
Меня зовут Сергей Бронников, я работаю в команде Tarantool. Когда я только присоединился к ней, то вёл для себя заметки по мере погружения в разработку. Эти заметки я решил переработать в статью. Она может быть интересна тестировщикам в проектах на C/C++ или пользователям Tarantool, которые хотят узнать, сколько мы усилий прикладываем к тому, чтобы снизить вероятность появления проблем в новых версиях.
Популярной статьей такого рода является описание тестирования библиотеки SQLite за авторством Ричарда Хиппа. Но у SQLite есть специфика: их инструменты тяжело переиспользовать в других проектах. Это следствие того, что у команды разработчиков SQLite есть обязательства поддерживать библиотеку как минимум до 2050 года, и для сокращения внешних зависимостей они все инструменты пишут сами с нуля (например, тест-раннер, инструмент для мутационного тестирования, Fossil SCM). У нас таких требований нет, поэтому в выборе инструментов мы не ограничены и пользуемся всем, что приносит пользу. И если вас что-то заинтересует, то вы достаточно легко сможете это принести в свой проект на C/C++. Если я вас заинтересовал — велкам под кат.
Как известно, тестирование — это часть разработки. Я расскажу о нашем подходе к разработке Tarantool, помогающем выловить до финального релиза подавляющее большинство багов. У нас тестирование действительно неотделимо от самой разработки, и каждый в команде отвечает за качество. Всё уместить в одну статью не получилось, поэтому в самом конце я привёл ссылки на другие статьи, которые могут её дополнить.
Ядерная часть Tarantool состоит из кода, который полностью написан нами, внешних компонентов и библиотек. Некоторые, впрочем, тоже написаны нами. Это важно, потому что большую часть сторонних компонентов мы тестируем только косвенно, во время интеграционного тестирования.
В большинстве случаев качество внешних компонентов на хорошем уровне, но было исключение — библиотека libcurl. При её использовании иногда случались memory corruptions. Поэтому из runtime-зависимости libcurl стал git-модулем в нашем репозитории.
За поддержку языка Lua отвечает LuaJIT, который включает в себя как среду исполнения языка, так и трассирующий JIT компилятор. Наша версия LuaJIT уже давно отличается от ванильного набором патчей, они добавляют как фичи, например профилировщик, так и новые тесты. Поэтому мы тщательно тестируем свой форк, чтобы не допустить регрессий. Хотя исходный код LuaJIT открыт и доступен под свободной лицензией, однако он не включает в себя регрессионные тесты. Поэтому мы собрали свой регрессионный тестовый набор из тестов для реализации Lua от PUC Rio, набора тестов от Франсуа Перра (François Perrad), тестов для других форков LuaJIT, и, конечно же, дополнили нашими собственными тестами.
Из других внешних библиотек это:
MsgPuck для сериализации данных в формате msgpack;
libcoro для реализации файберов;
libev для асинхронного ввода-вывода;
c-ares для асинхронного разрешения DNS-имён;
libcurl для работы с протоколом HTTP;
icu4c для поддержки Unicode;
OpenSSL, libunwind и zstd для сжатия данных;
small — наш набор специализированных аллокаторов памяти;
lua-cjson для работы с JSON, lua-yaml, luarocks, xxHash, PMurHash и других.
Основная часть проекта написана на C, небольшие части на C++ (в сумме 36 KLOC) и меньшая часть на Lua (14 KLOC).
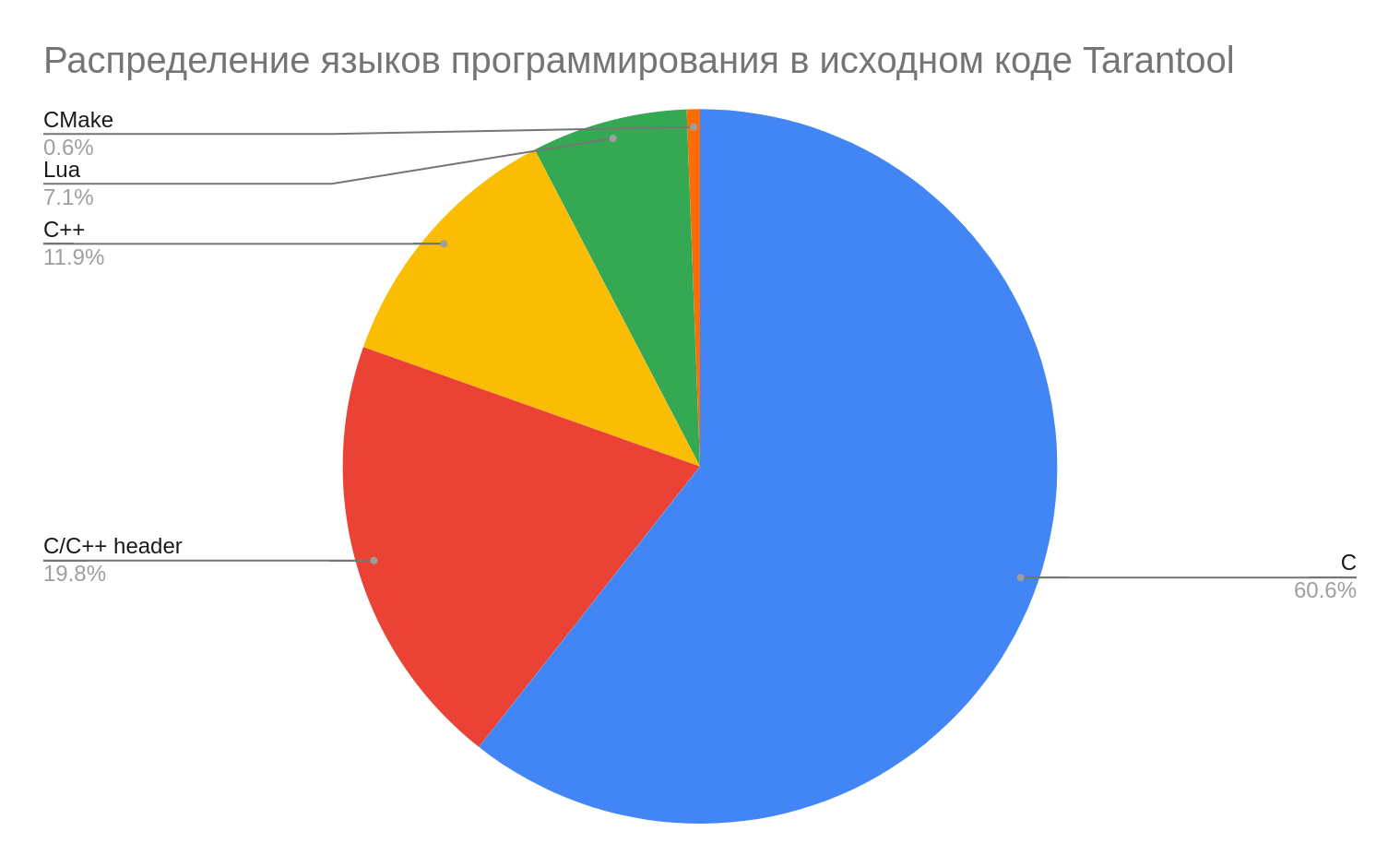
Подробный вывод статистики в cloc
767 text files.
758 unique files.
82 files ignored.
github.com/AlDanial/cloc v 1.82 T=0.78 s (881.9 files/s, 407614.4 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 274 12649 40673 123470
C/C++ Header 287 7467 36555 40328
C++ 38 2627 6923 24269
Lua 41 1799 2059 14384
yacc 1 191 342 1359
CMake 33 192 213 1213
...
-------------------------------------------------------------------------------
SUM: 688 25079 86968 205933
-------------------------------------------------------------------------------Остальные языки относятся к инфраструктуре проекта или тестам: CMake, Make, Python (часть старых тестов написана на нём, но сейчас мы его не используем для написания тестов).
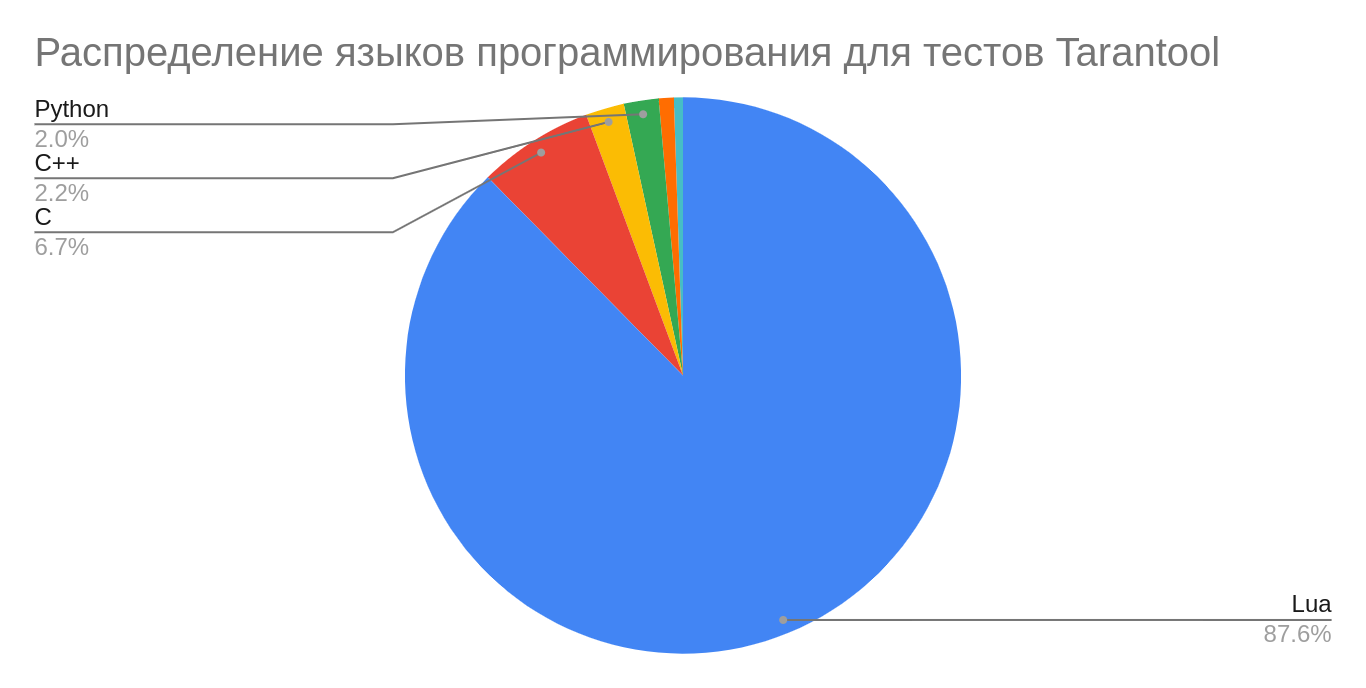
Подробный вывод cloc о распределении языков в тестах
2076 text files.
2006 unique files.
851 files ignored.
github.com/AlDanial/cloc v 1.82 T=2.70 s (455.5 files/s, 116365.0 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Lua 996 31528 46858 194972
C 89 2536 2520 14937
C++ 21 698 355 4990
Python 57 1131 1209 4500
C/C++ Header 11 346 629 1939
SQL 4 161 120 1174
...
-------------------------------------------------------------------------------
SUM: 1231 37120 51998 225336
-------------------------------------------------------------------------------Из такого распределения используемых языков программирования следует один из основных акцентов тестирования: выявление проблем, присущих языкам с ручным управлением памятью (stack-overflow, heap-buffer-overflow, use-after-free и других). Наша система непрерывной интеграции неплохо с этим справляется. В следующей части расскажу о её устройстве.
Непрерывная интеграция
В разработке у нас находится несколько веток Tarantool: основная ветка (master) и по одной ветке для каждой версии (1.10.x, 2.1.x, 2.2.x и т.д.). Новая функциональность появляется в новых минорных версиях, а bug fix’ы появляются во всех ветках. При слиянии в каждой из веток проходит полный цикл регрессионного тестирования с разными компиляторами, с разными опциями сборки, сборка пакетов под разные платформы и много чего ещё, об этом подробнее ниже. Всё это происходит автоматически в едином конвейере. Патчи попадают в основную ветку только после успешного прохождения всего конвейера. Пока что мы добавляем патчи в основную ветку вручную, но движемся в сторону автоматизации.
Сейчас у нас примерно 870 интеграционных тестов, и при тестировании в 5 потоков они проходят за 10 минут. Это, вроде бы, не так много, но тестирование в CI параметризовано разными семействами и версиями операционных систем, архитектурами, разными компиляторами и их опциями, поэтому общее время тестирования может достигать получаса.
Мы запускаем тесты на большом наборе ОС:
шесть версий Ubuntu;
три версии Debian;
пять версий Fedora;
две версии CentOS;
две версии OpenSUSE и FreeBSD;
две версии macOS.
Некоторые конфигурации ещё параметризуются версиями и опциями компилятора. Некоторые платформы имеют номинальный статус поддержки, например, macOS; их в основном используют разработчики. Другие, типа FreeBSD, активно тестируются, но случаи использования FreeBSD-порта Tarantool в production мне неизвестны. Третьи, как, например, Linux, широко используются для промышленной эксплуатации Tarantool нашими клиентами и пользователями.
Поэтому вторым уделяется больше внимания при разработке. Запуск тестов на разных операционных системах влияет на качество в проекте. Разные семейства ОС имеют разные аллокаторы памяти, могут иметь разные реализации libc, и редко, но такие отличия тоже позволяют находить баги.
Основная архитектура для нас это amd64, недавно добавили поддержку arm64 и она тоже представлена в CI. Запуск тестов на процессорах разных архитектур позволяет сделать код более портируемым за счёт разделения платформозависимого и платформонезависимого кода. Так можно выявлять баги, связанные с другим порядком байтов (big-endian vs little-endian), разной скоростью выполнения инструкций, разными результатами математических функций или с такими редкостями, как «минус ноль». Ещё такое тестирование облегчает портирование кода на новую архитектуру, если появится такая необходимость. Сильнее всего привязан к платформе LuaJIT, в нём используется много ассемблера и из кода на Lua он сразу генерирует машинный код.
Когда-то давно, когда не было такого разнообразия облачных CI-систем, мы, как и многие проекты, использовали Jenkins. Потом появился Travis-CI, интегрированный с GitHub, мы переехали на него. Наша матрица тестирования сильно выросла и бесплатная версия Travis-CI не позволяла подключать свои серверы, поэтому переехали на Gitlab CI. Из-за проблем с интеграцией GitHub PR’ов мы, как только появился GitHub Actions, начали плавный переезд на него, и теперь во всех проектах (а у нас в GitHub-организации их несколько сотен) пользуемся только им.
Можно сказать, что Github это наша платформа для всего цикла разработки: планирования задач, хранения кода, проверки новых изменений — полностью тестируем там. Для этого мы используем как свои физические серверы или виртуальные машины в облаке VK Cloud Solutions, так и виртуальные машины, которые предоставляет Github Actions. GitHub не лишён недостатков: иногда он недоступен, иногда происходят глюки, но у него хорошее соотношение цена-качество.
Если хотите разрабатывать переносимый код, то нужно его тестировать на разных операционных системах и архитектурах.
Инспекция кода
Как во всех нормальных проектах с хорошей культурой разработки, все патчи проходят тщательную проверку двумя другими разработчиками. Процедура проверки описана в открытом документе. Во многом он описывает оформление патчей и самопроверку изменений перед отправкой на анализ. Не буду пересказывать этот документ, расскажу только о моментах, которые затрагивают тестирование:
для патчей, которые исправляют баг, должен добавляться тест, который воспроизводит проблему;
для патчей, которые добавляют новую функциональность — как минимум один тест, а лучше много тестов, покрывающих эту функциональность;
тест не должен успешно проходить без патча;
тест не должен быть flaky, то есть после нескольких запусков показывать и успешный, и неуспешный результат;
тест не должен быть медленным, таким образом мы сохраняем небольшую длительность тестирования. Долгие тесты запускаются с отдельной опцией тест-раннеру.
Инспекция кода позволяет проверять изменения ещё одной парой глаз.
Статический и динамический анализ
Статический анализ мы используем для контроля общего стиля программирования и для поиска ошибок. Оформление кода должно соответствовать руководствам по стилю Lua, Python и С. Руководство по стилю для С во многом повторяет руководство по стилю ядра Linux, а руководство по стилю для кода на Lua следует стилю по умолчанию в luacheck, за исключением некоторых предупреждений, которые мы обычно выключаем. Всё это позволяет содержать код в едином стиле и улучшает удобочитаемость.
В сборочных файлах CMake мы используем флаги компиляторов, которые включают дополнительные проверки во время сборки, и следуем правилу «чистой» сборки, когда в выводе компилятора нет никаких необработанных предупреждений. Помимо статического анализа в самих компиляторах мы используем статический анализ в Coverity. Один раз использовали PVS-Studio, и он нашёл несколько некритичных ошибок в самом Tarantool и коннекторе tarantool-c. Ещё эпизодически использовали cppcheck, но не то чтобы он приносил много багов.
В кодовой базе Tarantool много Lua-кода, и когда мы решили исправить все предупреждения, которые он нашёл, то большинство их было о нарушении стиля программирования, и только четыре настоящих ошибки в основном коде и одна ошибка в коде тестов. Так что, если вы пишете на Lua, то не пренебрегайте luacheck и пользуйтесь им с самого начала.
Все новые изменения тестируются на сборках с включенными динамическими анализаторами для выявления проблем с памятью в C/C++ (Address Sanitizer), неопределённого поведения в C/C++ (UndefinedBehavior Sanitizer). Так как эти анализаторы могут влиять на производительность приложения, то по умолчанию флаги, которые их включают, выключены. Address Sanitizer хорошо себя показывает в CI, но для использования в канареечных сборках у него всё-таки большой overhead. Я пробовал пользоваться ночной сборкой Firefox, когда Mozilla стала включать в них ASAN, и комфортно им пользоваться было невозможно. Что говорить о СУБД с высокими требованиями к скорости. Но с GWP-ASAN этот overhead меньше, и мы думаем, как его применить в пакетах с промежуточными сборками.
Если санитайзеры выявляют проблемы на уровне кода, то assert’ы, повсеместно используемые в нашем коде, выявляют проблемы нарушения инвариантов в функциональности. Технически это макрос, который является частью стандартной библиотеки Си. assert() проверяет переданное выражение и завершает выполнение, если результат равен нулю. Всего около 5 000 таких проверок, они всегда включены только в отладочной сборке и выключены в релизных.
Сборочная система поддерживает и Valgrind, но выполнение кода под ним гораздо медленнее, чем с санитайзерами, поэтому в CI эта сборка не тестируется.
Функциональные регрессионные тесты
Так как интерпретатор Lua встроен в Tarantool и интерфейс к СУБД реализован с помощью Lua API, то использование Lua для тестов выглядит логичным следствием. Большая часть наших регрессионных тестов написана на Lua с использованием встроенных модулей Tarantool. Один из них — модуль TAP для тестирования кода на Lua. Он реализует набор примитивов для проверок в коде и структурирования тестов. Удобно, что есть некоторый минимум, которого достаточно для тестирования приложений на Lua. Многие модули или приложения, которые мы делаем, только этот модуль для тестирования и используют. Как очевидно из названия, он позволяет выводить результаты в формате TAP (Test Anything Protocol); пожалуй, это самый старый формат для тестовой отчётности. Часть тестов параметризованные (например, выполняются с двумя движками), и если учитывать тесты в разных конфигурациях, то их количество вырастает в полтора раза.
Большая часть функциональности Tarantool доступна с помощью Lua API, а если и нет, то можно получить к ней доступ с помощью FFI. FFI удобен в использовании, когда функция на C не должна быть частью Lua API, но нужна для теста. Главное, чтобы она не была объявлена как static. Пример использования С-кода в Lua с помощью FFI (правда, лаконично?):
local ffi = require "ffi"
ffi.cdef [[
int printf(const char *fmt, ...);
]]
ffi.C.printf("Hello %s!", "world")Для некоторых частей Tarantool, таких как самодостаточные библиотеки raft, http_parser, csv, msgpuck, swim, uuid, vclock и т. д., написаны модульные тесты. Для их написания используется header-only библиотека на С в стиле TAP-тестов.
Для запуска тестов мы используем собственный инструмент — test-run.py. Сейчас кажется спорным писать свой тест-раннер с нуля, но он уже есть и мы его поддерживаем. В проекте есть разные типы тестов: модульные написаны на С и запускаются как бинари, и, как и в случае c TAP тестами, test-run.py для них анализирует успешность выполнения тестовых сценариев по выводу в TAP-формате:
TAP version 13
1..20
ok 1 — trigger is fired
ok 2 — is not deleted
ok 3 — ctx.member is set
ok 4 — ctx.events is set
ok 5 — self payload is updated
ok 6 — self is set as a member
ok 7 — both version and payload events are presented
ok 8 — suspicion fired a trigger
ok 9 — status suspected
ok 10 — death fired a trigger
ok 11 — status dead
ok 12 — drop fired a trigger
ok 13 — status dropped
ok 14 — dropped member is not presented in the member table
ok 15 — but is in the event context
ok 16 — yielding trigger is fired
ok 17 — non-yielding still is not
ok 18 — trigger is not deleted until all currently sleeping triggers are finished Часть тестов сравнивает фактический вывод теста с эталонным: вывод нового теста сохраняют в файл и при дальнейших запусках сравнивают с фактическим. Такой подход, например, популярен для SQL-тестов (что в MySQL, что в PostgreSQL): достаточно написать нужные конструкции на SQL, выполнить, убедиться, что вывод корректный, и сохранить в файл. Надо только убедиться, что ввод получается всегда детерминированный, иначе добавите себе flaky-тестов. Вывод может зависеть от установленной локали в системе (поможет NO_LOCALE=1), от сообщений об ошибках, от времени или даты в выводе и т.д.
Такой подход у нас используется в тестах для поддержки SQL или репликации, потому что он удобен для отладки кода: можно вставлять тесты прямо в консоль и переключаться между экземплярами. Можно в интерактивном режиме экспериментировать, а потом этот код использовать как сниппет для тикета или сделать из него тест.
test-run.py позволяет нам запускать все типы тестов однообразно с формированием общего отчёта.
Для тестирования проектов на Lua у нас есть отдельный фреймворк luatest. Изначально это форк другого хорошего фреймворка luaunit. Форк позволил нам теснее интегрировать его с Tarantool (например, добавить специфичные фикстуры) и добавить много новых фич (интеграция с luacov, поддержка статуса XFail и др.) без зависимости от проекта luaunit.
Интересна история появления тестов для поддержки SQL в Tarantool. Мы взяли за основу часть кода SQLite, а именно парсер SQL-запросов и компилятор в байт-код с помощью VDBE. Одной из причин этого было близкое к 100 % покрытие тестами кода SQLite. Только вот тесты были написаны на языке TCL, а мы его совсем не используем. Чтобы портировать тесты, написанные на TCL, мы написали транслятор с TCL на Lua и после причёсывания получившегося кода импортировали их в кодовую базу. Этими тестами пользуемся до сих пор и по мере необходимости добавляем новые.
Отказоустойчивость — одно из требований к серверному ПО. Поэтому во многих тестах у нас используется внедрение сбоев (error injections) на уровне самого кода Tarantool. Для этого в исходном коде есть набор макросов и интерфейс в Lua API для включения. К примеру, нам нужно добавить сбой, который будет эмулировать задержку при записи в WAL. Добавляем ещё одну запись в массив ERRINJ_LIST в src/lib/core/errinj.h:
--- a/src/lib/core/errinj.h
+++ b/src/lib/core/errinj.h
@@ -151,7 +151,6 @@ struct errinj {
_(ERRINJ_VY_TASK_COMPLETE, ERRINJ_BOOL, {.bparam = false}) \
_(ERRINJ_VY_WRITE_ITERATOR_START_FAIL, ERRINJ_BOOL, {.bparam = false})\
_(ERRINJ_WAL_BREAK_LSN, ERRINJ_INT, {.iparam = -1}) \
+ _(ERRINJ_WAL_DELAY, ERRINJ_BOOL, {.bparam = false}) \
_(ERRINJ_WAL_DELAY_COUNTDOWN, ERRINJ_INT, {.iparam = -1}) \
_(ERRINJ_WAL_FALLOCATE, ERRINJ_INT, {.iparam = 0}) \
_(ERRINJ_WAL_IO, ERRINJ_BOOL, {.bparam = false}) \и добавляем этот сбой в код, который отвечает за запись операции в WAL:
--- a/src/box/wal.c
+++ b/src/box/wal.c
@@ -670,7 +670,6 @@ wal_begin_checkpoint_f(struct cbus_call_msg *data)
}
vclock_copy(&msg->vclock, &writer->vclock);
msg->wal_size = writer->checkpoint_wal_size;
+ ERROR_INJECT_SLEEP(ERRINJ_WAL_DELAY);
return 0;
}После этого можно включить задержку записи в журнал в отладочной сборке с помощью Lua-функции:
$ tarantool
Tarantool 2.8.0-104-ga801f9f35
type 'help' for interactive help
tarantool> box.error.injection.get('ERRINJ_WAL_DELAY')
---
- false
...
tarantool> box.error.injection.set('ERRINJ_WAL_DELAY', true)
---
- true
...Всего добавили 90 сбоев в разные части Tarantool, и с каждым из них выполняется как минимум один функциональный тест.
Интеграционное тестирование с экосистемой
Экосистема Tarantool состоит из большого количества коннекторов для разных языков программирования, вспомогательных библиотек для реализации популярных архитектурных паттернов (например, кеш или персистентная очередь). Помимо этого есть продукты, написанные на Lua с использованием функциональности Tarantool: Tarantool DataGrid и Tarantool Cartridge. Мы дополнительно тестируем предрелизные версии Tarantool с этими модулями и продуктами для проверки обратной совместимости.
Рандомизированное тестирование
Про часть наших тестов я хочу написать отдельно, потому что они отличаются от обычных тестов тем, что данные в них генерируются автоматически и случайным образом. В обычном регрессионном наборе таких тестов нет, они запускаются отдельно.
Ядро Tarantool написано, в основном, на С, и даже при аккуратной разработке трудно избежать проблем с управлением памятью: use-after-free, heap buffer overflow, NULL pointer dereference. Их наличие крайне нежелательно для серверного ПО. К счастью, развитие динамического анализа и технологий фаззинг-тестирования в последнее время позволяют снизить количество этих неприятностей в проекте.
Выше я говорил, что Tarantool использует сторонние библиотеки. Многие из них уже применяют фаззинг-тестирование: проекты curl, c-ares, zstd и openssl регулярно тестируются в инфраструктуре OSS Fuzz. В коде Tarantool много мест, где используется код для синтаксического разбора (например, SQL или парсинг HTTP-запросов) или разбора структур MsgPack. Такой код может быть уязвим для багов, связанных с управлением памятью. К счастью, фаззинг-тесты хорошо выявляют такие проблемы. Для Tarantool тоже есть интеграция с OSS Fuzz, но тестов пока не очень много и мы нашли только один баг в библиотеке http_parser. Возможно, со временем количество таких тестов будет увеличиваться, для желающих добавить новый есть подробная инструкция.
В 2020 году мы добавили поддержку синхронной репликации и MVCC. Появился запрос на тестирование этой функциональности и мы решили часть тестов сделать на основе фреймворка Jepsen. Консистентность проверяем с помощью анализа истории транзакций. Но рассказ про тестирование с помощью Jepsen вполне потянет на отдельную статью, поэтому об этом в следующий раз.
Нагрузочное тестирование и тестирование производительности
Одна из фич, из-за которых выбирают Tarantool, это высокая производительность. Было бы странно не тестировать её. У нас есть неформальный критерий — 1 миллион операций вставки кортежей в секунду на обычном железе. Каждый может запустить его на своей машине и получить 1 Mops на Tarantool своими собственными руками. Вот такой просто сниппет на Lua может быть неплохим вариантом бенчмарка для запуска с синхронной репликацией:
sergeyb@pony:~/sources$ tarantool relay-1mops.lua 2
making 1000000 operations, 10 operations per txn using 50 fibers
starting 1 replicas
master done 1000009 ops in time: 1.156930, cpu: 2.701883
master speed 864363 ops/sec
replicas done 1000009 ops in time: 3.263066, cpu: 4.839174
replicas speed 306463 ops/sec
sergeyb@pony:~/sources$ Для тестирования производительности мы запускаем и стандартные бенчмарки: популярные YCSB (Yahoo! Cloud Serving Benchmark), nosqlbench, linkbench, sysbench, TPC-H и TPC-C. А также cbench, наш собственный бенчмарк для Tarantool API. В нём примитивные операции написаны на С, а сценарии описываются на Lua.
Метрики
Для оценки покрытия кода регрессионными тестами мы собираем информацию о покрытии кода. Сейчас у нас покрыто 83 % всех строк и 51 % всех веток кода, это неплохие показатели. Для визуализации покрытых участков используем Coveralls. В случае сбора информации о покрытии кода на C/C++ ничего нового — инструментирование кода с опцией -coverage, запуск тестов и формирование отчёта с помощью gcov и lcov. А вот в случае Lua ситуация чуть хуже: здесь примитивный профилировщик, и luacov предоставляет информацию только о покрытии строк. Это немного расстраивает.
Релизный чеклист
Выпуск каждой новой версии сопряжён с ворохом разнообразных задач, за которые отвечают разные команды: тегирование релиза в репозитории, публикация пакетов со сборками, публикация документации на сайте, проверка результатов функционального тестирования и производительности, проверка открытых багов и триаж на следующий milestone, и т.д. Выпуск новой версии легко превратить в хаос или забыть о каком-то из шагов. Чтобы такого не случилось, мы описали процесс выпуска в виде чеклиста и следуем ему перед выпуском новой версии.
Заключение
Как говорил Козьма Прутков, «Нет предела совершенству». Со временем совершенствуются процессы и технологии для выявления багов, баги становятся сложнее и заковыристее, и чем сложнее и изощреннее система тестирования и обеспечения качества, тем меньше багов доходит до пользователя.
Полезные ссылки
Видеозапись и слайды доклада Роберто Иерузалимски о тестировании интерпретатора Lua (рекомендую!).
How SQLite Is Tested — популярная статья Ричарда Хиппа о том, как тестируется библиотека SQLite.
The Untold Story of SQLite With Richard Hipp — интервью с Ричардом Хиппом, в котором он, в числе прочего, рассказывает про тестирование SQLite.
Как я сократил код для нагрузочного тестирования в три раза — статья от коллег про успешное использование k6 для нагрузочного тестирования Tarantool.
Кто такая эта Ваша Pandora и при чем здесь Tarantool — статья от коллег про тестирование производительности в проектах, построенных на основе Tarantool (спойлер — с помощью Pandora).
Про библиотеку SMALL мой коллега написал подробную статью — Работа с памятью в Tarantool: Small — Specialized Memory ALLocators.
Как мы работаем над стабильностью нашей реализации Lua — доклад, в котором разработчик LuaVela рассказывает о тестировании и разработке одного из форков LuaJIT.
Fuzzing для тестирования JVM: зачем и как — интересный доклад о фаззинге JIT-компилятора.
Комментарии (14)

estet Автор
11.11.2021 14:46+1Привет, правильно я понял что error injections реализован через гитовые патчи кода?
Не понял, что такое гитовые патчи.
Если да, то почему не через тестовые имплементации интерфейсов (если это применимо для LUA)?
Наверное потому, что так было проще сделать. То, что вы описываете используется в SQLite, там есть набор вызовов, которые нужны библиотеке от ОС и легко можно реализацию менять на свою, см. https://www.sqlite.org/vfs.html.
Или, скажем, не через через фреймворки врапперы диска и прочих систем (как например сделано в Кафке - https://cwiki.apache.org/confluence/display/KAFKA/Fault+Injection)?
Обычно используют два подхода для внедрения сбоев: со стороны приложения и со стороны тестового окружения. У обоих подходов есть как плюсы так и минусы.
Для внедрения сбоев со стороны приложения большой плюс в простоте реализации, но есть минус - мы меняем код приложения и тем самым тестируем не тот код, который пойдёт в релиз. Есть даже специальные библиотеки для внедрения сбоев на уровне приложения - например https://github.com/pingcap/failpoint или https://github.com/albertito/libfiu. Соответственно для внедрения сбоев со стороны тестового окружения минус в том, что надо каким-то образом проксировать функции ОС, которые использует приложение (например сделать специальную ФС, использовать LD_PRELOAD и т.к.).


randoom
11.11.2021 15:27тем самым тестируем не тот код
Да, это именно то - что подтолкнуло меня к вопросу.
Не понял, что такое гитовые патчи.
Выглядит - как будто вы применяете гитовый патч на коде в релизной ветке, но не пушите, перекомпиливаете, и получаете измененную версию, в данном случае - с задержкой.
код из статьи напоминающий git patch Если все так - то при рефакторинге все рискует поехать, как этот риск закрываете?
estet Автор
11.11.2021 15:39Выглядит - как будто вы применяете гитовый патч на коде в релизной ветке, но не пушите, перекомпиливаете, и получаете измененную версию, в данном случае - с задержкой.
Реализация сбоев всегда в коде основной ветки проекта.
randoom
11.11.2021 17:54Так все-же, что на картинке?
Кто и как вносит изменения в код, и когда?
estet Автор
11.11.2021 21:17Так все-же, что на картинке?
Пример кода, который добавляет новый сбой в код Тарантула.
Кто и как вносит изменения в код, и когда?
Автор патча может добавить новый сбой тогда, когда посчитает нужным.
Если посмотрите на пример такого патча, то думаю все вопросы отпадут - https://github.com/tarantool/tarantool/commit/a82ec30466
randoom
12.11.2021 12:36Если посмотрите на пример такого патча
Суровые мерж-комментарии однако :)
то думаю все вопросы отпадут
К сожалению нет. Моего знания С и Lua явно недостаточно для понимания всех нюансов фикса.
Из того что вижу (скорректируйте где ошибся)
1) В продакшен код (в кору) добавляются методы вида `ERROR_INJECT(XXX, ...`
2) Срабатывают такие методы если в сценарии сказать `_(XXX, ERRINJ_BOOL, {.bparam = true})\`, видимо это настраивается на CI, так как по дефолту - false.
3) Итого тестовый код перемешан с рабочим, но отделен семантически через `ERROR_INJECT(...`.
estet Автор
12.11.2021 12:47В целом вы правильно поняли это работает :)
видимо это настраивается на CI, так как по дефолту - false.
Обычно, да, все сбои выключены, включаются при необходимости в самом тесте.
randoom
12.11.2021 13:13Супер, но тогда я вижу
небольшую проблему.Дело даже не в том
что "продакшен код загрязнен тeстовым" или
что "тестируется не то что в продакшене", а немного другой алгоритм (привет сайдэффекты! - в моей практике были случаи когда волатайл чтение помогало тестовому коду не падать, но этого чтения не было в продакшен коде :))
, а что непонятно как вы угадываете где вставить проблему.
Проблема же может случиться между любыми двумя строчками, а если говорим о многопоточке - то от сочетания сайдэффектов/рассинхрона между множеством потоков.
Насколько профитны такие тесты по отношению к "честным внедрениям сбоев со стороны тестового окружения"?
Есть ли Jepsen/Ducktape-like что-то в проекте?
estet Автор
12.11.2021 14:09Проблема же может случиться между любыми двумя строчками, а если говорим о многопоточке - то от сочетания сайдэффектов/рассинхрона между множеством потоков.
В Tarantool есть несколько потоков, каждый из них занимается своей задачей: поток для обработки транзакций, поток для работы с запросами из сети, поток для работы с WAL. (подробнее про архитектуру в этой статье). Если мы, например, добавляем сбой для журнала (WAL), то это повлияет только на работу потока, который работает с WAL.
Поэтому в этом плане поведение детерминированное.
Есть ли Jepsen/Ducktape-like что-то в проекте?
Jepsen - да. Цитирую статью: "В 2020 году мы добавили поддержку синхронной репликации и MVCC. Появился запрос на тестирование этой функциональности и мы решили часть тестов сделать на основе фреймворка Jepsen. Консистентность проверяем с помощью анализа истории транзакций. Но рассказ про тестирование с помощью Jepsen вполне потянет на отдельную статью, поэтому об этом в следующий раз.".
Про Ducktape-like не понял, что имеется ввиду.
randoom
12.11.2021 16:23то это повлияет только на работу потока, который работает с WAL.
Поэтому в этом плане поведение детерминированное.
Не готов поверить что нет влияния одного на другое.
Когда ломается что-то, оно обязательно цепанет что-то еще, если копнуть.
У нас, например, 60к тестов и очень часто вообще несвязанные компоненты аффектятся при багфиксах. Там гонка, тут контеншен, где-то вообще пул кончился, тут вообще читаем с локальной копии (оказывается), а здесь через сеть зацепило и тд.
Про Ducktape-like не понял, что имеется ввиду.
https://ducktape-docs.readthedocs.io/en/latest/
Это, скажем так, альтернативный Jepsen вариант тестирования отказами и не только, где сценарии могут быть любыми, не только проверка ACID.
------
непонятно как вы угадываете где вставить проблему
Насколько профитны такие тесты по отношению к "честным внедрениям сбоев со стороны тестового окружения"?
Вопросы все еще актуальны, очень интересно.
estet Автор
12.11.2021 17:59https://ducktape-docs.readthedocs.io/en/latest/
Это, скажем так, альтернативный Jepsen вариант тестирования отказами и не только, где сценарии могут быть любыми, не только проверка ACID.
Не слышал про такой. Судя по документации это набор примитивов для написания кластерных тестов. Оно живое? Там последний коммит был 8 месяцев назад.
Не готов поверить что нет влияния одного на другое.
Когда ломается что-то, оно обязательно цепанет что-то еще, если копнуть.
У нас, например, 60к тестов и очень часто вообще несвязанные компоненты аффектятся при багфиксах. Там гонка, тут контеншен, где-то вообще пул кончился, тут вообще читаем с локальной копии (оказывается), а здесь через сеть зацепило и тд.
Я рассказываю вам о том, что работает и используется в нашем процессе разработки. Очевидно, что если бы это не работало, то этим бы никто и не пользовался. Архитектура и код вашего проекта мне неизвестны, по каким-то причинам у вас это значит не работает.
непонятно как вы угадываете где вставить проблему
Тут, наверное, не совсем правильно использовать слово "угадывать".
ERRINJ вставляем в тех местах, где нужно симулировать сбой. Он просто временно меняет логику, чтобы проверить поведение, которое в нормальной ситуации не должно случиться.
Насколько профитны такие тесты по отношению к "честным внедрениям сбоев со стороны тестового окружения"?
Могу только в теории рассуждать. Частично ответил выше про плюсы и минусы одного и другого подхода. Могу добавить, что для быстрого и фокусного негативного тестирования подходит вариант с fault injection в коде Tarantool, а вариант с fault injection в окружении больше работает когда есть дополнительные ресурсы поддерживать инфраструктуру с этими fault injection. Так сказать первый вариант больше для разработчиков, второй - когда есть ресурсы в команде тестировщиков.
Кстати, fault injection в коде СУБД это не инновация Tarantool, точно такой же подход используется в MySQL (и в MariaDB наверняка).
randoom
12.11.2021 18:42Оно живое?
Определенно.
Используется в Kafka и Ignite.
Я на этом чуде ускорил crash recovery с десятков секунд до десятков миллисекунд на кластерах в 100+ узлов.
Архитектура и код вашего проекта мне неизвестны,
Apache Ignite.
https://github.com/apache/ignite
по каким-то причинам у вас это значит не работает.
Оно не НЕ работает, вопрос в необычном (для меня) подходе.
У нас есть тесты где мы останавливаем/фильтруем/изменяем сообщения например, потому что тестируем какой нить конкретный фэйловер.
При этом, тормозим мы их, реализуя "тормозитор" для конкретного теста/кейса, который тормозит только нужные сообщения или нужное число сообщений или сообщения на конкретный узел. Тоесть мы создаем именно те проблемы которые нужны тесту переопределяя необходимые компонены тестовыми имплементациями, а не располагаем проблемы по коду кроекта (с включением их через матрицу на CI).
Еще есть тесты на Ducktape - где мы "портим" окружение, но тут у нас подходы похожи.
Отсюда мой вопрос - почему был выбран этот вариант и чем он профитнее варианта создавать сложности именно в рамках конретного теста/кейса.
ERRINJ вставляем в тех местах, где нужно симулировать сбой.
Кажется что сбой может произойти между любыми двумя строчками же. При этом сбой может быть очень разным (задержка сети, диска, памяти, etc). Имея регрессию в тысячи тестов мы, потенциально, покрываем этот момент.
Располагая же инъекции ошибок по коду - невозможно ведь вставить их везде, между всеми строками, или код ошибок будет составлять 99.999% кода проекта.
И мой вопрос здесь именно в том - как вы ухитряетесь делать мало таких вставок и эффективно ловить проблемы.
estet Автор
12.11.2021 19:27+1Я на этом чуде ускорил crash recovery с десятков секунд до десятков миллисекунд на кластерах в 100+ узлов.
Судя по всему вот здесь ваши тесты - https://github.com/apache/ignite/tree/master/modules/ducktests/tests/ignitetest/tests Какие аккуратные тесты.
Отсюда мой вопрос - почему был выбран этот вариант и чем он профитнее варианта создавать сложности именно в рамках конретного теста/кейса.
Я думаю ответ - простота реализации и потому что так привык тестировать человек, который до этого разрабатывал MySQL.
Располагая же инъекции ошибок по коду - невозможно ведь вставить их везде, между всеми строками, или код ошибок будет составлять 99.999% кода проекта.
Да, тут вы правы. В симуляции сбоев в окружении у нас все более реалистично получается: если сбоит дисковая подсистема, то ошибки будут на всех файловых операциях у приложения. А с инъекциями в коде мы покрываем только конкретный кусочек кода. Мне кажется хорошая аналогия это юнит-тесты и интеграционные тесты. Первые быстрые, но далеки от бизнес требований, вторые долгие и сложные, но зато покрывают требования. В идеале лучше комбинировать оба подхода.
И мой вопрос здесь именно в том - как вы ухитряетесь делать мало таких вставок и эффективно ловить проблемы.
Хм, может тут Правило Парето в действии? ;-)
Сомневаюсь, что с инъекциями в коде можно переловить все проблемы, поэтому в тестах Jepsen у нас тоже сбои есть (хотя и не все).


randoom
Привет, правильно я понял что error injections реализован через гитовые патчи кода?
Если да, то почему не через тестовые имплементации интерфейсов (если это применимо для LUA)?
Или, скажем, не через через фреймворки врапперы диска и прочих систем (как например сделано в Кафке - https://cwiki.apache.org/confluence/display/KAFKA/Fault+Injection)?