | ориг. | Lncz | Ggpxl | RlSRGN |
| sample01 | 1040909 | 1533964 | 1593418 | 1486472 | 57.8 | 45.1 | 46.8 |
| sample02 | 1606323 | 2560961 | 2708832 | 2234673 | 50.5 | 41.0 | 45.6 |
| sample03 | 894173 | 1714758 | 1813965 | 1210865 | 60.9 | 54.4 | 55.9 |
| sample04 | 1311025 | 2081947 | 2278960 | 1846145 | 65.6 | 56.4 | 57.4 |
| sample05 | 849558 | 1416970 | 1456258 | 1172864 | 68.6 | 63.9 | 63.0 |
| sample06 | 452241 | 745710 | 842382 | 695724 | 68.1 | 65.1 | 66.6 |
| sample07 | 482440 | 936809 | 1195696 | 1038522 | 58.3 | 60.0 | 60.9 |
| sample08 | 765887 | 1424501 | 1621607 | 1235084 | 72.7 | 63.7 | 63.4 |
| sample09 | 1123533 | 2141817 | 2400667 | 1710914 | 55.3 | 59.3 | 62.4 |
| sample10 | 1278387 | 2355468 | 2637193 | 1963767 | 63.2 | 58.2 | 59.7 |
| sample11 | 1612505 | 2786874 | 3151952 | 2524981 | 78.4 | 65.9 | 66.6 |
| sample12 | 1169958 | 2264390 | 2588812 | 1824693 | 61.9 | 66.5 | 69.8 |
| sample13 | 590845 | 1296764 | 1380995 | 903423 | 74.8 | 74.3 | 73.2 |
| sample14 | 776364 | 1245854 | 1472989 | 1226939 | 58.6 | 52.0 | 55.2 |
| sample15 | 866486 | 1400401 | 1605220 | 1332608 | 69.6 | 64.5 | 65.5 |
| sample16 | 1310238 | 2125275 | 2608758 | 2096532 | 39.1 | 29.7 | 33.0 |
| sample17 | 698017 | 1249952 | 1280725 | 937598 | 56.2 | 54.2 | 56.7 |
| sample18 | 1732631 | 3292749 | 3752564 | 2892373 | 78.8 | 75.3 | 76.0 |
| sample19 | 738134 | 1293668 | 1464700 | 1108550 | 48.2 | 41.9 | 44.7 |
| sample20 | 1685835 | 2837290 | 3088802 | 2529888 | 56.9 | 51.4 | 53.6 |
| sample21 | 907662 | 1505524 | 1665626 | 1438411 | 47.0 | 39.6 | 42.6 |
| sample22 | 648045 | 1098574 | 1285524 | 1041852 | 56.5 | 49.0 | 53.1 |
| sample23 | 2908706 | 4989519 | 6136962 | 5476397 | 45.0 | 36.0 | 37.4 |
▍ Далее проверяем режим увеличения рисованных изображений
В качестве алгоритма для сравнения был выбран Waifu, который долгое время считался стандартом. Не имею дела с рисованной анимацией, поэтому могу только эмпирически предположить, что сейчас топовым алгоритмом является Anime4k. На примерах в интернете не наблюдается значительной разницы между Anime4k и RealESRGAN, поэтому в тестировании Anime4k не используется (нет смысла устанавливать ради нескольких картинок).
Уменьшение 4x ➟ 300x200

- Оригинал 1200x800
- Интерполяция Lancoz 300x200 ➟ 1200x800
- Апскейл Waifu 300x200 ➟ 1200x800
- Апскейл RealESRGAN 300x200 ➟ 1200x800
| Lancoz | Waifu | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |

- Оригинал 1200x900
- Интерполяция Lancoz 300x225 ➟ 1200x900
- Апскейл Waifu 300x225 ➟ 1200x900
- Апскейл RealESRGAN 300x225 ➟ 1200x900
| Lancoz | Waifu | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Уменьшение 4x ➟ 256x379

- Оригинал 1024x1514
- Интерполяция Lancoz 256x379 ➟ 1024x1514
- Апскейл Waifu 256x379 ➟ 1024x1514
- Апскейл RealESRGAN 256x379 ➟ 1024x1514
| Lancoz | Waifu | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
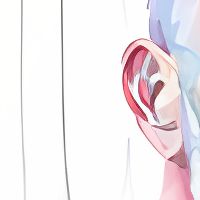
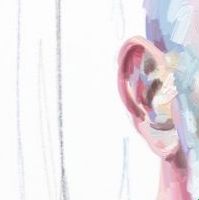
Уменьшение 4x ➟ 203x311

- Оригинал 810x1245
- Интерполяция Lancoz 203x311 ➟ 812x1244
- Апскейл Waifu 203x311 ➟ 812x1244
- Апскейл RealESRGAN 203x311 ➟ 812x1244
| Lancoz | Waifu | RealESRGAN | Оригинал |
|---|---|---|---|
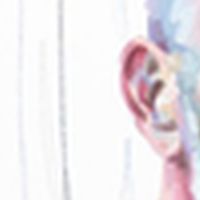 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Уменьшение 4x ➟ 375x211

- Оригинал 1500x844
- Интерполяция Lancoz 375x211 ➟ 1500x844
- Апскейл Waifu 375x211 ➟ 1500x844
- Апскейл RealESRGAN 375x211 ➟ 1500x844
| Lancoz | Waifu | RealESRGAN | Оригинал |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Специально для простых смертных существует версия RealESRGAN, упакованная в один файл, которая не требует установки вспомогательных библиотек.
Ссылки под разные ОС:
Портативная версия использует модели в своём формате, в комплекте есть следующие:
- realesrgan-x4plus (для общего применения)
- realesrnet-x4plus (устаревшая модель для общего применения)
- realesrgan-x4plus-anime (для рисованных изображений)
Самая мощная модель, аналогичная той, что использовалась в данном сравнении, лежит почему-то в другом месте:
- models-DF2K — это «official ESRGAN_x4»
- models-DF2K_JPEG — это та же модель, но способная переносить сильно сжатые JPEG. Пригодится, если на других моделях результат разваливается в мозаику.
Файлы моделей следует поместить в каталог ./models, переименовав по примеру содержимого.
Командная строка для запуска с дефолтной моделью realesrgan-x4plus:
realesrgan-ncnn-vulkan.exe -i dir_in -o dir_out -j 1:1:2
Для переключения модели нужно добавлять специальный ключ: "-n realesrgan-x4plus-anime",
"-n df2k-x4"
GFPGAN
Решение GFPGAN предназначено для восстановления детализации лиц с изображений низкого разрешения.
Существуют две модели:
- GFPGANCleanv1-NoCE-C2 — упрощённая модель
- GFPGANv1 — сложная модель
Сложная модель рисует настоящее лицо с фотографической точностью. У неё есть три проблемы:
- Требует дополнительной мороки с установкой.
- Не подстраивается под освещение фотографии.
- Почти всегда искажает цвет области вокруг лица, то есть нужно допиливать в фотошопе.
Простая модель соответственно не имеет таких проблем, но качество её работы заметно ниже.
Ради эксперимента проверим, что будет, если запустить алгоритм на хорошем разрешении.
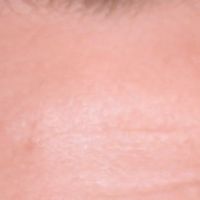
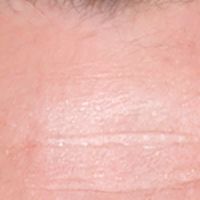
Уменьшение 2x ➟ 512x512

