
Введение
Когда я познакомилась со своим бойфрендом, я иногда ощущала небольшое сожаление от того, что у нас не было умилительной киношной истории встречи, несмотря на то, что мы пять лет жили в одном и том же городе и учились в одном университете. Наша история не уникальна для многих пар в 2020 году: на спаде между двумя волнами COVID мы начали общаться онлайн, в приложении для знакомств Bumble.
Я подумала, что благодаря истории местоположений Google, втихомолку отслеживающей данные GPS, можно было бы найти ответ на вопрос о том, насколько судьбоносно пересекались наши дорожки до встречи. Насколько близко мы были к тому, чтобы воспроизвести романтическую сцену «среди десятков людей они нашли глазами друг друга»?
Если вам неинтересны технические подробности, можете сразу перейти к разделу «Ответ»!
Исходные данные
Запросить и скачать всю зафиксированную историю местоположений можно через десктопную версию веб-сайта Google Maps. Эти данные хранятся в запакованной zip папке, состоящей из файлов JSON. Мой партнёр любезно согласился скачать свои данные и отправил их мне.
packages <-
c("tidyverse",
"lubridate",
"rjson",
"ggplot2",
"ggmap",
"wesanderson")
install.packages(setdiff(packages, rownames(installed.packages())))
library(tidyverse)
library(lubridate)
library(rjson)
library(ggplot2)
library(ggmap)
library(wesanderson)Извлечение
#Имена двух людей
x <- "Chan"
y <- "Dan"
#Адреса файла Records (ссылка на файл Records.json)
data_x <-
"~/Crossing paths/TakeoutChannon/Location History/Records.json"
data_y <-
"~/Crossing paths/TakeoutDandre/Location History/Records.json"
#Функция из библиотеки fromJSON для извлечения файлов JSON в объекты-списки R
extract_maps_data <- function(fileName, saveAs) {
rd <- fromJSON(file = fileName)
records_data <- unlist(rd, recursive = FALSE)
save(records_data, file = saveAs)
records_data
}
#Выполняем эту функцию для данных, если её ещё не выполняли, в противном случае загружаем их
if (file.exists("extracted_data_x.RData")) {
records_data_x <- get(load("extracted_data_x.RData"))
} else {
records_data_x <- extract_maps_data(fileName = data_x,
saveAs = "extracted_data_x.RData")
}
if (file.exists("extracted_data_y.RData")) {
records_data_y <- get(load("extracted_data_y.RData"))
} else {
records_data_y <- extract_maps_data(fileName = data_y,
saveAs = "extracted_data_y.RData")
}Преобразование
Задаём параметры
Прежде чем приступать к непосредственному преобразованию и очистке данных, необходимо задать границы временных интервалов и точности, чтобы нам не пришлось тратить время на обработку ненужных записей.
Предельное расстояние
В этой таблице показано, как измерения точности расстояний соотносятся друг с другом.
| accuracy.level | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| знаки после запятой | 3 | 4 | 5 | 6 |
| точность (м) | 111 | 11,1 | 1,11 | 0,111 |
| координаты | ± 00,000 | ± 00,0000 | ± 00,00000 | ± 00,000000 |
Данные имеют два типа показателей точности. Координаты GPS имеют разные количества знаков после запятой в зависимости от специфики местоположения. Также существуют измерения точности на основании силы сигнала GPS, указываемые в метрах.
Эти метрики точности определяют величину предельного расстояния для любых выводов, которые мы будем делать. Если мы решим, что мои дороги и дороги будущего бойфренда пересеклись, проходили ли мы в десятках, сотнях или тысячах метров друг от друга? Изначально я выбрала 1,11 м, что соответствует координатам с 4 знаками после запятой (± 00,0000), потому что думала, что даже в густонаселённых городских пространствах телефонная антенна имеет чрезвычайно высокую вероятность находиться в пределах прямой видимости. Однако качество данных (см. ниже) слишком ограничивало количество данных, что вынудило меня использовать точность расстояний в пределах 111 м.
Я объединила два типа метрик точности, чтобы во всех наших исследованиях точность расстояний была стандартизованной. Координаты с большим количеством знаков после запятой округляются. Это означает, что мы делим мир на более крупные блоки и перемещаем все точки внутри блока к его ближайшему углу. Все зафиксированные метрики точности с расстояниями меньше соответствующего расстояния в метрах отфильтровываются из массива данных.
#Предел расстояний
accuracy_level <- 1Предельное время
Также нам нужно задать временные границы для двух массивов данных. Первой датой будет самая ранняя дата реальной возможности вступить в контакт. Если конкретной самой ранней даты (например, времени переезда в один город) нет, то её можно задать как минимальную дату любого из двух массивов.
