

Эпиграф
Ни один дракон не может устоять перед загадками и потерянным временем для их решения. ― Дж.Р.Р. Толкин
Проблема
Сегодня мы попытаемся раскрыть пути решения одной из самых больших проблем JavaScript ― CPU-bound заданий. Сделаем мы это в 2 частях. В части I мы поговорим и попробуем использование исключительно CPU-bound заданий. В части II ― модули, которые используются для frontend, CPU+I/O-bound задания и тому подобное.
Что у нас есть?
Node.js имеет несколько способов исполнения CPU intensive заданий:
Просто запустить CPU-bound задачу в одном процессе, блокируя event loop. Кто-то может возразить, что это совсем не вариант, но если этот процесс был специально создан для этой задачи, то почему бы и нет. Правда не у всех есть пара дополнительных ядер.
Создать отдельные процессы (Child Processes), распределить между ними задания.
Создать cluster и заставить работать отдельные процессы в нем.
Использовать Worker Threads и создать несколько дополнительных потоков исполнения.
Попросить C++ разработчика написать C++ Addon, который загадочным образом выполняет CPU-bound задания. В конце концов, думаю все слышали старинные легенды про компилируемые языки программирования и о том, что “нативная” реализация ― это всегда успех (на этой фразе где-то в мире должен заплакать React Native разработчик, смотря на перформанс своего приложения).
В этой статье мы не будем обсуждать реализацию каждого их этих методов, поскольку они все уже довольно детально описаны в других статьях и документации.
Инструменты
Как пример CPU-bound задач мы возьмем разные хеш-функции. Инструментами станут “нативная” реализация конкретного модуля и версия, написанная на чистом JavaScript. Запускаться код буде на машине со следующими характеристиками: 8-ядерный процессор Intel® Core™ i7–7700HQ @ 2,80 ГГц
Будет ли что-то веселое?
Последним возникает вопрос ― каким образом донести основную идею, процесс и результаты исследования…
И для этого была выбрана самая популярная, крутая и продвинутая игра… 1999-го года ― Heroes of Might and Magic III
А теперь, давайте окунемся в легенду
Наш герой ― Node.js и как у любого героя, у него есть путь. Наш герой крепок и могуч. Уже победил множество врагов, потому решил, что настало время разобраться с самым страшным врагом ― CPU-bound задачами.
Команда Node.js
Наш герой должен иметь команду, так кого он возьмет с собой?
Cluster ― это 7 черных драконов, 7 Child Processes ― 7 красных драконов та 1 красный дракон, которого называют JS, потому что он всегда извергает на врагов только одну струю огня.
7 Worker Threads ― 7 молодых зеленых дракона. Неопытных, но готовых к борьбе.
1 C++ Addon ― 1 архангел. Опытный воин, который не раскрывает всех секретов своей силы, но прекрасно показавший себя в предыдущих сражениях.

Часть І
Первая битва
И первое зло на нашем пути это 1,400,000 строк (скелетная пехота), и единственный путь, который позволит нам их побороть ― прогнать их через Murmurhash (не криптографическая хеш-функция общего назначения) как можно быстрее.
Модуль murmurhash3js будет использован, как чистая js имплементация и murmurhash-native как “нативная”.

Имплементация (JS 1 процесс) ― ничего особенного, просто запускаем хеш-функцию в цикле и фиксируем разницу во времени до и после:
const murmurHash3 = require('murmurhash3js');
...
const hash128x64JS = () => {
...
const beforeAll = microseconds.now();
for (let i = 0; i < 1400000; i++) {
const hash = murmurHash3.x64.hash128(file[i]);
}
const afterAll = beforeAll + microseconds.since(beforeAll);
...
};Имплементация (Child Processes) ― порождаем (spawn) новый процесс и ждем окончания всех подсчетов (событие “close”):
...
let beforeJS;
let afterJS;
...
const hash128x64JSChildProcess = (i) => new Promise((resolve, reject) => {
const hash128x64JSChildProcess = spawn('node',
['./runners/murmurhash/runChildProcess/hash128x64JSChildProcess.js', i]);
...
hash128x64JSChildProcess.stdout.on('close', () => {
...
if (...) afterJS = beforeJS + microseconds.since(beforeJS);
resolve();
});
});
beforeJS = microseconds.now();
await Promise.all([
hash128x64JSChildProcess(0),
hash128x64JSChildProcess(1),
hash128x64JSChildProcess(2),
hash128x64JSChildProcess(3),
hash128x64JSChildProcess(4),
hash128x64JSChildProcess(5),
hash128x64JSChildProcess(6)
]);
...Имплементация (Cluster) ― разветвляем (fork) несколько (количество зависит от числа ядер процессора) рабочих процессов и ждем сообщение (messages) от них (про окончание работы) в основном процессе. В нашем случае як “сообщение” было использовано номер процесса:
...
const workers = [];
const masterProcess = () => new Promise((resolve, reject) => {
...
let start = 0;
for (let i = 0; i < 8; i++) {
const worker = cluster.fork();
workers.push(worker);
worker.on('message', (message) => {
...
if (...) resolve(microseconds.since(start));
});
}
start = microseconds.now();
workers[0].send({ processNumber: 0 });
workers[1].send({ processNumber: 1 });
workers[2].send({ processNumber: 2 });
workers[3].send({ processNumber: 3 });
workers[4].send({ processNumber: 4 });
workers[5].send({ processNumber: 5 });
workers[6].send({ processNumber: 6 });
});
const childProcess = () => {
process.on('message', (message) => {
hash128x64JSCluster(message.processNumber);
process.send({ processNumber: message.processNumber });
});
};
...Имплементация (Worker Threads) ― почти та же, что и у “cluster” ― мы создаем несколько воркеров (workers) и ждем в основном потоке (main thread) сообщение (message) об окончании работы:
...
const threads = [];
const mainThread = () => new Promise((resolve, reject) => {
...
const start = microseconds.now();
threads.push(new Worker(__filename, { workerData: { processNumber: 0 } }));
threads.push(new Worker(__filename, { workerData: { processNumber: 1 } }));
threads.push(new Worker(__filename, { workerData: { processNumber: 2 } }));
threads.push(new Worker(__filename, { workerData: { processNumber: 3 } }));
threads.push(new Worker(__filename, { workerData: { processNumber: 4 } }));
threads.push(new Worker(__filename, { workerData: { processNumber: 5 } }));
threads.push(new Worker(__filename, { workerData: { processNumber: 6 } }));
for (let worker of threads) {
...
worker.on('message', (msg) => {
...
if (...) resolve(microseconds.since(start));
});
}
});
...Имплементация (C++ Addon) ― просто используем C++ Addon (модуль) в основном потоке (так же просто, как в JS имплементации):
const { murmurHash128x64 } = require('murmurhash-native');
...
const hash128x64C = () => {
...
const beforeAll = microseconds.now();
for (let i = 0; i < 1400000; i++) {
const hash = murmurHash128x64(file[i]);
}
const afterAll = beforeAll + microseconds.since(beforeAll);
...
};…and “Action!”

Результаты первой битвы:

Как мы видим, C++ Addon ― это самое быстрое решение в этом случае. Child Processes/Cluster/Worker Threads показали почти одинаковый результат.
Второй раунд
Следующее зло на нашем пути ― это 140 строк (скелетные драконы) и мы можем победить их только с помощью Bcrypt (sync) ― адаптивной криптографической функции формирования ключа, что используется для безопасного хранения паролей. Функция основана на шифре Blowfish.
Имплементация абсолютно такая же, как и для Murmurhash. Отличаются только модули ― bcryptjs and bcrypt соответственно.

Пример использования:
const bcrypt = require('bcrypt');
...
const hashBcryptC = () => {
...
const beforeAll = microseconds.now();
for (let i = 0; i < 140; i++) {
const salt = bcrypt.genSaltSync(10);
const hash = bcrypt.hashSync(file[i], salt);
}
const afterAll = beforeAll + microseconds.since(beforeAll);
...
};
Результаты второго раунда:

В этом случае (sync) лучший вариант решения ― это разделить задание и выполнить параллельно, потому Child Processes/Cluster/Worker Threads справились лучше.
Финальная битва
Следующее зло ― это 140 строк (более мощные скелетные драконы) и мы точно сможем их победить, но на этот раз необходимо использовать асинхронный вариант Bcrypt. Имплементация аналогична предыдущей битве (даже модули те же).

Пример:
const bcrypt = require('bcrypt');
...
const hashPromise = (i) => async () => {
const salt = await bcrypt.genSalt(10);
const hash = await bcrypt.hash(file[i], salt);
};
const hashBcryptC = async () => {
const tasks = [];
for (let i = 0; i < 140; i++) {
tasks.push(hashPromise(i));
}
const beforeAll = microseconds.now();
await Promise.all(tasks.map((task) => task()));
const afterAll = beforeAll + microseconds.since(beforeAll);
return afterAll - beforeAll;
};
Результаты финальной битвы:
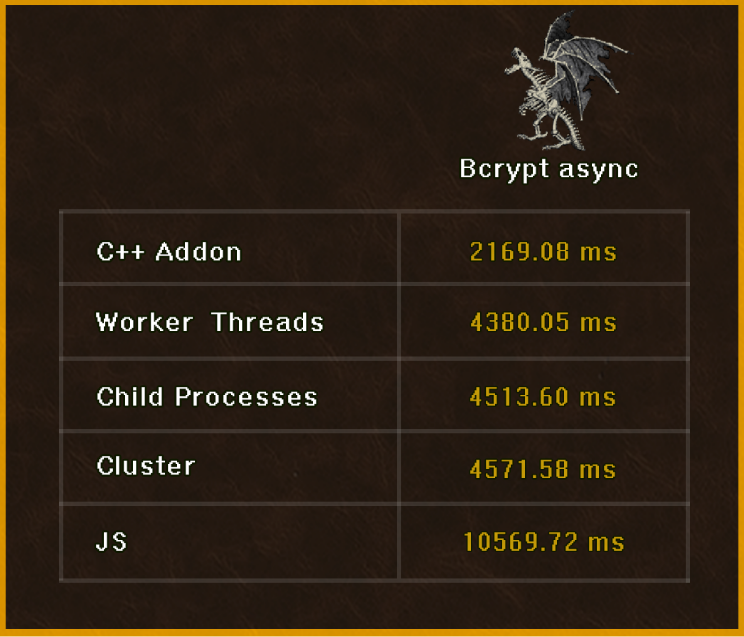
Мы не блокировали Event Loop и использовали UV thread pool, потому в этом случае C++ Addon вновь на коне.
…и результаты предыдущих битв:

Необходимо отметить, что есть одно секретное оружие для нашего архангела. С его помощью он может сражаться даже еще эффективнее. Это количество потоков в UV thread pool (UV_TREADPOOL_SIZE=size), которые может быть увеличено (имеет значение 4 по умолчанию). В нашем случае bycrypt использует crypto.randomBytes(), потому это помогло уменьшить время исполнения bcrypt async почти в 2 раза (при установке значения 8).
Часть II
Крепость Argon 2
Вторая часть нашей эпической истории начинается возле замка “Argon 2”. Его назвали в честь функции формирование ключа, которая была выбрана победителем Password Hashing Competition в июле 2015. Функция имеет 3 версии:
Argon2d подходит для защиты цифровой валюты и информационных систем, не подверженных атакам по сторонним каналам.
Argon2i обеспечивает высокую защиту от trade-off атак, но работает медленнее версии d из-за нескольких проходов по памяти.
Argon2id это гибридная версия.
Node.js с командой должен взять эту крепость, используя argon2-browser (js) и hash-wasm (нативный) модули.
Пример использования:
const argon2 = require('argon2-browser');
...
const hashPromise = (i) => async () => {
const salt = new Uint8Array(16);
const hash = await argon2.hash({
pass: file[i],
salt,
time: 256,
mem: 512,
hashLen: 32,
parallelism: 1,
type: argon2.ArgonType.Argon2d,
});
};
const hashArgon2JS = async () => {
const tasks = [];
for (let i = 0; i < 14; i++) {
tasks.push(hashPromise(i));
}
const beforeAll = microseconds.now();
await Promise.all(tasks.map((task) => task()));
const afterAll = beforeAll + microseconds.since(beforeAll);
...
};
Результаты битвы:

C++ Addon снова на вершине решения чистых CPU-bound заданий.
Восстановление замка
Пока все битвы завершены. Мы должны отстроить город и заручится поддержкой местного населения. Для этого мы ознакомимся со всеми местными законами и традициями. К счастью, все находится в xlsx формате в 7 файлах, которые содержат по 5000 строк в каждом (js xlsx и нативный xlsx-util модули будут использованы для “магического чтения”).
Пример использования (чтение и парсинг файла):
const xlsx = require('xlsx');
...
const xlsxJS = async () => {
const array = [...Array(7).keys()];
const before = microseconds.now();
await Promise.all(array.map((i) => xlsx.readFile(`./helpers/examples/file_example_XLSX_5000 (${i}).xlsx`)));
const after = before + microseconds.since(before);
return after - before;
};
Результаты чтения и парсинга:

В этом случае мы имеем смешанное I/O (чтение файла) и CPU (парсинг) интенсивное задание. C++ Addon справился быстрее именно из-за второй составляющей этой работы.
Время перемен
Наконец-то мы можем изменять старые законы и построить новое процветающее общество. Для этого мы используем jsonnet язык темплейтов. Он поможет нам при необходимости:
Сгенерировать данные для конфигурации.
Управлять расширенной конфигурацией.
Не иметь побочных эффектов.
Организовать, упростить и унифицировать наш код.
Модули @rbicker/jsonnet (js) и @unboundedsystems/jsonnet (нативный).
Пример использования:
const Jsonnet = require('@rbicker/jsonnet');
...
const jsonnet = new Jsonnet();
const jsonnetJS = () => {
const beforeAll = microseconds.now();
for (let i = 0; i < 7; i++) {
const myTemplate = `
{
person1: {
name: "Alice",
happy: true,
},
person2: self.person1 { name: "Bob" },
}`;
const output = jsonnet.eval(myTemplate);
}
const afterAll = beforeAll + microseconds.since(beforeAll);
...
};
Немного странный результат, который скорее всего зависит от внутренней реализации модулей.
В любом случае у нас есть финальные результаты:

И финальные результаты Части II:

Выводы
Из нашего исследования можно вынести следующее:
Необходимо ответственно относиться к выбору модулей. Читать код библиотек и учитывать среду, в которой приложение будет запущено. Популярность модуля ― далеко не самый важный критерий выбора.
Необходимо выбирать специфическое решение для специфической задачи. Child Processes, Cluster, Worker Threads ― каждый из этих инструментов имеет собственные характеристики и возможности использования.
Не можно забывать о других языках программирования, которые могут помочь решить некоторые из ваших задач (C++ Addons, Node-API, Neon library).
Необходимо планировать использование ресурсов (количество CPU или GPU ядер).
Принимайте рациональные архитектурные решения (имплементируйте собственный thread pool, запускайте CPU-bound задания в отдельном микросервисе и тд).
Найдите лучшую возможную комбинацию (C/C++/Rust/Go могут быть использованы не в основном потоке и event loop не будет заблокирован) и вы получите что-то вроде этого:

Спасибо за прочтение.
Надеюсь вам понравилась эта эпическая история и вы почувствовали себя частью легенды.
Для дополнительной информации и возможности проверить результаты, пожалуйста, посетите мой github.
Ironcast
Эх, ёлки, если б в своё время нам бы рассказывали про программирование -- не как набор функций и переменных с элементами математики а просто на примере функций Heroes2 или Doom2 без всяких переменных сейчас бы число профессиональных программистов было на порядок больше..