
Введение
Звук – HiFi-стриминг с большой командой инженеров. Мы используем передовые технологии и современный стек, и экспериментируем, чтобы решать сложные, нестандартные задачи. Одна из технологий – GraphQL.
Эта статья изначально создавалась как гайд по работе с GraphQL для инженеров Звука (системные аналитики, разработчики, QA). При этом статья может быть полезна всем, кто никогда не работал с GraphQL, но очень хочет понять, зачем он может быть нужен, и как поможет решить задачу вашего бизнеса.
В статье есть ответы на следующие вопросы:
Как мы используем GraphQL
GraphQL очень хорошо работает в случае, когда необходимо в приложении одни и те же объекты отображать в разных местах приложения с разным набором данных. У нас это альбомы, артисты, плейлисты, профили и т.д.
Для примера возьмём два варианта отображения артистов в Звуке:
1. Запрос данных артистов на странице Топ-100 https://zvuk.com/top100 (внизу страницы). Здесь запрашивается минимальный для отображения набор данных — id артиста, имя и аватарка. Причём запрашивается сразу несколько артистов.

Примеры запроса и ответа
Запрос

Ответ

2. Запрос данных артистов на странице артиста – https://zvuk.com/artist/3253180. Тут данных уже намного больше: id, имя, аватарка, топ популярных треков (включая данные самого трека), релизы (включая данные релиза), а также похожие артисты (включая данные).
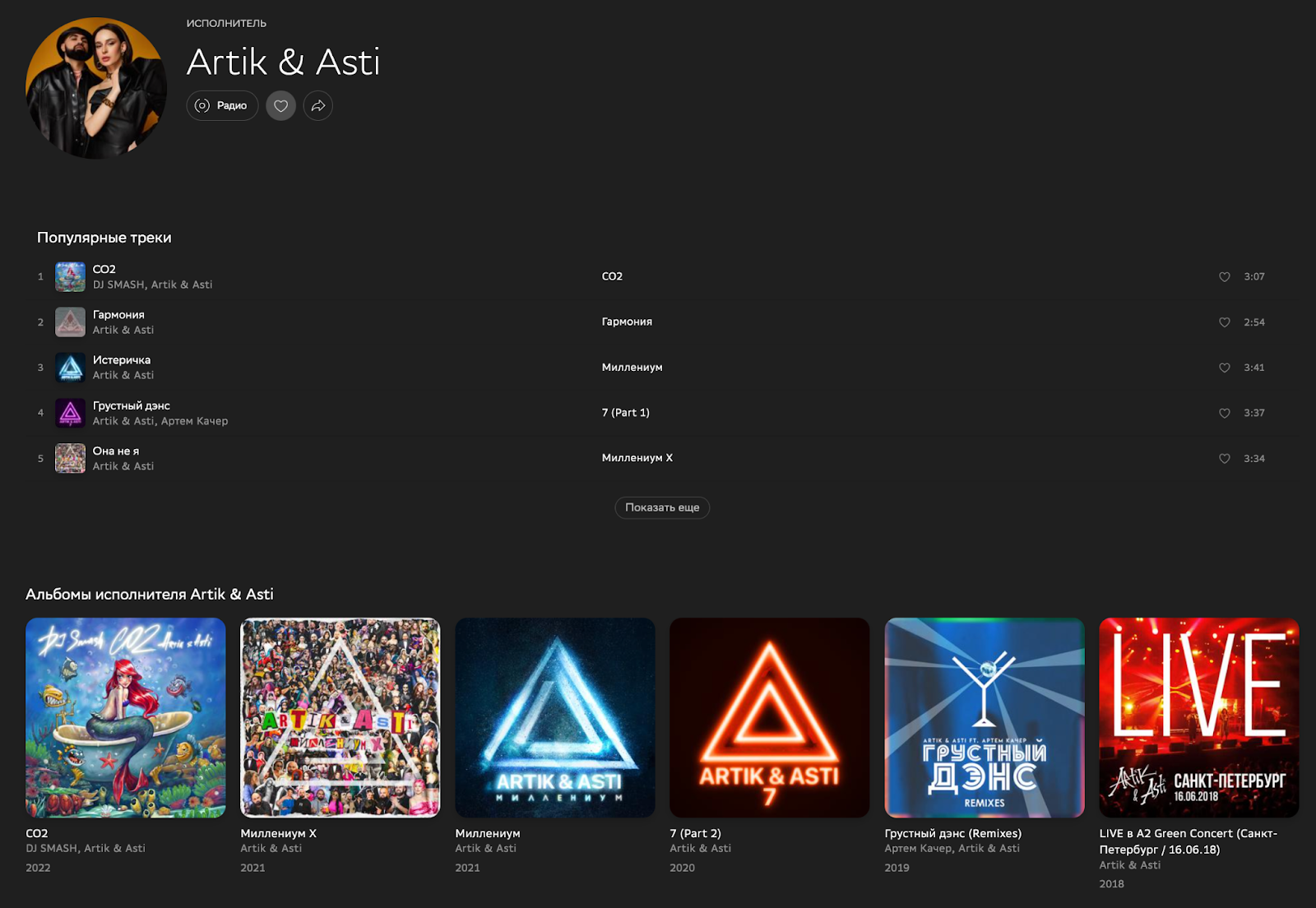
Пример запроса и ответа
Запрос

Ответ

Смысл в том, что клиентские приложения (WEB, IOS, Android) могут запрашивать только тот набор данных, который необходим для конкретного экрана. При этом, на бэкенде не приходится программировать несколько методов по отдельности. В GraphQL программируется каждое отдельное поле или объект (если это возможно).
Почему мы выбрали GraphQL?
Наш продукт устроен так, что в нём часто используются одни и те же объекты в разных представлениях (артисты на примере выше). Для решения этой проблемы есть следующие варианты:
Создавать разные API методы для каждого представления объекта только с необходимым набором данных.
Создать один метод для получения всех данных объекта.
В первом варианте получается очень много разработки на бэкенде, а во втором клиентские приложения часто будут получать очень много лишних данных. Решением этой проблемы может являться GraphQL.
GraphQL позволяет нам один раз запрограммировать объект со всеми его полями, а уже клиентское приложение отправит запрос только за теми данными, которые нужны ему прямо сейчас.
GraphQL Schema
Что это?
В GraphQL для разработки API пишется схема определённого вида. В схеме описываются:
Объекты – в GraphQL они задаются ключевым словом type и пишутся с большой буквы.
-
Поля объектов. У поля должно быть описано:
Название поля (всегда пишется с маленькой буквы)
-
Что возвращает это поле (всегда пишется с большой буквы):
Может быть один из типов (String, Int, Boolean и тд)
Другой объект (type)
Может ли это поле быть null (другими словами — обязательность). Обязательность обозначается знаком «!«
-
Методы запроса данных (query). У метода должно быть описано:
Название метода
Входные параметры
Выходные типы или объекты
-
Методы изменения данных (mutation). У этих методов должно быть описано то же самое:
Название метода
Входные параметры
Выходные типы или объекты
ENUM, UNION.
Связи с другими микросервисами (об этом тоже дальше).
Типы GraphQL
У GraphQL типы можно разделить на две группы:
-
Стандартные GraphQL типы. Например, это:
ID
Int
String
Boolean
DateTime и тд.
-
Пользовательские (то есть созданные нами) GraphQL типы. Например, это:
Artist
Track
Release
Profile и тд.
Пример GraphQL схемы
Это пример схемы нашего сервиса мета-информации (в нём хранится информация обо всех треках, релизах, артистах и тд)