## [1] "Самая первая запись Чен - 2014-10-11"
## [1] "Самая первая запись Дэна - 2015-01-13"
## [1] "Использовать 2015-01-13 или first_intersect_date, чтобы начать с самых ранних дат пересечения."start_looking_from <- as.POSIXct(first_intersect_date) #Начальная дата, с которой нужно начинать анализ данныхТакже у временного интервала есть конечная дата. Это дата и время, когда мы точно знали, что наши координаты GPS впервые совпадут.
best_day <- as.POSIXct("2020/08/08 1:00:00") #Подтверждённое время первого свидания <3Аналогично предельному расстоянию, полезно будет задать временные интервалы, чтобы группировать в них координаты. Это нужно, поскольку при учёте масштаба в метрах люди обычно не движутся по поверхности Земли достаточно быстро, чтобы их местоположение нужно было бы фиксировать много раз в секунду, однако данные хранятся с метками времени вплоть до миллисекунд.
Я выбрала 10 минут, потому что этот показатель тоже был для меня предельным; меня вполне устраивало это значение: так романтично, что мы могли бы сидеть на одной и той же скамейке с интервалом в 10 минут.
#Предел времени
time_accuracy <- "10 mins" #Дискретность делений времени. Для просмотра доступных категорий времени использовать ?round_date.Древовидные списки, которые я преобразовала из файлов JSON, по-прежнему ещё не очищены. На данный момент каждый массив данных состоит из сотен тысяч наблюдений, каждое из которых представлено в списочном формате, имеющем следующую структуру:
## List of 7
## $ latitudeE7 : num -2.59e+08
## $ longitudeE7: num 2.92e+08
## $ accuracy : num 2459
## $ activity :List of 2
## $ source : chr "CELL"
## $ deviceTag : num 1.44e+09
## $ timestamp : chr "2014-10-11T14:39:52.645Z"После завершения преобразования данных нам бы хотелось иметь два интервала данных (по одному для каждого человека), имеющих следующую структуру:
| индекс | метка времени | широта | долгота | точность | человек | координаты | источник |
|---|---|---|---|---|---|---|---|
| 1:nrows | время POSIXct | координаты dd | координаты dd | радиус в м | имя | ширина, долгота | источник сигнала |
Для этого мы выполним для обоих массивов данных следующую функцию:
transform_maps_data <-
function(x,
person,
time_accuracy,
distance_accuracy) {
# Извлечение интересующих нас переменных и отсечение всей информации, связанной с тем, когда, по мнению Google, мы ехали в транспорте или сидели на месте.
timestamp <-
lapply(x, pluck, "timestamp") %>% unlist() %>% data.frame()
latitude <-
lapply(x, pluck, "latitudeE7") %>% unlist() %>% data.frame()
longitude <-
lapply(x, pluck, "longitudeE7") %>% unlist() %>% data.frame()
accuracy <-
lapply(x, pluck, "accuracy") %>% unlist() %>% data.frame()
source <- lapply(x, pluck, "source") %>% unlist() %>% data.frame()
# Задаём индекс
index <- 1:nrow(timestamp)
# Комбинируем каждую из переменных в интервал данных в виде столбцов с понятными названиями.
records_df <-
cbind(timestamp, latitude, longitude, accuracy, source)
rownames(records_df) <- index
colnames(records_df) <-
c("timestamp", "latitude", "longitude", "accuracy", "source")
# Регулируем форматирование и добавляем важные столбцы.
output <- records_df %>%
# Форматируем метки времени, чтобы они были объектами POSIXct в часовом поясе системы, и округляем их с заданными пределами точности
mutate(timestamp_utc = as.POSIXct(timestamp, format = "%Y-%m-%dT%H:%M:%S", tz = "UTC")) %>%
mutate(timestamp = with_tz(timestamp_utc, tzone = Sys.timezone())) %>%
select(-timestamp_utc) %>%
mutate(timestamp = round_date(timestamp, unit = time_accuracy)) %>%
# Добавляем столбец с именем человека, которому принадлежат записи
mutate(person = person) %>%
# Широта и долгота находятся в удобном формате, позволяя нам копировать и вставлять их в Google Maps, и отфильтрованы по количеству знаков после запятой distance.accuracy
mutate(latitude = round((latitude / 10000000), distance_accuracy)) %>%
mutate(longitude = round((longitude / 10000000), distance_accuracy)) %>%
# Добавляем столбец для объединённых координат
mutate(coordinates = paste(latitude, longitude, sep = ", ")) %>%
# Отфильтровываем все записи вне пределов указанной точности
filter(accuracy <= google_reported_accuracy) %>%
filter(accuracy >= 0) %>%
# Отфильтровываем все записи до или после начальной и конечной дат
filter(timestamp >= start_looking_from) %>%
filter(timestamp <= best_day) %>%
# Для целостности удаляем неизвестные источники
filter(source != "UNKNOWN") %>%
# Удаляем дубликаты
unique()
}
#Выполняем функцию для двух массивов данных, в противном случае загружаем ранее сохранённые данные.
