

Автор статьи — Виктория Ляликова.
В данной статье хателось бы рассказать о том, как можно применить различные методы машинного обучения (ML) для обработки текста, чтобы можно было произвести его бинарную классифицию.
Рассмотрим задачу обработки естественного языка (NLP — Natural Lanuage Processing) на примере классификации психического здоровья для определения депрессии по комментариям в Reddit. Посмотрим на наш датасет:
import pandas as pd
data_depression = pd.read_csv('D:/vika/datasets/depression_dataset_reddit_cleaned.csv')
data_depression
Посмотрим, например, на какую-нибудь одну запись:
'sleep is my greatest and most comforting escape whenever i wake up these day the literal very first emotion i feel is just misery and reminding myself of all my problem i can t even have a single second to myself it s like waking up everyday is just welcoming yourself back to hell'.
Данный комментарий классифицируется как наличие депрессии у человека.
Далее посмотрим на гистограмму распределения.
import seaborn as sns
sns.countplot(data=data_depression, x="is_depression")
То есть можно увидеть, что в датасете количество комментариев соответствующих депрессии и ее отсутствию распределено приблизительно одинаково.Теперь приступим к обработке текста, чтобы его можно было применять в алгоритмах машинного обучения.
Сначала необходимо импортировать библиотеку NLTK, которая является ведущей для создания программ по обработке естественного языка на Python. И рассмотрим основные методы данного инструмента.
Также нам понадобится загрузить модуль RE, который является модулем по работе с регулярными выражениями и также помогает работать с текстом. Данный модуль позволяет производить поиск, замену, анализ и другие операции по работе с текстом.
import nltk
import re
nltk.download("stopwords") # поддерживает удаление стоп-слов
nltk.download('punkt') # делит текст на список предложений
nltk.download('wordnet') # проводит лемматизацию
from nltk.corpus import stopwordsРассмотрим основные шаги, которые необходимы для обработки текста.
Очистка текста от неалфавитных символов. Функция
re.subпозволяет заменить все, что подходит под шаблон на указанную строку. Например, вот так можно заменить все, что не является словами на пробелы:
re.sub("[^a-zA-Z]"," ",text)Токенизация. Данный метод позволяет разделить текст на так называемые токены, то есть на слова или предложения.
nltk.word_tokenize(text,language = "english")Лемматизация. Позволяет привести словоформу к лемме — ее нормальной (словарной) форме. Другими словами, лемматизация схожа с выделением основы каждого слова в предложении. Она обычно выполняется простым поиском форм в таблице. Кроме того, можно добавить некоторые пользовательские правила для анализа слов.
lemmatize = nltk.WordNetLemmatizer()
lemmatize.lemmatize(word) for word in textУдаление стоп-слов. Под стоп-словами обычно понимаются артикли, междометия, союзы и т.д., которые не несут смысловой нагрузки. При применении алгоритмов машинного обучения такие слова могут добавить много шума, поэтому лучше избавляться от них. В NLTK есть предустановленный список стоп-слов.
lemmatize.lemmatize(word) for word in text if not word in set(stopwords.words("stopwords"))Векторизация текста или преобразование текста в численную форму. Алгоритмы машинного обучения не умеют работать с текстом, поэтому необходимо превратить текст в цифры. Данная стратегия называется представлением «Мешок слов». Документы описываются вхождениями слов, при этом полностью игнорируется информация об относительном положении слов в документе. По мешку слов находят количество появлений каждого слова во всем тексте.
В пакете scikit-learn есть модуль CountVectorizer, который преобразовывает входной текст в матрицу, значениями которой являются количества вхождения данного ключа(слова) в текст. Таким образом, мы получим матрицу, размерность которой будет равна количеству всех слов, умноженных на количество документов. И элементами матрицы будут числа, которые означают, сколько раз всего слово встретилось в тексте.

Также популярным методом для векторизации текста является метод TF-IDF, который является статистической мерой для оценки важности слова в документе.
В тексте большого объема некоторые слова могут присутствовать очень часто, но при этом не нести никакой значимой информации о фактическом содержании текста (документа). Если такие данные передавать непосредственно классификатору, то такие частые термины могут затенять частоты более редких, но при этом более интересных терминов. Для того, чтобы этого избежать, достаточно разделить количество употреблений каждого слова в документе на общее количество слов в документе, это есть TF — частота термина. Термин IDF (inverse document frequency) обозначает обратную частоту термина (инверсия частоты) с которой некоторое слово встречается в документах. IDF позволяет измерить непосредственную важность термина.

