

Не существует набора строгих правил, следуя которым можно гарантировать надёжность продукта. В этой статье SRE-инженеры из Google расскажут о том, как оценить культуру надёжности в вашей организации и какой она должна быть.
Надёжное ПО повышает доверие пользователей к организации, эффективность процессов разработки и качество продуктов. Сбои вредят клиентам и бизнесу, но при разработке новых функций многие организации думают только об устранении последствий инцидентов и решают проблемы тактически, а не стратегически. Часто они не понимают, что можно работать быстро и при этом создавать надёжный продукт.
В Google много думают о надёжности продуктов, и некоторые аспекты этой философии хорошо изучены. Например, принципы проектирования продукта или системы. При этом мало кто задумывается о том, как влияют на надёжность продукта культура и менталитет в организации. Мы верим в то, что надёжность продукта зависит от архитектуры, процессов, культуры и менталитета в организации, а не только от усилий разработчиков при проектировании. Другими словами, надежность должна быть вплетена в ткань организации.
В этой статье рассказывается об опыте и извлеченных уроках управленцев из Google, которые повлияли на культуру продуктовых и инженерных команд.
Цели
Стремление к надёжности должно быть неотъемлемой частью корпоративной культуры. В Google выделяют несколько уровней культуры надёжности в организации. Они не сопровождаются строгими рекомендациями для улучшения ситуации. Не воспринимайте их как список обязательных правил или как способ навязать конкуренцию командам. Используйте их для вдохновения, чтобы развивать культуру своей команды и повышать надёжность ваших продуктов.
Континуум культуры надёжности в организации
На основе наблюдений в Google выделили пять уровней культуры надёжности: нулевой, реактивный, проактивный, стратегический и визионерский. Эти термины описывают организацию на момент времени, определяются целым рядом атрибутов и подходят для разных классов рабочих нагрузок.
Нулевой уровень
Надёжность обеспечивается постольку поскольку.
Главная метрика в организации — запуск функций. Все сфокусированы на ней.
Большинство проблем обнаруживается пользователями или тестировщиками.
Организация не знает о долгосрочных рисках для надёжности.
При разработке скорость важнее надёжности.
Этот уровень может подходить для продуктов и проектов, которые пока находятся на стадии разработки.
Реактивный уровень
Реакция организации на риски или проблемы с надёжностью напрямую связана с недавними инцидентами. Иногда после этого принимаются какие-то меры. Редко выделяются долгосрочные инвестиции на исправление системных проблем.
У команд определены какие-то метрики надёжности, и они используют их при необходимости.
Они пишут постмортемы в случае инцидентов и составляют тактические планы действий.
Героическими усилиями отдельных личностей поддерживается разумная доступность.
Периодически разработчики отвлекаются на исправление проблем, связанных с надёжностью. Разработка новых функций иногда может останавливаться.
Этот уровень подходит для продуктов и проектов до запуска или на этапе стабильного долгосрочного сопровождения.
Проактивный уровень
В организации существуют процессы для выявления и снижения потенциальных рисков надежности.
Риски регулярно пересматриваются и приоритизируются.
Команды проактивно управляют зависимостями и оценивают метрики надёжности (SLO).
Новые проекты на начальных этапах оцениваются на предмет известных рисков и режимов отказа. Сохранение минимальной функциональности (graceful degradation) входит в базовые требования.
Бизнес понимает, что нужно постоянно инвестировать в надёжность и поддерживать баланс между надёжностью и скоростью разработки.
На этом уровне должно находиться большинство сервисов и продуктов, особенно если у них большой потенциальный ущерб или они критически важны для бизнеса.
Стратегический уровень
Организации на этом уровне управляют классами рисков, внося системные изменения в архитектуры, продукты и процессы.
Надёжность лежит в основе любых действий по проектированию, разработке и сопровождению программного обеспечения. Организации используют системный подход к надёжности.
Существует тенденция к упрощению на уровне архитектуры продукта. Зависимости постоянно улучшаются или сводятся к минимуму.
