
В релизе PVS-Studio 7.18 утилита мониторинга компиляции для Windows получила новый механизм, который позволяет полностью устранить пропуски запусков компиляторов. В этой статье мы напомним, как наш анализатор справляется с разнообразными системами сборки и расскажем о реализации нового режима Wrap Compilers.

Введение
Исторически сложилось, что для разработки на языках C и C++ существует большое разнообразие систем сборки и компиляторов. С точки зрения статического анализатора целесообразно уделять основное внимание наиболее распространённым инструментам разработки. Это позволяет обеспечить наибольшее удобство использования основному кругу разработчиков.
Однако нельзя забывать про значительное количество программистов, пользующихся менее распространёнными наборами инструментов. Эти наборы могут включать специализированные компиляторы и тулчейны, среды для разработки и отладки Embedded систем.
Многие подобные инструменты не предоставляют возможности расширения своего функционала за счёт сторонних компонентов. Для других инструментов прямая интеграция анализатора потребует слишком больших затрат. Что же мы можем в этом случае предпринять?
В арсенале PVS-Studio для сбора необходимой для анализа информации есть механизмы отслеживания процесса компиляции. Эта своеобразная серебряная пуля позволяет взаимодействовать с широким (а потенциально любым) набором разных инструментов сборки проекта.
В зависимости от предоставляемых операционной системой средств мы различаем два подхода для отслеживания компиляции: трассировка сборки под Linux и мониторинг компиляции под Windows. При использовании механизма мониторинга утилиты CLMonitor под Windows пользователи могли сталкиваться с проблемой: анализатор временами пропускал случайные файлы исходников.
В этой статье вы узнаете, за счёт чего работают утилиты отслеживания компиляции, в чём причина пропусков компилируемых файлов под Windows и как удалось с этим справиться. Но сначала объясню, зачем нам вообще нужно собирать какую-то "необходимую для анализа информацию".
Почему нельзя просто взять и проанализировать файл с кодом
Итак, что должен сделать C или C++ анализатор, когда вы запускаете его на своем проекте? Ответ на этот вопрос поможет обозначить проблемы, с которыми мы сталкиваемся, и поговорить об их решении.
Попробуем проанализировать исходный код простого файла main.cpp:
#include <iostream>
int main()
{
std::cout << "Analyze me!";
}Что нам из него понятно?
Ну, есть функция main(), в теле которой вызывается оператор '<<'. Там есть строковый литерал и точка с запятой.
А что такое std::cout, и почему к нему вообще можно применить оператор сдвига, в который ещё и строка запихивается?
Разумеется, все эти детали должны быть где-то объявлены, а ещё лучше – определены.
Почти любой C++ программист знает, что объявления std::cout и всего прочего появятся после так называемого препроцессирования. В результате препроцессирования происходит рекурсивное включение заголовочных файлов, указанных директивой #include. Без препроцессирования, после которого будут видны необходимые определения в единице трансляции, анализировать в общем-то нечего. Разве что можно написать линтер "на регулярках", который на самом деле не понимает, как работает анализируемый код.
Получается, что анализатор должен "просто" сам сделать препроцессирование.
Читаем стандарт про 1-6 фазы трансляции и реализуем свой препроцессор. Запускаем… а он не может работать ни с одной сборочной системой! Проблемы можно перечислять, начиная с того, что непонятно, откуда нам взять заголовочный файл <iostream>.
Когда вы устанавливаете свой любимый компилятор, с ним обычно поставляется реализация стандартной библиотеки. И компилятор будет в курсе, где ему нужно искать файлы от своей библиотеки. А анализатору придется каждый раз указывать пути к директориям с включаемыми файлами.
Ещё на результат работы препроцессора влияют встроенные или установленные сборочной системой определения препроцессора. Они в свою очередь могут управлять условной компиляцией (директивы #if, #ifdef и т. д.), которая решает, какой код будет компилироваться, а какой надо вырезать в зависимости от:
- платформы;
- конфигурации сборки;
- любых других причин.
Настройки, управляющие компилятором, передаются от сборочной системы через параметры командной строки, или флажки запуска, или так называемый response-файл. При этом никаким стандартом не определено, что это за флажки. Системы сборки просто рассчитаны на передачу параметров с заранее известными форматами.
Возникает засада: чтобы обработать какой-нибудь произвольно взятый исходник, необходимо сделать суперпрепроцессор, который будет:
- уметь прикидываться родным препроцессором для любой сборочной системы;
- знать, где лежат нужные включаемые файлы;
- понимать любые аргументы и уметь выполнять нестандартные (и недокументированные) функции всех известных (и не очень) препроцессоров.
