

Привет! Меня зовут Адель, я аналитик ИТ-компании SimbirSoft, кроме того, я интересуюсь Data Science. Тема миграции данных из одной системы в другую не нова. Она связана с анализом большого объема информации и связей между различными участками данных, где стоимость ошибки может быть высокой и нужна особая ответственность. Вокруг этой информации построены основные бизнес-процессы, а значит от них напрямую зависит прибыль компании-клиента.
Каждый перенос данных – это большой пласт работ в проекте, и делая это уже много раз при запуске новых систем, мы постоянно ищем способы ускорения этих работ и уменьшения количества ошибок при переносе. В этой статье хочу рассказать, как можно решить проблему миграции чувствительных необработанных данных, которые на протяжении долгого времени заполнялись и хранились в Excel.
Материал будет полезен разработчикам и аналитикам при работе над проектами по миграции данных, поскольку содержит реальные проблемы и проверенные подходы к их решению. В статье рассмотрим, как правильно подготовить данные к переносу, когда нужно уйти от несистематичного и разрозненного хранения важной информации в таблицах Excel и локальных хранилищах. Поэтому материал может быть интересен и бизнесу.
Предыстория
В одном из наших проектов заказчик поставил перед нами ряд задач:
Структурировать и объединить все данные о клиентах и их сделках.
Сократить % ошибок при вводе данных.
Снизить % неучтенных сделок.
Повысить управляемость процессов – для последующего делегирования и обеспечения контроля над ними.
В этой статье расскажу только о переносе данных.
Итак. Сначала нам нужно было понять, как данные будут перетекать в новую ИТ-систему. С учетом всех предоставленных вводных на первом этапе было согласовано, что заказчик будет переносить их вручную, поскольку они очень важны для его бизнеса. Нам предстояло найти максимально простое и быстрое решение. Но не всё было так легко, как могло показаться.
Основные проблемы, с которыми мы столкнулись:
Информация ведется в excel-файлах, google sheets. Порядка сотни тысяч строк данных заведены в Excel вручную.
Сложно получить достоверную картину по состоянию дел.
Общая справочная информация не консолидирована, нет возможности отследить, что происходит по каждой конкретной сделке – из-за этого страдает уровень сервиса.
Все основные процессы зациклены вокруг владельца бизнеса.
Всё это не позволяло заказчику развивать бизнес в той степени, в какой ему хотелось.
В рамках типовой работы по миграции данных необходимо было:
Обработать и структурировать данные.
Разобрать данные по сущностям.
Сформировать связь с ними, согласно ER-модели.
Учесть различные требования. Например, нельзя терять данные в ходе их переноса, допускать дубликаты и т.п.
Дополнительно в рамках самой работы по парсингу нужно было:
Обосновать бюджет, работы и сроки.
Выстроить рабочий процесс и план работ.
Далее рассмотрим проблемы более детально. Большинство из них было связано с форматом хранимых данных (excel).
Проблема |
Причины |
Некорректные данные ручного ввода |
Данные вводились вручную на протяжении всего периода существования бизнеса. В итоге: там, где ждешь URL, получаешь комментарий, вместо email – беспорядочную запись. В добавление к этому – множество разных регистров, пробелов, добавленных запятых и прочего. |
Некорректные статусы |
В ходе работы над проектом пришлось структурировать процессы, в том числе переработать статусную модель. Некоторые утратили силу или были переименованы. |
Некорректные даты |
Формат Excel. Даты порой распознавались то ДД/ММ/ГГГГ, то ММ/ДД/ГГГГ. |
Некорректные электронные адреса |
Электронные адреса могли содержать невалидные данные либо были перечислены через запятую в частных случаях. |
Отсутствие обязательных данных |
При согласовании некоторые обязательные данные просто отсутствовали в исходных файлах |
Некорректный формат URL-адресов |
Разные регистры, лишние пробелы и т.п. |
Миграцию данных затрудняло то, что:
Данные хранились разрозненно, не было единого шаблона.
Всё осложнялось крайней чувствительностью данных. Ручная обработка не показывала нужных результатов с учётом большого массива информации.
Высокие требования к задаче по переносу данных диктовали необходимость валидации данных.
Как решали задачу
Полученные вводные данные заставили нас всерьез задуматься:
как решить задачу максимально быстро, с минимальными потерями и искажениями данных;
как проверить полученный результат.
Первым делом определили приоритеты к требованиям. Само решение задачи состояло из 5 шагов:

