

После переписывания Cyberscore я захотел отправить на сайт какие-нибудь результаты. Последнее, во что я играл, это Pokémon Legends: Arceus, по которой на Cyberscore есть около 3000 таблиц результатов. Я не собирался отправлять столько рекордов вручную, поэтому начал придумывать инструмент для автоматизации этого процесса.
Эта статья посвящена двум вещам: процессу извлечения результатов из JPG с помощью Rust и встраиванию этого функционала во фронтенд Cyberscore.
▍ Описание проекта
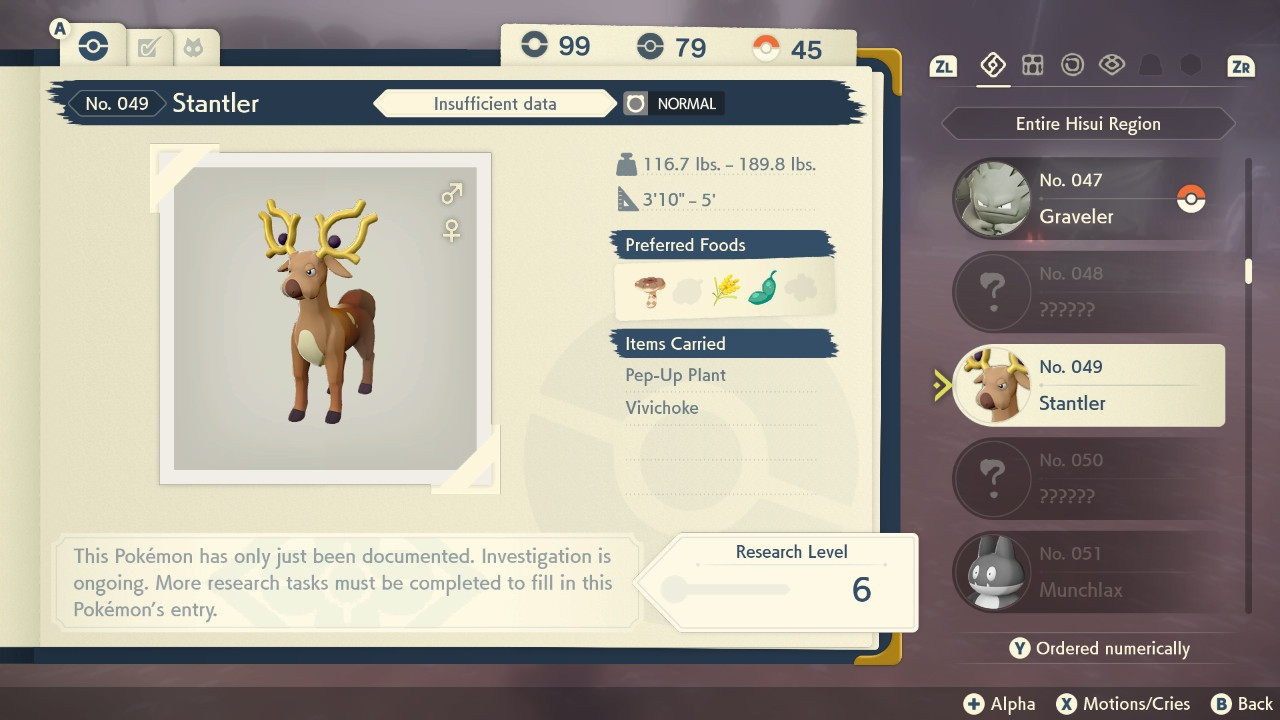
Большая часть результатов берётся из Покедекса. Для каждого вида Покемонов в Покедексе есть двухстраничная запись. Первая страница показывает общую информацию вроде имени, типа, предпочтительной еды, а также минимального/максимального веса и роста каждого пойманного экземпляра:
На второй странице приводятся исследовательские задачи, связанные с этим видом, а также достигнутый уровень исследования:

На этих двух скриншотах присутствует не менее 12 показателей, которые можно отправить в Cyberscore: диапазоны веса и роста (4), уровень исследования (1) и исследовательские задачи (7, последняя является игровым квестом и в счёт не идёт). Cyberscore также позволяет загружать в качестве рекордов скриншоты или видео, поэтому подход с обнаружением результатов на скриншотах и их автоматической отправкой показался мне хорошей идеей.
Пользователи уже разработали инструмент для New Pokémon Snap, который при помощи Python и OpenCV обрабатывает кучу скриншотов, генерируя CSV-файл с результатами. Это очень популярный инструмент, но я хотел сделать нечто встроенное непосредственно в сайт, чтобы избежать необходимости локальной установки. То есть просто загружать все скриншоты, подтверждать отсутствие ошибок при обнаружении искомых результатов, и всё.
Эта статья посвящена двум вещам: процессу извлечения результатов из JPG с помощью Rust и встраиванию этого функционала во фронтенд Cyberscore.
Ссылка на исходный код и демо находится в конце.
▍ Обнаружение результатов на скриншотах
Обнаружение результатов сложностей не вызвало: поскольку мы обрабатываем скриншоты игры, то информация всегда находится в одних и тех же местах с минимальным отклонением в пикселях. Первым делом нужно было понять, что вообще обнаруживать. Сначала требовалось определить, какой из пяти Покемонов в списке был выбран, после чего считать его номер в Покедексе. Затем нужно было узнать, какая страница Покедекса показывалась (всего, возможно, три) и считать соответствующие числа. В результате нас интересуют следующие окошки:

Чтобы выяснить, какой из пяти видов Покемонов выбран, я вычислял средний цвет верхнего ряда пикселей каждого из пяти окошек в разделе справа и определял, какой из них ближе к белому. Я усреднял каждый RGB-канал по отдельности и вычислял его расстояние до 255. Вероятно, можно было вычислить среднюю яркость и использовать её значение. В данном случае можно проделать эту операцию разными способами, я же просто выбрал первый рабочий.
Следующим шагом нужно было обнаружить фактический номер Покемона в Покедексе. Я начал с обычной пороговой операции, которая выглядит так:

Чтобы найти отдельные цифры в чёрно-белой версии, я обнаруживал все группы связанных пикселей с помощью системы непересекающихся множеств. Таким образом, для каждой цифры я получал набор пикселей (и их позиции, произвольно привязанные к верхнему левому углу ограничительной рамки цифры). Чтобы определить, какую именно цифру представляет тот или иной набор, я извлёк из нескольких скриншотов коллекцию образцов для каждой цифры и создал на их основе PNG-шаблон:

Применяя к этому шаблону ту же пороговую операцию и обнаружение связанных пикселей, я смог с помощью сопоставления находить наиболее близкий к определяемой цифре вариант. Если кратко, то этот алгоритм перебирает каждый пиксель внутри ограничительной рамки шаблона и цифры, вычисляет количество совпавших пикселей и возвращает вариант, в котором больше всего совпадений. Упорядочивание цифр по оси x давало мне
[0, 3, 7], что легко конвертировалось в 37.Эту же технику я применил и к другой странице Покедекса. Здесь мне понадобился дополнительный код, потому что иногда вес и рост содержали лишь одно число вместо диапазона. Тем не менее применение к обнаруженному тексту подходящих регулярных выражений решило проблему.
Чтобы определить, какая страница Покедекса выбрана (общая информация или исследовательские задачи), я обнаруживал, где именно среди вкладок в верхнем левом углу находился символ A. Для этого я делал сопоставление с шаблоном в обоих возможных положениях.
В конечном счёте получилась библиотека со следующим интерфейсом (несколько атрибутов упущены для ясности):
pub struct PokemonLegendsArceusOCR {}
impl PokemonLegendsArceusOCR {
pub fn new(a: image::DynamicImage, b: image::DynamicImage, c: image::DynamicImage);
pub fn selected_page(&self, proof: image::DynamicImage) -> Option<PokedexPage>;
pub fn research_tasks(&self, proof: &image::DynamicImage) -> Option<ResearchTaskProof>;
pub fn info(&self, proof: &image::DynamicImage) -> Option<InfoProof>;
}
pub enum PokedexPage {
Info,
ResearchTasks,
}
pub struct ResearchTaskProof {
pub dex: usize,
pub tasks: Vec<u32>,
}
pub struct InfoProof {
pub dex: usize,
pub weight: Weight,
pub height: Height,
}
pub struct Weight {
pub min: u32,
pub max: u32,
}
pub struct Height {
pub min: u32,
pub max: u32,
}Все эти изображения в конструкторе являются разными шаблонами для классификации, используемыми в каждой функции.
▍ Компиляция в WebAssembly
Изначально, следуя руководству MDN “Compiling Rust to WebAssembly”, я установил wasm-pack и скорректировал Cargo.toml:
[lib]
crate-type = ["lib", "cdylib"] # добавляем cdylib
[dependencies]
image = "0.24.1"
# добавляем эти три библиотеки
wasm-bindgen = "0.2"
js-sys = "0.3.56"
console_error_panic_hook = "0.1.7"Чтобы заставить мою библиотеку работать в WebAssembly, я начал с упрощения её API до одной функции, которая получает массив байт, представляющий проверяемый jpg, и возвращает то, что обнаружит. Ради упрощения обучающие изображения я вложил в программу с помощью макроса
include_bytes!.#[wasm_bindgen]
pub fn ocr_pla_dex(proof: &[u8]) -> Proof;
#[wasm_bindgen]
pub struct Proof {
#[wasm_bindgen(getter_with_clone)]
pub research: Option<ResearchTaskProof>,
pub info: Option<InfoProof>,
}
#[wasm_bindgen]
pub struct ResearchTaskProof {
pub dex: usize,
#[wasm_bindgen(getter_with_clone)]
pub tasks: Vec<u32>,
}Структуры с
wasm_bindgen автоматически генерируют геттеров и сеттеров для каждого публичного члена, но для того, чтобы это сработало, эти члены должны реализовывать Copy. Поскольку Vec этот типаж не реализует, я использовал атрибут getter_with_clone. Из-за Vec элемент ResearchTaskProof аналогично не имеет Copy, так что этот приём пришлось проделать и с pub research.Теперь я смог запустить
wasm-pack build --target web и получить набор файлов в pkg/, включая pla_ocr.js и pla_ocr_bg.wasm.<script type="module">
import init, {ocr_pla_dex} from "/js/ocr-pla/pla_ocr.js";
init();
window.ocr = ocr_pla_dex;
</script>
<script type="text/javascript">
document
.querySelector("#proof-form")
.addEventListener('submit', async (ev) => {
const file = document.getElementById('proof-form-field').files[0];
const buff = await file.arrayBuffer();
const bytes = new Uint8Array(buff);
const result = window.ocr(bytes);
});
</script>
Файл wasm загружается pla_ocr.js с использованием относительного URL, хотя в случае иного расположения его можно передать и в
init.При первом выполнении этого кода в браузере он не сработал – в консоли возникла ошибка
Unreachable code. Активировав console_error_panic_hook, я смог увидеть фактическое исключение: контейнер image пытался использовать потоки для декодирования jpeg-скриншота. Похоже, что эта фича включена по умолчанию, поэтому мне пришлось подредактировать Cargo.toml, чтобы отключить предустановленный функционал и активировать только, на мой взгляд, необходимый:[dependencies]
image = {
version = "0.24.1",
default-features = false,
features = ["gif", "jpeg", "png", "webp", "farbfeld"]
}Это решило проблему, и всё заработало. Немного поигравшись с кодом Cyberscore, я смог полностью интегрировать эту библиотеку оптического распознавания символов (OCR) на сайт.
Вот видео конечного результата:
▍ Заключение
Самым сложным здесь было написание JS для сопоставления результатов OCR с таблицами Cyberscore. В процессе также пришлось разобраться с несколькими пограничными случаями, например, не отправлять нулевые результаты или те, что меньше ранее отправленных. Следующим шагом будет поиск способа обобщения системы до нескольких игр.
Этим инструментом начали пользоваться и другие игроки. Причём он не только автоматически отсылает результаты, но и сокращает количество ошибок, которые люди совершают при вводе данных.
Исходный код для Rust-части лежит на Gitlab, а вот JS-часть недоступна, так как Cyberscore пока не является бесплатным ПО. Тем не менее самые важные моменты объяснены выше.
Если вас интересует тема компьютерного зрения, рекомендую посмотреть моё выступление на Rustconf 2021, посвящённое идентификации карточек Покемонов. В нём я разбираю различные случаи использования, но при этом также рассказываю о некоторых базовых и распространённых алгоритмах обработки изображений в этой области.