Кросс-функциональные команды могут одновременно поддерживать надежность и скорость разработки.
Организации отмечают успехи продвижения по этапам обеспечения качества и стабильности.
Этот уровень подходит для сервисов и продуктов, которым требуется очень высокая доступность для удовлетворения критических потребностей бизнеса.
Визионерский уровень
Организация достигла высочайшей надёжности и поддерживает другие компании на этом пути, делясь своими знаниями и опытом.
Все инженеры и другие специалисты понимают, что такое надёжность и как её достичь.
Системы обладают свойством самовосстановления.
Улучшения архитектуры в поддержку надёжности положительно влияют на продуктивность (скорость релизов), потому что на обслуживание тратится меньше времени.
На этом уровне находится очень мало продуктов и услуг, и это непременно лидеры отрасли.
На каком уровне находитесь вы?
Важно понимать, что организация не обязана находиться на стратегическом или визионерском уровне. Повышение уровня требует немалых расходов. По нашему опыту, для большинства продуктов будет вполне достаточно проактивного уровня.
Ниже приводится простой график распределения продуктов Google по уровням. Как видите, это стандартная гауссова кривая. Большинство команд находятся на проактивном уровне. Руководитель должен осознанно выбрать уровень в зависимости от требований продукта и ожиданий клиентов.
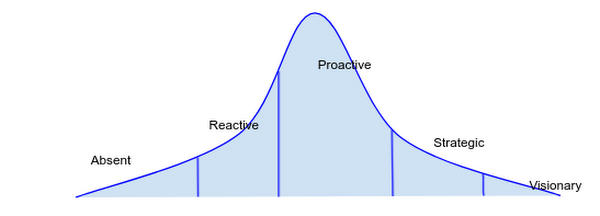
Часто уровни бывают смешанными. Например, в целом, команда может находиться на реактивном уровне с некоторыми атрибутами проактивного. Поддержание культуры высокой надёжности требует немалых усилий, но они окупаются за счёт расходов на сопровождение.
Просто честно оцените, на каком уровне вы находитесь, и целенаправленно развивайте атрибуты, необходимые именно для вашего продукта. Если у вас нет культуры надёжности или вы действуете реактивно, не забывайте, что это вполне нормальная ситуация для начальных этапов или долгосрочного сопровождения стабильного продукта.
Уровни надёжности в действии
Давайте посмотрим на примеры организаций и их прогресс (или регресс) по уровням.
Конечно, все компании и команды разные, и переход между уровнями может требовать больше или меньше времени, но обычно дорасти до хорошего проактивного уровня можно года за два-три. На проактивном уровне все части организации вносят свой вклад в надёжность продукта без ущерба для скорости релизов. Требуется время и усилия, чтобы оставаться на проактивном уровне.
Общими усилиями
Одна команда занималась инфраструктурными сервисами и начала с нескольких очень понятных API. Один толковый член команды, архитектор продуктов, хорошо понимал систему и следил за её бесперебойной работой. Он проверял разумность каждого решения о проектировании и участвовал в устранении всех крупных инцидентов. Он знал систему от и до и мог точно предсказать, что повлияет, а что не повлияет на ее стабильность. Когда он ушёл из команды, всё вышло из-под контроля. На бэкенде и фронтенде происходили сбой за сбоем.
В ответ руководители запустили краткосрочные и долгосрочные программы по восстановлению надёжности, направленные на то, чтобы сократить радиус поражения и последствия от глобальных сбоев. Руководство понимало, что одними инженерными решениями не обойтись. Нужно было изменить саму культуру компании, чтобы каждый сотрудник считал надёжность продукта своим приоритетом. Они провели масштабное обучение по методам обеспечения надёжности, включили в процесс проверки надёжности архитектуры и проекта и стали поощрять сотрудников за усилия, направленные на повышение надёжности.
В результате организации удалось подняться с реактивного уровня на стратегический и создать культуру, в которой надёжность — ответственность каждого сотрудника, а не маленькой группы энтузиастов.
Взлёты и падения
Конечные пользователи рассчитывают на надёжность продукта. От этого зависит их доверие к вам. Одна команда в Google долгие годы считала надёжность своим приоритетом и задавала планку для других команд. Она достигла визионерского уровня, но с годами к базовому сервису добавлялись всё новые продукты, и удерживать прежний уровень надёжности становилось все сложнее. Баланс между надёжностью и скоростью разработки был нарушен, и организация опустилась на реактивный уровень.
Чтобы исправить ситуацию, руководители пересмотрели свой подход к надёжности и практики работы, например, сместили приоритеты. Понадобилось несколько лет, чтобы вернуться на стратегический уровень.
Принципы надёжности как фундамент
Ещё одна команда выпустила новый продукт для пользователей и собиралась добавлять в него функции и расширять базу пользователей. Неожиданно продукт стал очень популярен.
Команда так сосредоточилась на том, чтобы учесть все требования пользователей и повысить привлекательность для клиентов, что у них накопился большой технический долг и много проблем с надёжностью. Они не продумали надёжность при создании сервиса, так что пришлось приложить огромные усилия, чтобы исправить ситуацию.
Например, они переписали очень много кода и переработали архитектуру, чтобы достичь стабильности. Руководители команды стали поощрять действия, направленные на повышение надёжности, во всех частях организации — от управления продуктами до разработки пользовательского интерфейса, чтобы сотрудники по всей организации помнили о важности надёжности для долгосрочного успеха продукта. Потребовалось несколько лет, чтобы сформировать новую культуру.
Заключение
Организация должна честно оценить свой уровень надёжности и определить, какой уровень подойдёт для её бизнеса и продукта. Нередко организации поднимаются по уровням, а затем спускаются обратно, когда продукт становится зрелым, стабилизируется, а затем уступает место новому поколению. Чтобы подняться на стратегический уровень, требуется больше четырёх лет и очень внушительные инвестиции по всем аспектам бизнеса. Вы должны быть уверены, что эти инвестиции оправданы.
Изучите свою культуру надёжности, оцените, на каком уровне вы находитесь, определите, какой уровень вам подходит, и аккуратно двигайтесь к нему. Изменить культуру сложно, и в этом вам не помогут приказы и штрафы. Не забывайте, что это непрерывный процесс. Бизнес постоянно меняется, поэтому невозможно раз и навсегда установить планку надёжности и надеяться, что она будет поддерживать себя сама.
Еще больше о надежности и SRE
С 6 по 27 декабря в Слёрм пройдет обновленный курс SRE: data-driven подход к управлению надежностью систем.
Обучение составлено по принципу полного погружения в среду, чтобы студенты не просто изучали теорию и смотрели видеоуроки, а могли сами потрогать различные инструменты и поработать в команде.
Для этого мы создали собственное приложение по продаже билетов для кинотеатров, на котором учащиеся в общей сумме больше 16 часов примеряют на себя роль SRE-инженеров и решают реальные задачи. Еженедельные теоретические лекции и ама-сессии со спикерами помогут выбрать, какие практики нужны именно вашему бизнесу и как их успешно внедрить.
На курсе вы:
узнаете, как снизить ущерб от отказов в будущем;
внедрите правки прямо в прод;
узнаете, как решать конкретные проблемы, связанные с надежностью сервиса;
поймете, какие метрики собирать и как это делать правильно;
научитесь быстро поднимать продакшн силами команды.
Формат предполагает разбор интересных кейсов и обмен опытом между участниками команды и спикерами. Помимо того, что учиться будет интересно, благодаря новым знаниям и практики вы сможете:
снизить процент отказов своего сервиса;
повысить скорость реагирования на отказы;
снизить риски при выкате новых фич;
увеличить скорость разработки.
Курс хорошо подходит как для только думающих внедрять в компании практики SRE, так и для сформировавшихся команд, которые хотят опробовать новые практики, улучшить имеющиеся и обменяться опытом с коллегами.
Начните учиться бесплатно
Посмотрите бесплатный демо-курс о внедрении SRE в компаниях и метриках, которые используют SRE-инженеры для мониторинга надежности системы.