
Часть 1. Технология гетерогенных ROLAP-кубов
Всем привет.
В этой публикации мы начнем рассказ о том, как наша BI-платформа «Форсайт» работает с данными. Как организовано взаимодействие платформы с СУБД и какие объемы информации мы можем эффективно обрабатывать. Что такое связка «BI+Data Lake» и как можно ее сформировать. Как в OLAP-кубах получать сведения из разных слоев данных: сырые/неструктурированные, детальные, консолидированные, валидированные, аналитические и т.п. Зачем для BI нужно деление на горячие, теплые и холодные данные. Ответы на все эти вопросы вы найдете в цикле наших статей.
Осуществлять аналитическую обработку данных, причем зачастую разной природы и масштабов – дело достаточно сложное. Поэтому мы разделили наш рассказ на несколько частей. Итак, давайте начнем первую часть нашего рассказа. Welcome под кат!
1.1. Как работает связка «BI+Data Lake»?
За последние 20 лет уровень программных продуктов обработки, хранения и анализа данных значительно вырос. Сначала были простые локальные базы данных, автономные под каждый проект. Затем сложные корпоративные хранилища данных с единой версией правды, гибкими методологиями ХД, медленно меняющимися справочниками второго типа (SCD2), сложными агрегациями первичных транзакционных данных и многое другое. Но количество информации в цифровом виде из года в год все росло и увеличивалось. Постепенно объем разнородных источников стал настолько велик, что появился устойчивый термин «большие данные» (Big Data). Далее возникает двойственная ситуация. Чем больше данных, тем дороже построить качественное КХД. Все эти «сырые» разнородные данные из разных источников нужно проверять, валидировать, систематизировать и так далее. Но, возможно, не всегда эту проверку требуется делать качественно и скрупулёзно.
Представьте себе, что из большого водоема данных вам потребуется вода, но для двух разных ситуаций. Первый случай – 100 куб. м воды для тушения лесного пожара, и второй случай – 150 мл бутилированной воды для питья. Во втором случае над водой из водоема будет произведена большая работа по её фильтрации, очистке, разливу по бутылкам. И только когда вода достигнет определенного качества, только тогда ей можно утолить жажду. В первом случае, наоборот, вам будет совершенно не важно, какого вода качества. Будет интересен только общий объем водоема и хватит ли его запасов на всю площадь пожара.
Примерно на такой же идее и основываются «Озёра данных» (Data Lakes). Мелкими ручейками разные данные в их натуральном формате (RAW, от англ. сырой/необработанный) «стекаются» в место их общего хранения. Это и есть Big Data. Затем информация в нужном объеме проходит систематизацию. В случае наличия «единой версии правды» информация попадает в хранилище данных (DWH) или, если с сырыми данными было произведено только минимум преобразований, то информация перемещается в слой хранения оперативных данных (ODS, Operation Data Storage). Основная разница между DWH и ODS в скорости и стоимости обработки данных. Следующим шагом по модификации информации является консолидация и итоговое систематизирование. Это проводит к формированию слоя детальных данных (DDS, Detail Data Storage).
Пример трансформации «ODS->DDS»
Когда в консолидированной модели крупного холдинга разнородная информация от дочерних компаний приводится к единому корпоративному плану счетов. При этом в DDS с одной стороны сохраняется первичная детализация по каждой дочерней компании (кто-то специализируется на производстве шариковых авторучек, а кто-то выпускает производственные станки), но появляются новые общие признаки, которые становятся общими для всех. Например, код корпоративного счета «Производство продукции». Далее все три потока информации (ОDS, DDS и DWH) собираются в общий слой представления аналитических данных (ADS, Analytical Data Store) или витрины предподготовленных данных (Data Marts).
Но это все про информацию и данные. При чем тут BI, совершенно справедливо спросите вы? Немного терпения. Доведем наш рассказ про «стекание» воды в озера данных до логической точки. Как же понять, в каких случаях нам нужно тщательно фильтровать воду для питья методом многоступенчатой очистки, а когда черпать ее бочками для тушения пожаров прямо из озера сразу вместе с живущей в ней биомассой? С точки зрения ИТ точнее будет даже сказать, не в каких случаях делать «захват» данных, а какими программными инструментами? Когда для обработки данных использовать миниатюрные щипчики для тонкой ювелирной работы, а когда и кувалда подойдет?
Ответы на эти вопросы дает гибкая система бизнес-аналитики, или Business Intelligence. В ней как раз сосредоточен тот набор необходимых аналитических инструментов, способных решить ту или иную задачу «колдовства над водой».

Например, для многомерного и всестороннего анализа данных подходит гибкая технология аналитической обработки данных (OLAP). Для анализа текстовой информации можно воспользоваться технологией text mining, которая, например, на основе лингвистического анализа сможет определить тональность высказывания и структурировать эти сведения. Совместив ее с инструментами интеллектуального анализа (data mining), можно выявить скрытые правила и закономерности в наборах данных. Интересный пример использования озёр данных рассказали сотрудники компании «Газпром нефть» в онлайн-журнале «Сибирская нефть» (см. здесь). Создание платформы «Умных озёр данных», в которой BI является неотъемлемой частью, позволяет этой нефтяной компании «детально анализировать потребительские предпочтения, разрабатывать максимально персонализированные предложения для клиентов», как пишет директор по региональным продажам Александр Крылов.
Поэтому хорошо «плавающая» BI-платформа сможет быстро и эффективно решить самые разнообразные задачи. Но, как и при любом «купании», все во многом зависит от водоема. В первую очередь от технологии хранения самих данных.
1.2. Для разных типов данных - разные технологии их хранения
Платформа «Форсайт» не является средством постоянного хранения больших объемов данных. Для этого мы всегда используем какую-либо внешнюю СУБД. Тут важно сделать уточнение, что для быстрой работы в нашем BI реализованы средства кэширования данных в ОЗУ (in-memory). Но это все же не способ длительного хранения данных, а скорее механизм быстрой обработки данных нашей платформой своими инструментами с высокой производительностью.

Таким образом, мы идем «по старинке» и для хранения данных используем БД от разных производителей: Oracle, MS SQL Server, PostgreSQL, Greenplum, Teradata, Vertica, ClickHouse, Hive, а также ряд проприетарных российских СУБД (PostgrePRO, Jatoba и линейку продуктов Arenadata). Для этого в платформе «Форсайт» реализован набор коннекторов. Для распространенных СУБД это нативные коннекторы на C++, остальные через ODBC. В случае с озёрами данных каждый источник целесообразно хранить в предназначенных для этого видах СУБД: реляционных, распределенных, колоночных и др. Далее объединение разных данных происходит уже на уровне многомерных кубов в ОЗУ средствами самой BI-платформы. Комбинация обработки данных «СУБД + оперативная память на BI» дает неплохой результат.
Часто разные источники одного многомерного OLAP-куба состоят из нескольких совершенно разных физических таблиц из разных баз данных. Например, исторические данные с длительной динамикой размещены в MPP-СУБД (что обеспечивает быстрое извлечение информации), а сценарии с эконометрическими расчетами прогнозов по этой динамике хранятся в реляционной СУБД (т.к. сценарии часто перечитываются и измененные данные требуется все время перезаписывать в БД маленькими порциями, а MPP плохо воспринимает micro-batch). В связи с этим для разных слоев данных приходится комбинировать разные СУБД, а итоговый аналитический срез данных объединяется уже на стороне BI в оперативной памяти.
Давайте более детально рассмотрим механизмы такой комбинации источников данных в OLAP-кубах нашей платформы «Форсайт».
1.3. Многомерные OLAP-кубы – основа любой BI
Самая первая и важная характеристика для OLAP-куба – это N измерений (или часто еще их называют аналитиками или справочниками). Они определяют размерность куба. Второе – это структура физического хранения. Давайте рассмотрим самый простой случай – одна таблица с фактами и N таблиц-справочников (классическая модель «звездочка»). Все таблицы расположенная в одной СУБД, например, PostgreSQL.
«Звездочка» – простой сценарий работы многомерного OLAP-куба
В платформе «Форсайт» вы легко сможете настроить такой источник данных с помощью отдельных конструкторов для измерений и многомерных кубов. Вся информация с настройками сохранится в репозитории метаданных. Измерения и кубы создаются как отдельные (самостоятельные) метаобъекты и могут быть переиспользованы. Например, справочник территорий создается один раз и может быть добавлен во все кубы в вашей ИТ-системе. Далее для чтения исходных данных через многомерный куб платформа (используя метаданные) определяет необходимые измерения - см. шаг 1 на рис. ниже. И затем формирует запрос в БД к таблицам-справочникам (шаг 2,3).
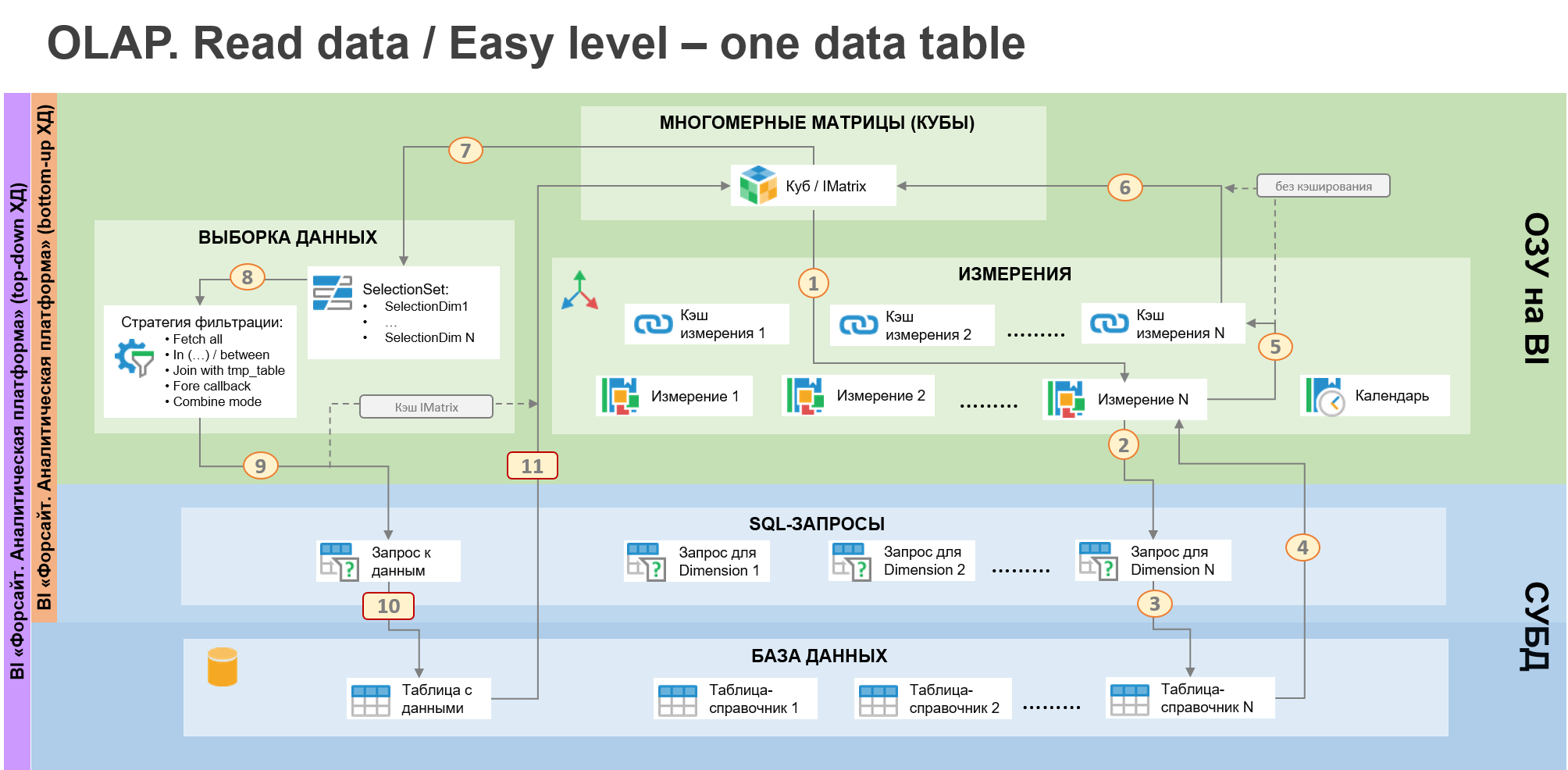
На основе ответа из БД определяется состав элементов для каждого измерения (шаг 4). Поддерживаются линейные или иерархические (сбалансированные/несбалансированные) измерения. У каждого элемента в измерении часть атрибутов заполняется данными из запроса к БД (ключ, наименование и т.п.), а часть может рассчитываться уже на стороне BI (например, порядок следования и элемент-владелец при вычисляемых иерархиях или какой-нибудь сложный алгоритм транслитерации ФИО сотрудников в латиницу для англоязычного наименования).
Структура сформированного справочника может быть размещена в сессионный кэш платформы (шаг 5). Тогда при последующих обращениях к этому измерению в рамках одной сессий запросов к БД в таблицу-справочник больше не будет. Это позволяет повысить скорость работы с источниками данных, когда в рамках одного сеанса работы с платформой пользователь обращается к одним и тем же данным много раз. Режим кэширования является опциональным (причем для каждого справочника), и его можно отключить. Например, если данные обновляются в БД в реальном времени.
Получив информацию о всех измерения (шаг 6), мы определим структуру куба, и можно переходить к этапу выборки данных. Содержание выборки определяется «отметкой» (SelectionSet), см. шаг 7. Отметка - это комбинация выбранных элементов в каждом измерении куба (Selection Dim 1…N). Установленная пользователем «отметка» напрямую влияет на структуру sql-запроса к таблицам с данными (шаг 9 и 10). И вот тут начинается самая сложная часть для OLAP-движка. С одной стороны, такой движок должен быть универсальный и автоматически адаптироваться под любую «отметку» пользователя. Т.е. генерировать максимально (насколько это возможно сделать автоматически) оптимальный sql-запрос с разной структурой условия where. С другой стороны, как уже говорили выше, должны поддерживаться разные типы СУБД, где в общем случае синтаксис PL/SQL и принципы их оптимальной работы могут сильно различаться.
Универсальный «движок» генерации sql-запросов к многомерным данным
Как решить вопрос оптимальности? Часто в разных статьях про производительность СУБД или даже BI упоминаются TPC-H тесты (http://www.tpc.org).

Они действительно хорошо показывают скорость реакции на разные аналитические запросы. Но в первую очередь они больше ориентированы на агрегированные ad-hoc отчеты, когда из многомилионной выборки данных требуется получить всего лишь десятки агрегированных и отфильтрованных значений. При этом условия (фильтрация) выборки организованы простыми логическими правилами: равно константа, between между двумя значениями, больше или меньше заданной величины и т.д.
При использовании в BI-платформе универсальной ROLAP модели, которая выполняет прямые реляционные запросы в БД, тесты намного сложнее. Например, для каждого четного измерения куба выбрать все их нечетные элементы, а для нечетных измерений – все четные элементы. Как вам такой тест? Он, конечно же, легко выполняется для справочников, состоящих из небольшого количества элементов. Например, пол, возраст, валюта. Здесь транслировать произвольную «отметку» пользователя (SelectionSet) из интерфейса BI в условия sql-запроса достаточно просто, т.к. количество элементов в справочниках небольшое. Обычный in (…) с парой значений или between (для случая, когда ключи выбранных элементов идут подряд), плюс правильный индекс на таблицу БД – любой OLAP «движок» сделает такое без особого труда и с высокой производительностью.
Совершенно другая история для справочников с большим количеством элементов: товарная номенклатура, реестр контрагентов, список студентов ВУЗа за последние 20 лет и т.д. Фильтрация в таблице фактов для таких условий выполняется по полям с высокой кардинальностью. Простой пример – структура дебиторской или кредиторской задолженности. Для крупного холдинга это сотни товарных позиций, десятки и сотни тысяч контрагентов (покупатели, поставщики, подрядчики). Еще добавляются виды деятельности, структура дочерних обществ холдинга и другие аналитические разрезы.
Затем в хаосе этой разряженной многомерной модели данных пользователь по известной и понятной только ему бизнес-логике выбрал какие-то элементы в каждом измерении куба. Может быть, один элемент, а может быть тысяча. И все эти условия должны автоматически транслироваться из BI-платформы на язык sql-запросов. Причем с проверкой каждого элемента, а не просто «все товары с ключом больше X или между Y и Z». Ведь в сводной таблице (pivot table) мы хотим увидеть «дебиторку/кредиторку» в разрезе конкретных выбранных товарных позиций и контрагентов, а не общую сумму всего агрегата целиком. И выполниться такой запрос должен быстро, а не часами «перебирать» на сервер БД декартово произведение комбинаций из всех возможных пересечений этих условий каждого из измерений.
При этом ожидается, что пользователь не пишет сложные и/или вложенные MDX запросы (разбитые на атомарные условия), а просто проставляет отметку в интересующих его разрезах куба и сразу получает плоскую сводную таблицу. Именно такая задача часто возникает в enterprise BI при реализации отчетов со сложной структурой. И тут тест производительности со всеми четными товарами и нечетными контрагентами очень показателен.
ROLAP vs MOLAP vs HOLAP – что лучше для Data Lake
Успех решения такой задачи (сформировать из BI-платформы быстро работающий sql-запрос с большим количеством условий) состоит из двух составляющий. Первое – это правильный выбор СУБД. Для обработки разных видов данных важно и нужно использовать разные типы СУБД. Именно поэтому мы остаемся приверженцами ROLAP, сочетая его с частичным HOLAP или in-memory OLAP. Только такой вариант обработки информации (прямое обращение к исходным данным с их опциональным кэшированием в рамках каждой сессии), является самым оптимальным для связи «озеро данных + BI».
Конечно, намного проще для BI-платформы пойти по пути внутреннего хранения данных. Регулярно «перекладывать» 100% всей необходимой информации в адаптированные структуры данных (MOLAP), а также использовать только «удобную» для себя технологию СУБД или собственную систему полного кэширования данных. Таким путем сейчас идет ряд российских и международных BI-платформ. Но этот подход не всегда эффективно встраивается в уже существующую систему озера данных заказчика. Точнее, рядом создается второе озеро-дублер, и информация по заданному расписанию «клонируется» во второй водоем. Дополнительно, такой подход с озером-дублером совершенно не работает для потоковых данных или real-time BI.
Именно поэтому вы получите только первую половину успеха, если для конкретного слоя данных (горячие, теплые или холодные данные) правильно подберете тот или иной тип СУБД. Точнее, этот выбор лучше делать сразу, на этапе проектирования архитектуры озера данных, рассматривая его в сочетании с целевой BI-платформой, которую вы планируете использовать в будущем. Например, для создания фабрики данных и аналитического КХД мы рекомендуем использовать комбинацию линейки продуктов «Форсайт» и «Аренадата».

Стратегии фильтрации в sql-запросах
Вторая составляющая успеха – это принципы работы в BI-платформе многомерного «движка» данных (rolap data engine). Механизмы формирования sql-запросов должны быть адаптированы под структуру и сценарии использования ROLAP-куба. В первую очередь это фильтрация данных, которые попадут в куб. Здесь важно найти оптимальный баланс между условиями выборки данных на стороне СУБД, и финальной фильтрацией и обработкой результатов sql-запросов уже на уровне бизнес-логики BI.
Например, если «отметка» состоит из идущих подряд элементов (ключи элементов отсортированы), но есть «дырки», то в определенных случаях для sql-запроса лучше работает условие in (1,2,…,9,10, 25,26,…,42,43, 89,90,…), а в каких-то случаях комбинация нескольких between…and…. Дополнительно часть условий (замедляющих выполнение sql-запроса) можно просто исключить из sql-условия, а уже финальное сокращение выборки из БД выполнить на стороне BI-платформы (уже не средствами СУБД, а программной логикой самой BI). Такие комбинации часто тоже показывают неплохой результат.
Для выбора оптимального sql-запроса в платформе «Форсайт» реализованы механизмы стратегии фильтрации данных многомерного куба (см. шаг 8 на OLAP-схеме выше). Суть такой стратегии заключается в том, чтобы в зависимости от структуры «отметки» куба (SelectionSet) по-разному генерировать текст условия в sql-запросах. Доступно несколько вариантов стратегии:

Используя ту или иную стратегию фильтрации, текст sql-запросов автоматически генерируется платформой. Причем это не единичное обращение к БД (select * from …) а целая серия sql-команд и запросов для организации работы разных вариантов стратегии фильтрации. Например, для варианта №4 требуется создание временных таблиц для сохранения информации по фильтрам с большим количеством элементов. Но автоматическая генерация такого комплексного скрипта требует учитывать синтаксис разных СУБД. Например, для СУБД PostgreSQL скрипт может быть таким:

Для других СУБД синтаксис sql-скрипта будет изменяться платформой «Форсайт» автоматически. Таким образом, настроив в репозитории платформы логическую структуру многомерных кубов, можно без проблем мигрировать эти кубы на разные СУБД. Потребуется только изменить настройки подключения к БД и привязку к целевым таблицам. Все необходимые sql-операции для извлечения данных платформа сделает самостоятельно, с учетом оптимальной стратегии фильтрации.
Сложные связи или как «подстроиться» под существующую структуру БД
Учитывая, что озёра данных формируются на основе разных источников, часто связи в базе данных между таблицами могут основываться на нескольких полях. Рассмотрим ситуацию, когда в каждом филиале используется своя локальная БД и первичный ключ для сотрудников по всей компании начинает пересекаться. Чтобы объединить информацию, в озере данных нужно уже создавать уникальный индекс из двух полей – branch_id и employee_id. И это вполне нормально. На таком «сдвоенном» индексе платформа «Форсайт» также может сформировать измерение. ROLAP-куб на основе такой логической связи двух атрибутов с таблицей фактов сформируется, но стратегия фильтрации для sql-запросов будет требовать корректировки. Тут уже нельзя для каждого поля применять условие фильтрации отдельно. Например, в измерении сотрудников мы выбрали одного специалиста из филиала A, а из филиала B выбрали 100 сотрудников (один из которых использует тот же самый ключ что и сотрудник из филиала A). Простое условие в sql-запросе будет следующим:
…… where branch_id in (‘branch_A’, ‘branch_B’) and employee_id in (1,2,…,100) and …...
Но оно не будет эффективным. Запрос будет явно избыточным, в случае если ключи всех 100 сотрудников из филиала «B» есть и в филиале «A». Замена команды in на between не даст нужного результата. Конечно BI-платформа при финальном размещении данных в OLAP-кубе (см. шаг 11) обязательно «отфильтрует» только 101 сотрудника (а не оставит все 200 человек), но драгоценное время будет потеряно, а производительность снижена.
На первом шаге мы пробовали усложнять структуру условия в sql-запросе, (branch_id = ‘branch_A’ and employee_id = 1) or (branch_id = ‘branch_B’ and ……), но ни к чему хорошему это не приводило. Для примеров с большой размерностью куба и высокой кардинальностью полей (с которыми связаны измерения) скорость работы БД была очень медленной. Но и упрощать условия sql-запроса и «тащить» с сервера БД на сервер BI лишние данные для последующей обработки в ОЗУ, тоже не очень хотелось. Чтобы решить эту задачу, мы расширили четвертый вариант стратегии фильтрации, создавая временную таблицу сразу для всех атрибутов индекса измерения. Это в ряде случаев очень сильно помогло.
Такие комплексные одновременные связи не ограничены по количеству полей-атрибутов в индексе измерения. Их может быть и три, и четыре и т.д. Также в одном индексе можно сочетать разные типы данных у атрибутов. Простой пример – календарное измерение. В платформе «Форсайт» индекс этого измерения по умолчанию состоит из двух атрибутов: дата начала периода и уровень календаря (год, квартал, месяц, день). Так сделано потому, что в случае многоуровневого календаря только дата «01.01.2022» не позволяет отличать «2022 год» и «1 января 2022 года».
1.4. Одна СУБД – несколько таблиц
Продолжая усложнять структуру данных в озере, представим ситуацию, когда таблиц фактов уже несколько. Плюс есть измерения, состоящие из нескольких таблиц-справочников, и нам необходимо объединить их в общую иерархию элементов. Т.е. простая модель «звездочки»/«снежинки» начинает усложняться.
Составные измерения из нескольких таблиц-справочников
Несколько таблиц-справочников в платформе «Форсайт» могут быть объединены в одно составное измерение. Такое измерение разделяется на блоки (см. шаг 2 на рисунке ниже). Каждый блок – это отдельный источник данных (dataSet), из которых получается общий список элементов составного измерения. Один dataSet может соответствовать только одной таблице-справочнику. Принцип работы измерения такой же, как и на предыдущей схеме – генерируется несколько запросов в БД, но уже к нескольким таблицам (см. шаги 3, 4).

По отношению друг к другу блоки измерения могут быть или линейные (тогда все их элементы расположены на одном уровне) или соподчиненные (элементы одного блока являются родителями элементов другого блока). Внутри одного блока элементы также могут быть расположены линейно или иерархически. Итоговое формирование элементов справочника происходит в оперативной памяти на стороне BI сервера на основе данных из ответа от БД (см. шаг 5, 6). При необходимости может использоваться кэш платформы (см. шаги 7-8).
Cвязь одного ROLAP-куба с несколькими таблицами фактами
Аналогичным образом вы можете добавить в ROLAP-куб и несколько таблиц фактов (см. шаги 11-13). Тогда каждую таблицу вы должны связать с индексами измерений, а точнее с атрибутами измерения, входящими в этот индекс. Эту связь можно настроить с одним и тем же общим индексом справочника или для каждой таблицы указать свой индекс. С одним индексом все просто. Все три таблицы связаны с одним и тем же атрибутом измерения – например, с числовым ключом элемента.
Рассмотрим связь по нескольким индексам. Например, в одном измерении есть три уникальных атрибута: ключ, классификационный код и мнемоника. Все они могут быть использованы для кодировки элементов справочника. Для каждого атрибута в измерении создан свой индекс. В каждой из трех таблиц фактов используется только одна из этих кодировок. Тогда при добавлении каждой таблицы в ROLAP-куб вы связываете её поле (содержащее значение какой-то из трех кодировок) с соответствующем индексом. При извлечении данных все три sql-запроса к трем таблицам фактам выполняются независимо. Каждый из запросов возвращает свою подвыборку данных в определенной кодировке (ключ, код или мнемоника). Далее все три массива данных объединяются в общую многомерную матрицу куба. Каждая полученная из БД точка данных (запись из курсора sql-запроса) будет размещена в том элементе измерения, которому соответствует указанный в связи атрибут (кодировка).

При такой настройке возможна ситуация, когда на одну и ту же точку в многомерной матрице куба будут претендовать значения из разных таблиц фактов (т.е., например, и код и мнемоника соответствуют одной точке данных). Для таких случаев можно настроить правила вычисления фактов на уровне BI-платформы. Например, простые агрегации (сумма, среднее, первый или последний элемент, количество точек и т.п.) или сложные функциональные правила (в том числе с учетом приоритетов таблиц-источников). Такие BI-вычисления можно сочетать с агрегацией на БД. Тогда в sql-запрос к каждой таблице фактов будет транслироваться group by вместе с sum, avr, count и др. (в том числе можно настроить собственную процедуру на PL/SQL). Затем все результаты из БД еще дополнительно при финальном формировании куба будет суммироваться (или выполняться иное правило), но уже на стороне BI-платформы.
Денормализация данных в ROLAP-кубе
Как уже обсуждали выше, индекс может состоять из нескольких атрибутов. Это потребует связать уже несколько полей таблицы фактов с атрибутами справочника (входящих в этот индекс). Также, в общем случае, можно связать поля таблицы фактов и с неуникальным индексом. Тогда данные будут дублироваться по всем элементам измерения, для которых установлено соответствующее значение неуникального атрибута. Такой вариант тоже практикуется.
Еще один из способов – совсем не устанавливать связь между атрибутами измерения и полями таблицы фактов. Тогда в матрице данных ROLAP-куба значения будут «размножаться» по элементам несвязанных измерений или «фиксироваться» на одном из заданных элементов. Такое поведение востребовано при соединении в кубе нескольких таблиц, часть из которых имеет меньшую размерность, т.е. вам просто нечего связать с атрибутами измерений.
Пример - объединение фактических и прогнозных (плановых) данных
Пример такого случая денормализации – объединение в одном кубе фактических и прогнозных данных, расположенных в двух разных таблицах. Для прогнозов обычно используют измерение сценариев: оптимистичный, пессимистичный, позитивный, негативный и т.п. Разный сценарий – разные цифры. Для фактических данных поле сценариев в таблице фактов бессмысленно. Но выбрав несколько сценариев, вам важно увидеть и динамику ретроспективной части временного ряда. Причем не важно, сколько сценариев вы выбрали – один или несколько.
Для разных фрагментов (блоков) измерения своя таблица фактов
Если в измерении куба создано несколько блоков, то для каждого из них можно определить отдельную связь с таблицей фактов. Например, хранить данные разной гранулярности (год, кв., месяц, день) в отдельных таблицах БД. В календарном измерении платформы уже выделены соответствующие блоки. Тогда привязку таблиц фактов нужно по-прежнему делать к атрибутам индексов, но уже не всего измерения в целом, а отдельно каждого блока.
Другой такой пример – это территориальное разделение (страны, регионы, города). При таком подходе вы можете таблицы-справочники связывать с таблицами фактов не только через общие индексы всего измерения (как уже обсуждали выше), но и через локальные индексы каждого блока.
Но тогда в чем разница иcпользования индексов всего измерения и индексов отдельных блоков? При такой «блочной» привязке в нашей BI-платформе для разной «отметки» (selectionSet для выборки данных) автоматические определяется нужные sql-запросы только к задействованным таблицам фактов. Каждый элемент измерения входит только в один блок. Поэтому определив «отметку» элементов в каждом из измерений, мы перед началом генерации текста sql-запросов можем однозначно сказать, какие из блоков используются. Соответственно, если часть блоков не попадает в «отметку», то и запросов к соответствующим незадействованным таблицам БД не будет. Связь по общему индексу измерения такое деление сделать не сможет, т.к. общие индексы всего измерения определяются для всех его элементов сразу.

Деление измерения на блоки не обязательно должно быть связано с разными уровнями иерархии (страны-регионы-города). Можно и линейные справочники разделить на несколько блоков и для соответствующих элементов отображать данные из разных таблиц фактов. Например, для показателей социально-экономического развития регионов данные о внешнеэкономической деятельности расположены в одной таблице БД, а показатели бюджета - в другой.
Гибкие возможности для работы с гибкими архитектурами КХД
Все указанные выше гибкие настройки в измерениях и ROLAP-кубах позволяют определять связи между таблицами-справочниками и таблицами фактов в совершенно разных архитектурах проектирования корпоративного хранилища данных: «звезда», «снежинка», Data Vault, частично «якорная» модель. Это обеспечивает интеграцию таких ROLAP-кубов с уже существующей физической архитектурой озера данных компании. Это является одним из важных условий при определении возможности внедрения BI-платформы в существующий ИТ-ландшафт организации.
1.5. Большой гиперкуб сразу для нескольких СУБД
Важно отметить, что взаимодействие с таблицами БД через BI позволяет организовать гетерогенную взаимосвязь между разными типами СУБД (в том числе, когда эта гетерогенность самой СУБД не поддерживается или ее настройка/производительность сильно ограничена). Так как вся логика sql-запросов и финальная обработка данные обрабатываются в оперативной памяти BI сервера - то прямых связей или DB-link между СУБД не требуется. С точки зрения нескольких баз данных каждый шаг делается независимо.
Одновременное чтение данных из разных СУБД
Давайте рассмотрим эти шаги. Сначала платформа запросила из БД одну порцию данных, сформировали на ней измерение. Каждое измерение формируется независимо друг от друга, а значит, и СУБД могут быть разные. Далее отмеченные в SelectionSet элементы («отметка») через стратегию фильтрации используются в sql-запросах к данным. Результаты запросов с данными платформа тоже получает независимо (отдельно от каждой СУБД), и из них в оперативной памяти BI-сервера формирует итоговую многомерную матрицу куба. В том числе обрабатывает (агрегирует) пересечения точек-фактов – это тоже уже обсуждали выше.

Такой подход позволяет создавать в платформе «Форсайт» гетерогенные ROLAP-кубы разной степени сложности. Используя эту возможность, вы практически всегда сможете подключиться к любому озеру данных, не важно, какой технологический стек оно использует и какая структура хранения данных в нем организована. Большие озера данных - это источник информации для большого количества ИТ-систем организации. И адаптировать физическую структуру хранения отдельно для каждой системы – такой возможности в озере данных часто нет.
При внедрении BI-платформы придется «подстраиваться» под то, что есть. Часто с точки зрения BI – это полный «зоопарк» СУБД (в хорошем смысле этого слова, рассматривая контекст горячих, теплых и холодных слоев данных). Подход гетерогенных ROLAP-кубов в этом случае очень хорошее и эффективное решение, которое становится посредником между разными источниками данных. Остается правильно его «приготовить» настроить.
«Быстро читать нельзя часто изменять» = «казнить нельзя помиловать»
Еще один интересный момент при таком гетерогенном обращении BI-платформы к разным БД – это режим чтения и записи (корректировки) данных. Разные типы СУБД по-разному работают в этих режимах. Например, реляционная СУБД PostgreSQL быстро записывает небольшие порции измененных данных (micro-batch), но медленно считывает сложные аналитические запросы. Для MPP-СУБД Greenplum противоположная ситуация. За счет массово-параллельной архитектуры чтение данных выполняется с высокой скоростью, но обновление данных возможно только большим порциями (batch), что совершенно не подходит для режима ручной корректировок информации в отчетности или при расчете целого среза данных при помощи «продвинутой» аналитики (advanced analytics).

Эти две взаимоисключающие возможности при работе разных СУБД с операциями чтения и записи похоже на крылатое выражение «казнить нельзя помиловать». Только «казнить» и «помиловать» нужно заменить «быстро читать» и «часто изменять» данные. К сожалению, для текущих реалий Business Intelligence это так. Для enterprise BI крайне важно одновременно работать с данными и на чтение, и на изменение (запись). Но большинство СУБД не предоставляют такую возможность одновременно, к сожалению.
Технология гетерогенного ROLAP-куба позволяет «разрубить» этот узел противоречия. Совместив в таком кубе таблицы фактов из разных СУБД, можно управлять потоками данных при чтении и записи. При чтении учитывать приоритеты слоев данных. Один слой данных - это выделенная отдельная СУБД, которая отвечает за источник оперативно изменяемых данных (назовем их оперативный слой данных). Сюда будем записывать все измененные данные. Остальные слои – это специализированные СУБД, где хранится весь исторический массив данных только для чтения (при необходимости можно разделить их на горячие/теплые/холодные данные и использовать СУБД от разных производителей). Далее при выполнении операции чтения данных первый приоритет отдать оперативному слою. Если там данных нет, значит, их не изменяли, и можно проверять все остальные слои исторических данных.
Источник изменяемых оперативных данных можно не «раздувать», и на регулярной основе (в периоды неактивного использования системы, например, каждую ночь, или чаще) реплицировать их в соответствующие источники для чтения. После этого оперативный слой можно очистить и начинать заполнять его новыми изменениями. Если репликацию делать часто, то в источнике для записи всегда будет немного данных. Поэтому операция чтения (в том числе при сложных аналитических sql-запросах) будет выполняться быстро, даже в случае применения обычной реляционной СУБД. Но это достаточно сложная тема и мы вынесем ее в отдельную часть цикла наших статей про работу BI и озера данных.
На этом наша первая часть цикла публикаций про практику работы платформы «Форсайт» с озером данных завершена. Следите за нашими следующими выпусками. Далее мы обязательно расскажем о других интересных особенностях работы нашей платформы с разными СУБД, сложными КХД и большими данными.
expdxx
Большой и интересный материал, спасибо. С первого раза полностью не смог осилить при том, что довольно глубоко нахожусь в теме BI, поэтому вернусь обязательно завтра)
Возможно, ответ на мое замечание есть в тексте, но я не обнаружил. Окей, заниматься дублированием данных в каком-либо внутреннем хранилище BI-системы действительно не всегда правильно, но получается, что для быстрого отклика системы у вас либо данные постоянно подняты в ОЗУ, либо множество пользователей бесконечно генерирует SQL-запросы. Какое быстродействие в подобных условиях обеспечивает BI-решение и какого масштаба требуются сервера? На примере таблицы в 2млн строк * 15 полей и порядка 15-20 пользователей в единицу времени. Не лучше ли предусмотреть для больших дашбордов (для которых требуется хранить только агрегаты, инкрементируемые к примеру раз в сутки, быстро поднимаемые в ОЗУ при открытии отчета) хранение во внутренних файлах а-ля Qlik QVD, а уже для ad-hoc отчетности live-connection к озеру? Заодно довольно просто решается вопрос одновременного доступа к данным большого числа пользователей. Вопрос быстродействия интерфейса у крупного руководства обычно стоит острее актуальности данных, сегодня им редко нужна информация младше сегодня-1 день.
Но в любом случае здорово, что у нас есть такое мощное BI-решение. Никогда не слышал ранее, ознакомлюсь, спасибо.
kaichou
На взгляд со стороны, Вы сами ответили на вопрос, который задали )
kvsman Автор
Спасибо большое за позитивный отзыв. Отвечая на вопросы:
1) Во многом быстродействие и аппаратные требования зависят от сложности проекта и объемов отчетов (кол-ва данных в них).Минимальные требования к BI- и веб-серверам представлены в нашей онлайн-справке (ссылка). Для отказоустойчивой и распределенной нагрузки мы рекомендуем использовать горизонтальное масштабирование и собирать кластер. Подробнее об этом можно посмотреть тут (ссылка). При очень «экономичных» отчетах/дэшбордах каждая нода кластера выдерживает 200-250 одновременных пользователей. Для «средних/сложных» отчетов мы рекомендуем исходить уже из нагрузки в 50-150 одновременных подключений на одну ноду.
2) Для обозначенного примера (2 млн записей в исходной таблице, 15-20 пользователей) с обращениями к СУБД раз в 2-3 сек проблем точно не возникнет. При тестовых испытаниях мы обычно ориентируемся на несколько сотен одновременных пользователей и объемы данных от 1 млрд. записей. Тут правда разные СУБД по-разному реагируют на такие эксперименты. Oracle/Teradata пока самые «стрессоустойчивые». PostgreSQL/Greenplum – если часами непрерывно и постоянно их «мучать», начинают «хандрить». Clickhouse – где то посередине. В след. статьях я планировал привести некоторые графики нагрузки в разрезе отклика нашего BI на отчеты с разным количеством данных. Думаю, там все будет наглядно.
3) «агрегаты, инкрементируемые к примеру раз в сутки…» - да, тут все верно. Прямое обращение из BI к исходным (первичным) данным не единственное решение. Когда частота обращение к агрегатам на порядки превышает регулярность обновления самих первичных данных, то адаптированная витрина – это самый оптимальный вариант. Кассовая (чековая) аналитика в ритейле или банковские платежи, наверное одни из показательных примеров. Но наш ROLAP как раз подходит для всех задач: и первичные данные и выделенная витрина.
4) Qlik QVD. Да, такой режим мы тоже практикуем. In-memory в нашей Платформе реализовано в двух вариантах: a) все данные сразу целиком загружаются в ОЗУ с полным предварительным прогревом или b) создается файловый кэш и далее из него в ОЗУ все время «переподкачивается» востребованная часть данных, а невостребованная постепенно вытесняется. У обоих этих вариантов есть свои плюсы и минусы, свои «уместные» сценарии использования, свои требования к оборудованию. Про эту нашу технологию я тоже планировал сделать отдельную публикацию. Если кратко, основной плюс файлового кэша – это очень высокая (по сравнению с sql-запросами) скорость работы, особенно при сложных условиях фильтрации (при «отметках» в сотни тыс. элементов - это секунды по сравнению с минутами при sql-запросах). Основной минус – длительное обновление маленьких фрагментов данных, т.к. приходится проводить сложную переиндексацию. В итоге – мы рекомендуем файловый кэш использовать для режима только чтения (например, в случае с дэшбордами). А "прогрев" полного кэша – для режима расчетов или загрузки данных.