

2021 год для Amazon Web Services является юбилейным по многим поводам: 15 лет с запуска первых сервисов, а сам re:Invent проходит уже 10-й раз! Второй день обучающей конференции подошел к концу, и в этой статье мы собрали самое важное за прошедшие дни.
По традиции лучшие solution архитекторы Amazon Web Services будут обсуждать все значимые анонсы re:Invent на русском языке в режиме лайф twitch на своем youtube канале. Регистрируйтесь, подключайтесь и задавайте ваши вопросы!

Безопасность всегда на первом месте
Безопасность - один из основных приоритетов для AWS, поэтому хочется начать именно с этой темы.
Amazon CodeGuru расширяет свой функционал, помогая не только автоматизировать код-ревью, определять потенциальные баги, но также находить сохраненные в коде "секреты". Amazon CodeGuru Reviewer Secrets Detector - инструмент для автоматического обнаружения паролей, API ключей, SSH ключей и токенов. Новый детектор использует ML для определения секретов и является частью код-ревью процесса.

Новая функциональность является частью CodeGuru Reviewer (поэтому не требует дополнительной оплаты) и поддерживает большинство API провайдеров: AWS, Atlassian, Datadog, Databricks, GitHub, Hubspot, Mailchimp, Salesforce, SendGrid, Shopify, Slack, Stripe, Tableau, Telegram.
Еще один инструмент по обнаружению уязвимостей, у которого расширился функционал - Amazon Inspector. Ассессменты теперь могут проходить в непрерывном режиме, а функционал инспектор агента переехал в AWS System Manager agent. Новые ресурсы - Amazon EC2 инстансы и Amazon Elastic Container Registry репозитории - автоматически добавятся в инспектор. Прогноз рисков и уязвимостей будет более точным благодаря сопоставлению мета информации из CVE (Common Vulnerability and Exposures) и особенности реализации окружения. Также добавилась поддержка интеграций с Amazon EvenBrige и AWS Security Hub.

Вычислительные ресурсы - новые типы инстансов и EBS

Новые типы инстансов Amazon EC2 Im4gn и Is4gen на базе процессоров AWS Graviton2
Im4gn и Is4gen - новые типы инстансов, оптимизированных для рабочих нагрузок, фокусированных на хранении данных, с возможностью получить до 30TB локального NVMe хранилища нового поколения на базе AWS Nitro SSDs. Оно было специально спроектировано AWS для увеличения производительности при работе с хранилищами данных и приложений с интенсивными I/O нагрузками (например, SQL/NoSQL базы данных, поисковые системы, распределенные файловые системы, и аналитика данных). Эти инстансы позволяют максимально увеличить количество обработанных транзакций в секунду (TPS) для высоко-интенсивных I/O нагрузок. Например, таких как реляционные базы данных ( MySQL, MariaDB, PostgreSQL), и NoSQL базы данных (KeyDB, ScyllaDB, Cassandra), которые имеют наборы данных среднего или большого размера и могут получать выгоду от высокой производительности вычислений и высокой пропускной способности сети.
Amazon EC2 I4i инстансы основаны на третьем поколении процессоров Intel Xeon Scalable и позволяют получить до 30 TB локального хранилища NVMe на базе нового поколения AWS Nitro SSD. Помимо высокой производительности и низких задержек на доступ к данным, Nitro SSD также имеют постоянно-включенное шифрование диска.
i4i инстансы предоставляют до 30% лучшее соотношение цены и производительности, на 60% снижение задержки I/O операций с диском и 75% меньшую вариативность задержек доступа к хранилищу по сравнению с i3 инстансами.
Эти инстансы отлично подходят для таких баз данных, как MySQL, Oracle DB, Microsoft SQL Server, а также NoSQL баз данных: MongoDB, Couchbase, Aerospike и Redis, где низкие задержки доступа к локальному хранилищу NVMe необходимы для гарантии выполнения SLA приложений.
G5g инстансы на Graviton2 и NVIDIA T4G Tensor Core GPUs (ссылка)
В дополнение к процессорам Graviton2 на G5g инстансы находятся NVIDIA T4G Tensor Core GPU для обеспечения лучшего соотношения цена-производительность для стриминга игр для Android с сетевой пропускной способностью до 25 Gbps и 19 Gbps пропускной способностью до EBS.
На этих инстансах можно получить до 30% меньшую цену стриминга за час для Android игр по сравнению с инстансами на основе x86 с GPU. G5g инстансы также идеально подходят для разработчиков машинного обучения, которым нужно эффективное по цене использование модели для предсказания (inference), либо они работают с ML моделями, чувствительными к производительности CPU, и используют библиотеки NVIDIA AI.
Другим примером использования является рендеринг графики с использованием библиотек NVIDIA, или рендеринг приложений на основе стандартных отраслевых API, таких как OpenGL или Vilkan.
При этом, если вам не нужна поддержка библиотек NVIDIA, вы можете использовать инстансы Inf1, которые дают до 70% меньшую цену за inference, по сравнению с G4dn инстансами.
Amazon EC2 M6a инстансы на базе 3го поколения процессоров AMD EPYC (ссылка)
Процессоры в этих инстансах работают на частотах до 3.6 GHz и имеют до 35% лучшее соотношение цена-качество по сравнению с предыдущим поколением инстансов M5a.
По сравнению с M5a новый тип инстансов M6a имеет следующие отличия:
Максимальный размер инстанса увеличен до 48xlarge с 192 vCPU и 768 GiB памяти, позволяя запустить больше рабочих нагрузок в рамках одного инстанса. M6a имеет поддержку Elastic Fabric Adapter (EFA) для рабочих нагрузок, которым нужна низкая сетевая задержка и высоко-масштабируемый канал взаимодействия между несколькими нодами - это могут быть HPC или видео процессинг.
До 35% выше производительность на каждый vCPU по сравнению с аналогичными инстансами M5a, до 50 Gbps сетевой пропускной способности, до 40 Gbps пропускной способности до Amazon EBS, почти что в два раза больше, чем в инстансах M5a.
Постоянно-работающий механизм шифрования памяти и поддержка новых AVX2 инструкций для ускорения работы алгоритмов шифрования и дешифрования.
Graviton 3

Процессоры AWS Graviton3 - это новое поколение в семействе процессоров AWS Graviton. Они имеют до 25% лучшую вычислительную производительность, до 2х раз выше производительность при работе с плавающей запятой и до 2х раз быстрее в криптографических нагрузках по сравнению с процессорами AWS Graviton2. AWS Graviton3 процессоры до 3x раз производительнее в ML нагрузках и включают поддержку bfloat16. Также они поддерживают тип памяти DDR5, что даёт на 50% большую пропускную способность памяти по сравнению с DDR4.
Amazon EC2 C7g инстансы на базе процессора AWS Graviton3 (ссылка)
Amazon EC2 C7g инстансы на основе нового поколения процессоров AWS Graviton3 обеспечивают лучшее соотношение цена-производительность в Amazon EC2 для нагрузок с высокими вычислительными требованиями. C7g инстансы идеально подходят для HPC рабочих нагрузок, для пакетной обработки, автоматизации проектирования электроники (EDA), игр, обработки видео, научного моделирования, распределённой аналитики, машинного обучения на основе CPU и показов рекламы. Они до 25% более производительные, чем инстансы 6-го поколения C6g на базе Graviton2. C7g инстансы - первые в облачной среде имеют поддержку памяти DDR5, дающей на 50% большую пропускную способность памяти по сравнению с DDR4 и обеспечивающей высокую скорость доступа к данным в памяти. Также C7g поддерживают Elastic Fabric Adapter (EFA) для приложений HPC, требующих высокий уровень межузловой связности.
Amazon EC2 Trn1 инстансы на базе AWS Trainium (предварительное ознакомление)

Trn1 инстансы обеспечивают лучшее соотношение цены и производительности для тренировки моделей глубокого обучения в облачной среде для таких сценариев использования, как NLP, обнаружение объектов, распознавание изображений, алгоритмов рекомендаций, интеллектуального поиска и многого другого. Они поддерживают до 16 Trainium акселераторов, до 800 Gbps EFA сетевой пропускной способности (в два раза больше по сравнению с инстансами на базе GPU) и сверхскоростное подключение внутри инстанса для максимально быстрого тренировки ML моделей в Amazon EC2.
AWS Outposts Servers two new form factors (ссылка)
AWS Outposts предоставляет вычислительные мощности для размещения на ваших локальных площадках, которые мониториятся и управляются AWS, и контролируются уже привычным вам AWS APIs. Возможно вы уже слышали про AWS Outposts - в форм-факторе полноразмерной 42U стойки.
Сегодня AWS запускает три новых сервера AWS Outposts на базе AWS Nitro System и с возможностью выбора x86 или Arm/Graviton2 процессоров:

В рамках каждого вашего Outposts сервера, вы можете запустить любое количество инстансов разного размера, но суммарно не выходящего за рамки доступных вычислительных ресурсов и доступного хранилища. Вы можете создавать кластера Amazon Elastic Container Service (Amazon ECS), также планируется добавить поддержку кластеров Amazon EKS в ближайшем будущем. Код, запускаемый вами на этих локальных ресурсах, может использовать все доступные сервисы облака AWS.
Каждый сервер Outposts подключается к облаку или через публичные каналы интернет, или посредством частных выделенных каналов на базе AWS Direct Connect. Также каждый сервер Outpost поддерживает локальный сетевой интерфейс (LNI), который обеспечивает присутствие на уровне Level 2 в вашей локальной сети для конечных точек сервисов AWS.
EBS
AWS Nitro SSD - высоко-производительные диски для приложений с интенсивной I/O нагрузкой (ссылка)
Первое поколение этих дисков использовалось в EBS томах io2 Block Express, благодаря чему вы получали диски с большим количеством IOPS, большой пропускной способностью и максимальным размером тома 64 TiB.
Второе поколение дисков AWS Nitro SSD спроектировано таким образом, чтобы избежать скачков в задержках доступа и обеспечить отличную производительность ввода-вывода для реальных рабочих нагрузок. На тестах инстансы, использующие новые AWS Nitro SSD, такие как Im4gn и Is4gen, показывали на 75% меньшую вариативность задержек доступа, чем на инстансах i3, что даёт более стабильную производительность.
Новый архивный класс хранения для Amazon EBS Snapshots (ссылка)
С помощью Amazon EBS Snapshots Archive, новым классом хранения для EBS Snapshots, вы можете сэкономить до 75% на цене за хранение для снэпшотов, которые вы хотите хранить более 90 дней и не планируете часто к ним обращаться.
EBS Snapshots Archive хранит полные снэпшоты вашего диска при цене хранения $0.0125/GB-месяц. В этом классе хранения - минимальный период хранения составляет 90 дней. Запросы снэпшотов в этом классе хранения имеют цену $0.03/GB() за переданный объём данных. (*цена на примере региона us-east-1)
Восстановите случайно удалённые снапшоты EBS с помощью Корзины (ссылка)
До этого момента, если вы случайно удалили ваш EBS снапшот, вам приходилось откатываться до предыдущего сохранённого снапшота, что увеличивало RPO ваших рабочих нагрузок. С новым функционалом Корзины вы можете задать срок хранения удалённых снапшотов и восстановить их до истечения этого времени.
Контейнеры и Kuberenetes
Karpenter
Одним из интересных релизов на re:Invent 2021 стал Karpenter - инструмент с открытым исходным кодом для автоматического масштабирования Kubernetes кластеров. Он появился как реакция на отзывы клиентов AWS. Раньше задача автомасштабирования кластера EKS решалась совместным использованием Amazon EC2 Auto Scaling групп и Kubernetes Cluster Autoscaler. Многие клиенты жаловались на то, что настройка правильного масштабирования была нетривиальной задачей, им не хватало возможностей k8s Cluster Autoscaler.
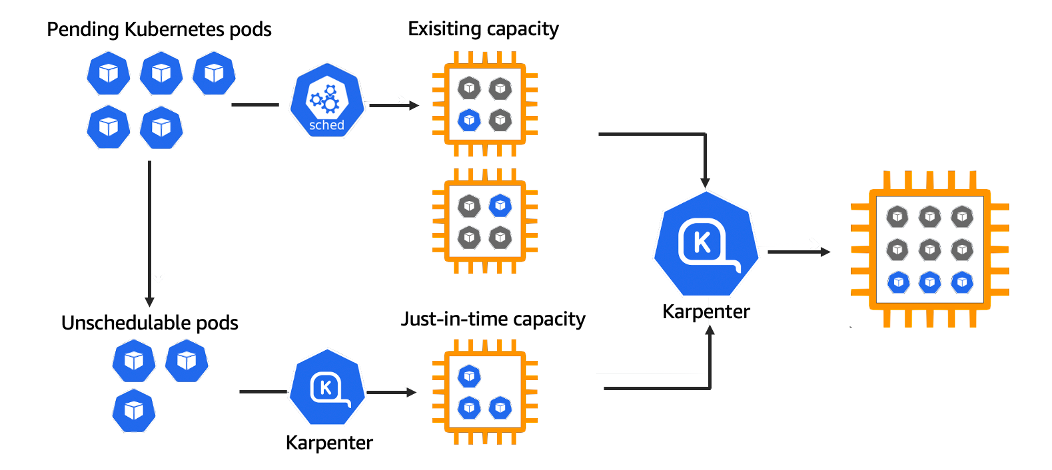
Когда Karpenter запущен в вашем кластере, он оценивает суммарный запрос ресурсов от подов, для которых не хватило места в текущей инфраструктуре, и принимает решения о запуске новых нодов и их остановке, чтобы ускорить запуск подов и уменьшить затраты на инфраструктуру. При этом Karpenter сам подбирает нужный размер и количество виртуальных машин, чтобы наиболее эффективно использовать вычислительные ресурсы. Он взаимодействует напрямую с сервисом виртуальных машин облачного провайдера, например Amazon EC2.
В AWS он может работать на всех типах вычислительных ресурсов - на виртуальных машинах, которые вы сами настроили и добавили в кластер (self-managed node groups), на виртуалках под управлением AWS (managed node groups) и на AWS Fargate. Начать ваше знакомство с Karpenter можно с его документации и демо видео с AWS Container Day
Кэширование публичных образов в Amazon ECR
Теперь можно подключить свои приватные ECR репозитории для кеширования образов из публичных репозиториев (без авторизации). Вы можете задать правила для каждого образа отдельно, и Amazon ECR будет сам автоматически синхронизировать версии образов в исходном репозитории, обновляя свой кеш раз в сутки. Подробнее - в документации.
Аналитика
Среди остальных анонсов новинки сервисов аналитики имеют кое-что общее, а именно: анонсированы возможности использования 4х сервисов в бессерверном режиме.
Amazon Kinesis Data Streams On-Demand Mode
Amazon Kinesis Data Streams - это бессерверный сервис по приему и обработке потоковых данных. Единственной сложной задачей при запуске потока данных в Kinesis было предсказание объема входящего потока, так как при создании Kinesis Data Stream нужно было указать количество шардов - то есть заранее задать максимальную емкость и пропускную способность стрима. Теперь добавлен новый режим конфигурирования - Kinesis Data Streams On-Demand. Этот новый режим работы потока автоматически масштабирует свою емкость в соответствии с изменяющимся объемом данных. Вы платите за каждый гигабайт данных, записанных, прочитанных и сохраненных в потоке в единицу времени.

Kinesis Data Stream в таком режиме способен обслуживать записи и чтение данных с пропускной способностью несколько гигабайт в минуту без планирования емкости. Вы можете также преобразовать существующий поток данных в режим “емкости по запросу” одним щелчком мыши в консоли AWS. Такой режим обеспечивает такую же высокую доступность и надежность, которые уже предлагает Kinesis Data Streams. Все функции, такие как AWS PrivateLink, Amazon Virtual Private Cloud, Enhanced Fan-Out и Extended Retention, работают без изменений. Когда вы переключаете существующие потоки на работу on-demand, вы можете продолжать использовать существующие приложения для записи и чтения данных без внесения каких-либо изменений в код или их простоя. В режиме “емкости по запросу” все существующие интеграции Kinesis Data Streams с другими сервисами AWS, такими как Amazon CloudWatch Logs, Amazon DynamoDB, Amazon Kinesis Data Firehose, Amazon Kinesis Data Analytics и Amazon Lambda, а также с Apache Spark и Apache Flink, продолжают работать.
Amazon MSK Serverless (preview)
Сегодня анонсирован public preview сервиса Amazon MSK Serverless. Это новый тип кластера Amazon MSK, который упрощает разработчикам запуск Apache Kafka без необходимости управлять его мощностью. MSK Serverless автоматически выделяет и масштабирует вычислительные ресурсы и хранилища, и поддерживает оплату на основе пропускной способности, поэтому вы можете использовать Apache Kafka по запросу. Вы платите почасовую ставку за кластер и почасовую ставку за каждый созданный раздел. Кроме того, вы платите за гигабайт пропускной способности и хранилища данных.
Теперь начать работу с Apache Kafka стало еще проще. В консоли управления AWS вы можете настроить безопасные и высокодоступные кластеры, которые автоматически масштабируются вместе с изменением i/o операций вашего приложения. MSK serverless полностью совместим с Apache Kafka, поэтому вы можете запускать существующие приложения без каких-либо изменений кода, или создавать новые приложения с помощью знакомых инструментов и API. MSK Serverless поддерживает встроенные интеграции с другими сервисами AWS, как например AWS PrivateLink, управление доступом с помощью AWS Identity and Access Management (IAM), и храниение схем данных с помощью AWS Glue Schema Registry. Подробнее
Amazon Redshift Serverless (preview)
Amazon Redshift теперь предоставляет в preview бессерверный вариант работы для запуска и масштабирования аналитики без необходимости создавать кластеры хранилищ данных и управлять ими. Благодаря Amazon Redshift Serverless аналитики, инженеры данных и разработчики могут использовать Amazon Redshift для получения результатов анализа информации за считанные секунды. Amazon Redshift Serverless автоматически выделяет и интеллектуально масштабирует вычислительную мощность DWH, чтобы обеспечить лучшую в своем классе производительность для всей вашей аналитики. Вы платите за вычислительные ресурсы, используемые для обработки данных и выполнения запросов, на посекундной основе. Конечно же, Вы можете использовать этот новый режим работы Redshift, не внося никаких изменений в существующие ETL задачи, приложения для аналитики и BI.
Прямо в консоли управления AWS вы можете начать запрашивать и анализировать данные с помощью Amazon Redshift Serverless. Нет необходимости вручную выбирать типы узлов, количество узлов, масштабирование и другие настройки. Вы можете воспользоваться готовыми примерами и наборами данных вместе с образцами запросов, чтобы немедленно приступить к знакомству с возможностями Redshift. Можно создавать базы данных, схемы, таблицы и загружать ваши данные из Amazon S3, получать доступ к данным из общих ресурсов (через Amazon Redshift data sharing) или восстановить снепшот кластера, созданный ранее. Amazon Redshift Serverless также позволяет напрямую анализировать данные в озерах данных Amazon S3, а также в операционных базах данных, таких как Amazon Aurora и Amazon RDS.
Предварительная версия Amazon Redshift Serverless доступна в следующих регионах: US East (N. Virginia), US West (N. California), US West (Oregon), Europe (Frankfurt), Europe (Ireland), Asia Pacific (Tokyo). Просмотрите страницу сервиса, пост в блоге, и раздел документации, чтобы начать работу с Redshift Serverless.
Amazon EMR Serverless (preview)
Представлена preview версия Amazon EMR Serverless - нового бессерверного варианта в Amazon EMR, который позволяет инженерам данных легко и эффективно выполнять аналитику данных петабайтных масштабов в облаке. Amazon EMR - это облачная платформа big data, используемая клиентами для выполнения крупномасштабных задач распределенной обработки данных, интерактивных SQL запросов и задач машинного обучения с использованием open-source аналитических платформ, таких как Apache Spark, Apache Hive и Presto. Благодаря EMR Serverless аналитики могут запустить приложения, созданные с использованием этих фреймворков, без необходимости настраивать, оптимизировать или управлять кластерами. EMR Serverless автоматически выделяет и масштабирует вычислительные ресурсы и ресурсы памяти, требуемые для работы аналитической задачи, и клиенты платят только за те ресурсы, которые они используют.
Используя EMR Serverless вы просто выбираете фреймворк, который хотите использовать для своего приложения, и его версию и отправляете задачи с помощью API - интерактивной среды EMR Studio или JDBC / ODBC клиентов. EMR Serverless автоматически высчитывает и выделяет вычислительные ресурсы и ресурсы памяти, необходимые для обработки запросов, и масштабирует их вверх и вниз на разных этапах обработки в зависимости от меняющихся требований. Например, Spark задаче может потребоваться два рабочих нода на первые 5 минут, десять исполнителей на следующие 10 минут и пять - на последние 20 минут в зависимости от типа обработки данных. EMR Serverless автоматически подготавливает и настраивает ресурсы по мере необходимости, поэтому вам не нужно думать заранее об изменении объемов данных с течением времени. А поскольку вы платите только за используемые ресурсы, EMR Serverless оказывается выгоден для выполнения обработки данных и аналитики петабайтного масштаба. Вы можете проверять статус выполняемых задач, просматривать историю задач и выполнять их отладку с помощью EMR Studio.
Preview версия Amazon EMR Serverless доступна в регионе US-East (N Virginia). Перейдите сюда, чтобы подписаться на preview, прочитайте блог и обратитесь к документации для получения дополнительных сведений.
Новые возможности AWS Lake Formation
Озеро данных может помочь вам собрать вместе разрозненные данные в централизованное хранилище. В нем можно хранить структурированные и неструктурированные данные. Однако настройка озер данных и управление ими включают множество ручных, сложных и трудоемких задач. AWS Lake Formation позволяет легко настроить безопасное озеро данных буквально за несколько дней.
Сегодня мы рады сообщить о запуске некоторых новых функций AWS Lake Formation, которые еще больше упрощают загрузку данных, оптимизацию их хранения, и управление доступом к озеру данных.
Управляемые таблицы (Governed Tables) - новый тип таблиц Amazon S3, упрощающий и повышающий надежность приема и управления данными любого объема. Управляемые таблицы поддерживают ACID транзакции, которые позволяют нескольким пользователям одновременно вставлять и удалять данные в нескольких управляемых таблицах. Транзакции ACID также позволяют выполнять запросы, возвращающие согласованные и актуальные данные. Изменения не фиксируются в случае ошибок в ваших ETL задачах или во время обновления данных.
Оптимизация хранилища с автоматическим сжатием для управляемых таблиц (Storage Optimization with Automatic Compaction) - когда этот параметр включен, AWS Lake Formation автоматически сжимает небольшие объекты S3 в управляемых таблицах в более крупные объекты, чтобы оптимизировать доступ к ним через инструменты аналитики, такие как Amazon Athena и Amazon Redshift Spectrum. Используя автоматическое сжатие, вам не нужно самим реализовывать специальные ETL задачи, которые читают, объединяют и сжимают данные в новые файлы, а затем заменяют исходные файлы.
Детализированный контроль доступа с безопасностью на уровне строк и ячеек (Granular Access Control with Row and Cell-Level Security) - вы можете настраивать доступ к определенным строкам и столбцам ваших данных в результатах запросов и в задачах AWS Glue ETL в зависимости от того, кто выполняет запрос.

Пропадает необходимость создания и постоянного обновления проекций и подмножеств ваших данных для разных ролей и уровней доступа. Эта функция работает как для управляемых, так и для традиционных таблиц S3. Больше информации - в блоге, и как обычно - в документации
Cloud Watch - расширяет функциональность
Появилось два значимых обновления в Amazon CloudWatch. Оба сосредоточенны на мониторинг приложения, но обо всем по порядку. Начнем с Amazon CloudWatch Evidently: он будет полезен в случае, если необходимо внедрить A/B тестирование, или фича флаг подход (Feature Toggles). В обоих ситуациях задача одна - добавить новый фунционал, и в случае непредвиденного поведения пользователей (например, идея не прошла проверку на пользователях) или системы, можно сделать быстрый возврат к предыдущему состоянию. Используя Amazon CloudWatch Evidently можно управлять запуском нового функционала, а также отслеживать его поведение:

Подробный туториал с примером A/B тестирования и созданием флага для фичи можно изучить в статье.
Второе обновление Amazon Cloud Watch сконцентрировано на мониторинге конечных пользователей. Real-User Monitoring (RUM) поможет собрать метрики для анализа пользовательского опыта вашего приложения. Добавив JavaScript снипет, который генерируется в процессе настройки Real-User Monitoring, и добавив его на страницу вашего приложения, можно собирать телеметрию производительности, ошибки JavaScript, HTTP ошибки, отслеживать путь пользователя и мониторить другие данные со стороны клиента.

Подключайтесь на стрим:
И это далеко не все анонсы, сделанные за эти два дня, но мы и не прощаемся - впереди еще несколько дней конференции! Мы продолжим делиться с вами новинками в текстовом формате и не только. Напоминаем, что в ближайшие дни пройдут 3 live-трансляции с обсуждениями самых интересных анонсов. Регистрируйтесь и увидимся на стриме!