Если кратко, то мы взяли день на исследование полученной информации. Это было нужно для оценки рисков и проблем. После этого провели небольшой мозговой штурм. В итоге сформировали план. На его основе приступили к реализации плана и отдали результат на утверждение.
Проведение исследования, результат – выделили проблемы, о которых упомянули выше.
Поиск решения, итог – обозначили риски и необходимые ресурсы.
-
Формирование и утверждение плана:
Продумали рабочий процесс.
Распределили участников и зоны ответственности.
Сформировали требования к данным.
Утвердили план с заказчиком.
Поэтапная реализация плана. Полученный результат направили заказчику на утверждение.
Утверждение результатов, сбор обратной связи и финальная валидация работы, доказательство того, что требования конкретного пользователя, продукта, услуги или системы удовлетворены.
Подробно расписывать не будем, перейдем к самому важному – к работе с данными.
Анализ данных и формирование эталона
Данные. Разделяй и властвуй
А что же с данными? А мы взяли и разделили их. Да, так просто.
И примерно это выглядит вот так:
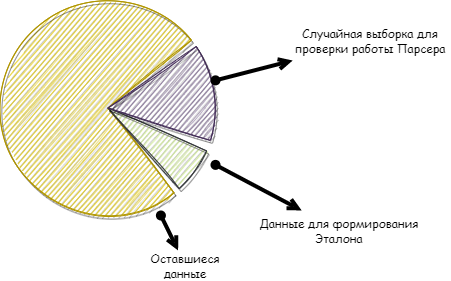
Разделение данных происходило так:

1. Для определения первоочередности загрузки данных предварительно классифицировали их на основные и подчиненные, т.е. зависимые данные.
2. Определили ключи, по которым данные будут связываться между собой.
3. Сформировали группы данных по общему признаку, в частности по клиентам.
4. Определили данные для формирования эталона.
5. Сделали выборку для миграции: взяли небольшой объем данных, на которых мы бы оттачивали свой парсер.
Соглашение
Требования к качеству работы были собраны и оговорены в самом начале, как я и писал выше. В этом разделе поговорим о требованиях к передаваемым для миграции данным.
Поскольку мы занимались переносом из сторонних внешних систем, у нас была возможность договориться о формате и шаблоне. Это необходимо, чтобы сократить количество ошибок, время на разработку и тестирование. Мы сформировали требования к данным, которые можно было привести к нужному формату на основе тех шаблонов, что нам предоставили.
Соглашение описывало требования к:
Наименованию столбцов;
Данным;
Тому, как необходимо поступать, если требования не соблюдены. Например: если дата некорректная – проставить текущую дату, а если отсутствует обязательная категория данных – поставить значение по умолчанию или сделать поле nullable и т.п.
Обработка данных с помощью Jupyter и Pandas

Для работы с данными, которые приходили от заказчика, я решил воспользоваться инструментами аналитика данных: Jupyter scipy-notebook и библиотекой Pandas.
Jupyter scipy-notebook и библиотека Pandas могут помочь, когда есть необходимость работы с данными из разных источников или когда надо просмотреть и проделать работу, не имея какого-либо специализированного ПО с удобным интерфейсом. К дополнительным преимуществам этого инструмента можно отнести:
возможность сбора данных как из файлов .csv, .xlsx, так и из любой базы данных.
возможность отобразить имеющиеся данные в табличном виде.
доступ ко всем операциям работы с данными, а также к инструментарию Python 3.
С помощью этих инструментов удалось в кратчайшие сроки:
Проверить соответствие данных требованиям.
Вывести все несоответствия построчно в отдельную таблицу.
Сформировать удобный визуальный отчет, который позволял бы руками сверить все несоответствия.
Загрузка данных была на стороне разработчика. А поскольку я люблю разбираться с данными, написал свой код для проработки данных, независимо от разработчика, использовав для этого Jupyter и библиотеку Pandas.
Предварительная обработка данных с помощью Jupyter и Pandas позволила визуализировать данные и достаточно быстро проверить их на соответствие требованиям самостоятельно, передать клиенту и QA-специалисту. Для QA отдельно залил код на Google Colab и показал, как им пользоваться.
Jupyter scipy-notebook позволяет не просто отдать кусок кода, который ещё надо проверить или даже постараться понять, а сразу показывает результат его исполнения. К тому же, он может сразу выгрузить получившийся результат в pdf или html-файл. Таким образом можно было сформировать и наглядно показать все проблемные участки заказчику. QA-специалист этим также охотно пользовался.
Для сверки и формирования отчета использовались:
около 10 различных количественных показателей, в том числе с предварительной обработкой данных и приведением строки к определенному виду
4 проверки соответствия корректности и соответствию данных
несколько проверок на соответствие формату данных, например, находится ли в записи email или там “абракадабра”.
Все несоответствия можно было сразу увидеть, свериться по всем контрольным срезам, сравнить со стартовыми данными и эталоном, а также визуально продемонстрировать заказчику весь пул проблем, связанных с миграцией данных. Это помогло добиться понимания необходимости проводимых работ.
Еще немного деталей
Ниже опишу некоторые участки кода. Сразу отмечу, что код отличается от использованного в проекте.
Я импортировал всего пару библиотек: pandas и re.
import pandas as pd
import re
Залил документ
path = '.dataframe.csv'
pd.read_csv(path)
df = pd.read_csv(path)
Проверил название столбцов в соответствии с соглашением.
Написал первую проверку на соответствие значения формата e-mail, собрал все уникальные значения по нужным мне данным.
for email in partner_email:
if not EMAIL_REGEX.match(email):
email_check = 'ERROR'
else:
email_check = 'O.K.'
df2 = df.loc[df['email'] == email]
print(f'{email_check} - {email.upper()}')
df_x = df2.loc[df2['Column1'] == 'Value1']['Column2'].sort_values().unique()
После чего каждое значение привёл к нужному формату и закинул в set(), чтобы избежать дубликатов. Далее вывел данные для визуальной проверки по каждому объекту.
Затем выделил данные по каждому столбцу, агрегировал их для получения контрольных сумм и последующей сверки значений. Потом привел все значения в удобочитаемый вид по каждому нужному мне объекту, используя обычный printf()
print(f'''
email: {email.upper()}
-------------------------------------------------
{len(x):3.0f} : some data1
…some code…
-------------------------------------------------
…some code…
-------------------------------------------------
Status : {status_check}
…some code…
Email : {the_email_check}
''')
Все некорректные значения по каждому столбцу перенес отдельно в таблицу в виде dataframe.
Реальные данные показать не могу, но примерно это выглядит так:

После каждой проверки мы сразу видели результат. Помимо этого, можно было выгрузить весь блокнот в html или pdf, а каждый dataframe – в нужный формат, например, Excel.
С какими рисками столкнулись в процессе и как их решали
Перечислю несколько подводных камней, с которыми мы встретились в кейсе. Отмечу, что для каждого мы реализовали простые подходы к их устранению.
На этапе исследования первый подводный камень – отсутствие ясных границ задачи. Было важно обозначить все критерии приемки работ и их границы. После чего, минуя этап поиска решения, мы сверялись с данными критериями, чтобы понять, что ничего не упустили.
На этапе планирования появился второй подводный камень – несогласованность. Какой бы хороший план ни был, если все заинтересованные участники не осведомлены о нём, толка будет мало. Было принято решение – задействовать заказчика и получить от него одобрение.
Далее уже нюансы конкретного кейса. Как разобрать большой кусок данных и раскидать его по полочкам? Третий подводный камень – отсутствие эталонных данных. Как понять, что результат верен? Необходимо было создать этот эталон на первом этапе реализации и провалидировать его с заказчиком.
Четвертый подводный камень – сами данные. При достаточно большом объёме данных могут встретиться разные проблемы. Основные из них мы описывали выше. Чтобы работать с этим риском, необходимо было реализовать предварительную обработку данных, а также иметь инструмент, который поможет сверить корректность полученных на входе данных.
Пятый подводный камень – мы не владельцы исходных данных. И поэтому не можем сказать, что получен нужный результат. После всех проверок и тестов необходимо было передать результат на финальное утверждение.
Результаты
При миграции данных можно столкнуться с большим количеством проблем и тонкостей, которые нужно учесть. Выявив проблемы и продумав процесс их решения, мы смогли достичь высоких и качественных результатов с минимальными для заказчика издержками. И что немаловажно, их можно было продемонстрировать и проверить.
Нам удалось обосновать бюджет, сроки и работы по кейсу, выдержать обозначенные атрибуты качества работы и попасть в ожидания заказчика.
В итоге примерно за 2,5 недели мы перенесли 97,6% данных без дубликатов и прочих проблем. А 2,4% вывели в отдельный документ для дальнейшей ручной проверки, поскольку содержание оставшихся данных оставляло желать лучшего, типовые подходы и инструкции не могли помочь.
По итогам самого проекта нам удалось успешно структурировать и объединить все данные о клиентах и их сделках, реализовав CRM. Мы исключили большинство ошибок при вводе данных вручную – через их валидацию при вводе в систему. Теперь абсолютно любая сделка “оставляет след” в системе, который можно увидеть в отчетах и дашбордах. Дополнительно сократилось время работы с таблицами и ускорился обмен данными между структурными единицами.
Вместо вывода
В миграции данных нужен системный подход: обозначьте все риски, роли и зоны ответственности на этапе планирования. Не стоит полагаться на авось. Пока напишете парсер и отловите все ошибки на нем, может оказаться, что в итоге он перенесет данные не так, как ожидалось, а значит будет потеряно время. Непрекращающиеся ревью результатов очередной версии парсера только где-нибудь на второй месяц покажут наличие серьезных проблем.
Заказчик – часть команды. Поэтому в определенной степени его также необходимо привлекать к планированию, ведь это позволит сэкономить время и бюджет клиента. Инструменты, о которых я упоминал выше, помогут визуализировать проблемы и результаты, донести их до заказчика и владельца продукта. Но описанный в статье способ, конечно, не единственный вариант решения задачи. Каждый случай уникален, хотя есть и общие принципы, которые можно использовать.
Надеюсь, опыт нашей команды был вам полезен. Если остались вопросы, пишите в комментариях, постараемся ответить. О других проектах можно прочитать тут.
Больше кейсов и интересных материалов в наших каналах: