

Вступительный текст про легендарную консоль, вода, бла-бла-бла. Искрой для появления статьи послужил неожиданный факт: ЦАП мегадрайва способен воспроизводить звук с качеством 26 килогерц 8 бит. Что? Хочу такое! Но… Максимальный размер картриджа 4 Мб, этого хватит на 2.5 минуты такого звука, с распаковкой современных кодеков старый процессор не справится. Качество против количества. Нерешаемое противоречие, но если сильно хочется, то всё получается.
Объяснение использованного принципа сжатия проще начать с декодера, вот его код на ассемблере для Motorolla 68000:
;d6 - Loops
;d5 - read_bytes_counter
;d3 - Window Length
;d0 - temp
move.B #$01, ($A11100) ; Request Z80 bus
move.B #$2B, ($A04000) ; Will switch DAC
move.B #$80, ($A04001) ; DAC On
move.B #$2A, ($A04000) ; Will DAC Out
@Next_Block
move.B (a6)+, d3 ; Read Wl
beq.S @Break ; If Wl = 0: Exit
move.B (a6)+, d6 ; Read Loops
@Repeat_Loop
move.B d3, d5 ; read_bytes_counter = Wl
@Next_Byte
move.B (a6)+,($A04001) ; Read DAC_byte & Play
moveq #30, d0 ; Prepare pause counter
@Pause dbf d0, @Pause ; 22 kHz delay
Subq.B #1, d5 ; Read_bytes_counter - 1
bne.S @Next_Byte ; If read_bytes_counter < Wl: Next_Byte
@Loop_Done
Subq.B #1, d6 ; Loops - 1
beq.S @Next_Block ; If Loops = 0: Next_Block
suba.W d3, a6 ; Reset datapointer
bra.S @Repeat_Loop
@Break
import numpy as np
from scipy.io.wavfile import write
f_name = r'C:\compressed_file.til'
wav_file = np.array([])
with open(f_name, 'rb') as file:
while True:
Wl = ord( file.read(1) )
if Wl == 0:
break
loops = ord( file.read(1) )
dac_block = np.frombuffer(file.read(Wl), dtype='uint8').astype('int')
dac_block = (dac_block - 127) / 127
restored = np.tile(dac_block, loops)
wav_file = np.append(wav_file, restored)
write(r'C:\output.wav', 22050, wav_file)
Никакой распаковки на самом деле нет: просто читаем последовательно блоки. Типичная загрузка двоичных данных, особенность лишь в том, что считывание блоков повторяется. Идея кодека банальна: ищем похожие фрагменты и сохраняем усреднённый образец, из которого во время воспроизведения будет воссоздан изначальный отрезок.
Звучит слишком просто, практически как «грабить корованы», но что-то маловато таких кодеков для микроконтроллеров и приставок. А известных нет совсем, потому что добиться вменяемого качества решением «в лоб», например, используя кластерный поиск, невозможно. Универсальное решение такого рода малореально, особенно для музыки в широком смысле. Поэтому введём ограничение. Кодек не будет работать с полифонией, это позволит сделать первый шаг: вычислить изменения основной частоты. Зная динамику частотного спектра, можно поделить запись на участки с одинаковой частотой, а внутри каждого такого фрагмента найти повторяющуюся форму волны.
Раз полифонии нет, то сжимать музыкальные треки целиком не получится. Насколько это плохо? От полноценного воспроизведения широкого спектра музыкальных жанров приставку отделяют две пропасти: невозможность реалистичного синтеза электрогитар и невозможность воспроизведения вокала. С гитарами мы разберёмся в другой раз, а вокал одного исполнителя — это монофонический звук, который имеет основную частоту, а значит его можно сжать нашим кодеком. Большинство звуковых эффектов в играх тоже можно считать монофоническими. Так что, кодек имеет практическую ценность. Лично мне больше всего хотелось услышать на приставке настоящий голос вместе с музыкой, остальные вероятные применения кодека — это уже бонусы.
Какую степень сжатия можно считать достижением цели? Если снизить частоту дискретизации несжатого звука до 11 кГц и уменьшить разрядность до 4 бит, то мы как бы сожмём звук в 4 раза, это будет минимальной планкой для оценки успеха.
❯ Часть 1
Прототип кодека будет написан на питоне, манипуляции со звуком будут производиться с помощью библиотеки librosa.
Пояснения к коду подготовительной стадии:
1. Загружаем WAV файл.
2. Стерео преобразуем в моно.
3. Преобразовываем частоту дискретизации в 22050 Гц. Чип тактируется частотой 53 кГц, максимальная частота корректной работы ЦАП 26 кГц, но целевая частота выбрана 22 кГц, во-первых, потому что преобразование из 44 в 22 даёт меньше искажений, во-вторых, некоторые функции librosa не умеет корректно работать с 44, поэтому сразу преобразовываем в итоговую частоту и работаем с ней.
4. Nframe — это главный параметр кодека, длина сжимаего блока. Чем он больше, тем выше эффект сжатия. Размер его выбран исходя из двух величин: скорости обработки звука мозгом и скорости обновления экрана в стандарте PAL. Если реконструировать звук из блоков длиннее чем 20 миллисекунд, появляется дискомфорт. При горизонтальном обновлении экрана генерируется прерывание с периодичностью 20 миллисекунд, что часто используется при обработке звука.
import math
from time import time
import librosa
import numpy as np
from numpy.fft import fft, rfft
from scipy.interpolate import interp1d
from scipy.ndimage import gaussian_filter1d
input_file = r"C:\input.wav"
FFS = 22050
Tframe = 1/50
waveform, sample_rate = librosa.load(input_file, sr=None, mono=True)
waveform = librosa.to_mono(waveform)
waveform = librosa.resample(waveform, orig_sr=sample_rate, target_sr=FFS)
print(f'{sample_rate} Hz converted to {FFS}, {waveform.shape[0]} points, {waveform.shape[0]/FFS:.2f} sec')
Nframe = round(Tframe*FFS)
Total_blocks = round(waveform.shape[0]/Nframe)
print(f'Points per block: {Nframe}, number of blocks: {waveform.shape[0]/Nframe:.2f}')
1. Производим поиск основного тона. Для отладки использовался древний, но быстрый метод yin. Точность его работы нас не устраивает из-за сильной погрешности, выливающейся в заметные артефакты, поэтому в финальном варианте используется метод pyin. Есть множество современных методов поиска основного тона, использующих нейросети, но мой нетбук из 2009 не оставляет особого выбора. Другие методы, хотя хвалились в интернете, оказались недостаточно стабильными. Правильное определение основного тона очень сильно влияет на конечный результат, поэтому это главная точка для дальнейшего улучшения кодека.
2. Знать динамику основного тона недостаточно, потому что существуют различные шумовые призвуки, которые входят в звучание речи и музыкальных инструментов. Эти призвуки тоже необходимо как-то сохранить. После поиска основного тона получаются участки с какой-то частотой и пробелы в которых находится неизвестно что: призвуки, просто шум, а может тишина. Чтобы дополнить информацию о призвуках, мы проверяем нераспознанные участки на наличие полезного сигнала с помощью анализа энтропии АЧХ, если АЧХ отрезка отличается от случайного, значит там может быть полезный звук. В таком случае для этого участка производим повторный поиск основной частоты методом «улучшенной автокорреляции», к счастью, код этой функции нашелся в гугле.