if (file.exists("X_Google_Maps_history.RData")) {
load("X_Google_Maps_history.RData")
} else{
x_records <-
transform_maps_data(
records_data_x,
person = x,
time_accuracy = time_accuracy,
distance_accuracy = distance_accuracy
)
}
if (file.exists("Y_Google_Maps_history.RData")) {
load("Y_Google_Maps_history.RData")
} else{
y_records <-
transform_maps_data(
records_data_y,
person = y,
time_accuracy = time_accuracy,
distance_accuracy = distance_accuracy
)
}В конце этапа преобразования у нас получились два кадра данных со следующей структурой:
## timestamp latitude longitude accuracy source person coordinates
## 1 2015-01-13 02:00:00 -25.89 29.252 12 CELL Chan -25.89, 29.252
## 3 2015-01-13 02:04:00 -25.89 29.252 12 CELL Chan -25.89, 29.252
## 4 2015-01-13 02:06:00 -25.89 29.252 12 CELL Chan -25.89, 29.252
## 5 2015-01-13 02:10:00 -25.89 29.252 12 CELL Chan -25.89, 29.252
## 7 2015-01-13 02:12:00 -25.89 29.252 27 CELL Chan -25.89, 29.252
## 8 2015-01-13 02:14:00 -25.89 29.252 27 CELL Chan -25.89, 29.252Загрузка
Сохраняем файлы.
save(x_records, file = "X_Google_Maps_history.RData")
save(y_records, file = "Y_Google_Maps_history.RData")Анализ
Объединяем записи
В данном случае работать с одним массивом данных проще, чем с двумя, поэтому для анализа мы создадим длинную версию всех записей.
# Объединяем записи
if(file.exists("combined_records.RData")) {
get(load("combined_records.RData"))
} else{
columns <-
c(
"person",
"timestamp",
"coordinates",
"latitude",
"longitude",
"accuracy",
"source"
)
combined <- full_join(x_records, y_records, by = columns) %>%
group_by(timestamp, coordinates, person) %>%
mutate(max_accuracy = min(accuracy), .keep = "unused") %>%
unique()
}## # A tibble: 418,929 × 7
## # Groups: timestamp, coordinates, person [408,904]
## timestamp latitude longitude source person coordinates max_accuracy
## <dttm> <dbl> <dbl> <chr> <chr> <chr> <dbl>
## 1 2015-01-13 02:00:00 -25.9 29.3 CELL Chan -25.89, 29… 12
## 2 2015-01-13 02:10:00 -25.9 29.3 CELL Chan -25.89, 29… 12
## 3 2015-01-13 02:20:00 -25.9 29.3 CELL Chan -25.89, 29… 27
## 4 2015-01-13 02:30:00 -25.9 29.3 CELL Chan -25.89, 29… 27
## 5 2015-01-13 02:40:00 -25.9 29.3 CELL Chan -25.89, 29… 27
## 6 2015-01-13 02:50:00 -25.9 29.3 CELL Chan -25.89, 29… 27
## 7 2015-01-13 03:00:00 -25.9 29.3 CELL Chan -25.89, 29… 27
## 8 2015-01-13 03:10:00 -25.9 29.3 CELL Chan -25.89, 29… 25
## 9 2015-01-13 03:20:00 -25.9 29.3 CELL Chan -25.89, 29… 25
## 10 2015-01-13 03:30:00 -25.9 29.3 CELL Chan -25.89, 29… 25
## # … и ещё 418 919 строкsave(combined, file = "combined_records.RData")
arrange(combined, coordinates) %>% head(5)## # A tibble: 5 × 7
## # Groups: timestamp, coordinates, person [5]
## timestamp latitude longitude source person coordinates max_accuracy
## <dttm> <dbl> <dbl> <chr> <chr> <chr> <dbl>
## 1 2018-10-20 16:00:00 -25.3 31.0 WIFI Dan -25.344, 31… 17
## 2 2018-10-20 16:10:00 -25.3 31.0 WIFI Dan -25.344, 31… 17
## 3 2015-12-29 09:50:00 -25.4 29.4 WIFI Chan -25.395, 29… 96
## 4 2015-12-29 10:00:00 -25.4 29.4 WIFI Chan -25.395, 29… 51
## 5 2015-12-29 10:20:00 -25.4 29.4 WIFI Chan -25.395, 29… 58Качество и полнота данных
Полнота данных
Анализ количества доступных записей для каждого человека и каждого периода демонстрирует, что 98% периодов Чен записи соответствуют стандартам точности. Для сравнения: записи содержались в 45% периодов Дэна.
Пробелы в записях могут быть вызваны отсутствием мобильного Интернета (который очень дорог в ЮАР) или тем, что телефоны были отключены. Кроме того, пробелы могли возникать, когда настройки конфиденциальности не позволяли собирать историю местоположений.
Эти переменные означают, что каким бы ни был результат, в незафиксированные моменты будет присутствовать неопределённость: возможно, наши пути пересекались, но этому нет никаких доказательств.

Рис. 1: Рассматриваемый интервал времени, демонстрирующий доступность записей для каждого человека. Интервалы времени, имеющие записи только для обоих людей, будут содержать потенциальные совпадения.