Здесь, например, описана сущность Трек, которая обладает следующими полями:
id – обязательное поле (обозначается знаком «!«) со стандартным GraphQL типом ID.
Название – поле, возвращающее стандартный GraphQL тип String – «Строка».
Продолжительность – поле, возвращающее стандартный GraphQL тип Int – «Целое число».
Есть ли у трека качество Flac – поле, возвращающее стандартный GraphQL тип Boolean – «Булево поле».
Артисты – поле, возвращающее массив объектов с типом Artists,
Здесь идёт ссылка на объект «Артист», объявленный нами в этой же схеме (вторая картинка). Объект «Артист» также имеет свои поля.
Query
Query – метод запроса данных в GraphQL. Для создания нового метода надо задать его внутри типа Query.

Например, для запроса данных о треках создаётся следующий query:
Название – getTracks.
Входные параметры – массив id треков (массив здесь обязателен, внутри массива тоже не может быть null).
Возвращаемый объект – тип Трек.
Для запроса данных надо написать query вот такого вида:
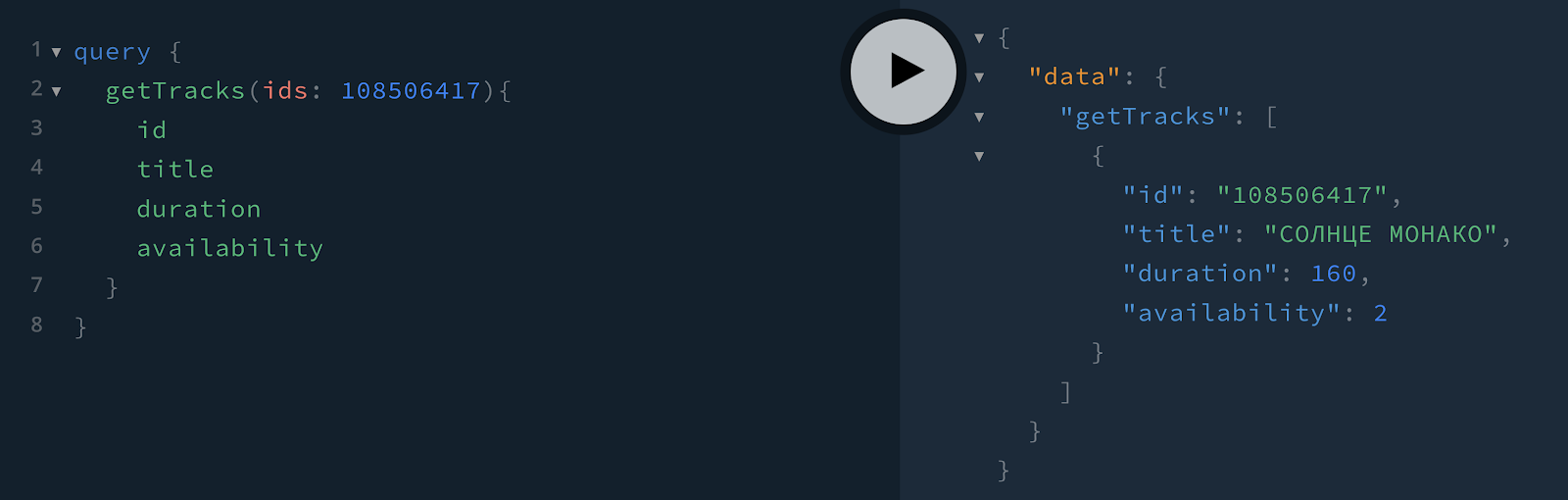
В ответ мы получаем те данные, которые мы запросили.
Если мы хотим получить не только название трека, но ещё и артистов, который исполняют этот трек, то надо выполнить вложенный запрос. Пример запроса:
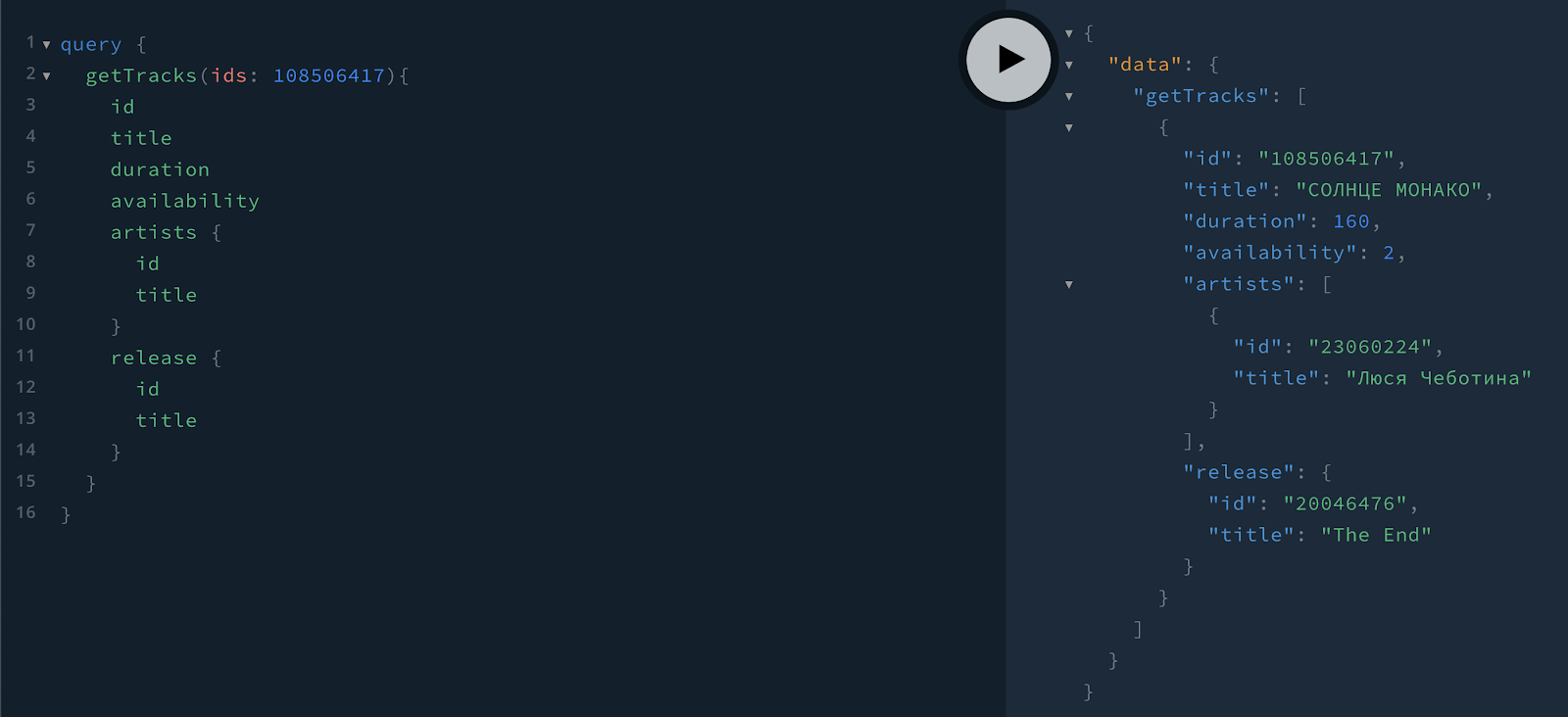
В ответе мы видим связь трека и артиста, который этот трек исполняет.
Mutation
Мутация – метод изменения данных. Для создания мутации её надо описать внутри типа Mutation.
Пример описания мутации – добавление и удаление сущностей из коллекции (коллекция – это хранилище любимых треков, альбомов и артистов пользователя). Здесь используется вложенность мутаций. Нужно это только для удобства.