Wl_s = []
no_voice = []
ref = None
sample_deficit = 0
file_bin = {'Blocks':[]}
max_ampl = 0
f0 = np.array([])
#f0 = librosa.yin(waveform, frame_length=Nframe*4, fmin=librosa.note_to_hz('C2'),fmax=librosa.note_to_hz('C7'))
f0, _, _ = librosa.pyin(waveform,sr=FFS,frame_length=Nframe*4,fmin=librosa.note_to_hz('C2'),fmax=librosa.note_to_hz('C7'))
f0 = np.nan_to_num(f0)
def eac(sig, winsize=512, rate=44100):
"""Return the dominant frequency in a signal."""
s = np.reshape(sig[:len(sig)//winsize*winsize], (-1, winsize))
s = np.multiply(s, np.hanning(winsize))
f = fft(s)
p = (f.real**2 + f.imag**2)**(1/3)
f = rfft(p).real
q = f.sum(0)/s.shape[1]
q[q < 0] = 0
intpf = interp1d(np.arange(winsize//2), q[:winsize//2])
intp = intpf(np.linspace(0, winsize//2-1, winsize))
qs = q[:winsize//2] - intp[:winsize//2]
qs[qs < 0] = 0
qs[:63] = 0 # DAC max 22 kHz = 64*22050/64
return rate/qs.argmax()
for i in range(Total_blocks):
no_voice_flag = 0
if f0[i] == 0 or f0[i] == np.inf:
wave_slice = waveform[i * Nframe: (i + 1) * Nframe]
flatness = librosa.feature.spectral_flatness(y=wave_slice)
if flatness < 0.5:
f0[i] = eac(wave_slice, winsize = Nframe, rate = FFS)
if f0[i] == 0 or f0[i] == np.inf:
no_voice_flag = 1
else:
no_voice_flag = 1
no_voice.append(no_voice_flag)
Wl_s.append(0)
Перейдём к сжатию:
1. Зная основной тон блока, вычисляем количество точек, которых достаточно для хранения одного периода тона. Эта величина будет постоянно встречаться под именем Wl — window length.
2. Вычисляем количество целых периодов тона в одном блоке, делим линейный сигнал на периоды и создаём двухмерный массив ss_2d, содержащий выделенные периоды.
3. В результате конечного усреднения периодов высокие частоты потеряются, поэтому мы заранее выделяем производную сигнала и трансформируем её в матрицу high_2d согласно границам периодов основного тона. Если высокие частоты не обрабатывать, то получится эффект шумоподавления.
4. Нашей целью является поиск усреднённой формы периода, для этого достаточно взять среднее значение по столбцам матрицы ss_2d и high_2d. Понятно, что фазы периодов далеки от 0, поскольку точно попасть в начало волны невозможно, ни при разделении на блоки размером Nframe, ни при разделении блока на периоды Wl. Придётся определять смещение от идеала для каждого периода. Построим идеальную синусоиду true_tone и сместим все периоды так, чтобы они были наиболее близки к эталону.
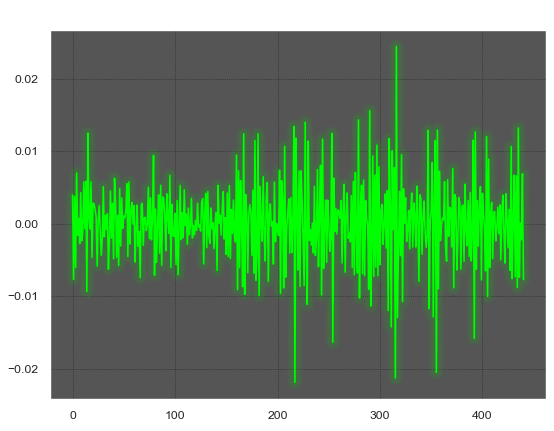
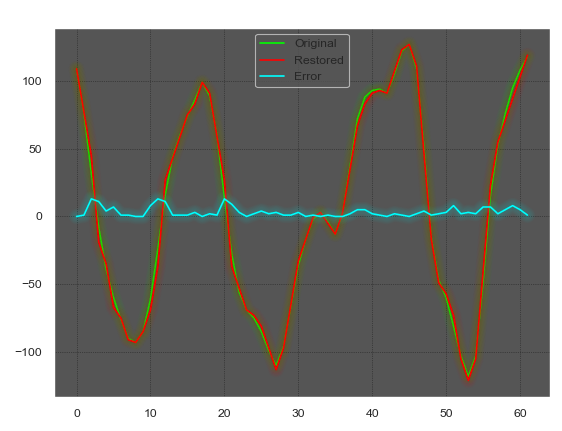
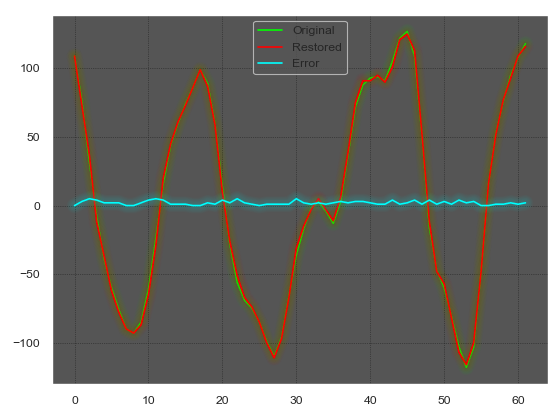
Исходный блок длиной Nframe

Блок, разделённый на периоды длиной Wl без выравнивания
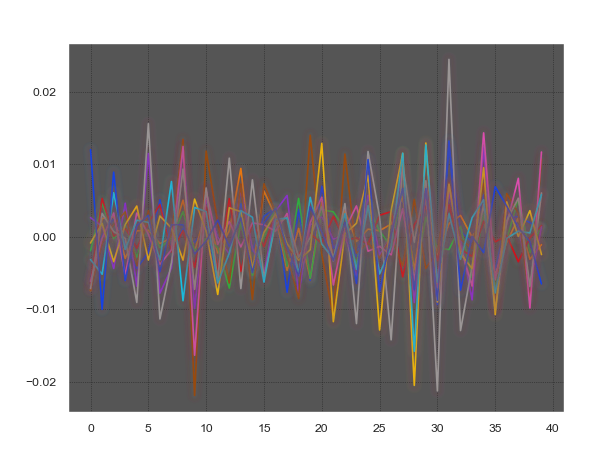
Блок, разделённый на периоды длиной Wl с выравниванием
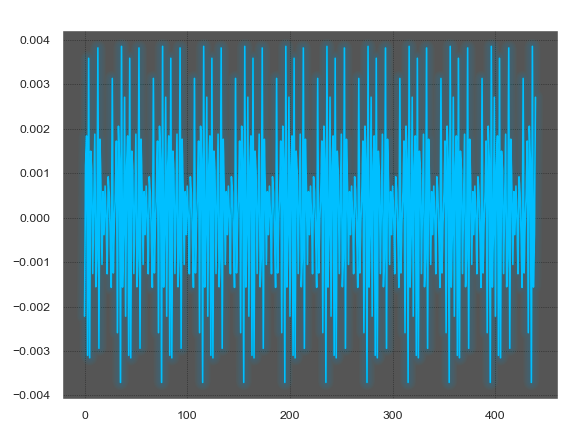
Восстановленный сигнал из среднего без выравнивания
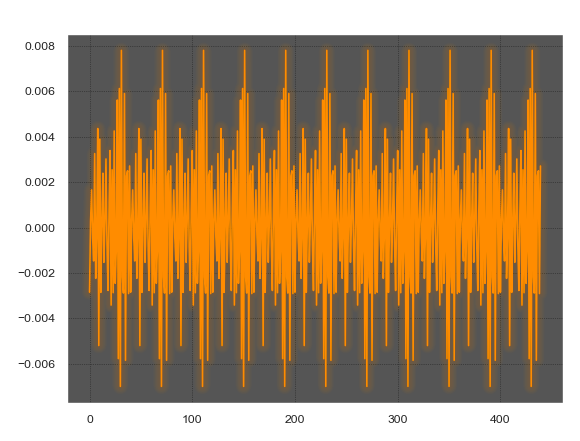
Восстановленный сигнал из среднего с выравниванием
5. Усреднение периодов как и поиск основного тона имеет критическое значение, кроме того оно имеет квадратичную сложность, что делает это место второй важной точкой для улучшения кодека. Наблюдать за перебором полного Wl*n_p было слишком дискомфортно, поэтому количество комбинаций уменьшено эвристикой, иногда дающей сбои. Для первого периода ищем сдвиг в диапазоне полуволны, а каждый следующий поиск начинаем относительно предыдущего найденного сдвига.