Тогда TF-IDF вычисляется следующим образом:
TF-IDF(term)=TF(term)*IDF(term)

В итоге код по работе с текстом выглядит следующим образом,
new_text = []
for i in data_depression.clean_text:
#удаляем неалфавитные символы
text = re.sub("[^a-zA-Z]"," ",i)
# токенизируем слова
text = nltk.word_tokenize(text,language = "english")
# лемматирзируем слова
text = [lemmatize.lemmatize(word) for word in i]
# соединяем слова
text = "".join(text)
new_text.append(text)В данной задаче текст будем преобразовывать в набор цифр с помощью модуля CountVectorizer для получения матрицы, содержащей 0 и 1.
# импортируем модуль
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words="english")
# проводим преобразование текста
matrix = count.fit_transform(new_text).toarray()Если мы ходим преобразовать текст, используя метод TF-IDF, тогда можно поступить следующим образом:
# импортируем модуль TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(stop_words="english")
#преобразуем текст
values = tfidf_vectorizer.fit_transform(new_text)После того, как обработка текста закончена, можно переходить непосредственно к применению алгоритмов машинного обучения.
Определим вектор с данными для обучения и вектор правильных ответов.
X=matrix
y = data_depression["is_depression"].values
Далее разделим выборку на тестовую и обучающую
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 42)Рассмотрим самый известный алгоритм — наивный классификатор Байеса. Данный алгоритм является одним из самых простых алгоритмов классификации, но при этом часто может работать не хуже более сложных алгоритмов. Метрики качества работы алгоритмов будут приведено ниже. Пока буду приводить только точность алгоритмов.
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB()
result_bayes = nb.fit(x_train, y_train)
nb.score(x_test,y_test)
0.8436520376175548Логистическая регрессия. Также является простейшим алгоритмом классификации. С помощью данного алгоритма можно разделить несложные объекты на 2 класса. Модель логистической регрессии быстро обучается и подходит для задач бинарной классификации.
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
result_logreg = logreg.fit(x_train, y_train)
logreg.score(x_test,y_test)
0.9564655172413793Метод опорных векторов. Данный метод также можно использовать для задач классификации, поскольку он категоризирует данные с помощью гиперплоскости.
from sklearn import svm
metodsvm = svm.SVC()
result_svm = metodsvm.fit(x_train, y_train)
metodsvm.score(x_test, y_test)
0.9543103448275863Теперь можно попробовать рассмотреть некоторые ансамблевые методы машинного обучения, такие как адаптивный бустинг и градиентный бустинг. Что мы знаем про ансамблевые методы? В ансамблевых методах несколько моделей обучаются для решения одной и той же проблемы и объединяются для получения более эффективных результатов. Основная идея заключается в том, что при правильном сочетании моделей можно получить более точную и надежную модель.
Считается, что алгоритм адаптивного бустинга лучше всего работает со слабыми обучающими алгоритмами и может достичь достаточно высокой точности при решении задач классификации. В AdaBoost базовые алгоритмы обучаются последовательно, учитывая опыт предыдущего. Так, каждый последующий алгоритм начинает придавать большее значение тем наблюдениям из тренировочного набора данных, на которых ошиблись предыдущие.
#адаптивный бустинг
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
modelClf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2), n_estimators=100, random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size = 0.33, random_state = 42)
modelclf_fit = modelClf.fit(X_train, y_train)
modelClf.score(X_valid, y_valid)
0.9361285266457681Градиентный бустинг, также как и адаптивный, обучает слабые алгоритмы последовательно, исправляя ошибки предыдущих. Принципиальное отличие этих алгоритмов заключается в способах изменения весов. Адаптивный бустинг использует итеративный метод оптимизации, в то время как градиентный оптимизирует веса с помощью градиентного спуска.
# градиентный бустинг
from sklearn.model_selection import train_test_split
# импортируем библиотеку
from sklearn.ensemble import GradientBoostingClassifier
modelClf = GradientBoostingClassifier(max_depth=2, n_estimators=150,random_state=12, learning_rate=1)
X_train, X_valid, y_train, y_valid = train_test_split(X, y,
test_size=0.3, random_state=12)
modelClf.fit(X_train, y_train)
modelClf.score(X_valid, y_valid)
0.928448275862069И напоследок хочется рассмотреть алгоритм работы простой нейронной сети (многослойный персептрон), в которой будет 2 полносвязнных слоя и 1 выходной с 1 выходом. Чтобы смоделировать нейронную сеть в python, нам понадобится фреймворк Keras, который является оболочкой над Tensorflow.
