
Несмотря на свою кажущуюся банальность, темы о вычислении синуса достаточно регулярно появляются на хабре. И каждый раз их авторы или делают сомнительные утверждения, или получают сомнительные результаты. Не в силах более терпеть, я тоже решил поучаствовать и внести свой, не менее сомнительный вклад в этот вопрос.
▍ Введение
Существуют три основных подхода к аппроксимации функций многочленами:
1. Разложение в ряд Тейлора:
Наиболее простой, наиболее известный (потому что его проходят в школе) и наименее эффективный. По сути представляют собой аппроксимацию через конечное количество производных в отдельно взятой точке, откуда и следуют его недостатки — ошибка аппроксимации возрастает по мере удаления от этой точки, далеко не для всех функций быстро сходится, для некоторых функций не сходится вообще, для некоторых функций в некоторых точках не применим вообще.
2. Метод наименьших квадратов:
Чуть менее известный, более сложный, но и более эффективный. Его идея заключается в минимизации площади между функцией и её аппроксимирующим многочленом. Недостатком является тот факт, что из минимизации площади вовсе не следует минимизация максимальных отклонений — поэтому ошибка аппроксимации хоть и осциллирует, но всё равно имеет тенденцию возрастать на краях диапазона.
3. Многочлены Чебышева:
Ещё более сложный, наименее известный, но часто наиболее оптимальный метод. Оптимальность его проистекает из того, что ошибка распределена по всему диапазону и ограничение максимального отклонения задаётся by design. Сложность вытекает из того, что сначала нужно считать коэффициенты для каждого отдельного многочлена Чебышева через далеко не простые интегралы даже для простых функций (в частности, для синуса получаются функции Бесселя, которые далеко не в каждом калькуляторе присутствуют), а затем их пересчитывать для суммарного итогового многочлена с запасом по точности. К счастью, имея в своём распоряжении современные системы компьютерной алгебры, всё это можно сделать лёгким движением руки, даже не вникая особо глубоко в математические основы происходящего.
Следует заметить, что этими тремя методы аппроксимации вовсе не ограничиваются — можно и производные считать в нескольких точках, а не только в одной, и другие разложения в степенные ряды применять, и рациональные многочлены использовать (например, аппроксимацию Паде и его вариации), а также различные варианты мини-макс алгоритмов.
▍ Подготовка
Используя Wolfram Mathematica, определим функцию, возвращающую аппроксимирующий многочлен заданного порядка для произвольной функции:
ChebyshevApproximation[n_, f_, x_] := N[Table[Integrate[
f ChebyshevT[k, x] (2/(\[Pi] Sqrt[1-x^2])), {x, -1, 1}], {k, 0, n}], 20] //
#[[1]]/2 + Sum[#[[k+1]] ChebyshevT[k, x], {k, 1, n}] & // SimplifyЗдесь точность полученных коэффициентов равна 20 десятичным знакам — для наших целей этого достаточно. Можно также задать отдельные реализации для чётных/нечётных функций, чтобы ускорить вычисления. Для нечётных функций она будет выглядеть как
ChebyshevOddApproximation[n_, f_, x_] := N[Table[2 Integrate[
f ChebyshevT[k, x] (2/(\[Pi] Sqrt[1-x^2])), {x, 0, 1}], {k, 1, n, 2}], 20] //
Sum[#[[((k+1)/2)]] ChebyshevT[k, x], {k, 1, n, 2}] & // Simplifyа для чётных как:
ChebyshevEvenApproximation[n_, f_, x_] := N[Table[2 Integrate[
f ChebyshevT[k, x] (2/(\[Pi] Sqrt[1-x^2])), {x, 0, 1}], {k, 0, n, 2}], 20] //
#[[1]]/2 + Sum[#[[((k+2)/2)]] ChebyshevT[k, x], {k, 2, n, 2}] & //
SimplifyNChebyshevApproximation[n_, f_, x_] := N[Simplify[Table[
NIntegrate[f ChebyshevT[k, x] (2/(\[Pi] Sqrt[1-x^2])), {x, -1, 1},
WorkingPrecision ->30, Exclusions->x^2 == 1, MaxRecursion -> 25], {k, 0, n}] //
Map[Sign[#] Max[0, (Abs[#]-10^-20)] &, #] & //
#[[1]]/2 + Sum[#[[k+1]] ChebyshevT[k, x], {k, 1, n}] &], 20]▍ Начало
Наиболее надёжный способ ускорить вычисление синуса — просто уменьшить степень аппроксимирующего многочлена, пожертвовав точностью. При использовании многочленов Чебышева количество верных знаков ориентировочно соответствует степени многочлена
f = Sin[x Pi/2];
p7 = ChebyshevApproximation[7, f, x]Получили многочлен:
Реально полученную погрешность можно увидеть, если вывести на график разницу между исходной функцией и этим многочленом:
Plot[f - p7 // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic}, WorkingPrecision -> 20] // Quiet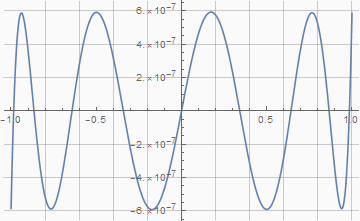
По графику видно, что на краях диапазона погрешность принимает максимальное значение. Это значит, что sin(90°) с таким многочленом будет равен не единице, а 0.999999414195269. Если важно, чтобы была именно единица — то для этого можно пойти на хитрость и немного расширить диапазон аппроксимации таким образом, чтобы отклонение на краях
p71 = Block[{z = 1, p},
Do[p = ChebyshevOddApproximation[7, Sin[x Pi/2/z], x] /. x -> x z // Simplify;
z *= (x /. FindRoot[(p-Sin[x Pi/2])==0, {x, 1}]), 5]; p]Результат:
Вот как теперь выглядит график отклонений:
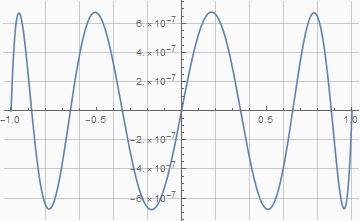
Погрешность неизбежно выросла, но совершенно незначительно.
Чтобы получить полноценную функцию синуса, необходимы вспомогательные манипуляции для приведения аргумента к диапазону
Сами функции будут выглядеть так:
double Sin7(double x)
{
x *= 0.63661977236758134308; // 2/Pi
bool sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
if ((xf & 1) == 1)
x = 1 - x;
bool per = ((xf >> 1) & 1) == 1;
double xx = x * x;
double y = x * (1.5707903005870776 + xx * (-0.6458858977085938 +
xx*(0.07941798513358536 - 0.0043223880120647346 * xx)));
return sign^per ? -y : y;
}double Sin7(double x)
{
x *= 0.63661977236758134308; // 2/Pi
int sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
if ((xf & 1) == 1)
x = 1 - x;
int per = ((xf >> 1) & 1) == 1;
double xx = x * x;
double y = x * (1.5707903005870776 + xx * (-0.6458858977085938 +
xx*(0.07941798513358536 - 0.0043223880120647346 * xx)));
return sign ^ per ? -y : y;
}В версии для C/C++ тип bool заменён на int — как показали измерения, компилятор в этом случае генерирует более эффективный код.
Здесь нужно сделать важное замечание. В целях оптимизации для получения целой части аргумента здесь используется не функция Floor(x), а приведение к целому типу (чтобы избежать вызова внешней библиотечной функции). Это приводит к тому, что аргумент не должен превышать максимальное для int значение, а именно 2147483647. Тип int можно заменить на long (а правильнее — на unsigned long), но в зависимости от платформы и компилятора это также может привести к замедлению кода. На достаточно больших значениях аргумента также возрастает погрешность из-за разности порядков у аргумента и периода
▍ Продолжение
При увеличении степени многочлена увеличивается количество вычислений и как следствие, накапливается дополнительная погрешность. Поэтому для близкой к double точности разумно разбить диапазон
fs4 = Sin[x Pi/4];
p13 = ChebyshevOddApproximation[13, fs4, x];
fc4 = 1-Cos[x Pi/4];
p12 = ChebyshevEvenApproximation[12, fc4, x];
Row[{CForm[(p13 /. x -> 2 x // HornerForm) /. x^2 -> xx] // Framed,
CForm[(p12 /. x -> 2 x // HornerForm) /. x^2 -> xx] // Framed}]
GraphicsRow[{
Plot[fs4 - p13 // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic},
WorkingPrecision -> 20, Background -> Hue[0.14, 0, 0.98]] // Quiet,
Plot[fc4 - p12 // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic},
WorkingPrecision -> 20, Background -> Hue[0.14, 0, 0.98]] // Quiet},
ImageSize -> Large, Spacings -> 5]Графики ошибок:

Здесь ошибка для косинуса получилась чуть больше, чем у синуса — но это не имеет значения, потому что они всё равно замаскируются накопленными погрешностями при вычислении многочлена.
double Sin13(double x)
{
x *= 0.63661977236758134308; // 2/Pi
bool sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
if ((xf & 1) == 1)
x = 1 - x;
bool per = ((xf >> 1) & 1) == 1;
double y;
if (x <= 0.5)
{
double xx = x * x;
y = x * (1.5707963267948965822 + xx * (-0.6459640975062407217 +
xx * (0.07969262624592800593 + xx * (-0.0046817541307639977752 +
xx * (0.00016044114022967599853 + xx * (-3.5986097146969802712e-6 +
5.629793865626169033e-8 * xx))))));
}
else
{
x = 1.0 - x;
double xx = x * x;
y = 1.0 - xx * (1.2337005501361513498 + xx * (-0.25366950789986513871 +
xx * (0.020863480734953519901 + xx * (-0.0009192599500952791151 +
xx * (0.000025200135454917479526 - 4.6552987291490935821e-7 * xx)))));
}
return sign^per ? -y : y;
}double Sin13(double x)
{
x *= 0.63661977236758134308; // 2/Pi
int sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
if ((xf & 1) == 1)
x = 1 - x;
int per = (xf >> 1) & 1;
double y;
if (x <= 0.5)
{
double xx = x * x;
y = x * (1.5707963267948965822 + xx * (-0.6459640975062407217 +
xx * (0.07969262624592800593 + xx * (-0.0046817541307639977752 +
xx * (0.00016044114022967599853 + xx * (-3.5986097146969802712e-6 +
5.629793865626169033e-8 * xx))))));
}
else
{
x = 1.0 - x;
double xx = x * x;
y = 1.0 - xx * (1.2337005501361513498 + xx * (-0.25366950789986513871 +
xx * (0.020863480734953519901 + xx * (-0.0009192599500952791151 +
xx * (0.000025200135454917479526 - 4.6552987291490935821e-7 * xx)))));
}
return sign ^ per ? -y : y;
}Такая реализация уже почти соответствует точности большинству библиотечных реализаций, но всё равно уступает им по точности в несколько бит.
▍ Табличный метод
Наивное представление о табличном методе состоит в том, что в таблице хранятся заранее вычисленные значения для узловых точек, а промежуточные значения получаются интерполяцией между ними. Заранее вычисленные значения действительно имеются, но промежуточные значения вычисляются не интерполяцией, а используя тригонометрические тождества:
где
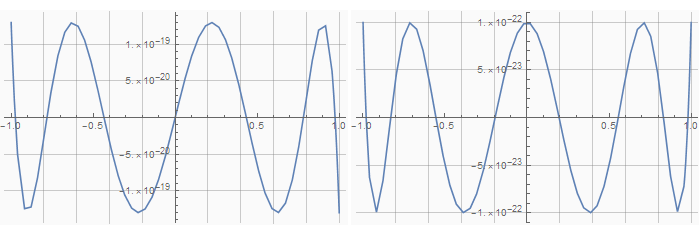
Оптимальный размер таблицы n выбирается экспериментально, чтобы разница между функциями
With[{count = 128, n = 5, m = 6},
fs = Sin[x Pi/2/count];
ps = ChebyshevOddApproximation[n, fs, x];
fc = Cos[x Pi/2/count];
pc = ChebyshevEvenApproximation[m, fc, x];
Row[{CForm[(ps // HornerForm) /. x^2 -> xx] // Framed,
CForm[(pc // HornerForm) /. x^2 -> xx] // Framed}]
GraphicsRow[{
Plot[fs - ps // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic},
WorkingPrecision -> 20, Background -> Hue[0.14, 0, 0.98]],
Plot[fc - pc // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic},
WorkingPrecision -> 25, Background -> Hue[0.14, 0, 0.98]]
}, ImageSize -> 700, Spacings -> 5] // Quiet
]Графики ошибок для 5-ой (синус) и 6-ой (косинус) степеней:
Код для получения таблицы тоже предельно прост:
With[{n = 128}, Table[N[Sin[x Pi/2], 18], {x, 0, 1, 1/n}]]{0, 0.0122715382857199261, 0.024541228522912288, 0.0368072229413588323,
0.0490676743274180143, 0.0613207363022085778, 0.0735645635996674235,
0.0857973123444398905, 0.098017140329560602, 0.110222207293883059,
0.122410675199216198, 0.134580708507126186, 0.146730474455361752,
0.158858143333861442, 0.170961888760301226, 0.183039887955140959,
0.195090322016128268, 0.20711137619221855, 0.219101240156869797,
0.23105810828067112, 0.24298017990326389, 0.254865659604514572,
0.266712757474898386, 0.278519689385053105, 0.290284677254462368,
0.302005949319228067, 0.313681740398891477, 0.325310292162262934,
0.336889853392220051, 0.348418680249434568, 0.359895036534988149,
0.371317193951837543, 0.382683432365089772, 0.393992040061048109,
0.405241314004989871, 0.416429560097637183, 0.427555093430282094,
0.438616238538527638, 0.4496113296546066, 0.460538710958240024,
0.471396736825997649, 0.482183772079122749, 0.492898192229784037,
0.503538383725717559, 0.514102744193221727, 0.524589682678468906,
0.534997619887097211, 0.545324988422046422, 0.555570233019602225,
0.565731810783613197, 0.575808191417845301, 0.58579785745643886,
0.595699304492433343, 0.605511041404325514, 0.615231590580626845,
0.624859488142386377, 0.634393284163645498, 0.643831542889791465,
0.653172842953776764, 0.662415777590171761, 0.671558954847018401,
0.680600997795453051, 0.689540544737066925, 0.698376249408972854,
0.707106781186547524, 0.715730825283818654, 0.724247082951466921,
0.732654271672412835, 0.740951125354959091, 0.749136394523459325,
0.757208846506484548, 0.765167265622458926, 0.773010453362736961,
0.780737228572094478, 0.788346427626606262, 0.795836904608883536,
0.80320753148064491, 0.810457198252594792, 0.817584813151583697,
0.824589302785025264, 0.831469612302545237, 0.838224705554838043,
0.844853565249707073, 0.851355193105265142, 0.85772861000027207,
0.863972856121586738, 0.870086991108711419, 0.876070094195406607,
0.88192126434835503, 0.887639620402853948, 0.89322430119551532,
0.898674465693953843, 0.903989293123443332, 0.909167983090522377,
0.914209755703530655, 0.919113851690057744, 0.923879532511286756,
0.928506080473215566, 0.932992798834738888, 0.937339011912574923,
0.941544065183020778, 0.945607325380521326, 0.949528180593036667,
0.953306040354193837, 0.956940335732208865, 0.960430519415565811,
0.963776065795439867, 0.966976471044852109, 0.970031253194543993,
0.972939952205560145, 0.975702130038528544, 0.978317370719627633,
0.980785280403230449, 0.983105487431216327, 0.985277642388941245,
0.987301418157858382, 0.989176509964780973, 0.990902635427780025,
0.992479534598709998, 0.993906970002356042, 0.995184726672196886,
0.996312612182778013, 0.997290456678690216, 0.998118112900149207,
0.998795456205172393, 0.999322384588349501, 0.99969881869620422,
0.999924701839144541, 1}Значения синуса и косинуса из неё получаются в зависимости от того, индексировать её с начала в конец или наоборот. Стоит уточнить, что здесь по факту размер получается на единицу больше, то есть 129 (из-за замыкающей единицы для
double[] sincostable = {...};
void SinCos(double x, out double sina, out double cosa)
{
x *= 0.63661977236758134308; // 2/Pi
bool sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
bool rev = (xf & 1) == 1;
if (rev)
x = 1 - x;
bool per = ((xf >> 1) & 1) == 1;
double z = x * 128;
int zf = (int)z;
z -= zf;
double sint = sincostable[zf];
double cost = sincostable[128 - zf];
double zz = z * z;
double ss = z * (0.012271846303085128928 + zz * (-3.0801968454884792651e-7 +
2.3193461291439683491e-12 * zz));
double cc = 1.0 - zz * (0.000075299105843272081 + zz*(-9.449925567834354484e-10 +
4.7437807891647010749e-15 * zz));
sina = (sign ^ per) ? -sint * cc - cost * ss : sint * cc + cost * ss;
cosa = (rev ^ per) ? sint * ss - cost * cc : cost * cc - sint * ss;
}const double sincostable[] = {...};
void SinCosByTable(double x, double* sina, double* cosa)
{
x *= 0.63661977236758134308; // 2/Pi
int sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
int rev = xf & 1;
if (rev)
x = 1 - x;
int per = (xf >> 1) & 1;
double z = x * 128;
int zf = (int)z;
z -= zf;
double sint = sincostable[zf];
double cost = sincostable[128 - zf];
double zz = z * z;
double ss = z * (0.012271846303085128928 + zz * (-3.0801968454884792651e-7 +
2.3193461291439683491e-12 * zz));
double cc = 1.0 - zz * (0.000075299105843272081 + zz * (-9.449925567834354484e-10 +
4.7437807891647010749e-15 * zz));
*sina = (sign ^ per) ? -sint * cc - cost * ss : sint * cc + cost * ss;
*cosa = (rev ^ per) ? sint * ss - cost * cc : cost * cc - sint * ss;
}Табличный метод можно использовать и по-другому — только для синуса, если разбить интервал
▍ Как тестировать
Когда речь идёт о реализации с меньшей точностью, то можно сравнивать значения с библиотечной реализацией и таким образом считать максимальное отклонение. Однако на точности близкой к double такой подход не прокатит — поскольку библиотечные реализации тоже имеют погрешности. Можно экспортировать значения в Wolfram Mathematica, но это сложнее и имеет свои тонкости, поскольку преобразование числа в формате double к текстовому десятичному виду также может искажать значения младших бит; или же можно экспортировать стороннюю библиотеку с заведомо большей точностью и сравнивать результаты уже в ней. Однако есть и другой путь — считать какую-нибудь функцию, значение которой можно посчитать аналитически, и сравнивать с этим значением полученный результат. У какой реализации будет наименьшее отклонение — та и точнее.
Хорошим кандидатом для этого является функция, суммирующая квадраты синусов с аргументами, равномерно распределённых в диапазоне от
Также нужно учитывать, что некоторые современные оптимизирующие компиляторы (в частности C++ от Intel и Microsoft) могут распознать сумму и вычислять её в 4 параллельных потоках на регистрах AVX, что при замерах производительности может показать значительное превосходство библиотечных реализаций (да, я столкнулся с этим). Чтобы этого избежать, можно на каждом этапе менять знак (то есть считать функцию
Можно рассмотреть и другие сценарии — например, вращать единичный вектор через комплексное умножение, который должен вернуться в исходное состояние, или же выполнять прямое и обратное FFT, и сравнивать полученный результат с исходным — но здесь мы не будем на этом подробно останавливаться, поскольку выбор корректного метода тестирования сильно зависит от конкретной цели использования.
using System.Diagnostics;
…
long count = (long)1e9;
Stopwatch sw = new Stopwatch();
double sum, secs;
sum = 0.0;
sw.Restart();
for (long i = -count; i <= count; i++)
{
double x = (double)i * Math.PI / count;
double y = Math.Sin(x);
sum += y * y;
}
secs = sw.ElapsedMilliseconds / 1000.0;
Console.WriteLine("mathsin\t{0}\t{1}", secs, sum - count);
...
// повторить для других реализаций#define _USE_MATH_DEFINES
#include <math.h>
#include <time.h>
...
long n = (long)1e9;
double sum;
double sign;
sum = 0;
sign = 1;
clock_t t = clock();
for (long i = -n; i <= n; i++)
{
double x = (double)i * M_PI / n;
double y = sin(x);
sum += y * y * sign;
sign = -sign;
sign = -sign;
}
t = clock() - t;
std::cout << "mathsin: dur: " << double(t) / CLOCKS_PER_SEC << ", " << sum - n << endl;
...
// повторить для других реализацийВ варианте для C/C++ добавлено немного бесполезных вычислений во избежание автоматической векторизации. Также по-хорошему его можно реализовать на шаблонах, чтобы не дублировать одинаковые куски кода для разных функций.
В обоих случаях время измеряется в секундах с точностью до миллисекунд. Сделано это для того, чтобы привести результаты к общему знаменателю и не зависеть от платформо-зависимых средств и отсутствующем в си std::chrono. Ну и заодно стимулировать выполнять код достаточно долго, чтобы накопилось хотя бы несколько секунд.
▍ Заключение и результаты
При замерах производительности все рассмотренные реализации оказались быстрее библиотечных и на C#, и на C++ с компилятором от Microsoft. На C++ была дополнительно протестирована функция fsincos из математического сопроцессора FPU процессоров x86/x64, которая тоже умеет считать и синус, и косинус одновременно.
Сводная таблица по результатам замеров на Core i7:
| реализация \ ускорение (в разы) | C# (.NET 4.8) | C++ (VS2019) | C++ vs. C# |
| библиотечная | 1 | 1 | 2.8 |
| Sin7 | 6.06 | 2.07 | 1.09 |
| Sin13 | 4.08 | 1.25 | 1.1 |
| SinCos | 2.62 | 1.21 | 1.3 |
| fsincos (FPU) | - | 0.28 | - |
Как обстоят дела с множеством других компиляторов и платформ — это тема отдельного исследования, которым, если честно, заниматься совсем не хочется. Но было бы интересно увидеть результаты от другого независимого источника.
Измерения точности с накоплениями погрешностей также дали вполне ожидаемый результат и на больших
Насколько скорость рассмотренных реализаций стоит нескольких дополнительных бит погрешности — каждый решает сам для себя самостоятельно. Однако лично я сам думаю, что если погрешность в несколько последних бит имеет критически важное значение — то точности double тут явно недостаточно и нужно переходить на другие типы данных. Также для увеличения точности вычислений можно использовать специальные техники — но это тема уже для отдельной статьи.

Комментарии (39)

kasyachitche
28.10.2021 12:37+7Из описания к таблице ничего не понятно. Что за цифры в таблице? Это соотношение производительности? Соотношение времени выполнения? Значение больше 1 — это превосходство предложенной реализации или стандартной?

Refridgerator Автор
28.10.2021 12:51+1Это отношение времени выполнения библиотечной реализации ко всем прочим. Sin7 выполняется в 6 раз быстрее, чем Math.Sin, то есть затрачивает в 6 раз меньше времени.

staticmain
28.10.2021 12:49+2У вас в коде для С битовый сдвиг для знакового числа. Это Implementation defined код.

technic93
28.10.2021 13:36+1можно было сделать xf unsigned и заменить битовые операции на деление и остаток.
Вот только для x > max_int могут быть проблемы с этим методом, технически там тоже уб в этом пребразовнии. Практически если число такое большое что погрешность точности порядка пи, синус всё равно не посчитать.


Zalechi
28.10.2021 14:53+16Выкусите, те кто говорят, что математика не нужна в программировании! /раунд/

DistortNeo
28.10.2021 19:12+6Сам по себе скалярный синус не особо интересен. Интересно вычисление синуса в векторных регистрах. И тут реализаций огромное множество. Хотелось бы видеть сравнение с векторными библиотеками, например Intel SVML. Вот, например, реализация синуса под AVX-512:
https://github.com/numpy/SVML/blob/main/linux/avx512/svml_z0_sin_s_la.s
Впечатляет код?Refridgerator Автор
29.10.2021 04:13Сравнивать с вручную написанным кодом на ассемблере — безнадёжное занятие. Мой личный рекорд на этом поприще — ускорение в 40 раз (вот тут писал об этом), причём даже без использования векторных регистров. А ещё векторные регистры можно использовать и для увеличения точности вычислений. Чистый синус в этом плане действительно мало интересен, а вот алгоритмы типа FFT, свёртки, рекурсивных фильтров, численного интегрирования или перемножения матриц — самое то.
DistortNeo
29.10.2021 11:15+1Сравнивать с вручную написанным кодом на ассемблере — безнадёжное занятие.
Почему же? Это сравнение наглядно покажет, насколько бесперспективно написание велосипедов.
Мой личный рекорд на этом поприще
Мой личный рекорд: реализация FFT на ~10-15% быстрее, чем fftw для изображения определённого размера. Причём не на ассмеблере, а на C++ с интринсиками. Но времени убил очень много.
а вот алгоритмы типа FFT, свёртки, рекурсивных фильтров, численного интегрирования или перемножения матриц — самое то.
А там особо ничего, кроме как доступа к памяти и кэшу, оптимизировать и не получится. А сложные алгоритмы перемножения матриц с хорошей асимптотикой далеко не всегда дают хорошие результаты.
Refridgerator Автор
29.10.2021 11:52А там особо ничего, кроме как доступа к памяти и кэшу, оптимизировать и не получится
То был список алгоритмов, в которых важна не только скорость, но и точность, поскольку все они страдают накоплением погрешности. SSE/AVX можно использовать для повышения их точности без особого ущерба производительности — просто это менее очевидно, чем распараллеливание однотипных вычислений.


dlinyj
29.10.2021 14:30+3Как ни странно, тема очень даже актуальная. Пример, мне надо генерировать синусоиду с помощью ШИМ на микроконтроллере, и для каждой итерации брать значение синуса. Всё хорошо, когда есть табличные значения, а если у тебя точка не попадает в таблицу? Брать линейную интерполяцию между точками? В данном случае погрешность не очень большая, но всё же.
Тут интересно порешать задачку, при сильных ограничениях в мощностях.Refridgerator Автор
29.10.2021 15:20+2Если нужна именно синусоида, то значения можно вычислять итеративно.
Как-то так// начальная инициализация cs = 1; // текущий косинус sn = 0; // текущий синус dx = pi / 65536; // приращение фазы cosdx = cos(dx); sindx = sin(dx); // цикл генерации синусоиды while (true) { tt = cs * cosdx - sn * sindx; sn = sn * cosdx + cs * sindx; cs = tt; amp = sqrt(cs*cs+sn*sn); cs /= amp; sn /= amp; }
Правда, при такой реализации фаза неизбежно будет «плавать».
UPD: возможно, что можно увеличить устойчивость такого метода при использовании ещё и предыдущих значений.
sim31r
30.10.2021 21:08Тут хватило бы билинейной интерполяции. Типа
F(x) = x[n] + K1*(x-x[n]) + K2*(x-x[n])^2
где x[n] ближайшее значение из таблицы
K1 можно взять или из аналогичной таблицы значений K1 посчитать как x[n+1] - x[n], линейная интерполяция
K2 взять из таблицы ранее рассчитанной, билинейная интерполяция
члены третьей и далее степени вряд ли нужны в данном контексте, при обычном ШИМ управлении двигателем, излишняя точность утонет в "шуме" общем системе.
Плюс таблица может быть без фиксированного шага по dx, в некоторых местах кривая аппроксимируется лучше, в других хуже, но это усложняет алгоритм, скорее всего необоснованно, метод интересен только теоретически.
Вот тут пример линейной интерполяции на С++ для ЦАП, подробно всё расписано, точности для практических применений хватает с запасом
Refridgerator Автор
31.10.2021 06:49Ну раз на то пошло дело, то есть ещё один путь.
1) используя многочлен низкой степени или таблицу с интерполяцией генерируем «грязную» синусоиду, с гармониками. Причём математически можно совершенно точно вычислить амплитуду всех гармоник (через разложение в ряд Фурье).
2) Пропускаем эту синусоиду через рекурсивный высокодобротный bandpass-фильтр, подавляющим первую гармонику до приемлемого уровня.
Refridgerator Автор
31.10.2021 11:17+1К слову, приведённая в статье аппроксимация многочленом 7-й степени (с 5-ю умножениями) даёт подавление гармоник на 125 дБ:
спектр
Для управления двигателем должно хватить. И его возможно даже можно улучшить, если минимизировать отклонения в частотной, а не во временной области.Refridgerator Автор
31.10.2021 16:52А если нужен 3-фазный ток — то можно сэкономить, генерируя не 3 синусоиды, а две: sin(x), cos(x) и использовать равенства
sin(x+2*pi/3) = 0.5*(-sin(x)+sqrt(3)*cos(x)) sin(x-2*pi/3) = 0.5*(-sin(x)-sqrt(3)*cos(x))


Balling
30.10.2021 04:47+2>из математического сопроцессора FPU процессоров x86/x64, которая тоже умеет считать и синус, и косинус одновременно.
Но зачем? Там же аппаратный баг у Intel, который так и не исправили. FPU FSIN и FCOS ошибаются очень сильно. Все пользуется кодом из glibc и sincos из AMD /Microsoft C library (MIT лицензия).
retrocomputing.stackexchange.com/questions/16523/intel-cpu-bug-in-the-90sfsincosRefridgerator Автор
30.10.2021 10:56+1Там же аппаратный баг у Intel, который так и не исправили
Баг был у fdiv, а не fsincos, и его не только исправили, но ещё и процессоры всем поменяли.FPU FSIN и FCOS ошибаются очень сильно
А чуть более подробно можно? При каких значениях аргумента какого порядка ошибки возникают. Потому как в своих испытаниях ничего такого я не заметил.Balling
30.10.2021 19:12+1www.reddit.com/r/programming/comments/2is4nj/comment/cl54afb
randomascii.wordpress.com/2014/10/09/intel-underestimates-error-bounds-by-1-3-quintillion
FSIN уже не исправишь, так как это сломает ожидания целой пачки програмного обеспечения. AMD попытались, но пришлось убирать. (У них один и тот же код для это в микроинструкциях.)
В ссылке сверху все описано, но я могу дать ссылки на обсуждение в glibc.
sourceware.org/bugzilla/show_bug.cgi?id=13658
github.com/bminor/glibc/commit/b35fe25ed9b3b406754fe681b1785f330d9faf62
На x86_64 они используют sinf кстати.
Очень вероятно, что то что вы тестируете это как раз програмный код оттуда.Refridgerator Автор
31.10.2021 07:03+1Я так понял, речь идёт о значении аргумента за пределами значения ±263. В таком случае это скорее «не баг, а фича»©, поскольку описывается в документации. Но за наводку спасибо — потестирую этот момент в своей реализации синуса повышенной точности.
Balling
31.10.2021 07:16Вы имеете в виду пример с 2646693125139304345? Нет это просто кто-то сильно увлекся. Но там уже ошибка при long-double precision the fsin fails to meet its guarantees at numbers as small as 3.01626.

longcake
30.10.2021 12:33Я физик, поэтому бесконечно далек от таких проблем, но мне всегда казалось что для вычисления синуса логично просто решать задачу Коши x'' + x = 0, x(0) = 0, x'(0) = 1
Тем более там есть интеграл x^2 + x'^2 = 1, который позволит даже грубым методам удержать погрешность в разумных пределах.
Почему не вычисляют так?
technic93
30.10.2021 14:06Решать задачу коши Рунге Куттой? Это надо сделать сколько шагов, несколько десятков, сложнее чем просто подставить число в многочлен 13го порядка.
sim31r
30.10.2021 21:15+1Ну а теперь попробуйте найти ответ на микроконтроллере типа Attiny 13, где 64 байта памяти, 1024 байт для программы. Для вычисления синуса можно выделить 200 байт на флеше и 8 байт оперативной памяти. Ну и уложиться желательно в 50-100 тактов процессора. Аппаратного умножения нет, деления нет.
Примерно такие же ограничения будут при формировании синусоиды на частоте 1000 МГц на ПЛИС, минимум логических элементов и высокие требования к быстродействию.

xvoland
02.11.2021 10:49Взято из Quake III Arena?
Ну, тогда считаем корень, быстрее всех )))
float Q_rsqrt( float number ) { const float x2 = number * 0.5F; const float threehalfs = 1.5F; union { float f; uint32_t i; } conv = {number}; // member 'f' set to value of 'number'. conv.i = 0x5f3759df - ( conv.i >> 1 ); conv.f *= threehalfs - x2 * conv.f * conv.f; return conv.f; }или вот так
float Q_rsqrt( float number ) { long i; float x2 ,y; const float threehalfs = 1.5F; x2 = number * 0.5F; y = number; i = * ( long * ) &y; i = 0x5f3759df - ( i >> 1); y = * ( float * ) &i; y = y * (threehalfs - ( x2 * y * y ) ); // 1st iteration // y = y * ( threehalfs - ( x2 * y * y ) ); //2nd iteration return y; }
NN1
Как минимум производительность C# тестировать через Stopwatch неверно.
Следует использовать https://benchmarkdotnet.org/
Также C# проверяет границы массива каждый раз, в отличии от C++.
Чтобы этого избежать можно взять указатель на массив или воспользоваться MemoryMarshal.GetArrayDataReference
Refridgerator Автор
Я пробовал делать через указатель, используя fixed в unsafe mode — получилось ещё хуже. fixed даёт прирост производительности, когда используется за пределами цикла.
aamonster
Разве в простых for-циклах по диапазону оптимизатор не справляется с удалением этих проверок?
NN1
Так и есть, но в функции SinCos нет цикла.
aamonster
Зато в вызывающей функции есть (но это да, для оптимизатора может быть сложновато). А в SinCos есть вычисления, в которых можно вычленить инвариант (но опять же может оказаться сложновато). В общем, надо смотреть, во что код бенчмарка скомпилируется на самом деле.