Как же анализатор может выполнить все эти требования? Разумеется, никак. По крайней мере сам.
Хитрость заключается в том, чтобы узнать у сборочной системы команду компиляции исходного файла. Затем нужно вызвать компилятор так же, но добавив пару настроек, которые вежливо попросят его сделать препроцессирование за нас. Выходит, мы можем не делать свой препроцессор, а использовать для этой цели действующий компилятор, который сам разберётся, что делать с исходником.
Получается, дело за малым? Чтобы точно повторить запуск компилятора для препроцессирования, нужно:
- извлечь путь до исполняемого файла компилятора;
- узнать аргументы командной строки запуска;
- сохранить исходную рабочую директорию;
- сохранить переменные окружения.
Рассмотрим варианты, которыми можно было бы это осуществить.
Как (не) получить команды компиляции
Итак, нам нужно узнать, с какими параметрами сборочная система запускает компиляторы. Самым прямолинейным вариантом будет просто взять и разобрать файлы сборочной системы, хранящие информацию о структуре и сборке проекта.
Так, например, работает PVS-Studio для Visual Studio. В этом случае нам везёт, так как задача разбора проектных .sln и .vcxproj файлов ложится на плечи сборки Microsoft.Build (классы SolutionFile и Project). На вход им подаётся файл решения/проекта. На выходе мы получаем список команд компиляции, которые можно передать анализатору.
Это один из первых подходов, который использовался в PVS-Studio. Он хорошо работает с Visual Studio и покрывает нужды подавляющего большинства пользователей.
К сожалению, достаточно сложно напрямую разобраться с любой произвольно выбранной системой сборки:
- придётся самим поддержать огромный зоопарк разных форматов проектных файлов;
- по ним может вообще не быть никаких спецификаций или часть информации окажется не задокументированной;
- детали реализации могут меняться от версии к версии сборочной системы;
- некоторые инструменты в принципе сложно достать для тестирования по тем или иным причинам.
Представьте себе, что нужно сделать CMake наоборот. Чтобы он из кучи разных форматов генерировал какой-то свой общий, через который можно будет управлять анализатором.
Проблема поддержки разнообразных сборочных систем была особенно актуальна при разработке анализатора под Linux. На этой системе программисты часто применяют кучу разных инструментов для разработки и сборки своих проектов. Да и определение структуры проектов может быть весьма условным. Например, makefile содержит скрипт на собственном языке, который должен просто "делать" какие-то команды. Зачастую без непосредственного выполнения сборки невозможно даже сразу определить файлы исходного кода для анализа. Расположение части файлов может находиться при помощи сторонних утилит. Какие-то файлы могут изначально не существовать, а генерироваться по шаблонам в процессе сборки. Такое себе "препроцессирование высшего порядка".
В общем, играть в кошки-мышки со сборочными системами – занятие весьма неблагодарное.
Мониторинг и трассировка
Так же, как и с препроцессированием, получается, что самым универсальным способом взаимодействия со сборочной системой будет полное абстрагирование от неё. Зачем разбираться со всеми возможными обёртками над сборкой проекта, если нужно узнать только конкретные команды компиляции? Хочется просто спросить у операционной системы, какие процессы она стартует, и отфильтровать только информацию о запусках компиляторов.
В случае с Linux этого можно достичь при помощи утилиты strace. Когда пользователь по гайду запускает подготовку к анализу через 'pvs-studio-analyzer trace — cmd_to_build_your_project', происходит вызов утилиты strace с необходимым набором опций. Затем strace вызывает 'cmd_to_build_your_project' и записывает в файл все системные вызовы, связанные с запусками порождаемых процессов. При помощи этого файла можно отследить иерархию процессов сборки проекта. Этот режим потому и называется трассировкой, поскольку собирает информацию последовательно, от запускающих процессов к запускаемым.
К сожалению, под Windows утилиты strace нет, а адекватный аналог найти не удалось. Пришлось сделать приложение CLMonitor, которое на основе вызовов WinAPI будет подобно диспетчеру задач "мониторить" список запущенных процессов и пытаться извлечь из них нужную информацию. Выглядит как набор грязных хаков, но работает :)
В целом запуски компиляторов перехватываются и PVS-Studio собирает нужную информацию. Однако в системе есть критический недостаток. Режим мониторинга слишком пассивен, что приводит к пропускам по следующим причинам:
- если процесс запустился и завершился достаточно быстро, цикл опроса запущенных приложений может не уследить за его запуском;
- если процесс удалось отследить, не факт, что удастся успеть собрать информацию о нём до его завершения;
- когда параметры запуска передаются не через командную строку, а через специальный временный response-файл, этот файл может быть удалён быстрее, чем до него доберется монитор и команда запуска окажется бесполезной.