Состав записей по источнику
Анализ источников записей демонстрирует, что большинство собранных записей было получено в случаях, когда телефон подключен к Wi-Fi.

Рис. 2: Количество записей по человеку и источнику.
Однако при изучении количества уникальных координат на источник становится очевидно, что большинство уникальных местоположений взято по GPS, и что записи Wi-Fi и мобильной сети привязаны к ограниченному списку местоположений. Все 58865 записей были сделаны при помощи всего 6747 WiFi-маршрутизаторов. Кроме того, 3239 записей были сделаны всего 256 вышками мобильной связи с уникальными координатами.
Мы можем лучше понять это, изучив суммарное количество уникальных записей на уникальное местоположение по источнику. Wi-Fi имеет наибольшее количество записей на местоположение, поскольку, когда мобильные устройства подключены к Wi-Fi, многие записи в радиусе действия Wi-Fi-маршрутизатора централизованы в местоположении маршрутизатора. То же самое справедливо и для сотовых вышек, однако с меньшей частотой. Вероятность фиксации с наибольшей точностью выше всего для записей GPS.
## source unique_locations unique_records records_per_location
## 1 CELL 256 3239 12.7
## 2 GPS 16303 58865 3.6
## 3 WIFI 6747 356825 52.9Точность источников
## Преобразование привело к созданию бесконечных значений на непрерывной оси y## Удалено 14 строк, содержащих отсутствующие значения.
Кроме того, важно учесть различия в точности разных источников. Наряду с наибольшей вероятностью фиксации координат вдалеке от централизованных Wi-Fi-маршрутизаторов и сотовых вышек, записи GPS также в среднем являются наиболее точными.

Рис. 3: Коробчатая диаграмма, демонстрирующая статистику точности по источнику записи. Не забывайте, что минимальная точность задана ранее, поэтому в графике учтены только записи с заданными параметрами.
Насколько близко мы были?
Вот исходный обзор некоторых из самых частых мест, которые мы оба посещали.
#Группируем данные по местам
places <- combined %>%
group_by(coordinates, person) %>%
summarise(latitude, longitude, timestamp, source, records = n()) %>%
arrange(desc(records))
#Находим все места, где был x
x_places <- places %>%
filter(person == x)
#Находим все места, где был y
y_places <- places %>%
filter(person == y)
#Находим пересечение мест, в которых был и x, и y
if (file.exists("both_places.RData")) {
both_places <- get(load("both_places.RData"))
} else {
both_places <-
full_join(x_places,
y_places,
by = c("latitude", "longitude", "coordinates", "source")) %>%
filter(!is.na(records.x)) %>%
filter(!is.na(records.y)) %>%
mutate(both_records = records.x + records.y) %>%
mutate(x_per = (records.x / both_records) * 100) %>%
mutate(y_per = (records.y / both_records) * 100) %>%