#Time * Frequency = Oscillations
Wl_s[i] = int(FFS / f0[i]) # number of points for main tone
if Wl_s[i] > 255:
Wl_s[i] = 255
n_p = Nframe // Wl_s[i]
ss = wave_slice[:n_p * Wl_s[i]]
ss_2d = np.resize(ss, (n_p, Wl_s[i]))
high = ss - np.roll(ss, -1)
high_2d = np.resize(high, (n_p, Wl_s[i]))
if np.sum(ss[:Wl_s[i] // 4]) >= 0:
phi = -np.pi/2
else:
phi = np.pi/2
true_tone = librosa.tone(f0[i], sr = FFS, length = Wl_s[i], phi = phi)
true_tone = true_tone * np.max(np.abs(ss_2d[n_p // 2]))
dist_opt = np.inf
iopt = 0
for x in range(-Wl_s[i]//8, Wl_s[i]//2):
tmp_ = np.roll(ss_2d[0], x)
dist = np.linalg.norm(tmp_ - true_tone)
if dist < dist_opt:
iopt = x
dist_opt = dist
iopt_prev = iopt
ss_2d[0] = np.roll(ss_2d[0], iopt)
high_2d[0] = np.roll(high_2d[0], iopt)
dist_opt = np.inf
iopt = 0
for j in range(1, n_p):
dist_opt = np.inf
for x in range(-Wl_s[i]//8, Wl_s[i]//4):
tmp_ = np.roll(ss_2d[j], x + iopt_prev)
dist = np.linalg.norm(tmp_ - true_tone)
if dist < dist_opt:
iopt = x + iopt_prev
dist_opt = dist
dist = np.linalg.norm(tmp_ - ss_2d[0])
if dist < dist_opt:
iopt = x + iopt_prev
dist_opt = dist
iopt_prev = iopt
ss_2d[j] = np.roll(ss_2d[j], iopt)
high_2d[j]= np.roll(high_2d[j], iopt)
avg = np.mean(ss_2d, axis=0)
high_part = np.mean(high_2d, axis=0)
avg = high_part + avg
Мы конечно молодцы, но если попробовать склеить текущий результат и послушать, то кроме радости нас постигнет разочарование в виде постоянных щелчков и бульканья. Щелчки — это результат резких перепадов граничных значений блоков. Второе — это более интересный эффект биения частот, возникающий из-за несовпадения фаз блоков. Период, выделенный из блока, после усреднения имеет фазу 0, сигнал в каждом последующем блоке как бы начинается заново, но если последовательные блоки имеют разные частоты, то возникает такое бульканье. Это упрощенное объяснение.
С биениями мы справимся тривиально, вместо расчёта фаз и обратного преобразования Фурье, повторно используем метод перебора фазы волны. Форма текущего сигнала подгоняется к в форме предыдущего. Как ни странно, это работает очень хорошо, артефакты исчезают.
С щелчками справиться оказалось гораздо сложнее, потому что нужно, чтобы края периода одновременно обеспечивали гладкий переход при повторении внутри блока и между текущим блоком и соседними. Текущее решение работает на троечку, но работает: стыкуем соседние полуволны разных блоков, сглаживаем переход, соединяем полуволны одного блока, сглаживаем, находим среднее между переходами и подмешиваем с градиентом к краям исходного блока. Правильным решением была бы аппроксимация полиномом перехода между соседними блоками, а потом аппроксимация перехода между концом блока и его началом.
if type(ref) != type(None):
dist_opt = np.inf
iopt = 0
len_avg = len(avg)
len_ref = len(ref)
if len_ref < len_avg:
k = math.ceil(len_avg/len_ref)
ref = np.tile(ref, k)
ref = ref[-len_avg:]
for x in range(Wl_s[i]):
tmp_avg = np.roll(avg, x)
dist = np.linalg.norm(tmp_avg-ref)
if dist < dist_opt:
iopt = x
dist_opt = dist
avg = np.roll(avg, iopt)
filt_depth = 3
if type(ref) != type(None):
min_wl = min(len(ref), len(avg))
ref_avg = np.concatenate((ref[-min_wl // 2:], avg[:min_wl // 2]))
avg_blurred_plus_end = gaussian_filter1d(ref_avg, filt_depth)
avg_blur = np.roll(avg_blurred_plus_end, -min_wl // 2)
f_len = min_wl // 4
else:
f_len = Wl_s[i] // 4
avg_halfrolled= np.roll(avg, Wl_s[i]//2)
avg_halfrolled_blur = gaussian_filter1d(avg_halfrolled, filt_depth, mode='wrap')
avg_blur = np.roll(avg_halfrolled_blur, -Wl_s[i]//2)
fade_in_curve = np.linspace(0.0, 1.0, f_len)
fade_out_curve = np.linspace(0.0, 1.0, f_len)[::-1]
avg[:f_len] = avg[:f_len] * fade_in_curve + avg_blur[:f_len] * fade_out_curve
avg[-f_len:] = avg[-f_len:] * fade_out_curve + avg_blur[-f_len:] *fade_in_curve
ref = avg
Перед сжатием нужно провести несколько проверок:
1. Проверяем, не состоит ли фрагмент из тишины, если так, то в блок запишем два нуля, повторяющиеся 220 раз (длина исходного блока = 441). Тишина составляет заметную часть дорожки с вокалом, поэтому вместо повторяющейся последовательности из четырёх байт [2, 220, 0, 0] стоило бы придумать специальный блок для замены множества пустых блоков, но это усложнение декодера.
2. Проверяем, не является ли фрагмент призвуком, если так, то он состоит из множества негармоничных частот и выделить периоды не получится. Заменить произвольный шум повторяющимся блоком без серьёзного матана непросто, поэтому в качестве временного решения берём среднее. Длина для таких блоков устанавливается константой, чем она меньше, тем хуже сохраняется характер звука.
3. Если фрагмент содержит тональный звук, то производим его сжатие, как было описано.
4. Далее оба вида блоков проходят через коррекцию фазы, и коррекцию граничных значений.
if np.mean(np.abs(wave_slice)) < 0.005:
Wl_s[i] = 2
n_p = round(Nframe/Wl_s[i])
avg = np.zeros(2)
else:
if no_voice[i] == 1:
Wl_s[i] = 128
n_p = round(Nframe/Wl_s[i])
ss = wave_slice[:n_p * Wl_s[i]]
ss_2d = np.resize(ss, (n_p, Wl_s[i]))
high = ss-np.roll(ss,-1)
high_2d = np.resize(high, (n_p, Wl_s[i]))
avg = np.mean(ss_2d, axis=0)
high = np.mean(high_2d, axis=0)
avg = avg + high
else:
<<compress>>
<<correct compression result>>
Все эти операции производятся в главном цикле, обрабатывающем каждый фрагмент длиной NFrame.
1. Сжимаем, корректируем текущий фрагмент.
2. Отслеживаем значение максимально встретившейся амплитуды max_ampl, чтобы при сохранении результата полностью заполнить диапазон 8 бит, поскольку громкость ЦАП относительно музыкального синтезатора невысока.
3. В одном фрагменте 441 сэмпл. Количество периодов, умноженное на длину периода почти никогда не равно этой цифре. Из-за этого при декодировании время звучания сократится, это было бы не особо критично, если бы не было нужды синхронизировать вокал с музыкой. Для синхронизации с исходным материалом будем оценивать потери сэмплов sample_deficit и добавлять компенсирующие повторы блоков.
for i in range(Total_blocks - 1):
wave_slice = waveform[i * Nframe: (i + 1) * Nframe]
# compression code here
# avg ~ result of compression
if max(abs(avg)) > max_ampl:
max_ampl = max(abs(avg))
restored_sample_len = n_p * Wl_s[i]
if sample_deficit !=0:
loops = n_p + round(sample_deficit / Wl_s[i])
if loops > 255:
loops = 255
else:
loops = n_p
restored = np.tile(avg, loops)
sample_deficit = sample_deficit + (Nframe-len(restored))
file_bin['Blocks'].append( {'Wl': Wl_s[i], 'loops': loops, 'block': avg} )
Записываем данные в файл. Поскольку ЦАП Сеги работает в диапазоне 0-255 и ожидает именно такие значения амплитуды, нужно заранее преобразовать знаковые значения в беззнаковые, чтобы не делать этого в декодере.
f_name = r'C:\output.til'
with open(f_name, 'wb') as file:
for value in file_bin['Blocks']:
file.write( (value['Wl']).to_bytes(1, byteorder='big', signed=False) )
file.write( (value['loops']).to_bytes(1, byteorder='big', signed=False) )
avg_raw = np.round(127 * value['block'] / max_ampl + 127)
file.write(avg_raw.astype('uint8'))
end = 0
file.write(end.to_bytes(1, byteorder='big', signed=False))
Кодек готов! Ура! Проверяем степень сжатия, она получается в диапазоне 5-8. Если в записи преобладают низкие частоты, то количество длинных блоков будет больше и наоборот, если больше высоких частот, то коэффициент сжатия выше.
Если прикидывать оптимистично, то 1 минута займёт 175 КБ, а в картридж поместится 22 минуты звука. Характер звучания получается интересный: лёгкий цифровой перегруз (усреднение периодов работает как компрессор) и артефакты, похожие на погрешности плёночных носителей, что гармонично сочетается с приставочным звуком.
❯ Часть 2
Кроме музыки игры также содержат графику и код, поэтому в лучшем случае для звука может быть доступен лишь 1 мегабайт. Чтобы отвоевать дополнительное время звучания воспользуемся известным трюком: перейдём от 8 бит к 4, сразу двойной выигрыш без изменения алгоритма сжатия.
Использовать 16 комбинаций для абсолютных значений — идея очень плохая. Перейдём к относительным величинам: каждое значение будет представлять собой изменение относительно предыдущего. 16 возможных значений полубайта будут соответствовать набору отрицательных и положительных приращений. Качество результата зависит от соответствия распределения приращений и данных. Самым простым будет взять степени двойки: 0, 1, 2, 4, 8, 16, 32, 64, 128, -1, -2, -4, -8, -16, -32, -64. Ошибка такого кодирования будет плавать в диапазоне 10-20%. На слух это будет восприниматься как хруст и шелест, очень заметно.
Что можно улучшить? В интернете описан интересный вариант составления с помощью статистики множества разных таблиц приращений, которые меняются кодером и декодером в зависимости от текущего значения. Качество действительно трудно отличить от 8 бит, но проблемой является размер таблиц, которые не поместятся в память вспомогательного процессора Z80, в которой размещается драйвер воспроизведения звука. Можно, конечно, делать распаковку на основном процессоре, но свой велосипед ближе к телу.
Главное противоречие дифференциального представления такое: таблица с небольшими приращениями даёт низкую ошибку на плавных участках и высокую на скачках, с большими приращениями наоборот. Как можно с помощью небольших приращений одновременно изменять сигнал сильно и слабо? Поможет интегрирующий элемент, эта сущность получила название «аккумулятор». Приращения будут изменять аккумулятор, а аккумулятор своей накопленной «массой» будет изменять сигнал. Там, где есть масса, есть и инерция, при быстро изменяющемся сигнале потребуются большие «тормозящие» значения, которых у нас в таблице нет, поэтому при превышении некоторого порога, аккумулятор сбрасывается в ноль и кодер начинает работать в простом дифференциальном режиме до выхода в спокойную зону. Таким образом одновременно хорошо обрабатываются резкие скачки и медленное изменение сигнала, ошибка уменьшилась в 2 раза.
Дифференциальное кодирование
Дифференциальное кодирование + аккумулятор
Далее приведён упрощенный код этого метода. Есть переменная со значением аккумулятора на предыдущем шаге и расчётное значение сигнала, которое получится при декодировании, относительно которого рассчитывается новое значение, чтобы компенсировать расхождение реального сигнала и восстановленного. Из этих величин на каждом шаге рассчитывается необоходимое изменение аккумулятора, для которого находится ближайшее значение в таблице приращений. Используя это значение, вычисляем новое состояние аккумулятора и восстановленного сигнала точно так же, как это будет происходить в декодере.
table = [0] + [x*x for x in range(1,9)] + [-(x*x) for x in range(2,9)]
encoded = []
encoded.append(avg[0])
akulmulator_prev = 0
val_prev = avg[0]
for j in range(1, len(avg)):
akk_diff = avg[j] - val_prev - akulmulator_prev
if abs(akulmulator_prev) > 21:
akulmulator_prev = 0
akk_diff = avg[j] - val_prev
candidate_i = 9999
dist = 9999
for i in range(16):
x = table[i]
if abs(x - akk_diff) < dist:
dist = abs(x - akk_diff)
candidate_i = i
encoded.append(candidate_i)
akulmulator_prev = akulmulator_prev + table[candidate_i]
val_prev = val_prev + akulmulator_prev
Декодер работает просто: значение полубайта через таблицу преобразуем в приращение, приращение добавляем к аккумулятору, аккумулятор добавляем к текущему значению, слишком раздувшийся аккумулятор сбрасываем. При малейшем несовпадении логики кодера и декодера, результат улетает в небеса, удобно.
restored = []
akulmulator = 0
val = encoded[0]
restored.append(val)
for i in range(1,len(encoded)):
akk_diff = table[encoded[i]]
if abs(akulmulator) > 21:
akulmulator = 0
akulmulator = akulmulator + akk_diff
val = val + akulmulator
restored.append(val)
В реальном кодеке всё немного сложнее:
1. Из-за колебаний аккумулятора сложно точно растянуть сигнал «под потолок». Восстановленный сигнал может убежать за 255, а так как каждое значение зависит от предыдущего и есть последующие блоки, то нельзя просто принудительно ограничить выброс. Многократно кодировать с разным масштабным коэффициентом, чтобы точно попасть в максимум, это странно. Поэтому, если есть признак того, что сигнал сильно скачет, для него вводится понижающий коэффициент. Это слабое место: либо сильный запас и потеря амплитуды, либо подбирать коэффициент руками.
2. Далее следует уже известное преобразование в 4 бита.
3. Завершается итерация соединением полубайтов в байты.
f_name = r'C:\output.til'
table = [0] + [x*x for x in range(1,9)] + [-(x*x) for x in range(1,8)]
first_block = True
all_blocks = np.round(127 * wav_file / max_ampl + 128)
naive_max = max(np.abs(np.diff(all_blocks) + all_blocks[1:]))
if naive_max > 255:
magic_k = 255/304
else:
magic_k = 1
with open(f_name, 'wb') as file:
akulmulator_prev = 0
val_prev = 0
for value in file_bin['Blocks']:
avg_raw = np.round(magic_k * 127 * value['block'] / max_ampl + 127)
z = []
if first_block:
file.write(int(avg_raw[0]).to_bytes(1,byteorder='big',signed=False))
val_prev = avg_raw[0]
first_block = False
file.write((value['Wl']).to_bytes(1,byteorder='big',signed=False))
file.write((value['loops']).to_bytes(1,byteorder='big',signed=False))
for j in range(len(avg_raw)):
akk_diff = avg_raw[j] - val_prev - akulmulator_prev
candidate_i = 9999
dist = 9999
if abs(akulmulator_prev) > 21:
akulmulator_prev = 0
akk_diff = avg_raw[j] - val_prev
for i in range(16):
x = table[i]
if abs(x - akk_diff) < dist:
dist = abs(x - akk_diff)
candidate_i = i
z.append(candidate_i)
akulmulator_prev = akulmulator_prev + table[candidate_i]
val_prev = val_prev + akulmulator_prev
if val_prev > 255 or val_prev < 0:
print('Value overflow: ', val_prev)
if akulmulator_prev > 255:
print('Akk overflow: ', akulmulator_prev)
if value['Wl'] & 1 == 1:
z.append(0)
avg_8bit = np.array(z).astype('uint8')
avg_4bit_packed = avg_8bit[0::2] << 4 | avg_8bit[1::2]
file.write(avg_4bit_packed)
end = 0
file.write(end.to_bytes(1,byteorder='big',signed=False))
Декодер на ассемблере привожу, но так как большинство посмотрит и закроет, то разъяснений не будет. Для меньшинства оставлены подробные комментарии, среда в которой это разрабатывалось называется SecondBasic.
Reload Table
Reload TilFile
'd7 - Dac_Block start
'd6 - Loops value
'd5 - Flags|read_bytes_counter
'd4 - akulmulator'|DAC last value'|akulmulator|DAC last value
'd3 - Wl
'd0 - temp
'a2 - quantize table
Asm
move.B #$01, ($A11100) ; request Z80 bus
move.B #$2B, ($A04000) ; Will DAC On
move.B #$80, ($A04001) ; DAC On
move.B #$2A, ($A04000) ; Will DAC Out
move.l #__SBSDATA_Table, a2 ; 4bit_to_value table
move.B (a6)+, d0 ; Read first DAC_byte
clr.L d5 ; flag = 0
clr.L d4 ; Val = 0
move.B d0, d4 ; Val = first_value
@Next_block
move.W d4, d0 ;
Swap d4 ;
move.W d0, d4 ; Save akk, Val d4.L_lo -> d4.L_hi
bclr.L #16, d5 ; Set 1st_2nd_byte_flag = 0
beq.S @Skip_offset_correction
adda #1, a6
@Skip_offset_correction
move.B (a6)+, d3 ; Read Wl
beq @Break ; If Wl = 0: EOF
move.B (a6)+, d6 ; Read Loops
move.L a6, d7 ; Keep Dac_Block start
@Repeat_Loop
move.B d3, d5 ; Wl->read_bytes_counter
bclr.L #16, d5 ; Set 1st_2nd_byte_flag = 0
@Next_DAC_Byte
bchg.L #16, d5 ; Check & Xor 1st_2nd_byte_flag
bne.S @Second_Nibble ; If 1st_2nd_byte_flag = 1: take 2nd half
move.B (a6), d0 ; Read DAC_byte
lsr.L #4, d0 ; Get first nibble
bra.S @First_Nibble
@Second_Nibble
clr.W d0
move.B (a6)+, d0 ; Read DAC_byte
@First_Nibble
And.W #$000F, d0 ; Filter rubbish Or get second nibble
move.B (a2,d0), d0 ; Convert 4bit To diff value
ror.w #8, d4 ; d4.B ~ akulmulator
cmp.B #21, d4 ; If abs(akulmulator)>21: akulmulator=0
sle d1
And.B d1, d4
cmp.B #-21, d4
sge d1
And.B d1, d4
add.B d0, d4 ; akulmulator = akulmulator + table[dac_block[i]]
move.B d4, d0
ror.w #8, d4 ; d4.B ~ Val
add.B d0, d4 ; Val = Val + akulmulator
move.B d4,($A04001) ; DAC_byte out
move.W #14, d0 ; Prepare pause counter
@Pause
dbf d0, @Pause ; 22 kHz delay
subi.B #1, d5 ; Read_bytes_counter - 1
bne @Next_DAC_Byte ; If read_bytes < Wl: Next_DacByte
@Loop_Done
Subq.B #1, d6 ; Loops - 1
beq @Next_block ; If Loops=0: Next_Block
move.L d4, d0
Swap d0
move.W d0, d4 ; Restore akk, Val d4.L_hi -> d4.L_lo
move.L d7, a6 ; Reset datapointer
bra @Repeat_Loop
@Break
End Asm
Print "End"
TilFile:
DataFile "C:\input.til", Bin
Table:
Data 0,1,4,9,16,25,36,49,64,-1,-4,-9,-16,-25,-36,-49
Степень сжатия получается в диапазоне 9-12, то есть 30 минут звука в хорошем качестве получится записать на один картридж. Это целый музыкальный альбом, а значит уже есть смысл попробовать совместить вокальную дорожку с музыкой.
Что такое аудиодрайвер в контексте Sega MD? Это программа, которая посылает данные в аудиочип: либо команды, похожие на MIDI, либо байты для ЦАП. На Сеге невозможно просто проиграть некий формат, необходим код, который преобразует музыку в команды для аудиочипа. Существуют старые драйверы, вырезанные в двоичном виде из игр, но применить их в проектах с неродными форматами файлов невозможно. Существует несколько новых драйверов, написанных энтузиастами. Для проигрывания музыки придётся использовать какой-то из них, потому что самостоятельно писать его слишком долго.
Просто скрестить код декодера и какого-либо из драйверов не получилось. Пришлось идти по очень сложному пути… Аудиочип может управляться, либо с главного процессора, либо со вспомогательного. Нормальные аудиодрайверы загружаются в память вспомогательного процессора, чтобы не тормозить основной цикл обработкой звука. Управлять аудиочипом одновременно с двух процессоров нельзя, чипом управляет кто-то один. Декодер вокала на основном процессоре и аудиодрайвер будут постоянно драться за доступ к аудиочипу.
Первой задачей было отучить аудиодрайвер трогать канал ЦАП, потому что он постоянно слал нули или дёргал туда-сюда включение отключение ЦАП. Начиналось с бинарного патчинга, но когда количество мест, в которых что-то трогало ЦАП перевалило за 10, мне показалось что дизассемблер выдал кашу, и тогда пришло время исходников =) Но от исходников легче не стало, потому что драйвер действительно в 50 местах совершал обращение к ЦАП. Позже стало ясно, что для точной синхронизации множество циклов было развёрнуто в повторение кода. Пришлось патчить все эти точки.
Звук вокала перестал шипеть, но музыкальные дорожки наполнились артефактами: музыкальные фразы прерывались или наоборот ноты зависали, появлялось неправильное звучание инструментов. Всё это было следствием того, что команды чипу состоят из двух операций: сначала посылается тип операции, потом значение операции, соответственно, когда две программы одновременно слали команды в аудиочип, происходили странности из-за совмещения двух половинок разных команд.
Музыка и вокал прекрасно работали по отдельности, но вместе создавали какофонию. Известные методы совместного доступа к ресурсам не помогли из-за того, что оба потока должны воспроизводиться непрерывно, ни один из них нельзя приостановить, заморозить, заглушить. Это был полный провал и несколько дней было потрачено на наивную попытку переписать чужой аудиодрайвер, сначала с целью научить его дружить с декодером, потом уже от безвыходности была попытка впихнуть декодер в него, но даже повысить частоту проигрывания с 14 кГц до 28 кГц не вышло. За неделю этой возни стало понятно, почему автор аудиодрайвера потратил на него 3 года, там ни пошевелить ничего, ни добавить было невозможно, всё сразу разваливалось в труху, каждый байт и каждая командочка были ровно на своём месте, о чем сразу намекал расчёт циклов вдоль всего исходника. Ценой больших усилий удалось отбить у драйвера жалкие 200 байт свободного места для новых инструкций, но грубое добавление дополнительных циклов проигрывания, во-первых, создавало артефакты, во-вторых, не хотело помещаться целиком в освобождённое место. Это был дважды полный провал.
Проблема получалась такая: 22 тысячи раз за секунду основной процессор отбирает доступ к аудиочипу у второго процессора. Второй процессор условно 200 раз за секунду шлет ноты и настройки воспроизведения. 100 шансов к 1, что нота не дойдет до чипа. Уровень ЦАП держится постоянным до обновления значения… Держится постоянным. Постоянным. Если у нас тишина, ноль, тогда зачем мы шлём тишину, ведь только сбиваем ноты? АГА! Пускай музыка нормально играет хотя бы там, где нет голоса, это позволит показать технологию, что эта идея работает. И, кстати, в 4-х битном кодировании, когда аккумулятор равен нулю, то сигнал не меняется, а это не только тишина, но и другие одинаковые значения. Не бинго, но хоть что-то.
Да, слушать невозможно, но цель другая — убедиться, что Cега может вытянуть декодер и музыку. Нужно только время, чтобы это нормально зазвучало, а технически всё получилось.
❯ Часть 3
А что, если всё довести до абсурда, и сделать еще большую степень сжатия? Зачем? А, например, для настоящих диалогов в RPG. Вот это был бы трюк: полноценные голосовые диалоги на Сеге!