На примере использование мутаций выглядит так:

Мы добавили трек с id 108506417 в коллекцию. В ответе нам вернулся null. Ошибки нет, всё успешно.
Можно выполнить запрос Query, чтобы получить треки из коллекции. Добавленный только что трек – там!

ENUM
Enum – конструкция для ограничения того, что можно передать в API. Например, при запросе добавления трека в коллекцию мы передавали туда тип CollectionItemType, который является enum и может принимать только следующие значения:
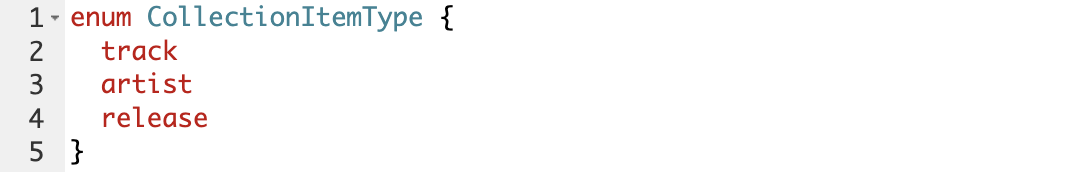
Если бы мы передали в запросе строку, которая не является одним из этих типов — на уровне API мы не смогли бы выполнить запрос.
UNION
Union – конструкция, которая позволяет одному объекту иметь разный набор данных. Например, у нас в Звуке есть несколько типов профилей – обычные пользователи, профили компаний и профили артистов. У профилей компаний есть сайт, которого нет у остальных типов. А у профилей артистов есть ссылка для донатов и связанный с профилем артист из сервиса информации о контенте. Для организации таких разных профилей используется UNION.

У профиля есть поле additionalData с типом ExtraProfileData, который является UNION. Соответственно, в зависимости от типа профиля он содержит те данные, которые у него должны быть. В схеме это описывается так:
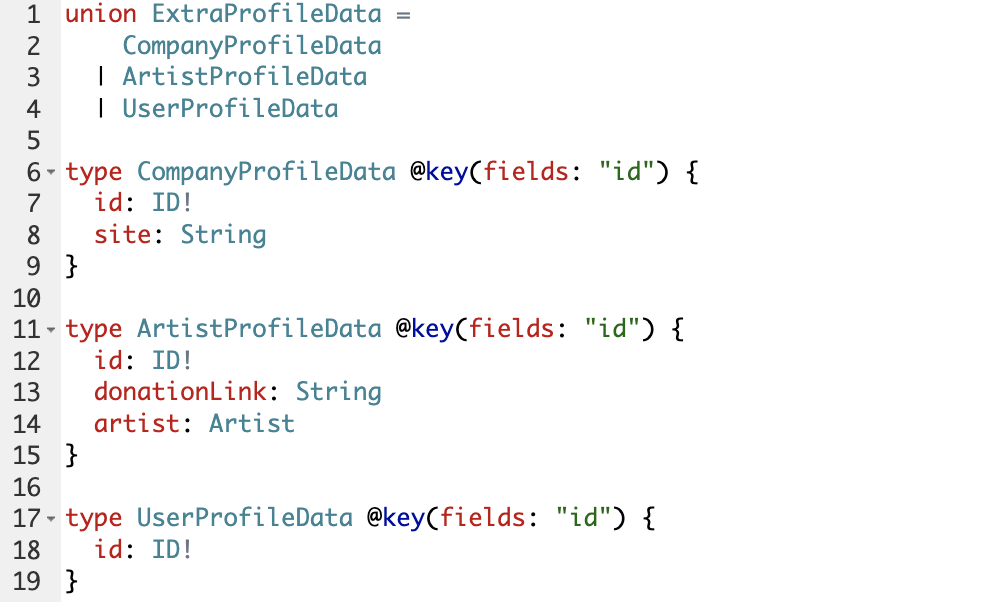
Пример запроса и ответа с UNION
Для выполнения запроса таких данных используется специальная конструкция.
При запросе объекта с UNION необходимо указать ключевое слово __typename. В ответ на это поле сервис вернёт одно из значений UNION (CompanyProfileData, ArtistProfileData, UserProfileData)
У каждого из объектов UNION может быть разный набор полей. Чтобы определить, какие поля мы хотим получить, надо указать конструкцию «... on CompanyProfileData». А дальше в этом объекте указать нужные поля.
Выглядит это так:
Запрос