mutate(dif_per = x_per - y_per) %>%
# mutate(time_dif = abs(difftime(timestamp.x, timestamp.y, units = "auto"))) %>%
mutate(time_dif = abs(timestamp.x - timestamp.y)) %>%
unique() %>%
arrange(desc(both_records))
}
save(both_places, file = "both_places.RData")Визуализация всех мест, где были мы оба
# Получаем данные карт от Google API
# Примечание: для доступа к API нужно получить ключ на платформе Google Maps.
# Перейдите по адресу https://mapsplatform.google.com/ -> get started -> credentials -> API keys
# Найдите Maps API Key и SHOW KEY, а затем скопируйте и вставьте свой ключ API ниже:
# register_google(key = "[your key]", write = TRUE)
#накладываем данные на карту, выполняем масштабирование по количеству записей и раскрашиваем по тому, кто посещал местоположения чаще
map_most_common_places <- get_map(
location = c(
lon = median(both_places$longitude),
lat = median(both_places$latitude)
),
zoom = 12,
scale = "auto",
maptype = "toner-lite"
)
common_places_map <- ggmap(map_most_common_places) +
geom_point(
aes(
x = longitude,
y = latitude,
size = both_records,
color = dif_per
),
data = both_places,
alpha = 0.8,
position = "jitter"
) +
scale_radius(range = c(1, 10),
name = "Number of records") +
scale_color_gradientn(
colors = three_colors,
name = "Most visited by person",
breaks = c(min(both_places$dif_per), 0, max(both_places$dif_per)),
labels = c(y, "both", x)
) +
theme(
text = element_text(family = "sans"),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank()
) +
ggtitle(label = "Common locations")
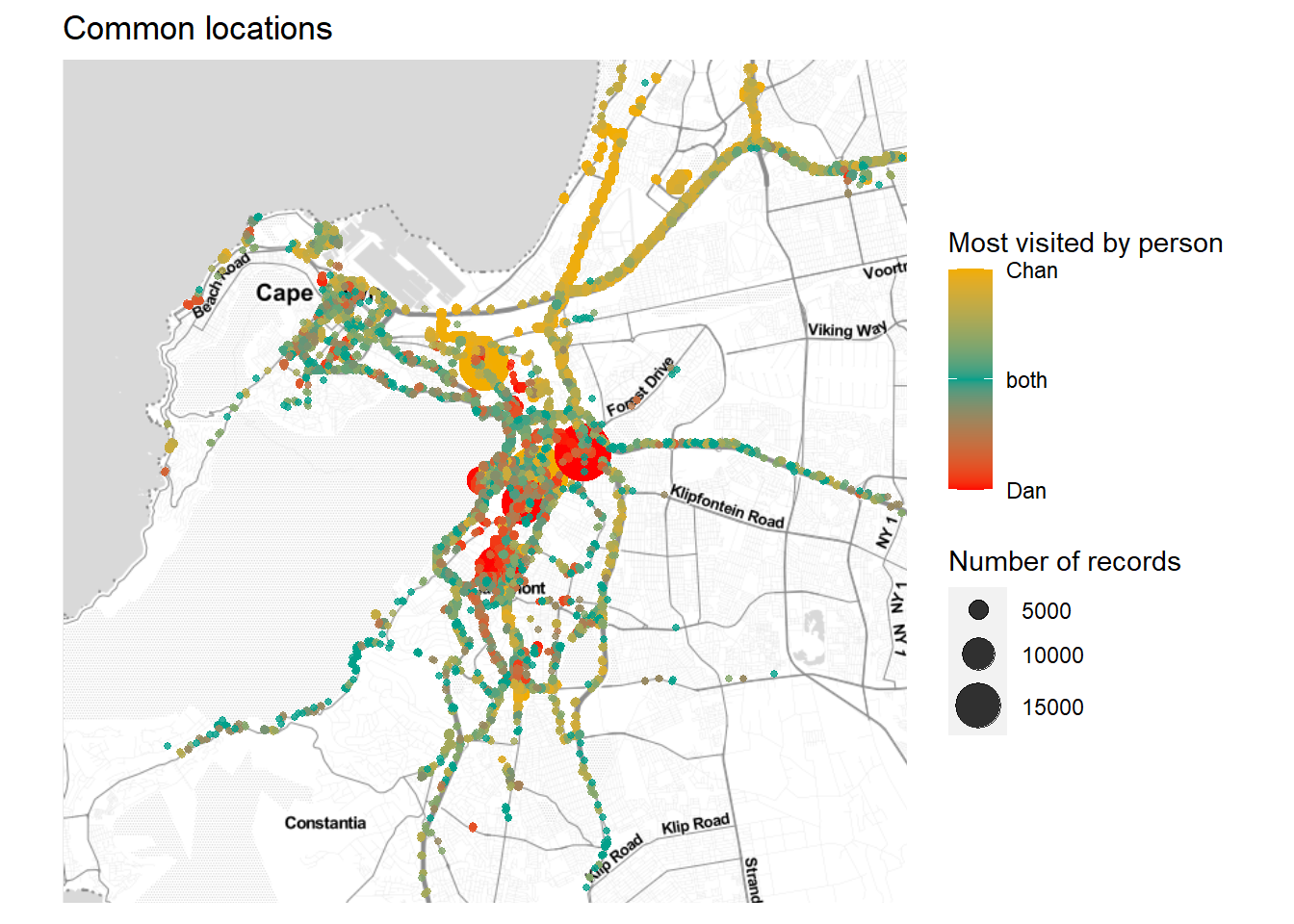
common_places_mapРис. 4: Общие местоположения, в которых оба человека были зафиксированы в пределах всего периода времени. Цветами обозначено, кому принадлежит большинство записей в каждом местоположении.
За пятилетний интервал было 2729 координат, где мы оба зафиксировали записи в какой-то период. Большинство общих местоположений — это основные дороги, ведущие в город и проходящие внутри него. Я жила и работала в северной части города, и это видно по жёлтому цвету. Мой партнёр больше всего времени жил и учился в университете и окрестностях, что видно по красным маркерам.
Насколько близко по времени друг к другу мы находились в этих местах пересечений?
Теперь, когда я смогла сократить количество потенциальных местоположений, в которых мы могли встретиться, нужно измерить, насколько близко по времени друг к другу мы были в этих местоположениях.
Мы уже вычислили разницу во времени (time_diff) между любыми двумя визитами в кадре данных both_places, потому что после объединения двух кадров данных для каждой метки времени посещений человека X появились соответствующие данные для каждой метки времени посещений человеком Y определённого набора координат.
#Чтобы минимизировать время выполнения, мы можем начать с фильтрации значений, разница во времени которых составляет более 12 часов (подавляющего большинства записей).
both_places_under_12_hours <- both_places %>%
filter(time_dif < (12 * 60 * 60))
#Затем можно выполнить группирование по координатам и включить в него случаи с минимальной разницей во времени между посещениями каждой координаты
grouped_places <- both_places_under_12_hours %>%
group_by(coordinates) %>%
mutate(closest_visit = min(time_dif))
closest_timestamps <- grouped_places %>%
unique() %>%
filter(time_dif == closest_visit) %>%
mutate(closest_visit = as.numeric(closest_visit) / 60)
crossed_paths <- closest_timestamps %>% filter(time_dif == 0)
map_close_brushes <- get_map(
location = c(
lon = median(closest_timestamps$longitude),
lat = median(closest_timestamps$latitude)
),
zoom = 15,
scale = "auto",
maptype = "toner-lite"
)
close_brushes_map <- ggmap(map_close_brushes) +
geom_point(
aes(x = longitude, y = latitude, color = closest_visit),
data = closest_timestamps,
size = 2,
alpha = 0.7,
position = "jitter"
) +
scale_color_gradientn(colors = three_colors, name = "Minutes apart (+/- 10 mins)") +
theme(
text = element_text(family = "sans"),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank()
) +
ggtitle(label = "Close encounters") +
geom_text(
data = closest_timestamps,
aes(longitude, latitude, label = closest_visit),
color = "white",
check_overlap = TRUE,
size = 3,
hjust = 0.5,
vjust = -1.2
)
close_brushes_map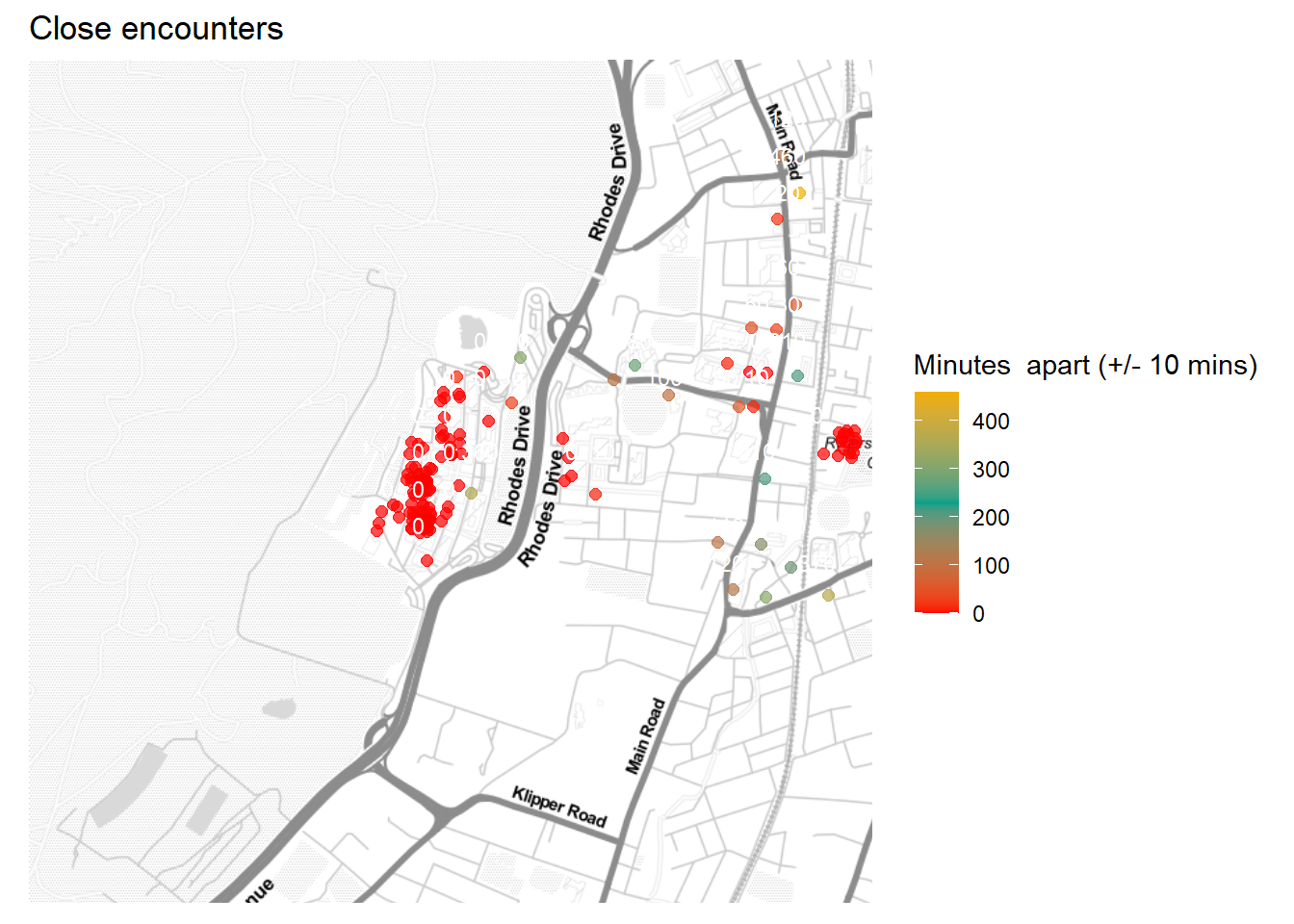
Рис. 5: Ближайшие кисти, демонстрирующие координаты, где наши пути могли пересечься с наибольшей вероятностью. Цвет означает, насколько близко мы были по времени. Красные маркеры — это случаи, когда нас разделяло десять минут или меньше.