Количество битов в два раза уже сокращено, остаётся уменьшать частоту. Уменьшаем до 11 кГц и это становится неприятно слушать. Что делают большие кодеки в таких случаях? Используют разные методы, не связанные напрямую со сжатием. Например, еще в древнем MP3pro или не очень древнем AAC+ используется алгоритм, называемый SBR = side band replication. Идея заключается в том, что высокие частоты сильно коррелируют с нижними, и если во время сжатия сохранить кривую, описывающую эту корреляцию, то при воспроизведении можно просто «нарисовать» высокие частоты из нижних. Результат звучит очень убедительно, от настоящих высоких частот при сильном сжатии отличить сложно, только для настоящих требуется в два раза больший битрейт. Очень классная идея.
А что, если сделать нечто подобное? Например, проигрывать два потока: один исходный 11 кГц, а второй 22 кГц, произведённый из первого. Как создать спектр в 2 раза выше исходного? Проиграть быстрее в 2 раза. У нас же блоки зацикленные, можем замедлять и ускорять воспроизведение как угодно. А громкость дополнительной дорожки отрегулируем в соответствии с уровнем теряющихся высоких частот. Это заработало, но на заднем фоне жалобно визжали бурундуки, надежда, что из-за малой громкости их не будет слышно, не оправдалась.
Очередной долгий тупик. Где раздобыть 22 кГц, точно скоррелированные с сигналом 11 кГц и без особой математики? Параллельно возникла другая проблема. Проигрывание частоты 11 кГц с частотой 22 кГц вызывало дикий звон на верхах, это было ожидаемо, но как это побороть стало понятно не сразу. Линейная интерполяция, конечно, не сильно помогла. Городить полноценную интерполяцию на слабом процессоре в реальном времени — удовольствие для утонченных гурманов, хотя я из таких, но приключений уже был перебор. Писать фильтр низкой частоты? Так он непредсказуемо замедляет сигнал, всё расползётся. Интернет мне ничем не помог, возможно, что я вообще первый человек, которому понадобилось воспроизводить сигнал низкой частоты с удвоенной частотой на слабом процессоре. Звучит бессмысленно, но к этой основе в 22 кГц будет добавляться дорожка с полноценными 22 кГц, поэтому это необходимо. В какой-то момент больше от бессилия, улыбаясь студенческим воспоминаниям, добавил бегущее среднее в 3 строчки. И тут снизошла божественная благодать, радио запело из отрезанной радиоточки, и чёртов ЦАП перестал звенеть. Это работало на эмуляторе, это работало на настоящей приставке.
В ходе борьбы со звоном, в голове постоянно всплывал детский вопрос: «Ну зачем нужна эта увеличенная частота? Почему нельзя воспроизводить 11, а между сэмплами вставлять дополнительные сэмплы, вот и будет в итоге 22.» Такие варианты проверялись в разных комбинациях, но все они звучали как плохие 11 кГц. Интересным показался только простой трюк: каждый сэмпл повторялся с уменьшенной громкостью и обратным знаком. Это совсем не было похоже на искомый результат, но в то же время в нём присутствовали частоты выше 11 кГц (понятно, что выше 5500 Гц, но если ещё мистера Найквиста позовём, то запутаемся в край). Убираем снижение громкости, за сэплом просто следует его отрицательная копия, и, о, чудо: это же те самые 22 кГц, скоррелированные с 11 кГц, без чего вся затея мертва. У нас есть 22 кГц, у нас есть нормальное воспроизведение 11 кГц, теперь всё обязательно заработает.
Правда, эти эксперименты проводились на питоне, а на эмуляторе и железе того же результата не получалось. Расчёска из смеси сигнала со своей отрицательной копией звучала как сильно зашумленный сигнал. Разбираться было бессмысленно, ведь повлиять было не на что. Оставалось попробовать понять физический смысл, заключенный в таком сигнале, ведь на слух было ясно, что это какой-то разностный сигнал, гораздо слабее амплитуды расчёски, а значит его можно рассчитать в явном виде. Скорее всего, при воспроизведении сюрпризов не будет.
Итак, накладываются две волны: прямая и обратная ей, с отставанием в половину сэмпла 11 кГц или один сэмпл 22 кГц. Каждая точка каждой волны участвует в появлении 2 точек общей волны.
Несколько дней размышлений привели к тому, что, очень близким аналогом такого сигнала является производная сигнала, чередующаяся с отрицательной производной: (X2-X1), -(X2-X1), (X3-X2), -(X3-X2). Это зазвучало нормально.
Переходим к кодеру, цикл сжатия фрагментов менять не будем, предполагая, что лучше работать с точностью 22 кГц.
1. Результирующий блок avg преобразуем в 11 кГц.
2. Далее интерполируем блок avg обратно в 22 кГц с помощью бегущего среднего с точностью 8 бит, точно так же, как это происходит в декодере на приставке.
3. Вычисляем ampl_avg_high_part — АЧХ разницы между настоящими 22 кГц и интерполированными.
4. Вычисляем bit_shifted_11 — источник высоких частот, амплитуда которого будет модулироваться. Вычисляется эквивалентно расчёту в декодере.
5. Ядром расчётов является перебор xopt — параметра битового сдвига. В процессе перебора происходит последовательный битовый сдвиг сигнала bit_shifted_11, что позволяет найти такое значение, при котором АЧХ сигнала bit_shifted_11 станет наиболее близко соответствовать потерянным высоким частотам.
6. Далее создаётся сигнал mix, который нужен для расчета максимальной амплитуды и отладки.
for i in range(Total_blocks):
wave_slice = waveform[i * Nframe: (i + 1) * Nframe]
# compression code here
# avg ~ result of compression
restored_sample_len = n_p * (Wl_s[i]//2)
if sample_deficit !=0:
loops = n_p + round(sample_deficit / (Wl_s[i]//2))
if loops > 255:
loops = 255
else:
loops = n_p
avg_11_ = resample(avg, Wl_s[i]//2, axis=0) # половинка
avg_11_[0] = avg[0]
avg_11_[-1] = avg[-1]
n_fft = int(22050 * 1/50)
n_fft = n_fft * 2
hop_length = n_fft // 4
def resample_avg11_to_22():
z=[]
value_array = np.repeat(np.round(avg_11_* 127), 2)
avg_v = value_array[0]
for x in value_array:
avg_v = (avg_v + x)/2
z.append(avg_v)
return np.array(z).astype('int8')
average_resample = resample_avg11_to_22()
avg_high_part = avg[:len(average_resample)] - average_resample/127
ampl_avg_high_part,_ = librosa.magphase(librosa.stft(avg_high_part,n_fft=n_fft,hop_length=hop_length))
bit_shifted_11 = np.round(avg_11_* 127).astype('int16')
bit_shifted_11 = (bit_shifted_11 - np.roll(bit_shifted_11,1))
b1 = bit_shifted_11
b2 = bit_shifted_11 * -1
bit_shifted_11 = np.stack([b1,b2]).flatten(order='F')
dist_opt = np.inf
xopt = 0
for shift_x in range(8):
bit_shifted_avg = bit_shifted_11.astype('int16') >> shift_x
z=[]
avg_v = bit_shifted_avg[0]
for x in bit_shifted_avg:
avg_v = (avg_v + x)/2
z.append(avg_v)
bit_shifted_avg = np.array(z)
if shift_x == 7:
bit_shifted_avg = bit_shifted_avg * 0
ampl_bit_shifted_avg,_ = librosa.magphase(librosa.stft(bit_shifted_avg/127,n_fft=n_fft,hop_length=hop_length))
d = np.linalg.norm(ampl_avg_high_part[:,0] - ampl_bit_shifted_avg[:,0])
if d < dist_opt:
xopt = shift_x
dist_opt = d
bit_shifted_11 = bit_shifted_11.astype('int16') >> xopt
if xopt==7:
bit_shifted_11 = bit_shifted_11 * 0
mix = average_resample/127 + bit_shifted_11/127
if max(abs(mix)) > max_ampl:
max_ampl = max(abs(mix))
Wl_s[i] = Wl_s[i] // 2
sample_deficit = sample_deficit + (Nframe // 2 - Wl_s[i] * loops)
block = {'Wl' : Wl_s[i],
'loops' : loops,
'hi_boost' : xopt,
'block' : avg_11_}
file_bin['Blocks'].append(block)
Про красоту декодера на ассемблере можно сказать только одно: это работает и как хорошо, что это закончилось.