Особенно эти косяки заметны на быстро собирающихся проектах, например, написанных на C для Embedded. На тестовом проекте из 10000 пустых единиц трансляции на моём рабочем компьютере количество пропусков доходило до 60%!
Gotta Catch 'Em All
Время от времени решить эту проблему пытались, пробуя разные подходы, но не особо успешно.
Например, используя механизм событий Event Tracing for Windows (ETW), система и разные приложения могут обмениваться сообщениями. Провайдеры могут создавать события с данными, которые обрабатываются потребителями. Логично было бы предположить, что можно найти события, содержащие нужную нам информацию.
Список зарегистрированных провайдеров можно узнать командой PowerShell:
Get-WinEvent -ListProvider * | select nameПровайдеров много, и вероятно, кто-то может посылать нам события о запуске процессов. Например, Microsoft-Windows-Kernel-Process. Этот провайдер действительно выдаёт события о запуске процессов с путём к исполняемому файлу, идентификатором созданного процесса (PID), PID родителя. Но командной строки и рабочей директории в этом типе события нет:
<Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="Microsoft-Windows-Kernel-Process" Guid="{....}"
/>
....
</System>
<EventData>
<Data Name="ProcessID"> 7520</Data>
<Data Name="ProcessSequenceNumber">296913</Data>
<Data Name="CreateTime">2022-03-29T07:06:53.228244700Z</Data>
<Data Name="ParentProcessID"> 10252</Data>
<Data Name="ParentProcessSequenceNumber">296903</Data>
<Data Name="ImageName">....\Windows\System32\notepad.exe</Data>
</EventData>
<RenderingInfo Culture="en-US">
<Level>Information </Level>
<Opcode>Start </Opcode>
<Keywords>
<Keyword>WINEVENT_KEYWORD_PROCESS</Keyword>
</Keywords>
<Task>ProcessStart</Task>
<Message>Process 7520 started at time ....</Message>
<Channel>Microsoft-Windows-Kernel-Process/Analytic</Channel>
<Provider>Microsoft-Windows-Kernel-Process </Provider>
</RenderingInfo>
</Event>Поскольку найти "нормальные" способы собрать нужную информацию не удалось, приходится изобретать свои велосипеды. Например, можно было бы запускать исходный сборочный процесс с DLL-инъекцией, которая бы проксировала вызовы CreateProcess, сохраняла нужную информацию и запускала потомков с такой же инъекцией. Получился бы аналог режима трассировки под Linux. Может, когда-нибудь попробуем так сделать.
Воспользоваться внешней утилитой сбора событий вроде Process Monitor может не позволить лицензия, и это не решает проблемы с response-файлами.
Один из моих коллег разрабатывал драйвер уровня ядра для перехвата запуска процессов. Например, так делают многие игровые античиты, чтобы определять подозрительную активность в системе и мешать отладке и реверсингу игрового процесса. Наработки в прод не пошли, так как опыта в поддержке таких решений у компании нет, и вообще слишком ЖОСКА. Кроме того, ошибки в системном драйвере могут привести к известным проблемам: от нестабильной работы системы до уязвимостей. Например, эксплуатируя слабости драйвера, можно добиться выполнения произвольного кода с повышенными правами, как это было с Capcom.sys.
Ещё один коллега недавно поделился информацией о другой не особо документированной, но интересной штуке – Image File Execution Options (IFEO). Она впоследствии и позволила успешно реализовать надежный перехват запуска процессов.
В реестре Windows есть путь 'HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options\', в который можно добавить новый ключ с именем некоторого исполняемого файла, скажем 'calc.exe'. Теперь, если в этом ключе создать строковое поле 'Debugger' со значением 'notepad.exe', при запуске калькулятора вместо него откроется окно Блокнота с текстом двоичного исполняемого файла калькулятора. Довольно интересное поведение.
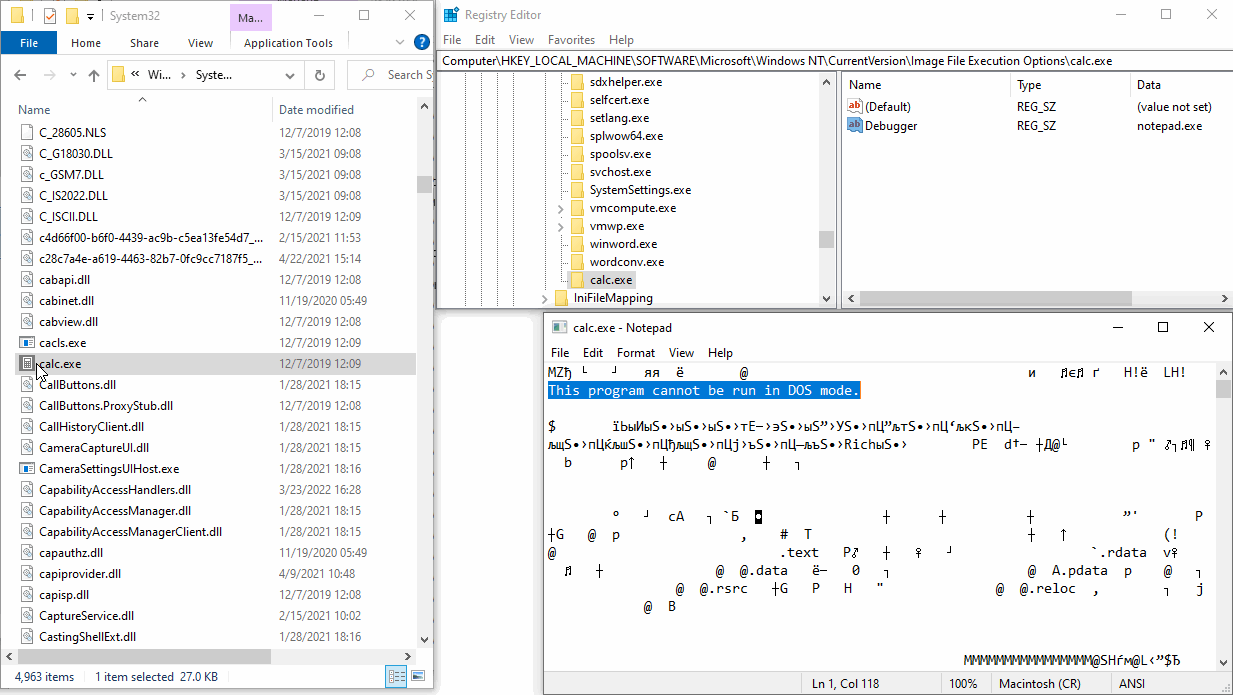
Получается, что вместо запуска одной программы, мы можем запустить совершенно другую, передав ей строку запуска исходной программы. То есть вместо вызова следующей команды:
OriginalExecutable.exe --original-argumentsБудет вызвана команда:
MyProxyExecutable.exe OriginalExecutable.exe --original-argumentsРежим Wrap Compilers
Используя описанный механизм, можно сделать специальную программу-обёртку, которая сможет запуститься сборочной системой вместо её родного компилятора. При этом такой трюк будет полностью прозрачен для процесса сборки. Обёртка будет иметь требуемое окружение, рабочую директорию и список аргументов запуска. То, что нам и надо.
После успешного внедрения в процесс сборки мы сами вольны решать, что делать дальше. Можно неспеша (в пределах разумного) связаться с некоторым сервером-арбитром, который аккумулирует информацию об отдельных запусках компиляции, а также прочитать созданные response-файлы. Чтобы не сломать дальнейший процесс сборки, стоит всё же самим запустить процесс компилятора с исходными параметрами. При этом нужно перебросить потоки ввода-вывода, чтобы работало отображение предупреждений и ошибок компиляции, и вернуть полученный по завершению код возврата.
Чтобы включить новый механизм перехвата, нужно при запуске сервера CLMonitor в режиме 'trace' или 'monitor' передать флаг '--wrapCompilers' со списком отслеживаемых компиляторов:
CLMonitor.exe trace --wrapCompilers cl.exeВ графическом интерфейсе появилось дополнительное поле для указания компиляторов:
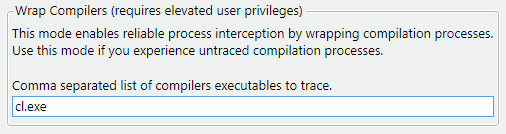
Далее в реестре Windows для заданных компиляторов зарегистрируются обёртки, которые внедрятся в дерево процессов сборки и начнут передавать информацию серверу.