Потрясающе! В 33 случаях (в основном в окрестностях кампуса) мы были ближе 111 метров друг от друга с промежутком в 10 или менее минут.
Находим наименьшие промежутки времени в тех же местоположениях
Когда же происходили эти близкие совпадения? Давайте создадим график от времени.
all_intervals <-
seq(from = start_looking_from, to = best_day, by = "10 min") %>%
as.data.frame()
colnames(all_intervals) <- "timestamp"
whole_time_x <-
full_join(all_intervals, x_records, by = "timestamp") %>%
mutate(person = x)
whole_time_y <-
full_join(all_intervals, y_records, by = "timestamp") %>%
mutate(person = y)
#Я использую формулу гаверсинуса для вычисления расстояния между двумя точками на сферической поверхности Земли, потому что эта формула обеспечивает наибольшую точность в масштабе метров.
haversine_calc <- function(lat.x, lat.y, lon.x, lon.y) {
#радиус Земли в км
r <- 6371
#преобразуем градусы в радианы
r.lat.x <- (lat.x * pi) / 180
r.lat.y <- (lat.y * pi) / 180
r.lon.x <- (lon.x * pi) / 180
r.lon.y <- (lon.y * pi) / 180
dlat <- r.lat.y - r.lat.x
dlon <- r.lon.y - r.lon.x
a <- sin(dlat / 2) ** 2 + cos(r.lat.x) * cos(r.lat.y) * sin(dlon / 2) ** 2
c <- 2 * asin(sqrt(a))
d <- c * r
}
whole_time_both <-
full_join(whole_time_x, whole_time_y, by = "timestamp") %>%
filter(!is.na(coordinates.x)) %>%
filter(!is.na(coordinates.y)) %>%
mutate(
distance = haversine_calc(
lat.x = latitude.x,
lat.y = latitude.y,
lon.x = longitude.x,
lon.y = longitude.y
) * 1000
) %>%
arrange(distance)
whole_time_both$accuracy <-
whole_time_both$accuracy.x + whole_time_both$accuracy.y
whole_time_simple <- whole_time_both %>%
select(timestamp, distance, accuracy) %>%
mutate(day = as.Date(timestamp)) %>%
group_by(day) %>%
transmute(min_dist = min(distance), min_acc = min(accuracy)) %>%
mutate(closest_brush = (min_dist == 0)) %>%
unique()
ggplot(whole_time_simple,
aes(x = day, y = min_dist, color = closest_brush)) +
geom_point(
alpha = 0.5,
position = "jitter",
fill = "white",
size = 3
) +
scale_color_discrete(two_colors, name = "Closest brush?") +
theme_classic() +
labs(x = "Date",
y = "Distance from each other (meters)",
title = "Distance apart over time") +
ylim(0, 2500)
Рис. 6: Расстояние между нами в моменты пересечения записей.
В 2016-2017 годах, когда я училась, и до моего выпуска расстояния между нами были меньше, чем в 2018 году, когда я перестала посещать кампус. Поэтому я считаю, что вероятность случайной встречи выше всего была в кампусе, а после этого шансы снизились.
Ответ
#Поиск дат, в которые мы находились друг от друга в 0 м (+/- 111 м)
dates_crossed_paths <- whole_time_both %>%
filter(distance == 0) %>%
mutate(day = as.Date(timestamp))
# %>%
# filter(!day %in% problem_dates)
#Визуализация
map_close_distances <- get_map(
location = c(lon = median(
c(
dates_crossed_paths$longitude.x,
dates_crossed_paths$longitude.y
)
),
lat = median(
c(
dates_crossed_paths$latitude.x,
dates_crossed_paths$latitude.y
)
)),
zoom = 17,
scale = "auto",
maptype = "toner-lite"
)
ggmap(map_close_distances) +
geom_point(
aes(x = longitude.y, y = latitude.y),
data = dates_crossed_paths,
color = two_colors[2],
size = 1,
alpha = 0.5,
position = "jitter"
) +
geom_point(
aes(x = longitude.x, y = latitude.x),
data = dates_crossed_paths,
color = two_colors[1],
size = 1,
alpha = 0.5,
position = "jitter"
) +
theme_void() +
labs(title = "Crossing paths on campus") +
facet_wrap( ~ day, ncol = 4, nrow = 8)
Рис. 7: Чен — синие отметки, Дэн — красные. Каждая из карт соответствует одному из дней, когда наши дороги пересеклись.
total_time_in_uni <- ((total_time/144) - as.numeric(as.Date(best_day) - as.Date("2018/01/01")))*(24*6) %>%
as.numeric()
both_records_time <- whole_time_both$timestamp %>% unique() %>% length()
per_time_with_records <- both_records_time/total_time_in_uni
extrapolated <- crossed_paths_n / per_time_with_records %>% round(digits = 1)Существует 33 зафиксированных случаев, когда мы могли пересечься, в основном в кампусе. Множество раз мы были друг от друга на расстоянии вытянутой руки, но даже не замечали друг друга. Учитывая, что всего 0,7851364% нашего времени имеют записи, соответствующие требованиям точности, то если экстраполировать это до начала 2018, когда я перестала посещать кампус университета (и сделав некоторые сомнительные допущения о том, что записи представляют собой случайную выборку), это значит, что мы могли пересекаться 41,25 раз!