В Keras для построения моделей нейронных сетей (models) мы собираем слои (layers). Для описания стандартных архитектур нейронных сетей в Keras уже существуют предопределенные классы для слоев:
Dense() – полносвязный слой;
Conv1D, Conv2D, Conv3D – сверточные слои;
Conv2DTranspose, Conv3DTranspose – транспонированные (обратные) сверточные слои;
SimpleRNN, LSTM, GRU – рекуррентные слои;
MaxPooling2D, Dropout, BatchNormalization – вспомогательные слои
Обратим внимание, что в Keras слои автоматически конструируются таким образом, чтобы соответствовать форме входного слоя, поэтому нет необходимости беспокоиться о совместимости слоев, что очень удобно.
Типичный процесс использования Keras для построения нейронной сети можно описать так:
Определение обучающих данных: входные и целевые векторы
Определение слоев сети (модель), отображающих входные данные в целевые
Настройка процесса обучения выбором функции потерь, оптимизатора и некоторых параметров для мониторинга
Выполнение итераций по обучающим данным вызовом метода
fit()и модели.
Если мы хотим создать нейронную сеть с последовательными слоями, нам также понадобится класс Sequential.
Загружаем необходимые библиотеки:
from keras import models
from keras import layers
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense1. Получаем обучающую и тестовую выборку:
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 42)2. Сначала создаем пустую модель Sequential:
model = models.Sequential()Теперь в пустую модель нейронной сети можно добавлять слои. Добавим 2 полносвязных слоя с 64 выходными нейронами и активационной функцией Relu (фактор нелинейности). Функция relu является самой популярной функцией в глубоком обучении, но, конечно, можно использовать и другие. Первому слою надо обязательно передать ожидаемую форму входных данных, т.е. размер входного вектора, это указывается в параметре input_shape.
model.add(layers.Dense(64,activation='relu',input_shape=(voc_len,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1, activation = 'sigmoid'))Последний слой сети имеет сигмоидальную активационную функцию, так как наша задача является задачей бинарной классификации и на выходе сети мы хотим получить оценку вероятности между 0 и 1 того, что наш образец относится к классу “1”.
3. После того, как модель создана, необходимо настроить процесс ее обучения с помощью вызова метода compile
from keras import optimizers
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])Объект optimizer определяет процедуру обучения, а именно оптимизатор алгоритма градиентного спуска. Доступны оптимизаторы SGD, RMSprop, Adam, Adadelta, Adagrad, Adamax, Nadam, Ftrl.
Объект loss — это функция, которая минимизируется в процессе обучения. Среди распространенных вариантов: среднеквадратичная ошибка (mse), categorical_crossentropy, binary_crossentropy.
Объект metrics используется для мониторинга обучения.
4. Для обучения модели необходимо вызвать метод fit(). Задаем тренировочные данные, количество эпох для обучения, валидационные данные для отслеживания производительности модели, что позволит отобразить значения функции потерь и метрики в режиме вывода для передаваемых данных в конце каждой эпохи. Зададим 20 эпох, чтобы потом можно было найти оптимальное количество эпох, которое необходимо для обучения.
history=model.fit(x_train, y_train, epochs=20,batch_size=512,validation_data=(x_test,y_test))Вызов метода fit вернет нам объект history, с помощью которого можно получить данные обо всем происходящем в процессе обучения.
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])Теперь можно вывести графики потерь и точности на этапах обучения и проверки

# построение графика потери на этапах проверки и обучения
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(history_dict['accuracy'])+1)
# построение графика потери на этапах проверки и обучения
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(history_dict['accuracy'])+1)
plt.plot(epochs, loss_values, 'bo', label = 'Потери на этапе обучения')
plt.plot(epochs, val_loss_values, 'b', label = 'Потери на этапе проверки')
plt.title('Потери на этапах обучения и проверки')
plt.xlabel('Эпохи')
plt.ylabel('Потери')
plt.legend()
plt.show()
# построение графика точности на этапах обучения и проверки
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
plt.plot(epochs, acc_values, 'bo', label = 'Точность на этапе обучения')
plt.plot(epochs, val_acc_values, 'b', label = 'Точность на этапе проверки')
plt.title('Точность на этапах обучения и проверки')
plt.xlabel('Эпохи')
plt.ylabel('Точность')
plt.legend()
plt.show()Посмотрев на графики, можно увидеть, что на этапе обучения потери снижаются с каждой эпохой, а точность растет. Как раз такого поведения и можно ожидать от оптимизации градиентным спуском, та величина, которую мы минимизируем, должна становиться все меньше с каждой итерацией. Но это не относится к потерям и точности на этапе проверки, можно заметить, что здесь пик был достигнут где-то на 4-5 эпохе. И, начиная с пятой эпохи, наблюдается переобучение, которое выражается в том, что функция потерь начинает расти. Такой картины стоило ожидать, так как модель, которая показывает хорошие результаты на обучающих данных, не обязательно будет показывать такие же хорошие результаты на данных, которых никогда не видела.