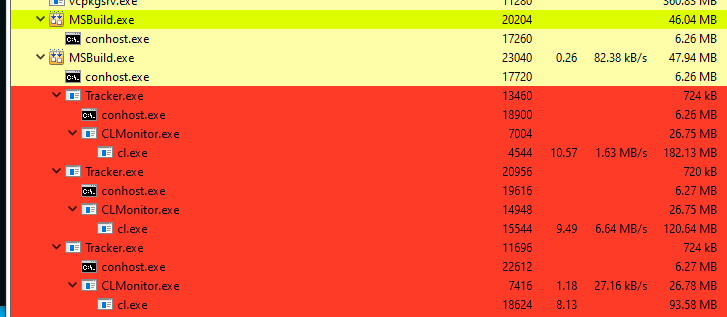
После завершения сборки и остановки сервера реестр вернётся в исходное состояние и начнется анализ отслеженных файлов. Всё идет по плану.
Детали реализации обёртки
Есть один интересный подводный камень. Если запущенное через IFEO приложение-дебаггер напрямую запустит процесс, к которому оно было прикреплено, то вместо запуска требуемого процесса запустится ещё одна обёртка. Затем эта обёртка запустит ещё одну… и так рекурсивно. Чтобы этого избежать, обёртка должна отключить запуск дебаггера на порождаемом процессе. Это делается при помощи обращений к WinAPI. У нас оно импортировано в класс Native. Определения нужных структур и функций можно взять из PInvoke.net.
Ниже приведу фрагмент кода на C#, который запускает процесс. Обработка ошибок вырезана для краткости.
static uint StartWrappedProcess(string commandLine)
{
// Выставляем запускаемому процессу текущие потоки ввода/вывода,
// чтобы он мог взаимодействовать с родительским процессом
var sInfo = new Native.STARTUPINFO();
sInfo.hStdInput = Native.GetStdHandle(Native.STD_INPUT_HANDLE);
sInfo.hStdOutput = Native.GetStdHandle(Native.STD_OUTPUT_HANDLE);
sInfo.hStdError = Native.GetStdHandle(Native.STD_ERROR_HANDLE);
// Пара нужных структур для старта процесса через CreateProcess
var pSec = new Native.SECURITY_ATTRIBUTES();
pSec.nLength = Marshal.SizeOf(pSec);
var tSec = new Native.SECURITY_ATTRIBUTES();
tSec.nLength = Marshal.SizeOf(tSec);
var pInfo = new Native.PROCESS_INFORMATION();
// Создаём процесс
// Отключаем повторный вызов дебаггера, чтобы не уйти в рекурсию
var creationFlags = Native.CreateProcessFlags.DEBUG_ONLY_THIS_PROCESS;
Native.CreateProcess(null, commandLine, ref pSec, ref tSec,
true, (uint)creationFlags, IntPtr.Zero,
null, ref sInfo, out pInfo);
// Наша функция, которая соберет информацию о созданном процессе
var info = QueryProcessInfo((uint)pInfo.dwProcessId, 0);
// Передаём информацию о компиляторе серверу
var client = new IpcClient();
client.Start();
client.SendMessage(info);
client.Stop();
// Наконец запускаем процесс компилятора
Native.DebugActiveProcessStop((uint)pInfo.dwProcessId);
if (Native.WaitForSingleObject(pInfo.hProcess, Native.INFINITE)
!= Native.WAIT_OBJECT_0)
{
// Ой. Процесс завершился неожиданным образом.
}
Native.GetExitCodeProcess(pInfo.hProcess, out var pExitCode);
Native.CloseHandle(pInfo.hProcess);
Native.CloseHandle(pInfo.hThread);
return pExitCode;
}Насколько безопасен такой подход?
Поскольку для работы этого режима происходит редактирование реестра, запуск сервера приходится производить с правами администратора. Это не должно стать сюрпризом.
Возникает вопрос, как восстановить исходное состояние реестра, если сервер по каким-то причинам остановится нештатно?
CLMonitor, запущенный в новом режиме, создаёт файл 'wrapperBackup.reg' по пути '%AppData%/PVS-Studio'. Открыв этот файл редактором реестра, можно удалить добавленные монитором ключи или восстановить исходные значения полей, которые он изменил. К тому же, если при запуске монитор обнаружит этот файл, он применит его автоматически.