Reload Table
Reload TilFile
'd7 - High_boost
'd6 - Loops value
'd5 - read_bytes_counter
'd4 - akulmulator'|DAC last value'|akulmulator|DAC last value
'd3 - Wl
'd2 - Flag|Average val
'd1 - temp
'd0 - temp
'a2 - quantize table
'a1 - Dac_Block start
Asm
move.B #$01, ($A11100) ; request Z80 bus
move.B #$2B, ($A04000) ; DAC On
move.B #$80, ($A04001) ; DAC On
move.B #$2A, ($A04000) ; Will DAC Out
move.l #__SBSDATA_Power2, a2 ; 4bit_to_value table
move.B (a6)+, d0 ; Read first DAC_byte
clr.L d4 ; Val = 0
clr.L d2 ; Flag, Avg_Val = 0
clr.L d3
move.B d0, d4 ; Val = first_value
@Next_block
move.W d4, d0 ;
Swap d4 ;
move.W d0, d4 ; Save akk, Val d4.L_lo -> d4.L_hi
bclr.L #16, d2 ; Set 1st_2nd_byte_flag = 0
beq.S @Skip_offset_correction
adda #1, a6
@Skip_offset_correction
move.B (a6)+, d3 ; Read Wl
beq @Break ; If Wl = 0: EOF
move.B (a6)+, d6 ; Read Loops
move.B (a6), d7 ; Read High_boost
eori.b #7, d7 ; prepare 7-d7 value
Swap d7 ;
move.B (a6)+, d7 ; Repeat Read High_boost
move.L a6, a1 ; Keep Dac_Block start
@Repeat_Loop
move.B d3, d5 ; Wl->read_bytes_counter
bclr.L #16, d2 ; Set 1st_2nd_byte_flag = 0
@Next_DAC_Byte
bchg.L #16, d2 ; Check & Xor 1st_2nd_byte_flag
bne.S @Second_Nibble ; If 1st_2nd_byte_flag = 1: take 2nd half
move.B (a6), d0 ; Read DAC_byte
lsr.L #4, d0 ; Get first nibble
bra.S @First_Nibble
@Second_Nibble
clr.W d0
move.B (a6)+, d0 ; Read DAC_byte
@First_Nibble
And.W #$000F, d0 ; Filter rubbish Or get second nibble
move.B (a2,d0), d0 ; Convert 4bit To diff value
ror.w #8, d4 ; d4.B ~ akulmulator
cmp.B #21, d4 ; If abs(akulmulator)>21: akulmulator=0
sle d1
And.B d1, d4
cmp.B #-21, d4
sge d1
And.B d1, d4
add.B d0, d4 ; akulmulator = akulmulator + twos[dac_block[i]]
move.B d4, d0
ror.w #8, d4 ; d4.B ~ Val
add.B d0, d4 ; Val = Val + akulmulator
move.B d4, d0
ext.W d0
Swap d3
ext.W d3
Sub.W d3, d0 ; d0 = diff
asr.W d7, d0 ; d0~diff, equalize
Swap d7
asr.B d7, d1 ; compensate asr cycles bias
Swap d7
cmp.B #7, d7 ; special Case To prevent -1
sne d1
And.B d1, d0
add.W d0, d2 ; Avg_Val = High + Avg_Val
move.B d4, d1
ext.W d1
add.W d1, d2 ; Avg_Val = Byte + Avg_Val
asr.W #1, d2 ; Avg_Val = Avg_Val / 2
move.B d2, d1 ; To keep average unchanged
add.B #$80, d1 ; Signed -> unsigned
move.B d1,($A04001) ; DAC_byte out
move.W d0, d1 ;keep diff
move.W #2, d0 ; Prepare pause counter
@Pause
dbf d0, @Pause ; 22 kHz delay
move.W #22, d0 ; Prepare pause counter
@Pause1
dbf d0, @Pause1 ; Read operations delay
Sub.W d1, d2 ; Avg_Val = Avg_Val - High
move.B d4, d1
move.B d4, d3 ; d3 = prev_byte
Swap d3
ext.W d1
add.W d1, d2 ; Avg_Val = Byte + Avg_Val
asr.W #1, d2 ; Avg_Val = Avg_Val / 2
move.B d2, d1 ; Keep average unchanged
add.B #$80, d1 ; Signed -> unsigned
move.B d1,($A04001) ; DAC_byte out
move.W #2, d0 ; Prepare pause counter
@Pause2
dbf d0, @Pause2 ; 22 kHz delay
@No_Pause
subi.B #1, d5 ; Read_bytes_counter - 1
bne @Next_DAC_Byte ; If read_bytes < Wl: Next_DacByte
@Loop_Done
Subq.B #1, d6 ; Loops - 1
beq @Next_block ; If Loops=0: Next_Block
move.L d4, d0
Swap d0
move.W d0, d4 ; Restore akk, Val d4.L_hi -> d4.L_lo
move.L a1, a6 ; Reset datapointer
bra @Repeat_Loop
@Break
End Asm
Print "That End"
TilFile:
DataFile "C:\input.til", Bin
Table:
Data 0,1,4,9,16,25,36,49,64,-1,-4,-9,-16,-25,-36,-49
45 минут цифрового звука на картридже! Слова разобрать можно, часть артефактов получится победить, но для музыки такое качество не годится, только для игр. Правда, из-за сложности декодера, запустить это решение можно лишь на основном процессоре, а значит цикл игры будет прерываться. Впрочем, для диалогов и заставок подойдёт.
❯ Итого
Сделать кодек получилось, дальше есть две ветки развития: бесконечно полировать качество или уйти в экстремальное сжатие, так как опыты показали, что с коэффициентом 1:55 ещё можно различать слова, только непонятно применение. Подошло бы для связи, если бы не требовательный к ресурсам кодер.
В середине процесса разработки, появилась неожиданная мысль, что представление сигнала повторяющимися блоками будет работать в машинном обучении, где проблема невозможности распаковки сжатого звука стоит так же остро. Это станет моим следующим исследованием.
Звуковая система Сеги таит ещё один секрет, лежавший там 20 лет, только сейчас умельцы пытаются подобраться к его использованию на практике. Вся эта работа в конечном итоге была подготовкой к тому, чтобы подойти к этой тайне, имея на руках работающую технологию упрощения частотного спектра.
Возможно, захочется почитать и это:
- ➤ Смартфон для джаваскриптера-олдфага: стоит ли гику брать дешманские девайсы на KaiOS? Смотрим на Nobby 240 LTE
- ➤ Легенда о слоне: как IT-компания Steepler создала Dendy и основала российский консольный рынок
- ➤ От Atari до Ouya: провальные игровые консоли
- ➤ Полигон для творчества за 1500 р. Структура платы, 256 UARTов и расширение спектра
- ➤ Max Payne: хороша ли неонуарная классика сегодня?
Новости, обзоры продуктов и конкурсы от команды Timeweb.Cloud — в нашем Telegram-канале ↩

Комментарии (27)

NickDoom
18.04.2024 08:45+11Аплодирую стоя.
Как было бы шикарно в какой-нибудь аркаде поймать стоп-кадр и услышать по «рации» вот таким вот голосом указания на следующий этап ^______^ Иногда мне кажется, что железо развивалось слишком быстро %) Так много упустили %)


dlinyj
18.04.2024 08:45+5Тут ещё не раскрыт огромный, но очень интересный пласт, который может потянуть несколько статей: это вообще архитектура приставки Sega, особенности разработки под неё. Какие кросскомпиляторы, как записывать Rom на приставку, как сделать свой хелло ворд и т.п. Ах, ассемблер, это же так круто.

Crash13
18.04.2024 08:45+2В идеале бы еще зацепить и другие платформы тех лет, например, PSX. Там тоже было много чего интересного. До сих пор вспоминаю с содроганием "reverse engineering" (96-97 года) с возможностью проверить гипотезу только записав образ на болванку. Для записи, помню, можно было использовать только резак "Teac" за штукарь зеленых и болванки проигрывались только обычные (без перезаписи). Потом, с годами, стало все просто и понятно, но первые годы,... Ж)

shiru8bit
18.04.2024 08:45+2На Genesis на ассемблере сейчас пишет полтора человека. Для 68K есть вполне нормальный GCC, которым в основном и пользуются.

Stanislavvv
18.04.2024 08:45+3Напомнило, как дофига лет назад мне попался .mod, в котором было NN сэмплов из Mo-Do - Eins Zwei Polizei и с их помощью реконструировали всю песню. Размер не помню, но с учётом того, что принесли на 5-дюймовой дискетке несколько .mod — вряд ли мегабайт :-)

man_of_letters Автор
18.04.2024 08:45Кстати, да. Ваш комментарий напомнил мне, что я забыл написать что-либо про трекерную музыку. Sega - это отличная консоль для прослушивания трекерной музыки и когда-нибудь появится возможность запускать большинство существующих композиций на ней.
dlinyj
18.04.2024 08:45+1Интересно было бы сделать некоторый плеер на базе консоли. Это забавная идея, надо сделать только на контроллере возможность доступа к файлам. Другое дело, какая скорость мапинга там требуется?
Нонче, правда. весьма шустрые МК есть за 200 рублей, так что успеют мапить.man_of_letters Автор
18.04.2024 08:45+6Существуют разные варианты насилия над Сегой, мне кажется неспортивным расширение девайсами, которые нельзя было бы купить в 90х. Интересно жить в понятных рамках. А контроллеры, FPGA, это всё превращает сегу в терминал и она исчезает как бы.
dlinyj
18.04.2024 08:45Я искренне разделяю эти чувства. Но в таком случае надо отказываться от эмуляторов и универсальных картриджей. Ведь эти картриджи содержат контроллер.
Тут интерес чуточку иной, мы же вместе понимаем что задействуем железо именно сеги для этих целей, а реализацию переноса файлов на устройство удобно и в стиле "тех лет" не знаю как реализовать, так чтобы это было просто и доступно. Не дискетку же городить?man_of_letters Автор
18.04.2024 08:45+3Универсальный картридж переливает образ в ПЗУ, и остаётся за кадром, система работает без изменений. А читать музыкальные треки с внешнего устройства это уже вызывает вопросы. Подобное устройство могло тогда существовать, но было бы оно у 80% владельцев приставки? Наверное это уже личный выбор, удобство против каноничности. С другой стороны в старших моделях универсальных картриджей более высокие лимиты(~32мб) на размер ROM, может и не надо ничего придумывать
dlinyj
18.04.2024 08:45Ну можно архитектурно что-то такое и придумать, чтобы не было мучительно больно :)

gxcreator
18.04.2024 08:45+3
хехе
Crash13
18.04.2024 08:45Какой стильный комбайн :) Я бы купил
Роботы сгенерили сей прекрасный образ?
LevC
18.04.2024 08:45+1Ну почему же роботы? Вполне реальные человеки: https://ru.wikipedia.org/wiki/Sega_Mega-CD

kowalski
18.04.2024 08:45+3Вот так выглядит относительно недавний плеер .mod файлов для Megadrive (4 канала, 26.4КГц). Там, конечно, просто ROM, без доступа к файлам. Вообще флеш-картриджи по идее дают шариться по SD, но куда читать?
А вот так, например, звучит тот же самый Tom's Diner, только 13 лет назад и на Commodore 64 (64К RAM, мегагерц тактовой, а DAC, строго говоря, вообще отсутствует). Ещё и со спецэффектами сверху)
И напоследок кластерный поиск, которым невозможно, но если очень хочется, то можно. Пациент тот же.



JTG
18.04.2024 08:45+3Характер звучания получается интересный: лёгкий цифровой перегруз (усреднение периодов работает как компрессор) и артефакты, похожие на погрешности плёночных носителей
В качестве демки просится это:
dlinyj
18.04.2024 08:45Тут уж если пилить такую демку, то надо полноценную делать, типа такой.
А тут уже и писиспикер более-менее справляется.
dlinyj
Спасибо за шикарную хабратортную статью! Я и не думал, что на сеге возможно проигрывать звук, и не понимал почему нет диалогов и используется только MIDI.
У меня возник вопрос, по теме увеличения частоты дискретизации: почему нельзя было использовать интерполяцию? Линейную, кубическую, сплайнами Акимы? Хотя скользящее среднее - это хороший фильтр.
man_of_letters Автор
Любой алгоритм интерполяции требует хотя бы операции умножения. Операция умножения на процессоре M68000 очень медленная и может занимать разное количество тактов в зависимости от умножаемых чисел. Она настолько тормозная, что одна эта команда может выполняться дольше одного цикла декодера. Классические алгоритмы интерполяции не реализовать. Существуют специальные методы интерполяции, использующие предвычисленные таблицы. Но они содержат множество операций, и скорости процессора не хватит чтобы в паузе между сэмплами частотой 22 кГц успеть рассчитать новую точку.
А про линейную интерполяцию и среднее написано в статье:
Резкие перепады сигнала линейная интерполяция не сглаживает, звук почти не отличается от исходного.
Этот метод и был использован, так как сочетает заметный эффект и быструю работу
dlinyj
Обожаю старое железо, которое позволяет пошерстеть мозгом. Великолепные высокотехнологические ребусы.
NickDoom
Атмега :) Там ещё и практический выхлоп есть :)
А вообще я всё ещё мечтаю об идеальном 4-битном MCU с кэшем-стеком и ручной выборкой строк флэша и DRAM, чтобы можно было оптимизировать до последнего транзистора/такта даже эту, обычно прозрачную, сторону вопроса :)
Заранее послать RAS, посчитать пока что-то в стеке (он же SRAM-кэш), пройтись CAS'ами по тому, что прочиталось, зарефрешить всё это обратно, послать ещё один RAS…
А если DRAM ещё и троичная (можно зарядить в одну или другую сторону), то нужно два чтения CAS (для положительных и отрицательных зарядов) и два рефреша, а потом софтово разбираться в полученном :) Но возможность такой DRAM пока под вопросом — изоляция в микрухах в основном сделана по принципу «p-n переход, повёрнутый своей „закрытой“ стороной», я немного заказные микрухи делал по молодости :) Такое «задом наперёд» фиг зарядишь :) А жаль, можно было бы ещё больше выжать из каждого ключа!
dlinyj
Как-то слишком сложно даже для меня, но я вот курю документацию на четырёхбитный микроконтроллер тетриса . На хабре было много статей по теме его реверса. Недостаток только один: нет sdk и он масочный, но уже есть эмуляторы ;)
Ti2
Только не midi, а FM (YM2612) каналы. Если под диалогами имеются ввиду озвучки с использованием pcm канала (который заменяет FM6), это есть чуть ли не в каждой второй игре (dune, rrr, vectorman). Обычно качество 10,4 Кгц. В MK3 и UMK3 6,5 Кгц c 4-bit дельта сжатием. В другой половине игр, в которых 'озвучки' нет, pcm канал всё равно используется для сэмплов ударных (kick, snare, tom и т.д.) и звуков, которые сложно сделать используя FM или PSG. Так что стандартная конфигурация - это 5xFM+1xPCM+3xPSG. А вот PSG каналы как раз не все игры используют. Например , Contra Hard Corps не использует, но при этом она программно микширует до 3 pcm, то есть выходит 5xFM+3xPCM (8,7 Кгц). И это всё работает (как правило) только на процессоре z80, без участия основного процессора mc68000.
dlinyj
Спасибо за ответ. Я вообще не в теме, и половина того что вы написали для меня непонятно. Не то чтобы я не занимался звуком (демку для Микроши делал), но так глубоко не копал.