Это настроило меня на очень философский лад. Скорее всего, мы проходили мимо друг друга каждую неделю в течение трёх лет, опустив голову или витая в облаках, мало обращая внимание на окружающих людей. Ченнон из прошлого даже отдалённо не могла предположить, какое влияние не замечаемый ею незнакомец окажет на неё. Узнав об этом, я не могу не смотреть на ежедневно проходящих мимо меня людей в ином свете.
Множество историй наших почти-встреч
Я рада, что залезла в эту кроличью нору, потому что теперь я думаю обо всех этих 41,25 почти-встречах, когда зрители наблюдали бы за нами в большом напряжении. 16 августа 2017 года, ровно за неделю и три года до того, как мы встретимся, Google записал одинаковые координаты GPS нашего местонахождения в этом месте, в котором я часто обедала, рядом с кофейней в здании факультета общественных наук. Прошёл ли он просто по лестнице? Сидел ли в тени деревьев? Стояли ли мы в одной очереди за кофе? Наверно, у Google нет ответов на все вопросы, но выпивая вместе кофе каждое утро, приятно представлять, что годами ранее мы могли молчаливо наслаждаться кофе рядом друг с другом.

Место, где мы пересеклись за три года до нашей встречи: -33.959, 18.46.
Полезные ресурсы
D. Kahle and H. Wickham. ggmap: Spatial Visualization with
ggplot2. The R Journal, 5(1), 144-161. URL http://journal.r-project.org/archive/2013-1/kahle-wickham.pdfMacarulla Rodriguez, Andrea & Tiberius, Christian & Bree,
Roel & Geradts, Zeno. (2018). Google timeline accuracy assessment
and error prediction. Forensic Sciences Research. 3. 240-255.
10.1080/20961790.2018.1509187.movable-type.co.uk/scripts/latlong.html#https://www.geeksforgeeks.org/program-distance-two-points-earth/#:~:text=For%20this%20divide%20the%20values,is%20the%20radius%20of%20Earth.
Комментарии (9)

Akr0n
07.10.2022 17:34+2То чувство, когда всегда и всем отключал эту фичу Гугл, а теперь даже как-то жалко :)

agmt
08.10.2022 06:06Вероятно, что-то не то с моими глазами, но я там чётко видел «Я собираю информацию, хотите, чтобы я её вам показывал? (А ещё я в другом городе и что я тебе сделаю, а в твоём городе тот, у кого есть доступ к локации по вышкам)»

metter
07.10.2022 17:45+3Недавно пересматривал старые фотографии и на одной из них (сделанной в центре города) встрели коллегу по работе, снятую крупным планом. Очень удивлялись.

Exchan-ge
08.10.2022 10:54+1Недавно пересматривал старые фотографии и на одной из них (сделанной в центре города) встрели коллегу по работе, снятую крупным планом.
В 1982 году танцевал на дискотеке с девушкой, лицо которой показалось мне знакомым («точно видел, но не помню где»)
Как выяснилось позже — я видел ее на фотографии «Школьники на линейке 1 сентября», сделанной в 1971 году и попавшей в иллюстрированный фотоальбом, условно назовем его «Наша область и областной центр» — фотограф увидел выразительное лицо девочки и снял ее крупным планом.
Этот фотоальбом был весьма популярным в городе (он и сейчас популярен в сети :) и я довольно часто его пересматривал.

maeris
08.10.2022 05:41+1А если бы она уехала в Японию, её бы там называли Chan-chan. Скелетор вернётся с забавными фактами через неделю.

Pavel1114
08.10.2022 07:38+3Потрясающе! В 33 случаях (в основном в окрестностях кампуса) мы были ближе 111 метров друг от друга с промежутком в 10 или менее минут.
учились в одном университете
Невероятно!
А вообще людям чтобы сойтись обычно мало оказаться на расстоянии менее 100 метро.
Но рассуждения милые и в качестве упражнения статья норм.
Exchan-ge
08.10.2022 10:58+3Мы с моей будущей женой родились, жили и учились очень далеко друг от друга.
А познакомились совершенно случайно.
Причем для возникновения взаимного интереса потребовалось секунд 15 (ей попала соринка в глаз и я помог ее вытащить :)
И это случилось очень давно…
TraurigerNarr
Это чертовски мило)