Ответ для компании

Ответ для обычного пользователя

При выполнении одного запроса (с разными id) мы получаем те данные, которые есть у конкретного профиля. Так у профиля компании мы получаем сайт, а у пользователя никаких дополнительных данных нет.
GraphQL в микросервисной архитектуре
Причём тут микросервисы?
В микросервисной архитектуре данные о какой-то сущности могут находиться в разных базах данных и разных микросервисах. В REST подходе это решается несколькими возможными вариантами: несколько запросов с клиента в разные сервисы, соединение данных на каком-то самописном сервисе и тд. В GraphQL для решения этой проблемы мы используем инструмент Apollo Federation.
Apollo Federation
Apollo Federation – open-source решение, которое позволяет значительно снизить количество необходимой разработки. Официальная документация Apollo: https://www.apollographql.com/docs/federation/
Архитектура Apollo Federation
Архитектура Apollo Federation состоит из:
Клиентов – потребителей информации, которые понимают GraphQL и умеют делать запросы на этом языке (Apollo Clients для React, iOS, Kotlin).
Шлюза (Траслятора). На backend cоздаётся новый уровень в слое обработки запросов, предоставляющий доступ к GraphQL для клиентов. Когда клиентское приложение придёт за данными, то сервис на этом уровне выполнит запросы в сервисы, которые являются источниками нужных данных (Apollo Federation).
Набора подграфов – отдельных серверных служб, в каждой из которых определена GraphQL-схема части суперграфа, за которую она отвечает. Эти сервисы выступают источниками данных для сервиса Federation.
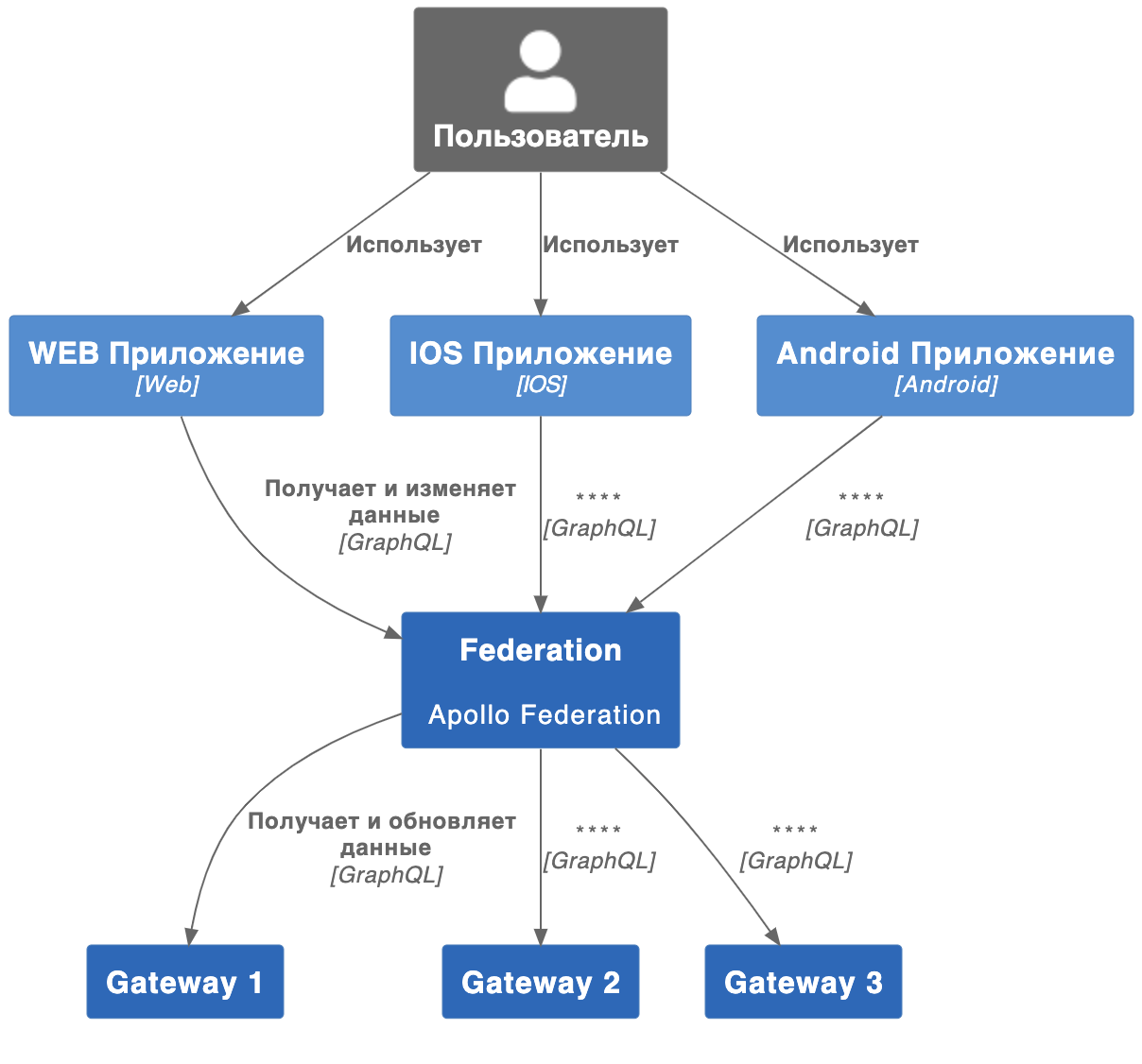
Как это работает у нас

