

31 марта 2022 года на сайте IETF был официально размещен текст рабочего документа (копия 1, копия 2) New UUID Formats (далее – стандарт), который должен формально обновить, а фактически заменить давно устаревший и изначально ущербный RFC 4122.
В стандарте представлены новые форматы универсальных уникальных идентификаторов (UUID), имеющих следующие свойства:
для использования в высоконагруженных приложениях и базах данных – как монолитных, так и распределенных,
возрастающие по времени генерации (без дополнительных секунд),
содержащие таймстемп, счетчик с инициализацией его сегментов нулем и псевдослучайным значением, а также собственно псевдослучайное значение,
объединенные с метаданными.
Стандарт рекомендует поставщикам СУБД обеспечить создание и хранение UUID новых форматов для использования в качестве идентификаторов или левых частей идентификаторов, таких как, помимо прочего:
первичные ключи,
суррогатные ключи для хронологических баз данных,
внешние ключи, включая используемые в полиморфных отношениях,
ключи для пар ключ-значение в столбцах JSON и базах данных типа «ключ-значение».
В долгих и жарких спорах удалось выработать стандарт по существу безупречного качества. Хотя некоторые туманные формулировки и прежние неудачные варианты технических решений сохранились в тексте, однако найдены оригинальные и красивые решения всех проблем. Стоит особенно отметить творческий вклад жителя Японии с псевдонимом LiosK и разумные решения инициаторов стандарта Brad Peabody и Kyzer Davis из США. Стандартом обеспечена максимально возможная скорость поиска записей по содержащемуся в них значению UUID. Стандарт содержит множество правильных рекомендаций с обоснованием. Единственный существенный изъян стандарта – это расточительное использование 6 из 128 битов UUID (сегменты ver и var) лишь для совместимости с отжившим RFC 4122. Стандарт превосходит ULID, KSUID, CUID и остальные аналоги. Все они были исследованы и указаны в стандарте.
Стандарт еще не утвержден, но поставщики СУБД уже могут начинать его реализовывать. Невозможно представить, что появится другой – более качественный и существенно отличающийся вариант стандарта. Приложенные к стандарту прототипы на языке C сильно упрощенные, и поэтому они не могут быть хорошей основой для разработки. Из трех предложенных форматов наибольшую практическую ценность представляет версия UUIDv7.
В текущую версию стандарта из-за нехватки времени не вошли альтернативные текстовые кодировки UUID. Инициаторы стандарта хотят включить их в следующую версию стандарта, причем кодировка Crockford’s Base32 уже ими одобрена.
Хотя стандарт предоставляет разработчикам генераторов UUID значительную свободу в очерченных рамках, но эталонная структура UUID, которая обсуждалась при выработке стандарта, следующая:
Обозначение в стандарте |
Позиция сегмента в UUID слева направо |
Длина, битов |
Двоичное значение или алгоритм расчета |
Предназначение |
unix_ts_ms |
1 |
48 |
Количество миллисекунд с полуночи (00:00:00) 1 января 1970 года по всемирному координированному времени (UTC) минус дополнительные секунды |
Обеспечение монотонности записываемых UUID. Таймстемп с миллисекундной точностью, отстающий от UTC на десятки секунд. Миллисекунда - это максимально возможная точность для упорядочения по моменту времени генерации UUID, приходящих из разных источников |
ver |
2 |
4 |
"0111" |
Версия UUIDv7. Смысл этого сегмента лишь в совместимости с RFC 4122 |
rand_a |
3 |
1 |
Сегмент счетчика, инициализируемый нулем каждую миллисекунду |
Защита от переполнения счетчика при маловероятной неудачной инициализации счетчика большим псевдослучайным значением |
4 |
11 |
Сегмент счетчика, инициализируемый псевдослучайным значением каждую миллисекунду |
Счетчик обеспечивает монотонность UUID из одного источника, генерируемых в течение миллисекунды. Инициализация счетчика псевдослучайным значением уменьшает вероятность коллизий UUID |
|
var |
5 |
2 |
"10" |
Вариант, детально описанный в стандарте или в RFC 4122, в отличие от других упомянутых в RFC 4122 вариантов. Смысл этого сегмента лишь в совместимости с RFC 4122 |
rand_b |
6 |
12 |
Сегмент счетчика, инициализируемый псевдослучайным значением каждую миллисекунду |
Счетчик должен быть достаточно длинным для защиты от переполнения, но не слишком длинным, чтобы ускорить желательный двоичный поиск UUID по старшим битам. В течение миллисекунды весь счетчик увеличивается на единицу для каждого следующего UUID |
7 |
50 |
Псевдослучайное значение, сгенерированное отдельно для каждого UUID |
В отличие от сегмента счетчика, инициализируемого псевдослучайным значением каждую миллисекунду, этот сегмент затрудняет угадывание близких по значению UUID с одинаковыми таймстемпами |
|
обозначение отсутствует |
справа от UUID в идентификаторе, используемом в качестве уникального или суррогатного ключа |
любая |
Кастомный сегмент, который может быть составным |
См. под таблицей возможные элементы кастомного сегмента |
Возможные элементы кастомного сегмента:
дополнительное псевдослучайное значение
тип сущности или код таблицы базы данных
пространство имен
shard (сегмент) или partition (секция)
код источника данных
код типа операции или типа сообщения
контрольная сумма
другие элементы, специфичные для приложения
Комментарии (52)

wildraid
03.04.2022 20:57+13Как раз на днях тестировал UUIDv7 в контексте использования в Snowflake. Всё работает, как и ожидалось - partition pruning улучшается радикально. Особенно по сравнению с UUIDv4, который, по сути, всегда вызывает full scan.
