
Evidently это библиотека, которая помогает оценивать, тестировать и мониторить производительности ML-моделей.
На текущий момент Evidently проводит анализ по трем основным направлениями:
Качество моделей
Дрейф фичей/таргета
Качество данных
Технически Evidently может работать на трех уровнях:
Интерактивном – т.е. вы проводите тесты и строите графики в ноутбуке.
Как часть пайплана обработки данных – вы встраиваете методы Evidently в свой DAG.
Как BI-инструмент – отправляйте метрики в BI систему вроде Grafana.
Начнем знакомство с Evidently с установки…
Установка
Для начала поставим саму библиотеку:
pip install evidentlyЕсли у вас еще не установлена система расширений для ноутбуков поставьте и ее:
pip install jupyter_contrib_nbextensionsДалее установим и включим расширение Evidently:
jupyter nbextension install --sys-prefix --symlink --overwrite --py evidently
jupyter nbextension enable evidently --py --sys-prefixПосле этого вы сможете наблюдать установленное расширение на вкладке Nbextensions.

На этом установка закончена и прежде чем мы перейдем к экспериментам, немного разберем теорию…
Терминология
Применение моделей машинного обучения предполагает, что набор данных на котором проводилось обучение и набор данных для предсказания похожи. Иначе точность модели будет оставлять желать лучшего, поскольку модель выучила одни закономерности, а вы подсовываете ей другие.
Различия могут быть как в очевидных вещах: например, расхождение в значениях категориальных переменных или в типах колонок, так и более сложных: например, выбросы или дрейф данных. Для поиска таких различий и предназначена Evidently.
Дрейф данных это изменение распределения в данных с течением времени. Для более подробного объяснения см. доклад:
- https://www.youtube.com/watch?v=LuBPN2KtCKQ
- https://habr.com/ru/company/glowbyte/blog/681772/

Evidently на вход принимает два набора данных: эталонный (reference) и текущий (current). Эталонный это тот, с которым мы производим сравнение и на который в идеале должны быть похожи другие датасеты. Обычно это датасет, на котором производилось обучение. Текущий датасет с т.з. машинного обучения это либо тестовый датасет, либо датасет для предсказания.
Для некоторых тестов достаточно одного набора данных.
Для анализа Evidently предоставляет две основные абстракции: Наборы тестов (TestSuite) и Отчеты (Report):
Наборы тестов помогают сравнить два набора данных структурированным образом и в основном предназначены для автоматического применения. Каждый набор содержит несколько отдельных тестов. Каждый тест оценивает конкретную метрику и возвращает результат: прошел/не прошел.
Отчеты же в основном предназначены для интерактивного выполнения в ноутбуках и исследования данных. Вместо простого прохождения тестов они рассчитывают различные показатели и создают дашборды с богатым визуальным оформлением.
Посмотрим как выглядит Evidently в ноутбуке:
Интерактивный режим
Каждый блок кода будем выполнять в отдельной ячейки…
Импортируем нужные библиотеки:
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from catboost import CatBoostRegressor
from evidently.pipeline.column_mapping import ColumnMapping
from evidently.report import Report
from evidently.metric_preset import DataDrift, NumTargetDrift
from evidently.test_suite import TestSuite
from evidently.test_preset import DataQuality, DataStability
from evidently.tests import *Загрузим данные…
df = fetch_california_housing(as_frame = True).frame
train = df.query('Latitude > 34')
test = df.query('Latitude <= 34')обучим модель…
fcols = list(df.columns[:-1])
target = 'MedHouseVal'
model = CatBoostRegressor(silent=True)
model.fit(train[fcols], train[target])и выполним предсказание…
train['pred'] = model.predict(train[fcols]);
test['pred'] = model.predict(test[fcols]);В зависимости от Теста/Отчета входные данные могут включать в себя фичи, истинные значения (метки) и прогнозы модели. Кому какие данные требуются смотрите: https://docs.evidentlyai.com/user-guide/tests-and-reports/input-data
Evidently ожидает увидеть определенную структуру во входных данных. В частности колонка с исходным таргетом должна называться target, а предсказания модели - prediction. И тут Вы можете либо переименовать исходные столбцы, либо указать маппинг колонок:
col_map = ColumnMapping()
col_map.target = 'MedHouseVal'
col_map.prediction = 'pred'Настройки маппинга довольно обширны. Более подробно вы сможете ознакомится с ними здесь: https://docs.evidentlyai.com/user-guide/tests-and-reports/column-mapping
Проведем тестирование:
myTest = TestSuite(tests=[DataStability()])
myTest.run(
reference_data=train, current_data=test, column_mapping=col_map)
myTestЗдесь мы:
Определяем набор тестов (указав один из преднастроенных - DataStability).
Проводим тестирование, указав тренировочный и тестовые датасеты.
Выводим результат.
Тесты можно применять либо ко всему датасету, либо к его отдельным столбцам.
Визуальное оформление тестов весьма скромное. По сути просто: прошли или нет.

Из функциональных возможностей, здесь есть различные группировки по статусу и можно посмотреть визуально на конкретный тест.
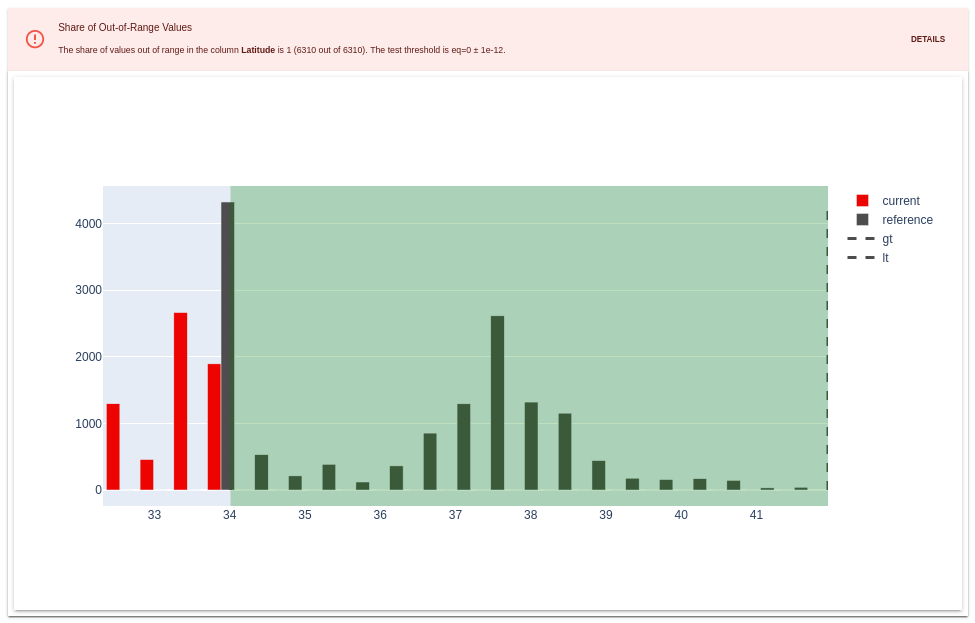
В TestSuite можно включить как наборы тестов так и отдельные тесты.
Список преднастроенных наборов на данный состоит из:
NoTargetPerformance
DataStability
DataQuality
DataDrift
Regression
MulticlassClassification
BinaryClassificationTopK
BinaryClassification
Подробнее с содержимым пресетов и со списком индивидуальных тестов (которые можно включить в набор) вы можете ознакомиться здесь: https://docs.evidentlyai.com/reference/all-tests
Теперь посмотрим как выглядит отчёт. Выполните следующий код:
myReport = Report(metrics=[DataDrift(), NumTargetDrift()])
myReport.run(reference_data=train, current_data=test)
myReportЗдесь мы:
Определили список отчетов, которые хотим построить.
Запустили их формирование, указав тренировочный и тестовые датасеты.
Вывели результат.
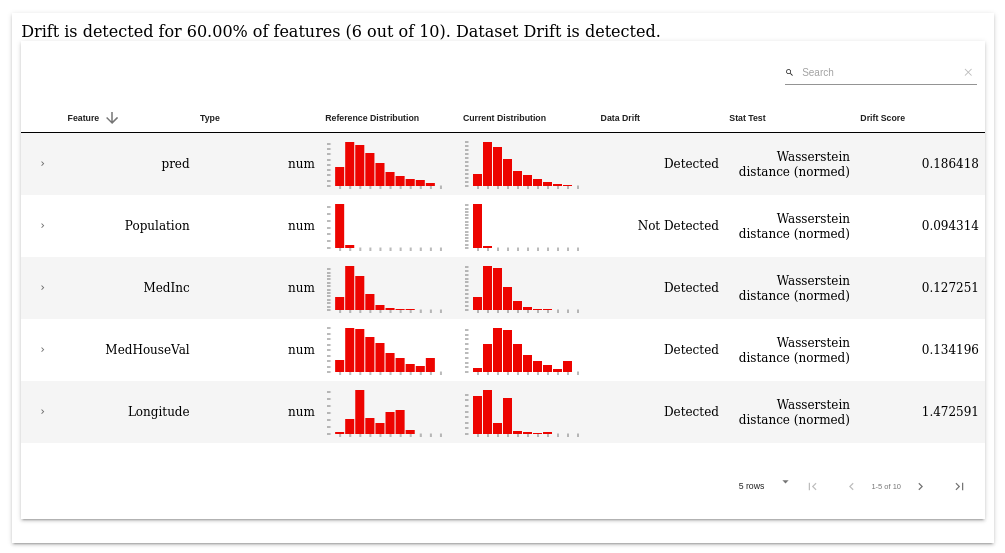
Визуальное оформление отчетов гораздо богаче:

Также как и в тестовых наборах в отдельные тесты можно провалиться.