У нас есть несколько баз данных, над ними находятся сервисы с GraphQL интерфейсом. Несколько сервисов с GraphQL интерфейсами объединяются сервисом Federation.
Что такое Federation? Сервис Federation собирается сам на основе схем других сервисов с GraphQL интерфейсами. Благодаря схемам остальных сервисов Федерация знает, где какие данные лежат. И сама за этими данными сходит, когда на неё придёт запрос. Сервис Federation не надо программировать, только настроить.
Как сделать связь между сервисами Apollo Federation
У нас в Звуке есть сервис Playlist GraphQL Service, который хранит в себе данные обо всех плейлистах. При этом в базе данных есть поле tracks, в котором просто лежит массив id треков (например — [ 123, 456, 789 ]). В сервисе плейлистов НЕТ данных треков (названия, картинки и тд).
При этом у нас есть сервис Content GraphQL Service, который хранит в себе мета-информацию по трекам (и не только).
Если мы выполним запрос данных плейлиста непосредственно к Playlist GraphQL Service, то сможем получить только id треков из этого плейлиста (так как в этом сервисе просто нет других данных).
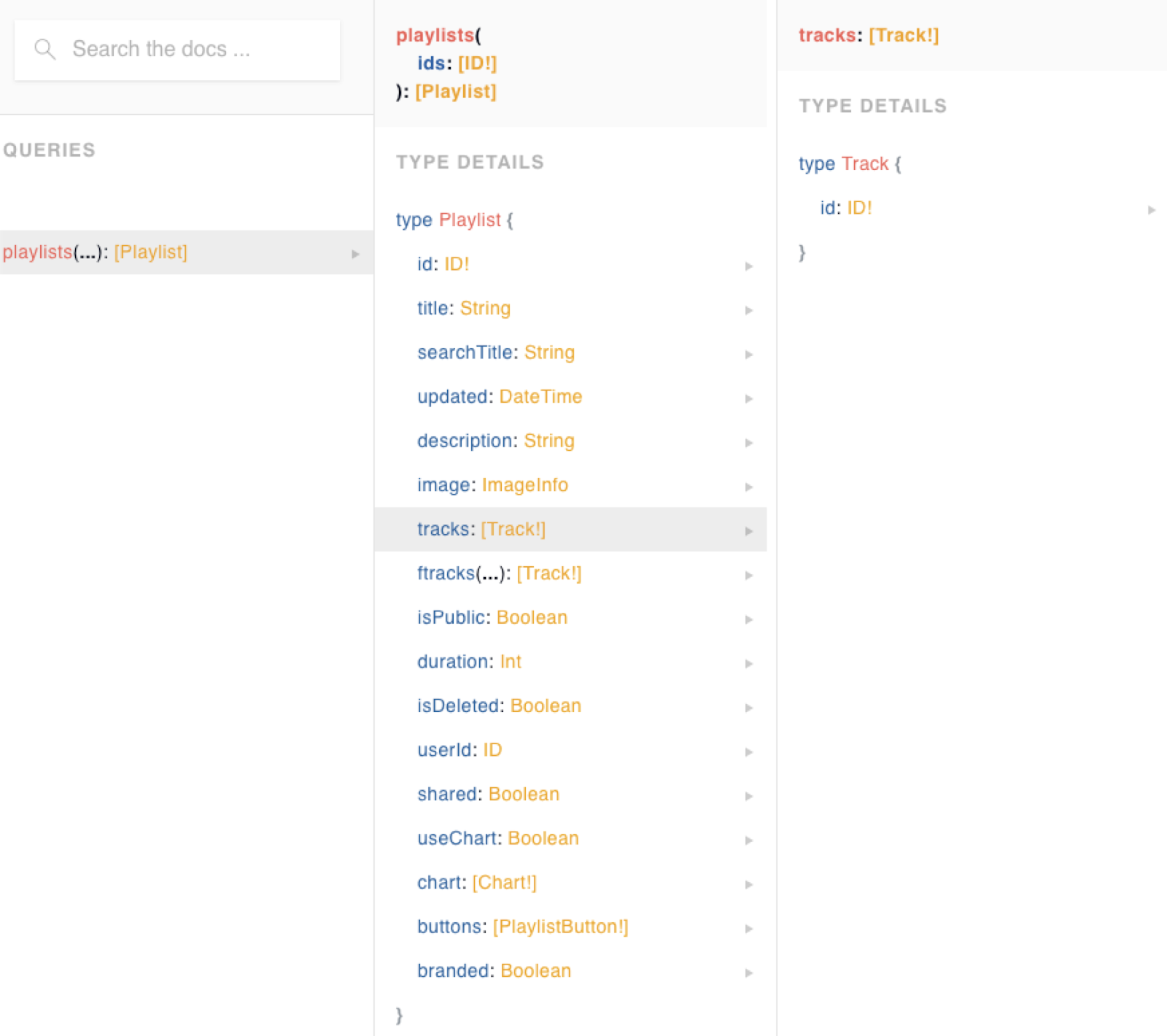
А при запросе к Federation мы видим в документации намного больше полей у трека, которые на самом деле лежат в Content GraphQL Service.
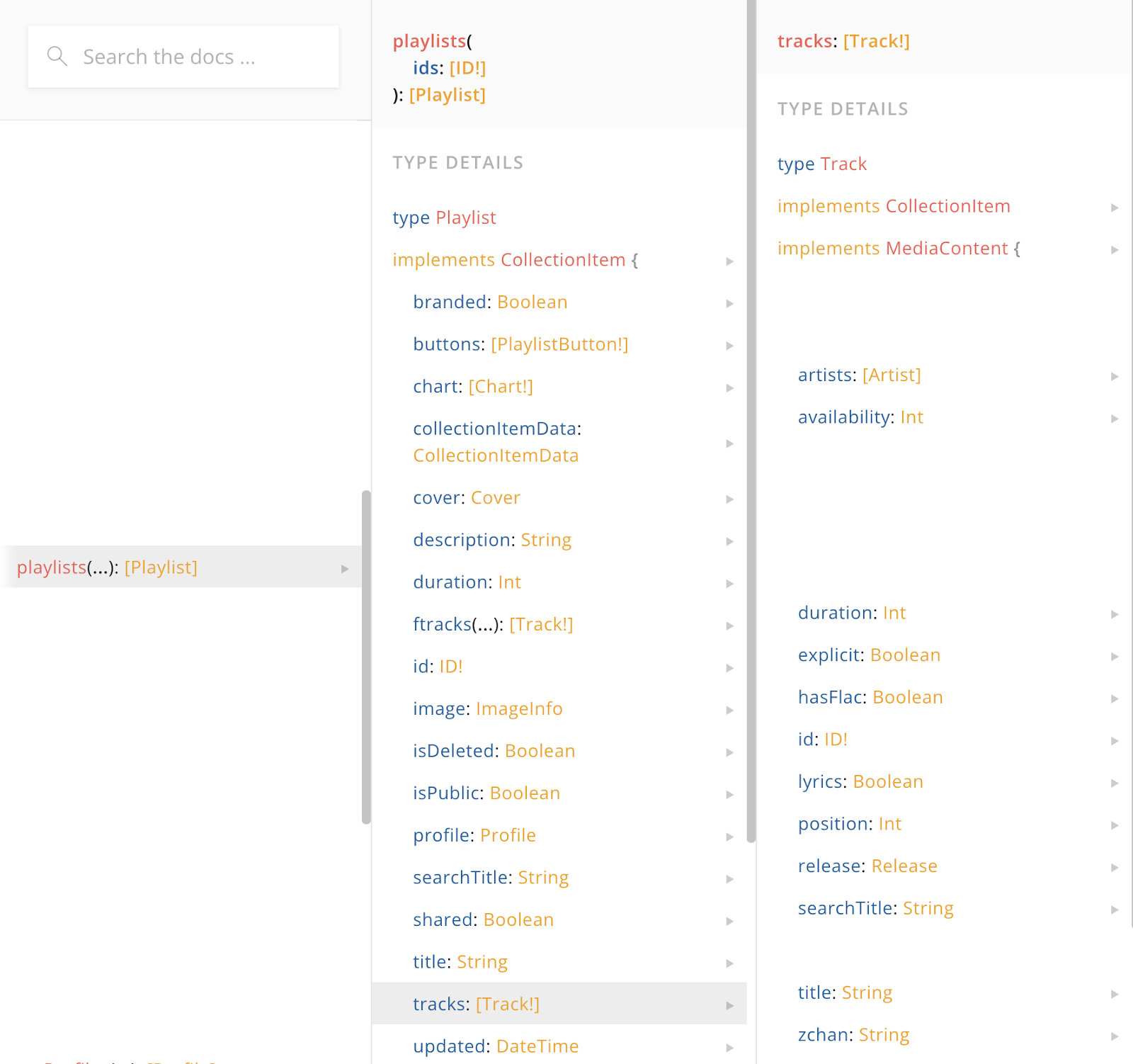
Можно выполнить один запрос сразу за всеми данными плейлиста. Для клиентских приложений всё выглядит так, как будто Федерация связывает между собой данные из разных сервисов и предоставляет единый удобный интерфейс.
Часть GraphQL схемы Playlist GraphQL Service:

Часть GraphQL схемы Content GraphQL Service:

Как сделать связь сущностей
Пример связи плейлистов и треков. Ещё раз отмечу – в сервисе плейлистов лежат только id треков, а в в сервисе мета лежит вся остальная мета-информация.
В Content GraphQL Service у сущности Track мы прописываем @key (fields: «id»), которые обозначают, что поле id – первичный ключ, по которому сущность можно связать с одноимёнными сущностями в других сервисах
-
В Playlist-Gateway надо создать сущность Track и прописать ей
@key (fields: «id») – по этому полю надо этот трек связывать с другими
@extends – эта сущность – наследник
@external около поля id значит, что это поле исходно находится в другом сервисе
В Playlist GraphQL Service у сущности Playlist поле tracks может возвращать тип Track, который мы уже обозначили в этом сервисе на шаге 2.
Теперь можно делать запросы, описанные выше.
Как это работает?
Благодаря тому, что на каждом сервисе есть описанная GraphQL Схема, Федерация знает, в какой сервис за какими данными надо обращаться. Так что для примера с плейлистами выполняется следующая последовательность шагов:
Запрос плейлистов с треками приходит на Федерацию (Federation)
Федерация идёт за данными плейлиста в Playlist GraphQL Service
Федерация получает данные плейлиста, и, в том числе, id треков, которые находятся в плейлисте
С этими id Федерация обращается в Content GraphQL Service для получения мета-данных треков
Федерация получает мета-данные треков, соединяет все данные из разных сервисов в один JSON и возвращает его на Фронт