- Оригинал 1024x1024
- Апскейл RealESRGAN 512x512 ➟ 2048x2048 -Lancoz➟ 1024x1024
- Улучшение GFPGAN модель cleanV1 512x512 ➟ 1024x1024
- Улучшение GFPGAN модель V1 512x512 ➟ 1024x1024
- Улучшение Remini 512x512 ➟ 1024x1024
| GFPGAN_cl | GFPGAN_v1 | RealESRGAN | Remini |
|---|---|---|---|
 |
 |
 |
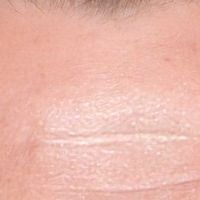 |
 |
 |
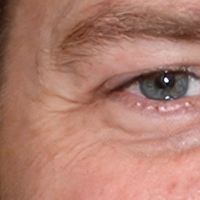 |
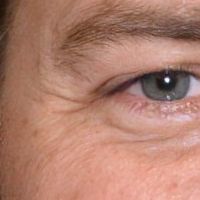 |
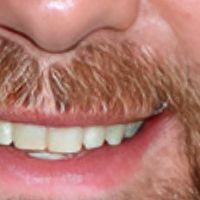 |
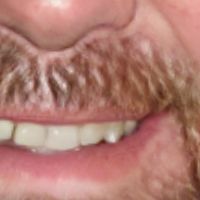 |
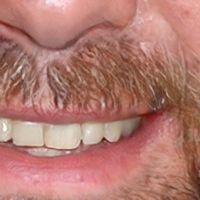 |
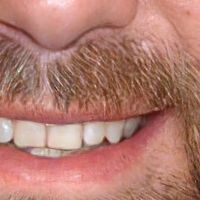 |
Теперь проверим: насколько малое изображение сможет восстановить алгоритм.
 |
 |
 |
 |
 |
 |
| Оригинал | GFPGAN_v1 |
|---|---|
 |
 |
 |
 |
 |
 |
Похожесть на оригинал сохраняется на очень низком разрешении, соотношение 10 раз! А если хочется большего разрешения чем 512х512 (фиксированный размер на выходе генератора лиц), можно пропустить последовательно через RealESRGAN и Remini.

Теперь протестируем возможности восстановления лиц на чём-нибудь практически значимом.
Апскейл приводится как исходная точка. Сравнивать будем с работой MS restore, который был лучшим из открытых алгоритмов восстановления лиц.

- Улучшение MS restore ➟ Апскейл RealESRGAN 537x824 ➟ 1074x1648
- Улучшение GFPGAN модель cleanV1 537x824 ➟ 1074x1648
- Улучшение GFPGAN модель V1 537x824 ➟ 1074x1648
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 482x615 ➟ 964x1230
- Улучшение GFPGAN модель cleanV1 482x615 ➟ 964x1230
- Улучшение GFPGAN модель V1 482x615 ➟ 964x1230
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |
Все эти изображения являются дагерротипами из коллекции конгресса США, их точной датировки нет, примерная охватывает 1840-1860 гг.
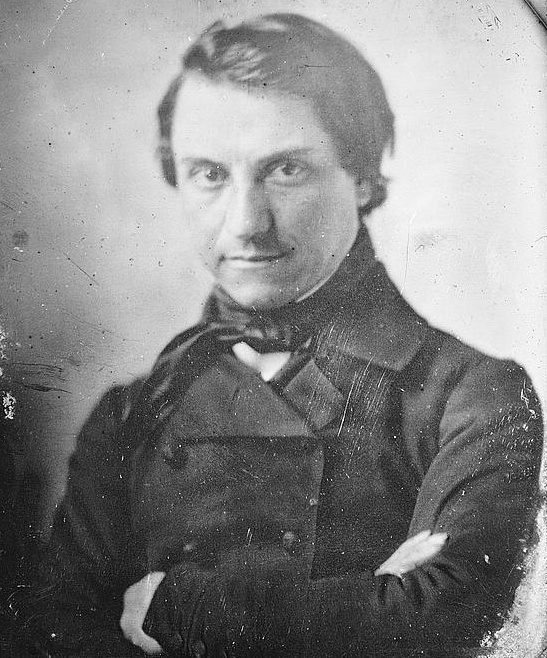
- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 640x496 ➟ 1280x992
- Улучшение GFPGAN модель cleanV1 640x496 ➟ 1280x992
- Улучшение GFPGAN модель V1 640x496 ➟ 1280x992
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 523x753 ➟ 1046x1506
- Улучшение GFPGAN модель cleanV1 523x753 ➟ 1046x1506
- Улучшение GFPGAN модель V1 523x753 ➟ 1046x1506
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |
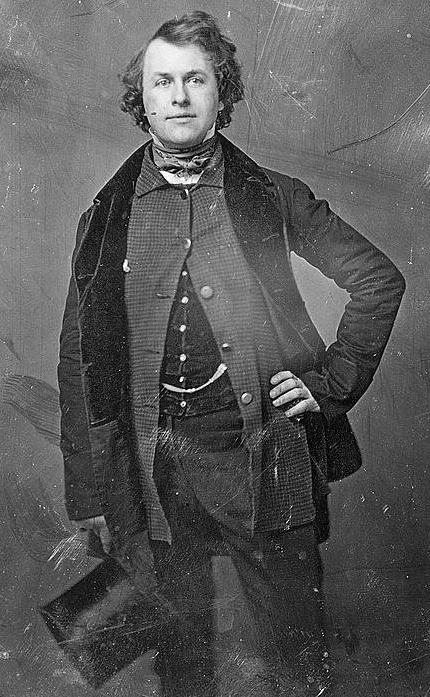
- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 430x697 ➟ 860x1394
- Улучшение GFPGAN модель cleanV1 430x697 ➟ 860x1394
- Улучшение GFPGAN модель V1 430x697 ➟ 860x1394
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 618x624 ➟ 1236x1248
- Улучшение GFPGAN модель cleanV1 618x624 ➟ 1236x1248
- Улучшение GFPGAN модель V1 618x624 ➟ 1236x1248
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 533x668 ➟ 1066x1336
- Улучшение GFPGAN модель cleanV1 533x668 ➟ 1066x1336
- Улучшение GFPGAN модель V1 533x668 ➟ 1066x1336
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 585x729 ➟ 1170x1458
- Улучшение GFPGAN модель cleanV1 585x729 ➟ 1170x1458
- Улучшение GFPGAN модель V1 585x729 ➟ 1170x1458
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |
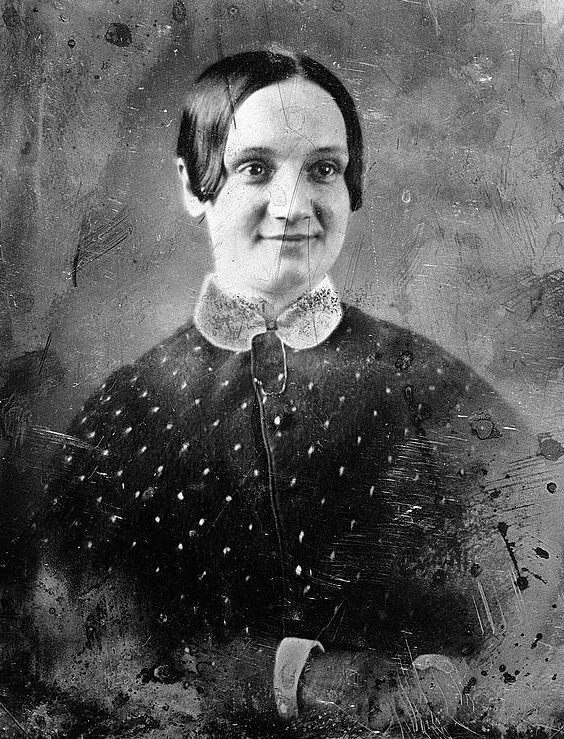
- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 564x739 ➟ 1128x1478
- Улучшение GFPGAN модель cleanV1 564x739 ➟ 1128x1478
- Улучшение GFPGAN модель V1 564x739 ➟ 1128x1478
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 597x747 ➟ 1194x1494
- Улучшение GFPGAN модель cleanV1 597x747 ➟ 1194x1494
- Улучшение GFPGAN модель V1 597x747 ➟ 1194x1494
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 577x736 ➟ 1154x1472
- Улучшение GFPGAN модель cleanV1 577x736 ➟ 1154x1472
- Улучшение GFPGAN модель V1 577x736 ➟ 1154x1472
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 742x538 ➟ 1484x1076
- Улучшение GFPGAN модель cleanV1 742x538 ➟ 1484x1076
- Улучшение GFPGAN модель V1 742x538 ➟ 1484x1076
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
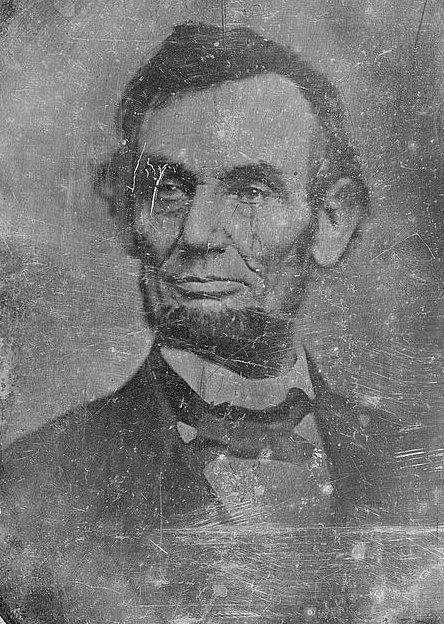
- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 444x624 ➟ 888x1248
- Улучшение GFPGAN модель cleanV1 444x624 ➟ 888x1248
- Улучшение GFPGAN модель V1 444x624 ➟ 888x1248
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 482x615 ➟ 964x1230
- Улучшение GFPGAN модель cleanV1 482x615 ➟ 964x1230
- Улучшение GFPGAN модель V1 482x615 ➟ 964x1230
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 614x822 ➟ 1228x1644
- Улучшение GFPGAN модель cleanV1 614x822 ➟ 1228x1644
- Улучшение GFPGAN модель V1 614x822 ➟ 1228x1644
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |

- Улучшение MS restore ➟ Апскейл RealESRGAN ➟ 565x780 ➟ 1130x1560
- Улучшение GFPGAN модель cleanV1 565x780 ➟ 1130x1560
- Улучшение GFPGAN модель V1 565x780 ➟ 1130x1560
| RealESRGAN | MS_restore | GFPGAN_cl | GFPGAN_v1 |
|---|---|---|---|
 |
 |
 |
 |
Бонусы
Для собственного удовольствия захотелось сделать цветные версии с помощью штуки из прошлой статьи. Пришлось сутки ждать пока она нагенерирует по 20 вариантов раскраски для каждой фотографии, выбирать удачные детали и стыковать в фотошопе.
Большие картинки по клику.










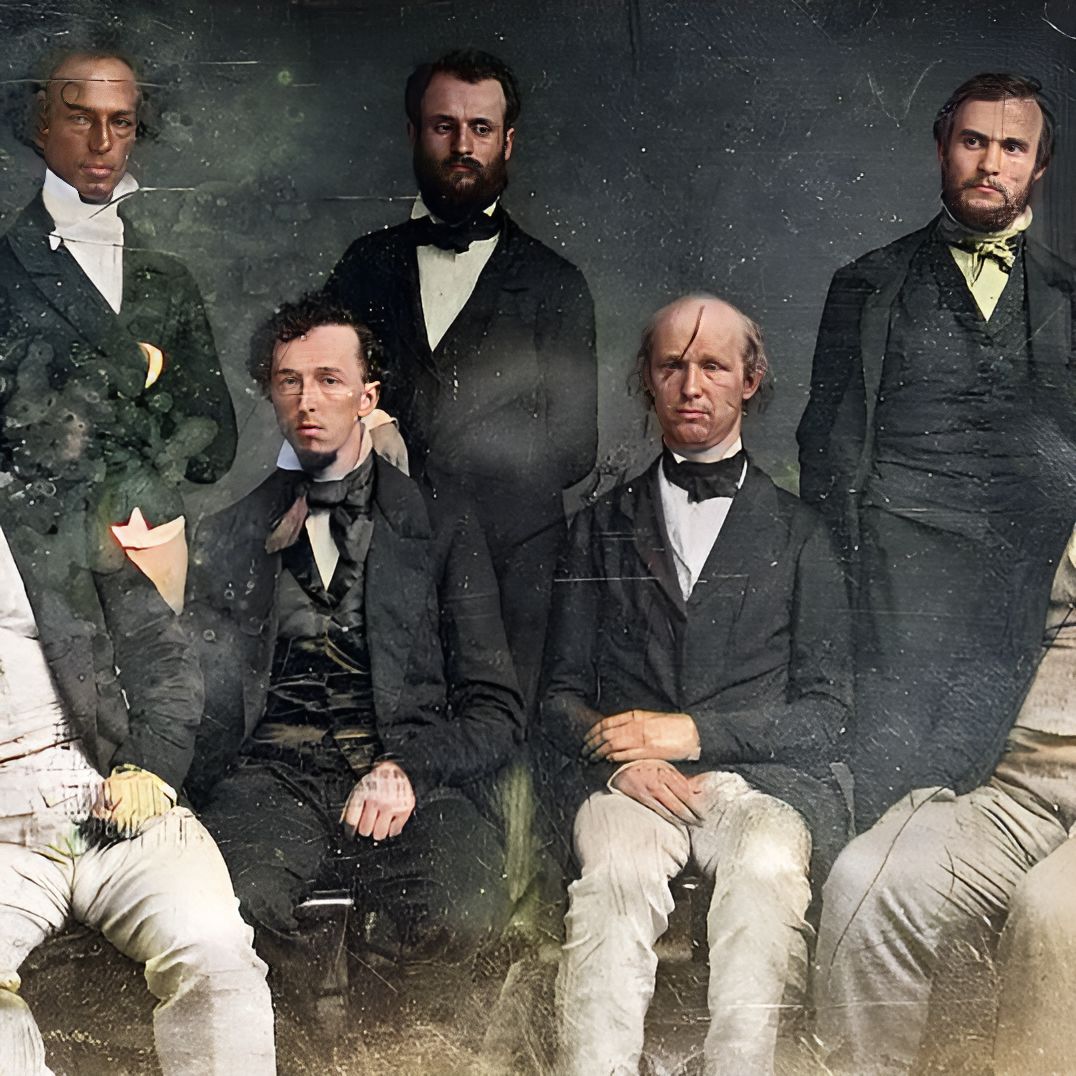




P.S.
Так вот к чему я это всё вёл: «Легко найти выключатель, если лампочка уже горит.» (Конфуций, VI в до н.э.) Проведя достаточное количество тестов, можно смело утверждать, что оба алгоритма офигеть какие крутые (и при этом, находятся в открытом доступе).

Комментарии (78)

Aquahawk
29.09.2021 17:01В sample 03 совсем другая эмоция на губах. Какой-то Сильвестр Сталоне проявился. А вообще шикарная статья на тему достоверности восстановления https://habr.com/ru/post/490620/

man_of_letters Автор
29.09.2021 17:20+13
Вы шутите так, верно? То, что такое сильное увеличение похоже на оригинал уже чудо.


Moldovich
29.09.2021 17:04| На результате от RealESRGAN листья деревьев выглядят не только реалистично, но и более чётко чем в оригинале, что-то необычное.
эмм, чётче, или вы про резкость всё же ?man_of_letters Автор
29.09.2021 17:14+4Оригинал — это оригинальное изображение, т.е. чётче исходного изображения.

dlinyj
29.09.2021 17:04+3Потрясающее исследование, просто поражает воображение! Хабр торт.
Хочется снять монокль и немного пошутить.
Когда немного перебрал :).
А, вот если серьёзно, то всякие истории фильмов, когда в отражении номера видят что-то уже не кажется такой уж глупостью.
Одной из мыслей у меня было, что можно даже из штучных пикселей получить достаточно большое количество информации, а с ИИ можно пойти даже дальше.
lxsmkv
29.09.2021 18:50+21Не хотел бы я, чтобы по искуственно увеличеной фотографии меня в ментовку замели, из-за того, что фантазии искуственного интеллекта случайно немного похожи на мою рожу.
И вообще вопрос, насколько изображения полученые искуственным путем могут применяться для сличения. Боюсь тут очень долго не будет нормального законодательства. Или до громких прецедентов.
Thero
30.09.2021 09:40+4в целом с плохим законодательством фантазии сотрудника полиции для вас страшнее фантазий нейросети.

DWZ
30.09.2021 23:17+1из-за того, что фантазии искуственного интеллекта случайно немного похожи на мою рожу.
Самое интересное, что большинство людей поверит компьютеру и *в принципе* не поймёт, где здесь "ха-ха"

xenon
05.10.2021 12:22Причем, в принципе, в основном будут склонны верить всякие.... кхм... гуманитарии. От судьи и прокурора до постовых полицейских.
Thero
29.09.2021 20:51+1увы эта информация будет недостоверной. номерок телефона с салфетки отражённой в пуговице вы так не восстановите.

Tarakanator
30.09.2021 09:10но вы можете восстановить информацию какого номера там точно нет. И этим очень сильно сузить список возможных вариантов номеров. И если у вас есть ещё какие-то данные про этот номер, то в итоге вполне возможно что и восстановите.
Thero
30.09.2021 09:39некоторые варианты с некоторой степенью достоверности.. но только если от этого номера вообще хоть что-то осталось, я скорее про случай где номер превращается в пару пикселей неотличимых от артефактов сжатия.
Tarakanator
30.09.2021 09:50Да, но не забывайте, что чтобы получить номер, нам не нужно восстанавливть изображение цифры. Нам достаточно восстановить саму цифру.
Если упрощая не нужно восстанавливать шрифт, которым написана эта цифра. Т.е. количество информации необходимое для восстановления номера сильно ниже, чем кажется на первый взгляд. из пары пикселей конечно не восстановить... но вот 4 пикселя на цифру может уже и достаточно.
xenon
05.10.2021 12:25Если нейросеть обучать по голливудским фильмам, то первые три цифры (555) она будет восстанавливать достаточно хорошо.
А еще, она всегда будет знать, что на салфетке либо написан номер телефона, либо просьба о помощи, либо секретные данные, которые шпион вынужден передавать связному таким образом, но никак не каляка-маляка и не подсчет стоимости ужина в ресторане.
Tarakanator
30.09.2021 09:09Так тут была статья с чудесными результатами восстановления строк символов низкого качества.

vsb
30.09.2021 11:40+6Проблема ИИ в том, что он "додумывает" недостающие детали, основываясь на своём "опыте", полученном при тренировке на эталонных изображениях". Это хорошо работает, когда эти детали просто создают атмосферу. Но если вам нужно получать информацию из этих деталей, то тут уже много вопросов возникает.
Как я понимаю, эти апскейлы можно представить, как работу художника, которому показали размытую картинку и попросили нарисовать на её основе чёткую. Он вполне может нарисовать очень красивую картинку, но какая надпись была на размытой дощечке, он не поймёт. Зато он каждый день ходит мимо бара с похожей надписью и воспроизведёт её.
Или другой пример - фотография человека с орденами. Апскейл вполне может поставить какой-нибудь случайный орден, похожий на исходный. Или художник, который не слишком разбирается во всём этом. Вот историк, который знает, когда эта фотография была снята, какие в то время были ордена, какие происходили события, может сделать более осознанную догадку. Но это уже не уровень текущих ИИ.

czz
30.09.2021 14:34Да, на примере фотографии стены каменного дома очень хорошо видно, что алгоритм придумал текстуру.


dcoder_mm
29.09.2021 17:08+15Плюс за использование HTML таблиц с маленькими жипегами, вместо неприлично больших png картинок
man_of_letters Автор
29.09.2021 17:23+26Благодарю-с, загрузить 840 картинок — это было весело
dcoder_mm
29.09.2021 17:41+2Понимаю вашу боль. У меня в посте про вертолет была всего сотня картинок, но они все были относительно крупные, и к середине поста habrastorage через раз отказывался загружать картинку из редактора (а через свой веб интерфейс отказывался с самого начала).
man_of_letters Автор
29.09.2021 17:50+9Статья была сверстана с локальными картинками.
Потом картинки из каждой папки загружались в сторадж, ссылки сохранялись для каждой папки.
Потом скрипт по ссылке картинки определял нужный комплект и по индексу подменял на ссылку в сторадже.
Боль была в создании мотивации так заморочиться. Подействовал аргумент «иначе, всё поперепутаешь и будешь переделывать минимум дважды и перепроверять 10 раз»dcoder_mm
29.09.2021 18:00картинки из каждой папки загружались в сторадж
Вот на этом этапе меня ждала самая большая боль, потому что пачка в N картинок обычно переставала загружаться на 2-3.
А вы не думали опубликовать этот скрипт?
man_of_letters Автор
29.09.2021 18:05+5И статья и скрипт живут внутри эзотерического редактора Leo Editor, код привязан к дереву статьи внутри редактора, так что никому это не пригодится)
p.s. Очень много и подробно писал про редактор тут


mSnus
29.09.2021 17:52но иногда интересно косячит! из ваших же примеров, посмотрите на лица:

странно как-то
man_of_letters Автор
29.09.2021 17:56+10
Господа! Те маленькие картинки в каждом примере это исходник с которого я увеличивал. Это невероятно малый размер. Лицо — это 12 на 12 точек. Потерпите еще два года, тогда будет уже чёткое лицо.



Thero
30.09.2021 09:29такой сервис натренирован сильно в пользу лучше найти лицо там где его нет, чем пропустить там где оно есть, у апскейл сетки такой приоритет считается ошибочным, но да потенциал в улучшении определения лиц есть.

TiesP
29.09.2021 18:02SR3 не пробовали для сравнения?
man_of_letters Автор
29.09.2021 18:19+31. Он закрыт
2. Люди пилят и выкладывают свои версии, но без обучения на промышленных мощностях, это не имеет ценности для использования

TheRaven
29.09.2021 18:05+4С аниме, имхо, вайфу справилась лучше. RealESRGAN даёт слишком жесткие линии, что особенно заметно на лице Мотоко.

vicsoftware
29.09.2021 18:38+3Я бы ещё сказал, что RealESRGAN старается везде подрисовать черные границы, даже там, где их нет.
man_of_letters Автор
29.09.2021 18:55+1Ценителям конечно виднее.
А если не ультрамаленький размер в нормальный, а нормальный в 4K?

RarogCmex
30.09.2021 08:22Комикс в 1 Мб весом и кодировкой jpeg превращается в 80+ мегабайт png. Чуда не происходит, но качество значительно возрастает в основном за счёт удаления jpeg-шумов. Я ожидал, что будет значительно больше артефактов.
man_of_letters Автор
30.09.2021 20:28Несколько моделей
Исходник -> upsc -> downsize (кроме модели x2)Cпойлер



drWhy
29.09.2021 18:45+2Женщину в красном можно было просто скачать из Матрицы в виде детализированной модели.
Остальное впечатляет — результаты, объём проведённых исследований, настойчивость и методичность при публикации.
Повышение качества изображения ведь кроме улучшения восприятия даёт возможность улучшать степень сжатия, устраняя шумы, занимающие в сжатом изображении большую долю. Особенно велик выигрыш будет для рисованных фильмов.
А если в видео восстановить модель заднего фона по всей сцене (газоны, дороги, стены и прочее преобразовать в «текстуры» и «градиенты»), то можно несущественный для восприятия сцены фон сжать значительно сильнее, чем с помощью традиционных алгоритмов, без существенного ухудшения качества результата.
Контрастные же объекты на переднем фоне после восстановления формы так и просятся быть векторизованными (сразу в 3D?), тогда последующий апскейл будет неактуален.

MaM
29.09.2021 18:56man_of_letters Автор
29.09.2021 19:39+4О, классно! Ссылка на тысячи статей про «Super resolution». Спасибо!

lxsmkv
29.09.2021 18:58Хотелось бы больше примеров с темнокожими, мне показалось, что он слабо справляется с темной кожей. А у африканских лиц и биометрия другая. Вообще интересно насколько маленьким должна быть фотография чтобы ИскИн начал менять биометрию африканского лица на биометрию европеоида.
man_of_letters Автор
29.09.2021 19:34+3Примеры
lxsmkv
29.09.2021 21:17+2Спасибо. Мне кажется, или у лица появляются монголоидные черты?
man_of_letters Автор
30.09.2021 11:08+2Так и есть. При сильном недостатке информации алгоритм часто уходит в Азию. Разработка китайская, можно поспекулировать, что у них перекос в наборе обучения, но это мои домыслы, может это на самом деле приближение с наименьшей ошибкой.



Enginfury
29.09.2021 19:09+3Все эти алгоритмы - хорошая вещь, но далеко не все справляются хорошо. Тот же Topaz Gigapixel меня не удивил, хотя я перебрал много алгоритмов. Но прогресс есть и это не может не радовать. Спасибо за статью.

Shaginov
29.09.2021 19:16+1Самая мощная модель, аналогичная той, что использовалась в данном сравнении, лежит почему-то в другом месте:
models-DF2K — это «official ESRGAN_x4»
Что-то у меня с этой моделью каша получается из картинки. Где бы взять модель которую Вы использовали?мой результат
man_of_letters Автор
29.09.2021 19:36+3Ваша картинка сжата больше некоторого порога, который недоступен для программы, видно сетку сжатия, она начинает воспринимать её как информацию. Попробуйте models-DF2K_JPEG, но чуда не будет.
Shaginov
29.09.2021 21:14+1Эта картинка из архива realesrgan-ncnn-vulkan-20210901-windows.zip, на который ведёт ссылка из статьи. Конечно я пробовал и другие фото с этим модулем, результат один — такое вот крошево из кубиков. Если я использую другие модели, то всё получается хорошо (с разной степенью качества). Но мне хочется попробовать модель, которую вы использовали. Об этом и вопрос :)
man_of_letters Автор
30.09.2021 11:49Понятия не имею что было в голове у тех кто паковал этот exe. Но это возмутительно! Нашел исходник этой картинки, уменьшил до такого же размера. Вот.
Спойлер




kr12
29.09.2021 19:54Как можно заметить, текстуры в тему получаются только для кожи и волос. Остальное или замазывает градиентом или крупнозернистым шумом, который на вид хуже, чем если вообще не применять. Итого: лучше, чем Topaz Gigapixel, но смысла для чего-то, кроме lineart, не вижу. Думаю даже лучше было бы, если алгоритм сложные места не трогал, а работал только по четким участкам без текстур

eugeneb0
29.09.2021 23:19У меня есть старая фотография куска газеты. Плёночная ещё. С очень нечётким текстом. Возьмётесь улучшить? Хочется прочесть если не текст, то хотя бы дату выпуска и заголовок.
TheRaven
29.09.2021 23:28+3Алгоритмы из статьи превратят всё в нечитаемую кашу, вам нужно смотреть в сторону deblur
eugeneb0
30.09.2021 00:12Собственно, примерно этого я и ожидал. Но хотелось услышать подтверждение.
man_of_letters Автор
30.09.2021 11:22+1Подтверждаю, точное восстановление информации делается другими алгоритмами.
Попробуйте программу хабраавтора отсюда habr.com/ru/post/180393
smartdeblur.net

Arxitektor
30.09.2021 09:42Будет ли работать RealESRGAN с изображениями большого разрешения ?
Например сделать из картинка 1920*1080 изображение 3840*2160 ?
man_of_letters Автор
30.09.2021 11:14+1Собственно в этом весь смысл. Если алгоритм справляется с низким разрешением, то с высоким подавно справится. На высоких разрешениях обычно возникает загвоздка с требованиями к видеопамяти, но в
алгоритм встроена хитрость: он может разбивать картинки на кусочки и обрабатывать их раздельно. Поэтому ничего не мешает сделать 4K.
olegbask
23.10.2021 19:29А алгоритм запустится на процессорах M1 Max или требует отдельного GPU? У м1 как раз 64 гига видеопамяти.

PzVI
30.09.2021 11:09Алгоритмы может и хороши, но перешарп итогового результата дикий. Вопрос только один. Авторы кода подслеповаты?!