Визуальная часть тестов однотипна для всех тестов, а вот каждый отчет имеет свою визуальную специфику:

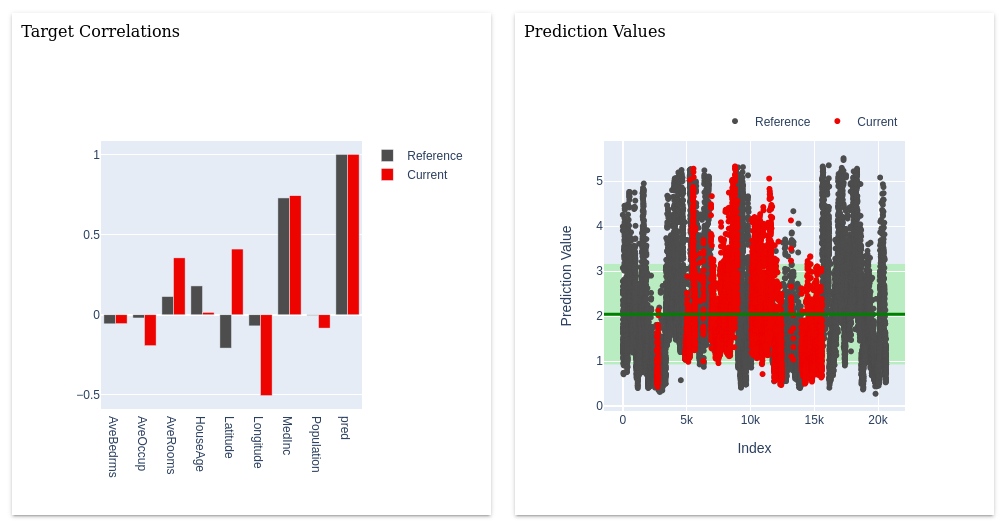
Т.к. графики строятся с помощью библиотеки Plotly, то их можно масштабировать и фильтровать.
На текущий момент доступны следующие отчеты:
Data Drift - сравнивает распределения входных признаков.
Data Quality - считает базовые статистики по фичам.
Numerical Target Drift - обнаруживает изменения в распределении числового таргета.
Categorical Target Drift - то же самое что и числового, только для категориального таргета.
Regression Performance - анализирует производительность регрессионной модели и ее ошибки.
Classification Performance - анализирует производительность и ошибки модели классификации. Работает как для бинарных, так и для мультиклассовых моделей.
Probabilistic Classification Performance - анализирует производительность модели классификации с т.з. предсказанных вероятностей, проверяет качество калибровки модели и ее ошибки.
Как они визуально выглядят можете посмотреть здесь: https://docs.evidentlyai.com/reports
Для больших датасетов отчеты могут долго строится. Как вариант можно попробовать использовать подвыборку из ваших данных.
Визуальную часть тестов и отчетов можно сохранить в виде HTML-страницы (например, чтобы отправить по почте):
myReport.save_html('file.htm')Сам не проверял, но в документации написано, что отчеты не отображаются в ноутбуках под виндой. А в целом, если есть проблемы с визуализацией, то в документации есть отдельная страница по этой теме:
https://docs.evidentlyai.com/user-guide/tests-and-reports/supported-environments
Автоматический пайплайн
Очевидно, что при промышленной эксплуатации моделей проводить регулярное ручное исследование данных не очень продуктивно. Для автоматические проверок вы можете извлечь всю необходимую информацию из тестов в формат JSON и спроектировать вокруг нее пайплайн. Например, если какие-либо тесты не пройдены, вы можете отправить оповещение, переобучить модель или создать отчет.
В Airflow это можно было бы сделать посредством оператора BranchPythonOperator:
...
def check_test():
myTest = TestSuite(tests=[DataStability()])
myTest.run(
reference_data=train, current_data=test, column_mapping=col_map)
myTest_dict = myTest.as_dict()
# Считаем кол-во неудачных тестов
fails_cnt = 0
for t in myTest_dict['tests']:
if t['status'] == 'FAIL':
fails_cnt += 1
if fails_cnt > 0:
return 'send_report'
else:
return 'save_prediction'
check_test_branch = BranchPythonOperator(
task_id = 'check_test',
python_callable = check_test)
...
Business Intelligence
Evidently может динамически строить аналитику и выводить ее посредством интеграции с такими BI-инструментами как Grafana и Prometheus.
За подробностями сюда:
https://docs.evidentlyai.com/integrations/evidently-and-grafana
https://github.com/evidentlyai/evidently/tree/main/examples/integrations/grafana_monitoring_service
Данные функционал находится в активной разработке.

Что дальше
А дальше изучаем примеры :)