Ещё один пример
У нас в Звуке есть социальная механика на пересечении музыки и технологий: пользователи могут проверить, насколько их вкусы совпадают, а ещё скоро появится возможность обогатить собственную коллекцию и получить плейлисты с рекомендациями на базе совместных предпочтений c треками в HiFi-качестве.
Каждый пользователь приложения Звук может увидеть жанровое совпадение предпочтений с другими слушателями в процентом соотношении. Оценка музыкальной совместимости базируется на анализе истории прослушиваний и действий пользователя внутри Звука — лайках и дизлайках

Реализовано это так, что у нас есть профиль в сервисе Profile GraphQL Service
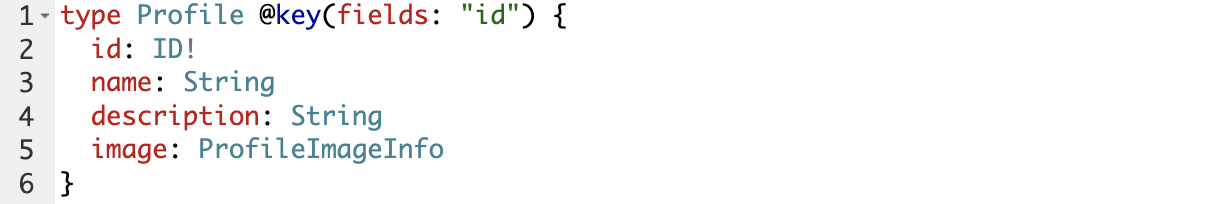
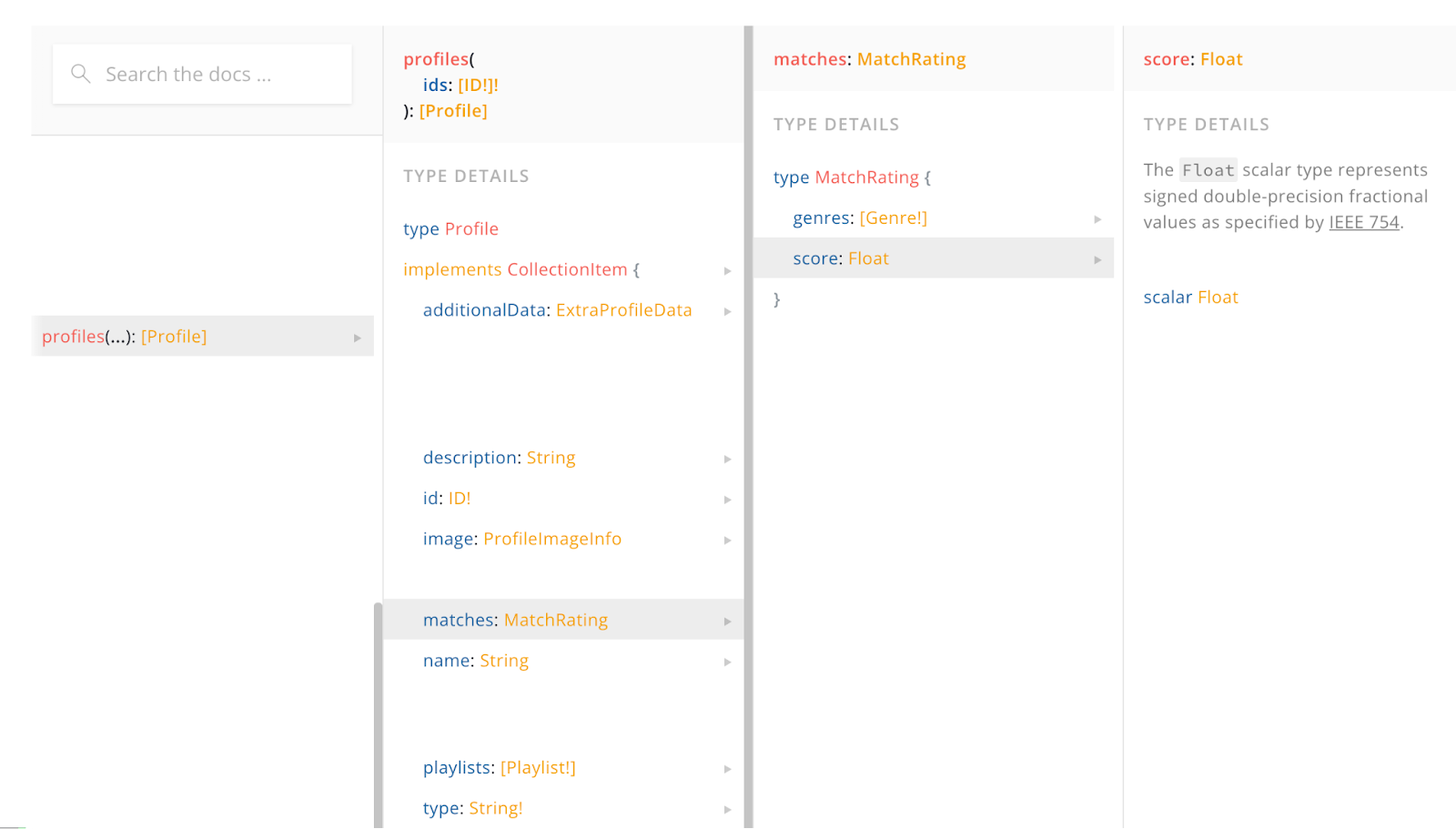
И у нас есть сервис Matchrating GraphQL Service, который производит расчёт и расширяет профиль этим числом score.

Это работает так, что когда на Федерацию приходит запрос профиля, где одним из полей будет поле matches, то Федерация сама знает, что за этим полем надо сходить в Matchrating GraphQL Service.
В итоге на Федерации документация выглядит так, что клиенты (IOS, Android, WEB) могут вообще не задумываться о том, где там что лежит.
Что было бы без GraphQL?
Ответ довольно очевиден – мы бы и дальше использовали REST. При этом нам пришлось бы намного больше сервисов программировать и поддерживать. Если рассмотреть пример со страницей плейлистов, то вполне можно было бы решить эту задачу и без использования GraphQL:
-
Отправка множества запросов данных с клиента, что значительно увеличивает нагрузку на фронтенд или мобильное приложение

-
Программирование и поддержка некоторого сервиса, который будет объединять данные из нескольких сервисов. По сути мы просто сами должны программировать аналог сервиса Federation (который, напомню, не требует разработки с нашей стороны)

При использовании REST API клиенты (фронтенд и мобильные приложения) всегда получали бы много лишних данных, которые не нужны им в данный момент для отрисовки страницы. GraphQL отдаёт клиентам только те данные, которые они запросили. Чем меньше данных, тем быстрее они загружаются с сервера в мобильное приложение.
Плюсы GraphQL
GraphQL создавался как альтернатива REST API и решает следующие проблемы:
Позволяет клиенту запрашивать только те данные, которые ему нужны.
Снимает необходимость несколько раз обращаться за данными.
Уменьшает зависимость клиента от сервера.
Делает разработку более эффективной за счет декларативного описания данных для API.
Минусы GraphQL
GraphQL, как и любая технология, имеет свои недостатки. Вот некоторые из них:
Уязвимость для атак на исчерпание ресурсов из-за избыточно сложных запросов с большой вложенностью (треки -> авторы трека -> треки авторов -> авторы трека -> …).
В GraphQL сложнее организовать ограничение доступа к данным. Каждый клиент может запросить почти всё, что хочет.
N+1 SQL-запросы (чтобы заполнить все поля-функции данными, может потребоваться новый SQL-запрос на каждое поле). У нас эта проблема решается использованием DataLoader’ов.
Более сложный подход к кэшированию в связи с тем, что в GraphQL нет возможности использовать стандартные для многих механизмы HTTP-кэширования. Для формирования ответа запрос GraphQL должен обязательно дойти до бэкенда.
Итог
Мы считаем, что в Звуке достоинства GraphQL значительно перевешивают недостатки. Благодаря этой технологии мы значительно упрощаем разработку и снижаем время доставки новых фичей до пользователей нашего сервиса.
Полезные ссылки
Официальная документация Apollo: https://www.apollographql.com/docs/federation/
Популярная статья на Habr с базовым объяснением концепции GraphQL: https://habr.com/ru/post/326986/

Нижников Евгений
Системный аналитик в Звуке, автор этой статьи
Комментарии (29)

Funb
09.11.2022 15:33-1Спасибо за статью, очень интересно и структурировано!
За примеры - отдельное спасибо.


dph
09.11.2022 19:07+4Не совсем понятно, а какой выигрыш у GraphQL в сравнении с каким-нибудь json-rpc-like протоколом. Указанные плюсы или совсем несущественные (уменьшение числа получаемых полей) или неверны (уменьшение зависимости от бэка). А вот проблемы - очень существенные, по сути делающими невозможным работу с сколь-нибудь существенной нагрузкой и объемом данных.
У GraphQL есть интересные сценарии использования - но совсем не такие, как указаны в статье.

Dogrtt
09.11.2022 20:37+2Уж как пробивал у нас на проекте один товарищ GQL, уж как нахваливал его, любо-дорого было послушать. Как он осмеивал и оплёвывал простой REST. Дали ему добро, в результате, он просит запрашивать максимум по 15-25 сущностей и не чаще чем раз в 5 секунд, иначе сервис ложится... В общем, то ли приготовил он его хреново, то ли лыжи не едут...

LabEG
09.11.2022 20:48Тоже встречал такую проблему, сложные запросы вешали сервер по нагрузке. Кучка маленьких рестов оказались много эффективнее.

Kwisatz
10.11.2022 09:35Потому что в инете очень много реализаций с крайне неэффективными резолверами, например с запросами в цикле. Причем самое смешное, что это исправляется очень быстро.
Хотя даже 100 сущностей перебором в цикле не должны давать сколь нибудь существенной нагрузки.
Протокол на самом деле очень крутой и решает множество проблем. Где то тут была такая же статья яндекса по переходу. Проблема в том что нет исчерпывающей, доступной каждому информации с указением best practice. Например сколько я обсуждал "проблему n+1" людя делятся на тех кто мучается (и даже не в курсе что резолверы так работать не должны) и тех кто не понимает о чем речь (потому что by design)

ggo
10.11.2022 10:33+1GraphQL хорош для взаимодействия фронта с беком. Человеческого фронта. В связи с чем на странице необходимы данные из 15-25 сущностей? Есть ощущение, что это избыточно.
Исходя из моего опыта, в абсолютном большинстве случаев достаточно до 5-6 сущностей на запрос. И вполне может быть несколько gql-запросов, каждый поставляет данные по своему жизненному циклу. Скажем профиль пользователя с его расширенными свойствами, типа подразделение, роли, должности, подтягиваются одним запросом. Табличные данные с пажинацией, другим запросом. Нотификации - третьим.
А проблема N+1 - у нее два аспекта. 1) если источник данных один для двух сущностей, которые нужно склеивать, то это значит разработчики поленились реализовать правильные фетчеры. graphql не причем, это просто транспорт. 2) источники данных разные для двух сущностей, которые нужно склеить. это нетривиальный случай. причем нетривиальный хоть для graphql, хоть для любой другой технологии. dataloader'ы из graphql позволяют закрыть определенные аспекты, но важно понимать, что задача склеивания данных из двух разных источников в общем случае само по себе нетривиальная.
Вот с чем нужно быть осторожным в graphql, это с мутациями. Использовать их очень точечно, там где логика тривиальна. Можно конечно RPC пытаться натягивать на мутации, но это чревато. Для RPC лучше использовать REST.

michael_v89
10.11.2022 14:17Мне кажется, мутации это и есть RPC в чистом виде, какой он и должен быть — с методами, аргументами и типами, а не имитация через HTTP-протокол. Только разделения на пространства имен нету, приходится префиксами группировать.

ermadmi78
12.11.2022 13:39GraphQL по своей природе позволяет вытаскивать сложные графы взаимосвязанных объектов. Что порождает проблему N+1 при взаимодействии с реляционными базами данных.
Это не означает, что GraphQL "плохой". Это означает, что GraphQL'ем надо уметь пользоваться. Точно так же, как и например SQL'ем. Ведь запросто можно написать SQL запрос, который "положит" реляционную базу. Но из за этого же никто не отказывается от реляционных баз в пользу файлового хранилища.
Тут вообще хорошо прослеживается аналогия с реляционными СУБД. Неопытный "GraphQL разработчик" совершает те же ошибки, что и неопытный "SQL разработчик".На первом месте стоит ошибка в проектировании GraphQL API. Неопытный "SQL разработчик" начитавшись умных книжек начинает проектировать схему базы данных чуть ли не в 5й нормальной форме. Неопытный "GraphQL разработчик" под впечатлением от возможностей синтаксиса GraphQL'я при проектировании API лепит связи там где нужно и там где не нужно. Лечится эта болезнь точно так же, как болезнь 5й нормальной формы - денормализацией. В случае реляционных СУБД проектируем схему в 3й нормальной форме, а потом, в узких местах "денормализуем" до 2й или даже 1й нормальной формы. В случае с GraphQL API закладываем в API все естественныен связи между нашими типами, а потом критически смотрим на получившуюся схему - и убираем все лишние связи и связи, которые потенциально могут породить сложные выборки.
Неопытный SQL разработчик выучив джойны начинает джойнить все что нужно и все что не нужно - потому что может. Точно так же, неопытный GraphQL разработчик начинает тащить сложные граф одним запросом, даже если для решения его прикладной задачи весь этот граф даром не нужен. Просто тащит, потому что может :)
В целом, при переходе на GraphQL нужно четко понимать, что это не серебряная пуля и не волшебная палочка Гарри Потера. Это очень мощный и серьезный инструмент. С помощью которого, при неумелом использовании, можно запросто отстрелить себе ноги. Но, если его хорошо освоить и грамотно использовать, то можно получить гигантские преимущества. На мой взгляд преимущества GraphQL перед REST API такие же, как преимущества реляционных СУБД перед помойкой из файликов.
LabEG
09.11.2022 20:47А как выглядит описание моделей для мобильных клиентов? На каждый кастомный квери запрос пишется кастомная модель?

pantsarny
09.11.2022 23:19Да, клиент формирует запрос и должен знать структуру ответа. По сути это коллекция моделей с ассоциативной вложеностью.