Пример того, как его можно сгенерировать на Python:
import random import time import uuid def uuid7(unix_ts_ms: int = None): """ UUIDv7 description: https://datatracker.ietf.org/doc/html/draft-peabody-dispatch-new-uuid-format-03#section-5.2 UUIDv7 example: https://datatracker.ietf.org/doc/html/draft-peabody-dispatch-new-uuid-format-03#appendix-B.2 """ if unix_ts_ms is None: unix_ts_ms = time.time_ns() // 1000000 ver = 7 variant = 2 rand_a = random.getrandbits(12) rand_b = random.getrandbits(62) # Offsets: # # unix_ts_ms = 128 - 48 = 80 # ver = 80 - 4 = 76 # rand_a = 76 - 12 = 64 # variant = 64 - 2 = 62 # rand_b = 62 - 62 = 0 return uuid.UUID(int=(unix_ts_ms << 80) + (ver << 76) + (rand_a << 64) + (variant << 62) + rand_b)
Metal_Messiah
04.04.2022 00:08+1Ваш код не учитывает отбрасывание дополнительных секунд с времени.

andreymal
04.04.2022 00:59+2В UNIX-времени изначально не существует дополнительных секунд и отбрасывать здесь нечего, не?
Metal_Messiah
04.04.2022 10:08+1Отнюдь. UTC часы добавляют эти секунды. Это делается при чем в ручном режиме, умные дядьки выбирают дату, потом придумывают и назначают другую. А есть часы UT1 которые без поправки лип секунд, начиная с 1980 (внезапно) года.
Именно такие стоят на спутниках GPS. Вот как получить эти часы -- я в душе не чаю :-(. Собственно интересно как авторы стандарта это видят? По табличке когда вводились лип секунды сверять? :-)
wildraid
04.04.2022 12:40+1Конкретно в Python на Windows и Unix это, похоже, не проблема. Документация говорит следующее:
Return the time in seconds since the epoch as a floating point number. The specific date of the epoch and the handling of leap seconds is platform dependent. On Windows and most Unix systems, the epoch is January 1, 1970, 00:00:00 (UTC) and leap seconds are not counted towards the time in seconds since the epoch. This is commonly referred to as Unix time. To find out what the epoch is on a given platform, look at
gmtime(0).Про другие платформы стоит подумать в будущем. Действительно, любопытная история.
Metal_Messiah
04.04.2022 16:30+1На википедии написано:
> Unix time number increases continuously into the next day during the leap second and then at the end of the leap second jumps back by 1 (returning to the start of the next day). For example, this is what happened on strictly conforming POSIX.1 systems at the end of 1998:
Не понимаю почему они так в стандарте написали про лип-секунды. Словно надо что-то делать, но что делать не написали. Почему нельзя было написать просто "Unix-time" ?
agmt
04.04.2022 19:47В Unix-time зафиксировано, что 1 день == 86400 секунд, потому чуть позже, когда появились високосные секунды, появилось требование не считать их (в итоге реальное количество секунд с 1970 на 27 секунд больше, чем возвращается time()).
Если же хочется заиспользовать правильные часы, есть таймзоны `right/*`: www.ucolick.org/~sla/leapsecs/right+gps.html$ TZ=UTC date; TZ=right/UTC date
Mon Apr 4 16:46:45 UTC 2022
Mon Apr 4 16:46:18 UTC 2022
А в традиционной unix-tz такое невозможно:$ TZ=right/UTC date -d @1483228826
Sat Dec 31 23:59:60 UTC 2016
Metal_Messiah
04.04.2022 10:21+1Честно говоря, я окончательно запутался. Вот тут https://stackoverflow.com/questions/16539436/unix-time-and-leap-seconds говорят, что POSIX Time не включает лип-секунды, и по этому это не совсем UTC. Я совсем запутался, но если кто знающий пояснит -- буду рад.
Еще одна статья по теме, но я ее пока не читал:
http://www.madore.org/~david/computers/unix-leap-seconds.html

amarao
03.04.2022 21:11А как они выглядят? как uuid4, но с семёрочкой?

edo1h
03.04.2022 21:41+1те же 128 бит, текстовое представление то же.
альтернативная (более компактная) запись рассматривается, но в стандарт не вошла (в статье это есть).
ИМХО особого смысла в альтернативной записи нет, экономия не настолько велика чтобы оправдать сломанную совместимость. вот если правда UUID с длиной более 128 бит получат распространение, то можно подумать и об альтернативной записи.
edo1h
03.04.2022 21:13+6надо же, достаточно близко к тому, что предлагал я
https://github.com/uuid6/uuid6-ietf-draft/issues/34
я доволен )
Metal_Messiah
04.04.2022 00:06+2А какова вероятность генерации коллизии с разных машин в одну и туже миллисекунду?
edo1h
04.04.2022 00:50+2я делал табличку с вероятностью коллизий:
https://docs.google.com/spreadsheets/d/1fUykRMW5v48FfpSKRPSvewyzUHywjxPlB6FjXvHa5Jg/edit#gid=0можете сделать копию и поиграться. в случае генерации миллиона uuid в секунду, вероятность столкнуться с коллизией за год ≈0.17%.
многовато, конечно, я предлагал способы существенно снизить вероятность коллизий. впрочем, для большинства применений этого вполне достаточно.на первом листе там немного другой подход: сколько uuid в секунду мы можем генерировать чтобы вероятность столкнуться с коллизиями за 50 лет была не больше одной миллиардной. получается ≈20к uuid в секунду.

vintage
04.04.2022 15:23+1Стоит иметь ввиду, что вероятность коллизий в случае рандома по началу крайне мала и только со временем, по мере насыщения, начинает расти. Если взять полные 128 бит рандома, то вероятность за четверть века получить хотя бы одну коллизию всего 0.1%:
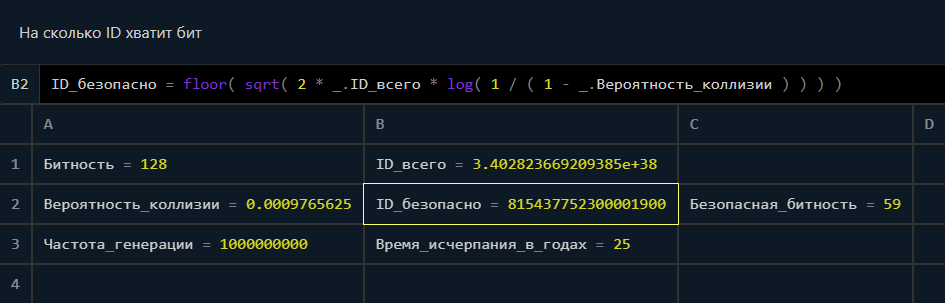
При этом в первый год вероятность коллизии в 500 раз меньше:
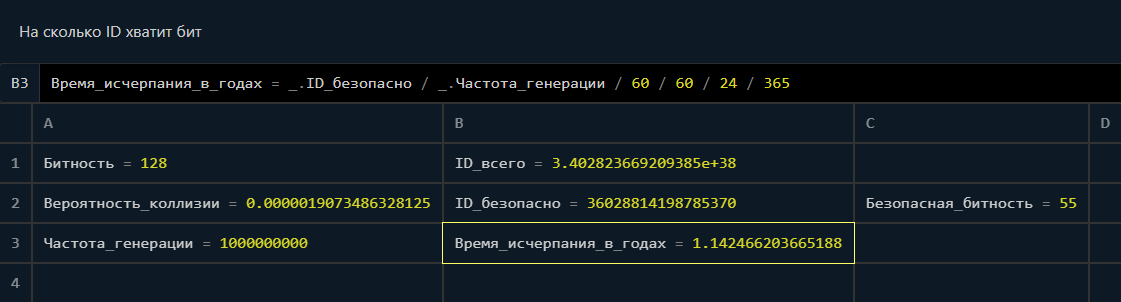
Кроме того, если рандому плевать когда были сгенерированы идентификаторы, то всем схемам с таймштампами уже не плевать и поэтому любые неравномерности в частоте генерации идентификаторов повышают риск коллизии.

funca
05.04.2022 00:09Вообще да, хотелось бы увидеть расчеты на которые опираются авторы спеки. Почему именно такие длины полей являются оптимальными?
edo1h
05.04.2022 00:59а что значит «оптимальными»? исходили больше из удобства (таймстамп длиной в целое число байт) и совместимости (128 бит на весь uuid, из которых 6 зарезервированы под вариант/версию)

SergeyProkhorenko Автор
05.04.2022 23:01+1Исходили вовсе не из "удобства".
Во-первых, были внешние ограничения (общая длина, сегменты ver и var), необходимые для совместимости с RFC 4122. Иначе сложно пропихнуть стандарт через утверждающие инстанции. Также беспокоились за совместимость с имеющимся софтом, который оперирует 128-битовами UUID. По мне так оптимальная длина не 128, а 160 битов.
Во-вторых, длина таймстемпа 48 битов диктовалась необходимостью хранить миллисекунды (для синхронизации UUID из разных источников через интернет бОльшая точность смысла не имеет), а также привязкой к Unix-time (тоже для более гладкого прохождения через утверждающие инстанции) и желанием избежать быстрого переполнения таймстемпа.
В-третьих, длина счетчика определялась необходимостью сохранять десятки тысяч записей в миллисекунду при пиковых нагрузках. То есть, ориентировались на производительность СУБД.
В-четвертых, длина самого правого псевдослучайного сегмента (не менее 32 битов) определялась необходимостью затруднить угадывание близких UUID, сгенерированных в течение миллисекунды.
Для некоторых сегментов длина задана жестко (где необходимо), а для других - как довольно широкая "вилка" (где возможно).
Да, было выравнивание по границам байтов (для человекочитаемости сегментов в обычной кодировке), но большой роли это не играло. Плюс-минус несколько битов - это несущественно. Но в целом длины сегментов заданы весьма разумно (кроме 6 битов, потраченных впустую на ver и var).edo1h
06.04.2022 00:55+1Также беспокоились за совместимость с имеющимся софтом, который оперирует 128-битовами UUID.
я про совместимость и написал.
Во-вторых, длина таймстемпа 48 битов диктовалась необходимостью хранить миллисекунды (для синхронизации UUID из разных источников через интернет бОльшая точность смысла не имеет), а также привязкой к Unix-time (тоже для более гладкого прохождения через утверждающие инстанции) и желанием избежать быстрого переполнения таймстемпа.
нет.
- уже существующий с 2005 года uuid работает со стонаносекундной точностью, никаких проблем с этим не видно. вы правда думаете, что в 2022 году, рассматривая стандарт на тысячелетия вперёд, мы не можем себе позволить такую точность? так, сюрприз, если таймстамп с такой точностью и недоступен, то никто не мешает брать миллисекундную точность, и «разбавлять» рандомом;
- я уже замучился говорить, что для целей uuid (уникальность и локальность) ничего страшного в переполнении таймстампа нет;
- ладно, пусть мы решили использовать миллисекундную точность и обойтись без переполнения таймстампа на время актуальности стандарта, в этом случае 44 битов хватило бы до 2527 года, вы правда думаете, что через 500 лет сегодняшние rfc будут интересовать кого-то помимо историков?
Плюс-минус несколько битов — это несущественно
так в том-то и дело, что не так уж и мало. 6 бит у нас «украла» совместимость со старыми версиями uuid. 5 бит таймстампа будут нулевыми ещё больше двухсот лет. один бит теряется на защиту от переполнения счётчика. всё в сумме это уже выглядит «не очень» для обепечения глобальной уникальности (тот же ms называет uuid guid'ом). вместо того, чтобы озаботиться уникальностью здесь и сейчас, зачем-то обеспечили защиту от переполнения таймстампа на ближайшие почти десять тысяч лет.
я продолжаю считать свой вариант лучше окончательной версии:
- максимальное возможное число изменяемых бит (читай: минимизация вероятности коллизий) при сохранении совместимости с rfc 4122 (новый uuid гарантированно не пересекается с описанными в раннем стандарте);
- сохранение монотонности при сдвигах времени назад до 2.5 секунд (что автоматом решает и вопрос с високосной секундой);
- минимизация числа решений, отданных на откуп реализации, всего два момента, в которых допустимы вариации: (a) требуется строгая монотонность или нет, (b) доступен ли таймер с требуемой точностью.
итоговый стандарт же слишком «жидкий»: размер счётчика не определён (вроде бы нет даже рекомендуемого значения), а обозначены широкие пределы; зачем-то оставили рандомное приращение значения счётчика, хотя потребности в нём при наличии рандомной части я не вижу; невнятная обработка скачков времени/високосных секунд.
впрочем, я уже написал, итоговый стандарт не так уж плох, для большинства применений он отлично подойдёт.
просто мне хотелось пропихнуть стандарт не конфликтующий с rfc 4122, и при этом по всем существенным параметрам не хуже явного фаворита среди конкурентов — ulid: с меньшей вероятностью коллизий, с прописанной в стандарте непредсказуемостью генерируемых идентификаторов, с прописанной в стандарте обработкой скачков таймстампа при коррекции времени/високосных секундах.
funca
06.04.2022 01:17Просто в качестве примеров здесь приводится множество различных альтернатив, которыми вдохновлялись авторы.
Взять например ShardingID у Instagram. У него похожая структура (block id, whatever), но лишь 41 бит на миллисекунды, что дает им запас в 41 год. Всего значение занимает 64 бита, что аккуратно укладывается в тип bigint Postgres (и соответственно ровно в два раза короче чем UUID). При желании вместо Btree вы можете использовать компактные BRIN индексы. В общем, здесь технические причины сделать именно так сделали, мне предельно ясны. Парни явно не собираются хранить картинки вечность, учитывают особенности своей СУБД и прагматично относятся к требованиям по железу.
Uuidv7 отводит для unix time слот в 8925 лет. Пытаюсь представить какое тут может быть практическое применение (неужели считать миллисекунды со дня просветления Будды)? Иначе это лишние деньги на
ветержелезо.Метаданные (как номер версии) удобны для обмена информацией в части протоколов. Но зачем их физически-то таскать в каждом значении? Не, я прекрасно понимаю почему их убрали из ULID, который делали с оглядкой на базы и обмен данными, освободив место для чего-то более осмысленного (снижающего вероятность коллизий, например). Вернуть обратно в UUIDv6(7,8), чтобы была возможность отличать один стандарт от другого, потому что кому-то хочется периодически выпускать новые RFC? Извините, платить за дополнительное железо ради такой прихоти нет ни какого желания.
В целом сложилось впечатление, что uuidv7 фокусируется больше на эстетической составляющей, отбросив многие технологические моменты своих прототипов. Получилось нечто совсем не свежее и с диким оверхедом. С другой стороны, это пока только draft и может быть все ещё переделают.



powerman
04.04.2022 01:11+1Честно говоря, не понимаю, зачем нужен этот стандарт. Есть же ULID, и он более чем хорош. Недостатком ULID указано "26 character Base32 can contain 130 bits where this UUID is 128 resulting in a potential decode error on a base32 string" - но, простите, это же бред (а ещё в строке могли использовать символы вне Base32, а ещё их может быть не 26… и, кстати, в UUID ровно та же проблема) и типичный NIH-синдром с выискиванием фатальных недостатков.
Какие реальные проблемы решает новый стандарт, которые не решены в ULID?
edo1h
04.04.2022 01:56+2- uild использует рандомные биты там, где в uuid из rfc 4122 находятся вариант/версия, в результате по идентификатору нельзя определить это uuid или ulid.
например, в ms sql применён хак для сортировки uuid, который не надо применять к ulid (тот уже сортируемый):
https://stackoverflow.com/questions/7810602/sql-server-guid-sort-algorithm-why - алгоритм генерации ulid в случае генерации более одного идентификатора в микросекунду даёт детерминированный результат, в некоторых случаях это может быть дополнительным вектором атаки;
- ulid — не rfc стандарт )
powerman
04.04.2022 10:24+1Это ведь отличие, а не проблема/недостаток, верно?
Он даёт монотонно возрастающий результат а не детерменированный - он добавляет случайное значение в заданном пользователем интервале: https://pkg.go.dev/github.com/oklog/ulid#Monotonic. По умолчанию данный интервал это 32 бита, так что на уязвимость это никак не тянет.
Смешно. И, кстати, поддержка ULID для разных БД уже есть.
Так что я возвращаюсь к своему изначальному вопросу: какие именно реальные проблемы есть в ULID, которые решает новый стандарт?
SergeyProkhorenko Автор
04.04.2022 11:45+7Вопрос правильный. Именно ULID'ы были основой для разработки стандарта в последние месяцы. Претензии к ULID следующие:
Это не стандарт (боятся использовать, и нет защиты соответствующих инвестиций)
На самом деле нет поддержки со стороны вендоров СУБД. Например, компания Postgres Professional давно знает, но не стала поддерживать ULID'ы
Раздел спецификации Monotonicity не является обязательным и не поддерживается со стороны разработчиков библиотек, за небольшим исключением
При использовании раздела спецификации Monotonicity:
легко угадать все близкие ULID в течение той же миллисекунды, что может быть небезопасным (реализация oklog частично решает эту проблему путем отступления от спецификации)
соседние ULID различаются лишь последними разрядами, что делает двоичный поиск UUID по старшим битам долгим
нет средств предотвращения переполнения счетчика при неудачной инициализации очень большим случайным значением
При наступлении дополнительной секунды риск переполнения счетчика возрастает ровно в 1000 раз
Не предусмотрено объединение ULID с метаданными (длинный идентификатор)
powerman
04.04.2022 12:50+1Наконец-то нормальный ответ, спасибо!
Давайте не будем. Полно RFC, которые на практике нарушаются, и полно "не стандартов", которые активно используются (в т.ч. ULID). Усилия, которые были потрачены на разработку и пропихивание UUIDv7 как RFC можно было заметно сэкономить, пропихивая в RFC ULID, если нужно было именно получить RFC.
Есть сторонние расширения. И для UUIDv7 тоже нет поддержки вендоров. (А если Вы скажете "пока нет" - так и для ULID так можно сказать.)
Обеспечить 100% гарантию монотонности и непредсказуемости (зная предыдущее значение) для неопределённого количества генерируемых в одну ms значений в рамках фиксированного количества бит - физически невозможно. Иными словами, тут обязательно будут какие-то trade-off. И вариант "не обеспечивать монотонность" в рамках ms - вполне приемлемый trade-off для многих приложений. Так что опциональность этой фичи, на мой взгляд, это достоинство, а не недостаток.
1. В целом - согласен. Но есть нюансы. Во-первых, данное отступление от спецификации - не является нарушением спецификации. Во-вторых, его можно внести в спецификацию, и это изменение даже будет обратно-совместимым. В общем, проблема есть, но она не критичная и решаемая, причём на уровне реализаций, без необходимости менять спеку.
2. В теории - всё верно. На практике - очень сомневаюсь, что это окажет сколь-либо заметное влияние на производительность БД. Кто-то проводит соответствующие бенчмарки, можно увидеть их результаты?
3. Во-первых, в ULID такое средство есть: в спеке чётко сказано, что при переполнении генерация ULID должна провалиться. Во-вторых, в UUIDv7 этих средств вообще нет - при генерировании чуть менее 17 млн. значений в одну ms случится переполнение, и я не увидел в спеке что в этой ситуации должно произойти.А точно не в 2 раза, а в 1000? И разве UUIDv7 в этом плане чем-то отличается?
Метаданные - в принципе странная фича, совершенно точно не являющаяся обязательной для уникальных ID, так что её отсутствие именно в спеке (ведь никто не мешает передать метаданные отдельно от любого ID, включая ULID) сложно считать недостатком.
Итого, резюмируя:
Недостаток "стандартизация и вендоры" проще и адекватнее решать пропихиванием одного из существующих решений, а не изобретением нового. Так что это не является ни недостатком ULID, ни достоинством UUIDv7. Это просто NIH-синдром - пропихивать собственное решение интереснее, чем чужое - это психологически понятно, но нельзя это всерьёз записывать в достоинства одному и недостатки другому.
Другой подход к реализации монотонности в UUIDv7 - не выглядит объективно лучшим или решающим какие-либо реальные проблемы. Он просто другой, вполне приемлемый. Т.е. снова NIH-синдром.
В UUIDv7 есть уникальная фича "метаданные". Довольно сомнительная, мягко говоря, и совершенно точно не оправдывающая создание нового стандарта.
Что я упустил?
SergeyProkhorenko Автор
04.04.2022 22:38+24.3 в UUIDv7 этих средств вообще нет - при генерировании чуть менее 17 млн. значений в одну ms случится переполнение, и я не увидел в спеке что в этой ситуации должно произойти.
Стандарт допускает достаточно большое удлинение счетчика (вплоть до 42 бит) за счет псевдо-случайного сегмента, чтобы заведомо избежать переполнения счетчика при любых мыслимых технологиях. Ценой удлинения счетчика будет более низкая скорость поиска записей.
Если счетчик неудачно инициализируется единицами в старших разрядах, то всё равно самый старший бит счетчика всегда инициализируется нулем. Это означает, что по меньшей мере половина счетчика всегда свободна при его инициализации в начале миллисекунды.
Если всё же произойдет переполнение счетчика, то стандарт рекомендует тем, кому нужна монотонность любой ценой, приостановить генерацию UUID и ждать следующей миллисекунды. Стандарт не требует этого ото всех. Моя точка зрения, что приостановка генерации UUID чревата крахом приложения, и нужно пренебречь абсолютной монотонностью, заморозить счетчик и продолжать генерировать уникальные, но не возрастающие UUID. Современные СУБД на это отреагируют лишь небольшим снижением скорости поиска некоторых записей.
5. А точно не в 2 раза, а в 1000? И разве UUIDv7 в этом плане чем-то отличается?
Когда возникает дополнительная секунда, таймстемп замораживается (ведь в минуте не может быть 61-ой секунды, и минута не может повториться), и счетчик, рассчитанный на 1 миллисекунду, вынужден заполняться 1 секунду, то есть, ровно в 1000 раз дольше.
Стандарт требует, чтобы дополнительные секунды не прибавлялись. Это означает, что ни одна формальная секунда (UTC) не будет длиться две фактических секунды, и счетчик не будет работать с экстремальной нагрузкой.
------------------------------------------------
Ваша обида понятна. Я тоже прилагал безуспешные усилия, чтобы ULID'ы появились в PostgreSQL. Время показало, что этот путь не приведет к успеху. ULID'ы так и не стали мейнстримом, как бы этого не хотелось. Что-то не хватило влиятельных желающих "пропихнуть" их в широкое использование. Поэтому было грех не воспользоваться статусом стандарта. Я убежден, что усилия по разработке стандарта были полезны.
powerman
04.04.2022 22:55+1Да нет никакой обиды. Мне не нравится UUID по двум причинам: чисто эстетически, и потому, что "на глаз" фиг отличишь какой он там версии, а версий неудачных было слишком уж много, поэтому когда клиенты будут присылать UUID намного сложнее полагаться на то, что клиент не использовал одну из неудачных версий, штатные валидаторы обычно пропускают любой UUID… и в результате либо надо городить дополнительные проверки на его версию, либо ждать проблем. В результате совместимость нового формата с UUID для меня звучит как серьёзный недостаток, который должен чем-то весомым компенсироваться… а каких-либо реальных преимуществ пока не видно.
В любом случае, большое спасибо за развёрнутые ответы. Я лично продолжу продвигать ULID, а если будет требование работать с UUID - ну, значит придётся ручками проверять что это v4 или v7, в зависимости от требований к монотонности.
andreymal
04.04.2022 23:05+3"на глаз" фиг отличишь какой он там версии
Справедливости ради, первая циферка в третьей группе символов однозначно определяет версию. Это не очень удобно, но выучить и отличать версии «на глаз» всё-таки реально
20f2cf91-7945-42c6-96f4-0444cc9e91d4
017ff62c-7500-70e6-8f41-f5154d136d02
edo1h
05.04.2022 01:04+2если будет требование работать с UUID — ну, значит придётся ручками проверять что это v4 или v7,
интересно, какой это use case? обычно использование всех вариаций uuid предполагает, что нам неинтересно что там внутри.
powerman
05.04.2022 01:26Это очень простой use case: хочется решить ту архитектурную проблему, из-за которой вообще понадобилось что-то вроде UUID, и не хочется при этом получить проблемы, которыми славятся все остальные версии UUID.
нам неинтересно что там внутри
К сожалению, многие абстракции "протекают", и эта - не исключение. Да, в теории оно должно "просто работать", и нам не должно быть интересно, что там внутри. Но на практике нам это очень даже интересно - потому что оно отказывается "просто работать" и так и норовит подкинуть неожиданных проблем.
edo1h
05.04.2022 01:46+2ну так всё-таки расскажите в каких случаях приложению требуется анализировать содержимое uuid
powerman
05.04.2022 02:24Это что, просьба LMGTFY? Почитайте хотя бы статью в русской вики, там всё неплохо описано.
edo1h
05.04.2022 02:27+1нет, это вопрос именно к вам: в какой задаче вам потребовалось различать разные варианты uuid
powerman
05.04.2022 02:45+1А, понял. Всё просто: когда мне нужен уникальный ID, генерируемый клиентами, и я начинаю искать подходящий для этой цели формат, мне нужно только это - уникальный ID, без каких-либо дополнительных проблем "в нагрузку".
Мне не нужны коллизии из-за слишком маленькой случайной части или некорректно реализованных библиотек на клиентах, мне не нужны утечки приватных данных клиентов, и мне даже не хочется задумываться о том, какие ещё могут быть проблемы если клиент использует ту версию UUID, которую даже сам RFC не рекомендует использовать "в качестве учетных данных для безопасности" (и нет, мне не хочется в каждом месте где используется UUID задумываться: "а не используется ли этот UUID в качестве учетных данных для безопасности").
Мне, помимо уникальности, может быть нужна ещё какая-то дополнительная фича, вроде монотонности. И ради фичи я готов думать о том, какой формат её обеспечивает, а какой нет. А вот задумываться о том, грозят ли мне чем-то известные недостатки UUID разных версий в каждом месте каждого проекта, или конкретно здесь обойдётся - нет ни малейшего желания.
Иными словами, различать разные версии необходимо для того, чтобы не нарваться на неприятности и даже не тратить силы пытаясь понять, могут ли в принципе случиться эти неприятности конкретно с этой версией UUID конкретно в этом месте данного проекта.
edo1h
05.04.2022 06:11+1Мне не нужны коллизии из-за слишком маленькой случайной части или некорректно реализованных библиотек на клиентах, мне не нужны утечки приватных данных клиентов, и мне даже не хочется задумываться о том, какие ещё могут быть проблемы если клиент использует ту версию UUID, которую даже сам RFC не рекомендует использовать "в качестве учетных данных для безопасности" (и нет, мне не хочется в каждом месте где используется UUID задумываться: "а не используется ли этот UUID в качестве учетных данных для безопасности").
понял про что вы.
но как ULID вас защитит от «некорректно реализованных библиотек на клиентах»?
и если вы постулируете использование UUID v7, то использование другой стороной иной версии UUID будет уже не на вашей совести )
SergeyProkhorenko Автор
05.04.2022 23:27Что же это за архитектура информационной системы, в которой клиенты могут прислать что угодно? Какой дистрибутив дали пользователям, пусть тем и пользуются. И в этом дистрибутиве должен быть жестко зашит генератор UUID. В противном случае могут прислать какую-нибудь ерунду без уникальности и монотонности, сгенерированную самопальным генератором, но семерка будет стоять, где положено по спецификации.
Если пользователям дозволено самим выбирать или мастерить генератор UUID, то, конечно, придется для "защиты от дурака" караулить UUID устаревших форматов, проверять полученные UUID на монотонность, лезть в их "потроха" и т.д. Но это неверный путь. Чем меньше "велосипедов", тем лучше. В идеале UUID должны генериться системным софтом (ОС, СУБД, браузер, брокер сообщений) и даже аппаратно.
powerman
06.04.2022 17:14Что же это за архитектура информационной системы, в которой клиенты могут прислать что угодно?
Клиент-серверная? :)
В противном случае могут прислать какую-нибудь ерунду без уникальности и монотонности, сгенерированную самопальным генератором, но семерка будет стоять, где положено по спецификации.
Могут, но это разные вещи - налажать нечаянно из-за недостаточной квалификации или внимательности, и специально отправлять некорректные данные с какой-то целью. Разные риски, разные последствия, разные методы противодействия.
Валидация версии UUID направлена против первой категории, и она вполне полезна в этом качестве, потому что лажи кругом намного больше, чем настолько целевых атак хакеров.