Файл восстановления реестра проверяется перед автоматическим применением. CLMonitor не будет его использовать, если найдёт записи, которые модифицируют что-то помимо ключей IFEO.
Режим Wrap Compilers возможно запустить только на известных анализатору исполняемых файлах компиляторов. Если в файле восстановления окажутся неизвестные программы, то он не будет использован для автоматического восстановления.
Такие меры нужны, поскольку если в поле 'Debugger' будет добавлен вызов некорректной программы, можно сломать запуск некоторых процессов. При этом будет весьма сложно определить причину, по которой перестала работать компиляция.
Если сервер не работает, а IFEO записи для запуска обёрток остались – обёртки просто продолжат выполнение переданных им процессов.
Заключение
Разнообразие средств разработки вынуждает искать общие подходы для работы с ними. Это, в свою очередь, приводит к своим особенностям и проблемам.
Механизм отслеживания компиляции – наиболее универсальный способ для сбора нужной анализатору информации. Теперь режим мониторинга стал гораздо надёжнее.
Если у вас есть другие идеи, как можно было бы реализовать такой механизм иначе (без написания драйвера), какие ещё неочевидности мы упустили из виду и т. д., мы открыты для предложений. Оставляйте свои комментарии.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Alexey Govorov. How PVS-Studio for Windows got new monitoring mode.
Комментарии (4)

tzlom
15.06.2022 00:11Раз что-то уже от рута работает, то оно может подключаться как отладчик к процессу, и по CreateProcess подключаться к дочерним процессам. Лучше чем хуки/инжекты т.к. официальный API и типа не троян.

MrROBUST Автор
15.06.2022 10:40Проблема в том, что монитор стоит в сторонке, и непосредственно сборкой не управляет. Только смотрит какие процессы компиляции запускаются.
Отсюда идут проблемы прошлой реализации. Можно не успеть подключиться к моменту старта сборки, пропустить часть порождённых процессов и упустить соответствующие исходные файлы.
В текущей схеме админские права не влияют на процесс отслеживания. Просто позволяют прописаться в реестр, чтобы поставить «барьер». Тогда стартующие процессы сами придут к нам в руки. Собственно последующая сборка выполняется от того пользователя, который её запустил. Без оглядки на сервер мониторинга.
Как сделать свой отладчик для трассировки порожденных процессов я пока не разбирался. Это конечно может помочь в будущем сделать трассировщик. Но в нём хочется обойтись без повышенных прав, и грубых манипуляций со сборочной системой (типа подмены бинарников компилятора), и лишних действий со стороны пользователя.

xi-tauw
Я понимаю, что мой опыт вряд ли обобщаем до автоматизации, но все же поделюсь своим подходом.
Если мне нужно проанализировать большой проект под линукс, то я начинал с создания автономного стенда для проекта, который бы позволял собирать исходники (благо, чаще всего такой стенд могли предоставить разработчики продукта). Дальше просто по стандартным этапам:
1) Разведка. Ищем все возможные компиляторы в системе. Нередко разработчики пользуются chroot'ом, так что слоям данных внутри chroot'а отдельные поиски.
2) Сбор первоначальной информации. Пишется простейший прокси-компилятор, которые собирает информацию о том как его вызвали (грубо говоря, argc, argv, envp) в файл и вызывает бинарник с приписанным к имени -orig. Дальше все настоящие компиляторы перемещались с этим самым дописанным -orig, а на их место помещался свеженаписанный прокси. Убеждаемся, что сборка проходит, получаем первую статистику о том, какие файлы и с какими параметрами компилируются.
3) Внедрение анализаторов. Дальше функциональность прокси-компилятора увеличивается - кроме вызова оригинального компилятора ему навешиваются задачи по вызову анализаторов. Решаются мелки типовые задачи: вызываем оригинальный gcc с расширенным набором проверок, но нужно убрать Werror, если есть, поменять имя выходного файла, чтобы он не мешал. Для вызова cppcheck нужно некоторые параметры переделать или убрать. Для scan-build'а тоже нужно правильно параметры передать. Для других анализаторов тоже свои мелкие доработки приходится делать.
4) Собираем результаты и уже вручную их разбираем.
Для Windows тоже делал подобное - подменял cl.exe на свой прокси, но там что-то не срасталось. В итоге пошел по пути dll hijack - подсовываю свою version.dll к cl.exe и в нем фильтрую чтобы убедится, что вызывают компилятор. Уже из библиотеки вызываются анализаторы.