Благодаря такому графику можно оценить оптимальное количество эпох, которое необходимо для обучения сети. В данном случае для предотвращения переобучения нейронную сеть будем обучать на 5 эпохах. Таким образом, обучим сеть с нуля и рассчитаем метрики качества разработанной модели нейронной сети.
Y_pred=model.predict(x_test)
# задаем порог 0,5 для классификации текста
Y_pred=(Y_pred>=0.5).astype("int")
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
print(classification_report(y_test,Y_pred))
print(confusion_matrix(y_test,Y_pred))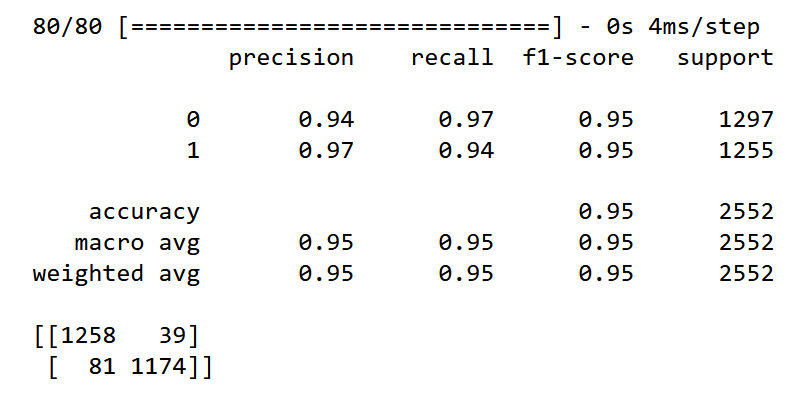
Результаты работы всех алгоритмов можно увидеть в таблице
Алгоритм |
Accuracy |
Precision |
Recall |
F1 |
Классификатор Байеса |
0.844 |
0.785 |
0.939 |
0.855 |
Логистическая регрессия |
0.956 |
0.987 |
0.924 |
0.954 |
Метод опорных векторов |
0.954 |
0.998 |
0.909 |
0.951 |
AdaBoost |
0.936 |
0.935 |
0.935 |
0.935 |
GradientBoost |
0.928 |
0.953 |
0.896 |
0.924 |
Многослойный персептрон |
0.953 |
0.968 |
0.937 |
0.951 |
Посмотрев на данную сравнительную таблицу, можно сказать, что классификатор Байеса, к сожалению, показал самые плохие результаты с точностью 0,84. У алгоритма адаптивного бустинга одинаковые показатели по всем метрикам, равные 0.94. Это связано с тем, что целью данного алгоритма является улучшение производительности алгоритмов. На мой взгляд, можно выделить 3 алгоритма, которые хорошо справились с задачей — это логистическая регрессия, метод опорных векторов и многослойный персептрон с точностью 0,95.
Приглашаем на открытое занятие «Пишем первую нейронную сеть». На нем рассмотрим основные этапы создания и обучения своей первой нейронной сети и попробуем решить известную задачу классификации MNIST полносвязной и сверточной нейронными сетями на примере фреймворка PyTorch. Регистрация — по ссылке.
QtRoS
В целом неплохая статья, базовая работа с текстом разобрана, но:
Вроде как уже неоднократно было такое на Хабре
Даже на ноутбуках можно использовать модели по типу BERT или USE, скорее всего они обойдут классические bag-of-words-like подходы по качеству, например благодаря адекватной обработке отрицаний (частицы "не" в частности)
BubaVV
USE так назвали, чтобы никто не нашел. Я кстати сталкивался прямо с такой сеткой как в статье на проде, со своими задачами справлялось просто и быстро
QtRoS
"Просто" это действительно сильный аргумент, и у меня тоже TF-IDF работает в проде :)
Кстати USE лучше гуглить по расшифровке, тогда сразу приводит на TF Hub. Кстати если кто знает годную PyTorch реализацию - буду благодарен за ссылку.