PsyHaSTe
30.09.2021 23:25+2

krote
01.10.2021 12:41+1Я все жду когда уровень сжатия видео дойдет до того что фильм скажем будет сжиматься в некий скрипт, где будет тайминг, описание движения объектов, их класс, движение камеры, описание эффектов и прочее. Чтобы приложив к такому фильму свой любимый набор актеров ,предметов, текстур подстроить его под себя. Хотят чернокожие фильм "властелин колец" с черными актерами - пожалуйста, а я например только с белыми, и сам выберу какой актер будет эльфом и т.п.
Да и в принципе книгу тоже ИИ сможет когда то превращать в фильм.
Это еще далекое будущее, но не нереальное.
drWhy
01.10.2021 13:14
Хм. А что, технология виртуальной камеры на Аватаре и Гравитации отработана, пора в «матрёшку» добавлять потоки геометрии сцены, перемещения камер и света, физики и т.д.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
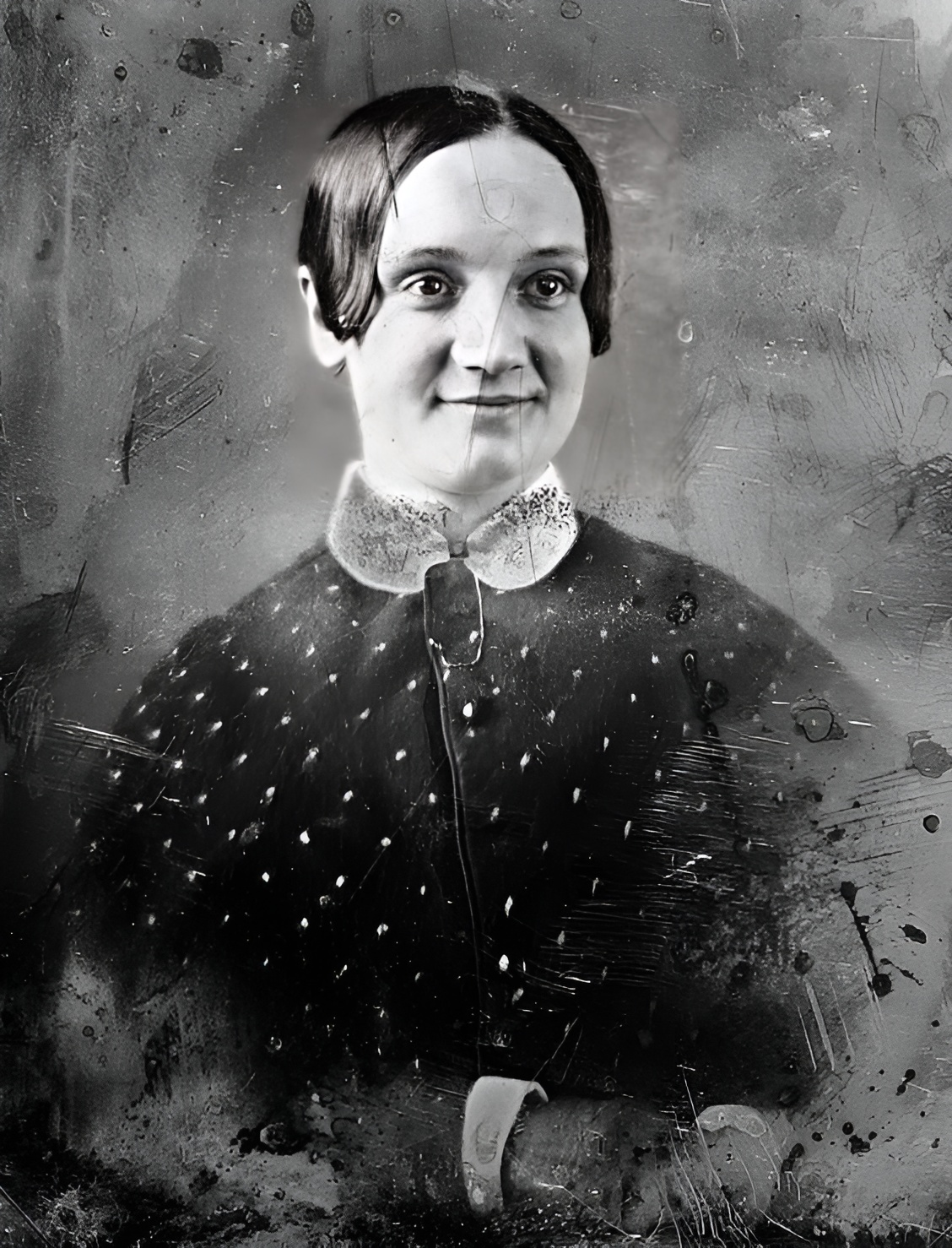{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
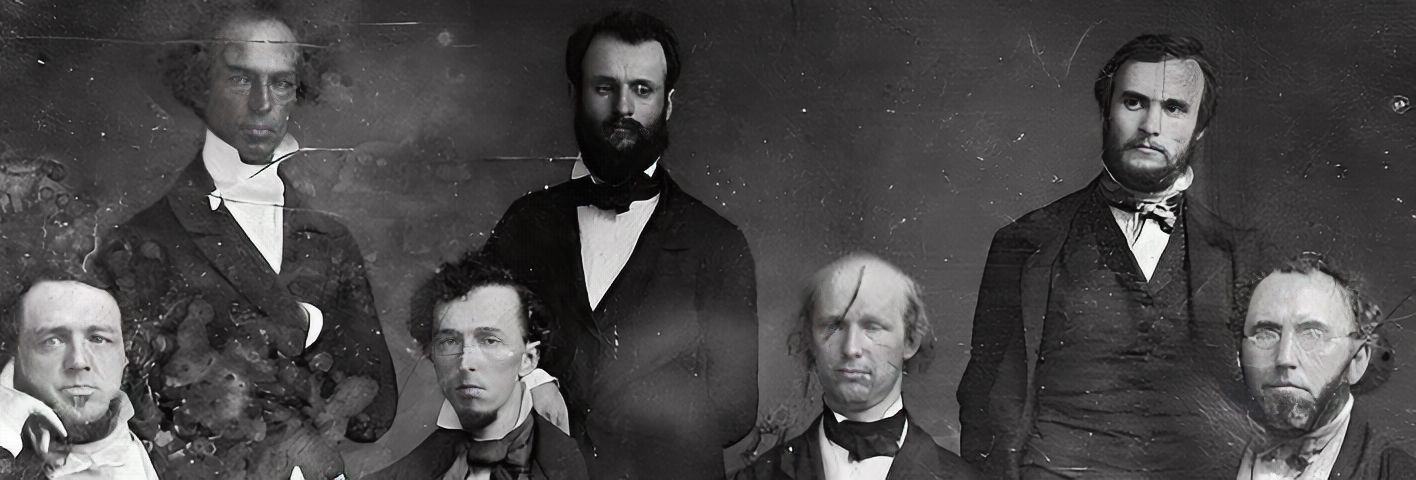{kind=link}
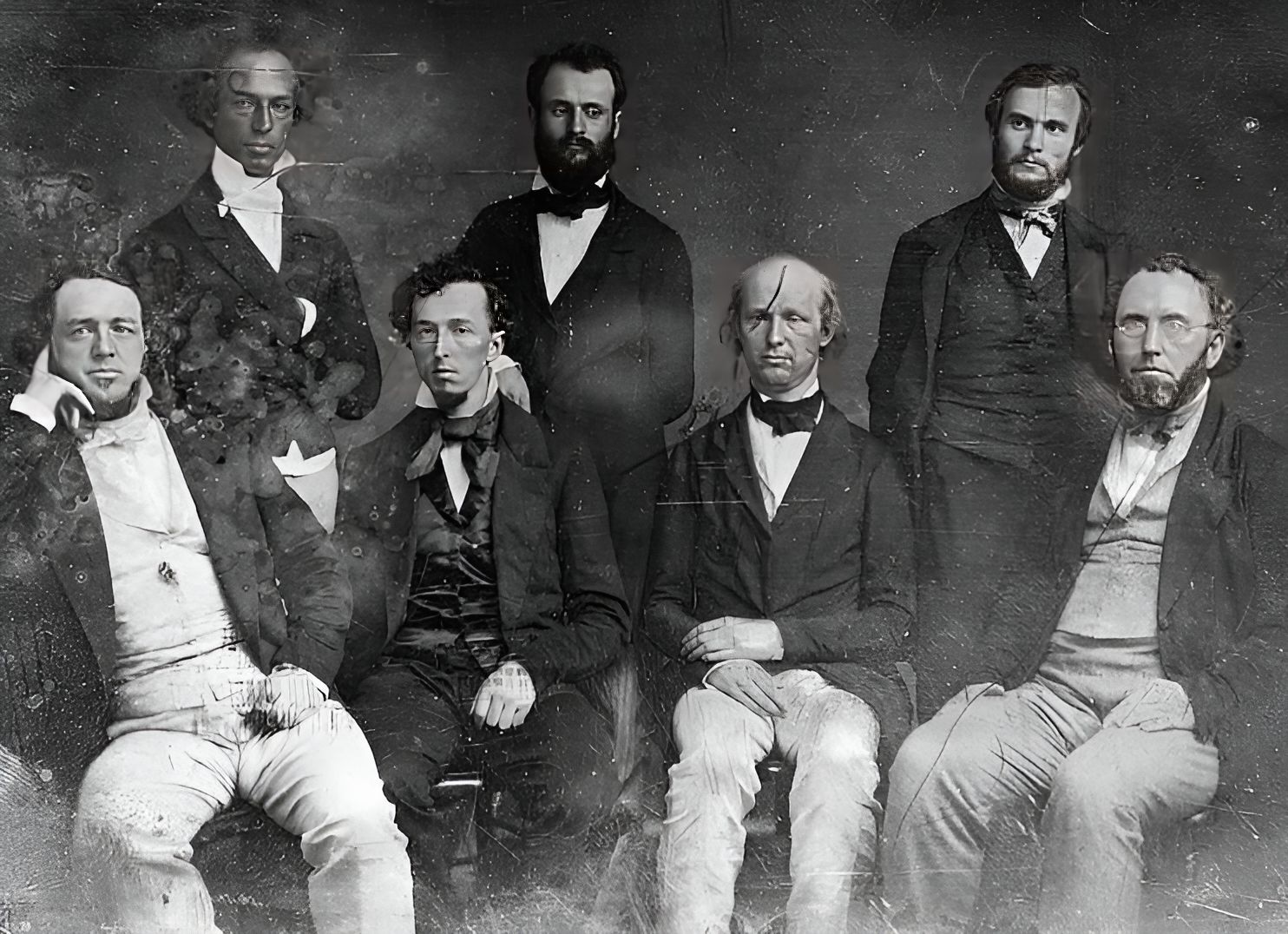{kind=link}
{kind=link}
{kind=link}
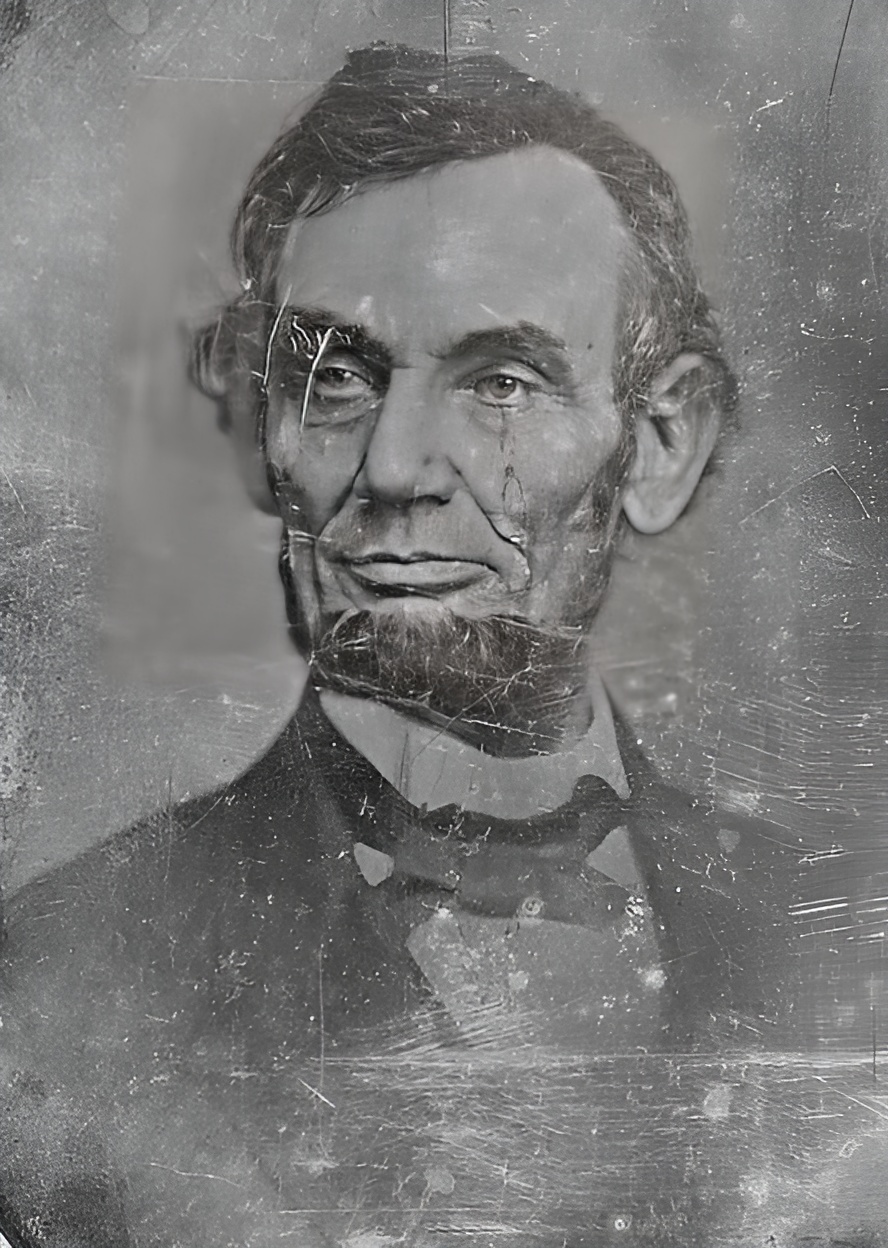{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

lagudal
29.10.2021 11:00Кто то сам пробовал уже, действительно ли реально получить такое качество на выходе при увеличении? Сейчас очень надо как раз…
Galperin_Mark
Статья, развивающая поднятую тему.
А также анимация от Google Brain Team: