
Всем привет.
Мы продолжаем цикл публикаций о том, как наша BI-платформа «Форсайт» работает с данными. В этой статье мы бы хотели поговорить о том, как выйти за рамки привычного online analytical processing (OLAP) и с помощью enterprise BI погрузиться в проблематику «Fixed format reporting». Какие средства и возможности дает BI-платформа для 100% точного воспроизведения шаблона официальной отчётности? Как это можно сделать с помощью трансформации и виртуализации данных многомерных ROLAP-кубов? Расскажем о том, как в платформе «Форсайт» на уровне бизнес-логики и семантического слоя можно выполнить аналоги реляционных операций view, join, group by и т.п. Итак, за всеми этими подробностями добро пожаловать под кат!
Данная статья является продолжением цикла статей про связку «BI+Data Lake». Предыдущие части: «Часть 1. Технология гетерогенных ROLAP-кубов».
1. OLAP и Prudential Reporting
1.1. Как совместить гибкость, упорядоченность и полное соответствие заданному шаблону?
В прошлой статье мы подробно поговорили о том, как организовать хранение разной информации в озере данных. Какие технологии СУБД для этого рационально использовать и как в BI с помощью гетерогенных ROLAP-кубов соединить все эти данные в единую многомерную матрицу. И затем вывести эту информации в разных OLAP-представлениях.
Сегодня хотелось бы поговорить о другой важной составляющей использования озёр данных. Указав в поисковой строке Google или Яндекс запрос «Fixed format reporting versus OLAP», мы получим много разносторонних и противоречивых ссылок. Действительно, в современном мире сложно представить оперативную аналитическую обработку данных в BI без технологии OLAP. Но это только с одной стороны. На другой чаше весов находится задача подготовки фиксированной и строго структурированной отчётности разного вида – без которой невозможно вести деятельность ни в одной сфере (к сожалению, бюрократия пока остается неотъемлемой частью нашей жизни, но, возможно, это позволяет избежать определенного хаоса). И это тоже про Business Intelligence. Уже много лет в словаре BI наравне с термином OLAP укоренился и термин Pixel-Perfect Reports, что дословно может быть переведено как «идеальный до пикселя». Другими словами, общий смысл заключается в том, что электронные варианты такой отчётности должны полностью соответствовать своему «бумажному» шаблону-образцу.
На этих двух чашах весов пытаются «перевесить» друг друга две разных задачи из BI, у которых один общий родитель (концепция обработки информации в виде многомерной модели данных, или просто кубов), но совершенно разные технологические цели:
Задача №1. Data Discovery – гибкий анализ и исследование многомерных данных. Действительно, основные операции технологии OLAP (drill down, roll up, slice and dice, pivot и т.п.) являются хорошим и мощным инструментом для аналитиков. Но все они имеют одно большое ограничение. А именно, строгую упорядоченность структуры многомерного куба, а также иерархию и последовательность элементов его измерений. Такой анализ чем-то похож на кубик-рубик. Вращать ребра кубика можно, но цвета всех клеточек в линии одновременно переедут на другую грань.
Задача №2. Data Reporting – формирование фиксированной отчётности, которая строго соответствует заданному шаблону (report templates). Если и для этого тоже использовать многомерные данные, то тут возникает проблема, которая полностью идет вразрез с предыдущей задачей. Упорядоченность и постоянство структуры кубов (которая для «data discovery» хорошо помогает при навигации по данным) – здесь уже начинает мешать на 100% точно повторить структуру заданного шаблона отчёта. Если снова сравнить с кубиком-рубиком, то при компоновке данных в отчётности нам просто нужно переклеить все цветные квадратики по заданной инструкции-шаблону, а не вращать грани при исследованиях.
Например, при выполнении операции drill down/roll up по территориальному разрезу совершенно правильно и лаконично выглядит иерархия «Россия/Федеральные округа/регионы каждого ФО». Но в шаблоне конкретного отчёта могут быть совершенно другой порядок и соподчиненность, которые определяются локальной бизнес-логикой шаблона отчёта. Россия и Приволжский федеральный округ в одном шаблоне могут быть размещены между Республикой Татарстан и Пермским краем (например, сортировка по величине какого-либо показателя), а в другом шаблоне Россия – уже соподчиненный элемент ПФО (например, ПФО = 110%, в том числе по РФ = 108%).
Еще сложнее, когда в шаблоне формы отчётности используется не один, а сразу несколько кубов. Причем шаблон организован так, что разные фрагменты данных из этих кубов чередуются несколько раз в хаотичном порядке, а не следуют друг за другом (т.е. мы не можем просто «склеить» их из нескольких разных OLAP, так как все данные перемешаны).
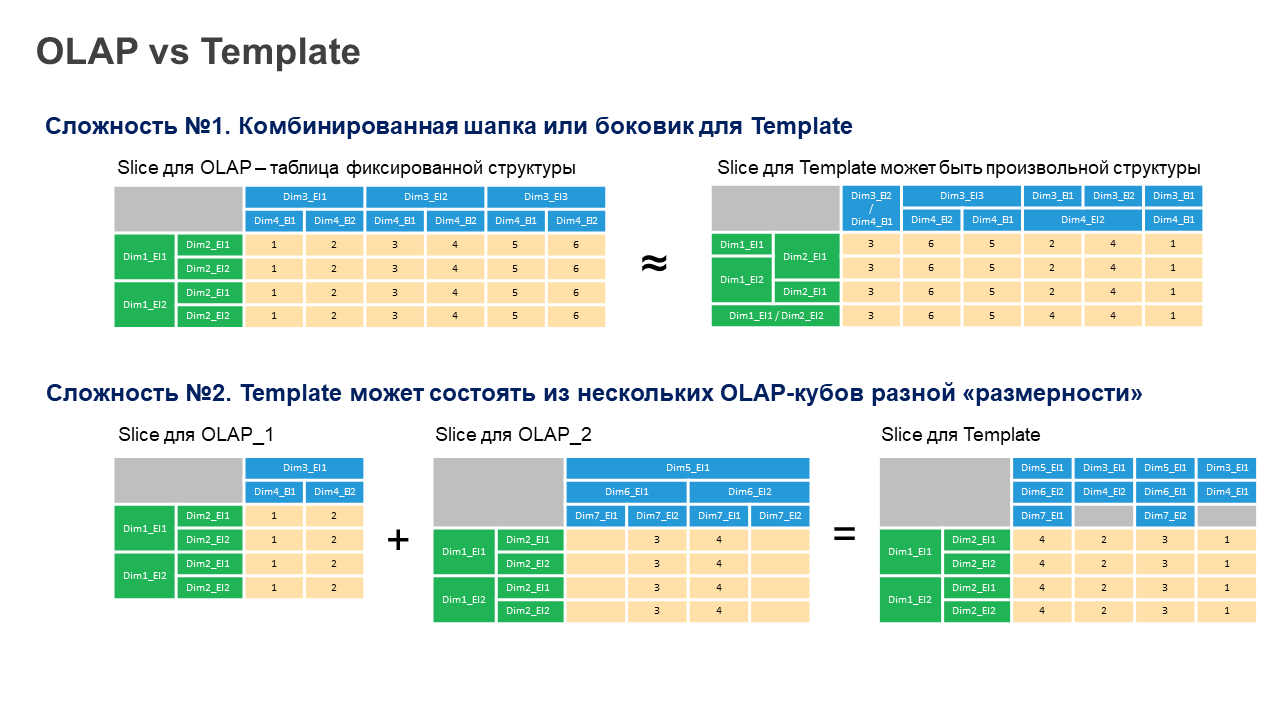
Таким образом, мы приходим к дилемме. А именно – как организовать общую и универсальную физическую структуру для упорядоченного хранения информации в озере данных? Но при этом всегда иметь гибкие возможности для произвольного представления этих данных в любых разрезах и формах. В том числе для реализации отчётности по фиксированным шаблонам.
1.2. Data Reporting: от физического дублирования к логической виртуализации данных
Один из способов разрешения этой дилеммы мы уже немного обсуждали в прошлой статье. В озере данных мы выделяли отдельный слой информации – специализированные витрины данных на уровне СУБД (data marts). В таких витринах для каждого шаблона/отчёта нужно создать отдельное реляционное представление. В нем через sql-запросы воспроизвести требуемую структуру и формат данных. Если sql-запрос достаточно сложный и скорость его выполнения не очень быстрая, то online режим переходит в offline (материализованное представление или их аналоги). Это существенно повышает скорость работы, но приводит к дублированию данных.
Другой способ – это виртуализация данных (Data Virtualization). При таком подходе уже не нужно программировать специальные sql-запросы. Интерфейс ИТ-системы позволяет пользователю извлекать информацию без знания каких-либо технических подробностей об этих данных (физической структуре, месте их хранения и т.п.). BI-платформа сама формирует все физические обращения к данным, на основе их логических «виртуальных» двойников. Обязательное и важное условие для двойника – все физические структуры у источников данных должны оставаться неизменными и в единственном экземпляре. Никакого дублирования и копирования данных. При создании большого количества виртуальных двойников размножаться должна только логика с описанием представления этих данных (шаблоны), а не сами данные.

Такая концепция Data Virtualization очень хорошо подходит для связки «BI+Data Lake». Действительно, один раз «залив» данные в озеро, можно затем в метаданных BI-платформы настраивать неограниченное количество их виртуальных представлений. И далее можно «черпать» воду из озёр этими виртуальными чашами.
Виртуализация данных позволяет адаптировать любые источники в озере данных под произвольный «Fixed Reporting». В том числе на первом шаге в BI могут быть сформированы ROLAP-кубы (в которых указана связь с физическими данными). Затем структурированные многомерные OLAP-кубы трансформируются под шаблоны отчетов (report template). Проблематику формирования произвольной шапки и боковика (обозначенную в пред. разделе) решают различные методы понижения и повышения размерности куба, а также альтернативные варианты представления. Это достаточная большая тема, и мы расскажем о ней в следующий раз. Другая проблема – объединение в отчете многомерных источников с разным количеством измерений. Вот об этом нам подробно хотелось бы рассказать в этой статье.
2. Сводные многомерные источники данных (агрегация в BI)
Для подготовки сводных отчётов часто возникает потребность из большого универсального гиперкуба (куда добавлены измерения на «все случаи жизни») оставить только часть его измерений-разрезов. Например, есть куб с информацией о выручке от продаж разной продукции разным контрагентам. И требуется получить сводные данные. Просуммировать выручку только по товарам или только по покупателям. Тогда лишние измерения из куба нужно просто исключить. При этом все исходные данные куба необходимо агрегировать. Это связано с тем, что новая уменьшенная комбинация измерений уникально уже не идентифицирует каждую точку в таблице фактов. Такая агрегация может быть выполнена в платформе «Форсайт» одним из двух способов:
Агрегация на стороне СУБД: На языке sql-запросов для такой агрегации используется конструкция …group by и соответствующие агрегатные функции для не группируемых полей. Такое поведение можно настроить в самом ROLAP-кубе. Тогда все измерения (у которых не выбран ни один элемент или выбраны все элементы) будут восприниматься платформой как исключенные. Все связанные с ними поля в таблице фактов перестанут участвовать в условиях фильтрации sql-запроса. Остальные поля будут сгруппированы через «group by». Также для каждого факта куба нужно заранее настроить правила агрегации. Могут использоваться как стандартные агрегатные sql-функции (sum, avg, min, max и т.п.), так и любая пользовательская функция на PL/SQL. Если у куба активирован такой режим, то rolap data engine автоматически сформирует sql-запрос с учетом исключаемых измерений и правил группировки полей (в платформе такой механизм называется Query Aggregator). Вся агрегация выполняется средствами СУБД, в BI-платформу передаются уже сводные данные.
Агрегация на стороне сервера приложений BI: В платформе «Форсайт» существует и второй вариант понижения размерности куба с агрегацией данных. Это создание куба-представления (CubeView). Суть такого варианта заключается в том, что на основе исходного многомерного куба формируется новый куб, но часть измерений в нем зафиксировано, т.е. исключено. Для всех зафиксированных измерений нужно выбрать один или несколько элементов справочника (с указанием метода агрегации). Все агрегационные расчеты при таком способе выполняются уже на стороне сервера приложений BI в оперативной памяти. Сначала будут получены все данные исходного куба-источника и далее куб-представление в виртуальной многомерной матрице данных выполнит все агрегации средствами BI-платформы (механизм Matrix Aggregator).
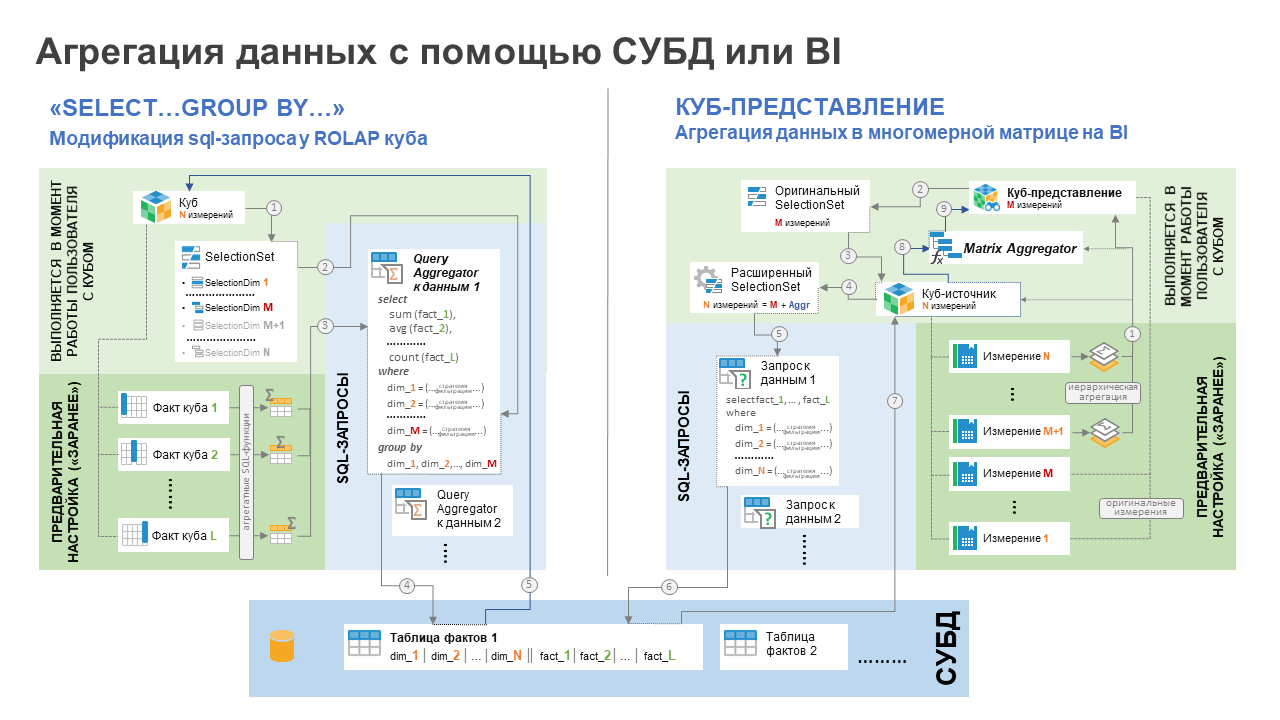
Куб-представление не является ROLAP-кубом в чистом виде. Не нужно в каждом из них отдельно задавать все связи с таблицами фактов. Достаточно настроить один ROLAP-куб-источник и далее на его основе можно формировать неограниченное количество кубов-представлений, понижая их размерность. Другими словами, куб-представление – это аналог реляционного select … from. Только вся обработка данных выполняется средствами BI. В том числе платформа «Форсайт» сама определяет необходимый объем данных для агрегации. Если выбраны узловые элементы-родители и в кубе-источнике используется иерархическая агрегация, то условия фильтрации sql-запроса дополнительно будут расширены этими необходимыми дочерними элементами из куба-источника.
Чем еще Matrix Aggregator отличается от Query Aggregator?
Важно понимать, что способ группировки данных в Matrix Aggregator дает два принципиальных отличия от использования Query Aggregator и sql-операции «group by»:
Вы можете точно указать все условия фильтрации для выбранных элементов у исключаемых измерений, в том числе учитывая бизнес-правила BI-платформы (права доступа, вычисляемые элементы, виртуальные/зависимые измерения, измерения с медленно меняющейся размерностью (SCD2), измерения на таблицах-справочниках из других БД и т.п.). Такие условия фильтрации могут по-другому ограничить исходную выборку данных из БД, и, как следствие, можно получить разные результаты агрегации через Query Aggregator и Matrix Aggregator.
Структура элементов у исключаемых измерений может быть иерархической. Внутри этой соподчиненности элементов также могут применяться правила агрегации. Например, в плане счетов доходов/расходов компании есть несколько уровней вложенности. Если мы хотим исключить это измерение и проагрегировать данные только по нескольким счетам первого уровня, нам необходимо:
a) сначала в кубе-источнике выполнить агрегацию по всей иерархии счетов (второй и последующие уровни);
b) затем получив иерархический агрегат по нужным нам счетам первого уровня, уже выполнить их группировку в кубе-представлении.
3. Объединение нескольких многомерных кубов
Один куб – это хорошо. Но что делать, когда шаблон отчёта состоит из нескольких многомерных кубов разной размерности. Т.е. мы не можем просто взять плоский slice из одного куба. Кубов может быть несколько, да еще и с разным количеством значимых измерений. Наверное, в этом упражнении как раз и заключается вся суть «виртуозности» любой BI-платформы. И чем проще неподготовленному пользователю выполнить настройку для решения такой задачи, тем «круче» статус BI.
3.1. Что такое виртуальный куб?
В платформе «Форсайт» для объединения нескольких многомерных источников существует виртуальный куб (VirtualCube). При его создании необходимо определить состав его кубов-источников. Все измерения у этих кубов-источников условно делятся на две группы:
Общие измерения. Одни и те же измерения, которые есть в каждом кубе. Они автоматически попадают в структуру измерений у виртуального куба. При извлечении данных все выбранные в них элементы транслируются в SelectionSet для кубов-источников.
Частные измерения. Уникальные измерения, которые присутствуют только в некоторых кубах-источниках. С ними все немного сложнее. Автоматический мэппинг для выбранных элементов тут сделать нельзя, т.к. эти измерения релевантны не для всех кубов-источников. Но и добавлять все такие уникальные измерения в структуру виртуального куба тоже не вариант. Тогда какая в нем ценность, если он просто повторяет объединенную структуру всех кубов-источников? В нашей платформе мы пошли другим путем. Все частные измерения мы объединили в одно общее комбинированное (виртуальное) измерение.

Иными словами, элементы всех частных измерений мы «склеили» в одно комбинированное (виртуальное) измерение. Но сам процесс «склейки» может происходить по двум разным вариантам.
Первый вариант – это создание конструируемого справочника (CustomDimension). В нем пользователь может самостоятельно определить состав, порядок и иерархию элементов. И каждый элемент заранее мэппируется с набором частных измерений того или иного куба-источника.
Второй вариант – составной справочник (CompoundDimension). В нем, в отличие от первого варианта, состав элементов и их порядок/иерархия определяются автоматически. Пользователю нужно только указать набор элементов в каждом частном измерении, а также порядок следования измерения в единой «склеенной» иерархии. Далее платформа автоматически сформирует составное измерение в виде декарта элементов.

У каждого из этих вариантов есть свои плюсы и свои минусы. Точнее, каждый из этих вариантов целесообразно использовать для разных сценариев применения.
3.2. Разные подходы к использованию виртуальных кубов
Основное различие в использовании заключается в том, как именно мы хотим применять такой виртуальный куб. Одно из направлений – это создание заранее подготовленной виртуальной витрины данных. Настроив заранее такой виртуальный куб, затем его можно использовать как обычный многомерный источник данных для всех инструментов платформы (отчётность, дэшборды, ETL, расчеты и т.п.) При таком подходе состав источников нужно определять сразу при настройке (фиксированная витрина данных).
Другое направление использования – это просмотр виртуально объединенных данных в отчётности в режиме реального времени. Тут, в отличие от фиксированной витрины, пользователь имеет возможность уже «на лету» изменять структуру виртуального куба (переменная витрина данных). Можно изменять как состав выбранных элементов, так и состав самих кубов-источников. Такой своего рода «множественный» Multi-OLAP. В самом простом случае, когда не требуется повторения сложной шапки или боковика отчёта, в Pivot можно просто «склеить» информацию из разных источников друг за другом. Для случая с анализом и исследованием данных это вполне подойдет. Для полного соответствия шаблону отчёта и динамически изменяемой шапке или боковику таблицы нужно «склеивать» разные области данных одного и того же куба-источника несколько раз. Тогда один и тот же куб-источник нужно размножить через условные «кубы-ссылки». Для каждой уникальной области данных будет своя ссылка. И выбор элементов в каждом из этих кубов-ссылок может быть переопределен в реальном времени. Т.е. количество элементов в общем составном измерении может увеличиваться или сокращаться. Одновременно с этим будет изменяться и объем выборки данных в виртуальном кубе.

4. JOIN для двух и более кубов с «почти общими» измерениями
При объединении двух и более кубов-источников в виртуальный куб все их измерения разделяются на общие и частные. Иногда возникает ситуация, когда формально разные измерения (в том числе с разными значениями ключей элементов) имеют одинаковый или схожий бизнес-смысл. Тогда идеологически такие измерения должны быть общими, но чисто технически они являются частными.
Рассмотрим простой пример. Имеется два источника. Первый – статистика стран мира. Второй – характеристики разных городов. Один куб содержит справочник стран, другой – городов. Первичные ключи у этих измерений, естественно, разные. Но в каждой стране есть город-столица. Поэтому часть элементов измерения городов можно «соединить» с элементами измерения стран. Такая операция эквивалентна sql-команде left/right join и может быть выполнена в платформе «Форсайт» на BI-сервере. Для этого в виртуальном кубе один из кубов-источников нужно сделать основным, остальные кубы будут соединяемые. Далее индекс измерения основного источника нужно связать с индексом в измерениях соединяемых кубов. После этого все соединенные таким способом измерения будут рассматриваться как единое и станут общими. В итоге, в виртуальный куб попадет измерение основного куба, а выбранные в нем элементы через мэппинг индексов будут транслироваться в соответствующие измерения в соединяемых кубах-источниках.
Вернемся к нашему примеру про страны и столицы. Два этих измерения можно связать через международный код страны ISO 3166-1. Тогда в виртуальном кубе измерение стран будет общим, и данные о характеристиках всех столиц (по которым есть данные и указано значение дополнительного атрибута ISO) будут добавлены в состав общих показателей.

5. Денормализация данных для нескольких объединенных кубов
Продолжая рассказ об объединении разноразмерных кубов в одну общую виртуальную структуру, мы подходим к самой интересной и сложной части. Это ситуация, когда боковик шаблона отчёта содержит частные измерения виртуального куба. Чтобы было более понятно, давайте рассмотрим на конкретном примере. Пусть имеется 4 куба-источника с разной информацией о состоянии инвестиционных проектов компании: общие характеристики проектов, показатели эффективности проектов, объем профинансированных средств по статьям расходов и планирование финансовых затрат. Состав измерений для этих кубов, а также требуемый шаблон отчёта представлен на рисунке ниже.

Как видно из рисунка, четыре из восьми измерений, в соответствии со структурой шаблона отчёта, должны стать общими. Но технически это опять невозможно, т.к. кроме измерения «Проекты» ни одно из них не входят сразу во все кубы-источники (см. красные знаки вопроса). С точки зрения шаблона отчёта – тут всё выглядит логично и понятно. Да, есть серые «мертвые» зоны, в которых по бизнес-логике никогда не будет данных, ну а что здесь страшного? Подобные денормализованные отчёты мы встречаем достаточно часто в нашей практике.
Для решения такой задачи в платформе «Форсайт» любое измерение у кубов-источников (входящих в виртуальный куб) можно определить одним из трех типов: частное измерение (FixedDim), фиксированное частное измерение (PinnedDim) или общее измерение (ForcedCommonDim). По умолчанию платформа самостоятельно маркирует измерения на основе их принадлежности ко всем или только выборочным кубам-источникам (как именно – мы уже рассматривали выше в разделе 3.1). Но опционально пользователь может изменить эти настройки. Часть измерений можно вообще исключить из виртуального куба, выбрав в них единственный фиксированный элемент (PinnedDim). Или принудительно сделать их общими (ForcedCommonDim), даже если измерение не входит во все кубы-источники (см. «Вариант общего измерения №2» на рисунке ниже).

Такая принудительная операция приводит к денормализации многомерной матрицы куба-источника (путем размножения или фиксации единственного значения) и позволяет привести структуру виртуального куба в соответствие с заданной структурой шаблона отчёта.
Давайте вернемся к нашему примеру с инвестиционными проектами и рассмотрим эту операцию более подробно. На первом шаге из таблиц фактов в кубы-источники извлекается исходная информация. Каждая физическая таблица строго нормализована и соответствует своей бизнес-логике. Один куб использует только одну таблицу. Все кубы-источники (построенные на этих таблицах фактов) содержат только нужное количество релевантных для них измерений. Где-то два измерения, где-то три и т.д. Далее в виртуальном кубе происходит денормализация модели данных, а именно расширение всех источников до «однородной» структуры (используя ForcedCommonDim). Иными словами, к «маленьким» кубам добавляются недостающие измерения. После этого все оставшиеся частные измерения нужно объединить в одно общее составное (см. CustomDim на рисунке ниже).

Всё, теперь виртуальный куб полностью соответствует структуре шаблона и его можно разместить в отчёте в виде плоского среза (Slice) – часть измерений в боковике таблицы (по строкам), часть в шапке (по столбцам), а часть как управляющие фиксированные параметры.
Таким образом, денормализацию исходных данных для произвольных заданных шаблонов отчётов можно эффективно выполнить средствами виртуализации в BI. Платформа «Форсайт» обладает набором интересных инструментов для такой виртуализации и позволяет настраивать достаточно «сложные» отчёты, основанные на информации из озера данных. В следующей статье нам немного хотелось бы поговорить о разных деталях виртуализации над измерениями в кубах. А также раскрыть количественную статистику некоторых замеров производительности и скорости быстродействия такой виртуализации данных в BI. До скорых встреч!