NizhnikovEvgeny Автор
10.11.2022 09:00Да, так и есть. Спасибо за ответ)
Может быть, будет полезно: в GraphQL запросах клиенты могут использовать Fragments для повторяющихся объектов с одним набором данных. Почитать можно здесь – https://graphql.org/learn/queries/#fragments

savostin
09.11.2022 21:02И все-таки, как вы решаете 1,2 и 4 "минусы"? Это, мне кажется, настолько большие проблемы, что без решения могут поставить крест на всей этой замечательной архитектуре.
NizhnikovEvgeny Автор
10.11.2022 09:23С одной стороны, надо развивать культуру разработки в компании (как минимум бэкенд должен общаться с фронтом). У нас все разработчики клиентских приложений знают об этих уязвимостях GraphQL, так что мы стараемся все вместе продумывать, чтобы их запросы были адекватны по нагрузке для бэкенда. А с другой стороны, и в GraphQL есть механизмы защиты от таких запросов. Можно, например, использовать систему весов. Для этого на каждое поле в схеме навешивается определённый вес. Итоговый вес приходящего запроса превышает максимальный – такой запрос не обрабатывается.
Лично я считаю, что GraphQL правда не очень подходит для сильно конфиденциальной информации, для важных пользовательских данных (поэтому GraphQL не слишком широко используется банками и тд). Однако и на уровне GraphQL сервисов у нас есть проверка токенов пользователя, так что никому ничего лишнего мы не отдадим.
-
Я упомянул, что с GraphQL имеются проблемы именно с использованием стандартного HTTP кэширования. Если мы при этом хотим отдать что-то очень быстро, нам это не мешает использовать Redis, чтобы не идти за данными в БД, а быстро получить их из памяти.
Если вам надо разработать простой сервис с небольшим количеством страниц, объектов и их взаимосвязей, то GraphQL может быть излишне сложным и медленным. Но если именно сложность системы и связи между различными объектами в ней значительно замедляют вашу разработку. GraphQL – классный вариант решения этой проблемы)
Спасибо за вопрос)
savostin
10.11.2022 11:36Ну, доступ-то к GraphQL имеют не только "хорошие разработчики backed'а", но и "плохие хакеры". Можно ж тупо выкачать всю, пусть и публичную, базу. Веса спасут, если нагрузка спокойная и/или прогнозируемая. А если маркетинг что-то хорошее придумает, а у вас сервис будет отваливаться по "Too many requests", полетят щепки... Есть ли какой-нибудь fail2ban в GraphQL?
Токены "хорошие"? Со сроком действия и возможностью/необходимостью обновления, типа JWT? В современном мире даже e-mail уже становится "конфиденциальной информацией", а тут такой простор для "парсинга", даже параметры можно выбрать...
NizhnikovEvgeny Автор
10.11.2022 11:47Можно спроектировать API так, чтобы даже у хакеров не было возможности получить чужие пользовательские данные (такие, как email). Если не украсть чужой пользовательский токен, никакие чужие данные даже хакер получить не сможет. Если уж хакер украл токен, то защититься в любом случае будет сложно, GraphQL тут не при чём.
Fail2ban, непрогнозируемая нагрузка и тд можно решать (и мы это делаем) на уровне nginx, который стоит перед нашим бэкендом. То есть GraphQL имеет непрямое отношение к этому. Все необходимые меры безопасности надо предпринимать не только на уровне кода, но и на уровне инфраструктуры (имею в виду nginx и тд)
michael_v89
10.11.2022 14:13При правильном подходе GraphQL API мало чем отличается от обычного REST/RPC API. Вы возвращаете сущность или DTO из контроллера, а GraphQL-слой выбирает из нее поля в соответствии с запросом и настройками маппинга. Не все библиотеки для GraphQL так делают, но это возможно.
savostin
10.11.2022 14:21О каких библиотеках речь? Клиентских? "Плохие люди" могут использовать "плохие библиотеки". Если я правильно понимаю, то GraphQL по сути как открытый MySQL - пиши свои запросы как хочешь и кто хочешь (понятно утрировано, но все же). Имхо, слой приложения хорош тем, что в нем относительно удобно можно (и нужно) ограничить доступ к данным.
michael_v89
10.11.2022 14:30Нет, для бэкенда Например для PHP есть библиотека GraphQLite. По личному впечатлению такой код проще писать и поддерживать, чем HTTP API с громоздкой документацией для Swagger.
savostin
10.11.2022 14:39Т.е. в данном случае GraphQL используется "тупо" как БД? Как мне кажется, идея была именно в том, чтобы отдать клиенту всю логику приложения и убрать слой php полностью.
Т.е. Javascript на клиенте делает запрос типа
curl 'https://zvuk.com/api/v1/graphql' --data-raw $'{"operationName":"getTracks","variables":{"withReleases":true,"withArtists":true,"ids":[124167105]}}"и получает JSON с данными напрямую (автор говорит через NGINX, но без PHP). Захотел, отсортировал как надо. Захотел, получил больше полей. Захотел, скачал всю базу ;)
NizhnikovEvgeny Автор
10.11.2022 14:53+2Нет нет нет, GraphQL совсем не предполагает отказ от разработки бэкенда. Под GraphQL может вообще не быть базы данных. Слой PHP (или любого другого языка) не исчезает.
Какие-то поля могут подтягиваться из базы (это надо прописывать кодом), какие-то поля могут быть получены по API из других систем (это тожно надо прописывать кодом), а какие-то поля могут быть рассчитаны прям в коде (очевидно, тут тоже код)
То есть GraphQL – это такое же API, которое надо разрабатывать. И логику для каждого объекта/поля можно (и нужно) отдельно программировать
michael_v89
10.11.2022 15:22+1Как мне кажется, идея была именно в том, чтобы отдать клиенту всю логику приложения и убрать слой php полностью.
Нет, такой идеи, насколько я знаю, нигде никогда не было.
GraphQL можно рассматривать как развитие обычного HTTP API, с типами и возможностью указывать список нужных полей. Что там что там нужен бэкенд.
ggo
10.11.2022 10:36+1кеширование на стороне источника данных. там где канонически и должно быть. понятно, что у этого есть свои плюсы/минусы.

stranger1101
10.11.2022 09:00Выглядит на первый взгляд интересно, но немного удивляет описанная в статье архитектура. Неужели Apollo Federation действительно
торчит голой ж в интернетдоступна с клиентов напрямую?Кажется же что тогда на неё ложиться ещё вагон всяких задач как раз в духе авторизации, прав доступа и тому подобного, или я ошибаюсь? И они, кажется, могут быть уникальны для каждого сетапа.
Но в роли того чтобы на беке собирать забросы по разным микросервисам - выглядит интересно.
NizhnikovEvgeny Автор
10.11.2022 09:03На самом деле, это скорее концептуальная архитектура на диаграмме. Вы очень правильно заметили, что в таком случае на федерацию ложится слишком много работы, для которой она не приспособлена.
В частности, для авторизации запросов перед федерацией ещё стоит nginx, который и проверяет токены пользователей)
Спасибо за хороший вопрос))
vmityuklyaev
Отличная статья, спасибо, сохранил в закладки)
Буду использовать как мануал ????