В идеале UUID должны
Но мы-то живём не в идеале.
andreymal
05.04.2022 02:31+2Лично я писал статью на русской вики (точнее, переводил с английской), но тоже не понимаю, зачем что-то анализировать
edo1h
05.04.2022 06:02+1потому, что "на глаз" фиг отличишь какой он там версии
а, дошло, вы про то, что ULID штатно использует Crockford's base32 и совсем не похож на каноническую запись UUID?
ну так если храним ULID в БД не в текстовом, а в бинарном представлении (uuid в postgresql или uniqueidentifier в ms sql), то это различие теряется.
и да, в следующую версию стандарта хотят добавить base32 и для UUID, так что ожидайте UUID v4 в base32 )))Он даёт монотонно возрастающий результат а не детерменированный — он добавляет случайное значение в заданном пользователем интервале
в стандарте такого нет
поэтому когда клиенты будут присылать UUID намного сложнее полагаться на то, что клиент не использовал одну из неудачных версий
ну ровно так же вы не проверите, что клиент не использовал реализацию ULID без рандомизации идентификаторов внутри миллисекунды.
более того, вариант/версия UUID как раз хранятся в самом идентификаторе, так что при желании вы можете не принимать какой-нибудь UUID v1 (я не говорю, что мне нравится эта идея, но вы первый начали проверку использования клиентами неудачных версий)
- uild использует рандомные биты там, где в uuid из rfc 4122 находятся вариант/версия, в результате по идентификатору нельзя определить это uuid или ulid.

demoth
04.04.2022 01:31По свойствам похоже на xid
edo1h
04.04.2022 02:04+1While preparing this specification the following 16 different implementations were analyzed for trends in total ID length, bit Layout, lexical formatting/encoding, timestamp type, timestamp format, timestamp accuracy, node format/components, collision handling and multi-timestamp tick generation sequencing.
- [ULID] by A. Feerasta
- [LexicalUUID] by Twitter
- [Snowflake] by Twitter
- [Flake] by Boundary
- [ShardingID] by Instagram
- [KSUID] by Segment
- [Elasticflake] by P. Pearcy
- [FlakeID] by T. Pawlak
- [Sonyflake] by Sony
- [orderedUuid] by IT. Cabrera
- [COMBGUID] by R. Tallent
- [SID] by A. Chilton
- [pushID] by Google
- [XID] by O. Poitrey
- [ObjectID] by MongoDB
- [CUID] by E. Elliott
demoth
04.04.2022 02:33+1Прям каждая компания под свои нужды придумала свой uid. Вероятно, UUIDv7 тут вряд ли что-то изменит, как минимум из-за длины.
edo1h
04.04.2022 02:40+1так длина та же самая, что и у остальных вариантов uuid из rfc 4122.
основная цель нового стандарта — базы данных, и тут новый uuid v7 можно применять без изменения структуры.

MentalBlood
04.04.2022 10:15
edo1h
05.04.2022 01:04да, разумеется. но, всё-таки, у стандартов, получивших номер rfc, шансов больше.


ivankudryavtsev
04.04.2022 08:09+3В RocksDB и прочих embedded kv uuid7 хорошо подходит для итерирования по времени возрастания/убывания записей. Еще на этапе draft-а пробовал, отлично решает свои задачи. Думаю, что в C* и прочих масштабируемых БД тоже найдет свое применение.
edo1h
05.04.2022 01:08+2я писал много раз, мне не нравится подобное использование uuid.
содержимое uuid — внутреннее дело генератора, пользователь не должен полагаться на какие-то свойства идентификатора помимо длины и уникальности.цель нового стандарта — решить проблему с неоптимальностью индексирования/партицирования по uuid (отсутствие локальности — сгенерированные последовательно значения оказываются разбросаны по случайным областям), а не заменить собой timestamp.
demon416nds
48 бит на время
Им проблем unixtime мало?
edo1h
так ничего страшного при переполнении не произойдёт же.
funca
Если не ошибаюсь, (2^48−1)÷(1000×60×60×24×365) это примерно 8925 лет с 1970. Потомки в 10895 году будут нас немножко ненавидеть (если не придумают раньше какой-нибудь новый стандарт или не перезагрузят цивилизацию).
edo1h
а с чего они будут ненавидеть-то?
основные цели нового стандарта UUID: уникальность и локальность (чтобы эффективно работали b-tree индексы или партицирование).
первое обеспечивается случайной частью, второе — таймстампом в начале.
переполнение не мешает ни тому, ни другому.
да, использовать UUID для сравнения дат (больше-меньше) не получится, но я считаю такое использование плохой идеей: стандартов формирования UUID больше одного, лучше не полагаться на «кишки» любого UUID.
я наоборот предлагал урезать временной период до переполнения чтобы снизить вероятность коллизий за счёт увеличения количества изменяемых бит — или случайных (расширить ширину случайного поля), или псевдослучайных (увеличить точность таймстампа).
в [почти] принятом же стандарте старшие 4 бита будут равны нулю больше 400 лет