

В чёрную пятницу, пока у нас стартует флагманский курс Data Science, делимся интерактивными графами подписок веб-разработчиков и разработчиков моделей ML, а также знакомим читателей с инструментом визуализации больших графов — PyGraphistry.
Такие данные — косвенный индикатор конкуренции языков и технологий. К примеру, можно попробовать выяснить, сколько разработчиков C++ следят за разработчиками Rust и наоборот. За подробностями и кодом приглашаем под кат.

Интерактивный граф вы найдёте здесь.
Загрузка набора данных
Мы проанализируем GitHub при помощи набора данных в Kaggle. Узлы — это разработчики, которые поставили звезду не менее чем 10 репозиториям. Если человек является разработчиком машинного обучения, то ml_target=1, иначе ml_target=0.
import pandas as pd
# Download the data at https://www.kaggle.com/femikj/github-social-network
nodes = pd.read_csv("github-social-network/github_target_1.csv")
# Change datatypes
nodes.id = nodes.id.astype(str)
nodes.ml_target = nodes.ml_target.astype(str)
nodes.head(10)
Рёбра (edges) — это наблюдения двух разработчиков друг за другом.
edges = pd.read_csv("github-social-network/github_edges_1.csv")
# Change datatypes
edges = edges.astype(str)
edges.head(10)
Cвязи ML и веб-разработчиков
Доля ML-разработчиков и веб-разработчиков
Начнём с определения процентного соотношения веб-разработчиков — ????(Web Developer) и разработчиков машинного обучения — ????(ML Developer) в сети.
import plotly.express as px
percent_web, percent_ml = nodes.ml_target.value_counts(normalize=True)
px.histogram(data_frame=nodes, x="ml_target", histnorm="probability density")74% разработчиков в этой сети — веб-разработчики.
Процент смешанных соединений
Каков процент смешанных соединений (между веб-разработчиком и разработчиком машинного обучения)?
Объединим таблицы edges и nodes:
edges = edges.merge(nodes, how="left", left_on="id_1", right_on="id").merge(
nodes, how="left", left_on="id_2", right_on="id", suffixes=("1", "2")
)[["id_1", "id_2", "name1", "name2", "ml_target1", "ml_target2"]]
edges.head(10)
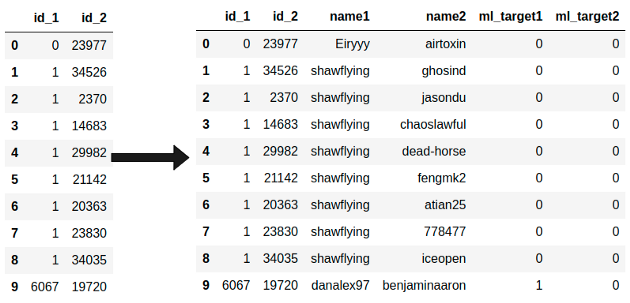
Затем рассчитайте процент смешанных связей в сети — ????(ML Developer connect to Web Developer).
cross_edge = edges.query("ml_target1 != ml_target2")
percentage_cross_edge = cross_edge.shape[0] / edges.shape[0]
percentage_cross_edge
0.1546558340224842Одинаковых соединений почти в 5,5 раз больше, чем смешанных.
Связи веб-разработчиков
Ещё один интересный вопрос: если человек — веб-разработчик, какой процент его связей — веб-разработчики, а какой — разработчики ML?
Чтобы ответить на этот вопрос, воспользуемся теоремой Байеса. Из этой теоремы известно, что:
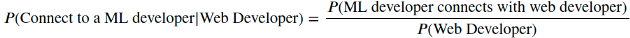
Мы уже знаем ????(ML-Developer connect to web Developer) и ????(Web Developer) из предыдущих расчётов. Воспользуемся этими цифрами, чтобы найти ????(connect to ML Developer|Web Developer):
percentage_cross_edge / percent_web0.20852347708049263Теперь легко найти ????(Web Developer|Web Developer):

Это означает, что если человек является веб-разработчиком, то:
вероятность, что связанные с ним люди тоже веб-разработчики, составляет 71,95%;
вероятность, что он связан с разработчиком ML, составляет 28,05%.
Эти цифры очень похожи на процент разработчиков ML и веб-разработчиков в сети (0,258 и 0,741).
Связи разработчиков ML
Мы можем найти ????(Connect to a Web developer|ML Developer):
percentage_cross_edge / percent_ml0.5986779897985065И ????(ML Developer|ML Developer):
1 - 0.58970.4103Если человек — разработчик ML, то:
вероятность, что связанные с ним или с ней люди также являются веб-разработчиками, составляет 59,87%;
вероятность, что связанные с ним люди — разработчики ML, составляет 41,03%.
Поскольку процент разработчиков ML в сети составляет всего 25,8%, удивительно наблюдать, что 41,03% связей разработчика ML — это разработчики ML. То есть разработчики ML с большей вероятностью будут следить друг за другом, чем за веб-разработчиками.
Визуализация сети с помощью PyGraphistry
Давайте попробуем подтвердить этот вывод. Визуализируем сеть GitHub с помощью PyGraphistry.
Что такое PyGraphistry?
PyGraphistry — это библиотека Python для визуализации больших графов. Здесь мы будем работать с большим графом, поэтому PyGraphistry — идеальный инструмент.Чтобы установить его, выполните:
pip install pygraphistryНачнём
Чтобы использовать PyGraphistry, создайте бесплатный аккаунт graphistry.com:
import graphistry
PASSWORD ="GRAPHISTRY_PASSWORD" # Insert your password here
USERNAME = "GRAPHISTRY_USERNAME" # Insert your username here
graphistry.register(api=3, username=USERNAME, password=PASSWORD)
Затем укажите узлы и рёбра графа. Чтобы показать разные значки для разных ролей, воспользуемся encode_point_icon:
g = graphistry.edges(edges, "id_1", "id_2")
# Choose icons here: https://fontawesome.com/v4.7.0/icons/
g = (g.nodes(nodes, "id").encode_point_icon(
"ml_target", categorical_mapping={1: "area-chart", 0: "mouse-pointer"}
)Теперь выводим граф Github:
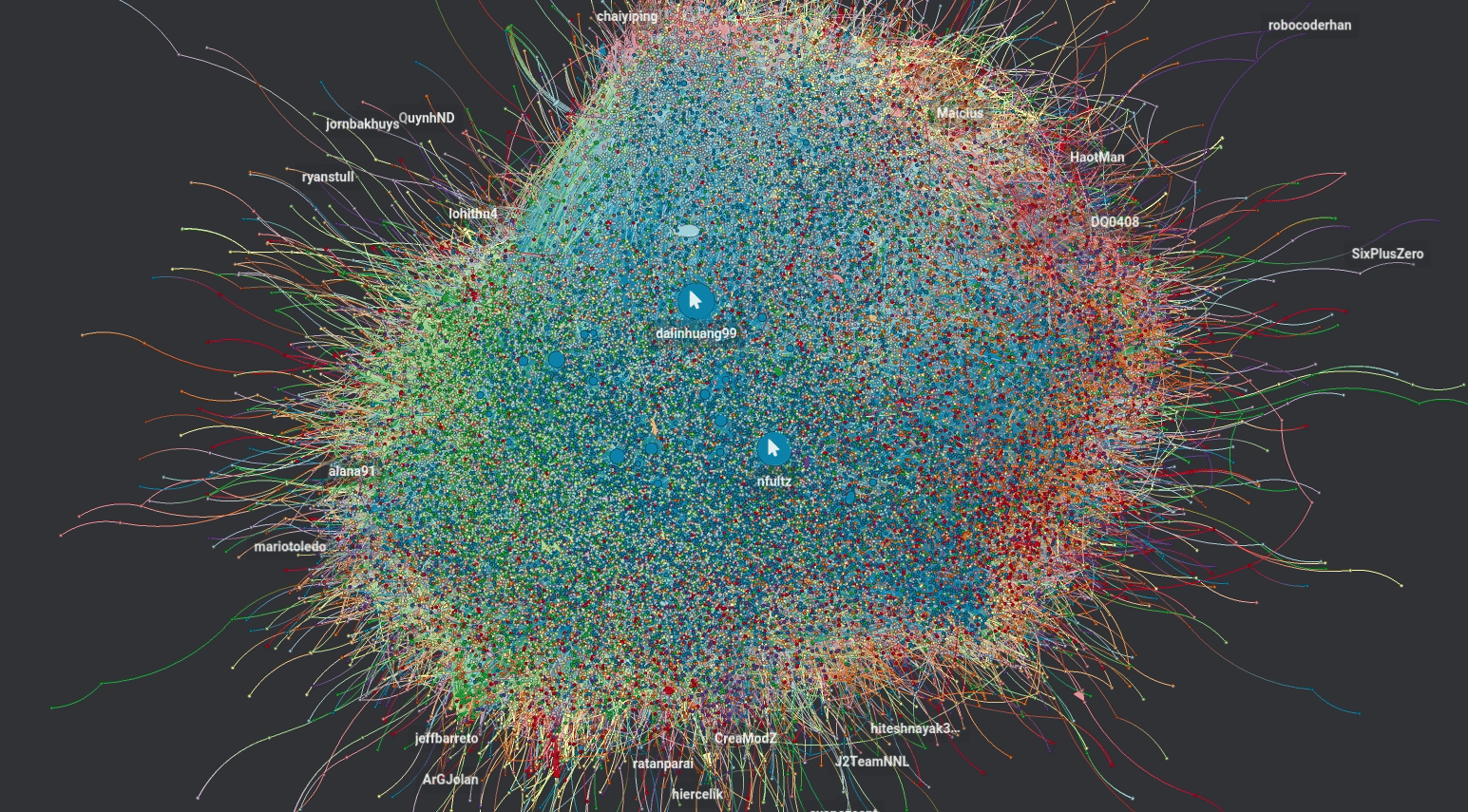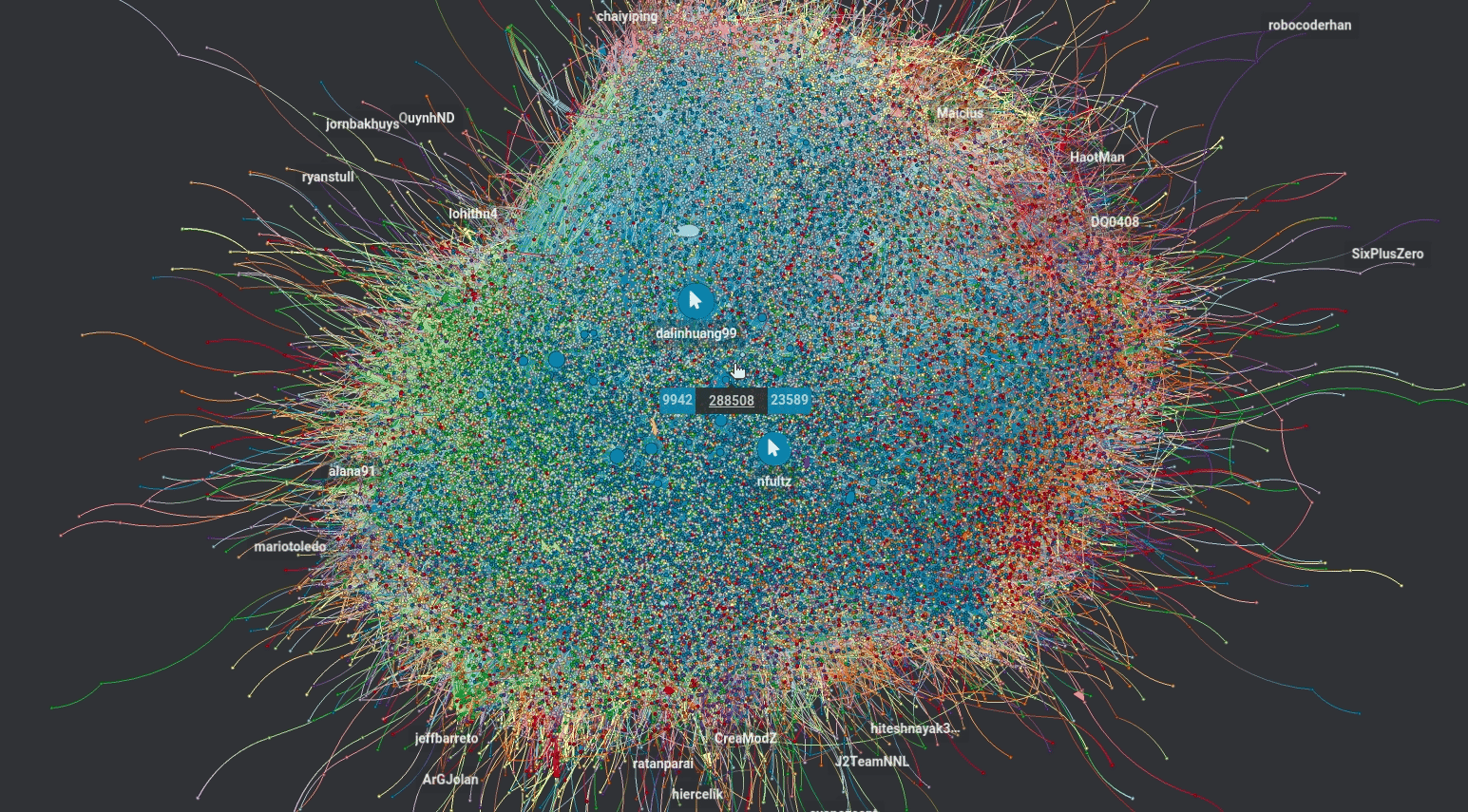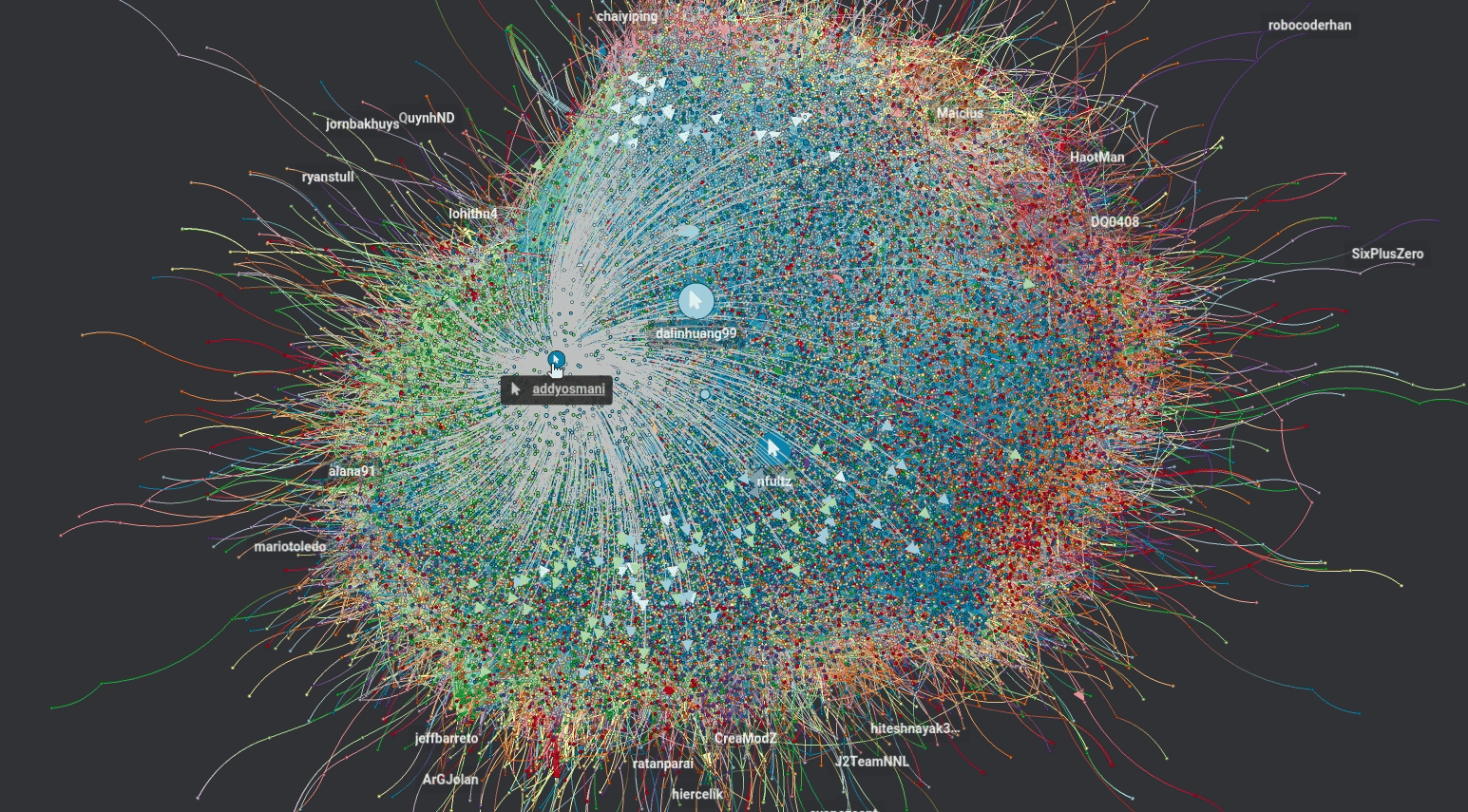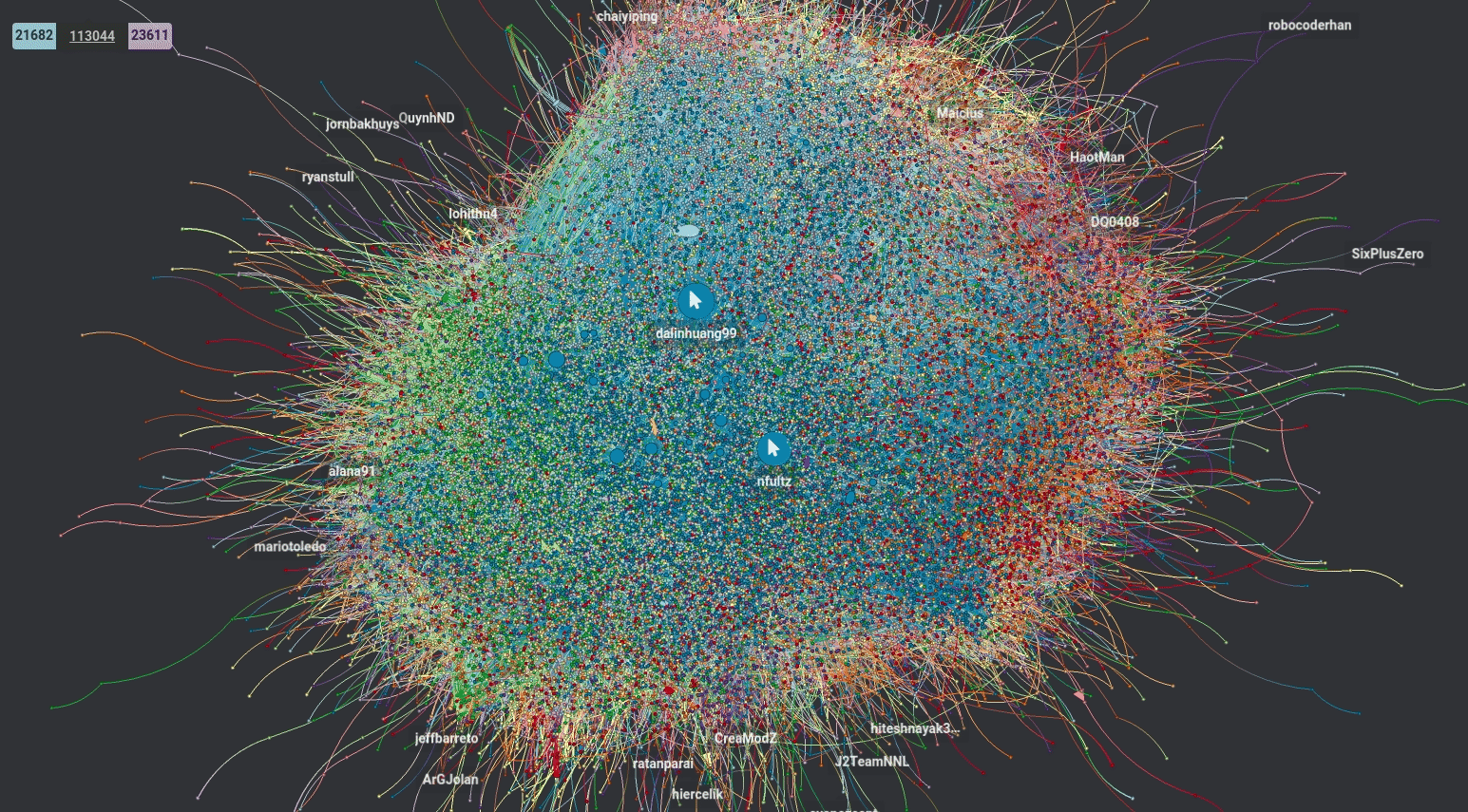
g.plot()В вашем блокноте должно появиться что-то вроде этого:

Интерактивный граф вы найдёте здесь.
Чем больше узел, тем больше количество его связей с другими узлами. Наведя курсор на определённый узел, вы увидите узлы, с которыми он связан.
Интерактивный граф вы найдёте здесь.
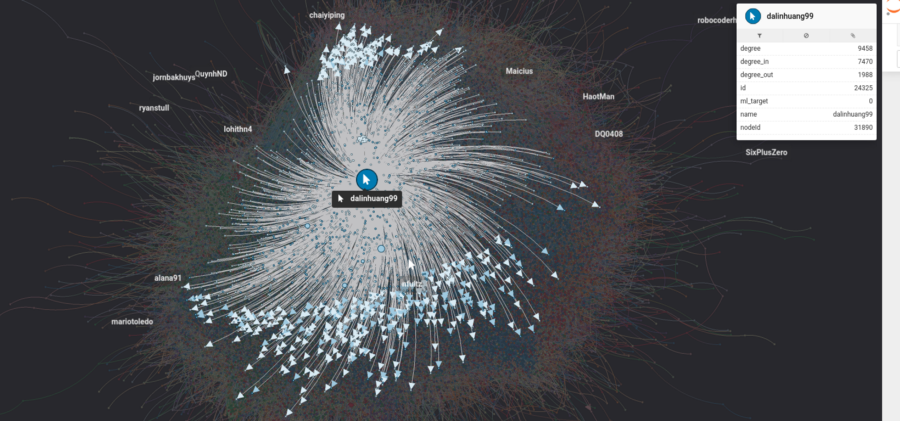
Щёлкнув по узлу, вы получите информацию о нём.
Цветовое кодирование точек
Граф красивый, но не очень информативный. Хочется знать, как разработчики разных ролей связаны друг с другом, поэтому раскрасим узлы с разными ролями в разные цвета. Разработчики моделей машинного обучения окрашены в серебряный цвет, веб-разработчики — в бордовый.
g2 = g.encode_point_color("ml_target", categorical_mapping={1: "silver", 0: "maroon"})
g2.plot()
Интерактивный граф вы найдёте здесь.
Если цвет отображается не так, как вы этого ожидали, возможно, нужно обновить страницу.
Видно, что разработчики одинаковых ролей имеют тенденцию группироваться.
Разработчики с наибольшим количеством связей
Нажмём на значок "Data Table" в верхней части экрана. Отсортируем её по количеству взаимосвязей и щёлкнем по интересующей точке, которая будет выделена:

Интерактивный граф здесь.
Из таблицы видно, что большинство популярных разработчиков — это веб-разработчики. Что неудивительно, ведь веб-разработчиков гораздо больше.
Найдём сообщества
Сообщество — это подмножество узлов, которые в одном и том же графе плотно связаны друг с другом и слабо связаны с узлами других сообществ. Попробуем найти сообщества с помощью метода Лувена. Мы имеем дело с большим графом, поэтому для ускорения кода воспользуемся cuGraph.
import cudf
import cugraph
from cugraph.community.louvain import louvain
# Turn a pandas DataFrame into a graph
G = cugraph.from_pandas_edgelist(edges, "id_1", "id_2")
# Get communities
parts, modularity_score = cugraph.louvain(G)
# View the first 10 rows
parts.head(10)
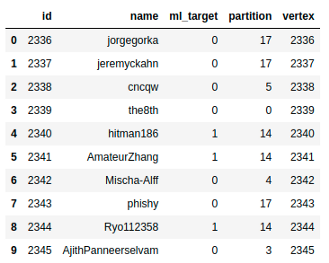
В таблице ниже, partition — это сообщество, которому принадлежит узел (вершина). Сколько существует сообществ? Давайте узнаем:
parts.partition.unique().valuesarray([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], dtype=int32)Их всего 22. Давайте представим, как выглядят эти сообщества. Объединим таблицы nodes с таблицами parts, чтобы получить имена узлов и их разделов.
# Join the parts and nodes table to get the name of the nodes
nodes_cudf = cudf.from_pandas(nodes)
nodes_part = nodes_cudf.merge(parts, how="left", left_on="id", right_on="vertex")
nodes_part.head(10)
Воспользуемся faker, чтобы раскрасить разделы в разные цвета.
from faker import Faker
Faker.seed(0)
fake = Faker()
g3 = (
g.nodes(nodes_part, "id")
.encode_point_icon(
"ml_target", categorical_mapping={1: "area-chart", 0: "mouse-pointer"}
)
.encode_point_color(
"partition", categorical_mapping={i: fake.color() for i in range(22)}
)
)
g3.plot()Вы должны увидеть нечто подобное:

Интерактивная версия здесь.
Видно, что узлы из одного сообщества имеют тенденцию объединяться в кластеры.
Сообщества разработчиков ML и веб-разработчиков
К каким сообществам принадлежит большинство веб-разработчиков? Мы можем выяснить это, выбрав только веб-разработчиков. Для этого нажмите кнопку Filter в верхней части экрана.

После этого отображаться должны только узлы веб-разработчиков:

Кажется, что веб-разработчики принадлежат к самым разным сообществам. А теперь посмотрим, к каким сообществам принадлежат разработчики моделей ML:

Граф только из разработчиков ML:

Интересно! Большинство разработчиков ML принадлежат к сообществу, окрашенному в розовый цвет. Это означает, что, в отличие от веб-разработчиков, разработчики ML, как правило, находятся в одном сообществе. Другими словами, разработчики ML теснее связаны друг с другом.
Процент разработчиков ML в каждом сообществе
Каков процент разработчиков ML в каждом сообществе? Чтобы выяснить это, воспользуемся сгруппированной гистограммой.
from faker import Faker
Faker.seed(0)
fake = Faker()
g3 = (
g.nodes(nodes_part, "id")
.encode_point_icon(
"ml_target", categorical_mapping={1: "area-chart", 0: "mouse-pointer"}
)
.encode_point_color(
"partition", categorical_mapping={i: fake.color() for i in range(22)}
)
)
g3.plot()Кажется, небольшой процент разработчиков ML есть в большинстве сообществ. Это означает, что большинство сообществ весьма разнообразны.
Заключение
Поздравляю! Вы только что узнали, как анализировать социальную сеть с помощью байесовской статистики и PyGraphistry. Свободно форкайте исходный код из этой статьи.
Продолжить изучение визуализации, Python и всей науки о данных вы сможете на наших курсах:

Подробности здесь.
Профессии и курсы
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также
mentin
Мне одному кажется, что с применением Баеса у них что-то не так?
Начинаем с формулы:
У них эта вероятность могла бы просто напросто оказаться больше единицы, если (в теоретическом эксперименте) все связи между ML и Web, то есть percentage_cross_edge = 1.
Ну и кроме того, они считают всё по одной цифре percentage_cross_edge, которая не полностью описывает ситуацию - может быть ассимметрия. Скажем (в другом теоретическом эксперименте) ML девелоперы связаны и друг с другом, и с Web, а Web друг-друга игнорируют. Тогда рассчитываемая ими "если человек является веб-разработчиком, вероятность, что связанные с ним люди тоже веб-разработчики" была бы ровно нулём, несмотря на то что percentage_cross_edge могла быть такой же.